


Meriv çawa vê gotarê dixwîne: Ez lêborînê dixwazim ji ber ku nivîs ewqas dirêj û kaotîk bû. Ji bo ku hûn wextê xilas bikin, ez her beşê bi pêşgotinek "Ez Fêr bûm" dest pê dikim, ku naveroka beşê di yek an du hevokan de kurt dike.
"Tenê çareseriyê nîşanî min bide!" Ger hûn tenê dixwazin bibînin ku ez ji ku derê hatim, wê hingê derbasî beşa "Bêtir Dahêner bibin", lê ez difikirim ku xwendina li ser têkçûnê balkêştir û bikêrtir e.
Min di van demên dawî de peywirdar kir ku pêvajoyek ji bo hilberandina hejmareke mezin a rêzikên DNA yên xav (ji hêla teknîkî ve çîpek SNP) saz bikim. Pêdivî bû ku zû bi zû daneyên li ser cîhek genetîkî ya diyarkirî (ku jê re SNP tê gotin) ji bo modela paşîn û karên din bistînin. Bi karanîna R û AWK, min karibû ku daneyan bi rengek xwezayî paqij bikim û birêxistin bikim, pir lezkirina pêvajoya pirsê. Ev ji bo min ne hêsan bû û gelek dubareyan hewce dikir. Ev gotar dê ji we re bibe alîkar ku hûn ji hin xeletiyên min dûr bixin û nîşanî we bidin ku min çi bi dawî kir.
Pêşîn, hin ravekirinên destpêkê.
Daneyên
Navenda hilberandina agahdariya genetîkî ya zanîngeha me di forma TSV ya 25 TB de daneyan peyda kir. Min ew di nav 5 pakêtan de dabeş kirin, ji hêla Gzip ve hatî berhev kirin, ku her yek ji wan nêzî 240 pelên çar gigabyte hene. Her rêzek daneyên yek SNP-ê ji yek kesan vedihewand. Bi tevahî, daneyên li ser ~ 2,5 mîlyon SNP û ~ 60 hezar kes hatine şandin. Digel agahdariya SNP-ê, pelan gelek stûnên bi hejmar hene ku taybetmendiyên cihêreng nîşan didin, wek tundiya xwendinê, pirbûna alelên cihêreng, hwd. Bi tevahî nêzîkî 30 stûnên bi nirxên bêhempa hebûn.
Armanc
Mîna her projeyek rêveberiya daneyê, ya herî girîng ew bû ku were destnîşankirin ka dê data çawa were bikar anîn. Di vê rewşê de em ê bi piranî model û rêçikên xebatê ji bo SNP-ê li ser bingeha SNP-ê hilbijêrin. Ango, em ê di carekê de tenê li ser yek SNP-ê hewceyê daneyan bikin. Diviya bû ku ez fêr bibim ka meriv çawa hemî tomarên ku bi yek ji 2,5 mîlyon SNP-ê ve girêdayî ne bi hêsanî, zû û erzan vegere.
Çawa vê yekê nekin
Ji bo vegotina klîşeyek minasib:
Min hezar carî têk neçû, min tenê hezar rê keşif kir ku ez ji parzûna komek daneyan di forma pirs-hevalê de dûr bixim.
Pêşî biceribînin
Ez çi fêr bûm: Rêyek erzan tune ku meriv 25 TB di yek carê de parsek bike.
Piştî ku li Zanîngeha Vanderbilt qursa "Rêbazên Pêşkeftî Ji bo Pêvajoya Daneyên Mezin" girt, ez pê bawer bûm ku hîle di çenteyê de bû. Dibe ku ew ê yek an du demjimêran bigire ku servera Hive saz bike da ku hemî daneyan bimeşîne û encamê rapor bike. Ji ber ku daneyên me di AWS S3 de têne hilanîn, min karûbar bikar anî , ku dihêle hûn pirsên Hive SQL li daneyên S3 bicîh bikin. Hûn ne hewce ne ku komek Hive saz bikin/berbikin, û hûn jî tenê ji bo daneyên ku hûn lê digerin didin.
Piştî ku min daneyên xwe û formata wê nîşanî Athena da, min hin ceribandinên bi pirsên weha re kirin:
select * from intensityData limit 10;Û zû encamên baş-sazkirî wergirtin. Amade.
Heya ku me hewl da ku di xebata xwe de daneyan bikar bînin ...
Ji min hat xwestin ku ez hemî agahdariya SNP-ê derxim da ku modela li ser ceribandinê bikim. Min pirs kir:
select * from intensityData
where snp = 'rs123456';...û dest pê kir li bendê. Piştî heşt hûrdeman û zêdetirî 4 TB daneyên daxwazkirî, min encam wergirt. Athena li gorî qebareya daneyên ku hatine dîtin, 5 $ ji bo her terabyte. Ji ber vê yekê ev daxwaza yekane 20 $ û heşt hûrdeman li bendê bû. Ji bo ku em modelê li ser hemî daneyan bimeşînin, diviyabû em 38 salan li bendê bimînin û 50 mîlyon dolar bidin, diyar e ku ev yek ji me re ne guncaw bû.
Pêwîst bû ku Parket bikar bînin ...
Ez çi fêr bûm: Hay ji mezinahiya pelên Parket û rêxistina wan hebin.
Min pêşî hewl da ku bi veguheztina hemî TSV-an re rewşê rast bikim . Ew ji bo xebitandina bi berhevokên daneya mezin re hêsan in ji ber ku agahdariya di wan de di forma stûnî de têne hilanîn: her stûn di bîra xwe / beşa dîskê de ye, berevajî pelên nivîsê, ku tê de rêzik hêmanên her stûnê dihewîne. Û heke hûn hewce ne ku tiştek bibînin, wê hingê tenê stûna pêwîst bixwînin. Wekî din, her pel rêzek nirxan di stûnekê de hilîne, ji ber vê yekê heke nirxa ku hûn lê digerin ne di rêza stûnê de be, Spark dê wextê xwe winda neke ku tevahiya pelê bişopîne.
