


Бірнеше жыл бұрын Кубернетес ресми GitHub блогында. Содан бері ол қызметтерді орналастырудың стандартты технологиясына айналды. Кубернетес қазір ішкі және мемлекеттік қызметтердің айтарлықтай бөлігін басқарады. Біздің кластерлеріміз өсіп, өнімділік талаптары күшейтілген сайын, біз Kubernetes-тегі кейбір қызметтерде қолданбаның жүктелуімен түсіндірілмейтін кідіріс пайда болғанын байқадық.
Негізінде, қолданбалар 100 мс дейін немесе одан да көп кездейсоқ көрінетін желі кідірісін бастан кешіреді, нәтижесінде күту уақыттары немесе қайталанулар болады. Қызметтер сұрауларға 100 мс жылдамырақ жауап бере алады деп күтілді. Бірақ егер қосылымның өзі сонша уақытты алса, бұл мүмкін емес. Бөлек, біз миллисекундтарды алуы керек өте жылдам MySQL сұрауларын байқадық және MySQL миллисекундтарда аяқталды, бірақ сұраушы қолданба тұрғысынан жауап 100 мс немесе одан көп уақытты алды.
Мәселе тек Kubernetes түйініне қосылу кезінде пайда болатыны бірден белгілі болды, тіпті қоңырау Kubernetes сыртынан келсе де. Мәселені қайта шығарудың ең оңай жолы - сынақ , ол кез келген ішкі хосттан жұмыс істейді, Kubernetes қызметін белгілі бір портта тексереді және мезгіл-мезгіл жоғары кідірістерді тіркейді. Бұл мақалада біз бұл мәселенің себебін қалай анықтай алатынымызды қарастырамыз.
Сәтсіздікке әкелетін тізбектегі қажетсіз күрделілікті жою
Сол мысалды қайта шығару арқылы біз мәселенің фокусын тарылтып, қажет емес күрделілік қабаттарын алып тастағымыз келді. Бастапқыда Вегета мен Кубернетес бүршіктері арасындағы ағында элементтер тым көп болды. Тереңірек желі мәселесін анықтау үшін олардың кейбірін жоққа шығару керек.
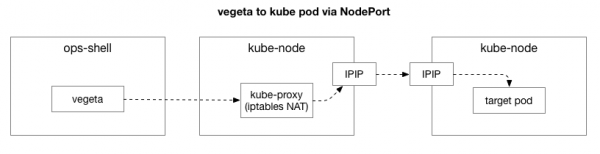
Клиент (Vegeta) кластердегі кез келген түйінмен TCP қосылымын жасайды. Kubernetes пайдаланатын қабаттасқан желі (бар деректер орталығы желісінің үстінде) ретінде жұмыс істейді , яғни ол деректер орталығының IP пакеттерінің ішіндегі қабаттасу желісінің IP пакеттерін инкапсуляциялайды. Бірінші түйінге қосылу кезінде желілік мекенжайды аудару орындалады (NAT) Kubernetes түйінінің IP мекенжайы мен портын IP мекенжайына және қабаттасу желісіндегі портқа (әсіресе, қолданбасы бар подкаст) аудару үшін күй. Кіріс пакеттер үшін әрекеттердің кері тізбегі орындалады. Бұл қызметтерді орналастыру және жылжыту кезінде үнемі жаңартылып, өзгеретін күйі және көптеген элементтері бар күрделі жүйе.
Утилита tcpdump Vegeta тестінде TCP қол алысу кезінде кідіріс бар (SYN және SYN-ACK арасында). Бұл қажетсіз күрделілікті жою үшін сіз пайдалана аласыз hping3 SYN пакеттері бар қарапайым «пингтер» үшін. Жауап пакетінде кешігу бар-жоғын тексереміз, содан кейін қосылымды қалпына келтіреміз. Біз деректерді тек 100 мс асатын пакеттерді қамту үшін сүзе аламыз және Vegeta-дағы толық желілік деңгей 7 сынағымен салыстырғанда мәселені қайта шығарудың оңай жолын аламыз. Мұнда ең баяу жауаптар бойынша сүзілген 30927 мс аралықпен «түйін порты» (10) қызметіндегі TCP SYN/SYN-ACK қолданатын Kubernetes түйіні «пингтері» берілген:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -S -p 30927 -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len = 46 IP = 172.16.47.27 ttl = 59 DF id = 0 спорт = 30927 жалау = SA seq = 1485 жеңіс = 29200 rtt = 127.1 мс
len = 46 IP = 172.16.47.27 ttl = 59 DF id = 0 спорт = 30927 жалау = SA seq = 1486 жеңіс = 29200 rtt = 117.0 мс
len = 46 IP = 172.16.47.27 ttl = 59 DF id = 0 спорт = 30927 жалау = SA seq = 1487 жеңіс = 29200 rtt = 106.2 мс
len = 46 IP = 172.16.47.27 ttl = 59 DF id = 0 спорт = 30927 жалау = SA seq = 1488 жеңіс = 29200 rtt = 104.1 мс
len = 46 IP = 172.16.47.27 ttl = 59 DF id = 0 спорт = 30927 жалау = SA seq = 5024 жеңіс = 29200 rtt = 109.2 мс
len = 46 IP = 172.16.47.27 ttl = 59 DF id = 0 спорт = 30927 жалау = SA seq = 5231 жеңіс = 29200 rtt = 109.2 мс
Бірінші бақылауды бірден жасай алады. Реттік нөмірлері мен уақытына қарағанда, бұл бір реттік кептеліс емес екені анық. Кешігу жиі жинақталады және ақырында өңделеді.
