

Ez dixwazim yekem ezmûna xweya serketî ya vegerandina databasek Postgres bi fonksiyona tevahî bi we re parve bikim. Min nîv sal berê bi Postgres DBMS re nas kir; berî wê di rêveberiya databasê de qet ezmûna min tunebû.

Ez wekî endezyarek nîv-DevOps di pargîdaniyek mezin a IT-ê de dixebitim. Pargîdaniya me ji bo karûbarên bargiraniyê nermalava pêşdebir dike, û ez ji performans, parastin û bicîhkirinê berpirsiyar im. Ji min re peywirek standard hate dayîn: nûvekirina serîlêdanek li ser yek serverê. Serlêdan di Django de tê nivîsandin, di dema nûvekirinê de koçberî têne kirin (guheztinên di avahiya databasê de), û berî vê pêvajoyê em bi bernameya standard pg_dump, tenê di rewşê de, databasek tam hildigirin.
Di dema avêtina avêtinê de xeletiyek nediyar derket (Guhertoya Postgres 9.5):
pg_dump: Oumping the contents of table “ws_log_smevlog” failed: PQgetResult() failed.
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989
pg_dump: The command was: COPY public.ws_log_smevlog [...]
pg_dunp: [parallel archtver] a worker process dled unexpectedly şaşî "rûpel nederbasdar di blokê de" behsa pirsgirêkên di asta pergala pelan de, ku pir xirab e. Li ser forumên cihêreng hate pêşniyar kirin ku bikin VALIYA TEMÛ bi vebijêrk sifir_zerar_rûpel ji bo çareserkirina vê pirsgirêkê. Belê, em biceribînin ...
Amadekirina ji bo Recovery
ATTENTION! Berî her hewildanek ji bo vegerandina databasa xwe, pê ewle bin ku hûn paşvekêşana Postgres bigirin. Ger we makîneyek virtual heye, databasê rawestîne û wêneyek bikişîne. Heke ne gengaz e ku wêneyek bikişîne, databasê rawestîne û naveroka pelrêça Postgres (tevî pelên wal jî) li cîhek ewle kopî bike. Ya sereke di karsaziya me de ew e ku em tiştan xirab nekin. Xwendin .
Ji ber ku databas bi gelemperî ji min re dixebitî, min xwe bi danûstendinek daneya birêkûpêk sînordar kir, lê tabloya bi daneyên zirardar veqetand (vebijark -T, --exclude-table=TABLE di pg_dump).
Pêşkêşkar fîzîkî bû, ne gengaz bû ku wêneyek bikişîne. Piştgir hat rakirin, em bimeşin.
Kontrola pergala pelê
Berî ku em hewl bidin ku databasê sererast bikin, pêdivî ye ku em pê ewle bin ku her tişt bi pergala pelê bixwe re rêkûpêk e. Û di rewşên xeletiyan de, wan rast bikin, ji ber ku wekî din hûn dikarin tiştan xirabtir bikin.
Di doza min de, pergala pelê ya bi databasê re hate saz kirin "/srv" û tîp ext4 bû.
Rawestandina databasê: rawestana systemctl postgresql@9.5-main.service û kontrol bikin ku pergala pelan ji hêla kesek ve nayê bikar anîn û bi karanîna fermanê dikare were rakirin lsof:
lsof +D /srv
Di heman demê de neçar ma ku databasa redis rawestim, ji ber ku ew jî bikar tîne "/srv". Dû re ez rakirim / srv (hejmar).
Pergala pelê bi karanîna karûbar hate kontrol kirin e2fsck bi guhertoya -f (Kontrolkirina zorê her çend pergala pelan paqij were nîşankirin):
Piştre, bi karanîna karûbar dumpe2fs (sudo dumpe2fs /dev/mapper/gu2—sys-srv | grep kontrol kirin) hûn dikarin piştrast bikin ku kontrol bi rastî hatîye kirin:

e2fsck dibêje ku di asta pergala pelê ext4 de tu pirsgirêk nehatin dîtin, ku tê vê wateyê ku hûn dikarin hewl bidin ku databasê sererast bikin, an bêtir vegerin valahiya tije (bê guman, hûn hewce ne ku pergala pelan paşde vegerînin û databasê dest pê bikin).
Ger serverek weya laşî heye, pê ewle bin ku hûn rewşa dîskan kontrol bikin (bi rêya smartctl -a /dev/XXX) an kontrolkerê RAID-ê da ku pê ewle bibin ku pirsgirêk ne di asta hardware de ye. Di doza min de, RAID derket "hardware", ji ber vê yekê min ji rêveberê herêmî pirsî ku rewşa RAID-ê kontrol bike (pêşkêşkar çend sed kîlometreyan ji min dûr bû). Wî got ku tu xeletî tune ne, ev tê vê wateyê ku em dikarin bê guman dest bi restorasyonê bikin.
