


ಹೈಲೋಡ್++ ಮತ್ತು ಡೇಟಾಫೆಸ್ಟ್ ಮಿನ್ಸ್ಕ್ 2019 ರಲ್ಲಿ ನನ್ನ ಪ್ರಸ್ತುತಿಗಳನ್ನು ಆಧರಿಸಿ.
ಇಂದು ಹಲವರಿಗೆ, ಮೇಲ್ ಆನ್ಲೈನ್ ಜೀವನದ ಅವಿಭಾಜ್ಯ ಅಂಗವಾಗಿದೆ. ಅದರ ಸಹಾಯದಿಂದ, ನಾವು ವ್ಯವಹಾರ ಪತ್ರವ್ಯವಹಾರವನ್ನು ನಡೆಸುತ್ತೇವೆ, ಹಣಕಾಸು, ಹೋಟೆಲ್ ಕಾಯ್ದಿರಿಸುವಿಕೆ, ಆರ್ಡರ್ ಪ್ರಕ್ರಿಯೆ ಮತ್ತು ಇನ್ನೂ ಹೆಚ್ಚಿನವುಗಳಿಗೆ ಸಂಬಂಧಿಸಿದ ಎಲ್ಲಾ ರೀತಿಯ ಪ್ರಮುಖ ಮಾಹಿತಿಯನ್ನು ಸಂಗ್ರಹಿಸುತ್ತೇವೆ. 2018 ರ ಮಧ್ಯದಲ್ಲಿ, ನಾವು ಮೇಲ್ ಅಭಿವೃದ್ಧಿಗಾಗಿ ಉತ್ಪನ್ನ ತಂತ್ರವನ್ನು ರೂಪಿಸಿದ್ದೇವೆ. ಆಧುನಿಕ ಮೇಲ್ ಹೇಗಿರಬೇಕು?
ಮೇಲ್ ಇರಬೇಕು ಬುದ್ಧಿವಂತಅಂದರೆ, ಹೆಚ್ಚುತ್ತಿರುವ ಮಾಹಿತಿಯ ಪರಿಮಾಣವನ್ನು ನ್ಯಾವಿಗೇಟ್ ಮಾಡಲು ಬಳಕೆದಾರರಿಗೆ ಸಹಾಯ ಮಾಡಲು: ಅದನ್ನು ಅತ್ಯಂತ ಅನುಕೂಲಕರ ರೀತಿಯಲ್ಲಿ ಫಿಲ್ಟರ್ ಮಾಡಿ, ರಚಿಸಿ ಮತ್ತು ಪ್ರಸ್ತುತಪಡಿಸಿ. ಅದು ಉಪಯುಕ್ತ, ನಿಮ್ಮ ಮೇಲ್ಬಾಕ್ಸ್ನಲ್ಲಿಯೇ ವಿವಿಧ ಸಮಸ್ಯೆಗಳನ್ನು ಪರಿಹರಿಸಲು ನಿಮಗೆ ಅನುವು ಮಾಡಿಕೊಡುತ್ತದೆ, ಉದಾಹರಣೆಗೆ, ದಂಡವನ್ನು ಪಾವತಿಸಿ (ದುರದೃಷ್ಟವಶಾತ್, ನಾನು ಬಳಸುವ ಕಾರ್ಯ). ಮತ್ತು ಅದೇ ಸಮಯದಲ್ಲಿ, ಮೇಲ್ ಮಾಹಿತಿ ರಕ್ಷಣೆಯನ್ನು ಒದಗಿಸಬೇಕು, ಸ್ಪ್ಯಾಮ್ ಅನ್ನು ಕಡಿತಗೊಳಿಸಬೇಕು ಮತ್ತು ಹ್ಯಾಕಿಂಗ್ನಿಂದ ರಕ್ಷಿಸಬೇಕು, ಅಂದರೆ, ಸುರಕ್ಷಿತ.
ಈ ಕ್ಷೇತ್ರಗಳು ಹಲವಾರು ಪ್ರಮುಖ ಕಾರ್ಯಗಳನ್ನು ವ್ಯಾಖ್ಯಾನಿಸುತ್ತವೆ, ಅವುಗಳಲ್ಲಿ ಹಲವು ಯಂತ್ರ ಕಲಿಕೆಯನ್ನು ಬಳಸಿಕೊಂಡು ಪರಿಣಾಮಕಾರಿಯಾಗಿ ಪರಿಹರಿಸಬಹುದು. ಕಾರ್ಯತಂತ್ರದ ಚೌಕಟ್ಟಿನೊಳಗೆ ಅಭಿವೃದ್ಧಿಪಡಿಸಲಾದ ಈಗಾಗಲೇ ಅಸ್ತಿತ್ವದಲ್ಲಿರುವ ವೈಶಿಷ್ಟ್ಯಗಳ ಉದಾಹರಣೆಗಳು ಇಲ್ಲಿವೆ - ಪ್ರತಿ ಪ್ರದೇಶಕ್ಕೂ ಒಂದು.
- ಸ್ಮಾರ್ಟ್ ಉತ್ತರಿಸಿ. ಮೇಲ್ ಒಂದು ಸ್ಮಾರ್ಟ್ ಪ್ರತ್ಯುತ್ತರ ಕಾರ್ಯವನ್ನು ಹೊಂದಿದೆ. ನರಮಂಡಲವು ಪತ್ರದ ಪಠ್ಯವನ್ನು ವಿಶ್ಲೇಷಿಸುತ್ತದೆ, ಅದರ ಅರ್ಥ ಮತ್ತು ಉದ್ದೇಶವನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳುತ್ತದೆ ಮತ್ತು ಪರಿಣಾಮವಾಗಿ ಮೂರು ಅತ್ಯಂತ ಸೂಕ್ತವಾದ ಪ್ರತಿಕ್ರಿಯೆ ಆಯ್ಕೆಗಳನ್ನು ನೀಡುತ್ತದೆ: ಧನಾತ್ಮಕ, ಋಣಾತ್ಮಕ ಮತ್ತು ತಟಸ್ಥ. ಇದು ಪತ್ರಗಳಿಗೆ ಉತ್ತರಿಸುವಾಗ ಸಾಕಷ್ಟು ಸಮಯವನ್ನು ಉಳಿಸಲು ಸಹಾಯ ಮಾಡುತ್ತದೆ ಮತ್ತು ಆಗಾಗ್ಗೆ ನಿಮಗಾಗಿ ಅಸಾಂಪ್ರದಾಯಿಕ ಮತ್ತು ತಮಾಷೆಯ ರೀತಿಯಲ್ಲಿ ಪ್ರತಿಕ್ರಿಯಿಸುತ್ತದೆ.
- ಅಕ್ಷರಗಳನ್ನು ಗುಂಪು ಮಾಡುವುದು, ಆನ್ಲೈನ್ ಸ್ಟೋರ್ಗಳಲ್ಲಿನ ಆರ್ಡರ್ಗಳಿಗೆ ಸಂಬಂಧಿಸಿದೆ. ನಾವು ಸಾಮಾನ್ಯವಾಗಿ ಇಂಟರ್ನೆಟ್ನಲ್ಲಿ ಖರೀದಿಗಳನ್ನು ಮಾಡುತ್ತೇವೆ ಮತ್ತು ನಿಯಮದಂತೆ, ಅಂಗಡಿಗಳು ಪ್ರತಿ ಆರ್ಡರ್ಗೆ ಹಲವಾರು ಪತ್ರಗಳನ್ನು ಕಳುಹಿಸಬಹುದು. ಉದಾಹರಣೆಗೆ, ಅತಿದೊಡ್ಡ ಸೇವೆಯಾದ ಅಲೈಕ್ಸ್ಪ್ರೆಸ್ ಒಂದು ಆರ್ಡರ್ಗೆ ಬಹಳಷ್ಟು ಪತ್ರಗಳನ್ನು ಕಳುಹಿಸುತ್ತದೆ ಮತ್ತು ಟರ್ಮಿನಲ್ ಸಂದರ್ಭದಲ್ಲಿ ಅವುಗಳ ಸಂಖ್ಯೆ 29 ತಲುಪಬಹುದು ಎಂದು ನಾವು ಲೆಕ್ಕ ಹಾಕಿದ್ದೇವೆ. ಆದ್ದರಿಂದ, ಹೆಸರಿಸಲಾದ ಎಂಟಿಟಿ ರೆಕಗ್ನಿಷನ್ ಮಾದರಿಯನ್ನು ಬಳಸಿಕೊಂಡು, ನಾವು ಆರ್ಡರ್ ಸಂಖ್ಯೆ ಮತ್ತು ಇತರ ಮಾಹಿತಿಯನ್ನು ಪಠ್ಯದಿಂದ ಹೊರತೆಗೆಯುತ್ತೇವೆ ಮತ್ತು ಎಲ್ಲಾ ಅಕ್ಷರಗಳನ್ನು ಒಂದು ಥ್ರೆಡ್ಗೆ ಗುಂಪು ಮಾಡುತ್ತೇವೆ. ನಾವು ಆದೇಶದ ಬಗ್ಗೆ ಮುಖ್ಯ ಮಾಹಿತಿಯನ್ನು ಪ್ರತ್ಯೇಕ ಪೆಟ್ಟಿಗೆಯಲ್ಲಿ ತೋರಿಸುತ್ತೇವೆ, ಇದು ಈ ರೀತಿಯ ಅಕ್ಷರಗಳೊಂದಿಗೆ ಕೆಲಸ ಮಾಡಲು ಸುಲಭಗೊಳಿಸುತ್ತದೆ.

- ಆಂಟಿಫಿಶಿಂಗ್. ಫಿಶಿಂಗ್ ಒಂದು ಅಪಾಯಕಾರಿ ರೀತಿಯ ಮೋಸದ ಇಮೇಲ್ ಆಗಿದ್ದು, ಇದರ ಸಹಾಯದಿಂದ ದಾಳಿಕೋರರು ಹಣಕಾಸಿನ ಮಾಹಿತಿ (ಬಳಕೆದಾರರ ಬ್ಯಾಂಕ್ ಕಾರ್ಡ್ಗಳ ಬಗ್ಗೆ ಸೇರಿದಂತೆ) ಮತ್ತು ಲಾಗಿನ್ಗಳನ್ನು ಪಡೆಯಲು ಪ್ರಯತ್ನಿಸುತ್ತಾರೆ. ಅಂತಹ ಇಮೇಲ್ಗಳು ಸೇವೆಯಿಂದ ಕಳುಹಿಸಲಾದ ನೈಜ ಇಮೇಲ್ಗಳನ್ನು ಅನುಕರಿಸುತ್ತವೆ, ದೃಶ್ಯವೂ ಸೇರಿದಂತೆ. ಆದ್ದರಿಂದ, ಕಂಪ್ಯೂಟರ್ ವಿಷನ್ ಸಹಾಯದಿಂದ, ನಾವು ದೊಡ್ಡ ಕಂಪನಿಗಳಿಂದ (ಉದಾಹರಣೆಗೆ, Mail.ru, Sber, Alfa) ಇಮೇಲ್ಗಳ ಲೋಗೋಗಳು ಮತ್ತು ಶೈಲಿಯನ್ನು ಗುರುತಿಸುತ್ತೇವೆ ಮತ್ತು ನಮ್ಮ ಸ್ಪ್ಯಾಮ್ ಮತ್ತು ಫಿಶಿಂಗ್ ವರ್ಗೀಕರಣಕಾರಕಗಳಲ್ಲಿನ ಪಠ್ಯ ಮತ್ತು ಇತರ ವೈಶಿಷ್ಟ್ಯಗಳ ಜೊತೆಗೆ ಇದನ್ನು ಗಣನೆಗೆ ತೆಗೆದುಕೊಳ್ಳುತ್ತೇವೆ.
ಯಂತ್ರ ಕಲಿಕೆ
ಮೇಲ್ನಲ್ಲಿ ಯಂತ್ರ ಕಲಿಕೆಯ ಬಗ್ಗೆ ಸ್ವಲ್ಪ. ಮೇಲ್ ಹೆಚ್ಚು ಲೋಡ್ ಆಗಿರುವ ವ್ಯವಸ್ಥೆಯಾಗಿದೆ: ಸರಾಸರಿ, 1,5 ಮಿಲಿಯನ್ DAU ಬಳಕೆದಾರರಿಗೆ ದಿನಕ್ಕೆ 30 ಬಿಲಿಯನ್ ಪತ್ರಗಳು ನಮ್ಮ ಸರ್ವರ್ಗಳ ಮೂಲಕ ಹಾದು ಹೋಗುತ್ತವೆ. ಅಗತ್ಯವಿರುವ ಎಲ್ಲಾ ಕಾರ್ಯಗಳು ಮತ್ತು ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ಸುಮಾರು 30 ಯಂತ್ರ ಕಲಿಕೆ ವ್ಯವಸ್ಥೆಗಳು ಬೆಂಬಲಿಸುತ್ತವೆ.
ಪ್ರತಿಯೊಂದು ಪತ್ರವು ಸಂಪೂರ್ಣ ವರ್ಗೀಕರಣ ಕನ್ವೇಯರ್ ಮೂಲಕ ಹಾದುಹೋಗುತ್ತದೆ. ಮೊದಲನೆಯದಾಗಿ, ನಾವು ಸ್ಪ್ಯಾಮ್ ಅನ್ನು ಫಿಲ್ಟರ್ ಮಾಡಿ ಉತ್ತಮ ಅಕ್ಷರಗಳನ್ನು ಬಿಡುತ್ತೇವೆ. ಬಳಕೆದಾರರು ಸಾಮಾನ್ಯವಾಗಿ ಆಂಟಿಸ್ಪ್ಯಾಮ್ನ ಕೆಲಸವನ್ನು ಗಮನಿಸುವುದಿಲ್ಲ, ಏಕೆಂದರೆ 95-99% ಸ್ಪ್ಯಾಮ್ಗಳು ಸೂಕ್ತವಾದ ಫೋಲ್ಡರ್ಗೆ ಸಹ ಹೋಗುವುದಿಲ್ಲ. ಸ್ಪ್ಯಾಮ್ ಗುರುತಿಸುವಿಕೆ ನಮ್ಮ ವ್ಯವಸ್ಥೆಯ ಬಹಳ ಮುಖ್ಯವಾದ ಭಾಗವಾಗಿದೆ ಮತ್ತು ಅತ್ಯಂತ ಕಷ್ಟಕರವಾಗಿದೆ, ಏಕೆಂದರೆ ಆಂಟಿಸ್ಪ್ಯಾಮ್ ಕ್ಷೇತ್ರದಲ್ಲಿ ರಕ್ಷಣಾ ಮತ್ತು ದಾಳಿ ವ್ಯವಸ್ಥೆಗಳ ನಡುವೆ ನಿರಂತರ ಹೊಂದಾಣಿಕೆ ಇರುತ್ತದೆ, ಇದು ನಮ್ಮ ತಂಡಕ್ಕೆ ನಿರಂತರ ಎಂಜಿನಿಯರಿಂಗ್ ಸವಾಲನ್ನು ಒದಗಿಸುತ್ತದೆ.
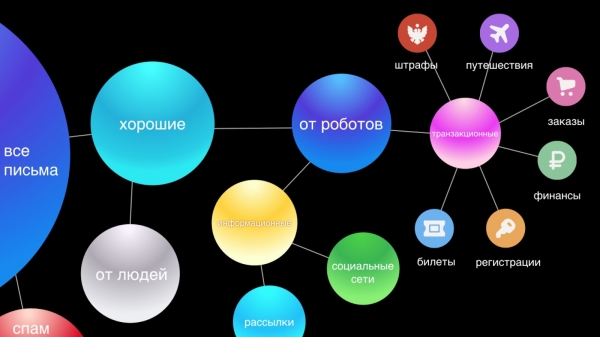
ಮುಂದೆ, ನಾವು ಜನರು ಮತ್ತು ರೋಬೋಟ್ಗಳಿಂದ ಪತ್ರಗಳನ್ನು ಪ್ರತ್ಯೇಕಿಸುತ್ತೇವೆ. ಜನರಿಂದ ಪತ್ರಗಳು ಅತ್ಯಂತ ಮುಖ್ಯ, ಆದ್ದರಿಂದ ನಾವು ಅವರಿಗೆ ಸ್ಮಾರ್ಟ್ ಪ್ರತ್ಯುತ್ತರದಂತಹ ಕಾರ್ಯಗಳನ್ನು ಒದಗಿಸುತ್ತೇವೆ. ರೋಬೋಟ್ಗಳಿಂದ ಪತ್ರಗಳನ್ನು ಎರಡು ಭಾಗಗಳಾಗಿ ವಿಂಗಡಿಸಲಾಗಿದೆ: ವಹಿವಾಟು - ಇವು ಸೇವೆಗಳಿಂದ ಬಂದ ಪ್ರಮುಖ ಪತ್ರಗಳು, ಉದಾಹರಣೆಗೆ, ಖರೀದಿಗಳು ಅಥವಾ ಹೋಟೆಲ್ ಕಾಯ್ದಿರಿಸುವಿಕೆಗಳ ದೃಢೀಕರಣ, ಹಣಕಾಸು ಮತ್ತು ಮಾಹಿತಿ - ಇದು ವ್ಯಾಪಾರ ಜಾಹೀರಾತು, ರಿಯಾಯಿತಿಗಳು.