Әрі қарай, біз кептелістің пайда болуына қандай компоненттер қатысуы мүмкін екенін білгіміз келеді. Мүмкін бұл NAT жүйесіндегі жүздеген iptables ережелерінің кейбірі? Немесе желіде IPIP туннельдерінде проблемалар бар ма? Мұны тексерудің бір жолы - жүйенің әрбір қадамын оны жою арқылы тексеру. Тек IPIP бөлігін қалдырып, NAT және желіаралық қалқан логикасын жойсаңыз не болады:
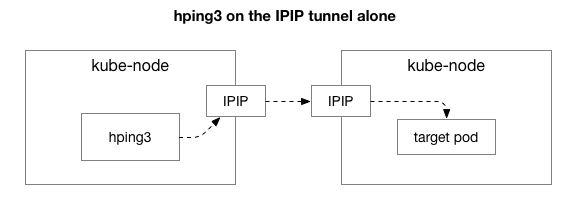
Бақытқа орай, Linux егер машина бір желіде болса, IP қабаттасу қабатына тікелей оңай қол жеткізуге мүмкіндік береді:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=40 ip=10.125.20.64 ttl=64 DF идентификаторы=0 спорт=0 жалаушалар=RA seq=7346 жеңіс=0 rtt=127.3 мс
len=40 ip=10.125.20.64 ttl=64 DF идентификаторы=0 спорт=0 жалаушалар=RA seq=7347 жеңіс=0 rtt=117.3 мс
len=40 ip=10.125.20.64 ttl=64 DF идентификаторы=0 спорт=0 жалаушалар=RA seq=7348 жеңіс=0 rtt=107.2 мс
Нәтижелерге қарағанда, мәселе әлі де бар! Бұған iptables және NAT кірмейді. Мәселен, мәселе TCP болып табылады ма? Кәдімгі ICMP пингінің қалай өтетінін көрейік:
theojulienne@kube-node-client ~ $ sudo hping3 10.125.20.64 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=28 ip=10.125.20.64 ttl=64 id=42594 icmp_seq=104 rtt=110.0 мс
len=28 ip=10.125.20.64 ttl=64 id=49448 icmp_seq=4022 rtt=141.3 мс
len=28 ip=10.125.20.64 ttl=64 id=49449 icmp_seq=4023 rtt=131.3 мс
len=28 ip=10.125.20.64 ttl=64 id=49450 icmp_seq=4024 rtt=121.2 мс
len=28 ip=10.125.20.64 ttl=64 id=49451 icmp_seq=4025 rtt=111.2 мс
len=28 ip=10.125.20.64 ttl=64 id=49452 icmp_seq=4026 rtt=101.1 мс
len=28 ip=10.125.20.64 ttl=64 id=50023 icmp_seq=4343 rtt=126.8 мс
len=28 ip=10.125.20.64 ttl=64 id=50024 icmp_seq=4344 rtt=116.8 мс
len=28 ip=10.125.20.64 ttl=64 id=50025 icmp_seq=4345 rtt=106.8 мс
len=28 ip=10.125.20.64 ttl=64 id=59727 icmp_seq=9836 rtt=106.1 мс
Нәтижелер мәселенің әлі жойылмағанын көрсетті. Мүмкін бұл IPIP туннелі шығар? Тестті одан әрі жеңілдетейік:
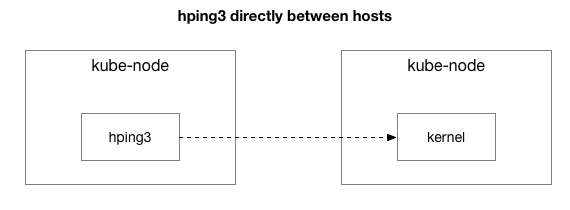
Барлық пакеттер осы екі хост арасында жіберіледі ме?