Min karekî hêsan kir da ku TSV-yên me veguherînin Parquet û pelên nû avêtin Athena. Nêzî 5 saetan girt. Lê gava ku min daxwaz kir, ji bo temamkirina wê bi heman dem û hindik hindik drav girt. Rastî ev e ku Spark, hewl dide ku peywirê xweşbîn bike, bi tenê yek perçeyek TSV vekir û ew xist nav perçeya xwe ya Parquet. Û ji ber ku her perçeyek têra xwe mezin bû ku tevaya tomarên gelek kesan dihewîne, her pelek hemî SNP-an vedihewîne, ji ber vê yekê Spark neçar ma ku hemî pelan veke da ku agahdariya ku jê re hewce dike derxe.
Balkêş e, celebê kompresyonê ya xwerû (û tê pêşniyar kirin) ya Parquet, şil, nayê dabeş kirin. Ji ber vê yekê, her îcrakar li ser karê vekêşandin û dakêşana danûstendina tevahî 3,5 GB asê mabû.
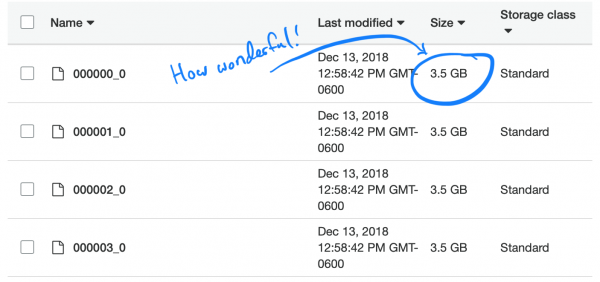
Ka em pirsgirêkê fam bikin
Ez çi fêr bûm: Rêzkirin dijwar e, nemaze ger dane belav kirin.
Ji min re xuya bû ku êdî min eslê pirsgirêkê fêm kir. Min tenê hewce kir ku daneyan li gorî stûna SNP-ê, ne ji hêla mirovan ve rêz bikim. Dûv re çend SNP dê di perçeyek daneya veqetandî de werin hilanîn, û dûv re fonksiyona "aqilmend" ya Parquet "tenê heke nirx di rêzê de be vedibe" dê bi hemî rûmeta xwe xwe nîşan bide. Mixabin, veqetandina bi mîlyaran rêzên ku li komekê belav bûne wekî karekî dijwar derketiye holê.
Ez li zanîngehê dersa algorîtmayan digirim: "Ew, kes guh nade tevliheviya hesabkirinê ya van hemî algorîtmayên dabeşkirinê"
Ez hewl didim ku li ser stûnek di 20TB de rêz bikim tablo: "Çima ev qas dirêj dibe?" têkoşîn.
- Nick Strayer (@NicholasStrayer)
AWS bê guman naxwaze ji ber sedema "Ez xwendekarek dilşewat im". Piştî ku min li ser Amazon Glue veqetand, ew 2 rojan bazda û têk çû.
Li ser dabeşkirinê çi ye?
Ez çi fêr bûm: Dabeşkirinên li Spark divê hevseng bin.
Dûv re min ramana dabeşkirina daneyan di kromozoman de hat. 23 ji wan hene (û çendên din jî heke hûn DNAya mîtokondrî û herêmên nenexşekirî bihesibînin).
Ev ê dihêle ku hûn daneyan li perçeyên piçûktir veqetînin. Ger hûn di skrîpta Glue de tenê yek rêzek li fonksiyona hinardekirina Spark zêde bikin partition_by = "chr", wê hingê divê data di nav kepçeyan de bêne dabeş kirin.
Genom ji gelek perçeyên ku jê re kromozom tê gotin pêk tê.
Mixabin, ew kar nekir. Kromozom xwedî mezinahiyên cihê ne, ku tê wateya rêjeyên cûda yên agahdariyê. Ev tê vê wateyê ku karên ku Spark ji karkeran re şandiye hevseng nebûne û hêdî hêdî temam bûne ji ber ku hin girêk zû qediyan û bêkar bûn. Lêbelê, peywir bi dawî bûn. Lê dema ku yek SNP dipirsin, bêhevsengiyê dîsa bû sedema pirsgirêkan. Mesrefa hilanîna SNP-ên li ser kromozomên mezin (ango, cihê ku em dixwazin daneyan bistînin) bi qasî 10-an kêm bûye. Gelek, lê ne bes e.
Ger em wê li beşên piçûktir jî parve bikin?
Ez çi fêr bûm: Qet hewl nedin ku 2,5 mîlyon dabeşan bikin.
Min biryar da ku ez herim derve û her SNP dabeş bikim. Vê yekê piştrast kir ku dabeşên mezinahiya wekhev bûn. EV RAKEKE XERAB BÛ. Min Glue bikar anî û rêzek bêguneh lê zêde kir partition_by = 'snp'. Kar dest pê kir û dest bi îcrayê kir. Rojek şûnda min kontrol kir û dît ku hîn jî tiştek ji S3 re nehatiye nivîsandin, ji ber vê yekê min peywir kuşt. Wusa dixuye ku Glue pelên navîn li cîhek veşartî li S3 dinivîsî, gelek pelan, dibe ku çend mîlyon. Di encamê de, xeletiya min ji hezar dolaran zêdetir bû û ji şêwirmendê min re ne xweş bû.
Dabeşkirin + dabeşkirin
Ez çi fêr bûm: Rêzkirin hîn jî dijwar e, wekî ahengkirina Spark.