ವಹಿವಾಟಿನ ಇಮೇಲ್ಗಳು ವೈಯಕ್ತಿಕ ಪತ್ರವ್ಯವಹಾರದಷ್ಟೇ ಮುಖ್ಯವೆಂದು ನಾವು ನಂಬುತ್ತೇವೆ. ಅವು ನಮ್ಮ ಬಳಿ ಇರಬೇಕು, ಏಕೆಂದರೆ ನಾವು ಆಗಾಗ್ಗೆ ಆರ್ಡರ್ ಅಥವಾ ವಿಮಾನ ಕಾಯ್ದಿರಿಸುವಿಕೆಯ ಬಗ್ಗೆ ಮಾಹಿತಿಯನ್ನು ತ್ವರಿತವಾಗಿ ಹುಡುಕಬೇಕಾಗುತ್ತದೆ ಮತ್ತು ನಾವು ಈ ಇಮೇಲ್ಗಳನ್ನು ಹುಡುಕಲು ಸಮಯವನ್ನು ಕಳೆಯುತ್ತೇವೆ. ಆದ್ದರಿಂದ, ಅನುಕೂಲಕ್ಕಾಗಿ, ನಾವು ಅವುಗಳನ್ನು ಸ್ವಯಂಚಾಲಿತವಾಗಿ ಆರು ಮುಖ್ಯ ವರ್ಗಗಳಾಗಿ ವಿಂಗಡಿಸುತ್ತೇವೆ: ಪ್ರಯಾಣ, ಆರ್ಡರ್ಗಳು, ಹಣಕಾಸು, ಟಿಕೆಟ್ಗಳು, ನೋಂದಣಿಗಳು ಮತ್ತು ಅಂತಿಮವಾಗಿ, ದಂಡಗಳು.
ಮಾಹಿತಿ ಪತ್ರಗಳು ಅತಿ ಹೆಚ್ಚು ಮತ್ತು ಬಹುಶಃ ಕಡಿಮೆ ಮುಖ್ಯವಾದ ಗುಂಪಾಗಿದ್ದು, ತಕ್ಷಣದ ಪ್ರತಿಕ್ರಿಯೆಯ ಅಗತ್ಯವಿಲ್ಲ, ಏಕೆಂದರೆ ಅಂತಹ ಪತ್ರವನ್ನು ಓದದಿದ್ದರೆ ಬಳಕೆದಾರರ ಜೀವನದಲ್ಲಿ ಗಮನಾರ್ಹವಾದ ಏನೂ ಬದಲಾಗುವುದಿಲ್ಲ. ನಮ್ಮ ಹೊಸ ಇಂಟರ್ಫೇಸ್ನಲ್ಲಿ, ನಾವು ಅವುಗಳನ್ನು ಎರಡು ಥ್ರೆಡ್ಗಳಾಗಿ ವಿಭಜಿಸುತ್ತೇವೆ: ಸಾಮಾಜಿಕ ನೆಟ್ವರ್ಕ್ಗಳು ಮತ್ತು ಸುದ್ದಿಪತ್ರಗಳು, ಹೀಗಾಗಿ ದೃಷ್ಟಿಗೋಚರವಾಗಿ ಇನ್ಬಾಕ್ಸ್ ಅನ್ನು ಸ್ವಚ್ಛಗೊಳಿಸುತ್ತದೆ ಮತ್ತು ಪ್ರಮುಖ ಅಕ್ಷರಗಳನ್ನು ಮಾತ್ರ ದೃಷ್ಟಿಯಲ್ಲಿ ಬಿಡುತ್ತದೆ.
ಶೋಷಣೆ
ಹೆಚ್ಚಿನ ಸಂಖ್ಯೆಯ ವ್ಯವಸ್ಥೆಗಳು ಕಾರ್ಯಾಚರಣೆಯಲ್ಲಿ ಅನೇಕ ತೊಂದರೆಗಳನ್ನು ಉಂಟುಮಾಡುತ್ತವೆ. ಎಲ್ಲಾ ನಂತರ, ಯಾವುದೇ ಸಾಫ್ಟ್ವೇರ್ನಂತೆ ಮಾದರಿಗಳು ಕಾಲಾನಂತರದಲ್ಲಿ ಕ್ಷೀಣಿಸುತ್ತವೆ: ವೈಶಿಷ್ಟ್ಯಗಳು ಮುರಿಯುತ್ತವೆ, ಯಂತ್ರಗಳು ವಿಫಲಗೊಳ್ಳುತ್ತವೆ, ವಕ್ರ ಕೋಡ್ ಅನ್ನು ಹೊರತರಲಾಗುತ್ತದೆ. ಇದರ ಜೊತೆಗೆ, ಡೇಟಾ ನಿರಂತರವಾಗಿ ಬದಲಾಗುತ್ತಿದೆ: ಹೊಸದನ್ನು ಸೇರಿಸಲಾಗುತ್ತದೆ, ಬಳಕೆದಾರರ ನಡವಳಿಕೆಯ ಮಾದರಿಗಳು ರೂಪಾಂತರಗೊಳ್ಳುತ್ತವೆ, ಇತ್ಯಾದಿ, ಆದ್ದರಿಂದ ಸರಿಯಾದ ಬೆಂಬಲವಿಲ್ಲದ ಮಾದರಿಯು ಕಾಲಾನಂತರದಲ್ಲಿ ಕೆಟ್ಟದಾಗಿ ಮತ್ತು ಕೆಟ್ಟದಾಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ.
ಯಂತ್ರ ಕಲಿಕೆಯು ಬಳಕೆದಾರರ ಜೀವನದಲ್ಲಿ ಆಳವಾಗಿ ತೂರಿಕೊಂಡಷ್ಟೂ, ಅವು ಪರಿಸರ ವ್ಯವಸ್ಥೆಯ ಮೇಲೆ ಹೆಚ್ಚಿನ ಪರಿಣಾಮ ಬೀರುತ್ತವೆ ಮತ್ತು ಪರಿಣಾಮವಾಗಿ, ಮಾರುಕಟ್ಟೆ ಆಟಗಾರರು ಹೆಚ್ಚಿನ ಆರ್ಥಿಕ ನಷ್ಟ ಅಥವಾ ಲಾಭವನ್ನು ಪಡೆಯಬಹುದು ಎಂಬುದನ್ನು ನಾವು ಮರೆಯಬಾರದು. ಆದ್ದರಿಂದ, ಹೆಚ್ಚು ಹೆಚ್ಚು ಕ್ಷೇತ್ರಗಳಲ್ಲಿ, ಆಟಗಾರರು ML ಅಲ್ಗಾರಿದಮ್ಗಳ ಕೆಲಸಕ್ಕೆ ಹೊಂದಿಕೊಳ್ಳುತ್ತಿದ್ದಾರೆ (ಕ್ಲಾಸಿಕ್ ಉದಾಹರಣೆಗಳೆಂದರೆ ಜಾಹೀರಾತು, ಹುಡುಕಾಟ ಮತ್ತು ಈಗಾಗಲೇ ಉಲ್ಲೇಖಿಸಲಾದ ಆಂಟಿಸ್ಪ್ಯಾಮ್).
ಯಂತ್ರ ಕಲಿಕೆ ಕಾರ್ಯಗಳು ಸಹ ಒಂದು ವಿಶಿಷ್ಟತೆಯನ್ನು ಹೊಂದಿವೆ: ವ್ಯವಸ್ಥೆಯಲ್ಲಿನ ಯಾವುದೇ ಬದಲಾವಣೆ, ಚಿಕ್ಕದಾದರೂ ಸಹ, ಮಾದರಿಯೊಂದಿಗೆ ಬಹಳಷ್ಟು ಕೆಲಸವನ್ನು ಉಂಟುಮಾಡಬಹುದು: ಡೇಟಾದೊಂದಿಗೆ ಕೆಲಸ ಮಾಡುವುದು, ಮರುತರಬೇತಿ, ನಿಯೋಜನೆ, ಇದು ವಾರಗಳು ಅಥವಾ ತಿಂಗಳುಗಳವರೆಗೆ ವಿಳಂಬವಾಗಬಹುದು. ಆದ್ದರಿಂದ, ನಿಮ್ಮ ಮಾದರಿಗಳು ಕಾರ್ಯನಿರ್ವಹಿಸುವ ಪರಿಸರವು ವೇಗವಾಗಿ ಬದಲಾಗುತ್ತದೆ, ಅವರ ಬೆಂಬಲಕ್ಕೆ ಹೆಚ್ಚಿನ ಶ್ರಮ ಬೇಕಾಗುತ್ತದೆ. ತಂಡವು ಅನೇಕ ವ್ಯವಸ್ಥೆಗಳನ್ನು ರಚಿಸಬಹುದು ಮತ್ತು ಅದರ ಬಗ್ಗೆ ಸಂತೋಷಪಡಬಹುದು ಮತ್ತು ನಂತರ ಹೊಸದನ್ನು ಮಾಡುವ ಸಾಮರ್ಥ್ಯವಿಲ್ಲದೆ ಬಹುತೇಕ ಎಲ್ಲಾ ಸಂಪನ್ಮೂಲಗಳನ್ನು ಅವರ ಬೆಂಬಲಕ್ಕಾಗಿ ಖರ್ಚು ಮಾಡಬಹುದು. ಸ್ಪ್ಯಾಮ್ ವಿರೋಧಿ ತಂಡದಲ್ಲಿ ನಾವು ಒಮ್ಮೆ ಅಂತಹ ಪರಿಸ್ಥಿತಿಯನ್ನು ಎದುರಿಸಿದ್ದೇವೆ. ಮತ್ತು ಬೆಂಬಲವನ್ನು ಸ್ವಯಂಚಾಲಿತಗೊಳಿಸಬೇಕು ಎಂಬ ಸ್ಪಷ್ಟ ತೀರ್ಮಾನವನ್ನು ನಾವು ಮಾಡಿದ್ದೇವೆ.
ಆಟೊಮೇಷನ್
ಏನನ್ನು ಸ್ವಯಂಚಾಲಿತಗೊಳಿಸಬಹುದು? ವಾಸ್ತವವಾಗಿ ಬಹುತೇಕ ಎಲ್ಲವೂ. ಯಂತ್ರ ಕಲಿಕೆಯ ಮೂಲಸೌಕರ್ಯವನ್ನು ವ್ಯಾಖ್ಯಾನಿಸುವ ನಾಲ್ಕು ಕ್ಷೇತ್ರಗಳನ್ನು ನಾನು ಗುರುತಿಸಿದ್ದೇನೆ:
- ಮಾಹಿತಿ ಸಂಗ್ರಹ;
- ಹೆಚ್ಚಿನ ತರಬೇತಿ;
- ನಿಯೋಜಿಸು;
- ಪರೀಕ್ಷೆ ಮತ್ತು ಮೇಲ್ವಿಚಾರಣೆ.
ಪರಿಸರವು ಅಸ್ಥಿರವಾಗಿದ್ದರೆ ಮತ್ತು ನಿರಂತರವಾಗಿ ಬದಲಾಗುತ್ತಿದ್ದರೆ, ಮಾದರಿಯ ಸುತ್ತಲಿನ ಸಂಪೂರ್ಣ ಮೂಲಸೌಕರ್ಯವು ಮಾದರಿಗಿಂತ ಹೆಚ್ಚು ಮುಖ್ಯವಾಗಿದೆ. ಇದು ಉತ್ತಮ ಹಳೆಯ ರೇಖೀಯ ವರ್ಗೀಕರಣವಾಗಬಹುದು, ಆದರೆ ನೀವು ಅದಕ್ಕೆ ಸರಿಯಾದ ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ನೀಡಿದರೆ ಮತ್ತು ಬಳಕೆದಾರರಿಂದ ಉತ್ತಮ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಹೊಂದಿಸಿದರೆ, ಅದು ಎಲ್ಲಾ ಗಂಟೆಗಳು ಮತ್ತು ಸೀಟಿಗಳೊಂದಿಗೆ ಅತ್ಯಾಧುನಿಕ ಮಾದರಿಗಳಿಗಿಂತ ಉತ್ತಮವಾಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ.
ಪ್ರತಿಕ್ರಿಯೆ ಲೂಪ್
ಈ ಚಕ್ರವು ಡೇಟಾ ಸಂಗ್ರಹಣೆ, ಹೆಚ್ಚುವರಿ ತರಬೇತಿ ಮತ್ತು ನಿಯೋಜನೆಯನ್ನು ಸಂಯೋಜಿಸುತ್ತದೆ - ಮೂಲಭೂತವಾಗಿ ಸಂಪೂರ್ಣ ಮಾದರಿ ನವೀಕರಣ ಚಕ್ರ. ಇದು ಏಕೆ ಮುಖ್ಯ? ಮೇಲ್ ನೋಂದಣಿ ವೇಳಾಪಟ್ಟಿಯನ್ನು ನೋಡಿ:
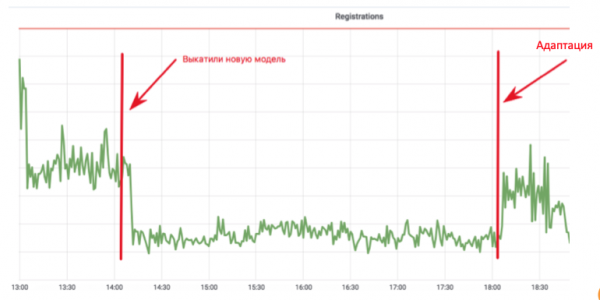
ಒಬ್ಬ ಯಂತ್ರ ಕಲಿಕೆಯ ಡೆವಲಪರ್, ಬಾಟ್ಗಳು ಮೇಲ್ನಲ್ಲಿ ನೋಂದಾಯಿಸಿಕೊಳ್ಳುವುದನ್ನು ತಡೆಯುವ ಆಂಟಿ-ಬಾಟ್ ಮಾದರಿಯನ್ನು ಜಾರಿಗೆ ತಂದಿದ್ದಾರೆ. ಗ್ರಾಫ್ ನಿಜವಾದ ಬಳಕೆದಾರರು ಮಾತ್ರ ಉಳಿಯುವ ಮೌಲ್ಯಕ್ಕೆ ಇಳಿಯುತ್ತದೆ. ಎಲ್ಲವೂ ಅದ್ಭುತವಾಗಿದೆ! ಆದರೆ ನಾಲ್ಕು ಗಂಟೆಗಳು ಕಳೆದವು, ಬಾಟ್ ನಿರ್ವಾಹಕರು ತಮ್ಮ ಸ್ಕ್ರಿಪ್ಟ್ಗಳನ್ನು ತಿರುಚುತ್ತಾರೆ ಮತ್ತು ಎಲ್ಲವೂ ಸಾಮಾನ್ಯ ಸ್ಥಿತಿಗೆ ಮರಳುತ್ತದೆ. ಈ ಅನುಷ್ಠಾನದಲ್ಲಿ, ಡೆವಲಪರ್ ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ಸೇರಿಸಲು ಮತ್ತು ಮಾದರಿಯನ್ನು ಮರುತರಬೇತಿ ನೀಡಲು ಒಂದು ತಿಂಗಳು ಕಳೆದರು, ಆದರೆ ಸ್ಪ್ಯಾಮರ್ ನಾಲ್ಕು ಗಂಟೆಗಳಲ್ಲಿ ಹೊಂದಿಕೊಳ್ಳಲು ಸಾಧ್ಯವಾಯಿತು.