theojulienne@kube-node-client ~ $ sudo hping3 172.16.47.27 --icmp -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 id=41127 icmp_seq=12564 rtt=140.9 мс
len=46 ip=172.16.47.27 ttl=61 id=41128 icmp_seq=12565 rtt=130.9 мс
len=46 ip=172.16.47.27 ttl=61 id=41129 icmp_seq=12566 rtt=120.8 мс
len=46 ip=172.16.47.27 ttl=61 id=41130 icmp_seq=12567 rtt=110.8 мс
len=46 ip=172.16.47.27 ttl=61 id=41131 icmp_seq=12568 rtt=100.7 мс
len=46 ip=172.16.47.27 ttl=61 id=9062 icmp_seq=31443 rtt=134.2 мс
len=46 ip=172.16.47.27 ttl=61 id=9063 icmp_seq=31444 rtt=124.2 мс
len=46 ip=172.16.47.27 ttl=61 id=9064 icmp_seq=31445 rtt=114.2 мс
len=46 ip=172.16.47.27 ttl=61 id=9065 icmp_seq=31446 rtt=104.2 мс
Біз жағдайды бір-біріне кез келген пакетті, тіпті ICMP пингін жіберетін екі Kubernetes түйініне жеңілдеттік. Мақсатты хост «нашар» болса (кейбіреулері басқаларға қарағанда нашар) болса, олар әлі де кідірісті көреді.
Енді соңғы сұрақ: неге кешігу тек kube-түйін серверлерінде болады? Бұл kube-түйін жіберуші немесе қабылдаушы болған кезде бола ма? Бақытымызға орай, мұны Кубернетестен тыс хосттан пакетті жіберу арқылы анықтау оңай, бірақ сол «белгілі нашар» алушы. Көріп отырғаныңыздай, мәселе жойылған жоқ:
theojulienne@shell ~ $ sudo hping3 172.16.47.27 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
len=46 ip=172.16.47.27 ttl=61 DF идентификаторы=0 спорт=9876 жалаушалар=RA seq=312 жеңіс=0 rtt=108.5 мс
len=46 ip=172.16.47.27 ttl=61 DF идентификаторы=0 спорт=9876 жалаушалар=RA seq=5903 жеңіс=0 rtt=119.4 мс
len=46 ip=172.16.47.27 ttl=61 DF идентификаторы=0 спорт=9876 жалаушалар=RA seq=6227 жеңіс=0 rtt=139.9 мс
len=46 ip=172.16.47.27 ttl=61 DF идентификаторы=0 спорт=9876 жалаушалар=RA seq=7929 жеңіс=0 rtt=131.2 мс
Содан кейін біз алдыңғы бастапқы kube-түйінінен сыртқы хостқа бірдей сұрауларды іске қосамыз (ол пинг RX және TX құрамдастарын қамтитындықтан бастапқы хостты қоспайды):
theojulienne@kube-node-client ~ $ sudo hping3 172.16.33.44 -p 9876 -S -i u10000 | egrep --line-buffered 'rtt=[0-9]{3}.'
^C
--- 172.16.33.44 hping statistic ---
22352 packets transmitted, 22350 packets received, 1% packet loss
round-trip min/avg/max = 0.2/7.6/1010.6 ms
Кешіктірілген пакетті түсірулерді зерттей отырып, біз кейбір қосымша ақпарат алдық. Атап айтқанда, жіберуші (төменгі) бұл күту уақытын көреді, бірақ алушы (жоғарғы) көрмейді - Delta бағанын қараңыз (секундтармен):
Сонымен қатар, егер сіз TCP және ICMP пакеттерінің (реттік нөмірлері бойынша) қабылдаушы жағындағы айырмашылықты қарастыратын болсаңыз, ICMP пакеттері әрқашан олар жіберілген реттілікпен келеді, бірақ әртүрлі уақытпен келеді. Сонымен қатар, TCP пакеттері кейде бір-біріне жабысып қалады, ал кейбіреулері кептеліп қалады. Атап айтқанда, егер сіз SYN пакеттерінің порттарын зерттесеңіз, олар жіберуші жағында орналасады, бірақ қабылдаушы жағында емес.
Қалай дегенінде нәзік айырмашылық бар заманауи серверлер (біздің деректер орталығындағылар сияқты) құрамында TCP немесе ICMP бар пакеттерді өңдейді. Пакет келгенде желілік адаптер оны «әр қосылымға хэштейді», яғни қосылымдарды кезекке бөліп, әрбір кезекті процессордың жеке өзегіне жіберуге тырысады. TCP үшін бұл хэш бастапқы және тағайындалған IP мекенжайы мен портты қамтиды. Басқаша айтқанда, әрбір қосылым әртүрлі хэштелген (әлеуетті). ICMP үшін порттар болмағандықтан тек IP мекенжайлары хэштелген.
Тағы бір жаңа байқау: осы кезеңде біз екі хост арасындағы барлық байланыстарда ICMP кідірістерін көреміз, бірақ TCP жоқ. Бұл бізге себеп RX кезегін хэштеумен байланысты болуы мүмкін екенін көрсетеді: кептеліс жауаптарды жіберуде емес, RX пакеттерін өңдеуде екені сөзсіз.
