

Қайырлы күн! Менің атым Данил Липовой, Sbertech-тегі біздің команда HBase-ті жедел деректер қоймасы ретінде пайдалана бастады. Оны зерттеу барысында мен жүйелеп, сипаттағым келген тәжірибе жинақталды (көпшілікке пайдалы болады деп сенеміз). Төмендегі барлық эксперименттер HBase 1.2.0-cdh5.14.2 және 2.0.0-cdh6.0.0-beta1 нұсқаларымен орындалды.
- Жалпы сәулет
- HBASE-ге деректерді жазу
- HBASE деректерін оқу
- Деректерді кэштеу
- Пакеттік деректерді өңдеу MultiGet/MultiPut
- Кестелерді аймақтарға бөлу стратегиясы (бөлу)
- Ақауларға төзімділік, ықшамдау және деректердің орналасуы
- Параметрлер және өнімділік
- Стресс тестілеу
- қорытындылар
1. Жалпы сәулет
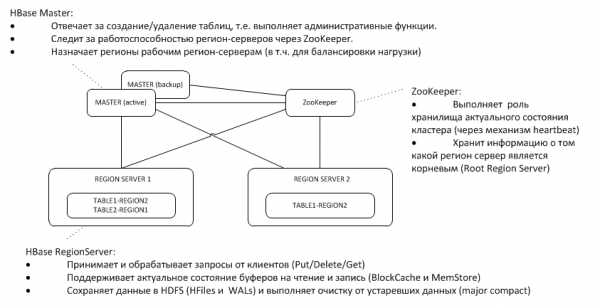
Сақтық көшірме Мастер ZooKeeper түйініндегі белсендінің жүрек соғуын тыңдайды және жоғалған жағдайда шебердің функцияларын қабылдайды.
2. Деректерді HBASE жүйесіне жазыңыз
Алдымен, ең қарапайым жағдайды қарастырайық - put(rowkey) көмегімен кестеге кілт-мән нысанын жазу. Клиент алдымен hbase:meta кестесін сақтайтын Түбірлік аймақ сервері (RRS) қайда орналасқанын білуі керек. Ол бұл ақпаратты ZooKeeper-ден алады. Осыдан кейін ол RRS-ке қатынасады және hbase:meta кестесін оқиды, одан ол қызығушылық кестесінде берілген жол пернесінің деректерін сақтауға қай RegionServer (RS) жауапты екендігі туралы ақпаратты шығарады. Болашақта пайдалану үшін мета кесте клиентпен кэштеледі, сондықтан кейінгі қоңыраулар жылдамырақ, тікелей RS-ке өтеді.
Әрі қарай, RS сұрауды алып, ең алдымен оны WriteAheadLog (WAL) қызметіне жазады, ол бұзылған жағдайда қалпына келтіру үшін қажет. Содан кейін деректерді MemStore дүкеніне сақтайды. Бұл берілген аймақ үшін кілттердің сұрыпталған жиынын қамтитын жадтағы буфер. Кестені аймақтарға (бөлімдерге) бөлуге болады, олардың әрқайсысында пернелердің бөлінген жиыны бар. Бұл жоғары өнімділікке қол жеткізу үшін аймақтарды әртүрлі серверлерге орналастыруға мүмкіндік береді. Алайда, бұл мәлімдеменің айқындығына қарамастан, бұл барлық жағдайда нәтиже бермейтінін кейінірек көреміз.
Жазбаны MemStore дүкеніне орналастырғаннан кейін клиентке жазбаның сәтті сақталғаны туралы жауап қайтарылады. Алайда, шын мәнінде ол тек буферде сақталады және дискіге белгілі бір уақыт өткеннен кейін немесе жаңа деректермен толтырылған кезде ғана түседі.
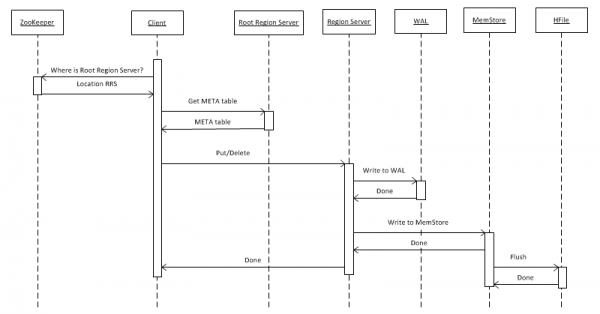
«Жою» әрекетін орындау кезінде деректер физикалық түрде жойылмайды. Олар жай ғана жойылған деп белгіленеді, ал жойылудың өзі 7-тармақта толығырақ сипатталған негізгі ықшам функцияны шақыру сәтінде орын алады.
