

본 연구에서는 PostgreSQL이 아닌 ClickHouse 데이터 소스를 사용하면 어떤 성능 향상을 얻을 수 있는지 확인하고 싶었습니다. 나는 ClickHouse를 사용함으로써 얻을 수 있는 생산성 이점을 알고 있습니다. FDW(Foreign Data Wrapper)를 사용하여 PostgreSQL에서 ClickHouse에 액세스하면 이러한 이점이 계속 유지됩니까?
연구된 데이터베이스 환경은 PostgreSQL v11, clickhousedb_fdw 및 ClickHouse 데이터베이스입니다. 궁극적으로 PostgreSQL v11에서는 clickhousedb_fdw를 통해 ClickHouse 데이터베이스로 라우팅되는 다양한 SQL 쿼리를 실행하게 됩니다. 그런 다음 FDW의 성능이 기본 PostgreSQL 및 기본 ClickHouse에서 실행되는 동일한 쿼리와 어떻게 비교되는지 살펴보겠습니다.
클릭하우스 데이터베이스
ClickHouse는 기존 데이터베이스 접근 방식보다 100~1000배 빠른 성능을 달성하고 XNUMX초 이내에 XNUMX억 개가 넘는 행을 처리할 수 있는 오픈 소스 컬럼형 데이터베이스 관리 시스템입니다.
Clickhousedb_fdw
clickhousedb_fdw - ClickHouse 데이터베이스(FDW)의 외부 데이터 래퍼는 Percona의 오픈 소스 프로젝트입니다. .
.
보시다시피 이는 PostgreSQL v11 서버의 ClickHouse 데이터베이스에서 SELECT 및 INSERT INTO를 허용하는 ClickHouse용 FDW를 제공합니다.
FDW는 집계 및 조인과 같은 고급 기능을 지원합니다. 이렇게 하면 리소스 집약적인 작업에 원격 서버의 리소스를 사용하여 성능이 크게 향상됩니다.
벤치마크 환경
- 슈퍼마이크로 서버:
- 인텔® 제온® CPU E5-2683 v3 @ 2.00GHz
- 2소켓 / 28코어 / 56스레드
- 메모리 : RAM의 256GB
- 스토리지: 삼성 SM863 1.9TB 엔터프라이즈 SSD
- 파일 시스템: ext4/xfs
- OS : Linux smblade01 4.15.0-42-generic #45~16.04.1-Ubuntu
- PostgreSQL: 버전 11
벤치마크 테스트
이 테스트에는 일부 기계 생성 데이터 세트를 사용하는 대신 1987년부터 2018년까지의 "보고된 작업자 시간별 생산성" 데이터를 사용했습니다. 데이터에 접근할 수 있습니다. .
데이터베이스 크기는 85GB이며 109개 열로 구성된 하나의 테이블을 제공합니다.
벤치마크 쿼리
ClickHouse, clickhousedb_fdw 및 PostgreSQL을 비교하는 데 사용한 쿼리는 다음과 같습니다.
Q#
쿼리에 집계 및 그룹화 기준이 포함됨
Q1
SELECT DayOfWeek, count(*) AS c FROM ontime WHERE 연도 >= 2000 AND 연도 <= 2008 GROUP BY DayOfWeek ORDER BY c DESC;
Q2
SELECT DayOfWeek, count(*) AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY DayOfWeek ORDER BY c DESC;
Q3
SELECT 출발지, 개수(*) AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY Origin ORDER BY c DESC LIMIT 10;
Q4
SELECT 캐리어, 개수() 정시부터 DepDelay>10 AND 연도 = 2007 GROUP BY Carrier ORDER BY count() 설명;
Q5
SELECT a.캐리어, c, c2, c1000/c2 as c3 FROM( 캐리어 선택, 개수() AS c FROM ontime WHERE DepDelay>10 AND Year=2007 GROUP BY Carrier ) a INNER JOIN ( SELECT Carrier,count(*) AS c2 FROM ontime WHERE Year=2007 GROUP BY Carrier)b on a.Carrier=b.Carrier ORDER c3 설명으로;
Q6
SELECT a.캐리어, c, c2, c1000/c2 as c3 FROM( 캐리어 선택, 개수() AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY Carrier) a INNER JOIN ( SELECT Carrier, count(*) AS c2 FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY 캐리어 ) b on a.Carrier=b.Carrier ORDER BY c3 DESC;
Q7
SELECT Carrier, avg(DepDelay) * 1000 AS c3 FROM 정시 WHERE Year >= 2000 AND Year <= 2008 GROUP BY Carrier;
Q8
SELECT 연도, 평균(DepDelay) FROM 정시 GROUP BY 연도;
Q9
연도를 선택하고 연도별 정시 그룹에서 c1으로 계산(*)합니다.
