

Periodesch entsteet d'Aufgab fir verwandte Daten ze sichen mat enger Rei vu Schlësselen. bis mir déi néideg Gesamtzuel vun de Rekorder kréien.
Dat "richtegt Liewen" Beispill ass ze weisen 20 eelste Problemer, opgezielt op der Lëscht vun de Mataarbechter (zum Beispill, bannent enger Divisioun). Fir verschidde Management "Dashboards" mat kuerzen Zesummefaassungen vun Aarbechtsberäicher, ass en ähnlecht Thema zimlech oft néideg.

An dësem Artikel wäerte mir d'Ëmsetzung an PostgreSQL vun enger "naiver" Léisung fir sou e Problem kucken, e "schlauere" a ganz komplexen Algorithmus "Loop" an SQL mat engem Ausgangsbedingung vun de fonnten Donnéeën, wat nëtzlech ka sinn fir allgemeng Entwécklung a fir aner ähnlech Fäll ze benotzen.
Loosst eis en Testdatenset aus huelen . Fir ze verhënneren datt déi ugewisen records vun Zäit zu Zäit "sprangen" wann déi zortéiert Wäerter zesummekommen, erweidert den Thema Index andeems Dir e primäre Schlëssel bäidréit. Zur selwechter Zäit gëtt dëst direkt Eenzegaartegkeet a garantéiert eis datt d'Sortéierungsuerdnung eendeiteg ass:
CREATE INDEX ON task(owner_id, task_date, id);
-- а старый - удалим
DROP INDEX task_owner_id_task_date_idx;Wéi et héieren ass, sou ass et geschriwwen
Als éischt, loosst eis déi einfachst Versioun vun der Ufro skizzéieren, d'Identitéite vun den Interpreten weiderginn :
SELECT
*
FROM
task
WHERE
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
ORDER BY
task_date, id
LIMIT 20; 
E bësse traureg - mir bestallt nëmmen 20 records, mee Index Scan et eis zréck 960 Linnen, déi dann och missen zortéiert ginn... Probéieren manner ze liesen.
unnest + ARRAY
Déi éischt Iwwerleeung déi eis hëlleft ass wa mir brauchen nëmmen 20 zortéiert records, dann just liesen net méi wéi 20 an der selwechter Uerdnung fir all zortéiert Schlëssel. Gutt, gëeegent Index (owner_id, task_date, id) mir hunn.
Loosst eis deeselwechte Mechanismus benotze fir ze extrahieren an "a Spalten ze verbreeden" integral Dësch Rekord, wéi an . Mir kënnen och ausklappen an eng Array benotze mat der Funktioun ARRAY():
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 -- ограничиваем тут...
)) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; -- ... и тут - тоже 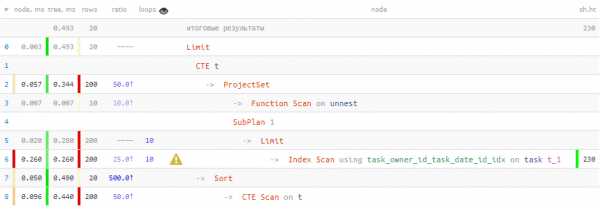
Oh, scho vill besser! 40% méi séier a 4.5 Mol manner Daten Ech hu missen et liesen.
Materialiséierung vun Dësch records via CTELoosst mech op d'Tatsaach opmierksam maachen, datt an e puer Fäll E Versuch direkt mat de Felder vun engem Rekord ze schaffen nodeems se an enger Ënnerquery gesicht goufen, ouni et an engem CTE ze "wrapelen", kann zu "multiplizéieren" InitPlan proportional zu der Zuel vun deene selwechte Felder:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1)
Buffers: shared hit=16
InitPlan 1 (returns $0)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 2 (returns $1)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 3 (returns $2)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4"
InitPlan 4 (returns $3)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
Dee selwechte Rekord gouf 4 Mol "opgekuckt" ... Bis PostgreSQL 11 geschitt dëst Verhalen regelméisseg, an d'Léisung ass et an engem CTE ze "wéckelen", wat eng absolut Limit fir den Optimizer an dëse Versiounen ass.
Rekursive Akkumulator
An der viregter Versioun, am Ganzen liesen mir 200 Linnen fir d'Wuel vun der néideg 20. Net 960, mä nach manner - ass et méiglech?
Loosst eis probéieren d'Wëssen ze benotzen déi mir brauchen am Ganzen 20 records. Dat ass, mir wäerten d'Donnéeën liesen nëmmen bis mir de Betrag erreechen dee mir brauchen.
Schrëtt 1: Start Lëscht
Natierlech soll eis "Zil" Lëscht vun 20 records mat den "éischten" records fir ee vun eise owner_id Schlësselen ufänken. Dofir wäerte mir als éischt esou fannen "ganz éischt" fir jiddereng vun de Schlësselen a füügt et op d'Lëscht, sortéiert se an der Uerdnung déi mir wëllen - (task_date, id).