HFile пішіміндегі файлдар HDFS жүйесінде жинақталады және мезгіл-мезгіл шағын файлдарды ештеңені жоймай үлкенірек файлдарға біріктіретін шағын ықшам процесс іске қосылады. Уақыт өте келе бұл деректерді оқу кезінде ғана пайда болатын мәселеге айналады (бұл туралы сәл кейінірек ораламыз).
Жоғарыда сипатталған жүктеу процесіне қосымша, әлдеқайда тиімді процедура бар, бұл дерекқордың ең күшті жағы - BulkLoad. Бұл біздің HFiles файлдарын өз бетінше қалыптастырып, оларды дискіге қоюымызға байланысты, бұл бізге тамаша масштабтауға және өте лайықты жылдамдықтарға қол жеткізуге мүмкіндік береді. Шындығында, бұл жерде шектеу HBase емес, аппараттық құралдардың мүмкіндіктері. Төменде 16 RegionServers және 16 NodeManager YARN (CPU Xeon E5-2680 v4 @ 2.40 ГГц * 64 ағын), HBase 1.2.0-cdh5.14.2 нұсқасынан тұратын кластердегі жүктеу нәтижелері берілген.
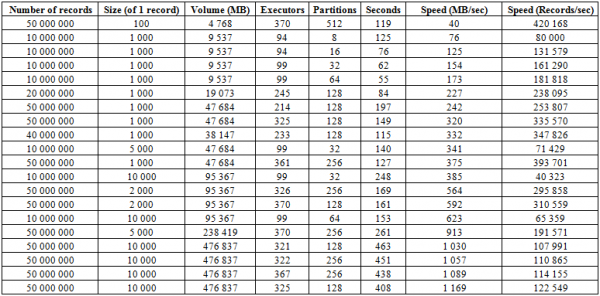
Мұнда кестедегі бөлімдердің (аймақтардың) санын, сондай-ақ Spark орындаушыларын көбейту арқылы жүктеп алу жылдамдығының артқанын көруге болады. Сондай-ақ, жылдамдық жазу көлеміне байланысты. Үлкен блоктар МБ/сек, шағын блоктар уақыт бірлігіне енгізілген жазбалар санының ұлғаюын береді, қалғандарының бәрі тең.
Сондай-ақ бір уақытта екі кестеге жүктеуді бастай аласыз және жылдамдықты екі есе арттыра аласыз. Төменде екі кестеге 10 КБ блокты бірден жазу әрқайсысында шамамен 600 МБ/сек жылдамдықпен (барлығы 1275 МБ/сек) болатынын көруге болады, бұл бір кестеге жазу жылдамдығы 623 МБ/сек (қараңыз). №11 жоғарыда)

Бірақ 50 КБ жазбалары бар екінші іске қосу жүктеу жылдамдығының аздап өсіп келе жатқанын көрсетеді, бұл оның шекті мәндерге жақындағанын көрсетеді. Сонымен қатар, HBASE-де іс жүзінде ешқандай жүктеме жасалмайтынын есте ұстаған жөн, ол үшін алдымен hbase:meta деректерін беру қажет, ал HFiles қаптағаннан кейін BlockCache деректерін қалпына келтіріп, сақтаңыз. Дискіге MemStore буфері, егер ол бос болмаса.
3. HBASE деректерін оқу
Егер клиентте hbase:meta-дан барлық ақпарат бар деп болжасақ (2-тармақты қараңыз), онда сұраныс қажетті кілт сақталған RS-ке тікелей өтеді. Біріншіден, іздеу MemCache ішінде орындалады. Деректердің бар-жоғына қарамастан, іздеу BlockCache буферінде және қажет болған жағдайда HFiles файлында да жүзеге асырылады. Егер деректер файлда табылса, ол BlockCache ішіне орналастырылады және келесі сұрауда жылдамырақ қайтарылады. Blum сүзгісін қолданудың арқасында HFile-де іздеу салыстырмалы түрде жылдам, яғни. деректердің шағын көлемін оқығаннан кейін, ол бұл файлда қажетті кілттің бар-жоғын дереу анықтайды, ал егер жоқ болса, келесіге өтеді.
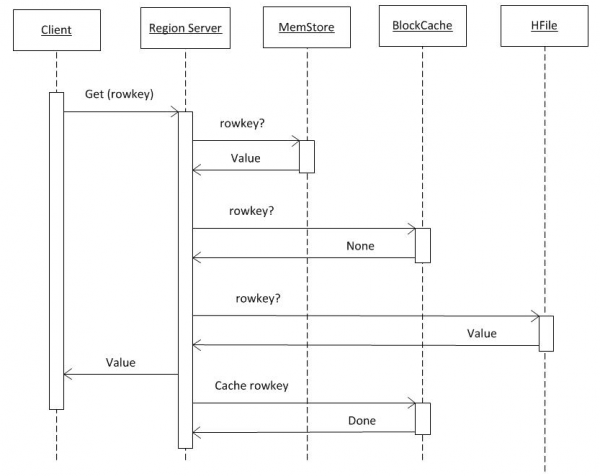
Осы үш көзден деректерді алған RS жауап береді. Атап айтқанда, егер клиент нұсқаны сұраса, ол нысанның бірнеше табылған нұсқасын бірден тасымалдай алады.
