


Badoo ನಲ್ಲಿ, ನಾವು ನಿರಂತರವಾಗಿ ಹೊಸ ತಂತ್ರಜ್ಞಾನಗಳನ್ನು ಮೇಲ್ವಿಚಾರಣೆ ಮಾಡುತ್ತೇವೆ ಮತ್ತು ನಮ್ಮ ಸಿಸ್ಟಂನಲ್ಲಿ ಬಳಸಲು ಯೋಗ್ಯವಾಗಿದೆಯೇ ಎಂದು ಮೌಲ್ಯಮಾಪನ ಮಾಡುತ್ತೇವೆ. ನಾವು ಈ ಅಧ್ಯಯನಗಳಲ್ಲಿ ಒಂದನ್ನು ಸಮುದಾಯದೊಂದಿಗೆ ಹಂಚಿಕೊಳ್ಳಲು ಬಯಸುತ್ತೇವೆ. ಇದು ಲಾಗ್ ಒಟ್ಟುಗೂಡಿಸುವ ವ್ಯವಸ್ಥೆಯಾದ ಲೋಕಿಗೆ ಸಮರ್ಪಿಸಲಾಗಿದೆ.
ಲಾಗ್ಗಳನ್ನು ಸಂಗ್ರಹಿಸಲು ಮತ್ತು ವೀಕ್ಷಿಸಲು ಲೋಕಿ ಒಂದು ಪರಿಹಾರವಾಗಿದೆ, ಮತ್ತು ಈ ಸ್ಟಾಕ್ ಅವುಗಳನ್ನು ವಿಶ್ಲೇಷಿಸಲು ಮತ್ತು ಪ್ರಮೀತಿಯಸ್ಗೆ ಡೇಟಾವನ್ನು ಕಳುಹಿಸಲು ಹೊಂದಿಕೊಳ್ಳುವ ವ್ಯವಸ್ಥೆಯನ್ನು ಸಹ ಒದಗಿಸುತ್ತದೆ. ಮೇ ತಿಂಗಳಲ್ಲಿ, ಮತ್ತೊಂದು ನವೀಕರಣವನ್ನು ಬಿಡುಗಡೆ ಮಾಡಲಾಯಿತು, ಇದನ್ನು ರಚನೆಕಾರರು ಸಕ್ರಿಯವಾಗಿ ಪ್ರಚಾರ ಮಾಡುತ್ತಾರೆ. ಲೋಕಿ ಏನು ಮಾಡಬಹುದು, ಅದು ಯಾವ ಸಾಮರ್ಥ್ಯಗಳನ್ನು ಒದಗಿಸುತ್ತದೆ ಮತ್ತು ನಾವು ಈಗ ಬಳಸುವ ಸ್ಟಾಕ್ನ ELK ಗೆ ಪರ್ಯಾಯವಾಗಿ ಎಷ್ಟು ಮಟ್ಟಿಗೆ ಕಾರ್ಯನಿರ್ವಹಿಸಬಹುದು ಎಂಬುದರ ಕುರಿತು ನಾವು ಆಸಕ್ತಿ ಹೊಂದಿದ್ದೇವೆ.
ಲೋಕಿ ಎಂದರೇನು
ಗ್ರಾಫನಾ ಲೋಕಿ ಎನ್ನುವುದು ಲಾಗ್ಗಳೊಂದಿಗೆ ಕೆಲಸ ಮಾಡಲು ಸಂಪೂರ್ಣ ಸಿಸ್ಟಮ್ಗಾಗಿ ಘಟಕಗಳ ಒಂದು ಗುಂಪಾಗಿದೆ. ಇತರ ರೀತಿಯ ವ್ಯವಸ್ಥೆಗಳಿಗಿಂತ ಭಿನ್ನವಾಗಿ, ಲೋಕಿ ಕೇವಲ ಲಾಗ್ ಮೆಟಾಡೇಟಾವನ್ನು ಸೂಚಿಸುವ ಕಲ್ಪನೆಯನ್ನು ಆಧರಿಸಿದೆ - ಲೇಬಲ್ಗಳು (ಪ್ರಮೀತಿಯಸ್ನಲ್ಲಿರುವಂತೆಯೇ), ಮತ್ತು ಲಾಗ್ಗಳನ್ನು ಪ್ರತ್ಯೇಕ ಭಾಗಗಳಾಗಿ ಸಂಕುಚಿತಗೊಳಿಸುತ್ತದೆ.
,
ಲೋಕಿಯೊಂದಿಗೆ ನೀವು ಏನು ಮಾಡಬಹುದು ಎಂಬುದನ್ನು ನಾವು ತಿಳಿದುಕೊಳ್ಳುವ ಮೊದಲು, "ಮೆಟಾಡೇಟಾವನ್ನು ಮಾತ್ರ ಸೂಚಿಕೆ ಮಾಡುವ ಕಲ್ಪನೆ" ಯಿಂದ ನಾವು ಏನನ್ನು ಅರ್ಥೈಸುತ್ತೇವೆ ಎಂಬುದನ್ನು ಸ್ಪಷ್ಟಪಡಿಸಲು ನಾನು ಬಯಸುತ್ತೇನೆ. nginx ಲಾಗ್ನಿಂದ ಒಂದು ಸಾಲಿನ ಉದಾಹರಣೆಯನ್ನು ಬಳಸಿಕೊಂಡು Elasticsearch ನಂತಹ ಸಾಂಪ್ರದಾಯಿಕ ಪರಿಹಾರಗಳಲ್ಲಿ ಲೋಕಿ ವಿಧಾನ ಮತ್ತು ಇಂಡೆಕ್ಸಿಂಗ್ ವಿಧಾನವನ್ನು ಹೋಲಿಸೋಣ:
172.19.0.4 - - [01/Jun/2020:12:05:03 +0000] "GET /purchase?user_id=75146478&item_id=34234 HTTP/1.1" 500 8102 "-" "Stub_Bot/3.0" "0.001"ಸಾಂಪ್ರದಾಯಿಕ ವ್ಯವಸ್ಥೆಗಳು ಹೆಚ್ಚಿನ ಸಂಖ್ಯೆಯ ಅನನ್ಯ user_id ಮತ್ತು item_id ಮೌಲ್ಯಗಳನ್ನು ಹೊಂದಿರುವ ಕ್ಷೇತ್ರಗಳನ್ನು ಒಳಗೊಂಡಂತೆ ಸಂಪೂರ್ಣ ಸಾಲನ್ನು ಪಾರ್ಸ್ ಮಾಡುತ್ತದೆ ಮತ್ತು ಎಲ್ಲವನ್ನೂ ದೊಡ್ಡ ಸೂಚಿಕೆಗಳಲ್ಲಿ ಸಂಗ್ರಹಿಸುತ್ತದೆ. ಈ ವಿಧಾನದ ಪ್ರಯೋಜನವೆಂದರೆ ನೀವು ಸಂಕೀರ್ಣ ಪ್ರಶ್ನೆಗಳನ್ನು ತ್ವರಿತವಾಗಿ ಚಲಾಯಿಸಬಹುದು, ಏಕೆಂದರೆ ಬಹುತೇಕ ಎಲ್ಲಾ ಡೇಟಾವು ಸೂಚ್ಯಂಕದಲ್ಲಿದೆ. ಆದರೆ ಇದು ವೆಚ್ಚದಲ್ಲಿ ಬರುತ್ತದೆ ಏಕೆಂದರೆ ಸೂಚ್ಯಂಕವು ದೊಡ್ಡದಾಗುತ್ತದೆ, ಇದು ಮೆಮೊರಿ ಅಗತ್ಯತೆಗಳಾಗಿ ಅನುವಾದಿಸುತ್ತದೆ. ಪರಿಣಾಮವಾಗಿ, ಪೂರ್ಣ-ಪಠ್ಯ ಲಾಗ್ ಸೂಚ್ಯಂಕವು ಲಾಗ್ಗಳಿಗೆ ಗಾತ್ರದಲ್ಲಿ ಹೋಲಿಸಬಹುದಾಗಿದೆ. ಅದರ ಮೂಲಕ ತ್ವರಿತವಾಗಿ ಹುಡುಕಲು, ಸೂಚ್ಯಂಕವನ್ನು ಮೆಮೊರಿಗೆ ಲೋಡ್ ಮಾಡಬೇಕು. ಮತ್ತು ಹೆಚ್ಚು ಲಾಗ್ಗಳು, ಸೂಚ್ಯಂಕವು ವೇಗವಾಗಿ ಬೆಳೆಯುತ್ತದೆ ಮತ್ತು ಅದು ಹೆಚ್ಚು ಮೆಮೊರಿಯನ್ನು ಬಳಸುತ್ತದೆ.
ಲೋಕಿ ವಿಧಾನವು ಸ್ಟ್ರಿಂಗ್ನಿಂದ ಅಗತ್ಯವಾದ ಡೇಟಾವನ್ನು ಮಾತ್ರ ಹೊರತೆಗೆಯಬೇಕು, ಅದರ ಮೌಲ್ಯಗಳ ಸಂಖ್ಯೆ ಚಿಕ್ಕದಾಗಿದೆ. ಈ ರೀತಿಯಾಗಿ ನಾವು ಒಂದು ಸಣ್ಣ ಸೂಚಿಯನ್ನು ಪಡೆಯುತ್ತೇವೆ ಮತ್ತು ಸಮಯ ಮತ್ತು ಸೂಚ್ಯಂಕ ಕ್ಷೇತ್ರಗಳ ಮೂಲಕ ಅದನ್ನು ಫಿಲ್ಟರ್ ಮಾಡುವ ಮೂಲಕ ಡೇಟಾವನ್ನು ಹುಡುಕಬಹುದು, ಮತ್ತು ನಂತರ ಸಾಮಾನ್ಯ ಅಭಿವ್ಯಕ್ತಿಗಳು ಅಥವಾ ಸಬ್ಸ್ಟ್ರಿಂಗ್ ಹುಡುಕಾಟದೊಂದಿಗೆ ಉಳಿದವನ್ನು ಸ್ಕ್ಯಾನ್ ಮಾಡಬಹುದು. ಪ್ರಕ್ರಿಯೆಯು ವೇಗವಾದಂತೆ ತೋರುತ್ತಿಲ್ಲ, ಆದರೆ ಲೋಕಿ ವಿನಂತಿಯನ್ನು ಹಲವಾರು ಭಾಗಗಳಾಗಿ ವಿಭಜಿಸುತ್ತದೆ ಮತ್ತು ಅವುಗಳನ್ನು ಸಮಾನಾಂತರವಾಗಿ ಕಾರ್ಯಗತಗೊಳಿಸುತ್ತದೆ, ಕಡಿಮೆ ಸಮಯದಲ್ಲಿ ಹೆಚ್ಚಿನ ಪ್ರಮಾಣದ ಡೇಟಾವನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುತ್ತದೆ. ಅವುಗಳಲ್ಲಿನ ಚೂರುಗಳು ಮತ್ತು ಸಮಾನಾಂತರ ವಿನಂತಿಗಳ ಸಂಖ್ಯೆಯನ್ನು ಕಾನ್ಫಿಗರ್ ಮಾಡಬಹುದು; ಹೀಗಾಗಿ, ಪ್ರತಿ ಯುನಿಟ್ ಸಮಯದವರೆಗೆ ಪ್ರಕ್ರಿಯೆಗೊಳಿಸಬಹುದಾದ ಡೇಟಾದ ಪ್ರಮಾಣವು ಒದಗಿಸಿದ ಸಂಪನ್ಮೂಲಗಳ ಪ್ರಮಾಣವನ್ನು ರೇಖಾತ್ಮಕವಾಗಿ ಅವಲಂಬಿಸಿರುತ್ತದೆ.
