

кирүү
Бул макалада мен белгилүү Huffman алгоритми, ошондой эле маалыматтарды кысуу анын колдонуу жөнүндө сөз болот.
Натыйжада, биз жөнөкөй архиватор жазабыз. Бул буга чейин талкууланган , бирок практикалык ишке ашыруусуз. Учурдагы посттун теориялык материалы мектептик информатика сабагынан жана Роберт Лафореттин “Javaдагы берилиштердин структуралары жана алгоритмдери” китебинен алынды. Ошентип, баары кесилген!
Бир нече ойлор
Кадимки текст файлында бир символ 8 бит (ASCII коддоо) же 16 (Юникод коддоо) менен коддолгон. Кийинки биз ASCII коддоону карап чыгабыз. Мисалы, s1 = "SUSIE IT IS EN ESYn" сызыгын алыңыз. Сапта жалпысынан 22 символ бар, албетте, боштуктарды жана жаңы сап белгиси - 'n'. Бул сапты камтыган файлдын салмагы 22*8 = 176 бит болот. Ошол замат суроо туулат: 8 символду коддоо үчүн бардык 1 битти колдонуу туурабы? Биз бардык ASCII символдорун колдонбойбуз. Алар жасашса дагы, эң кеңири таралган тамгага – S – мүмкүн болушунча кыска код, ал эми эң сейрек кездешүүчү – T (же U, же «n») үчүн – узунураак код берилсе, акылга сыярлык болмок. Хаффман алгоритми мына ушундан турат: файл минималдуу салмакка ээ болгон оптималдуу коддоо вариантын табуу керек. Ар кандай символдор үчүн коддун узундугу ар кандай болушу нормалдуу көрүнүш - алгоритм ушуга негизделген.
Коддоо
Эмне үчүн 'S' символуна код бербеңиз, мисалы, 1 бит узундуктагы: 0 же 1. Ал 1 болсун. Андан кийин эң көп таралган экинчи символ - ' ' (бостук) - 0 бериңиз. Элестетиңиз, сиз өзүңүздүн билдирүүңүздүн коддорун чече баштадыңыз - коддолгон s1 сап - жана сиз код 1ден башталганын көрүп жатасыз. Демек, сиз эмне кыласыз: бул S белгисиби же башка символбу, мисалы Абы? Ошондуктан, бир маанилүү эреже пайда болот:
Бир дагы код башкасынын префикси болбошу керек
Бул эреже алгоритмде негизги болуп саналат. Демек, кодду түзүү жыштык таблицасы менен башталат, ал ар бир символдун жыштыгын (пайда болгондордун санын) көрсөтөт:
 Эң көп жолуккан символдор эң аз коддолушу керек мүмкүн болгон биттердин саны. Мен мүмкүн болгон код таблицаларынын бирине мисал келтирем:
Эң көп жолуккан символдор эң аз коддолушу керек мүмкүн болгон биттердин саны. Мен мүмкүн болгон код таблицаларынын бирине мисал келтирем:
 Ошентип, коддолгон билдирүү төмөнкүдөй болот:
Ошентип, коддолгон билдирүү төмөнкүдөй болот:
10 01111 10 110 1111 00 10 010 1110 10 00 110 0110 00 110 10 00 1111 010 10 1110 01110
Ар бир белгинин кодун боштук менен бөлүп койдум. Бул чындап кысылган файлда болбойт!
Суроо туулат: бул жаш жигит коддор таблицасын түзүү үчүн кодду кантип ойлоп тапкан? Бул төмөндө талкууланмакчы.
Хаффман дарагын куруу
Бул жерде экилик издөө дарактары жардамга келет. Кабатыр болбоңуз, бул жерден издөө, киргизүү же жок кылуу ыкмаларынын кереги жок. Бул жерде java дарак структурасы болуп саналат:
public class Node {
private int frequence;
private char letter;
private Node leftChild;
private Node rightChild;
...
}
class BinaryTree {
private Node root;
public BinaryTree() {
root = new Node();
}
public BinaryTree(Node root) {
this.root = root;
}
...