4. Деректерді кэштеу
MemStore және BlockCache буферлері бөлінген үймедегі RS жадының 80%-ға дейінін алады (қалғаны RS қызмет тапсырмалары үшін сақталған). Егер әдеттегі пайдалану режимі бірдей деректерді жазатын және бірден оқитын процестер болса, BlockCache-ті азайтып, MemStore-ды көбейткен дұрыс, өйткені Жазу деректер оқу үшін кэшке түспесе, BlockCache азырақ пайдаланылады. BlockCache буфері екі бөліктен тұрады: LruBlockCache (әрдайым жинақта) және BucketCache (әдетте үймеден тыс немесе SSD дискісінде). BucketCache оқу сұраныстары көп болған кезде және олар LruBlockCache-ге сәйкес келмегенде пайдаланылуы керек, бұл қоқыс жинаушының белсенді жұмысына әкеледі. Сонымен қатар, оқу кэшін пайдаланудан өнімділіктің түбегейлі өсуін күтуге болмайды, бірақ біз бұған 8-тармақта ораламыз.
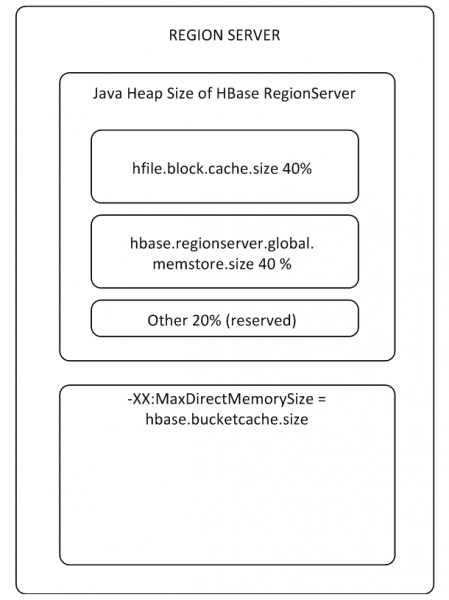
Бүкіл RS үшін бір BlockCache бар және әрбір кесте үшін бір MemStore бар (әрбір баған тобы үшін бір).
қалай теорияда жазу кезінде деректер кэшке түспейді және шын мәнінде кесте үшін CACHE_DATA_ON_WRITE және RS үшін «Жазудағы кэш деректері» «жалған» күйіне орнатылады. Алайда, іс жүзінде, егер біз MemStore дүкеніне деректерді жазып, содан кейін оны дискіге тазартсақ (осылайша оны тазартамыз), содан кейін алынған файлды жойсақ, содан кейін алу сұрауын орындау арқылы біз деректерді сәтті аламыз. Сонымен қатар, егер сіз BlockCache толығымен өшіріп, кестені жаңа деректермен толтырсаңыз да, содан кейін MemStore дискісін қалпына келтіріп, оларды жойып, басқа сеанстан сұрасаңыз да, олар бір жерден шығарылады. Сондықтан HBase тек деректерді ғана емес, сонымен қатар жұмбақ құпияларды сақтайды.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
"Cache DATA on Read" параметрі "false" мәніне орнатылған. Егер сізде қандай да бір идеялар болса, оны түсініктемелерде талқылауға қош келдіңіз.
5. MultiGet/MultiPut деректерді пакеттік өңдеу
Жалғыз сұрауларды өңдеу (Get/Put/Delete) өте қымбат операция, сондықтан мүмкін болса, оларды Тізімге немесе Тізімге біріктіру керек, бұл айтарлықтай өнімділікті арттыруға мүмкіндік береді. Бұл әсіресе жазу операциясына қатысты, бірақ оқу кезінде келесі қателік бар. Төмендегі график MemStore дүкенінен 50 000 жазбаны оқу уақытын көрсетеді. Оқу бір ағында орындалды және көлденең ось сұраудағы пернелердің санын көрсетеді. Мұнда сіз бір сұраудағы мың кілтке дейін ұлғайған кезде орындау уақыты төмендейтінін көре аласыз, яғни. жылдамдығы артады. Дегенмен, MSLAB режимі әдепкі бойынша қосылғанда, осы шекті мәннен кейін өнімділіктің түбегейлі төмендеуі басталады және жазбадағы деректер көлемі неғұрлым көп болса, жұмыс уақыты соғұрлым ұзағырақ болады.