ದೊಡ್ಡದಾದ, ವೇಗದ ಸೂಚ್ಯಂಕ ಮತ್ತು ಸಣ್ಣ, ಸಮಾನಾಂತರವಾದ ಬ್ರೂಟ್-ಫೋರ್ಸ್ ಇಂಡೆಕ್ಸ್ ನಡುವಿನ ಈ ವಹಿವಾಟು ವ್ಯವಸ್ಥೆಯ ವೆಚ್ಚವನ್ನು ನಿಯಂತ್ರಿಸಲು ಲೋಕಿಗೆ ಅನುಮತಿಸುತ್ತದೆ. ಅಗತ್ಯಗಳಿಗೆ ಅನುಗುಣವಾಗಿ ಇದನ್ನು ಸುಲಭವಾಗಿ ಕಾನ್ಫಿಗರ್ ಮಾಡಬಹುದು ಮತ್ತು ವಿಸ್ತರಿಸಬಹುದು.
ಲೋಕಿ ಸ್ಟಾಕ್ ಮೂರು ಘಟಕಗಳನ್ನು ಒಳಗೊಂಡಿದೆ: ಪ್ರಾಮ್ಟೇಲ್, ಲೋಕಿ, ಗ್ರಾಫನಾ. Promtail ಲಾಗ್ಗಳನ್ನು ಸಂಗ್ರಹಿಸುತ್ತದೆ, ಅವುಗಳನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸುತ್ತದೆ ಮತ್ತು ಅವುಗಳನ್ನು ಲೋಕಿಗೆ ಕಳುಹಿಸುತ್ತದೆ. ಲೋಕಿ ಅವರನ್ನು ಇಟ್ಟುಕೊಳ್ಳುತ್ತಾನೆ. ಮತ್ತು ಗ್ರಾಫನಾ ಲೋಕಿಯಿಂದ ಡೇಟಾವನ್ನು ವಿನಂತಿಸಬಹುದು ಮತ್ತು ಅದನ್ನು ಪ್ರದರ್ಶಿಸಬಹುದು. ಸಾಮಾನ್ಯವಾಗಿ, ಲಾಗ್ಗಳನ್ನು ಸಂಗ್ರಹಿಸಲು ಮತ್ತು ಅವುಗಳ ಮೂಲಕ ಹುಡುಕಲು ಲೋಕಿ ಅನ್ನು ಬಳಸಬಹುದು. ಪ್ರಮೀತಿಯಸ್ ಮಾರ್ಗವನ್ನು ಬಳಸಿಕೊಂಡು ಒಳಬರುವ ಡೇಟಾವನ್ನು ಪ್ರಕ್ರಿಯೆಗೊಳಿಸಲು ಮತ್ತು ವಿಶ್ಲೇಷಿಸಲು ಸಂಪೂರ್ಣ ಸ್ಟಾಕ್ ಉತ್ತಮ ಅವಕಾಶಗಳನ್ನು ಒದಗಿಸುತ್ತದೆ.
ಅನುಸ್ಥಾಪನಾ ಪ್ರಕ್ರಿಯೆಯ ವಿವರಣೆಯನ್ನು ಕಾಣಬಹುದು .
ಲಾಗ್ ಹುಡುಕಾಟ
ನೀವು ವಿಶೇಷ ಗ್ರಾಫನಾ ಇಂಟರ್ಫೇಸ್ - ಎಕ್ಸ್ಪ್ಲೋರರ್ನಲ್ಲಿ ಲಾಗ್ಗಳನ್ನು ಹುಡುಕಬಹುದು. ಪ್ರಶ್ನೆಗಳು LogQL ಭಾಷೆಯನ್ನು ಬಳಸುತ್ತವೆ, ಇದು Prometheus ನಲ್ಲಿ ಬಳಸಿದ PromQL ಗೆ ಹೋಲುತ್ತದೆ. ತಾತ್ವಿಕವಾಗಿ, ಇದನ್ನು ವಿತರಿಸಿದ grep ಎಂದು ಪರಿಗಣಿಸಬಹುದು.
ಹುಡುಕಾಟ ಇಂಟರ್ಫೇಸ್ ಈ ರೀತಿ ಕಾಣುತ್ತದೆ:
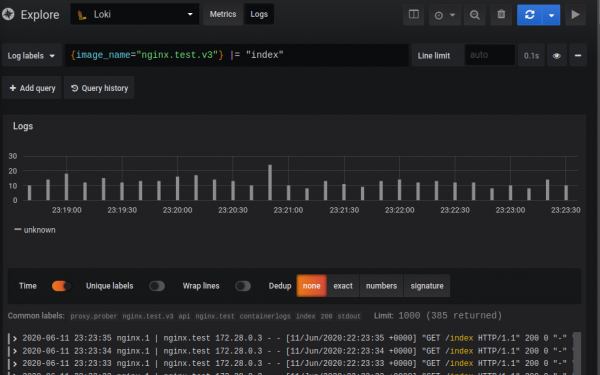
ವಿನಂತಿಯು ಎರಡು ಭಾಗಗಳನ್ನು ಒಳಗೊಂಡಿದೆ: ಸೆಲೆಕ್ಟರ್ ಮತ್ತು ಫಿಲ್ಟರ್. ಸೆಲೆಕ್ಟರ್ ಎನ್ನುವುದು ಲಾಗ್ಗಳಿಗೆ ನಿಯೋಜಿಸಲಾದ ಇಂಡೆಕ್ಸ್ಡ್ ಮೆಟಾಡೇಟಾ (ಲೇಬಲ್ಗಳು) ಬಳಸಿಕೊಂಡು ಹುಡುಕಾಟವಾಗಿದೆ ಮತ್ತು ಫಿಲ್ಟರ್ ಎಂಬುದು ಸೆಲೆಕ್ಟರ್ನಿಂದ ವ್ಯಾಖ್ಯಾನಿಸಲಾದ ದಾಖಲೆಗಳನ್ನು ಫಿಲ್ಟರ್ ಮಾಡುವ ಹುಡುಕಾಟ ಸ್ಟ್ರಿಂಗ್ ಅಥವಾ ರಿಜೆಕ್ಸ್ಪ್ ಆಗಿದೆ. ನೀಡಿರುವ ಉದಾಹರಣೆಯಲ್ಲಿ: ಕರ್ಲಿ ಬ್ರೇಸ್ಗಳಲ್ಲಿ ಸೆಲೆಕ್ಟರ್ ಇದೆ, ನಂತರ ಎಲ್ಲವೂ ಫಿಲ್ಟರ್ ಆಗಿದೆ.
{image_name="nginx.promtail.test"} |= "index"ಲೋಕಿ ಕಾರ್ಯನಿರ್ವಹಿಸುವ ವಿಧಾನದಿಂದಾಗಿ, ಸೆಲೆಕ್ಟರ್ ಇಲ್ಲದೆ ನೀವು ಪ್ರಶ್ನೆಗಳನ್ನು ಮಾಡಲು ಸಾಧ್ಯವಿಲ್ಲ, ಆದರೆ ಲೇಬಲ್ಗಳನ್ನು ನೀವು ಇಷ್ಟಪಡುವಷ್ಟು ಸಾಮಾನ್ಯಗೊಳಿಸಬಹುದು.
ಸೆಲೆಕ್ಟರ್ ಎನ್ನುವುದು ಕರ್ಲಿ ಬ್ರೇಸ್ಗಳಲ್ಲಿ ಕೀ-ಮೌಲ್ಯ ಮೌಲ್ಯವಾಗಿದೆ. ನೀವು ಆಯ್ಕೆದಾರರನ್ನು ಸಂಯೋಜಿಸಬಹುದು ಮತ್ತು ನಿರ್ವಾಹಕರು =, != ಅಥವಾ ನಿಯಮಿತ ಅಭಿವ್ಯಕ್ತಿಗಳನ್ನು ಬಳಸಿಕೊಂಡು ವಿವಿಧ ಹುಡುಕಾಟ ಪರಿಸ್ಥಿತಿಗಳನ್ನು ನಿರ್ದಿಷ್ಟಪಡಿಸಬಹುದು:
{instance=~"kafka-[23]",name!="kafka-dev"}
// Найдёт логи с лейблом instance, имеющие значение kafka-2, kafka-3, и исключит dev ಫಿಲ್ಟರ್ ಎನ್ನುವುದು ಪಠ್ಯ ಅಥವಾ regexp ಆಗಿದ್ದು ಅದು ಸೆಲೆಕ್ಟರ್ ಸ್ವೀಕರಿಸಿದ ಎಲ್ಲಾ ಡೇಟಾವನ್ನು ಫಿಲ್ಟರ್ ಮಾಡುತ್ತದೆ.
ಮೆಟ್ರಿಕ್ಸ್ ಮೋಡ್ನಲ್ಲಿ ಸ್ವೀಕರಿಸಿದ ಡೇಟಾವನ್ನು ಆಧರಿಸಿ ತಾತ್ಕಾಲಿಕ ಗ್ರಾಫ್ಗಳನ್ನು ಪಡೆಯಲು ಸಾಧ್ಯವಿದೆ. ಉದಾಹರಣೆಗೆ, nginx ಲಾಗ್ಗಳಲ್ಲಿ ಸ್ಟ್ರಿಂಗ್ ಇಂಡೆಕ್ಸ್ ಅನ್ನು ಹೊಂದಿರುವ ನಮೂದು ಎಷ್ಟು ಬಾರಿ ಕಾಣಿಸಿಕೊಳ್ಳುತ್ತದೆ ಎಂಬುದನ್ನು ನೀವು ಕಂಡುಹಿಡಿಯಬಹುದು:
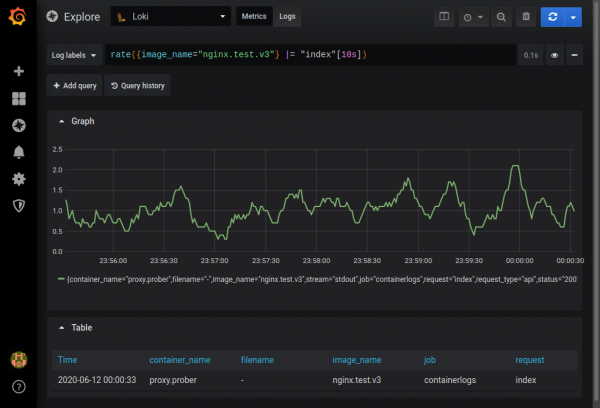
ಸಾಮರ್ಥ್ಯಗಳ ಸಂಪೂರ್ಣ ವಿವರಣೆಯನ್ನು ದಸ್ತಾವೇಜನ್ನು ಕಾಣಬಹುದು .
ಲಾಗ್ ಪಾರ್ಸಿಂಗ್
ದಾಖಲೆಗಳನ್ನು ಸಂಗ್ರಹಿಸಲು ಹಲವಾರು ಮಾರ್ಗಗಳಿವೆ:
- ಲಾಗ್ಗಳನ್ನು ಸಂಗ್ರಹಿಸಲು ಸ್ಟಾಕ್ನ ಪ್ರಮಾಣಿತ ಘಟಕವಾದ Promtail ಅನ್ನು ಬಳಸುವುದು.