Бұл ықтимал себептер тізімінен пакеттерді жіберуді болдырмайды. Біз қазір кейбір куб-түйін серверлерінде пакеттерді өңдеу мәселесі қабылдау жағында екенін білеміз.
Ядродағы пакеттерді өңдеуді түсіну Linux
Кейбір kube-node серверлеріндегі қабылдағышта мәселенің неліктен пайда болатынын түсіну үшін ядроның қалай жұмыс істейтінін қарастырайық Linux пакеттерді өңдейді.
Ең қарапайым дәстүрлі іске асыруға оралсақ, желілік карта пакетті қабылдайды және жібереді өзек Linuxөңдеуді қажет ететін пакет бар екенін білдіреді. Ядро басқа жұмысты тоқтатады, контекстті үзіліс өңдегішіне ауыстырады, пакетті өңдейді, содан кейін ағымдағы тапсырмаларға оралады.
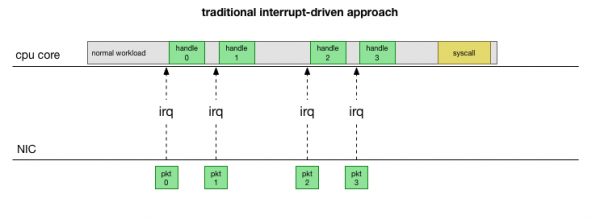
Бұл мәтінмәндік ауысу баяу: 10 Мбит/с желілік карталарда кідіріс 90-жылдары байқалмауы мүмкін, бірақ ең жоғары өткізу қабілеті секундына 10 миллион пакет болатын заманауи 15G карталарында шағын сегіз ядролы сервердің әрбір ядросы миллиондаған үзілуі мүмкін. секундына рет.
Үзілістерді үнемі өңдеудің қажеті болмас үшін, көптеген жылдар бұрын Linux қосылды : Барлық заманауи драйверлер жоғары жылдамдықта өнімділікті жақсарту үшін пайдаланатын желілік API. Төмен жылдамдықта ядро бұрынғыдай желілік картадан үзілістерді алады. Шекті мәннен асатын жеткілікті пакеттер келгенде, ядро үзілістерді өшіреді және оның орнына желілік адаптерді сұрауды және пакеттерді бөліктерге бөлуді бастайды. Өңдеу softirq, яғни in жүйелік қоңыраулар мен аппараттық үзілістерден кейін, ядро (пайдаланушы кеңістігінен айырмашылығы) әлдеқашан жұмыс істеп тұрған кезде.
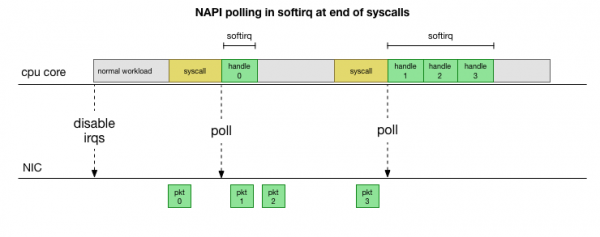
Бұл әлдеқайда жылдамырақ, бірақ басқа мәселе тудырады. Егер пакеттер тым көп болса, онда барлық уақыт желілік картадан пакеттерді өңдеуге жұмсалады, ал пайдаланушының кеңістігіндегі процестердің бұл кезектерді нақты босатуға уақыты болмайды (TCP қосылымдарынан оқу және т.б.). Ақырында кезектер толып, біз пакеттерді тастай бастаймыз. Тепе-теңдікті табу әрекетінде ядро softirq контекстінде өңделген пакеттердің максималды санына бюджетті орнатады. Бұл бюджет асып кеткенде, бөлек жіп оянады ksoftirqd (сіз олардың бірін көресіз ps per core) бұл жұмсақтықтарды қалыпты жүйені шақыру/үзу жолынан тыс өңдейді. Бұл ағын ресурстарды әділ бөлуге әрекеттенетін стандартты процесс жоспарлаушысы арқылы жоспарланған.
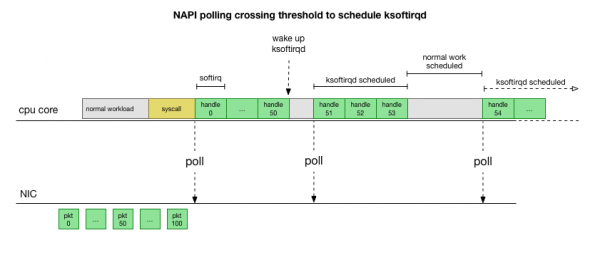
Ядроның пакеттерді қалай өңдейтінін зерттей отырып, кептелудің белгілі бір ықтималдығы бар екенін көруге болады. softirq қоңыраулары сирек қабылданатын болса, пакеттер желілік картадағы RX кезегінде өңделуі үшін біраз уақыт күтуге тура келеді. Бұл процессордың өзегін блоктайтын қандай да бір тапсырмаға байланысты болуы мүмкін немесе басқа нәрсе ядроның softirq іске қосылуына кедергі келтіруі мүмкін.