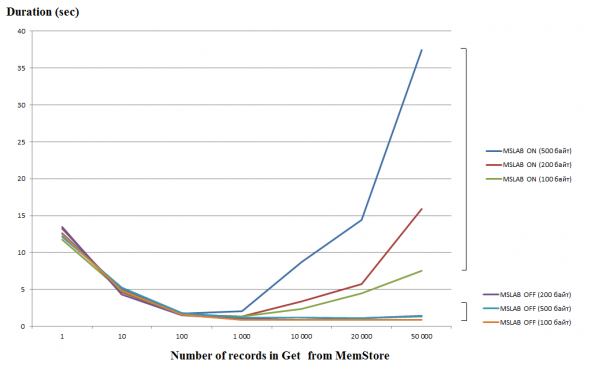
Сынақтар виртуалды машинада орындалды, 8 ядро, HBase 2.0.0-cdh6.0.0-beta1 нұсқасы.
MSLAB режимі жаңа және ескі ұрпақ деректерінің араласуына байланысты пайда болатын үйме фрагментациясын азайтуға арналған. Шешім ретінде, MSLAB қосылған кезде деректер салыстырмалы түрде шағын ұяшықтарға (бөлшектерге) орналастырылады және бөліктерде өңделеді. Нәтижесінде сұралған деректер пакетіндегі көлем бөлінген өлшемнен асқанда өнімділік күрт төмендейді. Екінші жағынан, бұл режимді өшіру де ұсынылмайды, өйткені ол деректерді қарқынды өңдеу сәтінде GC салдарынан тоқтап қалуға әкеледі. Жақсы шешім оқумен бір мезгілде put арқылы белсенді жазу жағдайында ұяшық көлемін ұлғайту болып табылады. Жазудан кейін MemStore дискісін қалпына келтіретін flush пәрменін орындасаңыз немесе BulkLoad арқылы жүктесеңіз, мәселе туындамайтынын атап өткен жөн. Төмендегі кестеде MemStore дүкенінен үлкенірек (және бірдей көлемде) деректерге арналған сұраулар баяулауға әкелетінін көрсетеді. Дегенмен, өлшемді үлкейту арқылы өңдеу уақытын қалыпты жағдайға қайтарамыз.
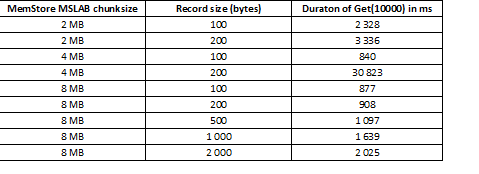
Бөлшектерді үлкейтуден басқа, деректерді аймақ бойынша бөлу көмектеседі, яғни. үстелді бөлу. Бұл әрбір аймаққа келетін сұраулардың азаюына әкеледі және олар ұяшыққа сәйкес келсе, жауап жақсы болып қалады.
6. Кестелерді аймақтарға бөлу стратегиясы (бөлу)
HBase кілт-мәнді сақтау орны болғандықтан және бөлу кілт арқылы жүзеге асырылады, деректерді барлық аймақтарға біркелкі бөлу өте маңызды. Мысалы, мұндай кестені үш бөлікке бөлу деректердің үш аймаққа бөлінуіне әкеледі:
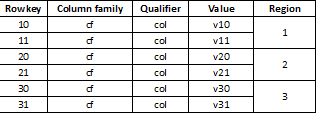
Бұл кейінірек жүктелген деректер, мысалы, ұзақ мәндерге ұқсайтын болса, бұл күрт баяулауға әкеледі, олардың көпшілігі бірдей цифрдан басталады, мысалы:
1000001
1000002
...
1100003
Кілттер байт массиві ретінде сақталғандықтан, олардың барлығы бірдей басталады және кілттердің осы ауқымын сақтайтын бір №1 аймаққа жатады. Бірнеше бөлу стратегиялары бар:
HexStringSplit – кілтті "00000000" => "FFFFFFFF" ауқымында он алтылық кодталған жолға айналдырады және сол жағын нөлдермен толтырады.
UniformSplit – кілтті "00" => "FF" ауқымында он алтылық кодтауы бар байт массивіне айналдырады және оң жақта нөлдермен толтырады.
Бұған қоса, бөлуге арналған кез келген ауқымды немесе пернелер жинағын көрсетуге және автоматты бөлуді конфигурациялауға болады. Дегенмен, ең қарапайым және тиімді тәсілдердің бірі UniformSplit және хэшті біріктіруді пайдалану болып табылады, мысалы, кілтті CRC32(rowkey) функциясы және жол пернесінің өзі арқылы іске қосудан ең маңызды байт жұбы:
хэш + қатар пернесі
Содан кейін барлық деректер аймақтар бойынша біркелкі таратылады. Оқу кезінде алғашқы екі байт жойылып, бастапқы кілт қалады. RS сонымен қатар аймақтағы деректер мен кілттердің көлемін бақылайды және шектен асып кетсе, оны автоматты түрде бөліктерге бөледі.