- ನೇರವಾಗಿ ಡಾಕರ್ ಕಂಟೇನರ್ ಬಳಸಿ
- Fluentd ಅಥವಾ Fluent Bit ಅನ್ನು ಬಳಸಿ, ಇದು ಲೋಕಿಗೆ ಡೇಟಾವನ್ನು ಕಳುಹಿಸಬಹುದು. ಪ್ರೋಮ್ಟೈಲ್ಗಿಂತ ಭಿನ್ನವಾಗಿ, ಅವರು ಯಾವುದೇ ರೀತಿಯ ಲಾಗ್ಗೆ ಸಿದ್ಧವಾದ ಪಾರ್ಸರ್ಗಳನ್ನು ಹೊಂದಿದ್ದಾರೆ ಮತ್ತು ಮಲ್ಟಿಲೈನ್ ಲಾಗ್ಗಳನ್ನು ಸಹ ನಿರ್ವಹಿಸಬಹುದು.
ಸಾಮಾನ್ಯವಾಗಿ Promtail ಅನ್ನು ಪಾರ್ಸಿಂಗ್ ಮಾಡಲು ಬಳಸಲಾಗುತ್ತದೆ. ಇದು ಮೂರು ಕೆಲಸಗಳನ್ನು ಮಾಡುತ್ತದೆ:
- ಡೇಟಾ ಮೂಲಗಳನ್ನು ಹುಡುಕುತ್ತದೆ.
- ಅವರಿಗೆ ಲೇಬಲ್ಗಳನ್ನು ಲಗತ್ತಿಸುತ್ತದೆ.
- ಲೋಕಿಗೆ ಡೇಟಾವನ್ನು ಕಳುಹಿಸುತ್ತದೆ.
ಪ್ರಸ್ತುತ Promtail ಸ್ಥಳೀಯ ಫೈಲ್ಗಳಿಂದ ಮತ್ತು systemd ಜರ್ನಲ್ನಿಂದ ಲಾಗ್ಗಳನ್ನು ಓದಬಹುದು. ಲಾಗ್ಗಳನ್ನು ಸಂಗ್ರಹಿಸುವ ಪ್ರತಿಯೊಂದು ಯಂತ್ರದಲ್ಲಿ ಇದನ್ನು ಸ್ಥಾಪಿಸಬೇಕು.
Kubernetes ನೊಂದಿಗೆ ಏಕೀಕರಣವಿದೆ: Promtail ಸ್ವಯಂಚಾಲಿತವಾಗಿ, Kubernetes REST API ಮೂಲಕ, ಕ್ಲಸ್ಟರ್ನ ಸ್ಥಿತಿಯನ್ನು ಗುರುತಿಸುತ್ತದೆ ಮತ್ತು ನೋಡ್, ಸೇವೆ ಅಥವಾ ಪಾಡ್ನಿಂದ ಲಾಗ್ಗಳನ್ನು ಸಂಗ್ರಹಿಸುತ್ತದೆ, ಕುಬರ್ನೆಟ್ಸ್ನಿಂದ ಮೆಟಾಡೇಟಾವನ್ನು ಆಧರಿಸಿ ಲೇಬಲ್ಗಳನ್ನು ತಕ್ಷಣವೇ ಪೋಸ್ಟ್ ಮಾಡುತ್ತದೆ (ಪಾಡ್ ಹೆಸರು, ಫೈಲ್ ಹೆಸರು, ಇತ್ಯಾದಿ.) .
ಪೈಪ್ಲೈನ್ ಬಳಸಿಕೊಂಡು ಲಾಗ್ನಿಂದ ಡೇಟಾದ ಆಧಾರದ ಮೇಲೆ ನೀವು ಲೇಬಲ್ಗಳನ್ನು ಸ್ಥಗಿತಗೊಳಿಸಬಹುದು. ಪೈಪ್ಲೈನ್ ಪ್ರೋಮ್ಟೇಲ್ ನಾಲ್ಕು ರೀತಿಯ ಹಂತಗಳನ್ನು ಒಳಗೊಂಡಿರುತ್ತದೆ. ಹೆಚ್ಚಿನ ವಿವರಗಳಲ್ಲಿ , ನಾನು ತಕ್ಷಣ ಕೆಲವು ಸೂಕ್ಷ್ಮ ವ್ಯತ್ಯಾಸಗಳನ್ನು ಗಮನಿಸುತ್ತೇನೆ.
- ಪಾರ್ಸಿಂಗ್ ಹಂತಗಳು. ಇದು RegEx ಮತ್ತು JSON ಹಂತವಾಗಿದೆ. ಈ ಹಂತದಲ್ಲಿ, ನಾವು ಲಾಗ್ಗಳಿಂದ ಬೇರ್ಪಡಿಸಿದ ನಕ್ಷೆ ಎಂದು ಕರೆಯಲ್ಪಡುವ ಡೇಟಾವನ್ನು ಹೊರತೆಗೆಯುತ್ತೇವೆ. ಹೊರತೆಗೆಯಲಾದ ನಕ್ಷೆಗೆ ನಮಗೆ ಅಗತ್ಯವಿರುವ ಕ್ಷೇತ್ರಗಳನ್ನು ಸರಳವಾಗಿ ನಕಲಿಸುವ ಮೂಲಕ ಅಥವಾ ನಿಯಮಿತ ಅಭಿವ್ಯಕ್ತಿಗಳ ಮೂಲಕ (RegEx) ನಾವು JSON ನಿಂದ ಹೊರತೆಗೆಯಬಹುದು, ಅಲ್ಲಿ ಹೆಸರಿಸಲಾದ ಗುಂಪುಗಳನ್ನು ಬೇರ್ಪಡಿಸಿದ ನಕ್ಷೆಗೆ "ಮ್ಯಾಪ್" ಮಾಡಲಾಗುತ್ತದೆ. ಹೊರತೆಗೆಯಲಾದ ನಕ್ಷೆಯು ಕೀ-ಮೌಲ್ಯದ ಅಂಗಡಿಯಾಗಿದೆ, ಅಲ್ಲಿ ಕೀ ಎಂಬುದು ಕ್ಷೇತ್ರದ ಹೆಸರಾಗಿದೆ ಮತ್ತು ಮೌಲ್ಯವು ಲಾಗ್ಗಳಿಂದ ಅದರ ಮೌಲ್ಯವಾಗಿದೆ.
- ರೂಪಾಂತರ ಹಂತಗಳು. ಈ ಹಂತವು ಎರಡು ಆಯ್ಕೆಗಳನ್ನು ಹೊಂದಿದೆ: ರೂಪಾಂತರ, ಅಲ್ಲಿ ನಾವು ರೂಪಾಂತರ ನಿಯಮಗಳನ್ನು ಹೊಂದಿಸುತ್ತೇವೆ ಮತ್ತು ಮೂಲ - ಹೊರತೆಗೆಯಲಾದ ನಕ್ಷೆಯಿಂದ ರೂಪಾಂತರಕ್ಕಾಗಿ ಡೇಟಾ ಮೂಲ. ಹೊರತೆಗೆಯಲಾದ ನಕ್ಷೆಯಲ್ಲಿ ಅಂತಹ ಯಾವುದೇ ಕ್ಷೇತ್ರವಿಲ್ಲದಿದ್ದರೆ, ಅದನ್ನು ರಚಿಸಲಾಗುತ್ತದೆ. ಈ ರೀತಿಯಾಗಿ ಹೊರತೆಗೆಯಲಾದ ನಕ್ಷೆಯನ್ನು ಆಧರಿಸಿರದ ಲೇಬಲ್ಗಳನ್ನು ರಚಿಸಲು ಸಾಧ್ಯವಿದೆ. ಈ ಹಂತದಲ್ಲಿ ನಾವು ಹೊರತೆಗೆಯಲಾದ ನಕ್ಷೆಯಲ್ಲಿನ ಡೇಟಾವನ್ನು ಸಾಕಷ್ಟು ಶಕ್ತಿಯುತವಾಗಿ ಬಳಸಿಕೊಂಡು ಕುಶಲತೆಯಿಂದ ನಿರ್ವಹಿಸಬಹುದು . ಹೆಚ್ಚುವರಿಯಾಗಿ, ಬೇರ್ಪಡಿಸಿದ ನಕ್ಷೆಯನ್ನು ಪಾರ್ಸಿಂಗ್ ಸಮಯದಲ್ಲಿ ಸಂಪೂರ್ಣವಾಗಿ ಲೋಡ್ ಮಾಡಲಾಗಿದೆ ಎಂದು ನಾವು ನೆನಪಿನಲ್ಲಿಟ್ಟುಕೊಳ್ಳಬೇಕು, ಇದು ಸಾಧ್ಯವಾಗಿಸುತ್ತದೆ, ಉದಾಹರಣೆಗೆ, ಅದರಲ್ಲಿರುವ ಮೌಲ್ಯವನ್ನು ಪರಿಶೀಲಿಸಲು: “{{if .tag}ಟ್ಯಾಗ್ ಮೌಲ್ಯ ಅಸ್ತಿತ್ವದಲ್ಲಿದೆ{end}}”. ಟೆಂಪ್ಲೇಟ್ ಷರತ್ತುಗಳು, ಲೂಪ್ಗಳು ಮತ್ತು ರಿಪ್ಲೇಸ್ ಮತ್ತು ಟ್ರಿಮ್ನಂತಹ ಕೆಲವು ಸ್ಟ್ರಿಂಗ್ ಕಾರ್ಯಗಳನ್ನು ಬೆಂಬಲಿಸುತ್ತದೆ.
- ಕ್ರಿಯೆಯ ಹಂತಗಳು. ಈ ಹಂತದಲ್ಲಿ ನೀವು ಹೊರತೆಗೆದ ವಿಷಯದೊಂದಿಗೆ ಏನನ್ನಾದರೂ ಮಾಡಬಹುದು:
- ಹೊರತೆಗೆದ ಡೇಟಾದಿಂದ ಲೇಬಲ್ ಅನ್ನು ರಚಿಸಿ, ಅದನ್ನು ಲೋಕಿ ಸೂಚಿಕೆ ಮಾಡುತ್ತಾರೆ.
- ಲಾಗ್ನಿಂದ ಈವೆಂಟ್ ಸಮಯವನ್ನು ಬದಲಾಯಿಸಿ ಅಥವಾ ಹೊಂದಿಸಿ.
- ಲೋಕಿಗೆ ಹೋಗುವ ಡೇಟಾವನ್ನು (ಲಾಗ್ ಪಠ್ಯ) ಬದಲಾಯಿಸಿ.
- ಮೆಟ್ರಿಕ್ಗಳನ್ನು ರಚಿಸಿ.
- ಫಿಲ್ಟರಿಂಗ್ ಹಂತಗಳು. ಹೊಂದಾಣಿಕೆಯ ಹಂತ, ಅಲ್ಲಿ ನಾವು /dev/null ಮಾಡಬೇಕಿಲ್ಲದ ನಮೂದುಗಳನ್ನು ಕಳುಹಿಸಬಹುದು ಅಥವಾ ಮುಂದಿನ ಪ್ರಕ್ರಿಯೆಗಾಗಿ ಫಾರ್ವರ್ಡ್ ಮಾಡಬಹುದು.