}
Бул толук код эмес, толук код төмөндө болот.
Бул даракты куруу алгоритми:
- Кабардын ар бир белгиси үчүн Түйүн объектин түзүңүз (s1 сызыгы). Биздин учурда 9 түйүн болот (Түйүн объектилери). Ар бир түйүн эки маалымат талаасынан турат: символ жана жыштык
- Ар бир түйүн үчүн Tree объектисин (BinaryTree) түзүңүз. Түйүн дарактын тамырына айланат.
- Бул дарактарды артыкчылыктуу кезекке киргизиңиз. Жыштык канчалык төмөн болсо, артыкчылык ошончолук жогору болот. Ошентип, казып алууда дайыма эң төмөнкү жыштыктагы дерво тандалып алынат.
Андан кийин сиз циклдик түрдө төмөнкүлөрдү кылышыңыз керек:
- Артыкчылыктуу кезектен эки даракты алып салыңыз жана аларды жаңы түйүндүн балдары кылыңыз (тамгасыз жаңы түзүлгөн түйүн). Жаңы түйүндүн жыштыгы эки тукум дарактын жыштыктарынын суммасына барабар.
- Бул түйүн үчүн тамыры ушул түйүндө турган дарак түзүңүз. Бул даракты кайра артыкчылыктуу кезекке салыңыз. (Дарак жаңы жыштыкка ээ болгондуктан, ал кезектеги жаңы жерде пайда болот)
- Кезекте бир гана дарак калмайынча 1 жана 2-кадамдарды улантыңыз - Хаффман дарагы
Бул алгоритмди s1 сапта карап көрөлү:
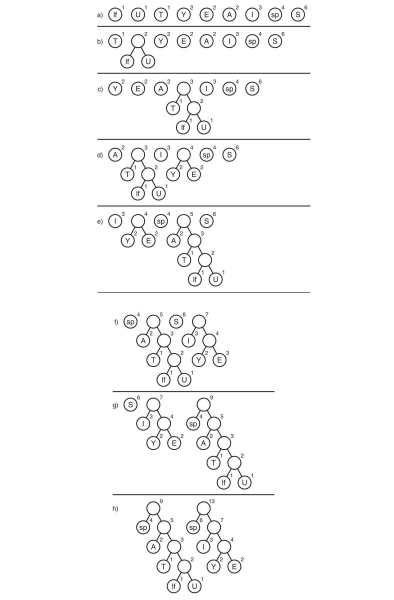
Бул жерде "lf" (сызык берүү) белгиси жаңы сапты билдирет, "sp" (мейкиндик) боштук.
Кийинкиси эмне?
Бизде Хаффман дарагы бар. макул. Жана аны менен эмне кылуу керек? Алар аны бекер эле алышпайт, андан кийин дарактын тамырынан жалбырактарына чейинки бардык жолдорду издөө керек. Эгер сол балага алып барса, 0 четин, оңго алып келсе, 1ди белгилөөгө макул бололу. Тактап айтканда, бул белгилөөдө символдун коду дарактын тамырынан дал ушул символду камтыган жалбыракка чейинки жол.
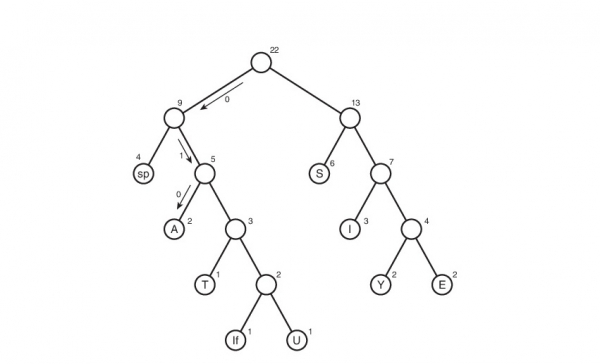
Коддор таблицасы ушундай болуп чыкты. Бул таблицаны карап көрсөк, ар бир символдун "салмагы" жөнүндө тыянак чыгарууга болот - бул анын кодунун узундугу. Андан кийин, кысылган түрдө баштапкы файлдын салмагы: 2 * 3 + 2 * 4 + 3 * 3 + 6 * 2 + 1 * 4 + 1 * 5 + 2 * 4 + 4 * 2 + 1 * 5 = 65 бит . Алгач анын салмагы 176 бит болгон. Демек, биз аны 176/65 = 2.7 эсеге азайттык! Бирок бул утопия. Мындай коэффициенттин алынышы күмөн. Неге? Бул бир аз кийинчерээк талкууланат.