7. Ақауларға төзімділік және деректердің орналасуы
Әрбір кілттер жинағына тек бір аймақ жауап беретіндіктен, RS апаттарымен немесе пайдаланудан шығарумен байланысты мәселелерді шешу HDFS жүйесінде барлық қажетті деректерді сақтау болып табылады. RS төмендегенде, шебер мұны ZooKeeper түйінінде жүрек соғуының болмауы арқылы анықтайды. Содан кейін ол қызмет көрсетілетін аймақты басқа RS-ке тағайындайды және HFiles таратылған файлдық жүйеде сақталғандықтан, жаңа иесі оларды оқиды және деректерге қызмет көрсетуді жалғастырады. Дегенмен, кейбір деректер MemStore-да болуы мүмкін болғандықтан және HFiles-ке кіруге уақыт болмағандықтан, HDFS-де де сақталған WAL операциялар тарихын қалпына келтіру үшін пайдаланылады. Өзгерістер қолданылғаннан кейін RS сұрауларға жауап бере алады, бірақ жылжыту кейбір деректер мен оларға қызмет көрсететін процестердің әртүрлі түйіндерде аяқталуына әкеледі, яғни. елді мекен азайып келеді.
Мәселені шешу үлкен тығыздау болып табылады - бұл процедура файлдарды олар үшін жауапты түйіндерге (олардың аймақтары орналасқан) жылжытады, нәтижесінде осы процедура кезінде желіге және дискілерге жүктеме күрт артады. Дегенмен, болашақта деректерге қол жеткізу айтарлықтай жеделдетіледі. Оған қоса, major_compaction аймақтағы бір файлға барлық HFiles біріктіруді орындайды, сонымен қатар кесте параметрлеріне байланысты деректерді тазартады. Мысалы, сақталуы тиіс нысан нұсқаларының санын немесе нысан физикалық түрде жойылғаннан кейін қызмет ету мерзімін көрсетуге болады.
Бұл процедура HBase жұмысына өте жағымды әсер етуі мүмкін. Төмендегі сурет белсенді деректерді жазу нәтижесінде өнімділіктің қалай төмендегенін көрсетеді. Мұнда сіз 40 ағынның бір кестеге қалай жазылғанын және 40 ағынның бір уақытта деректерді оқығанын көре аласыз. Жазу ағындары басқа ағындар оқитын HFi файлдарын көбірек жасайды. Нәтижесінде жадтан көбірек деректер жойылуы керек және ақырында GC жұмыс істей бастайды, бұл іс жүзінде барлық жұмысты парализациялайды. Негізгі нығыздаудың іске қосылуы нәтижесінде пайда болған қоқыстарды тазартуға және өнімділікті қалпына келтіруге әкелді.
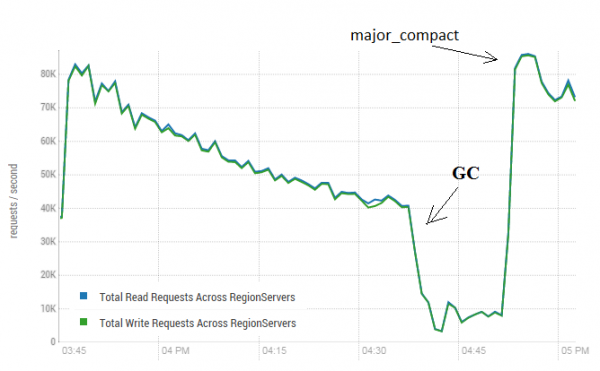
Сынақ 3 DataNode және 4 RS (CPU Xeon E5-2680 v4 @ 2.40 ГГц * 64 ағын) орындалды. HBase нұсқасы 1.2.0-cdh5.14.2
Айта кету керек, деректер белсенді түрде жазылатын және оқылатын «тірі» кестеде негізгі тығыздау іске қосылды. Желіде бұл деректерді оқу кезінде дұрыс емес жауапқа әкелуі мүмкін деген мәлімдеме болды. Тексеру үшін жаңа деректерді жасайтын және оны кестеге жазған процесс іске қосылды. Осыдан кейін мен бірден оқып, алынған мән жазылғанмен сәйкес келетінін тексердім. Бұл процесс орындалып жатқанда, негізгі тығыздау шамамен 200 рет орындалды және бірде-бір сәтсіздік тіркелмеді. Мүмкін, мәселе сирек және тек жоғары жүктеме кезінде пайда болуы мүмкін, сондықтан жазу және оқу процестерін жоспарланғандай тоқтатып, GC төмендеулерінің алдын алу үшін тазалауды орындаған дұрыс.