Hewldan 1: zero_zerar_rûpel
Em bi navgîniya psql re bi hesabek ku xwediyê mafên superbikarhêner e bi databasê ve girêdidin. Em hewceyê superbikarhênerek in, ji ber ku ... dibe sifir_zerar_rûpel tenê ew dikare biguhere. Di doza min de ew postgres e:
psql -h 127.0.0.1 -U postgres -s [base_name]
Dibe sifir_zerar_rûpel ji bo paşguhkirina xeletiyên xwendinê hewce ne (ji malpera postgrespro):
Dema ku PostgreSQL sernavek rûpelek xirab dibîne, ew bi gelemperî xeletiyek radigihîne û danûstendina heyî betal dike. Ger zero_damaged_pages çalak be, pergal li şûna hişyariyekê dide, rûpela xisar di bîrê de sifir dike, û pêvajo berdewam dike. Ev tevger daneyan, ango hemî rêzikên di rûpela zirarê de hilweşîne.
Em vebijarkê çalak dikin û hewl didin ku valahiyek tam a tabloyan bikin:
VACUUM FULL VERBOSE 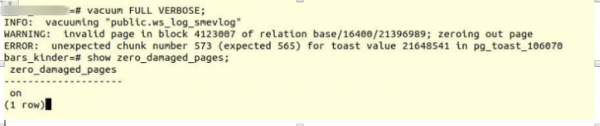
Mixabin, şansê xerab.
Em rastî xeletiyek bi heman rengî hatin:
INFO: vacuuming "“public.ws_log_smevlog”
WARNING: invalid page in block 4123007 of relation base/16400/21396989; zeroing out page
ERROR: unexpected chunk number 573 (expected 565) for toast value 21648541 in pg_toast_106070- Mekanîzmayek ji bo hilanîna "daneyên dirêj" di Poetgres de heke ew li ser yek rûpelê (8 kb-ya xwerû) cîh neke.
Hewldan 2: ji nû ve rêzkirin
Şîreta yekem ji Google re alîkarî nekir. Piştî çend hûrdeman lêgerînê, min tîpa duyemîn dît - çêkirin reindex maseya xerabûyî. Min ev şîret li gelek cihan dît, lê ew bawerî neanî. Ka em ji nû ve îndeks bikin:
reindex table ws_log_smevlog 
reindex bê pirsgirêk temam kirin.
Lêbelê, ev alîkarî nekir, VACUUM FULL bi xeletiyek wisa ket. Ji ber ku ez bi têkçûnan ve hatî bikar anîn, min dest pê kir ku li ser Înternetê li şîretan bigerim û rastî tiştek balkêş hat .
Hewldan 3: HILBIJARTIN, SÎNOR, JÎ
Gotara li jor pêşniyar kir ku rêz bi rêz li tabloyê binihêrin û daneyên pirsgirêk derxînin. Pêşî hewce bû ku em li hemî rêzan binêrin:
for ((i=0; i<"Number_of_rows_in_nodes"; i++ )); do psql -U "Username" "Database Name" -c "SELECT * FROM nodes LIMIT 1 offset $i" >/dev/null || echo $i; doneDi rewşa min de, tablo tê de ye 1 628 991 xetên! Pêwîst bû ku baş lênihêrîn , lê ev mijarek ji bo nîqaşek cuda ye. Roja şemiyê bû, min ev emir di tmux de kir û çû razam:
for ((i=0; i<1628991; i++ )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog LIMIT 1 offset $i" >/dev/null || echo $i; doneSerê sibê min biryar da ku kontrol bikim ka tişt çawa diçin. Bi sosretiya min, min kifş kir ku piştî 20 demjimêran, tenê 2% ji daneyan hatine qefilandin! Min nexwest 50 roj li bendê bimînim. Têkçûnek din a tevahî.
Lê min dev jê berneda. Min meraq kir ku çima şopandin ewqas dirêj girt. Ji belgeyê (dîsa li ser postgrespro) min dît:
OFFSET diyar dike ku berî ku dest bi derxistina rêzan bike, hejmara rêzên diyarkirî derbas bike.
Ger hem OFFSET û hem jî LIMIT bêne diyar kirin, pergal pêşî rêzên OFFSET berdide û dûv re dest bi jimartina rêzan ji bo astengiya LIMIT dike.Dema ku LIMIT bikar bînin, girîng e ku meriv ORDER BY-bendek jî bikar bîne da ku rêzikên encam bi rêzek taybetî werin vegerandin. Wekî din, dê binekomên rêzikan ên nediyar werin vegerandin.