Декоддоо
Ооба, балким, калган эң жөнөкөй нерсе - декоддоо. Менимче, силердин көбүңөр биз кысылган файлды кантип коддолгону жөнүндө эч кандай ишаратсыз жөн эле түзө албайбыз деп ойлодуңар - биз аны чече албайбыз! Ооба, ооба, мен үчүн муну түшүнүү кыйын болду, бирок мен кысуу таблицасы менен table.txt текст файлын түзүшүм керек болот:
01110
00
A010
E1111
I110
S10
T0110
U01111
Y1110
"Символ" "символ коду" формасындагы таблицага жазуу. Эмне үчүн 01110 символу жок? Чынында, бул символ менен, жөн гана мен файлга чыгарууда колдонгон java куралдары, жаңы сап белгиси - 'n' - жаңы сапка айландырылат (канчалык акылсыз угулбасын). Демек, жогору жактагы бош сап 01110 кодунун символу. 00 коду үчүн символ саптын башындагы боштук болуп саналат. Мен дароо айтайын, биздин Хан коэффициенти үчүн таблицаны сактоонун бул ыкмасы эң акылга сыйбас деп айтууга болот. Бирок аны түшүнүү жана ишке ашыруу оңой. Мен оптималдаштыруу боюнча комментарийлерде сиздин сунуштарды угууга кубанычта болом.
Бул таблицага ээ болуу кодду чечүүнү абдан жеңилдетет. Коддоштурууну түзүүдө кайсы эрежени карманганыбызды эстейли:
Бир дагы код башкасынын префикси болбошу керек
Бул жерде ал көмөктөшүүчү ролду ойнойт. Биз ырааттуу түрдө бит-бит окуйбуз жана натыйжада окулган биттерден турган d сабы символдун символуна туура келген коддоо менен дал келери менен, символдун символу (жана аны гана!) коддолгондугун дароо билебиз. Андан кийин, коддон чыгуучу сапка белги жазабыз (дешифрленген билдирүүнү камтыган сап), d сызыгын калыбына келтиребиз, андан кийин коддолгон файлды окуйбуз.
Реализация
Менин кодумду кемсинтип, архивди жаза турган убак келди. Аны компрессор деп атайлы.
Кайра баштаңыз. Биринчиден, биз Node классын жазабыз:
public class Node {
private int frequence;//частота
private char letter;//буква
private Node leftChild;//левый потомок
private Node rightChild;//правый потомок
public Node(char letter, int frequence) { //собственно, конструктор
this.letter = letter;
this.frequence = frequence;
}
public Node() {}//перегрузка конструтора для безымянных узлов(см. выше в разделе о построении дерева Хаффмана)
public void addChild(Node newNode) {//добавить потомка
if (leftChild == null)//если левый пустой=> правый тоже=> добавляем в левый
leftChild = newNode;
else {
if (leftChild.getFrequence() <= newNode.getFrequence()) //в общем, левым потомком
rightChild = newNode;//станет тот, у кого меньше частота
else {
rightChild = leftChild;
leftChild = newNode;
}
}
frequence += newNode.getFrequence();//итоговая частота
}
public Node getLeftChild() {
return leftChild;
}
public Node getRightChild() {
return rightChild;
}
public int getFrequence() {
return frequence;
}
public char getLetter() {
return letter;
}
public boolean isLeaf() {//проверка на лист