Өңдеуді ядроға немесе әдіске дейін тарылту
Softirq кідірістері әзірге болжам ғана. Бірақ бұл мағынасы бар және біз өте ұқсас нәрсені көріп жатқанымызды білеміз. Сондықтан келесі қадам осы теорияны растау болып табылады. Ал расталса, кешігулердің себебін табыңыз.
Баяу пакеттерімізге оралайық:
len=46 ip=172.16.53.32 ttl=61 id=29573 icmp_seq=1953 rtt=99.3 ms
len=46 ip=172.16.53.32 ttl=61 id=29574 icmp_seq=1954 rtt=89.3 мс
len=46 ip=172.16.53.32 ttl=61 id=29575 icmp_seq=1955 rtt=79.2 мс
len=46 ip=172.16.53.32 ttl=61 id=29576 icmp_seq=1956 rtt=69.1 мс
len=46 ip=172.16.53.32 ttl=61 id=29577 icmp_seq=1957 rtt=59.1 мс
len=46 ip=172.16.53.32 ttl=61 id=29790 icmp_seq=2070 rtt=75.7 мс
len=46 ip=172.16.53.32 ttl=61 id=29791 icmp_seq=2071 rtt=65.6 мс
len=46 ip=172.16.53.32 ttl=61 id=29792 icmp_seq=2072 rtt=55.5 мс
Бұрын талқыланғандай, бұл ICMP пакеттері бір NIC RX кезегіне хэштеледі және бір CPU ядросымен өңделеді. Егер біз операцияны түсінгіміз келсе Linux, процесті бақылау үшін бұл пакеттердің қайда (қай процессор ядросында) және қалай (softirq, ksoftirqd) өңделетінін білу пайдалы.
Енді ядроның жұмысын нақты уақыт режимінде бақылауға мүмкіндік беретін құралдарды пайдалану уақыты келді. LinuxМұнда біз қолдандық . Бұл құралдар жинағы ядродағы ерікті функцияларды біріктіретін және оқиғаларды оларды өңдей алатын және нәтижені сізге қайтара алатын пайдаланушы кеңістігі Python бағдарламасына буферлейтін шағын C бағдарламаларын жазуға мүмкіндік береді. Ядродағы ерікті функцияларды қосу қиын бизнес, бірақ утилита максималды қауіпсіздікке арналған және сынақ немесе әзірлеу ортасында оңай шығарылмайтын өндіріс мәселелерінің дәл түрін қадағалауға арналған.
Мұндағы жоспар қарапайым: біз ядроның осы ICMP пингтерін өңдейтінін білеміз, сондықтан ядро функциясына ілмек қоямыз. , ол кіріс ICMP жаңғырық сұрау пакетін қабылдайды және ICMP жаңғырық жауабын жіберуді бастайды. Көрсететін icmp_seq санын көбейту арқылы пакетті анықтай аламыз hping3 жоғары.
код күрделі көрінеді, бірақ бұл көрінгендей қорқынышты емес. Функция icmp_echo таратады struct sk_buff *skb: Бұл «жаңғырық сұрауы» бар пакет. Біз оны қадағалай аламыз, дәйектілікті шығарамыз echo.sequence (олмен салыстырады icmp_seq hping3 арқылы выше) және оны пайдаланушы кеңістігіне жіберіңіз. Ағымдағы процесс атауын/идентификаторын түсіру де ыңғайлы. Төменде ядро пакеттерді өңдеу кезінде тікелей көретін нәтижелер берілген:
TGID PID ПРОЦЕСС АТЫ ICMP_SEQ 0 0 своппер/11 770 0 своппер/0 11 771 своппер/0 0 11 своппер/772 0 0 своппер/11 773 0 прометей 0 11 774 своппер/20041 20086 775 своппер/0 0 11 своппер/776 0 0 баяндамашы-баяндама-лар 11
Бұл жерде контексте екенін атап өткен жөн softirq Жүйелік қоңырауларды жасаған процестер шын мәнінде ядро контекстінде пакеттерді қауіпсіз өңдейтін ядро болса, "процестер" ретінде пайда болады.