Q10
SELECT avg(cnt) FROM (SELECT 연도,월,count(*) AS cnt FROM ontime WHERE DepDel15=1 GROUP BY 연도,월) a;
Q11
avg(c1) from (년,월별 정시 그룹에서 c1로 연,월, 개수(*) 선택) a;
Q12
SELECT OriginCityName, DestCityName, count(*) AS c FROM ontime GROUP BY OriginCityName, DestCityName ORDER BY c DESC LIMIT 10;
Q13
SELECT OriginCityName, count(*) AS c FROM ontime GROUP BY OriginCityName ORDER BY c DESC LIMIT 10;
쿼리에 조인이 포함되어 있음
Q14
SELECT a.연도, c1/c2 FROM ( 연도 선택, 개수()1000 as c1 from ontime WHERE DepDelay>10 GROUP BY Year) a INNER JOIN (연도 선택, ontime GROUP BY Year에서 c2로 계산(*)) b on a.Year=b.Year ORDER BY a.Year;
Q15
SELECT a."연도", c1/c2 FROM ( "연도" 선택, 개수()1000 as c1 FROM Fontime WHERE “DepDelay”>10 GROUP BY “연도”) a INNER JOIN(“연도” 선택, count(*)를 c2 FROM Fontime GROUP BY “연도”로 선택) b on a.”연도”=b. "년도";
표-1: 벤치마크에 사용된 쿼리
쿼리 실행
다음은 다양한 데이터베이스 설정(인덱스가 있거나 없는 PostgreSQL, 기본 ClickHouse 및 clickhousedb_fdw)에서 실행될 때 각 쿼리의 결과입니다. 시간은 밀리초 단위로 표시됩니다.
Q#
PostgreSQL
PostgreSQL(인덱싱됨)
클릭 하우스
clickhousedb_fdw
Q1
27920
19634
23
57
Q2
35124
17301
50
80
Q3
34046
15618
67
115
Q4
31632
7667
25
37
Q5
47220
8976
27
60
Q6
58233
24368
55
153
Q7
30566
13256
52
91
Q8
38309
60511
112
179
Q9
20674
37979
31
81
Q10
34990
20102
56
148
Q11
30489
51658
37
155
Q12
39357
33742
186
1333
Q13
29912
30709
101
384
Q14
54126
39913
124
1364212
Q15
97258
30211
245
259
표-1: 벤치마크에 사용된 쿼리를 실행하는 데 걸린 시간
결과 보기
그래프는 쿼리 실행 시간을 밀리초 단위로 나타내고, X축은 위 표의 쿼리 번호를 나타내며, Y축은 실행 시간을 밀리초 단위로 나타냅니다. clickhousedb_fdw를 사용하여 postgres에서 검색된 ClickHouse 결과 및 데이터가 표시됩니다. 표에서 PostgreSQL과 ClickHouse 사이에는 큰 차이가 있지만 ClickHouse와 clickhousedb_fdw 사이에는 최소한의 차이가 있음을 알 수 있습니다.
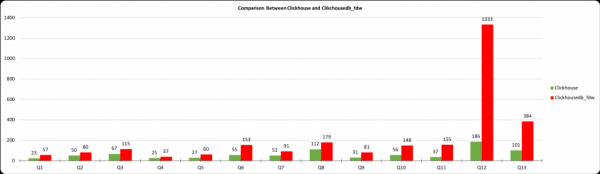
이 그래프는 ClickhouseDB와 clickhousedb_fdw의 차이점을 보여줍니다. 대부분의 쿼리에서 FDW 오버헤드는 Q12를 제외하고 그다지 높지 않으며 거의 중요하지 않습니다. 이 쿼리에는 조인과 ORDER BY 절이 포함되어 있습니다. ORDER BY GROUP/BY 절 때문에 ORDER BY는 ClickHouse로 드롭다운되지 않습니다.