ಅಂತಹ ಅಸಹನೀಯ ನೋವನ್ನು ತಪ್ಪಿಸಲು ಮತ್ತು ನಂತರ ಎಲ್ಲವನ್ನೂ ಮತ್ತೆ ಮಾಡುವುದನ್ನು ತಪ್ಪಿಸಲು, ಪ್ರತಿಕ್ರಿಯೆ ಲೂಪ್ ಹೇಗಿರುತ್ತದೆ ಮತ್ತು ಪರಿಸರ ಬದಲಾದರೆ ನಾವು ಏನು ಮಾಡುತ್ತೇವೆ ಎಂಬುದರ ಕುರಿತು ನಾವು ಆರಂಭದಲ್ಲಿ ಯೋಚಿಸಬೇಕು. ಡೇಟಾವನ್ನು ಸಂಗ್ರಹಿಸುವುದರೊಂದಿಗೆ ಪ್ರಾರಂಭಿಸೋಣ - ಇದು ನಮ್ಮ ಅಲ್ಗಾರಿದಮ್ಗಳಿಗೆ ಇಂಧನವಾಗಿದೆ.
ಮಾಹಿತಿ ಸಂಗ್ರಹ
ಆಧುನಿಕ ನರಮಂಡಲ ಜಾಲಗಳು ಹೆಚ್ಚು ಡೇಟಾವನ್ನು ಹೊಂದಿದ್ದರೆ, ಅವು ಉತ್ತಮವಾಗಿರುತ್ತವೆ ಮತ್ತು ಅವು ಮೂಲತಃ ಉತ್ಪನ್ನದ ಬಳಕೆದಾರರಿಂದ ಉತ್ಪತ್ತಿಯಾಗುತ್ತವೆ ಎಂಬುದು ಸ್ಪಷ್ಟವಾಗಿದೆ. ಬಳಕೆದಾರರು ಡೇಟಾವನ್ನು ಲೇಬಲ್ ಮಾಡುವ ಮೂಲಕ ನಮಗೆ ಸಹಾಯ ಮಾಡಬಹುದು, ಆದರೆ ನಾವು ಇದನ್ನು ದುರುಪಯೋಗಪಡಿಸಿಕೊಳ್ಳಲು ಸಾಧ್ಯವಿಲ್ಲ, ಏಕೆಂದರೆ ಕೆಲವು ಹಂತದಲ್ಲಿ ಬಳಕೆದಾರರು ನಿಮ್ಮ ಮಾದರಿಗಳಿಗೆ ತರಬೇತಿ ನೀಡುವುದರಿಂದ ಬೇಸತ್ತರು ಮತ್ತು ಅವರು ಬೇರೆ ಉತ್ಪನ್ನಕ್ಕೆ ಬದಲಾಯಿಸುತ್ತಾರೆ.
ಸಾಮಾನ್ಯ ತಪ್ಪುಗಳಲ್ಲಿ ಒಂದು (ನಾನು ಇಲ್ಲಿ ಆಂಡ್ರ್ಯೂ ಎನ್ಜಿ ಅವರನ್ನು ಉಲ್ಲೇಖಿಸುತ್ತಿದ್ದೇನೆ) ಬಳಕೆದಾರರ ಪ್ರತಿಕ್ರಿಯೆಯ ಮೇಲೆ ಅಲ್ಲ, ಪರೀಕ್ಷಾ ಡೇಟಾಸೆಟ್ನಲ್ಲಿನ ಮೆಟ್ರಿಕ್ಗಳ ಮೇಲೆ ಹೆಚ್ಚು ಗಮನಹರಿಸುವುದು, ಇದು ವಾಸ್ತವವಾಗಿ ಕೆಲಸದ ಗುಣಮಟ್ಟದ ಮುಖ್ಯ ಅಳತೆಯಾಗಿದೆ, ಏಕೆಂದರೆ ನಾವು ಬಳಕೆದಾರರಿಗಾಗಿ ಉತ್ಪನ್ನವನ್ನು ರಚಿಸುತ್ತಿದ್ದೇವೆ. ಬಳಕೆದಾರರಿಗೆ ಮಾದರಿಯ ಕೆಲಸ ಅರ್ಥವಾಗದಿದ್ದರೆ ಅಥವಾ ಇಷ್ಟವಾಗದಿದ್ದರೆ, ಎಲ್ಲವೂ ವ್ಯರ್ಥ.
ಆದ್ದರಿಂದ, ಬಳಕೆದಾರರಿಗೆ ಯಾವಾಗಲೂ ಮತ ಚಲಾಯಿಸುವ ಅವಕಾಶವಿರಬೇಕು, ನಾವು ಅವರಿಗೆ ಪ್ರತಿಕ್ರಿಯೆಗಾಗಿ ಒಂದು ಸಾಧನವನ್ನು ನೀಡಬೇಕು. ಹಣಕಾಸಿಗೆ ಸಂಬಂಧಿಸಿದ ಅಂಚೆಪೆಟ್ಟಿಗೆಯಲ್ಲಿ ಪತ್ರ ಬಂದಿದೆ ಎಂದು ನಾವು ಭಾವಿಸಿದರೆ, ನಾವು ಅದನ್ನು "ಹಣಕಾಸು" ಎಂದು ಗುರುತಿಸಬೇಕು ಮತ್ತು ಬಳಕೆದಾರರು ಒತ್ತಬಹುದಾದ ಗುಂಡಿಯನ್ನು ಎಳೆಯಬೇಕು ಮತ್ತು ಇದು ಹಣಕಾಸು ಅಲ್ಲ ಎಂದು ಹೇಳಬೇಕು.
ಪ್ರತಿಕ್ರಿಯೆ ಗುಣಮಟ್ಟ
ಬಳಕೆದಾರರ ಪ್ರತಿಕ್ರಿಯೆಯ ಗುಣಮಟ್ಟದ ಬಗ್ಗೆ ಮಾತನಾಡೋಣ. ಮೊದಲನೆಯದಾಗಿ, ನೀವು ಮತ್ತು ಬಳಕೆದಾರರು ಒಂದೇ ಪರಿಕಲ್ಪನೆಗೆ ವಿಭಿನ್ನ ಅರ್ಥಗಳನ್ನು ಹಾಕಬಹುದು. ಉದಾಹರಣೆಗೆ, ನೀವು ಮತ್ತು ಉತ್ಪನ್ನ ವ್ಯವಸ್ಥಾಪಕರು "ಹಣಕಾಸು" ಬ್ಯಾಂಕಿನಿಂದ ಬಂದ ಪತ್ರಗಳು ಎಂದು ನಂಬುತ್ತೀರಿ ಮತ್ತು ಅಜ್ಜಿಯಿಂದ ಅವರ ಪಿಂಚಣಿಯ ಬಗ್ಗೆ ಬಂದ ಪತ್ರವು ಹಣಕಾಸಿನ ವಿಷಯಗಳಿಗೆ ಸಂಬಂಧಿಸಿದೆ ಎಂದು ಬಳಕೆದಾರರು ನಂಬುತ್ತಾರೆ. ಎರಡನೆಯದಾಗಿ, ಯಾವುದೇ ತರ್ಕವಿಲ್ಲದೆ ಗುಂಡಿಗಳನ್ನು ಒತ್ತಲು ಇಷ್ಟಪಡುವ ಬಳಕೆದಾರರಿದ್ದಾರೆ. ಮೂರನೆಯದಾಗಿ, ಬಳಕೆದಾರರು ತಮ್ಮ ತೀರ್ಮಾನಗಳಲ್ಲಿ ಆಳವಾಗಿ ತಪ್ಪಾಗಿ ಭಾವಿಸಬಹುದು. ನಮ್ಮ ಅಭ್ಯಾಸದಿಂದ ಒಂದು ಗಮನಾರ್ಹ ಉದಾಹರಣೆಯೆಂದರೆ ವರ್ಗೀಕರಣದ ಅನುಷ್ಠಾನ. , ಇದು ತುಂಬಾ ತಮಾಷೆಯ ರೀತಿಯ ಸ್ಪ್ಯಾಮ್ ಆಗಿದೆ, ಆಫ್ರಿಕಾದಲ್ಲಿ ಇದ್ದಕ್ಕಿದ್ದಂತೆ ಕಂಡುಬಂದ ದೂರದ ಸಂಬಂಧಿಯಿಂದ ಬಳಕೆದಾರರಿಗೆ ಹಲವಾರು ಮಿಲಿಯನ್ ಡಾಲರ್ಗಳನ್ನು ತೆಗೆದುಕೊಳ್ಳಲು ಅವಕಾಶ ನೀಡಿದಾಗ. ಈ ವರ್ಗೀಕರಣವನ್ನು ಕಾರ್ಯಗತಗೊಳಿಸಿದ ನಂತರ, ನಾವು ಈ ಅಕ್ಷರಗಳ ಮೇಲೆ "ಸ್ಪ್ಯಾಮ್ ಅಲ್ಲ" ಕ್ಲಿಕ್ಗಳನ್ನು ಪರಿಶೀಲಿಸಿದ್ದೇವೆ ಮತ್ತು ಅವುಗಳಲ್ಲಿ 80% ರಸಭರಿತವಾದ ನೈಜೀರಿಯನ್ ಸ್ಪ್ಯಾಮ್ ಎಂದು ತಿಳಿದುಬಂದಿದೆ, ಇದು ಬಳಕೆದಾರರು ಅತ್ಯಂತ ಮೋಸಗಾರರಾಗಿರಬಹುದು ಎಂದು ಸೂಚಿಸುತ್ತದೆ.
ಮತ್ತು ಬಟನ್ಗಳ ಮೇಲೆ ಕ್ಲಿಕ್ ಮಾಡಬಹುದಾದ ಜನರು ಮಾತ್ರವಲ್ಲ, ಬ್ರೌಸರ್ನಂತೆ ನಟಿಸುವ ಬಾಟ್ಗಳು ಸಹ ಎಂಬುದನ್ನು ನಾವು ಮರೆಯಬಾರದು. ಆದ್ದರಿಂದ ಕಚ್ಚಾ ಪ್ರತಿಕ್ರಿಯೆ ಕಲಿಯಲು ಒಳ್ಳೆಯದಲ್ಲ. ಈ ಮಾಹಿತಿಯೊಂದಿಗೆ ನೀವು ಏನು ಮಾಡಬಹುದು?
ನಾವು ಎರಡು ವಿಧಾನಗಳನ್ನು ಬಳಸುತ್ತೇವೆ:
- ಸಂಬಂಧಿತ ML ನಿಂದ ಪ್ರತಿಕ್ರಿಯೆ. ಉದಾಹರಣೆಗೆ, ನಮ್ಮಲ್ಲಿ ಆನ್ಲೈನ್ ಆಂಟಿ-ಬಾಟ್ ವ್ಯವಸ್ಥೆ ಇದೆ, ಇದು ನಾನು ಈಗಾಗಲೇ ಹೇಳಿದಂತೆ, ಸೀಮಿತ ಸಂಖ್ಯೆಯ ವೈಶಿಷ್ಟ್ಯಗಳ ಆಧಾರದ ಮೇಲೆ ತ್ವರಿತ ನಿರ್ಧಾರ ತೆಗೆದುಕೊಳ್ಳುತ್ತದೆ. ಮತ್ತು ಎರಡನೇ, ನಿಧಾನವಾದ ವ್ಯವಸ್ಥೆ ಇದೆ, ವಾಸ್ತವದ ನಂತರ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ. ಇದು ಬಳಕೆದಾರ, ಅವನ ನಡವಳಿಕೆ ಇತ್ಯಾದಿಗಳ ಬಗ್ಗೆ ಹೆಚ್ಚಿನ ಡೇಟಾವನ್ನು ಹೊಂದಿದೆ. ಪರಿಣಾಮವಾಗಿ, ಅತ್ಯಂತ ಸಮತೋಲಿತ ನಿರ್ಧಾರವನ್ನು ತೆಗೆದುಕೊಳ್ಳಲಾಗುತ್ತದೆ ಮತ್ತು ಅದಕ್ಕೆ ಅನುಗುಣವಾಗಿ ಇದು ಹೆಚ್ಚಿನ ನಿಖರತೆ ಮತ್ತು ಸಂಪೂರ್ಣತೆಯನ್ನು ಹೊಂದಿರುತ್ತದೆ. ಈ ವ್ಯವಸ್ಥೆಗಳ ಕೆಲಸದಲ್ಲಿನ ವ್ಯತ್ಯಾಸವನ್ನು ನೀವು ಮೊದಲನೆಯದಕ್ಕೆ ತರಬೇತಿ ಡೇಟಾವಾಗಿ ನಿರ್ದೇಶಿಸಬಹುದು. ಹೀಗಾಗಿ, ಸರಳವಾದ ವ್ಯವಸ್ಥೆಯು ಯಾವಾಗಲೂ ಹೆಚ್ಚು ಸಂಕೀರ್ಣವಾದ ಒಂದರ ಕಾರ್ಯಕ್ಷಮತೆಗೆ ಹತ್ತಿರವಾಗಲು ಪ್ರಯತ್ನಿಸುತ್ತದೆ.
- ಕ್ಲಿಕ್ ವರ್ಗೀಕರಣ. ನೀವು ಪ್ರತಿ ಬಳಕೆದಾರ ಕ್ಲಿಕ್ ಅನ್ನು ಸರಳವಾಗಿ ವರ್ಗೀಕರಿಸಬಹುದು, ಅದರ ಸಿಂಧುತ್ವ ಮತ್ತು ಉಪಯುಕ್ತತೆಯನ್ನು ಮೌಲ್ಯಮಾಪನ ಮಾಡಬಹುದು. ನಾವು ಇದನ್ನು ಮೇಲ್ ಆಂಟಿಸ್ಪ್ಯಾಮ್ನಲ್ಲಿ, ಬಳಕೆದಾರ ಗುಣಲಕ್ಷಣಗಳು, ಅವರ ಇತಿಹಾಸ, ಕಳುಹಿಸುವವರ ಗುಣಲಕ್ಷಣಗಳು, ಪಠ್ಯ ಸ್ವತಃ ಮತ್ತು ವರ್ಗೀಕರಣಕಾರರ ಫಲಿತಾಂಶವನ್ನು ಬಳಸಿಕೊಂಡು ಮಾಡುತ್ತೇವೆ. ಪರಿಣಾಮವಾಗಿ, ಬಳಕೆದಾರರ ಪ್ರತಿಕ್ರಿಯೆಯನ್ನು ಮೌಲ್ಯೀಕರಿಸುವ ಸ್ವಯಂಚಾಲಿತ ವ್ಯವಸ್ಥೆಯನ್ನು ನಾವು ಪಡೆಯುತ್ತೇವೆ. ಮತ್ತು ಇದನ್ನು ಕಡಿಮೆ ಬಾರಿ ಮರು ತರಬೇತಿ ಮಾಡಬೇಕಾಗಿರುವುದರಿಂದ, ಅದರ ಕೆಲಸವು ಎಲ್ಲಾ ಇತರ ವ್ಯವಸ್ಥೆಗಳಿಗೆ ಮುಖ್ಯವಾಗಬಹುದು. ಈ ಮಾದರಿಯಲ್ಲಿ ಮುಖ್ಯ ಆದ್ಯತೆಯೆಂದರೆ ನಿಖರತೆ, ಏಕೆಂದರೆ ತಪ್ಪಾದ ಡೇಟಾದ ಮೇಲೆ ಮಾದರಿಯನ್ನು ತರಬೇತಿ ಮಾಡುವುದು ಪರಿಣಾಮಗಳಿಂದ ತುಂಬಿರುತ್ತದೆ.