Hewldana min a paşîn a dabeşkirinê bi dabeşkirina kromozoman û dûv re veqetandina her dabeşkirinê ve girêdayî bû. Di teoriyê de, ev ê her pirsê bileztir bike ji ber ku daneyên SNP-ya xwestinê diviyabû di nav çend perçeyên Parquet de di nav rêzek diyar de be. Mixabin, birêkûpêkkirina daneyên dabeşkirî jî karekî dijwar derket. Wekî encamek, min ji bo komek xwerû veguherî EMR-ê û heşt mînakên hêzdar (C5.4xl) û Sparklyr bikar anîn da ku karek maqûltir biafirînim…
# Sparklyr snippet to partition by chr and sort w/in partition
# Join the raw data with the snp bins
raw_data
group_by(chr) %>%
arrange(Position) %>%
Spark_write_Parquet(
path = DUMP_LOC,
mode = 'overwrite',
partition_by = c('chr')
)... lê dîsa jî ev kar bi dawî nebû. Min ew bi awayên cihêreng mîheng kir: veqetandina bîranînê ji bo her îcrakarê pirsê zêde kir, girêkên bi bîranînek mezin bikar anîn, guhêrbarên weşanê (guhêrbarên weşanê) bikar anîn, lê her carê ev bûn nîv-pîvan, û hêdî hêdî îcrakar dest pê kirin. heta ku her tişt raweste têk biçe.
Nûvekirin: Ji ber vê yekê ew dest pê dike.
- Nick Strayer (@NicholasStrayer)
Ez afirînertir dibim
Ez çi fêr bûm: Carinan daneyên taybetî hewceyê çareseriyên taybetî ne.
Her SNP nirxek pozîsyonek heye. Ev jimarek li gorî hejmara bazên li ser kromozoma wê ye. Ev rêgezek xweş û xwezayî ye ku daneyên me birêxistin dike. Di destpêkê de min xwest ku li gorî herêmên her kromozomê dabeş bikim. Mînakî, pozîsyonên 1 - 2000, 2001 - 4000, hwd. Lê pirsgirêk ev e ku SNP bi rengek wekhev li ser kromozoman nayên belav kirin, ji ber vê yekê mezinahiya komê dê pir cûda bibe.
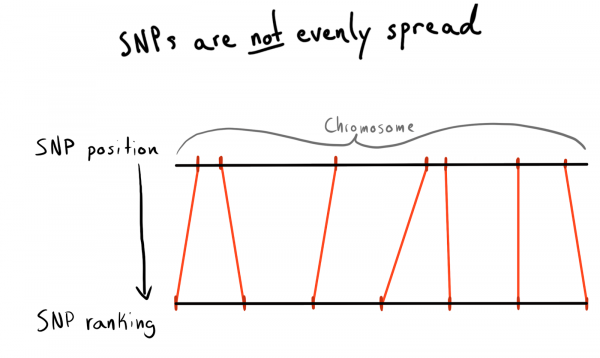
Di encamê de, ez hatim veqetandinek pozîsyonan li ser kategoriyan (pile). Bi karanîna daneyên jixwe dakêşandî, min daxwazek kir ku ez navnîşek SNP-yên bêhempa, pozîsyon û kromozomên wan bistînim. Dûv re min daneyên di hundurê her kromozomê de rêz kir û SNP li komên (bin) bi mezinahiyek diyarkirî berhev kir. Em bêjin her yek 1000 SNP. Vê yekê têkiliya SNP-bi-kom-per-kromozomê da min.
Di dawiyê de, min komên (bin) ji 75 SNP çêkir, sedem dê li jêr were ravekirin.
snp_to_bin <- unique_snps %>%
group_by(chr) %>%
arrange(position) %>%
mutate(
rank = 1:n()
bin = floor(rank/snps_per_bin)
) %>%
ungroup()Pêşîn bi Spark biceribînin
Ez çi fêr bûm: Kombûna çirûskê zû ye, lê dabeşkirin dîsa jî biha ye.
Min xwest ez vê çarçoweya daneya piçûk (2,5 mîlyon rêz) di Spark de bixwînim, wê bi daneyên xav re bigihînim hev, û dûv re wê bi stûna nû hatî zêdekirin ve parve bikim. bin.
# Join the raw data with the snp bins
data_w_bin <- raw_data %>%
left_join(sdf_broadcast(snp_to_bin), by ='snp_name') %>%
group_by(chr_bin) %>%
arrange(Position) %>%
Spark_write_Parquet(
path = DUMP_LOC,
mode = 'overwrite',
partition_by = c('chr_bin')
)
Min bikar anî sdf_broadcast(), ji ber vê yekê Spark dizane ku divê ew çarçoveya daneyê ji hemî girêkan re bişîne. Ev bikêr e ger daneya bi mezinahî piçûk be û ji bo hemî karan hewce be. Wekî din, Spark hewl dide ku biaqil be û li gorî hewcedariyê daneyan belav dike, ku dibe sedema hêdîbûnê.
Û dîsa, fikra min bi ser neket: peywiran demekê xebitîn, sendîka qedandin, û dûv re, mîna îcrakarên ku bi dabeşkirinê hatine destpêkirin, wan dest bi têkçûnê kirin.
Zêdekirina AWK
Ez çi fêr bûm: Dema ku te hînî bingehîn kirin xew neke. Bê guman kesek jixwe di salên 1980-an de pirsgirêka we çareser kiriye.
Heya vê gavê, sedema hemî têkçûnên min ên bi Spark re tevliheviya daneyên di komê de bû. Dibe ku rewş bi pêş-dermankirinê were baştir kirin. Min biryar da ku ez hewl bidim ku daneyên nivîsa xav li stûnên kromozoman dabeş bikim, ji ber vê yekê min hêvî kir ku Spark daneyên "pêş-parçekirî" peyda bikim.
Min li StackOverflow geriya ku meriv çawa bi nirxên stûnê veqetîne û dît Bi AWK re hûn dikarin pelek nivîsê li gorî nirxên stûnê bi nivîsandina wê di skrîptekê de li şûna şandina encaman veqetînin. stdout.
