


Hi omnes! Nomen meum est Oleg Sidorenkov, DomClick laboro ut caput quadrigis infrastructurae. Plus quam tres annos in productione Kubik usi sumus, et hoc tempore multa et varia momenta iucunda experti sumus cum ea. Hodie tibi narrabo quomodo, recta accessione, etiam plura ex vanilla Kubernetes ob botrum tuum exprimi potes. Go parati stabilis!
Optime nosti omnes Kubernetes esse scalam apertam fontem systematis continentis orchestrationis; bene, vel 5 binarii qui magicae operantur ad vitam cycli micro- riorum tuorum administrando in ambitu servientis. Praeterea instrumentum satis flexibile est, quod sicut Lego congregari potest ad maximam customizationem pro diversis operibus.
Et omnia bene esse videntur: servientes in botrum mitte ut ligna in caminata, et dolorem aliquem nescies. Sed si ambitus es, cogitabis: "Quomodo possum ignem ardentem servare et sylvae parcere?" Aliis verbis, quomodo invenire vias infrastructuras emendare et gratuita reducere.
1. Monitor team and application resources

Una communissima, sed modi efficax introductio precum/ limitum. Applicationes per spatia nomina divide, et spatia nomina per iunctos evolutionis. Priusquam instruere, pone valores applicationes ad consumptionem processus temporis, memoriae ac ephemeridis.
resources:
requests:
memory: 2Gi
cpu: 250m
limits:
memory: 4Gi
cpu: 500mPer experientiam venimus conclusionem: ne plus quam bis petitiones inflare debeas. Volumen botri in petitionibus computatur, et si applicationes differentias facultatum dabis, exempli gratia, 5-10 temporibus, tunc cogita quid nodo tuo eventurum sit, cum siliquis impletur et subito onus accipit. nihil boni. Ad minimum, iugulum, et ad maximum, vale dices opifici et onus cyclicum obtine in reliquis nodis post siliquas incipiunt.
Praeterea, ope limitranges In initio, valores copiae pro continente - minimum, maximum et defaltum potes constituere;
➜ ~ kubectl describe limitranges --namespace ops
Name: limit-range
Namespace: ops
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu 50m 10 100m 100m 2
Container ephemeral-storage 12Mi 8Gi 128Mi 4Gi -
Container memory 64Mi 40Gi 128Mi 128Mi 2Noli oblivisci facultates nominandi limitare ut una turma non possit omnes copias botri accipere;
➜ ~ kubectl describe resourcequotas --namespace ops
Name: resource-quota
Namespace: ops
Resource Used Hard
-------- ---- ----
limits.cpu 77250m 80
limits.memory 124814367488 150Gi
pods 31 45
requests.cpu 53850m 80
requests.memory 75613234944 150Gi
services 26 50
services.loadbalancers 0 0
services.nodeports 0 0Ut videri potest ex descriptione resourcequotas, si Opis turmae siliquas quae alias 10 cpu consumet explicare vult, cedula hoc non admittit et errorem mittet;
Error creating: pods "nginx-proxy-9967d8d78-nh4fs" is forbidden: exceeded quota: resource-quota, requested: limits.cpu=5,requests.cpu=5, used: limits.cpu=77250m,requests.cpu=53850m, limited: limits.cpu=10,requests.cpu=10Ad hanc quaestionem solvendam, instrumentum scribere potes, e.g copia atque imperio rempublicam committere posset.
2. elige meliorem file repono
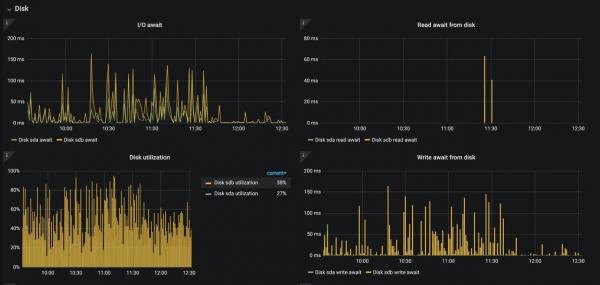
Hic velim perstare thema voluminum assiduorum et subsystem disci subsystem nodis laborantis Kubernetes. Spero neminem "Cubum" in productione HDD uti, sed interdum iustae SSD satis iam non est. Difficultatem invenimus ubi tigna orbis obtruncant ob operationes I/O, et multae non sunt solutiones:
Summus opera SSDs utere vel ad NVMe transi (si tuo proprio ferramento cures).