Бұл құралдың көмегімен біз белгілі бір процестерді кешіктіруді көрсететін нақты пакеттермен байланыстыра аламыз hping3. Оны қарапайым етейік grep белгілі бір мәндер үшін осы түсіруде icmp_seq. Жоғарыда көрсетілген icmp_seq мәндеріне сәйкес келетін пакеттер RTT-мен бірге белгіленді (жақшада біз RTT мәндері 50 мс-ден аз болғандықтан сүзгіден өткізген пакеттер үшін күтілетін RTT мәндері көрсетілген):
TGID PID ПРОЦЕСС АТЫ ICMP_SEQ ** RTT -- 10137 10436 кадвизор 1951 ж 10137 10436 кадвизор 1952 ж 76 76 ksoftirqd/11 1953 ** 99 мс 76 76 ksoftirqd/11 1954 ** 89 мс 76 76 ksoftirqd/11 1955 ** 79 мс 76 76 ksoftirqd/11 1956 ** 69 мс 76 76 ksoftirqd/11 1957 ** 59ms 76 76 ksoftirqd/11 1958 ** (49 мс) 76 76 ksoftirqd/11 1959 ** (39 мс) 76 76 ksoftirqd/11 1960 ** (29 мс) 76 76 ksoftirqd/11 1961 ** (19 мс) 76 76 ksoftirqd/11 1962 ** (9мс) -- 10137 10436 кадвизор 2068 10137 10436 кадвизор 2069 76 76 ksoftirqd/11 2070 ** 75 мс 76 76 ksoftirqd/11 2071 ** 65 мс 76 76 ksoftirqd/11 2072 ** 55 мс 76 76 ksoftirqd/11 2073 ** (45 мс) 76 76 ksoftirqd/11 2074 ** (35 мс) 76 76 ksoftirqd/11 2075 ** (25 мс) 76 76 ksoftirqd/11 2076 ** (15 мс) 76 76 ksoftirqd/11 2077 ** (5 мс)
Нәтижелер бізге бірнеше нәрсені айтады. Біріншіден, бұл пакеттердің барлығы контекст арқылы өңделеді ksoftirqd/11. Бұл машиналардың осы нақты жұбы үшін ICMP пакеттері қабылдау соңында 11 ядроға хэштелгенін білдіреді. Сондай-ақ біз кептеліс болған кезде жүйелік шақыру контекстінде өңделетін пакеттер бар екенін көреміз. cadvisor. Сонда ksoftirqd тапсырманы қабылдайды және жинақталған кезекті өңдейді: кейін жинақталған пакеттердің дәл саны cadvisor.
Оның алдында бірден жұмыс істейтіні cadvisor, оның мәселеге қатысуын білдіреді. Бір қызығы, мақсат - осы өнімділік мәселесін тудырмай, "қосудағы контейнерлердің ресурстарды пайдалануын және өнімділік сипаттамаларын талдау".
Контейнерлердің басқа аспектілері сияқты, бұлардың барлығы жоғары жетілдірілген құралдар және кейбір күтпеген жағдайларда өнімділік мәселелеріне тап болады деп күтуге болады.
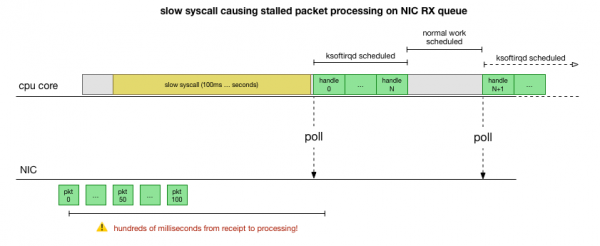
Кадвизор пакет кезегін бәсеңдететін не істейді?
Енді біз апаттың қалай болатынын, оны қай процесс тудыратынын және қай процессорда екенін жақсы түсінеміз. Қатты құлыптаудың арқасында ядроның Linux уақытында жоспарлауға уақыты жоқ ksoftirqd. Және біз пакеттердің контекстте өңделетінін көреміз cadvisor. Мұны болжау қисынды cadvisor баяу жүйені іске қосады, содан кейін сол уақытта жинақталған барлық пакеттер өңделеді:
Бұл теория, бірақ оны қалай тексеруге болады? Біз жасай алатын нәрсе - бұл процесс барысында процессордың өзегін қадағалап, пакеттер саны бюджеттен асып түсетін және ksoftirqd деп аталатын нүктені табыңыз, содан кейін осы нүктеге дейін CPU ядросында нақты не жұмыс істеп тұрғанын көру үшін сәл артқа қараңыз. . Бұл бірнеше миллисекунд сайын орталық процессорды рентгенге түсіру сияқты. Ол келесідей болады:
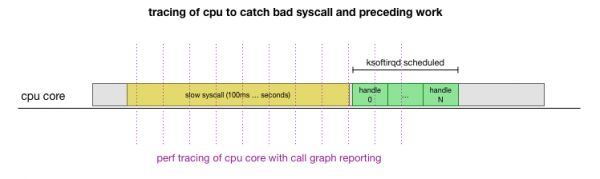
Ыңғайлы, мұның барлығын қолданыстағы құралдармен жасауға болады. Мысалы, берілген жиілікте берілген CPU ядросын тексереді және пайдаланушы кеңістігін де, ядроны да қоса алғанда, жұмыс істеп тұрған жүйенің шақыру графигін жасай алады LinuxСіз бұл жазбаны алып, бағдарламаның кішкентай шанышқысын пайдаланып өңдей аласыз. стек ізінің тәртібін сақтайтын Брендан Греггтен. Біз бір жолды стек іздерін әр 1 мс сайын сақтай аламыз, содан кейін үлгіні із тигенге дейін 100 миллисекундта бөлектеп, сақтай аламыз. ksoftirqd:
# record 999 times a second, or every 1ms with some offset so not to align exactly with timers
sudo perf record -C 11 -g -F 999
# take that recording and make a simpler stack trace.
sudo perf script 2>/dev/null | ./FlameGraph/stackcollapse-perf-ordered.pl | grep ksoftir -B 100
Міне нәтижелер:
(сотни следов, которые выглядят похожими)
cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_iter cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages cadvisor;[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];[cadvisor];entry_SYSCALL_64_after_swapgs;do_syscall_64;sys_read;vfs_read;seq_read;memcg_stat_show;mem_cgroup_nr_lru_pages;mem_cgroup_node_nr_lru_pages ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;ixgbe_poll;ixgbe_clean_rx_irq;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;bond_handle_frame;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;ipip_tunnel_xmit;ip_tunnel_xmit;iptunnel_xmit;ip_local_out;dst_output;__ip_local_out;nf_hook_slow;nf_iterate;nf_conntrack_in;generic_packet;ipt_do_table;set_match_v4;ip_set_test;hash_net4_kadt;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;hash_net4_test ksoftirqd/11;ret_from_fork;kthread;kthread;smpboot_thread_fn;smpboot_thread_fn;run_ksoftirqd;__do_softirq;net_rx_action;gro_cell_poll;napi_gro_receive;netif_receive_skb_internal;inet_gro_receive;__netif_receive_skb_core;ip_rcv_finish;ip_rcv;ip_forward_finish;ip_forward;ip_finish_output;nf_iterate;ip_output;ip_finish_output2;__dev_queue_xmit;dev_hard_start_xmit;dev_queue_xmit_nit;packet_rcv;tpacket_rcv;sch_direct_xmit;validate_xmit_skb_list;validate_xmit_skb;netif_skb_features;ixgbe_xmit_frame_ring;swiotlb_dma_mapping_error;__dev_queue_xmit;dev_hard_start_xmit;__bpf_prog_run;__bpf_prog_run
Мұнда көп нәрсе бар, бірақ ең бастысы, біз ICMP тресерінде бұрын көрген «ksoftirqd алдындағы кадвизор» үлгісін табамыз. Бұл нені білдіреді?
Әрбір жол белгілі бір уақыттағы CPU ізі болып табылады. Жолдағы стекке әрбір қоңырау нүктелі үтірмен бөлінеді. Жолдардың ортасында біз жүйе шақырылғанын көреміз: read(): .... ;do_syscall_64;sys_read; .... Осылайша, кадвизор жүйелік қоңырауға көп уақыт жұмсайды read()функцияларымен байланысты mem_cgroup_* (қоңырау стекінің жоғарғы жағы/жолдың соңы).
Қоңырауда нақты не оқылып жатқанын көру ыңғайсыз, сондықтан жүгірейік strace және cadvisor не істейтінін көрейік және 100 мс-ден ұзақ жүйелік қоңырауларды табайық:
theojulienne@kube-node-bad ~ $ sudo strace -p 10137 -T -ff 2>&1 | egrep '<0.[1-9]'
[pid 10436] <... futex resumed> ) = 0 <0.156784>
[pid 10432] <... futex resumed> ) = 0 <0.258285>
[pid 10137] <... futex resumed> ) = 0 <0.678382>
[pid 10384] <... futex resumed> ) = 0 <0.762328>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 658 <0.179438>
[pid 10384] <... futex resumed> ) = 0 <0.104614>
[pid 10436] <... futex resumed> ) = 0 <0.175936>
[pid 10436] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.228091>
[pid 10427] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 577 <0.207334>
[pid 10411] <... epoll_ctl resumed> ) = 0 <0.118113>
[pid 10382] <... pselect6 resumed> ) = 0 (Timeout) <0.117717>
[pid 10436] <... read resumed> "cache 154234880nrss 507904nrss_h"..., 4096) = 660 <0.159891>
[pid 10417] <... futex resumed> ) = 0 <0.917495>
[pid 10436] <... futex resumed> ) = 0 <0.208172>
[pid 10417] <... futex resumed> ) = 0 <0.190763>
[pid 10417] <... read resumed> "cache 0nrss 0nrss_huge 0nmapped_"..., 4096) = 576 <0.154442>
Сіз күткендей, біз мұнда баяу қоңырауларды көреміз read(). Оқу әрекеттерінің мазмұнынан және контексттен mem_cgroup бұл қиындықтар екені анық read() файлға жүгініңіз memory.stat, ол жадты пайдалануды және топтық шектеулерді көрсетеді (Докердің ресурстарды оқшаулау технологиясы). Cadvisor құралы контейнерлер үшін ресурстарды пайдалану туралы ақпаратты алу үшін осы файлды сұрайды. Бұл ядро немесе кадвизор күтпеген нәрсені істеп жатқанын тексерейік:
theojulienne@kube-node-bad ~ $ time cat /sys/fs/cgroup/memory/memory.stat >/dev/null
нақты 0м0.153с
пайдаланушы 0m0.000s
sys 0m0.152s
theojulienne@kube-node-bad ~ $
Енді біз қатені қайта жасай аламыз және ядроның Linux патологиямен кездеседі.