return leftChild == null && rightChild == null;
}
}
Азыр дарак:
class BinaryTree {
private Node root;
public BinaryTree() {
root = new Node();
}
public BinaryTree(Node root) {
this.root = root;
}
public int getFrequence() {
return root.getFrequence();
}
public Node getRoot() {
return root;
}
}
Приоритеттүү кезек:
import java.util.ArrayList;//да-да, очередь будет на базе списка
class PriorityQueue {
private ArrayList<BinaryTree> data;//список очереди
private int nElems;//кол-во элементов в очереди
public PriorityQueue() {
data = new ArrayList<BinaryTree>();
nElems = 0;
}
public void insert(BinaryTree newTree) {//вставка
if (nElems == 0)
data.add(newTree);
else {
for (int i = 0; i < nElems; i++) {
if (data.get(i).getFrequence() > newTree.getFrequence()) {//если частота вставляемого дерева меньше
data.add(i, newTree);//чем част. текущего, то cдвигаем все деревья на позициях справа на 1 ячейку
break;//затем ставим новое дерево на позицию текущего
}
if (i == nElems - 1)
data.add(newTree);
}
}
nElems++;//увеличиваем кол-во элементов на 1
}
public BinaryTree remove() {//удаление из очереди
BinaryTree tmp = data.get(0);//копируем удаляемый элемент
data.remove(0);//собственно, удаляем
nElems--;//уменьшаем кол-во элементов на 1
return tmp;//возвращаем удаленный элемент(элемент с наименьшей частотой)
}
}
Хаффман дарагын түзгөн класс:
public class HuffmanTree {
private final byte ENCODING_TABLE_SIZE = 127;//длина кодировочной таблицы
private String myString;//сообщение
private BinaryTree huffmanTree;//дерево Хаффмана
private int[] freqArray;//частотная таблица
private String[] encodingArray;//кодировочная таблица
//----------------constructor----------------------
public HuffmanTree(String newString) {
myString = newString;
freqArray = new int[ENCODING_TABLE_SIZE];
fillFrequenceArray();
huffmanTree = getHuffmanTree();
encodingArray = new String[ENCODING_TABLE_SIZE];
fillEncodingArray(huffmanTree.getRoot(), "", "");
}
//--------------------frequence array------------------------
private void fillFrequenceArray() {
for (int i = 0; i < myString.length(); i++) {
freqArray[(int)myString.charAt(i)]++;
}
}
public int[] getFrequenceArray() {
return freqArray;
}
//------------------------huffman tree creation------------------
private BinaryTree getHuffmanTree() {
PriorityQueue pq = new PriorityQueue();
//алгоритм описан выше
for (int i = 0; i < ENCODING_TABLE_SIZE; i++) {
if (freqArray[i] != 0) {//если символ существует в строке
Node newNode = new Node((char) i, freqArray[i]);//то создать для него Node
BinaryTree newTree = new BinaryTree(newNode);//а для Node создать BinaryTree
pq.insert(newTree);//вставить в очередь
}
}
while (true) {
BinaryTree tree1 = pq.remove();//извлечь из очереди первое дерево.