Logging reducere massa.
Fac "captiosus" siliquas aequante quod rapere orbis (
podAntiAffinity).
Tegumentum supra demonstrat id quod sub nginx-ingresso-rectoris disco accidit cum access_logorum logging capacitas est (~12 milia lignorum/sec). Haec conditio, utique, ad degradationem omnium applicationum in hoc nodo ducere potest.
Quod ad PV, heu, non omnia expertus sum Volumen Pertinax. Optima utere optione quae te decet. Historice in nostra regione factum est ut parva pars officiorum RWX volumina requireret, et iam olim NFS repositione ad hoc opus uti coeperunt. Vilis et satis. Utique ipse et ego cacas - benedicimus tibi, sed eam modulari didicimus, et caput meum amplius non dolet. Et si fieri potest, move ad S3 obiectum repono.
3. Oratio optimized imagines

Praestat ut imagines continente-optimized ut Kubernetes citius illas afferat et efficacius exequatur.
Optime significat imagines;
unam tantum applicationem vel unam tantum functionem praestare;
parvi ponderis, quia magnae imagines in retiaculis deteriores transmittuntur;
Sanitatis et promptitudinis terminos habent, qui Kubernetes in eventu temporis temporis agere permittunt;
utere vasis amicabilibus systematibus operantibus (velut Alpino vel CoreOS), quae magis repugnant errori conformatione;
uti multi scaena aedificat ita ut applicationes confectas tantum explicas et non fontes comitantes possis.
Multa instrumenta et operae sunt quae te imagines in musca frenare et optimize permittunt. Interest semper eas servare ac pro salute probatum. Itaque accipias:
Onus retis in totum botrum reducitur.
Reducing continens startup tempus.
Minores magnitudinis totius Docker subcriptio.
4. Usus DNS cache

Si de magnis oneribus loquimur, vita est satis otiosa sine systemate botri DNS. Olim tincidunt Kubernetes solutionem suam kube-dns sustentabant. Etiam hic effectum est, sed haec programmatio non in primis versabatur neque debitam observantiam producebat, quamvis simplex negotium esse videbatur. Tunc coredns apparuit, quem mutavimus et nullum dolorem habuimus, postea vero defectus DNS servitii in K8s factus est. Aliquando ad quadraginta milia RPS ad systema DNS crevit, quae solutio etiam insufficiens facta est. Sed, fortuna, Nodelocaldns exivit, aka nodi cache localis, aka .
Cur hoc utimur? In nucleo Linux Est vitium quod, cum petitiones multiplices per Conntrack NAT super UDP fiunt, condicionem certaminis (concurrency condition) pro inscriptionibus in tabulis Conntrack efficit, et pars commeatus per NAT perditur (omnis saltus per Servitium est NAT). Nodelocaldns hanc difficultatem solvit eliminando NAT et nexum ad TCP pro DNS sursum versus elevando, necnon recondendo localiter petitiones DNS ad DNS sursum versus (inclusa brevi cella negativa quinque secundorum).
5. Scala siliquae perpendiculariter et perpendiculariter automatice
Potesne confidenter dicere omnia opera tua parata esse duobus ad triplum oneris incremento? Quomodo opes apte collocant ad applicationes tuas? Custodiens duos siliquas ultra quod inposuit potest redundare, retinens autem ad dorsum periculum temporis incurrit ex subito incremento mercaturae ad servitium. Officia ut и .