ನಾವು ಡೇಟಾವನ್ನು ಸ್ವಚ್ಛಗೊಳಿಸುವಾಗ ಮತ್ತು ನಮ್ಮ ML ವ್ಯವಸ್ಥೆಗಳಿಗೆ ಮತ್ತಷ್ಟು ತರಬೇತಿ ನೀಡುವಾಗ, ಬಳಕೆದಾರರ ಬಗ್ಗೆ ನಾವು ಮರೆಯಬಾರದು, ಏಕೆಂದರೆ ನಮಗೆ, ಗ್ರಾಫ್ನಲ್ಲಿನ ಸಾವಿರಾರು, ಲಕ್ಷಾಂತರ ದೋಷಗಳು ಅಂಕಿಅಂಶಗಳಾಗಿವೆ ಮತ್ತು ಬಳಕೆದಾರರಿಗೆ, ಪ್ರತಿಯೊಂದು ದೋಷವು ಒಂದು ದುರಂತವಾಗಿದೆ. ಪ್ರತಿಕ್ರಿಯೆಯ ನಂತರ, ಬಳಕೆದಾರರು ಉತ್ಪನ್ನದಲ್ಲಿನ ನಿಮ್ಮ ದೋಷದೊಂದಿಗೆ ಹೇಗಾದರೂ ಬದುಕಬೇಕಾಗುತ್ತದೆ ಎಂಬ ಅಂಶದ ಜೊತೆಗೆ, ಭವಿಷ್ಯದಲ್ಲಿ ಅಂತಹ ಪರಿಸ್ಥಿತಿಗೆ ಅವರು ವಿನಾಯಿತಿಯನ್ನು ನಿರೀಕ್ಷಿಸುತ್ತಾರೆ. ಆದ್ದರಿಂದ, ಬಳಕೆದಾರರಿಗೆ ಮತ ಚಲಾಯಿಸಲು ಅವಕಾಶವನ್ನು ನೀಡುವುದು ಯಾವಾಗಲೂ ಯೋಗ್ಯವಾಗಿದೆ, ಆದರೆ ML ವ್ಯವಸ್ಥೆಗಳ ನಡವಳಿಕೆಯನ್ನು ಸರಿಪಡಿಸಲು ಸಹ, ಉದಾಹರಣೆಗೆ, ಪ್ರತಿ ಪ್ರತಿಕ್ರಿಯೆ ಕ್ಲಿಕ್ಗೆ ವೈಯಕ್ತಿಕ ಹ್ಯೂರಿಸ್ಟಿಕ್ಗಳನ್ನು ರಚಿಸುವುದು, ಮೇಲ್ ಸಂದರ್ಭದಲ್ಲಿ, ಈ ಬಳಕೆದಾರರಿಗೆ ಕಳುಹಿಸುವವರು ಮತ್ತು ಶೀರ್ಷಿಕೆಯ ಮೂಲಕ ಅಂತಹ ಅಕ್ಷರಗಳನ್ನು ಫಿಲ್ಟರ್ ಮಾಡುವ ಸಾಮರ್ಥ್ಯ ಇದಾಗಿರಬಹುದು.
ಇತರ ಬಳಕೆದಾರರು ಇದೇ ರೀತಿಯ ಸಮಸ್ಯೆಗಳಿಂದ ಬಳಲುತ್ತಿರುವುದನ್ನು ತಪ್ಪಿಸಲು, ಮಾದರಿಯನ್ನು ಅರೆ-ಸ್ವಯಂಚಾಲಿತ ಅಥವಾ ಹಸ್ತಚಾಲಿತ ಮೋಡ್ನಲ್ಲಿ ತಿರುಚಲು ಕೆಲವು ವರದಿಗಳು ಅಥವಾ ಬೆಂಬಲ ವಿನಂತಿಗಳನ್ನು ಬಳಸುವುದು ಸಹ ಅಗತ್ಯವಾಗಿದೆ.
ಕಲಿಕೆಗಾಗಿ ಸ್ವಯಂ ಅನ್ವೇಷಣೆಗಳು
ಈ ಹ್ಯೂರಿಸ್ಟಿಕ್ಸ್ ಮತ್ತು ಕ್ರಚ್ಗಳಲ್ಲಿ ಎರಡು ಸಮಸ್ಯೆಗಳಿವೆ. ಮೊದಲನೆಯದು, ನಿರಂತರವಾಗಿ ಬೆಳೆಯುತ್ತಿರುವ ಕ್ರಚ್ಗಳ ಸಂಖ್ಯೆಯನ್ನು ನಿರ್ವಹಿಸುವುದು ಕಷ್ಟ, ದೂರದವರೆಗೆ ಅವುಗಳ ಗುಣಮಟ್ಟ ಮತ್ತು ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಉಲ್ಲೇಖಿಸಬಾರದು. ಎರಡನೆಯ ಸಮಸ್ಯೆಯೆಂದರೆ ದೋಷವು ಆಗಾಗ್ಗೆ ಆಗದಿರಬಹುದು ಮತ್ತು ಮಾದರಿಯನ್ನು ಮರುತರಬೇತಿಗೊಳಿಸಲು ಹಲವಾರು ಕ್ಲಿಕ್ಗಳು ಸಾಕಾಗುವುದಿಲ್ಲ. ಈ ಎರಡು ಸಂಬಂಧವಿಲ್ಲದ ಪರಿಣಾಮಗಳನ್ನು ಈ ಕೆಳಗಿನ ವಿಧಾನವನ್ನು ಅನ್ವಯಿಸುವ ಮೂಲಕ ಗಮನಾರ್ಹವಾಗಿ ನೆಲಸಮ ಮಾಡಬಹುದು ಎಂದು ತೋರುತ್ತದೆ.
- ತಾತ್ಕಾಲಿಕ ಊರುಗೋಲನ್ನು ಸೃಷ್ಟಿಸೋಣ.
- ನಾವು ಅದರಿಂದ ಮಾದರಿಗೆ ಡೇಟಾವನ್ನು ಕಳುಹಿಸುತ್ತೇವೆ, ಸ್ವೀಕರಿಸಿದ ಡೇಟಾವನ್ನು ಒಳಗೊಂಡಂತೆ ಅದನ್ನು ನಿಯಮಿತವಾಗಿ ತರಬೇತಿ ನೀಡಲಾಗುತ್ತದೆ. ಇಲ್ಲಿ, ಸಹಜವಾಗಿ, ತರಬೇತಿ ಸೆಟ್ನಲ್ಲಿನ ಡೇಟಾದ ಗುಣಮಟ್ಟವನ್ನು ಕಡಿಮೆ ಮಾಡದಂತೆ ಹ್ಯೂರಿಸ್ಟಿಕ್ಸ್ ಹೆಚ್ಚಿನ ನಿಖರತೆಯನ್ನು ಹೊಂದಿರುವುದು ಮುಖ್ಯವಾಗಿದೆ.
- ನಂತರ ನಾವು ಕ್ರಚ್ ಕೆಲಸ ಮಾಡಲು ಮೇಲ್ವಿಚಾರಣೆಯನ್ನು ಸ್ಥಾಪಿಸುತ್ತೇವೆ ಮತ್ತು ಸ್ವಲ್ಪ ಸಮಯದ ನಂತರ ಕ್ರಚ್ ಇನ್ನು ಮುಂದೆ ಕಾರ್ಯನಿರ್ವಹಿಸದಿದ್ದರೆ ಮತ್ತು ಮಾದರಿಯಿಂದ ಸಂಪೂರ್ಣವಾಗಿ ಮುಚ್ಚಲ್ಪಟ್ಟಿದ್ದರೆ, ನಾವು ಅದನ್ನು ಸುರಕ್ಷಿತವಾಗಿ ತೆಗೆದುಹಾಕಬಹುದು. ಈಗ ಈ ಸಮಸ್ಯೆ ಮರುಕಳಿಸುವ ಸಾಧ್ಯತೆಯಿಲ್ಲ.
ಆದ್ದರಿಂದ ಊರುಗೋಲುಗಳ ಸೈನ್ಯವು ತುಂಬಾ ಉಪಯುಕ್ತವಾಗಿದೆ. ಮುಖ್ಯ ವಿಷಯವೆಂದರೆ ಅವರ ಸೇವೆ ತಾತ್ಕಾಲಿಕ, ಶಾಶ್ವತವಲ್ಲ.
ಹೆಚ್ಚಿನ ತರಬೇತಿ
ಮರುತರಬೇತಿ ಎಂದರೆ ಬಳಕೆದಾರರಿಂದ ಅಥವಾ ಇತರ ವ್ಯವಸ್ಥೆಗಳಿಂದ ಪಡೆದ ಪ್ರತಿಕ್ರಿಯೆಯಿಂದ ಹೊಸ ಡೇಟಾವನ್ನು ಸೇರಿಸುವ ಮತ್ತು ಅದರ ಮೇಲೆ ಅಸ್ತಿತ್ವದಲ್ಲಿರುವ ಮಾದರಿಗೆ ತರಬೇತಿ ನೀಡುವ ಪ್ರಕ್ರಿಯೆ. ಮರುತರಬೇತಿಯಲ್ಲಿ ಹಲವಾರು ಸಮಸ್ಯೆಗಳಿವೆ:
- ಮಾದರಿಯು ಹೆಚ್ಚುವರಿ ತರಬೇತಿಯನ್ನು ಬೆಂಬಲಿಸದಿರಬಹುದು, ಆದರೆ ಮೊದಲಿನಿಂದ ಮಾತ್ರ ಕಲಿಯುತ್ತದೆ.
- ಪ್ರಕೃತಿಯ ಪುಸ್ತಕದಲ್ಲಿ ಎಲ್ಲಿಯೂ ಹೆಚ್ಚುವರಿ ತರಬೇತಿಯು ಉತ್ಪಾದನೆಯಲ್ಲಿ ಕೆಲಸದ ಗುಣಮಟ್ಟವನ್ನು ಅಗತ್ಯವಾಗಿ ಸುಧಾರಿಸುತ್ತದೆ ಎಂದು ಬರೆಯಲಾಗಿಲ್ಲ. ಆಗಾಗ್ಗೆ, ಇದಕ್ಕೆ ವಿರುದ್ಧವಾಗಿ ಸಂಭವಿಸುತ್ತದೆ, ಅಂದರೆ, ಕ್ಷೀಣಿಸುವುದು ಮಾತ್ರ ಸಾಧ್ಯ.
- ಬದಲಾವಣೆಗಳು ಅನಿರೀಕ್ಷಿತವಾಗಿರಬಹುದು. ಇದು ನಾವೇ ಗುರುತಿಸಿಕೊಂಡಿರುವ ಸೂಕ್ಷ್ಮ ಅಂಶವಾಗಿದೆ. A/B ಪರೀಕ್ಷೆಯಲ್ಲಿ ಹೊಸ ಮಾದರಿಯು ಪ್ರಸ್ತುತದ ಫಲಿತಾಂಶಗಳಿಗೆ ಹೋಲಿಸಿದರೆ ಇದೇ ರೀತಿಯ ಫಲಿತಾಂಶಗಳನ್ನು ತೋರಿಸಿದರೂ, ಅದು ಒಂದೇ ರೀತಿ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ ಎಂದು ಅರ್ಥವಲ್ಲ. ಅವರ ಕೆಲಸವು ಸುಮಾರು ಒಂದು ಪ್ರತಿಶತದಷ್ಟು ಭಿನ್ನವಾಗಿರಬಹುದು, ಇದು ಹೊಸ ದೋಷಗಳನ್ನು ತರಬಹುದು ಅಥವಾ ಈಗಾಗಲೇ ಸರಿಪಡಿಸಲಾದ ಹಳೆಯದನ್ನು ಹಿಂತಿರುಗಿಸಬಹುದು. ನಾವು ಮತ್ತು ಬಳಕೆದಾರರು ಇಬ್ಬರೂ ಈಗಾಗಲೇ ಪ್ರಸ್ತುತ ದೋಷಗಳೊಂದಿಗೆ ಹೇಗೆ ಬದುಕಬೇಕೆಂದು ತಿಳಿದಿದ್ದೇವೆ ಮತ್ತು ಹೆಚ್ಚಿನ ಸಂಖ್ಯೆಯ ಹೊಸ ದೋಷಗಳು ಉದ್ಭವಿಸಿದಾಗ, ಬಳಕೆದಾರರು ಏನು ನಡೆಯುತ್ತಿದೆ ಎಂಬುದನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳದಿರಬಹುದು, ಏಕೆಂದರೆ ಅವರು ಊಹಿಸಬಹುದಾದ ನಡವಳಿಕೆಯನ್ನು ನಿರೀಕ್ಷಿಸುತ್ತಾರೆ.
ಆದ್ದರಿಂದ, ಮರುತರಬೇತಿಯಲ್ಲಿ ಅತ್ಯಂತ ಮುಖ್ಯವಾದ ವಿಷಯವೆಂದರೆ ಮಾದರಿ ಸುಧಾರಿಸುತ್ತದೆ ಅಥವಾ ಕನಿಷ್ಠ ಹದಗೆಡುವುದಿಲ್ಲ ಎಂದು ಖಾತರಿಪಡಿಸುವುದು.
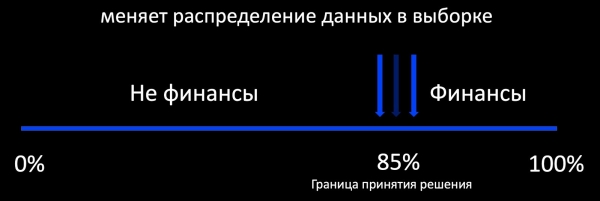
ಹೆಚ್ಚುವರಿ ತರಬೇತಿಯ ಬಗ್ಗೆ ಮಾತನಾಡುವಾಗ ನಾವು ಮೊದಲು ಮನಸ್ಸಿಗೆ ಬರುವುದು ಸಕ್ರಿಯ ಕಲಿಕೆಯ ವಿಧಾನ. ಇದರ ಅರ್ಥವೇನು? ಉದಾಹರಣೆಗೆ, ಒಂದು ವರ್ಗೀಕರಣಕಾರನು ಒಂದು ಪತ್ರವು ಹಣಕಾಸಿಗೆ ಸಂಬಂಧಿಸಿದೆಯೇ ಎಂದು ನಿರ್ಧರಿಸುತ್ತದೆ ಮತ್ತು ಅದರ ನಿರ್ಧಾರದ ಗಡಿಯ ಸುತ್ತಲೂ ನಾವು ಲೇಬಲ್ ಮಾಡಲಾದ ಉದಾಹರಣೆಗಳ ಮಾದರಿಯನ್ನು ಸೇರಿಸುತ್ತೇವೆ. ಇದು ಉತ್ತಮವಾಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ, ಉದಾಹರಣೆಗೆ, ಜಾಹೀರಾತಿನಲ್ಲಿ, ಅಲ್ಲಿ ಬಹಳಷ್ಟು ಪ್ರತಿಕ್ರಿಯೆ ಇರುತ್ತದೆ ಮತ್ತು ನೀವು ಮಾದರಿಯನ್ನು ಆನ್ಲೈನ್ನಲ್ಲಿ ತರಬೇತಿ ನೀಡಬಹುದು. ಆದರೆ ಕಡಿಮೆ ಪ್ರತಿಕ್ರಿಯೆ ಇದ್ದರೆ, ಉತ್ಪಾದನಾ ದತ್ತಾಂಶ ವಿತರಣೆಗೆ ಸಂಬಂಧಿಸಿದಂತೆ ನಾವು ಬಲವಾಗಿ ಪಕ್ಷಪಾತದ ಮಾದರಿಯನ್ನು ಪಡೆಯುತ್ತೇವೆ, ಅದರ ಆಧಾರದ ಮೇಲೆ ಕಾರ್ಯಾಚರಣೆಯ ಸಮಯದಲ್ಲಿ ಮಾದರಿಯ ನಡವಳಿಕೆಯನ್ನು ಮೌಲ್ಯಮಾಪನ ಮಾಡುವುದು ಅಸಾಧ್ಯ.
ವಾಸ್ತವವಾಗಿ, ನಮ್ಮ ಗುರಿ ಹಳೆಯ ಮಾದರಿಗಳನ್ನು, ಈಗಾಗಲೇ ತಿಳಿದಿರುವ ಮಾದರಿಗಳನ್ನು ಸಂರಕ್ಷಿಸುವುದು ಮತ್ತು ಹೊಸದನ್ನು ಪಡೆದುಕೊಳ್ಳುವುದು. ಇಲ್ಲಿ ನಿರಂತರತೆ ಮುಖ್ಯವಾಗಿದೆ. ನಾವು ಆಗಾಗ್ಗೆ ಬಹಳ ಕಷ್ಟಪಟ್ಟು ಹೊರತಂದ ಮಾದರಿ ಈಗಾಗಲೇ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತಿದೆ, ಆದ್ದರಿಂದ ನಾವು ಅದರ ಕಾರ್ಯಕ್ಷಮತೆಯ ಮೇಲೆ ಗಮನ ಹರಿಸಬಹುದು.