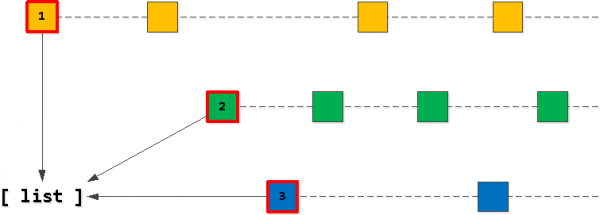
Schrëtt 2: Fannt déi "nächst" Entréen
Elo wa mir den éischten Entrée vun eiser Lëscht huelen an ufänken "Schrëtt" weider laanscht den Index de Besëtzer_id Schlëssel erhaalen, da sinn all déi fonnt records genee déi nächst an der resultéierender Auswiel. Natierlech, nëmmen bis mer den Hënneschten Schlëssel iwwerschreiden zweet Entrée an der Lëscht.
Wann et sech erausstellt, datt mer den zweete Rekord "geklomm" hunn, dann déi lescht gelies Entrée soll op d'Lëscht bäigefüügt ginn amplaz vum éischten (mat der selwechter Besëtzer_id), no deem mir d'Lëscht nees sortéieren.
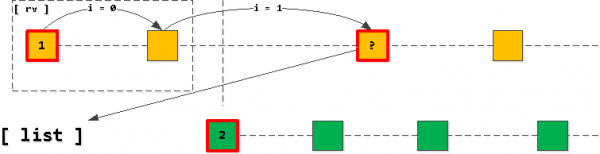
Dat ass, mir kréien ëmmer datt d'Lëscht net méi wéi eng Entrée fir all Schlëssel huet (wann d'Entréen auslafen a mir net "kreuzen", da verschwënnt déi éischt Entrée vun der Lëscht einfach an näischt gëtt derbäigesat ), a si ëmmer sortéiert an opsteigend Uerdnung vum Applikatiounsschlëssel (task_date, id).
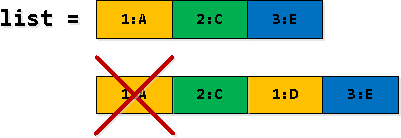
Schrëtt 3: Filter an "erweideren" records
An e puer vun de Reihen vun eiser rekursiver Auswiel, puer records rv ginn duplizéiert - als éischt fanne mir wéi "d'Grenz vun der 2. Entrée vun der Lëscht iwwerschreiden", an ersetzen se dann als 1. vun der Lëscht. Also déi éischt Optriede muss gefiltert ginn.
Déi gefaart lescht Ufro
WITH RECURSIVE T AS (
-- #1 : заносим в список "первые" записи по каждому из ключей набора
WITH wrap AS ( -- "материализуем" record'ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list -- сортируем список в нужном порядке
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
-- #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го
SELECT
CASE
-- если ничего не найдено для ключа 1-й записи
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] -- убираем ее из списка
-- если мы НЕ пересекли прикладной ключ 2-й записи
WHEN X.not_cross THEN
T.list -- просто протягиваем тот же список без модификаций
-- если в списке уже нет 2-й записи
WHEN T.list[2] IS NULL THEN
-- просто возвращаем пустой список
'{}'
-- пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}')
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( -- "материализуем" record
SELECT
CASE
-- если все-таки "перешагнули" через 2-ю запись
WHEN NOT T.not_cross
-- то нужная запись - первая из спписка
THEN T.list[1]
ELSE ( -- если не пересекли, то ключ остался как в предыдущей записи - отталкиваемся от нее
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
-- если 2-й записи уже нет в списке, но мы хоть что-то нашли
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE -- ничего не нашли или "перешагнули"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND -- ограничиваем тут количество
T.list IS DISTINCT FROM '{}' -- или пока список не кончился
)
-- #3 : "разворачиваем" записи - порядок гарантирован по построению
SELECT
(rv).*
FROM
T
WHERE
not_cross; -- берем только "непересекающие" записи 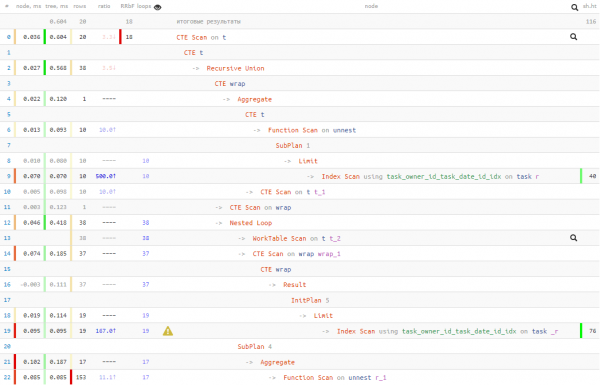
Sou, mir gehandelt 50% vun Daten liesen fir 20% vun Ausféierung Zäit. Dat ass, wann Dir Grënn hutt ze gleewen datt d'Liesen laang daueren kann (zum Beispill sinn d'Donnéeën dacks net am Cache, an Dir musst op d'Disk goen), da kënnt Dir op dës Manéier manner op d'Liesen hänken .
Op jidde Fall ass d'Ausféierungszäit besser erausgestallt wéi an der "naiver" éischt Optioun. Awer wéi eng vun dësen 3 Optiounen ze benotzen ass un Iech.
Source: will.com