Eşkere ye ku emrê jorîn xelet bû: yekem, tune bû ferman bi, encam dibe ku xelet be. Ya duyemîn, Postgres pêşî neçar ma ku rêzên OFFSET bişopîne û biavêje, û bi zêdebûnê BERSVAN hilberî dê hê bêtir kêm bibe.
Hewldan 4: Di forma nivîsê de xêzek derxînin
Dûv re ramanek xuya ya jêhatî hate hişê min: di forma nivîsê de bertekek bavêje û rêza tomarkirî ya paşîn analîz bike.
Lê pêşî, em li avahiya tabloyê binêrin. ws_log_smevlog:
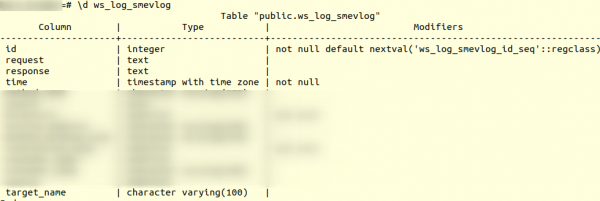
Di rewşa me de stûnek me heye "Id", ku nasnameya yekta (hejmar) rêzê dihewand. Plan wiha bû:
- Em di forma nivîsê de (di forma fermanên sql de) dest bi avêtina avêtinê dikin.
- Di demek diyarkirî de, dê dump ji ber xeletiyek were qut kirin, lê pelê nivîsê dê dîsa jî li ser dîskê were tomar kirin
- Em li dawiya pelê nivîsê dinêrin, bi vî rengî em nasnavê (id) ya rêza paşîn a ku bi serfirazî hate rakirin dibînin.
Min di forma nivîsê de dest bi kişandina dump kir:
pg_dump -U my_user -d my_database -F p -t ws_log_smevlog -f ./my_dump.dumpHilber, wekî ku dihat hêvîkirin, bi heman xeletiyê hate qut kirin:
pg_dump: Error message from server: ERROR: invalid page in block 4123007 of relatton base/16490/21396989 Bêtir bi rê ve terrî Min li dawiya çolê nêrî (dûvik -5 ./my_dump.dump) keşif kir ku çol li ser xeta bi id qut bûye 186 525. "Ji ber vê yekê pirsgirêk di rêza id 186 526 de ye, ew şikestî ye, û pêdivî ye ku were jêbirin!" - Ez difikirîm. Lê, pirsek ji databasê re kirin:
«hilbijêre * ji ws_log_smevlog ku id=186529"Derket ku her tişt bi vê xetê re baş bû... Rêzên bi nîşaneyên 186 - 530 jî bê pirsgirêk xebitîn. "Fikrekî birûmet" din têk çû. Dûv re min fêm kir ku çima ev yek çêbû: dema ku daneyan ji tabloyek jêbirin û biguhezînin, ew bi fizîkî nayên jêbirin, lê wekî "civînên mirî" têne nîşankirin, paşê tê autovacuum û van rêzan wekî jêbirin nîşan dide û dihêle ku ev rêz ji nû ve werin bikar anîn. Ji bo fêmkirinê, heke daneyên di tabloyê de biguhezin û otovacuum were çalak kirin, wê hingê ew bi rêz nayê hilanîn.
Hewldan 5: HILBIJARTIN, JI, WHERE id=
Têkçûn me xurtir dikin. Divê hûn ti carî dev jê bernedin, divê hûn heta dawiyê biçin û bi xwe û şiyanên xwe bawer bikin. Ji ber vê yekê min biryar da ku vebijarkek din biceribînim: tenê li hemî tomarên databasê yek bi yek binihêrim. Fêrbûna avahiya tabloya min (li jor binêre), me qadek id-ê heye ku yekta ye (mifteya seretayî). Di tabloyê de 1 rêzên me hene û id rêz in, ku tê vê wateyê ku em tenê dikarin wan yek bi yek derbas bikin:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneGer kesek fêm neke, ferman bi vî rengî dixebite: ew rêz bi rêz tabloyê dişoxilîne û stdout dişîne. / dev / null, lê heke fermana SELECT têk biçe, wê gavê metna çewtiyê tê çap kirin (stderr ji konsolê re tê şandin) û xêzek ku xeletî tê de tê çap kirin (bi xêra ||, ev tê vê wateyê ku bijarte pirsgirêk hebûn (koda vegerê ya fermanê ne 0)).
Ez bextewar bûm, min li qadê îndeks hatin afirandin id:

Ev tê vê wateyê ku dîtina rêzek bi nasnameya xwestinê divê pir dem negire. Di teoriyê de divê ew bixebite. Belê, em fermanê têxin hundur tmux û em herin razanê.