Сондай-ақ, негізгі тығыздау MemStore күйіне әсер етпейді, оны дискіге тазалау және оны ықшамдау үшін flush (connection.getAdmin().flush(TableName.valueOf(tblName))) пайдалану керек.
8. Параметрлер және өнімділік
Жоғарыда айтылғандай, HBase өзінің ең үлкен жетістігін BulkLoad орындаған кезде ештеңе істеудің қажеті жоқ жерде көрсетеді. Дегенмен, бұл көптеген жүйелер мен адамдарға қатысты. Дегенмен, бұл құрал деректерді жаппай үлкен блоктарда сақтау үшін қолайлырақ, ал егер процесс бірнеше бәсекелес оқу және жазу сұрауларын қажет етсе, жоғарыда сипатталған Get және Put пәрмендері пайдаланылады. Оңтайлы параметрлерді анықтау үшін кесте параметрлері мен параметрлерінің әртүрлі комбинацияларымен ұшырулар жүргізілді:
- 10 ағын бір уақытта 3 рет қатарынан іске қосылды (бұны ағындар блогы деп атаймыз).
- Блоктағы барлық ағындардың жұмыс уақыты орташаланған және блок жұмысының соңғы нәтижесі болды.
- Барлық ағындар бір кестемен жұмыс істеді.
- Жіп блогының әрбір басталуына дейін негізгі тығыздау орындалды.
- Әрбір блок келесі әрекеттердің біреуін ғана орындады:
— Қой
-Алу
—Алу+қою
- Әрбір блок өз жұмысының 50 000 итерациясын орындады.
- Жазбаның блок өлшемі 100 байт, 1000 байт немесе 10000 байт (кездейсоқ).
- Сұралған кілттердің әртүрлі санымен блоктар іске қосылды (бір кілт немесе 10).
- Блоктар әртүрлі кесте параметрлерінде орындалды. Параметрлер өзгертілді:
— BlockCache = қосулы немесе өшірулі
— BlockSize = 65 КБ немесе 16 КБ
— Бөлімдер = 1, 5 немесе 30
— MSLAB = қосылған немесе өшірілген
Сонымен, блок келесідей көрінеді:
а. MSLAB режимі қосылды/өшірілді.
б. Келесі параметрлер орнатылған кесте жасалды: BlockCache = шын/жоқ, BlockSize = 65/16 Кб, Бөлім = 1/5/30.
в. Қысу GZ мәніне орнатылды.
г. Бұл кестеде 10/1/10 байт жазбалары бар 100/1000 put/get/get+put операцияларын орындап, қатарынан 10000 50 сұрауды орындайтын (кездейсоқ кілттер) 000 ағын бір уақытта іске қосылды.
e. d нүктесі үш рет қайталанды.
f. Барлық жіптердің жұмыс уақыты орташа алынған.
Барлық мүмкін комбинациялар сыналған. Жазба өлшемі ұлғайған сайын жылдамдық төмендейді немесе кэштеуді өшіру баяулауды тудырады деп болжауға болады. Дегенмен, мақсат әрбір параметрдің әсер ету дәрежесі мен маңыздылығын түсіну болды, сондықтан жиналған деректер сызықтық регрессия функциясының кірісіне жіберілді, бұл маңыздылықты t-статистиканың көмегімен бағалауға мүмкіндік береді. Төменде Put операцияларын орындайтын блоктардың нәтижелері берілген. Комбинациялардың толық жиынтығы 2*2*3*2*3 = 144 опция + 72 тк. кейбіреулері екі рет жасалды. Осылайша, барлығы 216 жүгіріс бар:
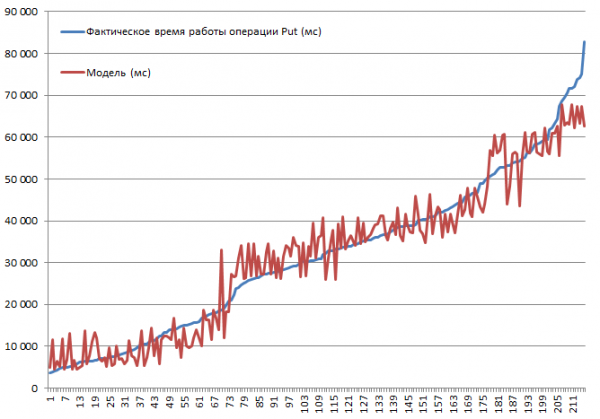
Тестілеу 3 DataNode және 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 ағын) тұратын шағын кластерде жүргізілді. HBase нұсқасы 1.2.0-cdh5.14.2.
Ең жоғары кірістіру жылдамдығы 3.7 секунд MSLAB режимі өшірілген кезде, бір бөлімі бар кестеде, BlockCache қосылған, BlockSize = 16, 100 байт жазбалары, бір бумаға 10 дана арқылы қол жеткізілді.
