

Уақыт өте келе әзірлеушіге қажет сұрауға параметрлер жиынтығын немесе тіпті бүкіл таңдауды жіберіңіз «кіре берісте». Кейде сіз бұл мәселенің өте оғаш шешімдерін кездестіресіз.
Енді артқа шегініп, не істеуге болмайтынын, неге және қалай жақсырақ жасауға болатынын көрейік.
Мәндерді сұрау мәтініне тікелей кірістіру
Ол әдетте келесідей көрінеді:
query = "SELECT * FROM tbl WHERE id = " + value...немесе келесідей:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)Бұл әдіс айтылған, жазылған және көп:

Әрқашан дерлік бұл SQL инъекцияларына тікелей жол және сұрау жолын «жабыстыруға» мәжбүр болатын іскерлік логикаға қажетсіз жүктеме.
Бұл тәсіл қажет болған жағдайда ғана ішінара негізделуі мүмкін бөлуді қолдану тиімдірек жоспарды алу үшін PostgreSQL 10 және одан төмен нұсқаларында. Бұл нұсқаларда сканерленген бөлімдердің тізімі жіберілетін параметрлерді есепке алмай, тек сұрау органының негізінде анықталады.
$n-аргументтер
Пайдаланыңыз параметрлері жақсы, пайдалануға мүмкіндік береді , іскери логикаға (сұрау жолы тек бір рет жасалады және жіберіледі) және дерекқор серверіне (әрбір сұрау данасы үшін қайта талдау және жоспарлау қажет емес) жүктемені азайту.
Аргументтердің айнымалы саны
Белгісіз аргументтерді өткізгіміз келгенде бізді проблемалар күтіп тұр:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...Егер сұрауды осы пішінде қалдырсақ, ол бізді ықтимал инъекциялардан қорғайтын болса да, бұл сұрауды біріктіру/талдау қажеттілігіне әкеледі. аргументтер санына байланысты әрбір опция үшін. Мұны әр уақытта жасағаннан гөрі жақсы, бірақ онсыз да жасай аласыз.
Құрамында бір ғана параметрді беру жеткілікті серияланған массив көрінісі:
... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}'Жалғыз айырмашылық - аргументті қалаған массив түріне нақты түрлендіру қажеттілігі. Бірақ бұл қиындық тудырмайды, өйткені біз қайда баратынымызды алдын ала білеміз.
Үлгіні (матрица) тасымалдау
Әдетте бұл дерекқорға «бір сұраныста» енгізу үшін деректер жиынын тасымалдаудың барлық нұсқалары:
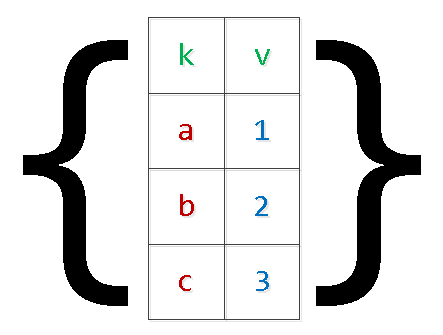
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...Жоғарыда сипатталған сұрауды «қайта желімдеу» мәселелерінен басқа, бұл бізді де әкелуі мүмкін жадында жоқ және сервердің бұзылуы. Себебі қарапайым – PG аргументтер үшін қосымша жадты сақтайды, ал жиынтықтағы жазбалар саны бизнес логикасының қолданбалы қажеттіліктерімен ғана шектеледі. Әсіресе клиникалық жағдайларда мен көруге тура келді «Сан» дәлелдері 9000 доллардан асады - олай істеме.
Қазірдің өзінде пайдаланып сұрауды қайта жазайық «екі деңгейлі» сериялау:
INSERT INTO tbl
SELECT
unnest[1]::text k
, unnest[2]::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
Иә, массив ішіндегі «күрделі» мәндер болған жағдайда, олар тырнақшалармен қоршалған болуы керек.
Осылайша өрістердің ерікті саны бар таңдауды «кеңейтуге» болатыны анық.