표 2에서는 쿼리 Q12와 Q13의 시간 점프를 볼 수 있습니다. 다시 말하지만 이는 ORDER BY 절로 인해 발생합니다. 이를 확인하기 위해 ORDER BY 절을 사용하거나 사용하지 않고 Q-14 및 Q-15 쿼리를 실행했습니다. ORDER BY 절이 없으면 완료 시간은 259ms이고 ORDER BY 절이 있으면 1364212입니다. 이 쿼리를 디버깅하기 위해 두 쿼리를 모두 설명하고 있으며 여기에 설명 결과가 있습니다.
Q15: ORDER BY 절이 없는 경우
bm=# EXPLAIN VERBOSE SELECT a."Year", c1/c2
FROM (SELECT "Year", count(*)*1000 AS c1 FROM fontime WHERE "DepDelay" > 10 GROUP BY "Year") a
INNER JOIN(SELECT "Year", count(*) AS c2 FROM fontime GROUP BY "Year") b ON a."Year"=b."Year";Q15: ORDER BY 절이 없는 쿼리
QUERY PLAN
Hash Join (cost=2250.00..128516.06 rows=50000000 width=12)
Output: fontime."Year", (((count(*) * 1000)) / b.c2)
Inner Unique: true Hash Cond: (fontime."Year" = b."Year")
-> Foreign Scan (cost=1.00..-1.00 rows=100000 width=12)
Output: fontime."Year", ((count(*) * 1000))
Relations: Aggregate on (fontime)
Remote SQL: SELECT "Year", (count(*) * 1000) FROM "default".ontime WHERE (("DepDelay" > 10)) GROUP BY "Year"
-> Hash (cost=999.00..999.00 rows=100000 width=12)
Output: b.c2, b."Year"
-> Subquery Scan on b (cost=1.00..999.00 rows=100000 width=12)
Output: b.c2, b."Year"
-> Foreign Scan (cost=1.00..-1.00 rows=100000 width=12)
Output: fontime_1."Year", (count(*))
Relations: Aggregate on (fontime)
Remote SQL: SELECT "Year", count(*) FROM "default".ontime GROUP BY "Year"(16 rows)Q14: ORDER BY 절을 사용한 쿼리
bm=# EXPLAIN VERBOSE SELECT a."Year", c1/c2 FROM(SELECT "Year", count(*)*1000 AS c1 FROM fontime WHERE "DepDelay" > 10 GROUP BY "Year") a
INNER JOIN(SELECT "Year", count(*) as c2 FROM fontime GROUP BY "Year") b ON a."Year"= b."Year"
ORDER BY a."Year";Q14: ORDER BY 절을 사용한 쿼리 계획
QUERY PLAN
Merge Join (cost=2.00..628498.02 rows=50000000 width=12)
Output: fontime."Year", (((count(*) * 1000)) / (count(*)))
Inner Unique: true Merge Cond: (fontime."Year" = fontime_1."Year")
-> GroupAggregate (cost=1.00..499.01 rows=1 width=12)
Output: fontime."Year", (count(*) * 1000)
Group Key: fontime."Year"
-> Foreign Scan on public.fontime (cost=1.00..-1.00 rows=100000 width=4)
Remote SQL: SELECT "Year" FROM "default".ontime WHERE (("DepDelay" > 10))
ORDER BY "Year" ASC
-> GroupAggregate (cost=1.00..499.01 rows=1 width=12)
Output: fontime_1."Year", count(*) Group Key: fontime_1."Year"
-> Foreign Scan on public.fontime fontime_1 (cost=1.00..-1.00 rows=100000 width=4)
Remote SQL: SELECT "Year" FROM "default".ontime ORDER BY "Year" ASC(16 rows)출력
이러한 실험 결과는 ClickHouse가 정말 좋은 성능을 제공하고 clickhousedb_fdw는 PostgreSQL에서 ClickHouse의 성능 이점을 제공한다는 것을 보여줍니다. clickhousedb_fdw를 사용할 때 약간의 오버헤드가 있기는 하지만 이는 무시할 수 있으며 ClickHouse 데이터베이스에서 기본적으로 실행하여 얻을 수 있는 성능과 비슷합니다. 이는 또한 PostgreSQL의 fdw가 탁월한 결과를 제공한다는 것을 확인시켜 줍니다.
Clickhouse를 통한 텔레그램 채팅
PostgreSQL을 사용한 텔레그램 채팅
출처 : habr.com