VPA sino te statim petitiones tuas/fines vasorum tuorum in legumine pendere usu ipso pendere. Quomodo utilis? Si siliquas habes quae aliqua de causa horizontaliter scandere non possunt (quod omnino certum non est), tunc probare potes mutationes suas facultatibus committere VPA. Eius pluma est ratio commendaticiis fundata in notitia historica et currenti a metrico-servo, quare si non vis postulationes/fines automatice mutare, simpliciter monitor opes suas commendare potes pro continentia et optimize occasus servare CPU et memoria in botro.
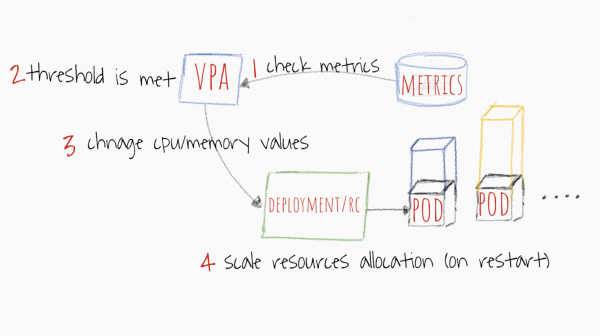 Imago sumpta ex https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Imago sumpta ex https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Schedularum in Kubernetibus petitionibus semper innititur. Quantitatem ibi posuistis, cedula nodi aptam in eo fundatam perquiret. Valores limites ad cubelet opus sunt intelligendum quando suffocare vel vasculum necare. Et cum solus modulus maximus sit petitiones pretii, VPA cum eo laborabit. Quoties applicationem directe scandis, definis quid sit petitio. Quid ergo ad fines eveniet? Hic modulus etiam proportionaliter escendetur.
For example, here are the usual pod settings;
resources:
requests:
memory: 250Mi
cpu: 200m
limits:
memory: 500Mi
cpu: 350mMachinam commendationem decernit ut applicatio tua 300m CPU et 500Mi ad recte currendum requiratur. Sequentes occasus erit:
resources:
requests:
memory: 500Mi
cpu: 300m
limits:
memory: 1000Mi
cpu: 525mUt supra, haec est scala proportionalis innixa petitionibus limitum rationum in manifesta:
CPU: 200m → 300m: ratio 1:1.75;
Memoria: 250Mi → 500Mi: ratio 1:2.
cum de HPAergo machina operationis est magis perspicua. Metrica ut CPU et memoria limen sunt, et si mediocris omnium replicationum limen excedit, applicatio scalis +1 sub dum valorem infra limen cadit vel donec maximus numerus replicationum pervenerit.
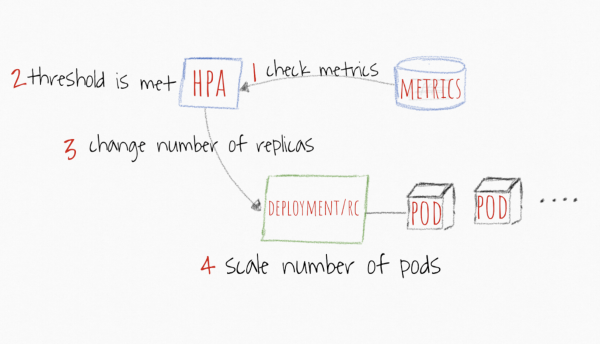 Imago sumpta ex https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Imago sumpta ex https://levelup.gitconnected.com/kubernetes-autoscaling-101-cluster-autoscaler-horizontal-pod-autoscaler-and-vertical-pod-2a441d9ad231
Praeter usitatas metri similes CPU et memoriam, limina consuetudini tuae ex Prometheo metri facere potes et cum illis operari, si accuratissimum esse putes indicium cum applicatione tua conscenderis. Semel applicatio stabilit sub limine metrico definito, HPA siliquas ascendere incipiet usque ad minimum numerum replicationum vel usque dum onus certum limen occurrit.
6. Noli oblivisci de Node Affinitatis et Pod affinitatis

Non omnes nodi eodem ferramento currunt, nec siliquae omnes applicationes intensivae computatae currunt. Kubernetes permittit ut specializationem nodis et siliquis utendi Node affinitas и Pod affinitas.