ಸಾಮಾನ್ಯ nginx ಲಾಗ್ಗಳನ್ನು ಸಂಸ್ಕರಿಸುವ ಉದಾಹರಣೆಯನ್ನು ಬಳಸಿಕೊಂಡು, ನೀವು Promtail ಅನ್ನು ಬಳಸಿಕೊಂಡು ಲಾಗ್ಗಳನ್ನು ಹೇಗೆ ಪಾರ್ಸ್ ಮಾಡಬಹುದು ಎಂಬುದನ್ನು ನಾನು ತೋರಿಸುತ್ತೇನೆ.
ಪರೀಕ್ಷೆಗಾಗಿ, nginx-proxy ಆಗಿ ಮಾರ್ಪಡಿಸಿದ nginx ಇಮೇಜ್ jwilder/nginx-proxy:alpine ಮತ್ತು HTTP ಮೂಲಕ ಸ್ವತಃ ಕೇಳಬಹುದಾದ ಸಣ್ಣ ಡೀಮನ್ ಅನ್ನು ತೆಗೆದುಕೊಳ್ಳೋಣ. ಡೀಮನ್ ಹಲವಾರು ಅಂತಿಮ ಬಿಂದುಗಳನ್ನು ಹೊಂದಿದೆ, ಇದು ವಿಭಿನ್ನ ಗಾತ್ರದ ಪ್ರತಿಕ್ರಿಯೆಗಳನ್ನು ವಿವಿಧ HTTP ಸ್ಥಿತಿಗಳೊಂದಿಗೆ ಮತ್ತು ವಿಭಿನ್ನ ವಿಳಂಬಗಳೊಂದಿಗೆ ಒದಗಿಸುತ್ತದೆ.
ನಾವು ಡಾಕರ್ ಕಂಟೈನರ್ಗಳಿಂದ ಲಾಗ್ಗಳನ್ನು ಸಂಗ್ರಹಿಸುತ್ತೇವೆ, ಅದನ್ನು /var/lib/docker/containers//-json.log ಹಾದಿಯಲ್ಲಿ ಕಾಣಬಹುದು
docker-compose.yml ನಲ್ಲಿ ನಾವು Promtail ಅನ್ನು ಕಾನ್ಫಿಗರ್ ಮಾಡುತ್ತೇವೆ ಮತ್ತು ಸಂರಚನೆಗೆ ಮಾರ್ಗವನ್ನು ಸೂಚಿಸುತ್ತೇವೆ:
promtail:
image: grafana/promtail:1.4.1
// ...
volumes:
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- promtail-data:/var/lib/promtail/positions
- ${PWD}/promtail/docker.yml:/etc/promtail/promtail.yml
command:
- '-config.file=/etc/promtail/promtail.yml'
// ...
promtail.yml ಗೆ ಲಾಗ್ಗಳಿಗೆ ಮಾರ್ಗವನ್ನು ಸೇರಿಸಿ (ಸಂರಚನೆಯಲ್ಲಿ “ಡಾಕರ್” ಆಯ್ಕೆ ಇದೆ, ಅದು ಒಂದೇ ಸಾಲಿನಲ್ಲಿ ಅದೇ ಕೆಲಸವನ್ನು ಮಾಡುತ್ತದೆ, ಆದರೆ ಅದು ಸ್ಪಷ್ಟವಾಗಿಲ್ಲ):
scrape_configs:
- job_name: containers
static_configs:
labels:
job: containerlogs
__path__: /var/lib/docker/containers/*/*log # for linux onlyಈ ಸಂರಚನೆಯನ್ನು ಸಕ್ರಿಯಗೊಳಿಸಿದಾಗ, ಎಲ್ಲಾ ಕಂಟೈನರ್ಗಳಿಂದ ಲಾಗ್ಗಳನ್ನು ಲೋಕಿಗೆ ಕಳುಹಿಸಲಾಗುತ್ತದೆ. ಇದನ್ನು ತಪ್ಪಿಸಲು, ನಾವು docker-compose.yml ನಲ್ಲಿ ಪರೀಕ್ಷಾ nginx ನ ಸೆಟ್ಟಿಂಗ್ಗಳನ್ನು ಬದಲಾಯಿಸುತ್ತೇವೆ - ಲಾಗಿಂಗ್ ಟ್ಯಾಗ್ ಕ್ಷೇತ್ರವನ್ನು ಸೇರಿಸಿ:
proxy:
image: nginx.test.v3
//…
logging:
driver: "json-file"
options:
tag: "{{.ImageName}}|{{.Name}}"promtail.yml ಅನ್ನು ಸಂಪಾದಿಸಲಾಗುತ್ತಿದೆ ಮತ್ತು ಪೈಪ್ಲೈನ್ ಅನ್ನು ಹೊಂದಿಸಲಾಗುತ್ತಿದೆ. ಇನ್ಪುಟ್ ಈ ಕೆಳಗಿನ ಪ್ರಕಾರದ ಲಾಗ್ಗಳನ್ನು ಒಳಗೊಂಡಿದೆ:
{"log":"u001b[0;33;1mnginx.1 | u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] "GET /api/index HTTP/1.1" 200 0 "-" "Stub_Bot/0.1" "0.096"n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.66740443Z"}
{"log":"u001b[0;33;1mnginx.1 | u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] "GET /200 HTTP/1.1" 200 0 "-" "Stub_Bot/0.1" "0.000"n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.702925272Z"}ಪೈಪ್ಲೈನ್ ಹಂತ:
- json:
expressions:
stream: stream
attrs: attrs
tag: attrs.tagನಾವು ಒಳಬರುವ JSON ನಿಂದ ಸ್ಟ್ರೀಮ್, attrs, attrs.tag (ಅವು ಅಸ್ತಿತ್ವದಲ್ಲಿದ್ದರೆ) ಕ್ಷೇತ್ರಗಳನ್ನು ಹೊರತೆಗೆಯುತ್ತೇವೆ ಮತ್ತು ಅವುಗಳನ್ನು ಬೇರ್ಪಡಿಸಿದ ನಕ್ಷೆಯಲ್ಲಿ ಇರಿಸುತ್ತೇವೆ.
- regex:
expression: ^(?P<image_name>([^|]+))|(?P<container_name>([^|]+))$
source: "tag"ನಾವು ಹೊರತೆಗೆಯಲಾದ ನಕ್ಷೆಯಲ್ಲಿ ಟ್ಯಾಗ್ ಕ್ಷೇತ್ರವನ್ನು ಹಾಕಲು ನಿರ್ವಹಿಸುತ್ತಿದ್ದರೆ, ನಂತರ regexp ಬಳಸಿ ನಾವು ಚಿತ್ರ ಮತ್ತು ಕಂಟೇನರ್ನ ಹೆಸರುಗಳನ್ನು ಹೊರತೆಗೆಯುತ್ತೇವೆ.
- labels:
image_name:
container_name:ನಾವು ಲೇಬಲ್ಗಳನ್ನು ನಿಯೋಜಿಸುತ್ತೇವೆ. ಇಮೇಜ್_ಹೆಸರು ಮತ್ತು ಕಂಟೈನರ್_ಹೆಸರು ಕೀಲಿಗಳು ಹೊರತೆಗೆಯಲಾದ ಡೇಟಾದಲ್ಲಿ ಕಂಡುಬಂದರೆ, ಅವುಗಳ ಮೌಲ್ಯಗಳನ್ನು ಅನುಗುಣವಾದ ಲೇಬಲ್ಗಳಿಗೆ ನಿಯೋಜಿಸಲಾಗುತ್ತದೆ.
- match:
selector: '{job="docker",container_name="",image_name=""}'
action: dropಇಮೇಜ್_ಹೆಸರು ಮತ್ತು ಕಂಟೈನರ್_ಹೆಸರು ಲೇಬಲ್ಗಳನ್ನು ಸ್ಥಾಪಿಸದ ಎಲ್ಲಾ ಲಾಗ್ಗಳನ್ನು ನಾವು ತ್ಯಜಿಸುತ್ತೇವೆ.
- match:
selector: '{image_name="nginx.promtail.test"}'
stages:
- json:
expressions:
row: logಚಿತ್ರದ_ಹೆಸರು nginx.promtail.test ಆಗಿರುವ ಎಲ್ಲಾ ಲಾಗ್ಗಳಿಗಾಗಿ, ಲಾಗ್ ಕ್ಷೇತ್ರವನ್ನು ಮೂಲ ಲಾಗ್ನಿಂದ ಹೊರತೆಗೆಯಿರಿ ಮತ್ತು ಅದನ್ನು ರೋ ಕೀಲಿಯೊಂದಿಗೆ ಬೇರ್ಪಡಿಸಿದ ನಕ್ಷೆಯಲ್ಲಿ ಇರಿಸಿ.
- regex:
# suppress forego colors
expression: .+nginx.+|.+[0m(?P<virtual_host>[a-z_.-]+) +(?P<nginxlog>.+)
source: logrowನಾವು ನಿಯಮಿತ ಅಭಿವ್ಯಕ್ತಿಗಳೊಂದಿಗೆ ಇನ್ಪುಟ್ ಲೈನ್ ಅನ್ನು ತೆರವುಗೊಳಿಸುತ್ತೇವೆ ಮತ್ತು nginx ವರ್ಚುವಲ್ ಹೋಸ್ಟ್ ಮತ್ತು nginx ಲಾಗ್ ಲೈನ್ ಅನ್ನು ಹೊರತೆಗೆಯುತ್ತೇವೆ.
- regex:
source: nginxlog
expression: ^(?P<ip>[w.]+) - (?P<user>[^ ]*) [(?P<timestamp>[^ ]+).*] "(?P<method>[^ ]*) (?P<request_url>[^ ]*) (?P<request_http_protocol>[^ ]*)" (?P<status>[d]+) (?P<bytes_out>[d]+) "(?P<http_referer>[^"]*)" "(?P<user_agent>[^"]*)"( "(?P<response_time>[d.]+)")?ನಿಯಮಿತ ಅಭಿವ್ಯಕ್ತಿಗಳನ್ನು ಬಳಸಿಕೊಂಡು nginx ಲಾಗ್ ಅನ್ನು ಪಾರ್ಸ್ ಮಾಡಿ.
- regex:
source: request_url
expression: ^.+.(?P<static_type>jpg|jpeg|gif|png|ico|css|zip|tgz|gz|rar|bz2|pdf|txt|tar|wav|bmp|rtf|js|flv|swf|html|htm)$
- regex:
source: request_url
expression: ^/photo/(?P<photo>[^/?.]+).*$
- regex:
source: request_url
expression: ^/api/(?P<api_request>[^/?.]+).*$ವಿನಂತಿ_url ಅನ್ನು ಪಾರ್ಸ್ ಮಾಡೋಣ. regexp ಅನ್ನು ಬಳಸಿಕೊಂಡು ನಾವು ವಿನಂತಿಯ ಉದ್ದೇಶವನ್ನು ನಿರ್ಧರಿಸುತ್ತೇವೆ: ಸ್ಥಿರ ಡೇಟಾಗೆ, ಫೋಟೋಗಳಿಗೆ, API ಗೆ ಮತ್ತು ಬೇರ್ಪಡಿಸಿದ ನಕ್ಷೆಯಲ್ಲಿ ಅನುಗುಣವಾದ ಕೀಲಿಯನ್ನು ಹೊಂದಿಸಿ.
