

Эски модадагы жакшы жашынмак оюну жасалма интеллект (AI) боттору үчүн алар кандай чечим чыгарарын жана бири-бири менен жана алардын айланасындагы ар кандай объектилер менен өз ара аракеттенишээрин көрсөтүү үчүн сонун сыноо болушу мүмкүн.
анын , белгилүү болуп калган коммерциялык эмес жасалма интеллект изилдөө уюмунун OpenAI изилдөөчүлөрү тарабынан жарыяланган. Dota 2 компьютердик оюнунда илимпоздор жасалма интеллект менен башкарылган агенттер виртуалдык чөйрөдө бири-биринен жашырынып, издөөдө татаалыраак болууга кантип үйрөтүлгөнүн сүрөттөшөт. Изилдөөнүн жыйынтыгы көрсөткөндөй, эки боттон турган команда союздаштары жок бир агентке караганда натыйжалуураак жана тезирээк үйрөнөт.

Окумуштуулар көптөн бери атак-даңкка ээ болгон ыкманы колдонушкан , анда жасалма интеллект аны менен өз ара аракеттенүүнүн белгилүү ыкмаларына ээ болуу менен ага белгисиз чөйрөгө жайгаштырылган, ошондой эле анын иш-аракеттеринин тигил же бул натыйжасы үчүн сыйлыктар жана айып пулдар системасы бар. Бул ыкма AI виртуалдык чөйрөдө ар кандай аракеттерди адам ойлогондон миллиондогон эсе ылдам, эбегейсиз ылдамдыкта аткарууга жөндөмдүү болгондуктан, кыйла натыйжалуу. Бул сыноо жана ката аркылуу берилген маселени чечүү үчүн эң натыйжалуу стратегияларды табууга мүмкүндүк берет. Бирок бул ыкманын да кээ бир чектөөлөрү бар, мисалы, чөйрөнү түзүү жана көптөгөн окуу циклдерин өткөрүү чоң эсептөө ресурстарын талап кылат, ал эми процесстин өзү AI иш-аракеттеринин натыйжаларын анын максаты менен салыштыруу үчүн так системаны талап кылат. Мындан тышкары, агент тарабынан ушундай жол менен алынган көндүмдөр сүрөттөлгөн тапшырма менен чектелет жана AI аны менен күрөшүүгө үйрөнгөндөн кийин, андан ары өркүндөтүүлөр болбойт.