Ең төменгі кірістіру жылдамдығы 82.8 секунд MSLAB режимі қосылғанда, бір бөлімі бар кестеде, BlockCache қосылған, BlockSize = 16, 10000 1 байт, әрқайсысы XNUMX жазбалар арқылы алынды.
Енді үлгіні қарастырайық. Біз R2 негізіндегі модельдің жақсы сапасын көреміз, бірақ бұл жерде экстраполяцияға қарсы екені анық. Параметрлер өзгерген кезде жүйенің нақты әрекеті сызықты болмайды, бұл модель болжау үшін емес, берілген параметрлерде не болғанын түсіну үшін қажет. Мысалы, мұнда біз Студент критерийінен BlockSize және BlockCache параметрлерінің Put операциясы үшін маңызды емес екенін көреміз (бұл әдетте болжамды):

Бірақ бөлімдер санын көбейту өнімділіктің төмендеуіне әкелетіні біршама күтпеген жағдай (біз BulkLoad көмегімен бөлімдер санын көбейтудің оң әсерін көрдік), бірақ түсінікті. Біріншіден, өңдеу үшін бір аймақтың орнына 30 аймаққа сұраныс жасау керек және деректер көлемі бұл табыс әкелетіндей емес. Екіншіден, жалпы жұмыс уақыты ең баяу RS арқылы анықталады және DataNodes саны АЕМ санынан аз болғандықтан, кейбір аймақтарда нөлдік орын бар. Ал, алғашқы бестікке назар аударайық:

Енді Get блоктарын орындау нәтижелерін бағалайық:

Бөлімдердің саны маңыздылығын жоғалтты, бұл деректердің жақсы кэштелгенімен және оқу кэшінің ең маңызды (статистикалық) параметр болып табылатынымен түсіндіріледі. Әрине, сұраудағы хабарлар санын көбейту өнімділік үшін өте пайдалы. Үздік ұпайлар:

Соңында, алдымен алуды орындаған, содан кейін қойған блоктың үлгісін қарастырайық:

Мұнда барлық параметрлер маңызды. Ал көшбасшылардың нәтижелері:

9. Жүктеме сынағы
Ақырында, біз азды-көпті лайықты жүктемені іске қосамыз, бірақ сізде салыстыратын нәрсе болған кезде бұл әрқашан қызықтырақ болады. Кассандраның негізгі әзірлеушісі DataStax веб-сайтында бар HBase 0.98.6-1 нұсқасын қоса, бірқатар NoSQL қоймаларының NT. Жүктеу 40 ағынмен, деректер көлемі 100 байтпен, SSD дискілерімен жүзеге асырылды. Оқу-Өзгерту-Жазу операцияларын сынау нәтижесі келесі нәтижелерді көрсетті.
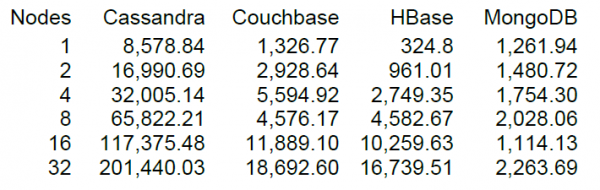
Менің түсінуімше, оқу 100 жазбадан тұратын блоктарда жүргізілді және 16 HBase түйіндері үшін DataStax сынағы секундына 10 мың операцияның өнімділігін көрсетті.
Біздің кластерімізде 16 түйіннің болуы бақыт, бірақ олардың әрқайсысында 64 ядро (жіптер) бар екендігі өте «бақытты» емес, ал DataStax тестінде тек 4 бар. Екінші жағынан, оларда SSD дискілері бар, ал бізде HDD бар. немесе одан да көп жаңа HBase нұсқасы мен процессорды жүктеме кезінде пайдалану іс жүзінде айтарлықтай өскен жоқ (көрнекі түрде 5-10 пайызға). Дегенмен, осы конфигурацияны пайдалануды бастауға тырысайық. Әдепкі кесте параметрлері, оқу 0-ден 50 миллионға дейінгі кілт диапазонында кездейсоқ орындалады (яғни, әр уақытта іс жүзінде жаңа). Кестеде 50 бөлімге бөлінген 64 миллион жазба бар. Кілттер crc32 көмегімен хэштелген. Кесте параметрлері әдепкі, MSLAB қосылған. 40 ағынды іске қоса отырып, әрбір ағын 100 кездейсоқ кілттер жинағын оқиды және жасалған 100 байтты дереу осы кілттерге жазады.
Стенд: 16 DataNode және 16 RS (CPU Xeon E5-2680 v4 @ 2.40 ГГц * 64 ағын). HBase нұсқасы 1.2.0-cdh5.14.2.