Serê sibê min dît ku nêzîkî 90 navnîşan hatine dîtin, ku tenê ji 000% zêdetir e. Encamek hêja dema ku bi rêbaza berê (5%) re were berhev kirin! Lê min nexwest 2 rojan li bendê bim...
Hewldana 6: SELECT, JI, WHERE id >= û id <
Xerîdar xwediyê serverek hêja bû ku ji databasê re hatî veqetandin: dual-processor Intel Xeon E5-2697 v2, li cihê me bi qasî 48 têlan hebûn! Barkirina serverê navîn bû; me dikaribû bi qasî 20 mijaran bêyî pirsgirêk dakêşin. Di heman demê de têra RAM jî hebû: bi qasî 384 gigabayt!
Ji ber vê yekê, pêdivî ye ku ferman were paralel kirin:
for ((i=1; i<1628991; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneLi vir îmkan bû ku meriv nivîsek xweşik û xweşik binivîsîne, lê min rêbaza paralelkirina herî bilez hilbijart: bi destan rêza 0-1628991 li navberên 100 tomaran veqetîne û 000 fermanên formê ji hev cuda bimeşîne:
for ((i=N; i<M; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; doneLê ev ne hemû ye. Di teoriyê de, girêdana bi databasê re hin dem û çavkaniyên pergalê jî digire. Girêdana 1 ne pir jîr bû, hûn ê bipejirînin. Ji ber vê yekê, bila em 628 rêzan li şûna girêdana yek bi yek vegerînin. Di encamê de, tîm bi vî rengî veguherand:
for ((i=N; i<M; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; doneDi danişîna tmux de 16 pencereyan vekin û fermanan bimeşînin:
1) for ((i=0; i<100000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 2) for ((i=100000; i<200000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done … 15) for ((i=1400000; i<1500000; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done 16) for ((i=1500000; i<1628991; i=$((i+1000)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id>=$i and id<$((i+1000))" >/dev/null || echo $i; done
Rojek şûnda min encamên yekem stand! Ango (nirxên XXX û ZZZ êdî nayên parastin):
ERROR: missing chunk number 0 for toast value 37837571 in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value XXX in pg_toast_106070
829000
ERROR: missing chunk number 0 for toast value ZZZ in pg_toast_106070
146000Ev tê wê wateyê ku sê rêzan xeletiyek dihewîne. Nasnameyên qeydên problematîk ên yekem û duyemîn di navbera 829 û 000 de bûn, nasnameyên ya sêyemîn di navbera 830 û 000 de bûn. Piştre, em bi tenê pêdivî bû ku em nirxa rastîn a qeydên pirsgirêk bibînin. Ji bo kirina vê yekê, em bi pêngavek 146-ê bi tomarên pirsgirêkî re li rêza xwe dinihêrin û nasnameyê nas dikin:
for ((i=829000; i<830000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number 2 (expected 0) for toast value 37837843 in pg_toast_106070 829449 for ((i=146000; i<147000; i=$((i+1)) )); do psql -U my_user -d my_database -c "SELECT * FROM ws_log_smevlog where id=$i" >/dev/null || echo $i; done 829417 ERROR: unexpected chunk number ZZZ (expected 0) for toast value XXX in pg_toast_106070 146911
Dawiya xweş
Me xetên pirsgirêk dîtin. Em bi psql diçin nav databasê û hewl didin ku wan jêbirin:
my_database=# delete from ws_log_smevlog where id=829417;
DELETE 1
my_database=# delete from ws_log_smevlog where id=829449;
DELETE 1
my_database=# delete from ws_log_smevlog where id=146911;
DELETE 1Bi sosretiya min, têketin bêyî vebijarkê jî bêyî pirsgirêk hatin jêbirin sifir_zerar_rûpel.
Dûv re min bi databasê ve girêda, kir VACUUM FULL (Ez difikirim ku ne hewce bû ku meriv vê yekê bike), û di dawiyê de min bi serfirazî hilanînê bi kar anî pg_dump. Çêlek bê xeletî hate girtin! Pirsgirêk bi vî rengî ehmeqî çareser bû. Kêfxweşiyê sînor nas nedikir, piştî ewqas têkçûnan me karî çareseriyekê peyda bikin!
Pejirandin û Encam
Bi vî rengî ezmûna min a yekem a sererastkirina databasek rastîn a Postgres derket holê. Ez ê vê serpêhatiyê demek dirêj bi bîr bînim.
Û di dawiyê de, ez dixwazim spasiya PostgresPro bikim ji bo wergerandina belgeyan bi rûsî û ji bo , ku di dema analîzkirina pirsgirêkê de gelek alîkarî kir.
Source: www.habr.com