try {
BinaryTree tree2 = pq.remove();//извлечь из очереди второе дерево
Node newNode = new Node();//создать новый Node
newNode.addChild(tree1.getRoot());//сделать его потомками два извлеченных дерева
newNode.addChild(tree2.getRoot());
pq.insert(new BinaryTree(newNode);
} catch (IndexOutOfBoundsException e) {//осталось одно дерево в очереди
return tree1;
}
}
}
public BinaryTree getTree() {
return huffmanTree;
}
//-------------------encoding array------------------
void fillEncodingArray(Node node, String codeBefore, String direction) {//заполнить кодировочную таблицу
if (node.isLeaf()) {
encodingArray[(int)node.getLetter()] = codeBefore + direction;
} else {
fillEncodingArray(node.getLeftChild(), codeBefore + direction, "0");
fillEncodingArray(node.getRightChild(), codeBefore + direction, "1");
}
}
String[] getEncodingArray() {
return encodingArray;
}
public void displayEncodingArray() {//для отладки
fillEncodingArray(huffmanTree.getRoot(), "", "");
System.out.println("======================Encoding table====================");
for (int i = 0; i < ENCODING_TABLE_SIZE; i++) {
if (freqArray[i] != 0) {
System.out.print((char)i + " ");
System.out.println(encodingArray[i]);
}
}
System.out.println("========================================================");
}
//-----------------------------------------------------
String getOriginalString() {
return myString;
}
}
Коддогон/декоддорду камтыган класс:
public class HuffmanOperator {
private final byte ENCODING_TABLE_SIZE = 127;//длина таблицы
private HuffmanTree mainHuffmanTree;//дерево Хаффмана (используется только для сжатия)
private String myString;//исходное сообщение
private int[] freqArray;//частотаная таблица
private String[] encodingArray;//кодировочная таблица
private double ratio;//коэффициент сжатия
public HuffmanOperator(HuffmanTree MainHuffmanTree) {//for compress
this.mainHuffmanTree = MainHuffmanTree;
myString = mainHuffmanTree.getOriginalString();
encodingArray = mainHuffmanTree.getEncodingArray();
freqArray = mainHuffmanTree.getFrequenceArray();
}
public HuffmanOperator() {}//for extract;
//---------------------------------------compression-----------------------------------------------------------
private String getCompressedString() {
String compressed = "";
String intermidiate = "";//промежуточная строка(без добавочных нулей)
//System.out.println("=============================Compression=======================");
//displayEncodingArray();
for (int i = 0; i < myString.length(); i++) {
intermidiate += encodingArray[myString.charAt(i)];
}
//Мы не можем писать бит в файл. Поэтому нужно сделать длину сообщения кратной 8=>
//нужно добавить нули в конец(можно 1, нет разницы)
byte counter = 0;//количество добавленных в конец нулей (байта в полне хватит: 0<=counter<8<127)
for (int length = intermidiate.length(), delta = 8 - length % 8;
counter < delta ; counter++) {//delta - количество добавленных нулей
intermidiate += "0";
}
//склеить кол-во добавочных нулей в бинарном предаствлении и промежуточную строку
compressed = String.format("%8s", Integer.toBinaryString(counter & 0xff)).replace(" ", "0") + intermidiate;
//идеализированный коэффициент
setCompressionRatio();
//System.out.println("===============================================================");
return compressed;
}
private void setCompressionRatio() {//посчитать идеализированный коэффициент
double sumA = 0, sumB = 0;//A-the original sum
for (int i = 0; i < ENCODING_TABLE_SIZE; i++) {
if (freqArray[i] != 0) {
sumA += 8 * freqArray[i];
sumB += encodingArray[i].length() * freqArray[i];
}
}
ratio = sumA / sumB;
}
public byte[] getBytedMsg() {//final compression
StringBuilder compressedString = new StringBuilder(getCompressedString());
byte[] compressedBytes = new byte[compressedString.length() / 8];
for (int i = 0; i < compressedBytes.length; i++) {
compressedBytes[i] = (byte) Integer.parseInt(compressedString.substring(i * 8, (i + 1) * 8), 2);
}
return compressedBytes;
}
//---------------------------------------end of compression----------------------------------------------------------------