ಮೇಲ್ನಲ್ಲಿ ವಿಭಿನ್ನ ಮಾದರಿಗಳನ್ನು ಬಳಸಲಾಗುತ್ತದೆ: ಮರಗಳು, ರೇಖೀಯ, ನರಮಂಡಲ ಜಾಲಗಳು. ಪ್ರತಿಯೊಂದಕ್ಕೂ, ಹೆಚ್ಚುವರಿ ತರಬೇತಿಗಾಗಿ ನಾವು ನಮ್ಮದೇ ಆದ ಅಲ್ಗಾರಿದಮ್ ಅನ್ನು ತಯಾರಿಸುತ್ತೇವೆ. ಹೆಚ್ಚುವರಿ ತರಬೇತಿಯ ಪ್ರಕ್ರಿಯೆಯಲ್ಲಿ, ನಾವು ಹೊಸ ಡೇಟಾವನ್ನು ಮಾತ್ರವಲ್ಲದೆ, ಆಗಾಗ್ಗೆ ಹೊಸ ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ಸಹ ಪಡೆಯುತ್ತೇವೆ, ಅದನ್ನು ನಾವು ಕೆಳಗಿನ ಎಲ್ಲಾ ಅಲ್ಗಾರಿದಮ್ಗಳಲ್ಲಿ ಗಣನೆಗೆ ತೆಗೆದುಕೊಳ್ಳುತ್ತೇವೆ.
ರೇಖೀಯ ಮಾದರಿಗಳು
ನಮಗೆ ಲಾಜಿಸ್ಟಿಕ್ ರಿಗ್ರೆಷನ್ ಇದೆ ಎಂದು ಹೇಳೋಣ. ನಾವು ಈ ಕೆಳಗಿನ ಘಟಕಗಳಿಂದ ನಷ್ಟ ಮಾದರಿಯನ್ನು ರೂಪಿಸುತ್ತೇವೆ:
- ಹೊಸ ಡೇಟಾದಲ್ಲಿ ಲಾಗ್ಲಾಸ್;
- ನಾವು ಹೊಸ ವೈಶಿಷ್ಟ್ಯಗಳ ತೂಕವನ್ನು ಕ್ರಮಬದ್ಧಗೊಳಿಸುತ್ತೇವೆ (ನಾವು ಹಳೆಯದನ್ನು ಮಾತ್ರ ಬಿಡುತ್ತೇವೆ);
- ಹಳೆಯ ಮಾದರಿಗಳನ್ನು ಸಂರಕ್ಷಿಸಲು ನಾವು ಹಳೆಯ ದತ್ತಾಂಶದಿಂದ ಕಲಿಯುತ್ತೇವೆ;
- ಮತ್ತು, ಬಹುಶಃ, ಅತ್ಯಂತ ಮುಖ್ಯವಾದ ವಿಷಯ: ನಾವು ಹಾರ್ಮೋನಿಕ್ ಕ್ರಮಬದ್ಧಗೊಳಿಸುವಿಕೆಯನ್ನು ಸ್ಥಗಿತಗೊಳಿಸುತ್ತೇವೆ, ಇದು ರೂಢಿಯ ಪ್ರಕಾರ ಹಳೆಯ ಮಾದರಿಗೆ ಹೋಲಿಸಿದರೆ ತೂಕದಲ್ಲಿ ಬಲವಾದ ಬದಲಾವಣೆಯನ್ನು ಖಾತರಿಪಡಿಸುವುದಿಲ್ಲ.
ಪ್ರತಿಯೊಂದು ನಷ್ಟ ಘಟಕವು ಗುಣಾಂಕಗಳನ್ನು ಹೊಂದಿರುವುದರಿಂದ, ನಾವು ಅಡ್ಡ-ಮೌಲ್ಯಮಾಪನವನ್ನು ಬಳಸಿಕೊಂಡು ಅಥವಾ ಉತ್ಪನ್ನದ ಅವಶ್ಯಕತೆಗಳನ್ನು ಆಧರಿಸಿ ನಮ್ಮ ಕಾರ್ಯಕ್ಕೆ ಸೂಕ್ತವಾದ ಮೌಲ್ಯಗಳನ್ನು ಆಯ್ಕೆ ಮಾಡಬಹುದು.
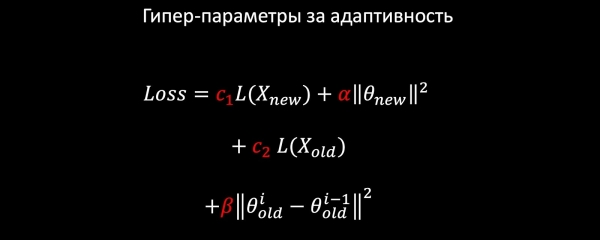
ಮರಗಳು
ನಿರ್ಧಾರ ವೃಕ್ಷಗಳಿಗೆ ಹೋಗೋಣ. ಮರಗಳನ್ನು ಮರುತರಬೇತಿ ಮಾಡಲು ನಾವು ಈ ಕೆಳಗಿನ ಅಲ್ಗಾರಿದಮ್ ಅನ್ನು ರೂಪಿಸಿದ್ದೇವೆ:
- ಹಳೆಯ ದತ್ತಾಂಶ ಸಂಗ್ರಹದ ಮೇಲೆ ತರಬೇತಿ ಪಡೆದ 100-300 ಮರಗಳ ಕಾಡನ್ನು ಈ ಉತ್ಪಾದನೆಯು ನಡೆಸುತ್ತದೆ.
- ನಾವು ಕೊನೆಯಲ್ಲಿ M = 5 ತುಣುಕುಗಳನ್ನು ತೆಗೆದುಹಾಕಿ 2M = 10 ಹೊಸದನ್ನು ಸೇರಿಸುತ್ತೇವೆ, ಸಂಪೂರ್ಣ ಡೇಟಾ ಸೆಟ್ನಲ್ಲಿ ತರಬೇತಿ ನೀಡಲಾಗುತ್ತದೆ, ಆದರೆ ಹೊಸ ಡೇಟಾಗೆ ಹೆಚ್ಚಿನ ತೂಕದೊಂದಿಗೆ, ಇದು ಸ್ವಾಭಾವಿಕವಾಗಿ ಮಾದರಿಯಲ್ಲಿ ಹೆಚ್ಚುತ್ತಿರುವ ಬದಲಾವಣೆಯನ್ನು ಖಾತರಿಪಡಿಸುತ್ತದೆ.
ಕಾಲಾನಂತರದಲ್ಲಿ ಮರಗಳ ಸಂಖ್ಯೆ ಬಹಳವಾಗಿ ಹೆಚ್ಚಾಗುತ್ತದೆ ಎಂಬುದು ಸ್ಪಷ್ಟವಾಗಿದೆ, ಮತ್ತು ಸಮಯವನ್ನು ಪೂರೈಸಲು ಅವುಗಳನ್ನು ನಿಯತಕಾಲಿಕವಾಗಿ ಕಡಿಮೆ ಮಾಡಬೇಕಾಗುತ್ತದೆ. ಇದಕ್ಕಾಗಿ, ನಾವು ಈಗ ಎಲ್ಲೆಡೆ ಇರುವ ಜ್ಞಾನ ಬಟ್ಟಿ ಇಳಿಸುವಿಕೆ (ಕೆಡಿ) ಅನ್ನು ಬಳಸುತ್ತೇವೆ. ಅದರ ಕಾರ್ಯಾಚರಣೆಯ ತತ್ವದ ಬಗ್ಗೆ ಸಂಕ್ಷಿಪ್ತವಾಗಿ.
- ನಮ್ಮಲ್ಲಿ ಪ್ರಸ್ತುತ "ಸಂಕೀರ್ಣ" ಮಾದರಿ ಇದೆ. ನಾವು ಅದನ್ನು ತರಬೇತಿ ಡೇಟಾಸೆಟ್ನಲ್ಲಿ ಚಲಾಯಿಸುತ್ತೇವೆ ಮತ್ತು ಔಟ್ಪುಟ್ ವರ್ಗಗಳ ಸಂಭವನೀಯತೆಯ ವಿತರಣೆಯನ್ನು ಪಡೆಯುತ್ತೇವೆ.
- ಮುಂದೆ, ವರ್ಗ ವಿತರಣೆಯನ್ನು ಗುರಿ ವೇರಿಯೇಬಲ್ ಆಗಿ ಬಳಸಿಕೊಂಡು ಮಾದರಿಯ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಪುನರಾವರ್ತಿಸಲು ನಾವು ವಿದ್ಯಾರ್ಥಿ ಮಾದರಿಗೆ (ಈ ಸಂದರ್ಭದಲ್ಲಿ ಕಡಿಮೆ ಮರಗಳನ್ನು ಹೊಂದಿರುವ ಮಾದರಿ) ತರಬೇತಿ ನೀಡುತ್ತೇವೆ.
- ಇಲ್ಲಿ ಗಮನಿಸಬೇಕಾದ ಅಂಶವೆಂದರೆ, ನಾವು ಯಾವುದೇ ಡೇಟಾಸೆಟ್ ಲೇಬಲಿಂಗ್ ಅನ್ನು ಬಳಸುವುದಿಲ್ಲ ಮತ್ತು ಆದ್ದರಿಂದ ಅನಿಯಂತ್ರಿತ ಡೇಟಾವನ್ನು ಬಳಸಬಹುದು. ಸಹಜವಾಗಿ, ನಾವು ವಿದ್ಯಾರ್ಥಿ ಮಾದರಿಗೆ ತರಬೇತಿ ಸೆಟ್ ಆಗಿ ಉತ್ಪಾದನಾ ಡೇಟಾದ ಮಾದರಿಯನ್ನು ಬಳಸುತ್ತೇವೆ. ಹೀಗಾಗಿ, ತರಬೇತಿ ಸೆಟ್ ನಮಗೆ ಮಾದರಿಯ ನಿಖರತೆಯನ್ನು ಖಚಿತಪಡಿಸಿಕೊಳ್ಳಲು ಅನುವು ಮಾಡಿಕೊಡುತ್ತದೆ, ಮತ್ತು ಸ್ಟ್ರೀಮ್ನ ಮಾದರಿಯು ಉತ್ಪಾದನಾ ವಿತರಣೆಯಲ್ಲಿ ಇದೇ ರೀತಿಯ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಖಚಿತಪಡಿಸುತ್ತದೆ, ತರಬೇತಿ ಸೆಟ್ನ ಪಕ್ಷಪಾತವನ್ನು ಸರಿದೂಗಿಸುತ್ತದೆ.
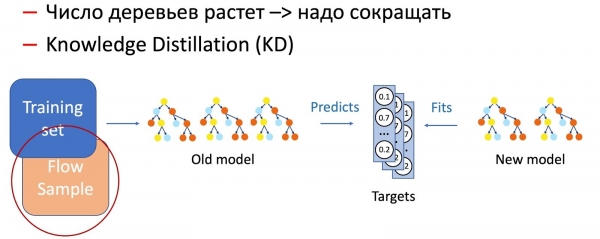
ಈ ಎರಡು ತಂತ್ರಗಳ ಸಂಯೋಜನೆಯು (ನಾಲೆಡ್ಜ್ ಡಿಸ್ಟಿಲೇಷನ್ ಬಳಸಿ ಮರಗಳನ್ನು ಸೇರಿಸುವುದು ಮತ್ತು ನಿಯತಕಾಲಿಕವಾಗಿ ಅವುಗಳ ಸಂಖ್ಯೆಯನ್ನು ಕಡಿಮೆ ಮಾಡುವುದು) ಹೊಸ ಮಾದರಿಗಳ ಪರಿಚಯ ಮತ್ತು ಸಂಪೂರ್ಣ ನಿರಂತರತೆಯನ್ನು ಖಚಿತಪಡಿಸುತ್ತದೆ.
KD ಯೊಂದಿಗೆ, ನಾವು ಮಾದರಿ ವೈಶಿಷ್ಟ್ಯಗಳೊಂದಿಗೆ ಕಾರ್ಯಾಚರಣೆಗಳ ನಡುವೆ ವ್ಯತ್ಯಾಸವನ್ನು ನಿರ್ವಹಿಸುತ್ತೇವೆ, ಉದಾಹರಣೆಗೆ ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ತೆಗೆದುಹಾಕುವುದು ಮತ್ತು ಅಂತರಗಳೊಂದಿಗೆ ಕೆಲಸ ಮಾಡುವುದು. ನಮ್ಮ ಸಂದರ್ಭದಲ್ಲಿ, ವಿಫಲಗೊಳ್ಳುವ ಪ್ರವೃತ್ತಿಯನ್ನು ಹೊಂದಿರುವ ಡೇಟಾಬೇಸ್ನಲ್ಲಿ ಸಂಗ್ರಹಿಸಲಾದ ಹಲವಾರು ಪ್ರಮುಖ ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು (ಕಳುಹಿಸುವವರು, ಪಠ್ಯ ಹ್ಯಾಶ್ಗಳು, URL ಗಳು, ಇತ್ಯಾದಿ) ನಾವು ಹೊಂದಿದ್ದೇವೆ. ತರಬೇತಿ ಸೆಟ್ನಲ್ಲಿ ಯಾವುದೇ ವೈಫಲ್ಯದ ಸಂದರ್ಭಗಳಿಲ್ಲದ ಕಾರಣ, ಮಾದರಿಯು ಅಂತಹ ಅಭಿವೃದ್ಧಿಗೆ ಸಿದ್ಧವಾಗಿಲ್ಲ. ಅಂತಹ ಸಂದರ್ಭಗಳಲ್ಲಿ, ನಾವು KD ಮತ್ತು ವರ್ಧನೆ ತಂತ್ರಗಳನ್ನು ಸಂಯೋಜಿಸುತ್ತೇವೆ: ಡೇಟಾದ ಒಂದು ಭಾಗಕ್ಕೆ ತರಬೇತಿ ನೀಡುವಾಗ, ನಾವು ಅಗತ್ಯ ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ತೆಗೆದುಹಾಕುತ್ತೇವೆ ಅಥವಾ ಶೂನ್ಯಗೊಳಿಸುತ್ತೇವೆ ಮತ್ತು ಮೂಲ ಲೇಬಲ್ಗಳನ್ನು (ಪ್ರಸ್ತುತ ಮಾದರಿಯ ಔಟ್ಪುಟ್ಗಳು) ತೆಗೆದುಕೊಳ್ಳುತ್ತೇವೆ, ವಿದ್ಯಾರ್ಥಿ ಮಾದರಿಯು ಈ ವಿತರಣೆಯನ್ನು ಪುನರಾವರ್ತಿಸಲು ಕಲಿಯುತ್ತದೆ.
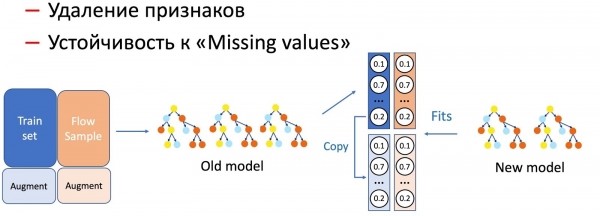
ಮಾದರಿ ಕುಶಲತೆಯು ಹೆಚ್ಚು ಗಂಭೀರವಾದಷ್ಟೂ, ಹರಿವಿನ ಮಾದರಿಗಳ ಶೇಕಡಾವಾರು ಪ್ರಮಾಣವು ಹೆಚ್ಚಾಗಿರುತ್ತದೆ ಎಂದು ನಾವು ಗಮನಿಸಿದ್ದೇವೆ.
ವೈಶಿಷ್ಟ್ಯ ತೆಗೆಯುವಿಕೆ, ಸರಳವಾದ ಕಾರ್ಯಾಚರಣೆಗೆ ಹರಿವಿನ ಒಂದು ಸಣ್ಣ ಭಾಗ ಮಾತ್ರ ಬೇಕಾಗುತ್ತದೆ, ಏಕೆಂದರೆ ಕೇವಲ ಒಂದೆರಡು ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ಬದಲಾಯಿಸಲಾಗಿದೆ ಮತ್ತು ಪ್ರಸ್ತುತ ಮಾದರಿಯನ್ನು ಒಂದೇ ಸೆಟ್ನಲ್ಲಿ ತರಬೇತಿ ನೀಡಲಾಗಿದೆ - ವ್ಯತ್ಯಾಸವು ಕಡಿಮೆಯಾಗಿದೆ. ಮಾದರಿಯನ್ನು ಸರಳೀಕರಿಸಲು (ಮರಗಳ ಸಂಖ್ಯೆಯನ್ನು ಹಲವಾರು ಬಾರಿ ಕಡಿಮೆ ಮಾಡುವುದು) 50/50 ಅಗತ್ಯವಿದೆ. ಮತ್ತು ಮಾದರಿಯ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಗಂಭೀರವಾಗಿ ಪರಿಣಾಮ ಬೀರುವ ಪ್ರಮುಖ ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯ ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ಕಳೆದುಕೊಂಡರೆ, ಎಲ್ಲಾ ರೀತಿಯ ಅಕ್ಷರಗಳಲ್ಲಿ ಲೋಪಗಳಿಗೆ ನಿರೋಧಕವಾದ ಹೊಸ ಮಾದರಿಯ ಕೆಲಸವನ್ನು ಮಟ್ಟ ಹಾಕಲು ಇನ್ನೂ ಹೆಚ್ಚಿನ ಹರಿವಿನ ಅಗತ್ಯವಿದೆ.