AIны жашынмак ойноого үйрөтүү үчүн илимпоздор "Багытсыз чалгындоо" деп аталган ыкманы колдонушту, мында агенттер оюн дүйнөсү жөнүндө түшүнүгүн өркүндөтүү жана утуп алуу стратегияларын иштеп чыгуу үчүн толук эркиндикке ээ. Бул DeepMind изилдөөчүлөрү бир нече жасалма интеллект системаларында колдонгон мульти-агенттүү окутуу ыкмасына окшош. . Бул учурда, AI агенттери мурда оюндун эрежелери боюнча үйрөтүлгөн эмес, бирок убакыттын өтүшү менен алар негизги стратегияларды үйрөнүп, атүгүл маанилүү эмес чечимдер менен изилдөөчүлөрдү таң калтыра алышкан.
Жашынмак оюнунда, бир нече агенттин иши жашырынууга тийиш болгон, издөө агенттеринин командасы кыймылсыз болуп турганда, бир аз старт алгандан кийин, атаандаштарынын көз карашынан качышы керек болчу. Мындан тышкары, бул контекстте "көз карашы" жеке боттун алдында 135 градус конус болуп саналат. Агенты не могли удаляться слишком далеко за пределы игровой площадки и были вынуждены перемещаться по случайно сгенерированным комнатам с возможностью использовать некоторые внешние объекты (ящики, передвижные стены, специальные пандусы), разбросанные вокруг, которые можно было использовать как для создания укрытий, так и для проникновения аларда.
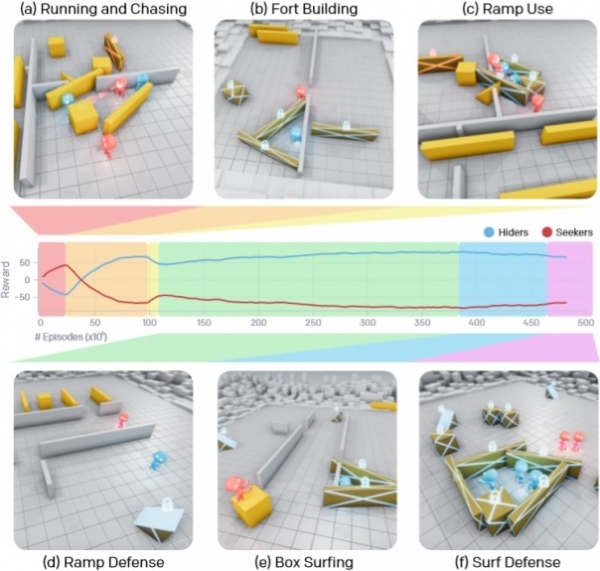
Узакка созулган окуу процесси аркылуу AI агенттери алты уникалдуу стратегияны үйрөнүштү, алардын ар бири аларга оюндун кийинки этабына өтүүгө жардам берди. Адегенде издөөчүлөр жана жашынуучу топтор жөн эле качып, бири-бирин кууп чыгышкан, бирок 25 миллионго жакын беттешүүдөн кийин жашынуучу топ кутулар менен өтмөктөрдү жаап, алардан баш калкалоочу жайларды курууну үйрөнүшкөн. Дагы 75 миллион матчтан кийин команда бул жашынган жерлерге кирүү үчүн пандустарды колдонуу жолдорун тапты. Дагы 10 миллион раунддан кийин жашынуучулар пандустарды оюн аянтчасынын четине сүйрөп чыгып, каршылаштары пайдаланбашы үчүн аларды бекитип алууну үйрөнүштү.

