


Den 9. Januar gouf Pandas 1.0.0rc verëffentlecht. Déi viregt Versioun vun der Bibliothéik ass 0.25.
Déi éischt grouss Verëffentlechung enthält vill super nei Features, inklusiv verbessert automatesch Dateframe Summatioun, méi Ausgangsformater, nei Datentypen, a souguer eng nei Dokumentatiounssäit.
All Ännerungen kënne gekuckt ginn , am Artikel beschränke mir eis op eng kleng, manner technesch Iwwerpréiwung vun de wichtegste Saachen.
Dir kënnt d'Bibliothéik wéi gewinnt installéieren Pip, awer zënter dem Schreiwen ass Pandas 1.0 nach ëmmer Fräisetzung Kandidat, Dir musst d'Versioun explizit uginn:
pip install --upgrade pandas==1.0.0rc0Sidd virsiichteg: well dëst eng grouss Verëffentlechung ass, kann den Update den alen Code briechen!
Iwwregens, Ënnerstëtzung fir Python 2 ass zënter dëser Versioun komplett gestoppt (wat kéint e gudde Grond sinn — ca. Iwwersetzung). Pandas 1.0 erfuerdert op d'mannst Python 3.6+, also wann Dir net sécher sidd, kontrolléiert wéi eng Dir installéiert hutt:
$ pip --version
pip 19.3.1 from /usr/local/lib/python3.7/site-packages/pip (python 3.7)
$ python --version
Python 3.7.5Deen einfachste Wee fir d'Pandas Versioun ze kontrolléieren ass dëst:
>>> import pandas as pd
>>> pd.__version__
1.0.0rc0Verbessert Auto-Zesummesetzung mat DataFrame.info
Meng Liiblingsinnovatioun war d'Aktualiséierung vun der Method DataFrame.info. D'Funktioun ass vill méi liesbar ginn, wat de Prozess vun der Datefuerschung nach méi einfach mécht:
>>> df = pd.DataFrame({
...: 'A': [1,2,3],
...: 'B': ["goodbye", "cruel", "world"],
...: 'C': [False, True, False]
...:})
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 3 non-null int64
1 B 3 non-null object
2 C 3 non-null object
dtypes: int64(1), object(2)
memory usage: 200.0+ bytesErausginn Dëscher am Markdown Format
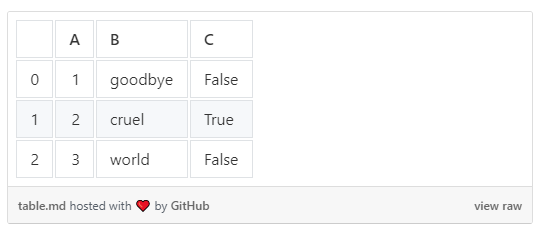
Eng gläich agreabel Innovatioun ass d'Fäegkeet fir Datenframes op Markdown Dëscher ze exportéieren DataFrame.to_markdown.
>>> df.to_markdown()
| | A | B | C |
|---:|----:|:--------|:------|
| 0 | 1 | goodbye | False |
| 1 | 2 | cruel | True |
| 2 | 3 | world | False |Dëst mécht et vill méi einfach Dëscher op Siten wéi Medium ze publizéieren mat github Gists.
Nei Zorte fir Strings a Booleaner
D'Pandas 1.0 Verëffentlechung huet och nei bäigefüügt experimentell Zorte. Hir API kann nach ëmmer änneren, also benotzt se mat Vorsicht. Awer am Allgemengen, Pandas recommandéiert nei Zorten ze benotzen wou et Sënn mécht.
Fir de Moment muss de Besetzung explizit gemaach ginn:
>>> B = pd.Series(["goodbye", "cruel", "world"], dtype="string")
>>> C = pd.Series([False, True, False], dtype="bool")
>>> df.B = B, df.C = C
>>> df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 3 non-null int64
1 B 3 non-null string
2 C 3 non-null bool
dtypes: int64(1), object(1), string(1)
memory usage: 200.0+ bytesNotéiert wéi d'Kolonn D-Typ weist nei Typen - String и bool.
Déi nëtzlechst Feature vum neie Stringtyp ass d'Fäegkeet ze wielen nëmmen Rei Kolonnen aus dateframes. Dëst kann d'Parsing vun Textdaten vill méi einfach maachen:
df.select_dtypes("string")Virdrun konnten Zeilenkolonnen net ausgewielt ginn ouni explizit Nimm ze spezifizéieren.
Dir kënnt méi iwwer nei Zorte liesen .
Merci fir d'Liesen! Déi komplett Lëscht vun Ännerungen, wéi scho gesot, kann gekuckt ginn .
Source: will.com