ಫಾಸ್ಟ್ಟೆಕ್ಸ್ಟ್
ಫಾಸ್ಟ್ಟೆಕ್ಸ್ಟ್ಗೆ ಹೋಗೋಣ. ಪದದ ಪ್ರಾತಿನಿಧ್ಯ (ಎಂಬೆಡಿಂಗ್) ಪದದ ಎಂಬೆಡಿಂಗ್ನ ಮೊತ್ತ ಮತ್ತು ಅದರ ಎಲ್ಲಾ ಅಕ್ಷರ N-ಗ್ರಾಮ್ಗಳನ್ನು ಒಳಗೊಂಡಿರುತ್ತದೆ ಎಂದು ನಾನು ನಿಮಗೆ ನೆನಪಿಸುತ್ತೇನೆ, ಸಾಮಾನ್ಯವಾಗಿ ಟ್ರಿಗ್ರಾಮ್ಗಳು. ಸಾಕಷ್ಟು ಟ್ರಿಗ್ರಾಮ್ಗಳು ಇರಬಹುದಾದ್ದರಿಂದ, ಬಕೆಟ್ ಹ್ಯಾಶಿಂಗ್ ಅನ್ನು ಬಳಸಲಾಗುತ್ತದೆ, ಅಂದರೆ, ಸಂಪೂರ್ಣ ಜಾಗವನ್ನು ನಿರ್ದಿಷ್ಟ ಸ್ಥಿರ ಹ್ಯಾಶ್ಮ್ಯಾಪ್ ಆಗಿ ಪರಿವರ್ತಿಸುವುದು. ಪರಿಣಾಮವಾಗಿ, ತೂಕದ ಮ್ಯಾಟ್ರಿಕ್ಸ್ ಅನ್ನು ಪದಗಳ ಸಂಖ್ಯೆ + ಬಕೆಟ್ಗಳಿಂದ ಆಂತರಿಕ ಪದರದ ಆಯಾಮದೊಂದಿಗೆ ಪಡೆಯಲಾಗುತ್ತದೆ.
ಮರುತರಬೇತಿ ಸಮಯದಲ್ಲಿ, ಹೊಸ ವೈಶಿಷ್ಟ್ಯಗಳು ಕಾಣಿಸಿಕೊಳ್ಳುತ್ತವೆ: ಪದಗಳು ಮತ್ತು ಟ್ರಿಗ್ರಾಮ್ಗಳು. Facebook ನಿಂದ ಪ್ರಮಾಣಿತ ಮರುತರಬೇತಿಯಲ್ಲಿ, ಗಮನಾರ್ಹವಾದ ಏನೂ ಸಂಭವಿಸುವುದಿಲ್ಲ. ಹೊಸ ಡೇಟಾದಲ್ಲಿ ಕ್ರಾಸ್-ಎಂಟ್ರೊಪಿ ಹೊಂದಿರುವ ಹಳೆಯ ತೂಕವನ್ನು ಮಾತ್ರ ಮರುತರಬೇತಿ ಮಾಡಲಾಗುತ್ತದೆ. ಹೀಗಾಗಿ, ಹೊಸ ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ಬಳಸಲಾಗುವುದಿಲ್ಲ, ಸಹಜವಾಗಿ, ಈ ವಿಧಾನವು ಉತ್ಪಾದನೆಯಲ್ಲಿ ಮಾದರಿಯ ಅನಿರೀಕ್ಷಿತತೆಗೆ ಸಂಬಂಧಿಸಿದ ಮೇಲಿನ ಎಲ್ಲಾ ಅನಾನುಕೂಲಗಳನ್ನು ಹೊಂದಿದೆ. ಆದ್ದರಿಂದ, ನಾವು ಫಾಸ್ಟ್ಟೆಕ್ಸ್ಟ್ ಅನ್ನು ಸ್ವಲ್ಪ ಸುಧಾರಿಸಿದ್ದೇವೆ. ನಾವು ಎಲ್ಲಾ ಹೊಸ ತೂಕವನ್ನು (ಪದಗಳು ಮತ್ತು ಟ್ರಿಗ್ರಾಮ್ಗಳು) ಸೇರಿಸುತ್ತೇವೆ, ಕ್ರಾಸ್-ಎಂಟ್ರೊಪಿಯೊಂದಿಗೆ ಸಂಪೂರ್ಣ ಮ್ಯಾಟ್ರಿಕ್ಸ್ ಅನ್ನು ಮರುತರಬೇತಿ ಮಾಡುತ್ತೇವೆ ಮತ್ತು ರೇಖೀಯ ಮಾದರಿಯೊಂದಿಗೆ ಸಾದೃಶ್ಯದ ಮೂಲಕ ಹಾರ್ಮೋನಿಕ್ ಕ್ರಮಬದ್ಧಗೊಳಿಸುವಿಕೆಯನ್ನು ಸೇರಿಸುತ್ತೇವೆ, ಇದು ಹಳೆಯ ತೂಕಗಳಲ್ಲಿ ಅತ್ಯಲ್ಪ ಬದಲಾವಣೆಯನ್ನು ಖಾತರಿಪಡಿಸುತ್ತದೆ.

ಸಿಎನ್ಎನ್
ಕನ್ವಲ್ಯೂಷನಲ್ ನೆಟ್ವರ್ಕ್ಗಳೊಂದಿಗೆ ಇದು ಸ್ವಲ್ಪ ಹೆಚ್ಚು ಜಟಿಲವಾಗಿದೆ. ಕೊನೆಯ ಪದರಗಳನ್ನು CNN ನಲ್ಲಿ ತರಬೇತಿ ನೀಡುತ್ತಿದ್ದರೆ, ಸಹಜವಾಗಿ, ಹಾರ್ಮೋನಿಕ್ ಕ್ರಮಬದ್ಧಗೊಳಿಸುವಿಕೆಯನ್ನು ಅನ್ವಯಿಸಬಹುದು ಮತ್ತು ನಿರಂತರತೆಯನ್ನು ಖಾತರಿಪಡಿಸಬಹುದು. ಆದರೆ ಸಂಪೂರ್ಣ ನೆಟ್ವರ್ಕ್ಗೆ ತರಬೇತಿ ನೀಡಬೇಕಾದರೆ, ಅಂತಹ ಕ್ರಮಬದ್ಧಗೊಳಿಸುವಿಕೆಯನ್ನು ಎಲ್ಲಾ ಪದರಗಳಿಗೆ ಅನ್ವಯಿಸಲಾಗುವುದಿಲ್ಲ. ಆದಾಗ್ಯೂ, ಟ್ರಿಪ್ಲೆಟ್ ಲಾಸ್ ಮೂಲಕ ಪೂರಕ ಎಂಬೆಡಿಂಗ್ಗಳನ್ನು ತರಬೇತಿ ಮಾಡುವ ಆಯ್ಕೆ ಇದೆ ().
ತ್ರಿವಳಿ ನಷ್ಟ
ಫಿಶಿಂಗ್ ವಿರೋಧಿ ಕಾರ್ಯವನ್ನು ಉದಾಹರಣೆಯಾಗಿ ಬಳಸಿಕೊಂಡು, ನಾವು ಸಾಮಾನ್ಯ ಪರಿಭಾಷೆಯಲ್ಲಿ ಟ್ರಿಪ್ಲೆಟ್ ನಷ್ಟವನ್ನು ವಿಶ್ಲೇಷಿಸುತ್ತೇವೆ. ನಾವು ನಮ್ಮ ಲೋಗೋವನ್ನು ತೆಗೆದುಕೊಳ್ಳುತ್ತೇವೆ, ಜೊತೆಗೆ ಇತರ ಕಂಪನಿಗಳ ಲೋಗೋಗಳ ಧನಾತ್ಮಕ ಮತ್ತು ಋಣಾತ್ಮಕ ಉದಾಹರಣೆಗಳನ್ನು ತೆಗೆದುಕೊಳ್ಳುತ್ತೇವೆ. ನಾವು ಮೊದಲನೆಯದರ ನಡುವಿನ ಅಂತರವನ್ನು ಕಡಿಮೆ ಮಾಡುತ್ತೇವೆ ಮತ್ತು ಎರಡನೆಯದರ ನಡುವಿನ ಅಂತರವನ್ನು ಹೆಚ್ಚಿಸುತ್ತೇವೆ, ತರಗತಿಗಳ ಹೆಚ್ಚಿನ ಸಾಂದ್ರತೆಯನ್ನು ಖಚಿತಪಡಿಸಿಕೊಳ್ಳಲು ನಾವು ಇದನ್ನು ಸಣ್ಣ ಅಂತರದೊಂದಿಗೆ ಮಾಡುತ್ತೇವೆ.
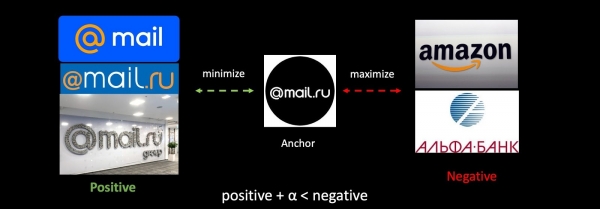
ನಾವು ನೆಟ್ವರ್ಕ್ ಅನ್ನು ಮರುತರಬೇತಿಗೊಳಿಸಿದರೆ, ನಮ್ಮ ಮೆಟ್ರಿಕ್ ಸ್ಥಳವು ಸಂಪೂರ್ಣವಾಗಿ ಬದಲಾಗುತ್ತದೆ ಮತ್ತು ಅದು ಹಿಂದಿನದಕ್ಕೆ ಸಂಪೂರ್ಣವಾಗಿ ಹೊಂದಿಕೆಯಾಗುವುದಿಲ್ಲ. ವೆಕ್ಟರ್ಗಳನ್ನು ಬಳಸುವ ಕಾರ್ಯಗಳಲ್ಲಿ ಇದು ಗಂಭೀರ ಸಮಸ್ಯೆಯಾಗಿದೆ. ಈ ಸಮಸ್ಯೆಯನ್ನು ಪರಿಹರಿಸಲು, ನಾವು ತರಬೇತಿಯ ಸಮಯದಲ್ಲಿ ಹಳೆಯ ಎಂಬೆಡಿಂಗ್ಗಳಲ್ಲಿ ಮಿಶ್ರಣ ಮಾಡುತ್ತೇವೆ.
ನಾವು ತರಬೇತಿ ಸೆಟ್ಗೆ ಹೊಸ ಡೇಟಾವನ್ನು ಸೇರಿಸಿದ್ದೇವೆ ಮತ್ತು ಮಾದರಿಯ ಎರಡನೇ ಆವೃತ್ತಿಯನ್ನು ಮೊದಲಿನಿಂದಲೂ ತರಬೇತಿ ನೀಡಿದ್ದೇವೆ. ಎರಡನೇ ಹಂತದಲ್ಲಿ, ನಾವು ನಮ್ಮ ನೆಟ್ವರ್ಕ್ ಅನ್ನು ಉತ್ತಮಗೊಳಿಸುತ್ತೇವೆ: ಮೊದಲು, ಕೊನೆಯ ಪದರವನ್ನು ಉತ್ತಮಗೊಳಿಸಲಾಗುತ್ತದೆ ಮತ್ತು ನಂತರ ಸಂಪೂರ್ಣ ನೆಟ್ವರ್ಕ್ ಅನ್ನು ಫ್ರೀಜ್ ಮಾಡಲಾಗುತ್ತದೆ. ತ್ರಿವಳಿಗಳನ್ನು ರಚಿಸುವ ಪ್ರಕ್ರಿಯೆಯಲ್ಲಿ, ಎಂಬೆಡಿಂಗ್ಗಳ ಒಂದು ಭಾಗವನ್ನು ಮಾತ್ರ ತರಬೇತಿ ಪಡೆದ ಮಾದರಿಯನ್ನು ಬಳಸಿಕೊಂಡು ಲೆಕ್ಕಹಾಕಲಾಗುತ್ತದೆ, ಉಳಿದವು - ಹಳೆಯದನ್ನು ಬಳಸಿ. ಹೀಗಾಗಿ, ಉತ್ತಮಗೊಳಿಸುವಿಕೆಯ ಪ್ರಕ್ರಿಯೆಯಲ್ಲಿ, ಮೆಟ್ರಿಕ್ ಸ್ಥಳಗಳು v1 ಮತ್ತು v2 ನ ಹೊಂದಾಣಿಕೆಯನ್ನು ನಾವು ಖಚಿತಪಡಿಸುತ್ತೇವೆ. ಹಾರ್ಮೋನಿಕ್ ಕ್ರಮಬದ್ಧಗೊಳಿಸುವಿಕೆಯ ಒಂದು ವಿಶಿಷ್ಟ ಆವೃತ್ತಿ.
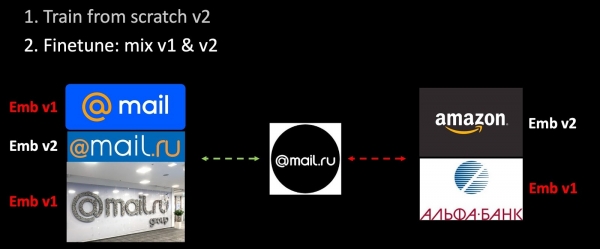
ಸಂಪೂರ್ಣ ವಾಸ್ತುಶಿಲ್ಪ
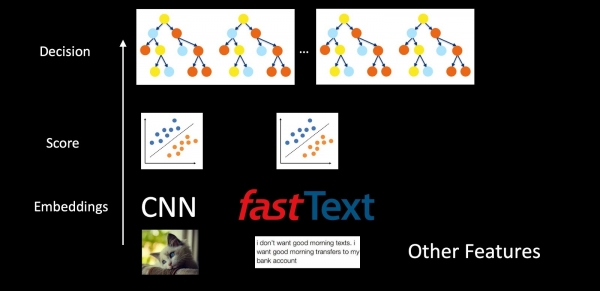
ನಾವು ಆಂಟಿಸ್ಪ್ಯಾಮ್ ಉದಾಹರಣೆಯನ್ನು ಬಳಸಿಕೊಂಡು ಇಡೀ ವ್ಯವಸ್ಥೆಯನ್ನು ಪರಿಗಣಿಸಿದರೆ, ಮಾದರಿಗಳು ಪ್ರತ್ಯೇಕವಾಗಿಲ್ಲ, ಆದರೆ ನೆಸ್ಟೆಡ್ ಆಗಿರುತ್ತವೆ. ನಾವು ಚಿತ್ರಗಳು, ಪಠ್ಯ ಮತ್ತು ಇತರ ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ತೆಗೆದುಕೊಳ್ಳುತ್ತೇವೆ ಮತ್ತು CNN ಮತ್ತು ಫಾಸ್ಟ್ ಟೆಕ್ಸ್ಟ್ ಸಹಾಯದಿಂದ ನಾವು ಎಂಬೆಡಿಂಗ್ಗಳನ್ನು ಪಡೆಯುತ್ತೇವೆ. ನಂತರ, ಎಂಬೆಡಿಂಗ್ಗಳ ಮೇಲೆ ವರ್ಗೀಕರಣಗಳನ್ನು ಅನ್ವಯಿಸಲಾಗುತ್ತದೆ, ಇದು ವಿಭಿನ್ನ ವರ್ಗಗಳಿಗೆ (ಇಮೇಲ್ಗಳ ಪ್ರಕಾರಗಳು, ಸ್ಪ್ಯಾಮ್, ಲೋಗೋದ ಉಪಸ್ಥಿತಿ) ಸ್ಕೋರ್ಗಳನ್ನು ಉತ್ಪಾದಿಸುತ್ತದೆ. ನಂತರ ಅಂತಿಮ ನಿರ್ಧಾರವನ್ನು ತೆಗೆದುಕೊಳ್ಳಲು ಸ್ಕೋರ್ಗಳು ಮತ್ತು ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ಮರಗಳ ಕಾಡಿನಲ್ಲಿ ಇರಿಸಲಾಗುತ್ತದೆ. ಈ ಯೋಜನೆಯಲ್ಲಿ ಪ್ರತ್ಯೇಕ ವರ್ಗೀಕರಣಗಳು ವ್ಯವಸ್ಥೆಯ ಕೆಲಸದ ಫಲಿತಾಂಶಗಳನ್ನು ಉತ್ತಮವಾಗಿ ಅರ್ಥೈಸಲು ಮತ್ತು ಸಮಸ್ಯೆಗಳ ಸಂದರ್ಭದಲ್ಲಿ ಘಟಕಗಳಿಗೆ ಹೆಚ್ಚು ನಿರ್ದಿಷ್ಟವಾಗಿ ತರಬೇತಿ ನೀಡಲು ನಮಗೆ ಅವಕಾಶ ಮಾಡಿಕೊಡುತ್ತವೆ, ಬದಲಿಗೆ ಎಲ್ಲಾ ಡೇಟಾವನ್ನು ಕಚ್ಚಾ ರೂಪದಲ್ಲಿ ನಿರ್ಧಾರ ಮರಗಳಿಗೆ ಫೀಡ್ ಮಾಡುತ್ತವೆ.