Неліктен оқу әрекеті соншалықты баяу?
Бұл кезеңде басқа пайдаланушылардан ұқсас мәселелер туралы хабарламаларды табу оңайырақ. Белгілі болғандай, кадвизор трекерінде бұл қате ретінде хабарланған , бұл жай ғана ешкім кідірістің желі стекінде де кездейсоқ көрінетінін байқамады. Шынында да, кадвизор күтілгеннен көп CPU уақытын тұтынатыны байқалды, бірақ бұған аса мән берілмеді, өйткені біздің серверлерімізде процессорлық ресурстар көп, сондықтан мәселе мұқият зерттелмеген.
Мәселе мынада, топтар аттар кеңістігінде (контейнер) жадты пайдалануды ескереді. Осы топтағы барлық процестер шыққанда, Docker жад тобын шығарады. Дегенмен, «жад» жай ғана процесс жады емес. Процесс жадының өзі бұдан былай пайдаланылмаса да, ядро әлі де жад тобында кэштелген тістер мен инодтар (каталог және файл метадеректері) сияқты кэштелген мазмұндарды тағайындайтын сияқты. Мәселе сипаттамасынан:
зомби топтары: процестері жоқ және жойылған, бірақ әлі де бөлінген жады бар топтар (менің жағдайда, dentry кэшінен, бірақ оны бет кэшінен немесе tmpf файлдарынан да бөлуге болады).
Топты босату кезінде кэштегі барлық беттерді ядро тексеруі өте баяу болуы мүмкін, сондықтан жалқау процесс таңдалады: бұл беттер қайтадан сұралғанша күтіңіз, содан кейін жад шынымен қажет болғанда топты тазалаңыз. Осы уақытқа дейін статистиканы жинау кезінде cgroup әлі де ескеріледі.
Өнімділік тұрғысынан олар өнімділік үшін жадты құрбан етті: кейбір кэштелген жадты артта қалдыру арқылы бастапқы тазалауды жылдамдатады. Бұл жақсы. Ядро кэштелген жадтың соңғысын пайдаланғанда, топ ақыр соңында тазартылады, сондықтан оны «ағып кету» деп атауға болмайды. Өкінішке орай, іздеу механизмінің нақты жүзеге асырылуы memory.stat бұл ядро нұсқасында (4.9), біздің серверлердегі жадтың үлкен көлемімен біріктірілген, соңғы кэштелген деректерді қалпына келтіруге және топ зомбилерін тазалауға әлдеқайда көп уақыт қажет екенін білдіреді.
Біздің кейбір түйіндерімізде топтық зомбилердің көп болғаны сонша, оқу және кідіріс секундтан асып кетті.
Кадвизор мәселесін шешу жолы жүйедегі dentries/inode кэштерін дереу босату болып табылады, бұл оқу кідірісін, сондай-ақ хосттағы желі кідірісін дереу жояды, өйткені кэшті тазалау кэштелген топ зомби беттерін қосады және олар да босатылады. Бұл шешім емес, бірақ мәселенің себебін растайды.
Жаңа ядро нұсқаларында (4.19+) қоңырау өнімділігі жақсартылды memory.stat, сондықтан осы ядроға ауысу мәселені шешті. Сонымен бірге бізде Kubernetes кластерлеріндегі проблемалық түйіндерді анықтауға, оларды әдемі түрде төгуге және қайта жүктеуге арналған құралдар болды. Біз барлық кластерлерді тарадық, жеткілікті жоғары кідіріспен түйіндерді тауып, оларды қайта жүктедік. Бұл бізге қалған серверлердегі ОЖ жаңартуға уақыт берді.
қорытындылай келе
Бұл қате RX NIC кезегін өңдеуді жүздеген миллисекундтар бойы тоқтатқандықтан, ол бір уақытта MySQL сұраулары мен жауап пакеттері арасындағы қысқа қосылымдарда жоғары кідіріс пен қосылымның ортаңғы кідірісін тудырды.
Kubernetes сияқты ең іргелі жүйелердің өнімділігін түсіну және қолдау оларға негізделген барлық қызметтердің сенімділігі мен жылдамдығы үшін өте маңызды. Сіз басқаратын әрбір жүйе Kubernetes өнімділігін жақсартуды пайдаланады.
Ақпарат көзі: www.habr.com
