

Жақсы ескі жасырынбақ ойыны жасанды интеллект (AI) боттары үшін олардың шешімдерді қалай қабылдайтынын және бір-бірімен және олардың айналасындағы әртүрлі нысандармен өзара әрекеттесетінін көрсету үшін тамаша сынақ болуы мүмкін.
оның жылы , танымал болған коммерциялық емес жасанды интеллект зерттеу ұйымы OpenAI зерттеушілері жариялады. Dota 2 компьютерлік ойынында ғалымдар жасанды интеллектпен басқарылатын агенттердің виртуалды ортада бір-бірін іздеуге және жасыруға неғұрлым күрделірек үйретілгенін сипаттайды. Зерттеу нәтижелері екі боттан тұратын топ одақтастары жоқ кез келген агентке қарағанда тиімдірек және жылдамырақ үйренетінін көрсетті.

Ғалымдар бұрыннан атақ-даңққа ие болған әдісті қолданды , онда жасанды интеллект онымен өзара әрекеттесудің белгілі бір тәсілдеріне ие бола отырып, оған беймәлім ортаға орналастырылады, сондай-ақ оның әрекетінің сол немесе басқа нәтижесі үшін сыйақылар мен айыппұлдар жүйесі бар. Бұл әдіс AI-ның виртуалды ортада адам ойлағаннан миллиондаған есе жылдам, үлкен жылдамдықпен әртүрлі әрекеттерді орындау қабілетіне байланысты өте тиімді. Бұл сынақ және қателіктер арқылы берілген мәселені шешудің ең тиімді стратегияларын табуға мүмкіндік береді. Бірақ бұл тәсілдің кейбір шектеулері де бар, мысалы, ортаны құру және көптеген оқу циклдерін жүргізу үлкен есептеу ресурстарын қажет етеді, ал процестің өзі AI әрекеттерінің нәтижелерін мақсатымен салыстырудың дәл жүйесін талап етеді. Сонымен қатар, агент осылайша алған дағдылар сипатталған тапсырмамен шектеледі және AI оны жеңуді үйренген кезде, одан әрі жақсартулар болмайды.
Жасырынбақ ойнауға AI-ны үйрету үшін ғалымдар «бағытсыз барлау» деп аталатын әдісті қолданды, мұнда агенттер ойын әлемі туралы түсінігін дамытуға және жеңіске жету стратегияларын әзірлеуге толық еркіндік береді. Бұл DeepMind зерттеушілері бірнеше жасанды интеллект жүйелерін пайдаланған кезде қолданатын мультиагенттік оқыту тәсіліне ұқсас. . Бұл жағдайда, AI агенттері бұрын ойын ережелеріне үйренбеген, бірақ уақыт өте келе олар негізгі стратегияларды үйренді және тіпті тривиальды емес шешімдермен зерттеушілерді таң қалдыра алды.
Жасырынбақ ойынында жұмысы жасырыну болатын бірнеше агенттер іздеу агенттерінің командасы қозғалмай тұрғанда, аздап алға бастағаннан кейін қарсыластарының көз алдында көрінбеуі керек болды. Сонымен қатар, бұл контексте «көру сызығы» - бұл жеке боттың алдындағы 135 градус конус. Агенты не могли удаляться слишком далеко за пределы игровой площадки и были вынуждены перемещаться по случайно сгенерированным комнатам с возможностью использовать некоторые внешние объекты (ящики, передвижные стены, специальные пандусы), разбросанные вокруг, которые можно было использовать как для создания укрытий, так и для проникновения оларда.
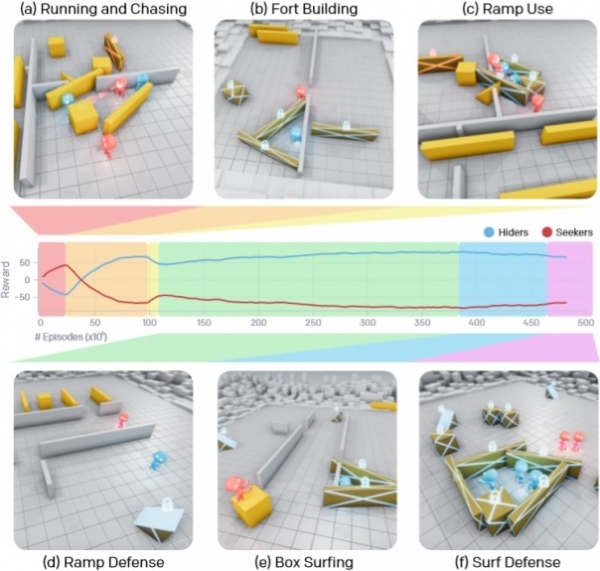
Ұзақ оқу процесі арқылы AI агенттері әрқайсысы ойынның келесі кезеңіне өтуге көмектескен алты бірегей стратегияны үйренді. Бастапқыда іздеушілер мен жасырынушылар тобы қашып, бір-бірін қуды, бірақ 25 миллионға жуық матчтан кейін жасырынушылар тобы қораптармен өткелдерді жауып, олардан баспана жасауды үйренді. Тағы 75 миллион матчтан кейін команда осы жасырынуларға кіру үшін пандустарды пайдалану жолдарын тапты. Тағы 10 миллион раундтан кейін жасырынушылар пандустарды ойын алаңының шетіне сүйреп апарып, қарсыластарының оларды пайдалануына жол бермеу үшін оларды орнына бекітуді үйренді.