- template:
source: request_type
template: "{{if .photo}}photo{{else if .static_type}}static{{else if .api_request}}api{{else}}other{{end}}"ಟೆಂಪ್ಲೇಟ್ನಲ್ಲಿ ಷರತ್ತುಬದ್ಧ ಆಪರೇಟರ್ಗಳನ್ನು ಬಳಸಿಕೊಂಡು, ನಾವು ಬೇರ್ಪಡಿಸಿದ ನಕ್ಷೆಯಲ್ಲಿ ಸ್ಥಾಪಿಸಲಾದ ಕ್ಷೇತ್ರಗಳನ್ನು ಪರಿಶೀಲಿಸುತ್ತೇವೆ ಮತ್ತು ವಿನಂತಿಯ_ಪ್ರಕಾರ ಕ್ಷೇತ್ರಕ್ಕೆ ಅಗತ್ಯವಿರುವ ಮೌಲ್ಯಗಳನ್ನು ಹೊಂದಿಸುತ್ತೇವೆ: ಫೋಟೋ, ಸ್ಥಿರ, API. ಅದು ವಿಫಲವಾದರೆ ಇನ್ನೊಂದನ್ನು ನಿಯೋಜಿಸಿ. request_type ಈಗ ವಿನಂತಿಯ ಪ್ರಕಾರವನ್ನು ಒಳಗೊಂಡಿದೆ.
- labels:
api_request:
virtual_host:
request_type:
status:ನಾವು ಹೊರತೆಗೆಯಲಾದ ಮ್ಯಾಪ್ನಲ್ಲಿ ಹಾಕಲು ನಿರ್ವಹಿಸುತ್ತಿದ್ದುದನ್ನು ಆಧರಿಸಿ ನಾವು ಲೇಬಲ್ಗಳನ್ನು api_request, virtual_host, request_type ಮತ್ತು ಸ್ಥಿತಿ (HTTP ಸ್ಥಿತಿ) ಹೊಂದಿಸಿದ್ದೇವೆ.
- output:
source: nginx_log_rowಔಟ್ಪುಟ್ ಬದಲಾಯಿಸಿ. ಈಗ ಹೊರತೆಗೆದ ನಕ್ಷೆಯಿಂದ ಸ್ವಚ್ಛಗೊಳಿಸಿದ nginx ಲಾಗ್ ಲೋಕಿಗೆ ಹೋಗುತ್ತದೆ.
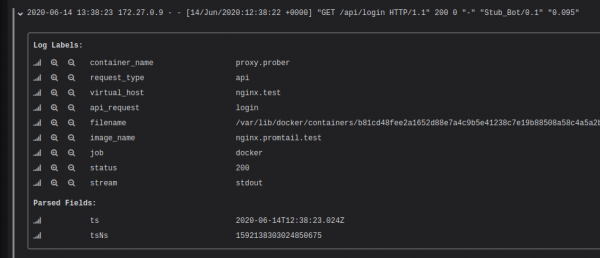
ಮೇಲಿನ ಸಂರಚನೆಯನ್ನು ಚಲಾಯಿಸಿದ ನಂತರ, ಲಾಗ್ನಿಂದ ಡೇಟಾದ ಆಧಾರದ ಮೇಲೆ ಪ್ರತಿ ನಮೂದುಗೆ ಲೇಬಲ್ಗಳನ್ನು ನಿಗದಿಪಡಿಸಲಾಗಿದೆ ಎಂದು ನೀವು ನೋಡಬಹುದು.
ನೆನಪಿನಲ್ಲಿಟ್ಟುಕೊಳ್ಳಬೇಕಾದ ಒಂದು ವಿಷಯವೆಂದರೆ, ಹೆಚ್ಚಿನ ಸಂಖ್ಯೆಯ ಮೌಲ್ಯಗಳೊಂದಿಗೆ (ಕಾರ್ಡಿನಾಲಿಟಿ) ಲೇಬಲ್ಗಳನ್ನು ಹಿಂಪಡೆಯುವುದು ಲೋಕಿಯನ್ನು ಗಮನಾರ್ಹವಾಗಿ ನಿಧಾನಗೊಳಿಸುತ್ತದೆ. ಅಂದರೆ, ನೀವು ಸೂಚ್ಯಂಕದಲ್ಲಿ user_id ಅನ್ನು ಹಾಕಬಾರದು. ಲೇಖನದಲ್ಲಿ ಇದರ ಬಗ್ಗೆ ಇನ್ನಷ್ಟು ಓದಿ "" ಆದರೆ ನೀವು ಸೂಚ್ಯಂಕಗಳಿಲ್ಲದೆ user_id ಮೂಲಕ ಹುಡುಕಲು ಸಾಧ್ಯವಿಲ್ಲ ಎಂದು ಇದರ ಅರ್ಥವಲ್ಲ. ಹುಡುಕುವಾಗ ನೀವು ಫಿಲ್ಟರ್ಗಳನ್ನು ಬಳಸಬೇಕಾಗುತ್ತದೆ (ಡೇಟಾವನ್ನು "ದೋಚಿ"), ಮತ್ತು ಇಲ್ಲಿ ಸೂಚ್ಯಂಕವು ಸ್ಟ್ರೀಮ್ ಐಡೆಂಟಿಫೈಯರ್ ಆಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸುತ್ತದೆ.
ದಾಖಲೆಗಳ ದೃಶ್ಯೀಕರಣ
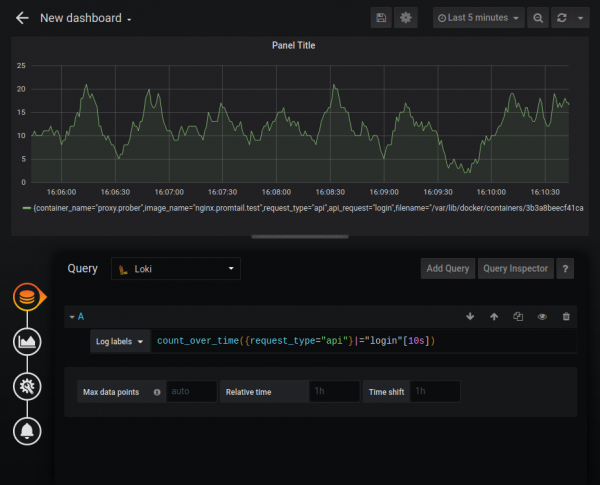
Logi LogQL ಅನ್ನು ಬಳಸಿಕೊಂಡು ಗ್ರಾಫನಾ ಗ್ರಾಫ್ಗಳಿಗೆ ಡೇಟಾ ಮೂಲವಾಗಿ ಕಾರ್ಯನಿರ್ವಹಿಸಬಹುದು. ಕೆಳಗಿನ ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ಬೆಂಬಲಿಸಲಾಗುತ್ತದೆ:
- ದರ - ಪ್ರತಿ ಸೆಕೆಂಡಿಗೆ ದಾಖಲೆಗಳ ಸಂಖ್ಯೆ;
- ಕಾಲಾನಂತರದಲ್ಲಿ ಎಣಿಕೆ - ನಿರ್ದಿಷ್ಟಪಡಿಸಿದ ಶ್ರೇಣಿಯಲ್ಲಿನ ದಾಖಲೆಗಳ ಸಂಖ್ಯೆ.
ಒಟ್ಟು ಮೊತ್ತ, ಸರಾಸರಿ ಮತ್ತು ಇತರವುಗಳ ಒಟ್ಟುಗೂಡಿಸುವಿಕೆ ಕಾರ್ಯಗಳೂ ಇವೆ. ನೀವು ಸಾಕಷ್ಟು ಸಂಕೀರ್ಣ ಗ್ರಾಫ್ಗಳನ್ನು ನಿರ್ಮಿಸಬಹುದು, ಉದಾಹರಣೆಗೆ HTTP ದೋಷಗಳ ಸಂಖ್ಯೆಯ ಗ್ರಾಫ್:
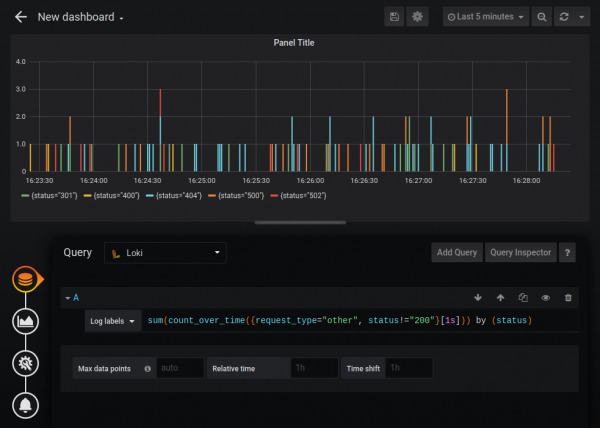
ಪ್ರಮೀತಿಯಸ್ ಡೇಟಾ ಮೂಲಕ್ಕೆ ಹೋಲಿಸಿದರೆ ಸ್ಟ್ಯಾಂಡರ್ಡ್ ಡೇಟಾ ಮೂಲ ಲೋಕಿ ಕ್ರಿಯಾತ್ಮಕತೆಯಲ್ಲಿ ಸ್ವಲ್ಪಮಟ್ಟಿಗೆ ಕಡಿಮೆಯಾಗಿದೆ (ಉದಾಹರಣೆಗೆ, ನೀವು ದಂತಕಥೆಯನ್ನು ಬದಲಾಯಿಸಲು ಸಾಧ್ಯವಿಲ್ಲ), ಆದರೆ ಲೋಕಿ ಅನ್ನು ಪ್ರಮೀತಿಯಸ್ ಪ್ರಕಾರದೊಂದಿಗೆ ಮೂಲವಾಗಿ ಸಂಪರ್ಕಿಸಬಹುದು. ಇದು ದಾಖಲಿತ ನಡವಳಿಕೆಯೇ ಎಂದು ನನಗೆ ಖಚಿತವಿಲ್ಲ, ಆದರೆ ಡೆವಲಪರ್ಗಳ ಪ್ರತಿಕ್ರಿಯೆಯಿಂದ ನಿರ್ಣಯಿಸುವುದು “”, ಉದಾಹರಣೆಗೆ, ಸಂಪೂರ್ಣವಾಗಿ ಕಾನೂನುಬದ್ಧವಾಗಿದೆ, ಮತ್ತು ಲೋಕಿ PromQL ನೊಂದಿಗೆ ಸಂಪೂರ್ಣವಾಗಿ ಹೊಂದಿಕೊಳ್ಳುತ್ತದೆ.
ಪ್ರಮೀತಿಯಸ್ ಪ್ರಕಾರದೊಂದಿಗೆ ಲೋಕಿ ಅನ್ನು ಡೇಟಾ ಮೂಲವಾಗಿ ಸೇರಿಸಿ ಮತ್ತು URL / ಲೋಕಿ ಸೇರಿಸಿ:

ಮತ್ತು ನಾವು ಪ್ರಮೀತಿಯಸ್ನಿಂದ ಮೆಟ್ರಿಕ್ಗಳೊಂದಿಗೆ ಕೆಲಸ ಮಾಡುತ್ತಿರುವಂತೆ ನಾವು ಗ್ರಾಫ್ಗಳನ್ನು ಮಾಡಬಹುದು:
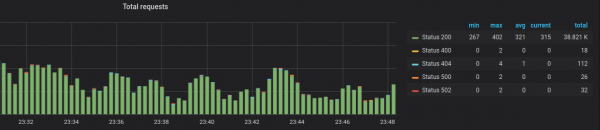
ಕಾರ್ಯನಿರ್ವಹಣೆಯಲ್ಲಿನ ವ್ಯತ್ಯಾಸವು ತಾತ್ಕಾಲಿಕವಾಗಿದೆ ಮತ್ತು ಡೆವಲಪರ್ಗಳು ಭವಿಷ್ಯದಲ್ಲಿ ಇದನ್ನು ಸರಿಪಡಿಸುತ್ತಾರೆ ಎಂದು ನಾನು ಭಾವಿಸುತ್ತೇನೆ.