Min skrîptek Bash nivîsî da ku wê biceribînim. Yek ji TSV-yên pakkirî dakêşand, dûv re bi karanîna wê vekir gzip û şandin awk.
gzip -dc path/to/chunk/file.gz |
awk -F 't'
'{print $1",..."$30">"chunked/"$chr"_chr"$15".csv"}'Ew xebitî!
Dagirtina kokan
Ez çi fêr bûm: gnu parallel - Tiştekî efsûnî ye, divê her kes jê bi kar bîne.
Veqetandin pir hêdî bû û gava ku min dest pê kir htopji bo kontrolkirina karanîna mînakek hêzdar (û biha) EC2, derket holê ku min tenê yek bingehek û bi qasî 200 MB bîranîn bikar tîne. Ji bo ku pirsgirêk çareser bibe û gelek drav winda nekin, diviya bû ku em fêhm bikin ka meriv çawa xebata paralel bikin. Xwezî, di pirtûkek bêkêmasî de Min beşa Jeron Janssens li ser paralelbûnê dît. Ez jê fêr bûm gnu parallel, rêbazek pir maqûl e ji bo pêkanîna multithreading li Unix.

Dema ku min bi karanîna pêvajoya nû dest bi dabeşkirinê kir, her tişt baş bû, lê dîsa jî tengahiyek hebû - dakêşana tiştên S3 li ser dîskê ne pir bilez bû û ne bi tevahî paralel bû. Ji bo rastkirina vê, min ev kir:
- Min fêhm kir ku gengaz e ku meriv qonaxa dakêşana S3 rasterast di lûleyê de bicîh bike, bi tevahî hilanîna navberê ya li ser dîskê ji holê rake. Ev tê vê wateyê ku ez dikarim ji nivîsandina daneyên xav li ser dîskê dûr bixim û li ser AWS hilanînê hê piçûktir, û ji ber vê yekê erzantir bikar bînim.
- kom
aws configure set default.s3.max_concurrent_requests 50Hejmara mijarên ku AWS CLI bikar tîne pir zêde kir (ji hêla xwerû 10 hene). - Min veguherand mînakek EC2 ku ji bo leza torê xweşbînkirî ye, bi tîpa n di nav de. Min dît ku windakirina hêza pêvajoyê dema ku n-nimûnan bikar tînin ji zêdebûna leza barkirinê bêtir tê telafî kirin. Ji bo piraniya karan min c5n.4xl bikar anî.
- Guhertin
gzipli ser , ev amûrek gzip-ê ye ku dikare tiştên xweş bike da ku peywira destpêkê ya ne-paralelîzekirî ya vekêşana pelan paralel bike (vê yekê herî kêm alîkarî kir).
# Let S3 use as many threads as it wants
aws configure set default.s3.max_concurrent_requests 50
for chunk_file in $(aws s3 ls $DATA_LOC | awk '{print $4}' | grep 'chr'$DESIRED_CHR'.csv') ; do
aws s3 cp s3://$batch_loc$chunk_file - |
pigz -dc |
parallel --block 100M --pipe
"awk -F 't' '{print $1",..."$30">"chunked/{#}_chr"$15".csv"}'"
# Combine all the parallel process chunks to single files
ls chunked/ |
cut -d '_' -f 2 |
sort -u |
parallel 'cat chunked/*_{} | sort -k5 -n -S 80% -t, | aws s3 cp - '$s3_dest'/batch_'$batch_num'_{}'
# Clean up intermediate data
rm chunked/*
doneVan gavan bi hev re têne hev kirin ku her tişt pir zû bixebite. Bi zêdekirina leza dakêşanê û rakirina nivîsandina dîskê, ez naha dikaribûm di nav çend demjimêran de pakêtek 5 terabyte pêvajo bikim.
Tiştek şîrîntir ji dîtina hemî bingehên ku hûn li ser AWS-ê didin têne bikar anîn tune. Bi saya gnu-parallel ez dikarim csv-ya 19gig bi qasî ku ez dikarim dakêşim vekim û vekim. Min nikarîbû çirûskekê jî bigirim ku vê bimeşînim.
- Nick Strayer (@NicholasStrayer)
Divê ev tweet behsa 'TSV' bikira. Alas.
Bikaranîna daneyên nû yên parskirî
Ez çi fêr bûm: Spark ji daneyên nekompresandî hez dike û ji berhevkirina dabeşan hez nake.
Naha daneyên di S3-ê de bi rengek nepak (bixwîne: parvekirî) û nîv-fermankirî bû, û ez dikarim dîsa vegerim Spark. Surprîzek li benda min bû: Min dîsa nekarî bigihîjim tiştê ku min dixwest! Pir dijwar bû ku meriv ji Spark re bêje ka dane çawa hatine dabeş kirin. Û tewra gava ku min ev kir, derket holê ku gelek partîsîyon hene (95 hezar), û gava ku min bikar anî coalesce hejmara wan daxist sînorên maqûl, vê yekê dabeşkirina min hilweşand. Ez bawer im ku ev dikare were rast kirin, lê piştî çend rojan lêgerînê min nekarî çareseriyek bibînim. Min di dawiyê de hemî peywirên li Spark qedand, her çend demek dirêj kir û pelên min ên Parquet-ê yên parçebûyî ne pir piçûk bûn (~ 200 KB). Lêbelê, data li cîhê ku hewce bû bû.
Pir piçûk û bêheval, ecêb!
Testkirina pirsên Spark-ê yên herêmî
Ez çi fêr bûm: Di çareserkirina pirsgirêkên hêsan de Spark pir zêde ye.
