

Dema ku rewş hene li ser maseyek bêyî mifteya bingehîn an jî navnîşek bêhempa ya din, ji ber çavdêriyek, klonên bêkêmasî yên tomarên berê hene tê de hene.

Mînakî, nirxên metrîkek kronolojîk li PostgreSQL bi karanîna tîrêjek COPY têne nivîsandin, û dûv re têkçûnek ji nişka ve çêdibe, û beşek ji daneyên bi tevahî wekhev dîsa digihîje.
Meriv çawa databasê ji klonên nehewce xilas dike?
Dema ku PK ne arîkar e
Rêya herî hêsan ew e ku pêşî li rewşek wiha were girtin. Mînakî, PRIMARY KEY lîstin. Lê ev her gav bêyî zêdekirina qebareya daneyên hilandî ne gengaz e.
Mînakî, heke rastbûna pergala çavkaniyê ji rastbûna zeviyê di databasê de bilindtir e:
metric | ts | data
--------------------------------------------------
cpu.busy | 2019-12-20 00:00:00 | {"value" : 12.34}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 10}
cpu.busy | 2019-12-20 00:00:01 | {"value" : 11.2}
cpu.busy | 2019-12-20 00:00:03 | {"value" : 15.7}
Te ferq kir? Di şûna 00:00:02 de jimartin di databasê de bi ts-yê saniyeyek berê hate tomar kirin, lê ji hêla serîlêdanê ve pir derbasdar ma (piştî, nirxên daneyê cûda ne!).
Bê guman hûn dikarin bikin PK (metric, ts) - lê wê hingê em ê ji bo daneyên derbasdar nakokiyên têxê bistînin.
Dikane PK (metric, ts, data) - lê ev ê hêjmara wê pir zêde bike, ku em ê bikar neynin.
Ji ber vê yekê, vebijarka herî rast ev e ku meriv navnîşek ne-yekserî ya birêkûpêk çêbike (metrîk, ts) û bi pirsgirêkan re piştî ku rastî derkevin holê jî mijûl bibin.
"Şerê klonîk dest pê kir"
Hin celeb qeza çêbû, û naha divê em tomarên klonê ji tabloyê hilweşînin.

Ka em daneyên orîjînal model bikin:
CREATE TABLE tbl(k text, v integer);
INSERT INTO tbl
VALUES
('a', 1)
, ('a', 3)
, ('b', 2)
, ('b', 2) -- oops!
, ('c', 3)
, ('c', 3) -- oops!!
, ('c', 3) -- oops!!
, ('d', 4)
, ('e', 5)
;Li vir destê me sê caran lerizî, Ctrl+V asê ma û êdî...
Pêşîn, em fêhm bikin ku tabloya me dikare pir mezin be, ji ber vê yekê piştî ku em hemî klonan bibînin, ji me re tê pêşniyar kirin ku em bi rastî "tiliya xwe bixin" da ku jêbirin. tomarên taybetî bêyî ku ji nû ve li wan bigerin.
Û rêyek wusa heye - ev , Nasnameya fîzîkî ya tomarek taybetî.
Ango, berî her tiştî, pêdivî ye ku em ctid tomaran di çarçoveya naveroka tevahî ya rêza tabloyê de berhev bikin. Vebijarka herî hêsan ev e ku meriv tevahiya rêzê binivîsîne:
SELECT
T::text
, array_agg(ctid) ctids
FROM
tbl T
GROUP BY
1;
t | ctids
---------------------------------
(e,5) | {"(0,9)"}
(d,4) | {"(0,8)"}
(c,3) | {"(0,5)","(0,6)","(0,7)"}
(b,2) | {"(0,3)","(0,4)"}
(a,3) | {"(0,2)"}
(a,1) | {"(0,1)"}
Ma gengaz e ku meriv neyê avêtin?Di prensîbê de, ew di pir rewşan de gengaz e. Heya ku hûn dest bi karanîna zeviyên vê tabloyê bikin cureyên bêyî operatorê wekheviyê:
CREATE TABLE tbl(k text, v integer, x point);
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T;
-- ERROR: could not identify an equality operator for type tbl
Erê, em tavilê dibînin ku heke di rêzê de ji yekê zêdetir têketin hebe, ev hemî klon in. Ka em tenê wan bihêlin:
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T;unnest
------
(0,6)
(0,7)
(0,4)Ji bo kesên ku dixwazin kurt binivîsinHûn jî dikarin bi vî rengî binivîsin:
SELECT
unnest((array_agg(ctid))[2:])
FROM
tbl T
GROUP BY
T::text;Ji ber ku nirxa rêzika rêzkirî bixwe ji me re ne balkêş e, me ew bi tenê ji stûnên vegerî yên jêrpirsînê avêt.
Tiştek hindik maye ku bikin - bikin DELETE seta ku me standiye bikar bîne:
DELETE FROM
tbl
WHERE
ctid = ANY(ARRAY(
SELECT
unnest(ctids[2:])
FROM
(
SELECT
array_agg(ctid) ctids
FROM
tbl T
GROUP BY
T::text
) T
)::tid[]);Ka em xwe kontrol bikin:
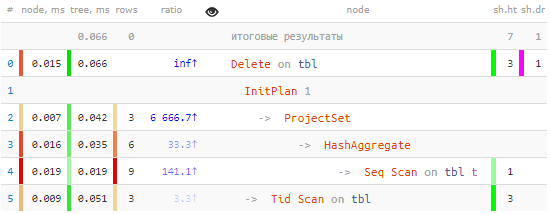
Erê, her tişt rast e: 3 tomarên me ji bo yekane Seq Scan ya tevahiya tabloyê hatin hilbijartin, û girêka jêbirinê ji bo lêgerîna daneyan hate bikar anîn. derbasbûna yekane bi Tid Scan:
-> Tid Scan on tbl (actual time=0.050..0.051 rows=3 loops=1)
TID Cond: (ctid = ANY ($0))Ger we gelek tomar paqij kir, .
Werin em ji bo tabloyek mezintir û bi jimareyek mezin a dubareyan kontrol bikin:
TRUNCATE TABLE tbl;
INSERT INTO tbl
SELECT
chr(ascii('a'::text) + (random() * 26)::integer) k -- a..z
, (random() * 100)::integer v -- 0..99
FROM
generate_series(1, 10000) i; 
Ji ber vê yekê, rêbaz bi serfirazî dixebite, lê divê ew bi hin hişyariyê were bikar anîn. Ji ber ku ji bo her tomarek ku tê jêbirin, rûpelek daneyê di Tid Scan de tê xwendin, û yek jî di Delete de.
Source: www.habr.com