ಅಂತಿಮವಾಗಿ, ನಾವು ಪ್ರತಿ ಹಂತದಲ್ಲೂ ನಿರಂತರತೆಯನ್ನು ಖಾತರಿಪಡಿಸುತ್ತೇವೆ. CNN ಮತ್ತು ಫಾಸ್ಟ್ ಟೆಕ್ಸ್ಟ್ನಲ್ಲಿ ಕೆಳ ಹಂತದಲ್ಲಿ ನಾವು ಮಧ್ಯದಲ್ಲಿ ವರ್ಗೀಕರಣಕಾರಕಗಳಿಗಾಗಿ ಹಾರ್ಮೋನಿಕ್ ಕ್ರಮಬದ್ಧಗೊಳಿಸುವಿಕೆಯನ್ನು ಬಳಸುತ್ತೇವೆ - ಸಂಭವನೀಯತೆಯ ವಿತರಣೆಯ ಸ್ಥಿರತೆಗಾಗಿ ಹಾರ್ಮೋನಿಕ್ ಕ್ರಮಬದ್ಧಗೊಳಿಸುವಿಕೆ ಮತ್ತು ಸ್ಕೋರ್ ಮಾಪನಾಂಕ ನಿರ್ಣಯವನ್ನು ಸಹ ಬಳಸುತ್ತೇವೆ. ಮತ್ತು ಬೂಸ್ಟ್ ಮಾಡಿದ ಮರಗಳನ್ನು ಕ್ರಮೇಣ ಅಥವಾ ಜ್ಞಾನ ಬಟ್ಟಿ ಇಳಿಸುವಿಕೆಯೊಂದಿಗೆ ತರಬೇತಿ ನೀಡಲಾಗುತ್ತದೆ.
ಸಾಮಾನ್ಯವಾಗಿ, ಅಂತಹ ನೆಸ್ಟೆಡ್ ಮೆಷಿನ್ ಲರ್ನಿಂಗ್ ಸಿಸ್ಟಮ್ ಅನ್ನು ನಿರ್ವಹಿಸುವುದು ಸಾಮಾನ್ಯವಾಗಿ ಕಷ್ಟಕರವಾಗಿರುತ್ತದೆ, ಏಕೆಂದರೆ ಕೆಳ ಹಂತದ ಯಾವುದೇ ಘಟಕವು ಮೇಲಿನ ಸಂಪೂರ್ಣ ವ್ಯವಸ್ಥೆಯ ನವೀಕರಣಕ್ಕೆ ಕಾರಣವಾಗುತ್ತದೆ. ಆದರೆ ನಮ್ಮ ಸೆಟಪ್ನಲ್ಲಿ ಪ್ರತಿಯೊಂದು ಘಟಕವು ಸ್ವಲ್ಪ ಬದಲಾಗುವುದರಿಂದ ಮತ್ತು ಹಿಂದಿನದಕ್ಕೆ ಹೊಂದಿಕೆಯಾಗುವುದರಿಂದ, ಸಂಪೂರ್ಣ ರಚನೆಯನ್ನು ಮರುತರಬೇತಿ ಮಾಡುವ ಅಗತ್ಯವಿಲ್ಲದೇ ಇಡೀ ವ್ಯವಸ್ಥೆಯನ್ನು ತುಂಡುಗಳಾಗಿ ನವೀಕರಿಸಬಹುದು, ಇದು ಗಂಭೀರ ಓವರ್ಹೆಡ್ ಇಲ್ಲದೆ ನಿರ್ವಹಿಸಲು ಅನುವು ಮಾಡಿಕೊಡುತ್ತದೆ.
ನಿಯೋಜಿಸಿ
ನಾವು ವಿವಿಧ ರೀತಿಯ ಮಾದರಿಗಳ ಡೇಟಾ ಸಂಗ್ರಹಣೆ ಮತ್ತು ಹೆಚ್ಚುವರಿ ತರಬೇತಿಯನ್ನು ಒಳಗೊಂಡಿದ್ದೇವೆ, ಆದ್ದರಿಂದ ನಾವು ಅವುಗಳನ್ನು ಉತ್ಪಾದನಾ ಪರಿಸರಕ್ಕೆ ನಿಯೋಜಿಸುವತ್ತ ಸಾಗುತ್ತಿದ್ದೇವೆ.
ಎ/ಬಿ ಪರೀಕ್ಷೆ
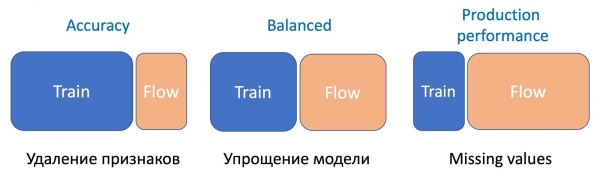
ನಾನು ಮೊದಲೇ ಹೇಳಿದಂತೆ, ಡೇಟಾ ಸಂಗ್ರಹಣಾ ಪ್ರಕ್ರಿಯೆಯಲ್ಲಿ, ನಾವು ಸಾಮಾನ್ಯವಾಗಿ ಪಕ್ಷಪಾತದ ಮಾದರಿಯನ್ನು ಪಡೆಯುತ್ತೇವೆ, ಇದು ಮಾದರಿಯ ಉತ್ಪಾದನಾ ಕಾರ್ಯಕ್ಷಮತೆಯನ್ನು ಮೌಲ್ಯಮಾಪನ ಮಾಡಲು ಅಸಾಧ್ಯವಾಗಿಸುತ್ತದೆ. ಆದ್ದರಿಂದ, ನಿಯೋಜಿಸುವಾಗ, ವಿಷಯಗಳು ನಿಜವಾಗಿ ಹೇಗೆ ನಡೆಯುತ್ತಿವೆ ಎಂಬುದನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳಲು, ಅಂದರೆ A/B ಪರೀಕ್ಷೆಗಳನ್ನು ನಡೆಸಲು ಮಾದರಿಯನ್ನು ಹಿಂದಿನ ಆವೃತ್ತಿಯೊಂದಿಗೆ ಹೋಲಿಸಬೇಕು. ವಾಸ್ತವವಾಗಿ, ಗ್ರಾಫ್ಗಳನ್ನು ಹೊರತರುವ ಮತ್ತು ವಿಶ್ಲೇಷಿಸುವ ಪ್ರಕ್ರಿಯೆಯು ಸಾಕಷ್ಟು ದಿನಚರಿಯಾಗಿದೆ ಮತ್ತು ಯಾಂತ್ರೀಕರಣಕ್ಕೆ ಉತ್ತಮವಾಗಿ ಹೊಂದಿಕೊಳ್ಳುತ್ತದೆ. ಮಾದರಿ ಪ್ರತಿಕ್ರಿಯೆಗಳು ಮತ್ತು ಬಳಕೆದಾರರ ಪ್ರತಿಕ್ರಿಯೆಯ ಕುರಿತು ಲಭ್ಯವಿರುವ ಎಲ್ಲಾ ಮೆಟ್ರಿಕ್ಗಳನ್ನು ಸಂಗ್ರಹಿಸುವಾಗ ನಾವು ನಮ್ಮ ಮಾದರಿಗಳನ್ನು ಕ್ರಮೇಣ 5%, 30%, 50% ಮತ್ತು 100% ಬಳಕೆದಾರರಿಗೆ ಹೊರತರುತ್ತೇವೆ. ಯಾವುದೇ ಗಂಭೀರವಾದ ಹೊರಗಿನವರ ಸಂದರ್ಭದಲ್ಲಿ, ನಾವು ಸ್ವಯಂಚಾಲಿತವಾಗಿ ಮಾದರಿಯನ್ನು ಹಿಂದಕ್ಕೆ ತರುತ್ತೇವೆ ಮತ್ತು ಇತರ ಸಂದರ್ಭಗಳಲ್ಲಿ, ಸಾಕಷ್ಟು ಸಂಖ್ಯೆಯ ಬಳಕೆದಾರ ಕ್ಲಿಕ್ಗಳನ್ನು ಸಂಗ್ರಹಿಸಿದ ನಂತರ, ನಾವು ಶೇಕಡಾವಾರು ಪ್ರಮಾಣವನ್ನು ಹೆಚ್ಚಿಸಲು ನಿರ್ಧರಿಸುತ್ತೇವೆ. ಪರಿಣಾಮವಾಗಿ, ನಾವು ಹೊಸ ಮಾದರಿಯನ್ನು ಸಂಪೂರ್ಣವಾಗಿ ಸ್ವಯಂಚಾಲಿತವಾಗಿ 50% ಬಳಕೆದಾರರಿಗೆ ತರುತ್ತೇವೆ ಮತ್ತು ಸಂಪೂರ್ಣ ಪ್ರೇಕ್ಷಕರಿಗೆ ಹೊರತರುವಿಕೆಯನ್ನು ಒಬ್ಬ ವ್ಯಕ್ತಿಯಿಂದ ಅನುಮೋದಿಸಲಾಗುತ್ತದೆ, ಆದರೂ ಈ ಹಂತವನ್ನು ಸಹ ಸ್ವಯಂಚಾಲಿತಗೊಳಿಸಬಹುದು.
ಆದಾಗ್ಯೂ, A/B ಪರೀಕ್ಷಾ ಪ್ರಕ್ರಿಯೆಯು ಆಪ್ಟಿಮೈಸೇಶನ್ಗೆ ಅವಕಾಶ ನೀಡುತ್ತದೆ. ವಾಸ್ತವವಾಗಿ ಯಾವುದೇ A/B ಪರೀಕ್ಷೆಯು ಸಾಕಷ್ಟು ಉದ್ದವಾಗಿದೆ (ನಮ್ಮ ಸಂದರ್ಭದಲ್ಲಿ, ಪ್ರತಿಕ್ರಿಯೆಯ ಪ್ರಮಾಣವನ್ನು ಅವಲಂಬಿಸಿ ಇದು 6 ರಿಂದ 24 ಗಂಟೆಗಳವರೆಗೆ ತೆಗೆದುಕೊಳ್ಳುತ್ತದೆ), ಇದು ಸಾಕಷ್ಟು ದುಬಾರಿ ಮತ್ತು ಸಂಪನ್ಮೂಲ-ಸೀಮಿತವಾಗಿದೆ. ಇದರ ಜೊತೆಗೆ, A/B ಪರೀಕ್ಷೆಯ ಒಟ್ಟಾರೆ ಸಮಯವನ್ನು ಮೂಲಭೂತವಾಗಿ ವೇಗಗೊಳಿಸಲು ಪರೀಕ್ಷೆಗೆ ಸಾಕಷ್ಟು ಹೆಚ್ಚಿನ ಶೇಕಡಾವಾರು ಹರಿವಿನ ಅಗತ್ಯವಿದೆ (ಸಣ್ಣ ಶೇಕಡಾವಾರು ಪ್ರಮಾಣದಲ್ಲಿ ಮೆಟ್ರಿಕ್ಗಳನ್ನು ನಿರ್ಣಯಿಸಲು ಸಂಖ್ಯಾಶಾಸ್ತ್ರೀಯವಾಗಿ ಮಹತ್ವದ ಮಾದರಿಯನ್ನು ಸಂಗ್ರಹಿಸಲು ಇದು ಬಹಳ ಸಮಯ ತೆಗೆದುಕೊಳ್ಳಬಹುದು), ಇದು A/B ಸ್ಲಾಟ್ಗಳ ಸಂಖ್ಯೆಯನ್ನು ಅತ್ಯಂತ ಸೀಮಿತಗೊಳಿಸುತ್ತದೆ. ನಿಸ್ಸಂಶಯವಾಗಿ, ನಾವು ಪರೀಕ್ಷೆಗೆ ಹೆಚ್ಚು ಭರವಸೆಯ ಮಾದರಿಗಳನ್ನು ಮಾತ್ರ ಹಾಕಬೇಕಾಗಿದೆ, ಅದರಲ್ಲಿ ನಾವು ಹೆಚ್ಚುವರಿ ತರಬೇತಿಯ ಪ್ರಕ್ರಿಯೆಯಲ್ಲಿ ಸಾಕಷ್ಟು ಪಡೆಯುತ್ತೇವೆ.
ಈ ಸಮಸ್ಯೆಯನ್ನು ಪರಿಹರಿಸಲು, ನಾವು A/B ಪರೀಕ್ಷೆಯ ಯಶಸ್ಸನ್ನು ಮುನ್ಸೂಚಿಸುವ ಪ್ರತ್ಯೇಕ ವರ್ಗೀಕರಣಕಾರಕಕ್ಕೆ ತರಬೇತಿ ನೀಡಿದ್ದೇವೆ. ಇದನ್ನು ಮಾಡಲು, ನಾವು ನಿರ್ಧಾರ ತೆಗೆದುಕೊಳ್ಳುವಿಕೆ, ನಿಖರತೆ, ಮರುಸ್ಥಾಪನೆ ಮತ್ತು ತರಬೇತಿ ಸೆಟ್ನಲ್ಲಿ, ಮುಂದೂಡಲ್ಪಟ್ಟ ಸೆಟ್ನಲ್ಲಿ ಮತ್ತು ಸ್ಟ್ರೀಮ್ನಿಂದ ಮಾದರಿಯಲ್ಲಿನ ಇತರ ಮೆಟ್ರಿಕ್ಗಳ ಅಂಕಿಅಂಶಗಳನ್ನು ವೈಶಿಷ್ಟ್ಯಗಳಾಗಿ ತೆಗೆದುಕೊಳ್ಳುತ್ತೇವೆ. ನಾವು ಮಾದರಿಯನ್ನು ಉತ್ಪಾದನೆಯಲ್ಲಿರುವ ಪ್ರಸ್ತುತ ಒಂದರೊಂದಿಗೆ, ಹ್ಯೂರಿಸ್ಟಿಕ್ಸ್ನೊಂದಿಗೆ ಹೋಲಿಸುತ್ತೇವೆ ಮತ್ತು ಮಾದರಿಯ ಸಂಕೀರ್ಣತೆಯನ್ನು ಗಣನೆಗೆ ತೆಗೆದುಕೊಳ್ಳುತ್ತೇವೆ. ಈ ಎಲ್ಲಾ ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ಬಳಸಿಕೊಂಡು, ಪರೀಕ್ಷಾ ಇತಿಹಾಸದ ಮೇಲೆ ತರಬೇತಿ ಪಡೆದ ವರ್ಗೀಕರಣಕಾರರು ಅಭ್ಯರ್ಥಿ ಮಾದರಿಗಳನ್ನು ಸ್ಕೋರ್ ಮಾಡುತ್ತಾರೆ, ನಮ್ಮ ಸಂದರ್ಭದಲ್ಲಿ ಇವು ಮರಗಳ ಕಾಡುಗಳಾಗಿವೆ ಮತ್ತು ಅವುಗಳಲ್ಲಿ ಯಾವುದನ್ನು A/B ಪರೀಕ್ಷೆಗೆ ಹಾಕಬೇಕೆಂದು ನಿರ್ಧರಿಸುತ್ತಾರೆ.