Bi dakêşana daneyan di formatek jîr de, min karî lezê biceribînim. Skrîptek R saz bikin da ku serverek Spark-ê ya herêmî bimeşîne, û dûv re çarçoveyek daneya Spark ji hilanîna koma Parquet-ê ya diyarkirî (bin) bar kir. Min hewl da ku hemî daneyan bar bikim lê nekarim Sparklyr dabeşkirinê nas bike.
sc <- Spark_connect(master = "local")
desired_snp <- 'rs34771739'
# Start a timer
start_time <- Sys.time()
# Load the desired bin into Spark
intensity_data <- sc %>%
Spark_read_Parquet(
name = 'intensity_data',
path = get_snp_location(desired_snp),
memory = FALSE )
# Subset bin to snp and then collect to local
test_subset <- intensity_data %>%
filter(SNP_Name == desired_snp) %>%
collect()
print(Sys.time() - start_time)Înfazê 29,415 saniye girt. Pir çêtir, lê ji bo ceribandina girseyî ya tiştek ne pir baş e. Wekî din, min nekarî bi cachkirinê re tiştan bilez bikim ji ber ku gava min hewl da ku çarçoveyek daneyê di bîranînê de cache bikim, Spark her gav têk diçû, tewra gava ku min ji 50 GB bêtir bîranîn ji danegehek ku giraniya wê ji 15 kêmtir e veqetand.
Vegere AWK
Ez çi fêr bûm: Di AWK de rêzikên hevgirtî pir bikêr in.
Min fêm kir ku ez dikarim lezên bilindtir bigihînim. Min ew di nav ecêbek ecêb de hate bîra min Min li ser taybetmendiyek xweş bi navê "" Di bingeh de, ev cotên key-nirx in, ku ji ber hin sedeman di AWK de bi rengek cûda têne gotin, û ji ber vê yekê min bi rengekî pir li ser wan nefikirî. bi bîr xist ku têgeha "arrayên komeleyê" ji peyva "cotê kilît-nirx" pir kevntir e. Heta ku hûn , hûn ê vê termê li wir nebînin, lê hûn ê rêzikên hevgirtî bibînin! Wekî din, "hevoka key-nirx" bi gelemperî bi databasan re têkildar e, ji ber vê yekê pir maqûltir e ku meriv wê bi hashmap re berhev bike. Min fêm kir ku ez dikarim van rêzikên hevgirtî bikar bînim da ku SNP-yên xwe bi tabloyek bin û daneya xav re bêyî karanîna Spark-ê re têkildar bikim.
Ji bo vê yekê, di skrîpta AWK de min blok bikar anî BEGIN. Ev perçeyek kodê ye ku berî rêza yekem a daneyê ji laşê sereke yê nivîsarê re were derbas kirin.
join_data.awk
BEGIN {
FS=",";
batch_num=substr(chunk,7,1);
chunk_id=substr(chunk,15,2);
while(getline < "snp_to_bin.csv") {bin[$1] = $2}
}
{
print $0 > "chunked/chr_"chr"_bin_"bin[$1]"_"batch_num"_"chunk_id".csv"
}
tîma while(getline...) hemî rêzên ji koma CSV (bin) bar kir, stûna yekem (navê SNP) wekî mifteya rêza hevgirtî destnîşan kir bin û nirxa duyemîn (kom) wekî nirx. Piştre di blokê de { }, ya ku li ser hemî rêzikên pelê sereke tê darve kirin, her rêzek ji pelê derketinê re tê şandin, ku li gorî koma xwe (bin) navek yekta distîne: ..._bin_"bin[$1]"_....
Guhêrbar batch_num и chunk_id daneyên ku ji hêla boriyê ve hatî peyda kirin, ji rewşek pêşbaziyê dûr dixin, û her xêza darvekirinê dimeşe parallel, li pelê xwe yê yekta nivîsand.
Ji ber ku min hemî daneyên xav li peldankên li ser kromozomên ku ji ceribandina min a berê ya bi AWK re mabûn belav kir, naha ez dikarim skrîptek Bashek din binivîsim da ku yek kromozomê bişopînim û daneyên dabeşkirî yên kûr ji S3 re bişînim.
DESIRED_CHR='13'
# Download chromosome data from s3 and split into bins
aws s3 ls $DATA_LOC |
awk '{print $4}' |
grep 'chr'$DESIRED_CHR'.csv' |
parallel "echo 'reading {}'; aws s3 cp "$DATA_LOC"{} - | awk -v chr=""$DESIRED_CHR"" -v chunk="{}" -f split_on_chr_bin.awk"
# Combine all the parallel process chunks to single files and upload to rds using R
ls chunked/ |
cut -d '_' -f 4 |
sort -u |
parallel "echo 'zipping bin {}'; cat chunked/*_bin_{}_*.csv | ./upload_as_rds.R '$S3_DEST'/chr_'$DESIRED_CHR'_bin_{}.rds"
rm chunked/*
Senaryo ji du beşan pêk tê parallel.
Di beşa yekem de, dane ji hemî pelên ku agahdariya li ser kromozoma xwestî vedihewîne, têne xwendin, dûv re ev dane li ser têlan têne belav kirin, ku pelan li komên guncan (bin) belav dikin. Ji bo ku ji şert û mercên pêşbaziyê dûr nekevin dema ku pir kêşan li heman pelê dinivîsin, AWK navên pelan derbas dike da ku daneyan li cîhên cihê binivîsîne, mînakî. chr_10_bin_52_batch_2_aa.csv. Wekî encamek, gelek pelên piçûk li ser dîskê têne afirandin (ji bo vê yekê min cildên terabyte EBS bikar anîn).
Conveyor ji beşa duyemîn parallel di nav koman (bin) re derbas dibe û pelên wan ên kesane di CSV c-ya hevpar de berhev dike catû paşê wan ji bo hinardekirinê dişîne.
Weşana li R?
Ez çi fêr bûm: Hûn dikarin têkilî daynin stdin и stdout ji tîpek R, û ji ber vê yekê wê di lûleyê de bikar bînin.