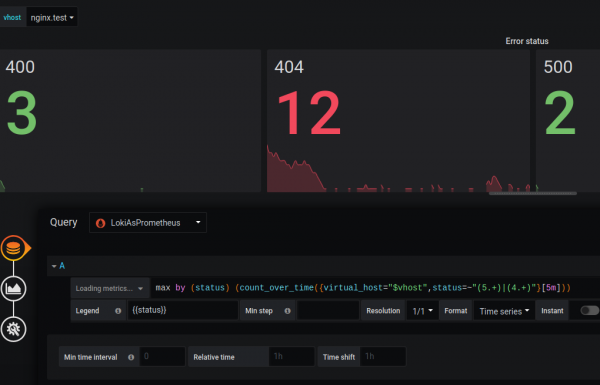
ಮೆಟ್ರಿಕ್ಸ್
ಲಾಗ್ಗಳಿಂದ ಸಂಖ್ಯಾತ್ಮಕ ಮೆಟ್ರಿಕ್ಗಳನ್ನು ಹೊರತೆಗೆಯಲು ಮತ್ತು ಅವುಗಳನ್ನು ಪ್ರಮೀತಿಯಸ್ಗೆ ಕಳುಹಿಸುವ ಸಾಮರ್ಥ್ಯವನ್ನು ಲೋಕಿ ಒದಗಿಸುತ್ತದೆ. ಉದಾಹರಣೆಗೆ, nginx ಲಾಗ್ ಪ್ರತಿ ಪ್ರತಿಕ್ರಿಯೆಗೆ ಬೈಟ್ಗಳ ಸಂಖ್ಯೆಯನ್ನು ಒಳಗೊಂಡಿರುತ್ತದೆ, ಜೊತೆಗೆ, ಪ್ರಮಾಣಿತ ಲಾಗ್ ಸ್ವರೂಪದ ನಿರ್ದಿಷ್ಟ ಮಾರ್ಪಾಡಿನೊಂದಿಗೆ, ಅದು ಪ್ರತಿಕ್ರಿಯಿಸಲು ತೆಗೆದುಕೊಂಡ ಸೆಕೆಂಡುಗಳ ಸಮಯವನ್ನು ಹೊಂದಿರುತ್ತದೆ. ಈ ಡೇಟಾವನ್ನು ಹೊರತೆಗೆಯಬಹುದು ಮತ್ತು ಪ್ರಮೀತಿಯಸ್ಗೆ ಕಳುಹಿಸಬಹುದು.
promtail.yml ಗೆ ಇನ್ನೊಂದು ವಿಭಾಗವನ್ನು ಸೇರಿಸಿ:
- match:
selector: '{request_type="api"}'
stages:
- metrics:
http_nginx_response_time:
type: Histogram
description: "response time ms"
source: response_time
config:
buckets: [0.010,0.050,0.100,0.200,0.500,1.0]
- match:
selector: '{request_type=~"static|photo"}'
stages:
- metrics:
http_nginx_response_bytes_sum:
type: Counter
description: "response bytes sum"
source: bytes_out
config:
action: add
http_nginx_response_bytes_count:
type: Counter
description: "response bytes count"
source: bytes_out
config:
action: incಹೊರತೆಗೆಯಲಾದ ನಕ್ಷೆಯಿಂದ ಡೇಟಾದ ಆಧಾರದ ಮೇಲೆ ಮೆಟ್ರಿಕ್ಗಳನ್ನು ವ್ಯಾಖ್ಯಾನಿಸಲು ಮತ್ತು ನವೀಕರಿಸಲು ಆಯ್ಕೆಯು ನಿಮಗೆ ಅನುಮತಿಸುತ್ತದೆ. ಈ ಮೆಟ್ರಿಕ್ಗಳನ್ನು ಲೋಕಿಗೆ ಕಳುಹಿಸಲಾಗಿಲ್ಲ - ಅವು ಪ್ರಾಮ್ಟೈಲ್ /ಮೆಟ್ರಿಕ್ಸ್ ಎಂಡ್ಪಾಯಿಂಟ್ನಲ್ಲಿ ಗೋಚರಿಸುತ್ತವೆ. ಈ ಹಂತದಲ್ಲಿ ಸ್ವೀಕರಿಸಿದ ಡೇಟಾವನ್ನು ಸ್ವೀಕರಿಸಲು ಪ್ರಮೀತಿಯಸ್ ಅನ್ನು ಕಾನ್ಫಿಗರ್ ಮಾಡಬೇಕು. ಮೇಲಿನ ಉದಾಹರಣೆಯಲ್ಲಿ, request_type=“api” ಗಾಗಿ ನಾವು ಹಿಸ್ಟೋಗ್ರಾಮ್ ಮೆಟ್ರಿಕ್ ಅನ್ನು ಸಂಗ್ರಹಿಸುತ್ತೇವೆ. ಈ ರೀತಿಯ ಮೆಟ್ರಿಕ್ಗಳೊಂದಿಗೆ ಶೇಕಡಾವಾರುಗಳನ್ನು ಪಡೆಯಲು ಅನುಕೂಲಕರವಾಗಿದೆ. ಸ್ಥಿರ ಮತ್ತು ಫೋಟೋಗಾಗಿ, ಬೈಟ್ಗಳ ಮೊತ್ತ ಮತ್ತು ಸರಾಸರಿಯನ್ನು ಲೆಕ್ಕಾಚಾರ ಮಾಡಲು ನಾವು ಬೈಟ್ಗಳನ್ನು ಸ್ವೀಕರಿಸಿದ ಸಾಲುಗಳ ಸಂಖ್ಯೆಯನ್ನು ಸಂಗ್ರಹಿಸುತ್ತೇವೆ.
ಮೆಟ್ರಿಕ್ಗಳ ಬಗ್ಗೆ ಇನ್ನಷ್ಟು ಓದಿ .
Promtail ನಲ್ಲಿ ಪೋರ್ಟ್ ತೆರೆಯಿರಿ:
promtail:
image: grafana/promtail:1.4.1
container_name: monitoring.promtail
expose:
- 9080
ports:
- "9080:9080"promtail_custom ಪೂರ್ವಪ್ರತ್ಯಯದೊಂದಿಗೆ ಮೆಟ್ರಿಕ್ಗಳು ಗೋಚರಿಸುತ್ತವೆಯೇ ಎಂದು ಖಚಿತಪಡಿಸಿಕೊಳ್ಳಿ:
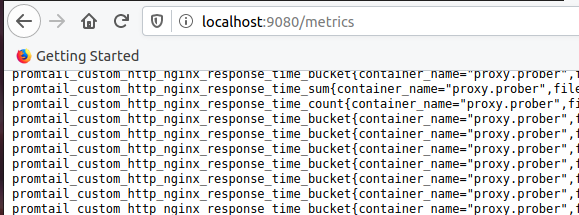
ಪ್ರಮೀತಿಯಸ್ ಅನ್ನು ಸ್ಥಾಪಿಸುವುದು. ಉದ್ಯೋಗ ಪ್ರಾಮ್ಟೇಲ್ ಸೇರಿಸಿ:
- job_name: 'promtail'
scrape_interval: 10s
static_configs:
- targets: ['promtail:9080']ಮತ್ತು ನಾವು ಗ್ರಾಫ್ ಅನ್ನು ಸೆಳೆಯುತ್ತೇವೆ:
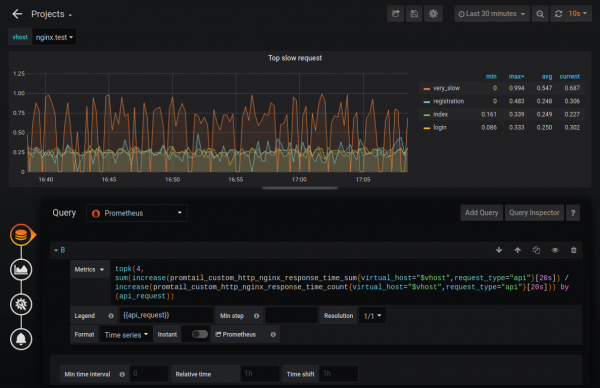
ಈ ರೀತಿಯಲ್ಲಿ ನೀವು ಕಂಡುಹಿಡಿಯಬಹುದು, ಉದಾಹರಣೆಗೆ, ನಾಲ್ಕು ನಿಧಾನವಾದ ಪ್ರಶ್ನೆಗಳು. ಈ ಮೆಟ್ರಿಕ್ಗಳಿಗಾಗಿ ನೀವು ಮಾನಿಟರಿಂಗ್ ಅನ್ನು ಸಹ ಹೊಂದಿಸಬಹುದು.
ಸ್ಕೇಲಿಂಗ್
ಲೋಕಿ ಏಕ ಬೈನರಿ ಮೋಡ್ನಲ್ಲಿರಬಹುದು ಅಥವಾ ಚೂರುಚೂರು ಮೋಡ್ನಲ್ಲಿರಬಹುದು (ಅಡ್ಡವಾಗಿ-ಸ್ಕೇಲೆಬಲ್ ಮೋಡ್). ಎರಡನೆಯ ಸಂದರ್ಭದಲ್ಲಿ, ಇದು ಡೇಟಾವನ್ನು ಕ್ಲೌಡ್ಗೆ ಉಳಿಸಬಹುದು ಮತ್ತು ಭಾಗಗಳು ಮತ್ತು ಸೂಚ್ಯಂಕವನ್ನು ಪ್ರತ್ಯೇಕವಾಗಿ ಸಂಗ್ರಹಿಸಲಾಗುತ್ತದೆ. ಆವೃತ್ತಿ 1.5 ಒಂದೇ ಸ್ಥಳದಲ್ಲಿ ಸಂಗ್ರಹಿಸುವ ಸಾಮರ್ಥ್ಯವನ್ನು ಪರಿಚಯಿಸುತ್ತದೆ, ಆದರೆ ಉತ್ಪಾದನೆಯಲ್ಲಿ ಅದನ್ನು ಬಳಸಲು ಇನ್ನೂ ಶಿಫಾರಸು ಮಾಡಲಾಗಿಲ್ಲ.
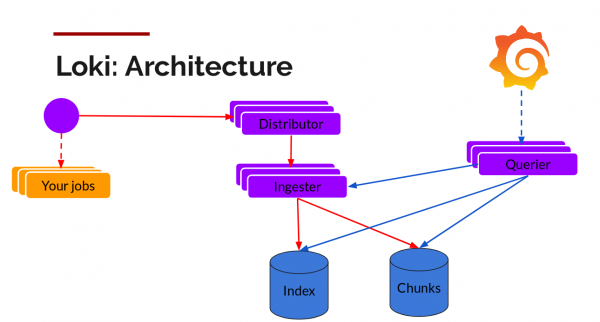
ಭಾಗಗಳನ್ನು S3-ಹೊಂದಾಣಿಕೆಯ ಸಂಗ್ರಹಣೆಯಲ್ಲಿ ಸಂಗ್ರಹಿಸಬಹುದು ಮತ್ತು ಸೂಚಿಕೆಗಳನ್ನು ಸಂಗ್ರಹಿಸಲು ಅಡ್ಡಲಾಗಿ ಸ್ಕೇಲೆಬಲ್ ಡೇಟಾಬೇಸ್ಗಳನ್ನು ಬಳಸಬಹುದು: ಕಸ್ಸಂದ್ರ, ಬಿಗ್ಟೇಬಲ್ ಅಥವಾ ಡೈನಮೋಡಿಬಿ. ಲೋಕಿಯ ಇತರ ಭಾಗಗಳು - ವಿತರಕರು (ಬರೆಯಲು) ಮತ್ತು ಕ್ವೆರಿಯರ್ (ಪ್ರಶ್ನೆಗಳಿಗಾಗಿ) - ಸ್ಥಿತಿಯಿಲ್ಲ ಮತ್ತು ಅಡ್ಡಲಾಗಿ ಅಳೆಯಲಾಗುತ್ತದೆ.