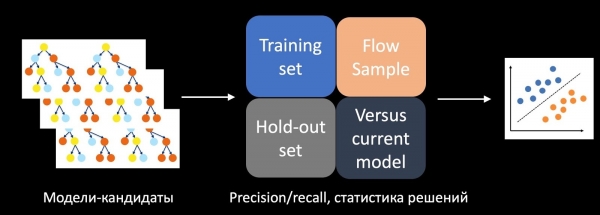
ಅನುಷ್ಠಾನದ ಸಮಯದಲ್ಲಿ, ಈ ವಿಧಾನವು ಯಶಸ್ವಿ A/B ಪರೀಕ್ಷೆಗಳ ಸಂಖ್ಯೆಯನ್ನು ಹಲವಾರು ಬಾರಿ ಹೆಚ್ಚಿಸಲು ನಮಗೆ ಅವಕಾಶ ಮಾಡಿಕೊಟ್ಟಿತು.
ಪರೀಕ್ಷೆ ಮತ್ತು ಮೇಲ್ವಿಚಾರಣೆ
ವಿಚಿತ್ರವೆಂದರೆ, ಪರೀಕ್ಷೆ ಮತ್ತು ಮೇಲ್ವಿಚಾರಣೆ ನಮ್ಮ ಆರೋಗ್ಯಕ್ಕೆ ಹಾನಿ ಮಾಡುವುದಿಲ್ಲ, ಬದಲಾಗಿ, ಅವು ಅದನ್ನು ಸುಧಾರಿಸುತ್ತವೆ ಮತ್ತು ಅನಗತ್ಯ ಒತ್ತಡವನ್ನು ನಿವಾರಿಸುತ್ತವೆ. ಪರೀಕ್ಷೆಯು ವೈಫಲ್ಯವನ್ನು ತಡೆಯಲು ನಿಮಗೆ ಅನುಮತಿಸುತ್ತದೆ ಮತ್ತು ಬಳಕೆದಾರರ ಮೇಲಿನ ಪರಿಣಾಮವನ್ನು ಕಡಿಮೆ ಮಾಡಲು ಮೇಲ್ವಿಚಾರಣೆಯು ಅದನ್ನು ಸಮಯಕ್ಕೆ ಪತ್ತೆಹಚ್ಚಲು ನಿಮಗೆ ಅನುಮತಿಸುತ್ತದೆ.
ಬೇಗ ಅಥವಾ ನಂತರ ನಿಮ್ಮ ಸಿಸ್ಟಮ್ ಯಾವಾಗಲೂ ತಪ್ಪುಗಳನ್ನು ಮಾಡುತ್ತದೆ ಎಂಬುದನ್ನು ಅರ್ಥಮಾಡಿಕೊಳ್ಳುವುದು ಬಹಳ ಮುಖ್ಯ - ಇದು ಯಾವುದೇ ಸಾಫ್ಟ್ವೇರ್ನ ಅಭಿವೃದ್ಧಿ ಚಕ್ರದಿಂದಾಗಿ. ಸಿಸ್ಟಮ್ ಅಭಿವೃದ್ಧಿಯ ಆರಂಭದಲ್ಲಿ ಎಲ್ಲವೂ ನೆಲೆಗೊಳ್ಳುವವರೆಗೆ ಮತ್ತು ನಾವೀನ್ಯತೆಗಳ ಮುಖ್ಯ ಹಂತವು ಪೂರ್ಣಗೊಳ್ಳುವವರೆಗೆ ಯಾವಾಗಲೂ ಅನೇಕ ದೋಷಗಳು ಇರುತ್ತವೆ. ಆದರೆ ಕಾಲಾನಂತರದಲ್ಲಿ, ಎಂಟ್ರೊಪಿ ಅದರ ಹಾನಿಯನ್ನುಂಟುಮಾಡುತ್ತದೆ ಮತ್ತು ದೋಷಗಳು ಮತ್ತೆ ಕಾಣಿಸಿಕೊಳ್ಳುತ್ತವೆ - ಸುತ್ತಮುತ್ತಲಿನ ಘಟಕಗಳ ಅವನತಿ ಮತ್ತು ಡೇಟಾದಲ್ಲಿನ ಬದಲಾವಣೆಗಳಿಂದಾಗಿ, ನಾನು ಆರಂಭದಲ್ಲಿ ಉಲ್ಲೇಖಿಸಿದ್ದೇನೆ.
ಯಾವುದೇ ಯಂತ್ರ ಕಲಿಕಾ ವ್ಯವಸ್ಥೆಯನ್ನು ಅದರ ಜೀವನ ಚಕ್ರದ ಉದ್ದಕ್ಕೂ ಅದರ ಲಾಭದ ದೃಷ್ಟಿಯಿಂದ ಪರಿಗಣಿಸಬೇಕು ಎಂಬುದನ್ನು ಇಲ್ಲಿ ನಾನು ಗಮನಿಸಲು ಬಯಸುತ್ತೇನೆ. ಕೆಳಗಿನ ಗ್ರಾಫ್ ಅಪರೂಪದ ರೀತಿಯ ಸ್ಪ್ಯಾಮ್ ಅನ್ನು ಹಿಡಿಯಲು ಕಾರ್ಯನಿರ್ವಹಿಸುವ ವ್ಯವಸ್ಥೆಯ ಉದಾಹರಣೆಯನ್ನು ತೋರಿಸುತ್ತದೆ (ಗ್ರಾಫ್ನಲ್ಲಿನ ರೇಖೆಯು ಶೂನ್ಯದ ಸುತ್ತಲೂ ಇದೆ). ಒಮ್ಮೆ, ತಪ್ಪಾಗಿ ಕ್ಯಾಶ್ ಮಾಡಲಾದ ವೈಶಿಷ್ಟ್ಯದಿಂದಾಗಿ, ಅದು ಹುಚ್ಚನಂತೆ ಹೋಯಿತು. ಅದೃಷ್ಟವಶಾತ್, ಅಸಹಜ ಪ್ರಚೋದನೆಗೆ ಯಾವುದೇ ಮೇಲ್ವಿಚಾರಣೆ ಇರಲಿಲ್ಲ, ಇದರ ಪರಿಣಾಮವಾಗಿ ವ್ಯವಸ್ಥೆಯು ನಿರ್ಧಾರ ತೆಗೆದುಕೊಳ್ಳುವ ಮಿತಿಯಲ್ಲಿ ಸ್ಪ್ಯಾಮ್ ಫೋಲ್ಡರ್ಗೆ ಅಕ್ಷರಗಳನ್ನು ದೊಡ್ಡ ಪ್ರಮಾಣದಲ್ಲಿ ಉಳಿಸಲು ಪ್ರಾರಂಭಿಸಿತು. ಪರಿಣಾಮಗಳ ತಿದ್ದುಪಡಿಯ ಹೊರತಾಗಿಯೂ, ವ್ಯವಸ್ಥೆಯು ಈಗಾಗಲೇ ಹಲವು ತಪ್ಪುಗಳನ್ನು ಮಾಡಿದೆ, ಅದು ಐದು ವರ್ಷಗಳಲ್ಲಿ ಸ್ವತಃ ಪಾವತಿಸುವುದಿಲ್ಲ. ಮತ್ತು ಇದು ಮಾದರಿಯ ಜೀವನ ಚಕ್ರದ ವಿಷಯದಲ್ಲಿ ಸಂಪೂರ್ಣ ವೈಫಲ್ಯವಾಗಿದೆ.
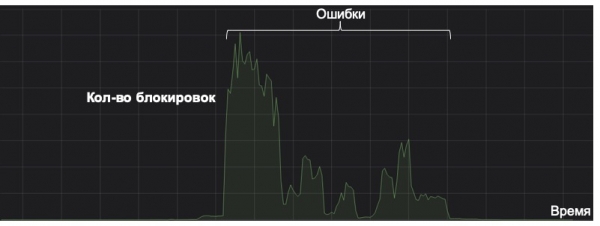
ಆದ್ದರಿಂದ, ಮೇಲ್ವಿಚಾರಣೆಯಂತಹ ಸರಳ ವಿಷಯವು ಮಾದರಿಯ ಜೀವನದಲ್ಲಿ ಪ್ರಮುಖವಾಗಬಹುದು. ಪ್ರಮಾಣಿತ ಮತ್ತು ಸ್ಪಷ್ಟ ಮೆಟ್ರಿಕ್ಗಳ ಜೊತೆಗೆ, ಮಾದರಿಯ ಪ್ರತಿಕ್ರಿಯೆಗಳು ಮತ್ತು ದರಗಳ ವಿತರಣೆಯನ್ನು ನಾವು ಪರಿಗಣಿಸುತ್ತೇವೆ, ಜೊತೆಗೆ ಪ್ರಮುಖ ವೈಶಿಷ್ಟ್ಯಗಳ ಮೌಲ್ಯಗಳ ವಿತರಣೆಯನ್ನು ಸಹ ಪರಿಗಣಿಸುತ್ತೇವೆ. KL ಡೈವರ್ಜೆನ್ಸ್ ಬಳಸಿ, ನಾವು ಪ್ರಸ್ತುತ ವಿತರಣೆಯನ್ನು ಐತಿಹಾಸಿಕ ಒಂದರೊಂದಿಗೆ ಅಥವಾ A/B ಪರೀಕ್ಷೆಯಲ್ಲಿನ ಮೌಲ್ಯಗಳನ್ನು ಉಳಿದ ಹರಿವಿನೊಂದಿಗೆ ಹೋಲಿಸಬಹುದು, ಇದು ಮಾದರಿಯಲ್ಲಿನ ವೈಪರೀತ್ಯಗಳನ್ನು ಗಮನಿಸಲು ಮತ್ತು ಸಮಯದಲ್ಲಿನ ಬದಲಾವಣೆಗಳನ್ನು ಹಿಂದಕ್ಕೆ ತರಲು ನಮಗೆ ಅನುವು ಮಾಡಿಕೊಡುತ್ತದೆ.
ಹೆಚ್ಚಿನ ಸಂದರ್ಭಗಳಲ್ಲಿ, ನಾವು ಭವಿಷ್ಯದಲ್ಲಿ ಮೇಲ್ವಿಚಾರಣೆಗಾಗಿ ಬಳಸುವ ಸರಳ ಹ್ಯೂರಿಸ್ಟಿಕ್ಸ್ ಅಥವಾ ಮಾದರಿಗಳನ್ನು ಬಳಸಿಕೊಂಡು ನಮ್ಮ ಮೊದಲ ಆವೃತ್ತಿಯ ವ್ಯವಸ್ಥೆಗಳನ್ನು ಪ್ರಾರಂಭಿಸುತ್ತೇವೆ. ಉದಾಹರಣೆಗೆ, ನಿರ್ದಿಷ್ಟ ಆನ್ಲೈನ್ ಸ್ಟೋರ್ಗಳಿಗೆ ನಿಯಮಿತ ಅಭಿವ್ಯಕ್ತಿಗಳಿಗೆ ಹೋಲಿಸಿದರೆ ನಾವು NER ಮಾದರಿಯನ್ನು ಮೇಲ್ವಿಚಾರಣೆ ಮಾಡುತ್ತೇವೆ ಮತ್ತು ಅವುಗಳಿಗೆ ಹೋಲಿಸಿದರೆ ವರ್ಗೀಕರಣದ ಕವರೇಜ್ ಕಡಿಮೆಯಾದರೆ, ನಾವು ಕಾರಣಗಳನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡುತ್ತೇವೆ. ಹ್ಯೂರಿಸ್ಟಿಕ್ಸ್ನ ಮತ್ತೊಂದು ಉಪಯುಕ್ತ ಅನ್ವಯಿಕೆ!
ಫಲಿತಾಂಶಗಳು
ಲೇಖನದ ಪ್ರಮುಖ ವಿಚಾರಗಳನ್ನು ಮತ್ತೊಮ್ಮೆ ಪರಿಶೀಲಿಸೋಣ.
- ಫಿಬ್ಡೆಕ್. ನಾವು ಯಾವಾಗಲೂ ಬಳಕೆದಾರರ ಬಗ್ಗೆ ಯೋಚಿಸುತ್ತೇವೆ: ಅವರು ನಮ್ಮ ತಪ್ಪುಗಳೊಂದಿಗೆ ಹೇಗೆ ಬದುಕುತ್ತಾರೆ, ಅವುಗಳನ್ನು ಹೇಗೆ ವರದಿ ಮಾಡಲು ಸಾಧ್ಯವಾಗುತ್ತದೆ. ತರಬೇತಿ ಮಾದರಿಗಳಿಗೆ ಬಳಕೆದಾರರು ಶುದ್ಧ ಪ್ರತಿಕ್ರಿಯೆಯ ಮೂಲವಲ್ಲ ಎಂಬುದನ್ನು ನಾವು ಮರೆಯುವುದಿಲ್ಲ ಮತ್ತು ಸಹಾಯಕ ML ವ್ಯವಸ್ಥೆಗಳ ಸಹಾಯದಿಂದ ಅದನ್ನು ಸ್ವಚ್ಛಗೊಳಿಸಬೇಕು. ಬಳಕೆದಾರರಿಂದ ಸಿಗ್ನಲ್ ಸಂಗ್ರಹಿಸಲು ಯಾವುದೇ ಮಾರ್ಗವಿಲ್ಲದಿದ್ದರೆ, ನಾವು ಪ್ರತಿಕ್ರಿಯೆಯ ಪರ್ಯಾಯ ಮೂಲಗಳನ್ನು ಹುಡುಕುತ್ತೇವೆ, ಉದಾಹರಣೆಗೆ, ಸಂಬಂಧಿತ ವ್ಯವಸ್ಥೆಗಳು.
- ಹೆಚ್ಚಿನ ತರಬೇತಿ. ಇಲ್ಲಿ ಮುಖ್ಯ ವಿಷಯವೆಂದರೆ ನಿರಂತರತೆ, ಆದ್ದರಿಂದ ನಾವು ಪ್ರಸ್ತುತ ಉತ್ಪಾದನಾ ಮಾದರಿಯನ್ನು ಅವಲಂಬಿಸಿದ್ದೇವೆ. ಹಾರ್ಮೋನಿಕ್ ಕ್ರಮಬದ್ಧಗೊಳಿಸುವಿಕೆ ಮತ್ತು ಇದೇ ರೀತಿಯ ತಂತ್ರಗಳಿಂದಾಗಿ ಹೊಸ ಮಾದರಿಗಳು ಹಿಂದಿನದಕ್ಕಿಂತ ಹೆಚ್ಚು ಭಿನ್ನವಾಗಿರದಂತೆ ನಾವು ತರಬೇತಿ ನೀಡುತ್ತೇವೆ.
- ನಿಯೋಜಿಸಿ. ಮೆಟ್ರಿಕ್ಗಳ ಮೂಲಕ ಸ್ವಯಂ ನಿಯೋಜನೆಯು ಮಾದರಿಗಳನ್ನು ಕಾರ್ಯಗತಗೊಳಿಸುವ ಸಮಯವನ್ನು ಬಹಳವಾಗಿ ಕಡಿಮೆ ಮಾಡುತ್ತದೆ. ಅಂಕಿಅಂಶಗಳನ್ನು ಮೇಲ್ವಿಚಾರಣೆ ಮಾಡುವುದು ಮತ್ತು ನಿರ್ಧಾರ ತೆಗೆದುಕೊಳ್ಳುವಿಕೆಯ ವಿತರಣೆ, ಬಳಕೆದಾರರು ಬೀಳುವ ಸಂಖ್ಯೆಯು ನಿಮ್ಮ ಶಾಂತಿಯುತ ನಿದ್ರೆ ಮತ್ತು ಉತ್ಪಾದಕ ವಾರಾಂತ್ಯಗಳಿಗೆ ಅತ್ಯಗತ್ಯ.
ಸರಿ, ನೀವು ಓದುವುದು ನಿಮ್ಮ ML ವ್ಯವಸ್ಥೆಗಳನ್ನು ವೇಗವಾಗಿ ಸುಧಾರಿಸಲು, ಅವುಗಳನ್ನು ವೇಗವಾಗಿ ಮಾರುಕಟ್ಟೆಗೆ ತರಲು ಮತ್ತು ಅವುಗಳನ್ನು ಹೆಚ್ಚು ವಿಶ್ವಾಸಾರ್ಹವಾಗಿಸಲು ಸಹಾಯ ಮಾಡುತ್ತದೆ, ಕೆಲಸದಿಂದ ಒತ್ತಡದ ಪ್ರಮಾಣವನ್ನು ಕಡಿಮೆ ಮಾಡುತ್ತದೆ ಎಂದು ನಾನು ಭಾವಿಸುತ್ತೇನೆ.
ಮೂಲ: www.habr.com