Dibe ku we di nivîsara xweya Bash de ev rêz dîtibe: ...cat chunked/*_bin_{}_*.csv | ./upload_as_rds.R.... Ew hemî pelên koma hevgirtî (bin) werdigerîne tîpa R ya jêrîn. {} teknîkeke taybet e parallel, ya ku her daneya ku ew dişîne ji herika diyarkirî re rasterast di nav fermanê de bixwe. Dibe {#} Nasnameyek mijara yekta peyda dike, û {%} numreya cîhê kar temsîl dike (dubare kirin, lê qet bi hevdemî). Lîsteya hemî vebijarkan dikare tê de were dîtin
#!/usr/bin/env Rscript
library(readr)
library(aws.s3)
# Read first command line argument
data_destination <- commandArgs(trailingOnly = TRUE)[1]
data_cols <- list(SNP_Name = 'c', ...)
s3saveRDS(
read_csv(
file("stdin"),
col_names = names(data_cols),
col_types = data_cols
),
object = data_destination
)
Dema ku guherbar file("stdin") veguhestiye readr::read_csv, Daneyên ku di skrîpta R-yê de hatine wergerandin di çarçoveyek de têne barkirin, ku paşê di formê de ye .rds-bikaranîna pelê aws.s3 rasterast ji S3 re hatî nivîsandin.
RDS tiştek mîna guhertoyek piçûk a Parquet-ê ye, bêyî hûrguliyên hilanîna dengbêjan.
Piştî qedandina senaryoya Bash min pakêtek girt .rds-Pelên ku di S3-ê de cih digirin, ku destûr da min ku ez kompresyon û celebên çêkirî bikar bînim.
Tevî bikaranîna frena R, her tişt pir zû xebitî. Ne ecêb e, beşên R yên ku daneyan dixwînin û dinivîsin pir xweşbîn in. Piştî ceribandina li ser yek kromozomek navîn, kar li ser mînakek C5n.4xl bi qasî du demjimêran qediya.
Sînorên S3
Ez çi fêr bûm: Bi saya pêkanîna riya biaqil, S3 dikare gelek pelan bi rê ve bibe.
Ez fikar bûm ka S3 dê bikaribe gelek pelên ku jê re hatine veguheztin bi rê ve bibe. Ez dikarim navên pelan watedar bikim, lê S3 dê çawa li wan bigere?

Peldankên li S3 tenê ji bo pêşandanê ne, di rastiyê de pergal bi sembolê re eleqedar nabe /.
Wusa dixuye ku S3 rêça pelek taybetî wekî mifteyek hêsan di celebek tabloyek haş an databasa-bingeha belgeyê de nîşan dide. Sapek dikare wekî tabloyek were fikirîn, û pel dikarin di wê tabloyê de wekî tomar bêne hesibandin.
Ji ber ku lez û karîgerî ji bo bidestxistina qezencê li Amazonê girîng e, ne ecêb e ku ev pergala rêça key-wek pelê bi rengek xweş xweşkirî ye. Min hewl da ku hevsengiyek bibînim: da ku ez ne hewce bûm ku ez gelek daxwazên xwe bikim, lê ku daxwaz zû hatin bicîh kirin. Derket holê ku çêtirîn e ku meriv nêzî 20 hezar pelan çêbike. Ez difikirim ku ger em xweşbîniyê bidomînin, em dikarin bi lezbûnek zêde bigihîjin (mînak, çêkirina kelekek taybetî tenê ji bo daneyê, bi vî rengî mezinahiya tabloya lêgerînê kêm bike). Lê ji bo ceribandinên din dem û pere tune bû.
Çi lihevhatina cross?
Tiştê ku ez Fêr bûm: Sedema jimare yek a dema wendakirinê xweşbînkirina rêbaza hilanîna we ji zû de ye.
Di vê nuqteyê de, pir girîng e ku hûn ji xwe bipirsin: "Çima formatek pelê xwedan bikar bînin?" Sedem di leza barkirinê de ye (barkirina pelên CSV-ya gzipped 7 carî dirêjtir dirêj kir) û lihevhatina bi tevgerên xebata me re. Ez dikarim ji nû ve bifikirim ka R dikare bi hêsanî pelên Parquet (an Arrow) bêyî barkirina Spark bar bike. Di laboratûara me de her kes R-yê bikar tîne, û heke ez hewce bikim ku daneyan veguherînim formatek din, hîn jî daneyên nivîsa orîjînal di destê min de ne, ji ber vê yekê ez dikarim dîsa boriyê bimeşînim.
Dabeşkirina kar
Ez çi fêr bûm: Hewl nedin ku bi destan karan xweşbîn bikin, bila komputer wiya bike.
Min tevgera xebatê li ser yek kromozomê xelet kir, naha divê ez hemî daneyên din pêvajoyê bikim.
Min dixwest ku ez çend mînakên EC2 ji bo veguheztinê rakim, lê di heman demê de ez ditirsiyam ku ez barek pir nehevseng di nav karên cûda yên pêvajoyê de bigirim (wek ku Spark ji dabeşên bêhevseng êş kişand). Wekî din, ez ne eleqedar bûm ku ji bo her kromozomê yek mînakek zêde bikim, ji ber ku ji bo hesabên AWS-ê 10 mînakan sînorek xwerû heye.
Dûv re min biryar da ku ez skrîptek bi R binivîsim da ku karên pêvajoyê xweşbîn bikim.