ұятсыз, ұясыз, …
Кейде мен айтқан «массивтер массивінің» орнына бірнеше «бағандар массивінің» өту нұсқалары бар. :
SELECT
unnest($1::text[]) k
, unnest($2::integer[]) v;Бұл әдіс арқылы әртүрлі бағандар үшін мәндер тізімін жасау кезінде қателессеңіз, оны алу өте оңай. күтпеген нәтижелер, ол сервер нұсқасына да байланысты:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |JSON
9.3 нұсқасынан бастап PostgreSQL json түрімен жұмыс істеуге арналған толыққанды функцияларға ие болды. Сондықтан, енгізу параметрлерінің анықтамасы сіздің браузеріңізде орын алса, оны дәл сол жерде қалыптастыруға болады json нысаны SQL сұрауына арналған:
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'Алдыңғы нұсқалар үшін бірдей әдісті қолдануға болады әрбір (hstore), бірақ hstore ішіндегі күрделі нысандарды алып тастау арқылы дұрыс «конволюция» проблемаларды тудыруы мүмкін.
json_populate_recordset
Егер сіз «input» json массивіндегі деректер кейбір кестені толтыру үшін пайдаланылатынын алдын ала білсеңіз, json_populate_recordset функциясын пайдалану арқылы «сілтемені жою» өрістерінде көп нәрсені үнемдеуге және оларды қажетті түрлерге шығаруға болады:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);json_to_recordset
Және бұл функция кесте пішіміне сүйенбестен, берілген нысандар массивін таңдауға жай ғана «кеңейтеді»:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2УАҚЫТТЫ КЕСТЕЛ
Бірақ егер тасымалданатын үлгідегі деректер көлемі өте үлкен болса, оны бір реттелген параметрге тастау қиын және кейде мүмкін емес, өйткені ол бір реттік талап етеді. жадтың үлкен көлемін бөлу. Мысалы, ұзақ, ұзақ уақыт бойы сыртқы жүйеден оқиғалар туралы деректердің үлкен пакетін жинау керек, содан кейін оны дерекқор жағында бір рет өңдегіңіз келеді.
Бұл жағдайда ең жақсы шешім пайдалану болады :
CREATE TEMPORARY TABLE tbl(k text, v integer);
...
INSERT INTO tbl(k, v) VALUES($1, $2); -- повторить много-много раз
...
-- тут делаем что-то полезное со всей этой таблицей целиком
Әдіс жақсы үлкен көлемдегі кездейсоқ аударымдар үшін деректер.
Деректер құрылымын сипаттау тұрғысынан уақытша кестенің «қалыпты» кестеден бір ғана айырмашылығы бар. pg_class жүйелік кестесінде, ал pg_type, pg_depend, pg_attribute, pg_attrdef, ... - мүлде ештеңе.
Сондықтан, олардың әрқайсысы үшін қысқа мерзімді қосылымдардың көп саны бар веб-жүйелерде мұндай кесте әр жолы жаңа жүйелік жазбаларды жасайды, олар деректер базасына қосылу жабылған кезде жойылады. Ақырында, TEMP TABLE бақылаусыз пайдалану pg_catalog кестелерінің «ісінуіне» әкеледі. және оларды пайдаланатын көптеген операцияларды баяулатады.
Әрине, мұны пайдалану арқылы шешуге болады мерзімді өту VACUUM FULL жүйелік каталог кестелеріне сәйкес.
Сеанс айнымалылары
Алдыңғы жағдайдағы деректерді өңдеу бір SQL сұрауы үшін өте күрделі деп есептейік, бірақ сіз оны жиі орындағыңыз келеді. Яғни, біз процессуалдық өңдеуді қолданғымыз келеді , бірақ деректерді уақытша кестелер арқылы тасымалдауды пайдалану тым қымбат болады.
Біз сондай-ақ анонимді блокқа өту үшін $n-параметрлерін пайдалана алмаймыз. Сеанс айнымалылары мен функция бізге осы жағдайдан шығуға көмектеседі ағымдағы_параметр.
9.2 нұсқасына дейін алдын ала конфигурациялау қажет болды теңшелетін_айнымалы_сыныптар «сіздің» сеанс айнымалылары үшін. Ағымдағы нұсқаларда келесідей нәрсені жаза аласыз:
SET my.val = '{1,2,3}';
DO $$
DECLARE
id integer;
BEGIN
FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP
RAISE NOTICE 'id : %', id;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- NOTICE: id : 1
-- NOTICE: id : 2
-- NOTICE: id : 3Басқа шешімдерді басқа қолдау көрсетілетін процедуралық тілдерде табуға болады.
Сіз басқа жолдарды білесіз бе? Пікірлерде бөлісіңіз!
Ақпарат көзі: www.habr.com