DevOpsDays ವ್ಯಾಂಕೋವರ್ 2019 ಸಮ್ಮೇಳನದಲ್ಲಿ, ಭಾಗವಹಿಸುವವರಲ್ಲಿ ಒಬ್ಬರು ಕ್ಯಾಲಮ್ ಸ್ಟ್ಯಾನ್ ಲೋಕಿ ಅವರ ಯೋಜನೆಯು ಒಟ್ಟು ಗಾತ್ರದ 1% ಕ್ಕಿಂತ ಕಡಿಮೆ ಸೂಚ್ಯಂಕದೊಂದಿಗೆ ಪೆಟಾಬೈಟ್ಗಳ ಲಾಗ್ಗಳನ್ನು ಹೊಂದಿದೆ ಎಂದು ಘೋಷಿಸಿದರು: "".
ಲೋಕಿ ಮತ್ತು ELK ಹೋಲಿಕೆ
ಸೂಚ್ಯಂಕ ಗಾತ್ರ
ಪರಿಣಾಮವಾಗಿ ಸೂಚ್ಯಂಕ ಗಾತ್ರವನ್ನು ಪರೀಕ್ಷಿಸಲು, ಮೇಲಿನ ಪೈಪ್ಲೈನ್ ಅನ್ನು ಕಾನ್ಫಿಗರ್ ಮಾಡಲಾದ nginx ಕಂಟೇನರ್ನಿಂದ ನಾನು ಲಾಗ್ಗಳನ್ನು ತೆಗೆದುಕೊಂಡಿದ್ದೇನೆ. ಲಾಗ್ ಫೈಲ್ 406 MB ಯ ಒಟ್ಟು ಪರಿಮಾಣದೊಂದಿಗೆ 624 ಸಾಲುಗಳನ್ನು ಒಳಗೊಂಡಿದೆ. ಒಂದು ಗಂಟೆಯೊಳಗೆ ಲಾಗ್ಗಳನ್ನು ರಚಿಸಲಾಗಿದೆ, ಪ್ರತಿ ಸೆಕೆಂಡಿಗೆ ಸರಿಸುಮಾರು 109 ನಮೂದುಗಳು.
ಲಾಗ್ನಿಂದ ಎರಡು ಸಾಲುಗಳ ಉದಾಹರಣೆ:

ELK ನಿಂದ ಸೂಚಿಕೆ ಮಾಡಿದಾಗ, ಇದು 30,3 MB ಯ ಸೂಚ್ಯಂಕ ಗಾತ್ರವನ್ನು ನೀಡಿತು:
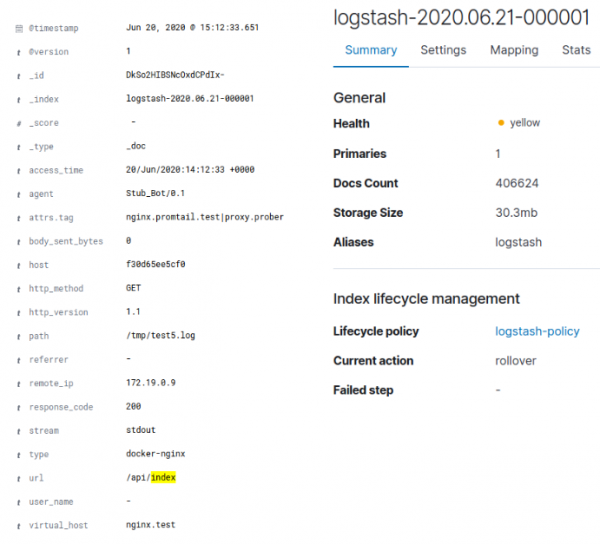
ಲೋಕಿಯ ಸಂದರ್ಭದಲ್ಲಿ, ಇದು ಸರಿಸುಮಾರು 128 KB ಸೂಚ್ಯಂಕ ಮತ್ತು ಸುಮಾರು 3,8 MB ಡೇಟಾವನ್ನು ತುಣುಕುಗಳಲ್ಲಿ ಉಂಟುಮಾಡಿದೆ. ಲಾಗ್ ಅನ್ನು ಕೃತಕವಾಗಿ ರಚಿಸಲಾಗಿದೆ ಮತ್ತು ದೊಡ್ಡ ಪ್ರಮಾಣದ ಡೇಟಾವನ್ನು ಹೊಂದಿಲ್ಲ ಎಂದು ಗಮನಿಸಬೇಕಾದ ಅಂಶವಾಗಿದೆ. ಡೇಟಾದೊಂದಿಗೆ ಮೂಲ ಡಾಕರ್ JSON ಲಾಗ್ನಲ್ಲಿ ಸರಳವಾದ ಜಿಜಿಪ್ 95,4% ಸಂಕುಚಿತತೆಯನ್ನು ನೀಡಿತು ಮತ್ತು ಸ್ವಚ್ಛಗೊಳಿಸಿದ nginx ಲಾಗ್ ಅನ್ನು ಮಾತ್ರ ಲೋಕಿಗೆ ಕಳುಹಿಸಲಾಗಿದೆ ಎಂಬ ಅಂಶವನ್ನು ಗಣನೆಗೆ ತೆಗೆದುಕೊಂಡರೆ, 4 MB ವರೆಗಿನ ಸಂಕೋಚನವು ಅರ್ಥವಾಗುವಂತಹದ್ದಾಗಿದೆ. ಲೋಕಿ ಲೇಬಲ್ಗಳಿಗೆ ವಿಶಿಷ್ಟ ಮೌಲ್ಯಗಳ ಒಟ್ಟು ಸಂಖ್ಯೆ 35 ಆಗಿತ್ತು, ಇದು ಸೂಚ್ಯಂಕದ ಸಣ್ಣ ಗಾತ್ರವನ್ನು ವಿವರಿಸುತ್ತದೆ. ELK ಗಾಗಿ ಲಾಗ್ ಅನ್ನು ಸಹ ತೆರವುಗೊಳಿಸಲಾಗಿದೆ. ಹೀಗಾಗಿ, ಲೋಕಿ ಮೂಲ ಡೇಟಾವನ್ನು 96% ಮತ್ತು ELK ಅನ್ನು 70% ರಷ್ಟು ಸಂಕುಚಿತಗೊಳಿಸಿದರು.
ಮೆಮೊರಿ ಬಳಕೆ
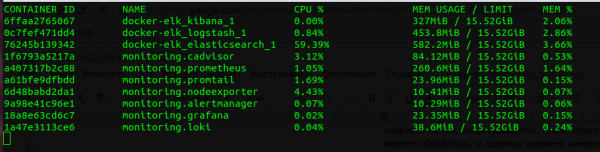
ನಾವು ಸಂಪೂರ್ಣ ಪ್ರಮೀತಿಯಸ್ ಮತ್ತು ELK ಸ್ಟಾಕ್ ಅನ್ನು ಹೋಲಿಸಿದರೆ, ನಂತರ ಲೋಕಿ "ತಿನ್ನುತ್ತದೆ" ಹಲವಾರು ಬಾರಿ ಕಡಿಮೆ. Go ಸೇವೆಯು Java ಸೇವೆಗಿಂತ ಕಡಿಮೆ ಬಳಸುತ್ತದೆ ಎಂಬುದು ಸ್ಪಷ್ಟವಾಗಿದೆ, ಮತ್ತು JVM ಹೀಪ್ ಎಲಾಸ್ಟಿಕ್ ಸರ್ಚ್ನ ಗಾತ್ರ ಮತ್ತು ಲೋಕಿಗೆ ನಿಯೋಜಿಸಲಾದ ಮೆಮೊರಿಯನ್ನು ಹೋಲಿಸುವುದು ತಪ್ಪಾಗಿದೆ, ಆದರೆ ಲೋಕಿಯು ಕಡಿಮೆ ಮೆಮೊರಿಯನ್ನು ಬಳಸುತ್ತದೆ ಎಂಬುದು ಗಮನಿಸಬೇಕಾದ ಸಂಗತಿ. ಇದರ ಸಿಪಿಯು ಪ್ರಯೋಜನವು ಅಷ್ಟು ಸ್ಪಷ್ಟವಾಗಿಲ್ಲ, ಆದರೆ ಇದು ಸಹ ಇರುತ್ತದೆ.
ವೇಗ
ಲೋಕಿ ಲಾಗ್ಗಳನ್ನು ವೇಗವಾಗಿ "ತಿನ್ನುತ್ತದೆ". ವೇಗವು ಅನೇಕ ಅಂಶಗಳ ಮೇಲೆ ಅವಲಂಬಿತವಾಗಿದೆ - ಯಾವ ರೀತಿಯ ಲಾಗ್ಗಳು, ಅವುಗಳನ್ನು ಪಾರ್ಸ್ ಮಾಡುವಲ್ಲಿ ನಾವು ಎಷ್ಟು ಅತ್ಯಾಧುನಿಕ, ನೆಟ್ವರ್ಕ್, ಡಿಸ್ಕ್, ಇತ್ಯಾದಿ - ಆದರೆ ಇದು ಖಂಡಿತವಾಗಿಯೂ ELK ಗಿಂತ ಹೆಚ್ಚಾಗಿರುತ್ತದೆ (ನನ್ನ ಪರೀಕ್ಷೆಯಲ್ಲಿ - ಸುಮಾರು ಎರಡು ಪಟ್ಟು ಹೆಚ್ಚು). ಲೋಕಿ ಸೂಚ್ಯಂಕದಲ್ಲಿ ಕಡಿಮೆ ಡೇಟಾವನ್ನು ಇರಿಸುತ್ತಾರೆ ಮತ್ತು ಅದರ ಪ್ರಕಾರ, ಇಂಡೆಕ್ಸಿಂಗ್ನಲ್ಲಿ ಕಡಿಮೆ ಸಮಯವನ್ನು ಕಳೆಯುತ್ತಾರೆ ಎಂಬ ಅಂಶದಿಂದ ಇದನ್ನು ವಿವರಿಸಲಾಗಿದೆ. ಹುಡುಕಾಟ ವೇಗದೊಂದಿಗೆ, ಪರಿಸ್ಥಿತಿಯು ವಿರುದ್ಧವಾಗಿದೆ: ಲೋಕಿ ಹಲವಾರು ಗಿಗಾಬೈಟ್ಗಳಿಗಿಂತ ದೊಡ್ಡದಾದ ಡೇಟಾವನ್ನು ಗಮನಾರ್ಹವಾಗಿ ನಿಧಾನಗೊಳಿಸುತ್ತದೆ, ಆದರೆ ELK ಯ ಹುಡುಕಾಟ ವೇಗವು ಡೇಟಾದ ಗಾತ್ರವನ್ನು ಅವಲಂಬಿಸಿರುವುದಿಲ್ಲ.