Pêşî, min ji S3 pirsî ku her kromozom çiqas cîhê hilanînê dagir kiriye hesab bike.
library(aws.s3)
library(tidyverse)
chr_sizes <- get_bucket_df(
bucket = '...', prefix = '...', max = Inf
) %>%
mutate(Size = as.numeric(Size)) %>%
filter(Size != 0) %>%
mutate(
# Extract chromosome from the file name
chr = str_extract(Key, 'chr.{1,4}.csv') %>%
str_remove_all('chr|.csv')
) %>%
group_by(chr) %>%
summarise(total_size = sum(Size)/1e+9) # Divide to get value in GB
# A tibble: 27 x 2
chr total_size
<chr> <dbl>
1 0 163.
2 1 967.
3 10 541.
4 11 611.
5 12 542.
6 13 364.
7 14 375.
8 15 372.
9 16 434.
10 17 443.
# … with 17 more rows
Dûv re min fonksiyonek nivîsand ku mezinahiya tevahî digire, rêza kromozoman dihejîne, wan di koman de dabeş dike. num_jobs û ji we re vedibêje ku mezinahiyên hemî karên pêvajoyê çiqas cûda ne.
num_jobs <- 7
# How big would each job be if perfectly split?
job_size <- sum(chr_sizes$total_size)/7
shuffle_job <- function(i){
chr_sizes %>%
sample_frac() %>%
mutate(
cum_size = cumsum(total_size),
job_num = ceiling(cum_size/job_size)
) %>%
group_by(job_num) %>%
summarise(
job_chrs = paste(chr, collapse = ','),
total_job_size = sum(total_size)
) %>%
mutate(sd = sd(total_job_size)) %>%
nest(-sd)
}
shuffle_job(1)
# A tibble: 1 x 2
sd data
<dbl> <list>
1 153. <tibble [7 × 3]>Dûv re min bi purrr re bi hezar hûrgulî bazda û ya çêtirîn hilbijart.
1:1000 %>%
map_df(shuffle_job) %>%
filter(sd == min(sd)) %>%
pull(data) %>%
pluck(1)
Ji ber vê yekê min bi komek peywirên ku bi mezinahiyê pir dişibin hev qediya. Dûv re ya ku mabû ew bû ku ez skrîpta xweya berê ya Bash di nav lekeyek mezin de pêça for. Vê xweşbîniyê bi qasî 10 hûrdeman nivîsandin. Û ev pir kêmtir e ji ya ku ez ê xerc bikim ji bo afirandina peywiran bi destan heke ew bêhevseng bûn. Ji ber vê yekê, ez difikirim ku ez bi vê xweşbîniya pêşîn rast bûm.
for DESIRED_CHR in "16" "9" "7" "21" "MT"
do
# Code for processing a single chromosome
fiDi dawiyê de ez fermana girtinê lê zêde dikim:
sudo shutdown -h now
... û her tişt pêk hat! Bi karanîna AWS CLI, min mînakan bi karanîna vebijarkê rakir user_data ji wan re skrîptên Bash yên karên wan ji bo pêvajoyê. Ew bixweber diherikin û diqewimin, ji ber vê yekê min drav neda hêza pêvajoyek zêde.
aws ec2 run-instances ...
--tag-specifications "ResourceType=instance,Tags=[{Key=Name,Value=<<job_name>>}]"
--user-data file://<<job_script_loc>>Ka em pak bikin!
Ez çi fêr bûm: Divê API ji bo hêsan û nermbûna karanîna hêsan be.
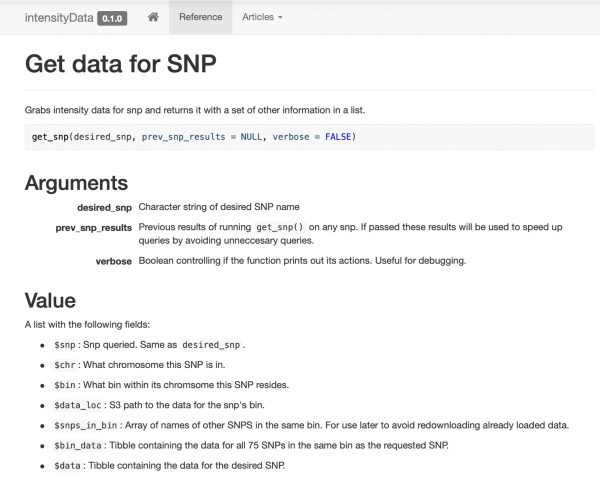
Di dawiyê de min dane li cîh û forma rast girt. Tiştê ku mabû ev bû ku pêvajoya karanîna daneyan bi qasî ku pêkan hêsan bike da ku ji hevkarên min re hêsantir bike. Min dixwest ku ji bo afirandina daxwazan API-yek hêsan çêkim. Ger di paşerojê de ez biryarê bidim ku ji xwe biguherim .rds ji bo pelên Parquet, wê hingê divê ev ji bo min pirsgirêkek be, ne ji bo hevkarên min. Ji bo vê yekê min biryar da ku pakêtek R-ya navxweyî çêkim.
Pakêtek pir hêsan ku tê de tenê çend fonksiyonên gihîştina daneyê ku li dora fonksiyonek hatine organîzekirin vedihewîne û belge bikin get_snp. Min malperek jî ji hevalên xwe re çêkir , da ku ew bi hêsanî mînak û belgeyan bibînin.
Caching Smart
Ez çi fêr bûm: Ger daneyên we baş hatine amadekirin, cachkirin dê hêsan be!
Ji ber ku yek ji xebatkarên sereke heman modela analîzê li ser pakêta SNP-ê sepand, min biryar da ku binning ji bo berjewendiya xwe bikar bînim. Dema ku daneyan bi SNP veguhezîne, hemî agahdariya ji komê (bin) bi tiştê vegerî ve girêdayî ye. Ango, pirsên kevin dikarin (di teorîyê de) pêvajokirina pirsên nû lez bikin.
# Part of get_snp()
...