//------------------------------------------------------------extract-----------------------------------------------------
public String extract(String compressed, String[] newEncodingArray) {
String decompressed = "";
String current = "";
String delta = "";
encodingArray = newEncodingArray;
//displayEncodingArray();
//получить кол-во вставленных нулей
for (int i = 0; i < 8; i++)
delta += compressed.charAt(i);
int ADDED_ZEROES = Integer.parseInt(delta, 2);
for (int i = 8, l = compressed.length() - ADDED_ZEROES; i < l; i++) {
//i = 8, т.к. первым байтом у нас идет кол-во вставленных нулей
current += compressed.charAt(i);
for (int j = 0; j < ENCODING_TABLE_SIZE; j++) {
if (current.equals(encodingArray[j])) {//если совпало
decompressed += (char)j;//то добавляем элемент
current = "";//и обнуляем текущую строку
}
}
}
return decompressed;
}
public String getEncodingTable() {
String enc = "";
for (int i = 0; i < encodingArray.length; i++) {
if (freqArray[i] != 0)
enc += (char)i + encodingArray[i] + 'n';
}
return enc;
}
public double getCompressionRatio() {
return ratio;
}
public void displayEncodingArray() {//для отладки
System.out.println("======================Encoding table====================");
for (int i = 0; i < ENCODING_TABLE_SIZE; i++) {
//if (freqArray[i] != 0) {
System.out.print((char)i + " ");
System.out.println(encodingArray[i]);
//}
}
System.out.println("========================================================");
}
}
Файлга жазууну жеңилдеткен класс:
import java.io.File;
import java.io.PrintWriter;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.Closeable;
public class FileOutputHelper implements Closeable {
private File outputFile;
private FileOutputStream fileOutputStream;
public FileOutputHelper(File file) throws FileNotFoundException {
outputFile = file;
fileOutputStream = new FileOutputStream(outputFile);
}
public void writeByte(byte msg) throws IOException {
fileOutputStream.write(msg);
}
public void writeBytes(byte[] msg) throws IOException {
fileOutputStream.write(msg);
}
public void writeString(String msg) {
try (PrintWriter pw = new PrintWriter(outputFile)) {
pw.write(msg);
} catch (FileNotFoundException e) {
System.out.println("Неверный путь, или такого файла не существует!");
}
}
@Override
public void close() throws IOException {
fileOutputStream.close();
}
public void finalize() throws IOException {
close();
}
}
Файлдан окууну жеңилдеткен класс:
import java.io.FileInputStream;
import java.io.EOFException;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.Closeable;
import java.io.File;
import java.io.IOException;
public class FileInputHelper implements Closeable {
private FileInputStream fileInputStream;
private BufferedReader fileBufferedReader;
public FileInputHelper(File file) throws IOException {
fileInputStream = new FileInputStream(file);
fileBufferedReader = new BufferedReader(new InputStreamReader(fileInputStream));
}
public byte readByte() throws IOException {
int cur = fileInputStream.read();
if (cur == -1)//если закончился файл
throw new EOFException();
return (byte)cur;
}
public String readLine() throws IOException {
return fileBufferedReader.readLine();
}
@Override
public void close() throws IOException{
fileInputStream.close();
}
}
Ооба, жана негизги класс:
import java.io.File;
import java.nio.charset.MalformedInputException;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.NoSuchFileException;
import java.nio.file.Paths;
import java.util.List;
import java.io.EOFException;
public class Main {
private static final byte ENCODING_TABLE_SIZE = 127;
public static void main(String[] args) throws IOException {
try {//указываем инструкцию с помощью аргументов командной строки
if (args[0].equals("--compress") || args[0].equals("-c"))
compress(args[1]);
else if ((args[0].equals("--extract") || args[0].equals("-x"))
&& (args[2].equals("--table") || args[2].equals("-t"))) {
extract(args[1], args[3]);
}
else
throw new IllegalArgumentException();
} catch (ArrayIndexOutOfBoundsException | IllegalArgumentException e) {
System.out.println("Неверный формат ввода аргументов ");
System.out.println("Читайте Readme.txt");
e.printStackTrace();
}
}
public static void compress(String stringPath) throws IOException {