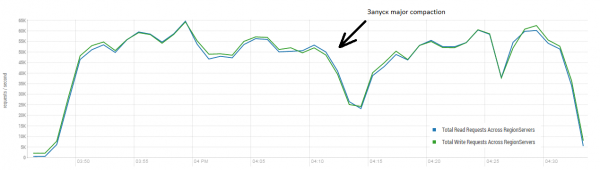
Орташа нәтиже секундына 40 мың операцияға жақын, бұл DataStax сынағымен салыстырғанда айтарлықтай жақсы. Дегенмен, эксперименттік мақсаттар үшін сіз шарттарды сәл өзгерте аласыз. Барлық жұмыс тек бір үстелде, сонымен қатар бірегей кілттерде ғана орындалатыны екіталай. Негізгі жүктемені тудыратын белгілі бір «ыстық» кілттер жиынтығы бар делік. Сондықтан, үлкенірек жазбалары бар жүктемені (10 КБ), сонымен қатар 100 топтамада, 4 түрлі кестеде және сұралған кілттер ауқымын 50 мыңға дейін шектеуге тырысайық. Төмендегі графикте 40 ағынның іске қосылуы көрсетілген, әрбір ағын оқылады 100 кілттер жинағы және дереу осы пернелерге кездейсоқ 10 КБ жазады.
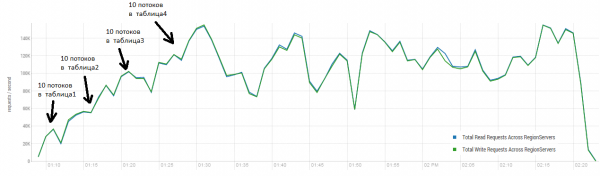
Стенд: 16 DataNode және 16 RS (CPU Xeon E5-2680 v4 @ 2.40 ГГц * 64 ағын). HBase нұсқасы 1.2.0-cdh5.14.2.
Жүктеме кезінде негізгі тығыздау бірнеше рет іске қосылды, жоғарыда көрсетілгендей, бұл процедурасыз өнімділік біртіндеп төмендейді, бірақ орындау кезінде қосымша жүктеме де пайда болады. Артықшылықтар әртүрлі себептермен туындайды. Кейде ағындар жұмысын аяқтады және оларды қайта іске қосу кезінде үзіліс болды, кейде үшінші тарап қолданбалары кластерге жүктеме жасайды.
Оқу және бірден жазу HBase үшін ең қиын жұмыс сценарийлерінің бірі болып табылады. Егер сіз тек шағын қою сұрауларын жасасаңыз, мысалы, 100 байт, оларды 10-50 мың данадан тұратын бумаларға біріктіріп, секундына жүздеген мың операцияларды ала аласыз және жағдай тек оқуға арналған сұрауларға ұқсас. Айта кету керек, нәтижелер DataStax алған нәтижелерден түбегейлі жақсырақ, ең алдымен 50 мың блоктардағы сұрауларға байланысты.
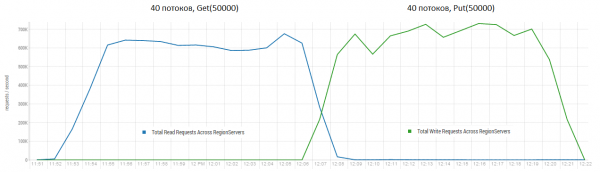
Стенд: 16 DataNode және 16 RS (CPU Xeon E5-2680 v4 @ 2.40 ГГц * 64 ағын). HBase нұсқасы 1.2.0-cdh5.14.2.
10. Қорытындылар
Бұл жүйе өте икемді түрде конфигурацияланған, бірақ көптеген параметрлердің әсері әлі белгісіз. Олардың кейбіреулері сынақтан өтті, бірақ алынған сынақ жиынтығына кірмеді. Мысалы, алдын ала эксперименттер кездейсоқ құрылған деректер үшін түсінікті көрші ұяшықтардағы мәндерді пайдалана отырып ақпаратты кодтайтын DATA_BLOCK_ENCODING сияқты параметрдің елеусіз маңыздылығын көрсетті. Егер сіз қайталанатын нысандардың көп санын пайдалансаңыз, пайда айтарлықтай болуы мүмкін. Тұтастай алғанда, HBase деректердің үлкен блоктарымен операцияларды орындау кезінде айтарлықтай өнімді болуы мүмкін жеткілікті байыпты және жақсы ойластырылған деректер қорының әсерін береді деп айта аламыз. Әсіресе, оқу мен жазу процестерін уақытында ажырату мүмкін болса.
Егер сіздің пікіріңізде жеткілікті түрде ашылмаған нәрсе болса, мен сізге толығырақ айтып беруге дайынмын. Біз сізді тәжірибеңізбен бөлісуге немесе бір нәрсемен келіспесеңіз, талқылауға шақырамыз.
Ақпарат көзі: www.habr.com