# Test if our current snp data has the desired snp.
already_have_snp <- desired_snp %in% prev_snp_results$snps_in_bin
if(!already_have_snp){
# Grab info on the bin of the desired snp
snp_results <- get_snp_bin(desired_snp)
# Download the snp's bin data
snp_results$bin_data <- aws.s3::s3readRDS(object = snp_results$data_loc)
} else {
# The previous snp data contained the right bin so just use it
snp_results <- prev_snp_results
}
...
Dema ku pakêtê ava dikim, min gelek pîvanan dimeşîne ku dema ku rêbazên cihêreng bikar tîne lezê bide berhev. Ez pêşniyar dikim ku hûn vê yekê paşguh nekin, ji ber ku carinan encam nediyar in. Bo nimûne, dplyr::filter ji girtina rêzan bi karanîna fîlterkirin-based îndekskirinê pir zûtir bû, û derxistina stûnek yek ji çarçoveyek daneya parzûnkirî ji karanîna hevoksaziya îndekskirinê pir zûtir bû.
Ji kerema xwe not bikin ku object prev_snp_results mifteyê dihewîne snps_in_bin. Ev komek ji hemî SNP-yên bêhempa yên di komekê de ye (bin), ku dihêle hûn zû zû kontrol bikin ka we berê daneya ji pirsek berê heye. Di heman demê de ew hêsan dike ku bi vê kodê ve di nav grûpek (bin) de li hemî SNP-an vegere:
# Get bin-mates
snps_in_bin <- my_snp_results$snps_in_bin
for(current_snp in snps_in_bin){
my_snp_results <- get_snp(current_snp, my_snp_results)
# Do something with results
}Encam
Naha em dikarin (û bi ciddî dest pê kirine) model û senaryoyên ku berê ji me re nedihatin meşandin bimeşînin. Tiştê çêtirîn ev e ku hevkarên min ên laboratuarê ne hewce ne ku li ser tu tevliheviyan bifikirin. Ew tenê fonksiyonek heye ku dixebite.
Û her çend pakêt wan hûrguliyan diparêze, min hewl da ku formata daneyê têra xwe sade bikim ku ew karibin wê fêm bikin ger ez sibê ji nişka ve wenda bibim…
Leza bi berçav zêde bûye. Em bi gelemperî perçeyên genomê yên girîng ên fonksiyonel dişoxilînin. Berê, me nikarîbû wiya bikin (ew pir biha bû), lê naha, bi saya avahiyek komê (bin) û cachkirinê, daxwazek ji bo yek SNP bi navînî kêmtirî 0,1 çirkeyan digire, û karanîna daneyê wusa ye. kêm ku lêçûnên ji bo S3 fistiq in.
Di van demên dawî de min ji bo laboratûara xwe guheztina 25+ TB daneyên genotîpkirina xav girt. Dema ku min dest pê kir, karanîna çirûskê 8 hûrdem girt û 20 $ lêçû ku ji SNP-ê pirsîn. Piştî bikaranîna AWK + ji bo pêvajoyê, ew naha ji 10-anek saniyeyê kêmtir digire û 0.00001 $ lê dike. My personal serkeftin.
- Nick Strayer (@NicholasStrayer)
encamê
Ev gotar qet ne rêberek e. Çareserî derket holê ku ferdî ye, û hema bê guman ne çêtirîn. Belê, ew rêwîtiyek e. Ez dixwazim yên din jî fêm bikin ku biryarên bi vî rengî di serî de bi tevahî pêk nayên, ew encama ceribandin û xeletiyê ne. Di heman demê de, heke hûn li zanyarek daneyê digerin, ji bîr mekin ku karanîna van amûran bi bandor ezmûnek hewce dike, û ezmûn lêçûn dike. Kêfxweş im ku îmkanên min ên dayîna pereyan hebûn, lê gelek kesên din ên ku dikarin heman karî ji min çêtir bikin, ji ber tunebûna pereyan qet fersendê nabînin ku biceribînin.
Amûrên daneyên mezin pirreng in. Ger wextê we hebe, hûn dikarin hema bê guman çareseriyek zûtir bi karanîna teknîkên paqijkirina daneya hişmend, hilanîn û derxistinê binivîsin. Di dawiyê de ew bi analîzek lêçûn-fêdeyê tê.
Tiştê ku ez fêr bûm:
- rêyek erzan tune ku meriv di carekê de 25 TB parsek bike;
- Hay ji mezinahiya pelên Parquet û rêxistina wan hebin;
- Divê dabeşên di Spark de hevseng bin;
- Bi gelemperî, qet hewl nekin ku 2,5 mîlyon dabeşan çêbikin;
- Rêzkirin hîn jî dijwar e, wekî sazkirina Spark;
- carinan daneyên taybetî hewceyê çareseriyên taybetî ne;
- Kombûna çirûskê zû ye, lê dabeşkirin hîn jî biha ye;
- Dema ku ew tiştên bingehîn fêrî we dikin, xew nekin, belkî kesek jixwe di salên 1980-an de pirsgirêka we çareser kiriye;
gnu parallel- ev tiştekî efsûnî ye, divê her kes wê bikar bîne;- Spark ji daneyên nekompresandî hez dike û ji berhevkirina dabeşan hez nake;
- Spark di çareserkirina pirsgirêkên hêsan de pir zêde ye;
- Rêzikên hevgirtî yên AWK pir bikêr in;
- hûn dikarin têkilî daynin
stdinиstdoutji tîpek R, û ji ber vê yekê wê di boriyê de bikar bînin; - Bi saya pêkanîna riya biaqil, S3 dikare gelek pelan pêvajoyê bike;
- Sedema sereke ya wendakirina wextê xweşbînkirina zû ya rêbaza hilanîna we ye;
- hewl nekin ku peywiran bi destan xweş bikin, bila komputer wiya bike;
- Divê API ji bo hêsan û nermbûna karanîna hêsan be;
- Ger daneyên we baş hatine amadekirin, cachkirin dê hêsan be!
Source: www.habr.com