Si nodos habes ad operationes computandas intensivas aptas, tunc ad maximam efficaciam melius est applicationes ad nodos respondentes ligare. Ad hoc usus nodeSelector cum nodi pittacium.
Duo nodos dicamus te habere: unum cum CPUType=HIGHFREQ et numerus celeriter metretas, alius cum MemoryType=HIGHMEMORY plura memoria et velocius exequantur. Facillima via est nodi assignare instruere HIGHFREQaddendo ad sectionem spec hoc electrix:
…
nodeSelector:
CPUType: HIGHFREQModo magis carus et specifice hoc facere est uti nodeAffinity in agro affinity razdela spec. Duo sunt bene:
requiredDuringSchedulingIgnoredDuringExecution: siliquas tantum in certis nodis explicabit (nec alibi) (schedula) siliquas explicabit);preferredDuringSchedulingIgnoredDuringExecution: occasus mollis (schedularum certis nodis explicare conabitur, et si deficit, nodi proximo disponere conabitur).
Specificare specifica syntaxin ad pittacia nodi administranda, ut In, NotIn, Exists, DoesNotExist, Gt aut Lt. Sed memento quod multiplex methodus in longis pittaciis indicem retardabit decisionem in rebus criticis faciendis. Id est, simplicem retinent.
Ut supra dictum est, Kubernetes permittit tibi ut siliquae hodiernae affinitas collocetur. Hoc est, efficere potes ut quaedam siliquae cum aliis siliquis in eadem promptitudine zonae (ad nubes pertinentes) vel nodis cooperantur.
В podAffinity agri affinity razdela spec eosdem agros praesto sunt apud of * nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution и preferredDuringSchedulingIgnoredDuringExecution. Sola differentia est matchExpressions siliquas ad nodi ligaturam, quae iam cum pittacio illo vasculum currit.
Kubernetes etiam agrum offert podAntiAffinityquod e contrario vasculum nodi non ligat cum legumine specificis.
De verbis nodeAffinity Idem admoneri potest: regulas simplices et logicas servare stude, ne leguminem specificationem cum multiplici regularum statuto onerare conaris. Facillimum est regulam creare quae condicionibus botri non congruit, superfluum onus in schedula creans et ad altiorem effectum redigendo.
7. Taints & tolerantiae
Est alius modus regendi schedulae. Si magnum botrum cum centenis nodis et millibus microserviorum habes, difficillimum est ne siliquas quasdam certis nodis evinciantur.
In hac machinationes labes - praecepta prohibentes - adiuvat. Exempli causa, in quibusdam missionibus potes quosdam nodos prohibere siliquas. Adhibere labem ad nodi specifica uti optio debes taint in kubectl. Specificare clavem et valorem ac deinde labem similem NoSchedule aut NoExecute:
$ kubectl taint nodes node10 node-role.kubernetes.io/ingress=true:NoScheduleEtiam notatu dignum est mechanismum lues tres effectus principales sustinere; NoSchedule, NoExecute и PreferNoSchedule.
NoSchedulesignificat quod nunc nullum erit ingressum in legumen specificatione respondentemtolerations, nodo explicari non poterit (in hoc exemplonode10).PreferNoSchedule- versio simpliciorNoSchedule. Hoc in casu, cedula temptabit ne siliquas collocare quae ingressum non congruentem habenttolerationsper node, sed haec limitatio dura non est. Si copiae non sunt in botro, siliquae in hac nodo explicari incipient.NoExecute- hunc effectum saltem evacuatio siliquae proximae quae ingressum non habet congruentemtolerations.
Interestingly, haec agendi ratio utens tolerationes mechanismi cassari potest. Hoc opportunum est cum nodi "prohibiti" sunt et tantum opus est ut officia infrastructura in ea ponant. Quomodo facere? Siliquas illas tantum concedunt quibus idonea est tolerantia.