388 миллион ширенкеден кийин издөөчүлөр тосулган пандустарды колдонуп, аларга алынып келинген ящиктерге чыгууну үйрөнүштү, андан кийин түздөн-түз алардын үстүнө жылып, көчмө дубалдардан түзүлгөн душмандын жашырынуу жайларына кирип кетишти. Акыр-аягы, 458 миллион матчтан кийин, жашырынган команда бардык объектилерди жаап, андан кийин баш калкалоочу жай куруу керек деген тыянакка келишти, бул алардын акыркы жеңишине алып келди.
Өзгөчө таасирдүү нерсе, 22 миллион матчтан кийин агенттер өз аракеттерин координациялоону үйрөнүштү жана алардын кызматташуусунун натыйжалуулугу келечекте гана жогорулады, мисалы, баш калкалоочу жайды түзүү үчүн ар бири өз кутусун же дубалын алып келип, объекттердин өз үлүшүн тандап алды. блок, каршылаштарына кыйынчылык оюнду татаалдаштырат.

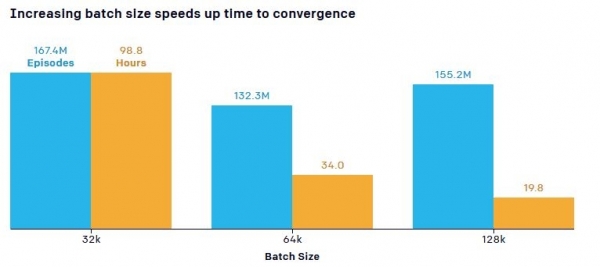
Окумуштуулар окутуунун ылдамдыгына окутуу объектилеринин санынын (нейрондук тармак аркылуу өтүүчү маалыматтардын көлөмү – “Партиянын көлөмү”) таасирине байланыштуу маанилүү жагдайды да белгилешти. Демейки модель жашынган топ пандустарды тосууну үйрөнгөн чекитке жетүү үчүн 132,3 сааттык машыгуунун ичинде 34 миллион матчты талап кылды, ал эми көбүрөөк маалымат машыгуу убактысынын байкаларлык кыскарышына алып келди. Мисалы, параметрлердин санын (тренингдин бүткүл процессинде алынган маалыматтардын бир бөлүгү) 0,5 миллиондон 5,8 миллионго чейин көбөйтүү, тандоонун эффективдүүлүгүн 2,2 эсеге жогорулатты, ал эми киргизилген маалыматтардын көлөмүн 64 КБдан 128 КБга чейин көбөйтүү окутууну азайтты. убакыт дээрлик бир жарым эсе.
Ишинин аягында изилдөөчүлөр оюндагы машыгуу агенттерге оюндан тышкары ушул сыяктуу тапшырмаларды аткарууга канчалык жардам бере аларын сынап көрүүнү чечишти. Бардыгы болуп беш тест болду: объекттердин санын билүү (объект көзгө көрүнбөй, колдонулбаса дагы бар экенин түшүнүү); "кулпу жана кайтып келүү" - баштапкы абалын эстеп калуу жана кандайдыр бир кошумча тапшырманы аткаргандан кийин ага кайтып келүү; "ырааттуу бөгөттөө" - 4 куту эшиги жок үч бөлмөгө туш келди жайгаштырылган, бирок ичине кирүү үчүн пандустар бар, агенттер алардын баарын таап, бөгөттөш керек болчу; кутуларды алдын ала белгиленген сайттарга жайгаштыруу; цилиндр түрүндөгү объектинин айланасында баш калкалоочу жайды түзүү.
Натыйжада беш тапшырманын үчөөндө оюнда алдын ала машыгуудан өткөн боттор маселелерди нөлдөн баштап чечүүгө үйрөтүлгөн AIга караганда тезирээк үйрөнүп, жакшы натыйжаларды көрсөтүштү. Алар тапшырманы аткарууда жана баштапкы абалга кайтып келүүдө, жабык бөлмөлөрдөгү кутуларды ырааттуу түрдө тосууда жана берилген жерлерге кутуларды коюуда бир аз жакшыраак аткарышты, бирок объекттердин санын таанууда жана башка объекттин айланасын жабууда бир аз начарыраак аткарышты.
Окумуштуулар аралаш натыйжаларды AI кантип үйрөнүп, белгилүү бир көндүмдөрдү эстеп калганына байланыштырышат. "Оюндун алдындагы машыгуу эң жакшы аткарылган тапшырмалар мурда үйрөнүлгөн көндүмдөрдү тааныш жол менен кайра колдонууну камтыган, ал эми калган тапшырмаларды нөлдөн баштап үйрөтүлгөн AIга караганда жакшыраак аткаруу аларды башка жол менен колдонууну талап кылат деп ойлойбуз. кыйыныраак» деп жазышат чыгарманын авторлоштору. "Бул жыйынтык окутуу аркылуу алынган көндүмдөрдү бир чөйрөдөн экинчисине өткөрүүдө натыйжалуу кайра колдонуу ыкмаларын иштеп чыгуу зарылдыгын көрсөтөт."
Аткарылган иш чынында эле таасирдүү, анткени бул окутуу ыкмасын колдонуунун келечеги ар кандай оюндардын чегинен алыс. Окумуштуулардын айтымында, алардын иши ооруларды диагностикалоого, татаал протеин молекулаларынын структураларын болжолдоого жана КТ сканерлерин талдай ала турган "физикага негизделген" жана "адамга окшош" жүрүм-туруму бар AI түзүү үчүн маанилүү кадам болуп саналат.
Төмөнкү видеодо сиз бүтүндөй окуу процесси кантип өткөнүн, AI кантип командада иштөөгө үйрөнгөнүн жана анын стратегиялары барган сайын куу жана татаал болуп калганын ачык көрө аласыз.

Source: 3dnews.ru
