

Wéinst menger Aarbechtslinn muss ech mat Situatiounen këmmeren wann en Entwéckler eng Ufro schreift an denkt "D'Basis ass schlau, et kann alles selwer handhaben!«
A verschiddene Fäll (deelweis aus Ignoranz vun de Fäegkeeten vun der Datebank, deelweis vu virzäitegen Optimisatiounen), féiert dës Approche zum Erscheinungsbild vun "Frankensteins".
Als éischt ginn ech e Beispill vun esou enger Demande:
-- для каждой ключевой пары находим ассоциированные значения полей
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- находим min/max значений для каждого первого ключа
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- связываем по первому ключу ключевые пары и min/max-значения
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;Fir d'Qualitéit vun enger Ufro substantiell ze evaluéieren, loosst eis e puer arbiträr Dateset erstellen:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
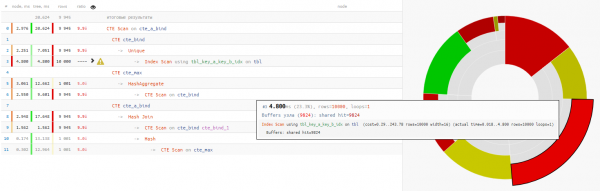
Et stellt sech eraus datt d'Liesen vun den Donnéeën huet manner wéi e Véierel vun der Zäit gedauert Ufro Ausféierung:
Stéck fir Stéck auserneen huelen
Loosst eis d'Ufro méi no kucken a verwonnert sinn:
- Firwat ass MAT RECURSIVE hei wann et keng rekursiv CTEs sinn?
- Firwat min / Max Wäerter an engem separaten CTE gruppéiere wa se dann iwwerhaapt un d'Original Probe gebonne sinn?
+25% Zäit - Firwat benotzt en bedingungslosen 'SELECT * FROM' um Enn fir de fréiere CTE ze widderhuelen?
+14% Zäit
An dësem Fall ware mir ganz glécklech datt Hash Join fir d'Verbindung gewielt gouf, an net Nested Loop, well dann hätte mir net nëmmen een CTE Scan Pass kritt, mee 10K!
e bëssen iwwer CTE ScanHei musse mir dat erënneren CTE Scan ass ähnlech wéi Seq Scan - dat heescht keng Indexéierung, awer nëmmen eng komplett Sich, déi erfuerdert 10K x 0.3ms = 3000ms fir Zyklen duerch cte_max oder 1K x 1.5ms = 1500ms wann Dir duerch cte_bind!
Eigentlech, wat wollt Dir als Resultat kréien? Jo, normalerweis ass dëst d'Fro, déi iergendwou an der 5.
Mir wollten fir all eenzegaarteg Schlësselpaar erausginn min/max aus der Grupp duerch key_a.
Also loosst eis et dofir benotzen :
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a); 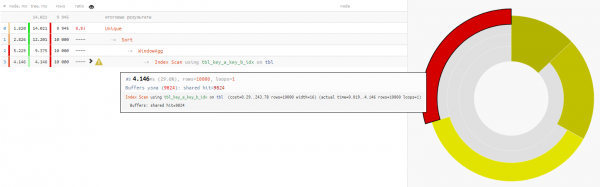
Zënter d'Liesen vun Daten a béid Optiounen dauert déiselwecht ongeféier 4-5ms, dann all eis Zäit gewannen -32% - dëst ass a senger purster Form Laascht aus der Basis CPU geläscht, wann esou eng Demande dacks genuch ausgefouert gëtt.
Am Allgemengen, sollt Dir d'Basis net forcéieren fir "de ronnen ze droen, de Quadrat ze rullen."
Source: will.com