Hic est quid legumen speciem quaerere velim:
spec:
tolerations:
- key: "node-role.kubernetes.io/ingress"
operator: "Equal"
value: "true"
effect: "NoSchedule"Hoc non significat quod proximus redeploy in hac particulari nodi cadet, hanc affinitatem nodi mechanismi et non esse. nodeSelector. Sed iungendo plures lineas, flexibiles occasus efficere potes.
8. Pone Pod instruere prioritatem
Quia siliquas nodis assignavit, non significat omnes siliquas eodem prioritate tractandas esse. Exempli gratia, siliquas quasdam ante alios explicari velis.
Kubernetes diversis modis Pod Prioritatem et Preemptionem configurandi praebet. Obiectio pluribus partibus constat: object PriorityClass et ager descriptiones priorityClassName in vasculi specificatione. Intueamur exemplum:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 99999
globalDefault: false
description: "This priority class should be used for very important pods only"Nos creare PriorityClassda ei nomen, descriptionem et valorem. Altior valuetanto prius. Valor esse potest quamlibet 32-bitrum integer minus quam vel 1 par. Superiores valores siliquae systematis missioni-criticae reservantur, quae plerumque occupari non possunt. Dispositio solum fiet si vasculum summum prioratus locum non habet ut se circumflectat, tunc siliquae quaedam ex nodo quadam evacuentur. Si haec machina nimis rigida est pro te, optionem addere potes preemptionPolicy: Neveret tunc nulla preemptio erit, vasculum primum in queue stabit et schedulam expectabit ut liberas facultates ei inveniat.
Deinde creamus vasculum in quo nomen indicamus priorityClassName:
apiVersion: v1
kind: Pod
metadata:
name: static-web
labels:
role: myrole
spec:
containers:
- name: web
image: nginx
ports:
- name: web
containerPort: 80
protocol: TCP
priorityClassName: high-priority
Tot genera prioritas creare potes quot voles, cum hoc commendatur ne auferas (inquam te ipsum ad humilem, medium et praecipuum modum).
Sic, si opus est, augere potes efficientiam criticam explicandi muneris, ut nginx-ingressor, moderator, coredns, etc.
9. Optimise botrum etc

ETCD cerebrum totius botri dici potest. Magni interest ut operationem huius database in altam servet, quia celeritas operationum in Cube ab ea pendet. Vexillum satis, et simul, solutionem bonam fore ad custodiam ETCD botrum nodi magistrorum ut minimam moram kube-apiservatori habeat. Si hoc non potes facere, pone quam proxime ETCD, band bonam inter participes. Item attende quot nodos de ETCD sine dampno botri cadere possit
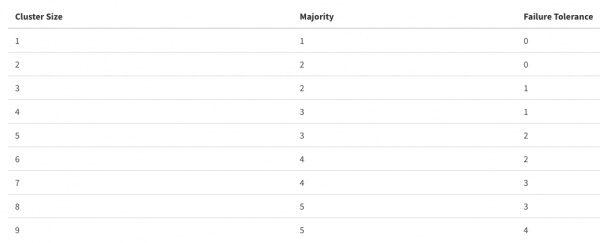
Meminerint quod nimis augere numerum membrorum in botro posse augeri culpae tolerantiae sumptu effectus, omnia moderata esse debent.
Si loquimur de institutione muneris, pauca sunt commendationes;
Habere bene hardware, secundum magnitudinem botri (legere potes) ).
Tweak paucos parametros si botrum inter duas DCs vel retis et orbis disieceris multum optandum (legere potes. ).
conclusio,
Hic articulus describitur puncta quae turma nostra parere conatur. Haec descriptio actionum non gradatim est, sed optiones utiles ad botrum capitis optimizing. Patet unumquemque botrum singulariter esse suo modo, et solutiones conformationis multum variari possunt, ita interest ut tuas opiniones in quomodo tu monitores tuos uvas Kubernetes et quomodo perficias emendas. Experientiam tuam communica in comment, interesting scire erit.
Source: www.habr.com
")