388 миллион сіріңкеден кейін іздеушілер өздеріне әкелінген жәшіктерге көтерілу үшін бұғатталған пандустарды пайдалануды үйренді, содан кейін оларға тікелей жылжып, портативті қабырғалардан жасалған жаудың жасырын жерлеріне енуді үйренді. Ақырында, 458 миллион матчтан кейін жасырынған топ барлық нысандарды жауып, содан кейін баспана салу керек деген қорытындыға келді, бұл олардың түпкілікті жеңісіне әкелді.
Ең қызығы, 22 миллион матчтан кейін агенттер өз әрекеттерін үйлестіруді үйренді және олардың жұмысының тиімділігі болашақта ғана артады, мысалы, баспана жасау үшін әрқайсысы өз қорапшасын немесе қабырғасын әкелді және объектілердің өз үлесін таңдады. блоктау, қарсыластарға қиын ойынды қиындату.

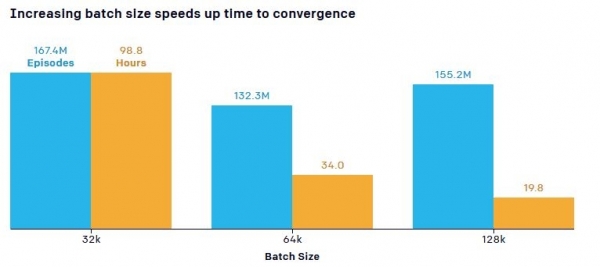
Ғалымдар оқу жылдамдығына оқыту объектілерінің санының (нейрондық желі арқылы өтетін деректер көлемі – «Пакет өлшемі») әсер етуіне байланысты маңызды жайтты да атап өтті. Әдепкі модель жасырынған топ пандустарды жабуды үйренген нүктеге жету үшін 132,3 сағаттық жаттығудың ішінде 34 миллион матчты қажет етті, ал көбірек деректер жаттығу уақытының айтарлықтай қысқаруына әкелді. Мысалы, параметрлер санын (барлық оқу процесі кезінде алынған деректердің бір бөлігі) 0,5 миллионнан 5,8 миллионға дейін ұлғайту іріктеу тиімділігін 2,2 есеге арттырды, ал кіріс деректерінің өлшемін 64 КБ-тан 128 Кбайтқа дейін арттыру оқытуды азайтты. уақыт шамамен бір жарым есе.
Жұмыстың соңында зерттеушілер ойын ішіндегі жаттығулар агенттерге ойыннан тыс ұқсас тапсырмаларды орындауға қаншалықты көмектесетінін тексеруді шешті. Барлығы бес сынақ болды: объектілердің санын білу (объектінің көзге көрінбейтін және пайдаланылмаса да өмір сүруін жалғастыратынын түсіну); «құлыптау және қайтару» - өзінің бастапқы орнын есте сақтау және кейбір қосымша тапсырманы орындағаннан кейін оған оралу мүмкіндігі; «дәйекті блоктау» - 4 қорап кездейсоқ үш бөлмеде есіксіз орналастырылды, бірақ ішке кіру үшін пандустар бар, агенттер олардың барлығын тауып, блоктауы керек; алдын ала белгіленген учаскелерде жәшіктерді орналастыру; цилиндр түріндегі объектінің айналасында баспана жасау.
Нәтижесінде бес тапсырманың үшеуінде ойында алдын ала дайындықтан өткен боттар мәселені нөлден бастап шешуге үйретілген AI-ға қарағанда тезірек үйреніп, жақсы нәтиже көрсетті. Олар тапсырманы орындауда және бастапқы қалыпқа оралуда, жабық бөлмелердегі жәшіктерді дәйекті түрде блоктауда және берілген аумақтарға жәшіктерді орналастыруда сәл жақсырақ жұмыс істеді, бірақ нысандардың санын тану және басқа нысанның айналасында жабу жасауда сәл әлсіз орындалды.
Зерттеушілер аралас нәтижелерді AI белгілі бір дағдыларды қалай меңгеретіні мен есте сақтайтынына байланыстырады. «Біздің ойымызша, ойын кезіндегі дайындық ең жақсы орындалған тапсырмалар бұрын үйренген дағдыларды таныс жолмен қайта пайдалануды қамтиды, ал қалған тапсырмаларды нөлден үйретілген AI-ға қарағанда жақсырақ орындау оларды басқа жолмен пайдалануды талап етеді, бұл көп қиынырақ» деп жазады туындының авторлары. «Бұл нәтиже оқыту арқылы алынған дағдыларды бір ортадан екіншісіне ауыстыру кезінде тиімді қайта пайдалану әдістерін әзірлеу қажеттілігін көрсетеді».
Орындалған жұмыс шынымен де әсерлі, өйткені бұл оқыту әдісін қолдану перспективасы кез келген ойынның шегінен асып түседі. Зерттеушілердің айтуынша, олардың жұмысы ауруларды диагностикалауға, күрделі ақуыз молекулаларының құрылымдарын болжауға және КТ сканерлеуіне талдау жасай алатын «физикаға негізделген» және «адамға ұқсас» мінез-құлқы бар AI құру жолындағы маңызды қадам.
Төмендегі бейнеде сіз бүкіл оқу процесінің қалай өткенін, AI топтық жұмысты қалай үйренгенін және оның стратегиялары барған сайын айлакер және күрделі бола түскенін анық көре аласыз.

Ақпарат көзі: 3dnews.ru