ಲಾಗ್ ಹುಡುಕಾಟ
ಲಾಗ್ ಹುಡುಕಾಟ ಸಾಮರ್ಥ್ಯಗಳ ವಿಷಯದಲ್ಲಿ ಲೋಕಿಯು ELK ಗಿಂತ ಗಮನಾರ್ಹವಾಗಿ ಕೆಳಮಟ್ಟದಲ್ಲಿದೆ. ನಿಯಮಿತ ಅಭಿವ್ಯಕ್ತಿಗಳೊಂದಿಗೆ ಗ್ರೆಪ್ ಶಕ್ತಿಯುತವಾಗಿದೆ, ಆದರೆ ಇದು ಪ್ರಬುದ್ಧ ಡೇಟಾಬೇಸ್ಗಿಂತ ಕೆಳಮಟ್ಟದ್ದಾಗಿದೆ. ಶ್ರೇಣಿಯ ಪ್ರಶ್ನೆಗಳ ಕೊರತೆ, ಲೇಬಲ್ಗಳಿಂದ ಮಾತ್ರ ಒಟ್ಟುಗೂಡಿಸುವಿಕೆ, ಲೇಬಲ್ಗಳಿಲ್ಲದೆ ಹುಡುಕಲು ಅಸಮರ್ಥತೆ - ಇವೆಲ್ಲವೂ ಲೋಕಿಯಲ್ಲಿ ಆಸಕ್ತಿಯ ಮಾಹಿತಿಯನ್ನು ಹುಡುಕುವಲ್ಲಿ ನಮ್ಮನ್ನು ಮಿತಿಗೊಳಿಸುತ್ತದೆ. ಲೋಕಿ ಬಳಸಿ ಏನನ್ನೂ ಕಂಡುಹಿಡಿಯಲಾಗುವುದಿಲ್ಲ ಎಂದು ಇದರ ಅರ್ಥವಲ್ಲ, ಆದರೆ ನೀವು ಮೊದಲು ಪ್ರಮೀತಿಯಸ್ ಚಾರ್ಟ್ಗಳಲ್ಲಿ ಸಮಸ್ಯೆಯನ್ನು ಕಂಡುಕೊಂಡಾಗ ಲಾಗ್ಗಳೊಂದಿಗೆ ಕೆಲಸ ಮಾಡುವ ಹರಿವನ್ನು ಇದು ವ್ಯಾಖ್ಯಾನಿಸುತ್ತದೆ ಮತ್ತು ನಂತರ ಲಾಗ್ಗಳಲ್ಲಿ ಏನಾಯಿತು ಎಂಬುದನ್ನು ನೋಡಲು ಈ ಲೇಬಲ್ಗಳನ್ನು ಬಳಸಿ.
ಇಂಟರ್ಫೇಸ್
ಮೊದಲನೆಯದಾಗಿ, ಇದು ಸುಂದರವಾಗಿದೆ (ಕ್ಷಮಿಸಿ, ವಿರೋಧಿಸಲು ಸಾಧ್ಯವಾಗಲಿಲ್ಲ). ಗ್ರಾಫಾನಾವು ಸುಂದರವಾಗಿ ಕಾಣುವ ಇಂಟರ್ಫೇಸ್ ಅನ್ನು ಹೊಂದಿದೆ, ಆದರೆ ಕಿಬಾನಾ ಹೆಚ್ಚು ವೈಶಿಷ್ಟ್ಯಗಳನ್ನು ಹೊಂದಿದೆ.
ಲೋಕಿಯ ಒಳಿತು ಕೆಡುಕುಗಳು
ಲೋಕಿ ಪ್ರಮೀತಿಯಸ್ನೊಂದಿಗೆ ಸಂಯೋಜನೆಗೊಳ್ಳುವುದು ಒಂದು ಪ್ರಯೋಜನವಾಗಿದೆ, ಆದ್ದರಿಂದ ನಾವು ಮೆಟ್ರಿಕ್ಗಳನ್ನು ಪಡೆಯುತ್ತೇವೆ ಮತ್ತು ಬಾಕ್ಸ್ನಿಂದ ಎಚ್ಚರಿಕೆಯನ್ನು ಪಡೆಯುತ್ತೇವೆ. ಲಾಗ್ಗಳನ್ನು ಸಂಗ್ರಹಿಸಲು ಮತ್ತು ಕುಬರ್ನೆಟ್ಸ್ ಪಾಡ್ಗಳಿಂದ ಅವುಗಳನ್ನು ಸಂಗ್ರಹಿಸಲು ಇದು ಅನುಕೂಲಕರವಾಗಿದೆ, ಏಕೆಂದರೆ ಇದು ಪ್ರೊಮೆಥಿಯಸ್ನಿಂದ ಆನುವಂಶಿಕವಾಗಿ ಪಡೆದ ಸೇವಾ ಅನ್ವೇಷಣೆಯನ್ನು ಹೊಂದಿದೆ ಮತ್ತು ಲೇಬಲ್ಗಳನ್ನು ಸ್ವಯಂಚಾಲಿತವಾಗಿ ಲಗತ್ತಿಸುತ್ತದೆ.
ಅನಾನುಕೂಲವೆಂದರೆ ದುರ್ಬಲ ದಾಖಲಾತಿ. ಕೆಲವು ವಿಷಯಗಳು, ಉದಾಹರಣೆಗೆ, Promtail ನ ವೈಶಿಷ್ಟ್ಯಗಳು ಮತ್ತು ಸಾಮರ್ಥ್ಯಗಳು, ಕೋಡ್ ಅನ್ನು ಅಧ್ಯಯನ ಮಾಡುವ ಪ್ರಕ್ರಿಯೆಯಲ್ಲಿ ಮಾತ್ರ ನಾನು ಕಂಡುಹಿಡಿದಿದ್ದೇನೆ, ಅದೃಷ್ಟವಶಾತ್ ಇದು ತೆರೆದ ಮೂಲವಾಗಿದೆ. ಮತ್ತೊಂದು ಅನನುಕೂಲವೆಂದರೆ ದುರ್ಬಲ ಪಾರ್ಸಿಂಗ್ ಸಾಮರ್ಥ್ಯಗಳು. ಉದಾಹರಣೆಗೆ, ಲೋಕಿ ಮಲ್ಟಿಲೈನ್ ಲಾಗ್ಗಳನ್ನು ಪಾರ್ಸ್ ಮಾಡಲು ಸಾಧ್ಯವಿಲ್ಲ. ಮತ್ತೊಂದು ಅನನುಕೂಲವೆಂದರೆ ಲೋಕಿ ತುಲನಾತ್ಮಕವಾಗಿ ಯುವ ತಂತ್ರಜ್ಞಾನವಾಗಿದೆ (1.0 ನವೆಂಬರ್ 2019 ರಲ್ಲಿ ಬಿಡುಗಡೆಯಾಯಿತು).
ತೀರ್ಮಾನಕ್ಕೆ
ಲೋಕಿ 100% ಆಸಕ್ತಿದಾಯಕ ತಂತ್ರಜ್ಞಾನವಾಗಿದ್ದು, ಇದು ಸಣ್ಣ ಮತ್ತು ಮಧ್ಯಮ ಗಾತ್ರದ ಯೋಜನೆಗಳಿಗೆ ಸೂಕ್ತವಾಗಿದೆ, ಇದು ಲಾಗ್ ಒಟ್ಟುಗೂಡಿಸುವಿಕೆ, ಲಾಗ್ ಹುಡುಕಾಟ, ಮೇಲ್ವಿಚಾರಣೆ ಮತ್ತು ಲಾಗ್ ವಿಶ್ಲೇಷಣೆಯ ಅನೇಕ ಸಮಸ್ಯೆಗಳನ್ನು ಪರಿಹರಿಸಲು ನಿಮಗೆ ಅನುವು ಮಾಡಿಕೊಡುತ್ತದೆ.
ನಾವು Badoo ನಲ್ಲಿ ಲೋಕಿ ಅನ್ನು ಬಳಸುವುದಿಲ್ಲ ಏಕೆಂದರೆ ನಮಗೆ ಸೂಕ್ತವಾದ ELK ಸ್ಟಾಕ್ ಅನ್ನು ನಾವು ಹೊಂದಿದ್ದೇವೆ ಮತ್ತು ಇದು ಹಲವಾರು ವರ್ಷಗಳಿಂದ ವಿವಿಧ ಕಸ್ಟಮ್ ಪರಿಹಾರಗಳೊಂದಿಗೆ ಬೆಳೆದಿದೆ. ನಮಗೆ, ಎಡವಟ್ಟು ದಾಖಲೆಗಳ ಮೂಲಕ ಹುಡುಕುತ್ತಿದೆ. ದಿನಕ್ಕೆ ಸುಮಾರು 100 GB ಲಾಗ್ಗಳೊಂದಿಗೆ, ನಾವು ಎಲ್ಲವನ್ನೂ ಹುಡುಕಲು ಮತ್ತು ಸ್ವಲ್ಪ ಹೆಚ್ಚು ಮತ್ತು ತ್ವರಿತವಾಗಿ ಮಾಡಲು ಸಾಧ್ಯವಾಗುತ್ತದೆ. ಚಾರ್ಟಿಂಗ್ ಮತ್ತು ಮೇಲ್ವಿಚಾರಣೆಗಾಗಿ, ನಮ್ಮ ಅಗತ್ಯಗಳಿಗೆ ಅನುಗುಣವಾಗಿ ಮತ್ತು ಪರಸ್ಪರ ಸಂಯೋಜಿಸಲ್ಪಟ್ಟ ಇತರ ಪರಿಹಾರಗಳನ್ನು ನಾವು ಬಳಸುತ್ತೇವೆ. ಲೋಕಿ ಸ್ಟಾಕ್ ಸ್ಪಷ್ಟವಾದ ಪ್ರಯೋಜನಗಳನ್ನು ಹೊಂದಿದೆ, ಆದರೆ ಇದು ನಾವು ಈಗಾಗಲೇ ಹೊಂದಿದ್ದಕ್ಕಿಂತ ಹೆಚ್ಚಿನದನ್ನು ನೀಡುವುದಿಲ್ಲ ಮತ್ತು ಅದರ ಪ್ರಯೋಜನಗಳು ಖಂಡಿತವಾಗಿಯೂ ವಲಸೆಯ ವೆಚ್ಚವನ್ನು ಮೀರುವುದಿಲ್ಲ.
ಮತ್ತು ಸಂಶೋಧನೆಯ ನಂತರ ನಾವು ಲೋಕಿ ಅನ್ನು ಬಳಸಲಾಗುವುದಿಲ್ಲ ಎಂಬುದು ಸ್ಪಷ್ಟವಾದರೂ, ನಿಮ್ಮ ಆಯ್ಕೆಯಲ್ಲಿ ಈ ಪೋಸ್ಟ್ ನಿಮಗೆ ಸಹಾಯ ಮಾಡುತ್ತದೆ ಎಂದು ನಾವು ಭಾವಿಸುತ್ತೇವೆ.
ಲೇಖನದಲ್ಲಿ ಬಳಸಲಾದ ಕೋಡ್ನೊಂದಿಗೆ ರೆಪೊಸಿಟರಿ ಇದೆ .
ಮೂಲ: www.habr.com