List<String> stringList;
File inputFile = new File(stringPath);
String s = "";
File compressedFile, table;
try {
stringList = Files.readAllLines(Paths.get(inputFile.getAbsolutePath()));
} catch (NoSuchFileException e) {
System.out.println("Неверный путь, или такого файла не существует!");
return;
} catch (MalformedInputException e) {
System.out.println("Текущая кодировка файла не поддерживается");
return;
}
for (String item : stringList) {
s += item;
s += 'n';
}
HuffmanOperator operator = new HuffmanOperator(new HuffmanTree(s));
compressedFile = new File(inputFile.getAbsolutePath() + ".cpr");
compressedFile.createNewFile();
try (FileOutputHelper fo = new FileOutputHelper(compressedFile)) {
fo.writeBytes(operator.getBytedMsg());
}
//create file with encoding table:
table = new File(inputFile.getAbsolutePath() + ".table.txt");
table.createNewFile();
try (FileOutputHelper fo = new FileOutputHelper(table)) {
fo.writeString(operator.getEncodingTable());
}
System.out.println("Путь к сжатому файлу: " + compressedFile.getAbsolutePath());
System.out.println("Путь к кодировочной таблице " + table.getAbsolutePath());
System.out.println("Без таблицы файл будет невозможно извлечь!");
double idealRatio = Math.round(operator.getCompressionRatio() * 100) / (double) 100;//идеализированный коэффициент
double realRatio = Math.round((double) inputFile.length()
/ ((double) compressedFile.length() + (double) table.length()) * 100) / (double)100;//настоящий коэффициент
System.out.println("Идеализированный коэффициент сжатия равен " + idealRatio);
System.out.println("Коэффициент сжатия с учетом кодировочной таблицы " + realRatio);
}
public static void extract(String filePath, String tablePath) throws FileNotFoundException, IOException {
HuffmanOperator operator = new HuffmanOperator();
File compressedFile = new File(filePath),
tableFile = new File(tablePath),
extractedFile = new File(filePath + ".xtr");
String compressed = "";
String[] encodingArray = new String[ENCODING_TABLE_SIZE];
//read compressed file
//!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!check here:
try (FileInputHelper fi = new FileInputHelper(compressedFile)) {
byte b;
while (true) {
b = fi.readByte();//method returns EOFException
compressed += String.format("%8s", Integer.toBinaryString(b & 0xff)).replace(" ", "0");
}
} catch (EOFException e) {
}
//--------------------
//read encoding table:
try (FileInputHelper fi = new FileInputHelper(tableFile)) {
fi.readLine();//skip first empty string
encodingArray[(byte)'n'] = fi.readLine();//read code for 'n'
while (true) {
String s = fi.readLine();
if (s == null)
throw new EOFException();
encodingArray[(byte)s.charAt(0)] = s.substring(1, s.length());
}
} catch (EOFException ignore) {}
extractedFile.createNewFile();
//extract:
try (FileOutputHelper fo = new FileOutputHelper(extractedFile)) {
fo.writeString(operator.extract(compressed, encodingArray));
}
System.out.println("Путь к распакованному файлу " + extractedFile.getAbsolutePath());
}
}
Readme.txt файлын өзүңүз жазышыңыз керек болот :)
жыйынтыктоо
Менин айткым келгени ушул болду окшойт. Эгерде сизде кодду, алгоритмди же жалпысынан кандайдыр бир оптималдаштырууну өркүндөтүү боюнча менин компетентсиздигим жөнүндө айта турган нерсеңиз болсо, анда жазыңыз. Эгерде мен эч нерсе түшүндүрө элек болсом, анда да жазыңыз. Комментарийлерде сизден кабар алгым келет!
PS
Ооба, ооба, мен дагы эле ушул жердемин, анткени коэффициентти унуткан жокмун. s1 сабы үчүн коддоо таблицасынын салмагы 48 байт - баштапкы файлдан бир топ чоң, жана биз кошумча нөлдөрдү унуткан жокпуз (кошулган нөлдөрдүн саны 7) => кысуу катышы бирден азыраак болот: 176/ (65 + 48*8 + 7) = 0.38. Эгер сиз да муну байкаган болсоңуз, анда бул сиздин жүзүңүз гана эмес. Ооба, бул ишке ашыруу кичинекей файлдар үчүн өтө натыйжасыз болот. Бирок чоң файлдар менен эмне болот? Файлдын өлчөмдөрү коддоо таблицасынын өлчөмүнөн алда канча чоңураак. Бул жерде алгоритм керек болсо иштейт! Мисалы, үчүн Архиватор 1.46 реалдуу (идеалдуу эмес) коэффициентти чыгарат - дээрлик бир жарым эсе! Ооба, файл англис тилинде болушу керек болчу.
Source: www.habr.com
