


Jei administruojate virtualią infrastruktūrą, pagrįstą „VMware vSphere“ (ar bet kokia kita technologija), tikriausiai dažnai girdite vartotojų skundus: „Virtuali mašina lėta! Šioje straipsnių serijoje analizuosiu našumo rodiklius ir pasakysiu, kas ir kodėl sulėtėja ir kaip užtikrinti, kad nesulėtėtų.
Apsvarstysiu šiuos virtualios mašinos veikimo aspektus:
- CPU,
- RAM
- DISKAS,
- Tinklas.
Pradėsiu nuo procesoriaus.
Norėdami analizuoti našumą, mums reikės:
- „vCenter“ našumo skaitikliai – našumo skaitikliai, kurių grafikus galima peržiūrėti per vSphere Client. Informacija apie šiuos skaitiklius pasiekiama bet kurioje kliento versijoje („storas“ klientas C#, žiniatinklio klientas „Flex“ ir žiniatinklio klientas HTML5). Šiuose straipsniuose naudosime ekrano kopijas iš C# kliento, tik todėl, kad jos atrodo geriau miniatiūrinės :)
- ESXTOP – programa, kuri veikia iš ESXi komandinės eilutės. Su jo pagalba galite gauti našumo skaitiklių reikšmes realiuoju laiku arba įkelti jas tam tikram laikotarpiui į .csv failą tolesnei analizei. Toliau papasakosiu daugiau apie šį įrankį ir pateiksiu keletą naudingų nuorodų į dokumentus ir straipsnius šia tema.
Teorijos tiek
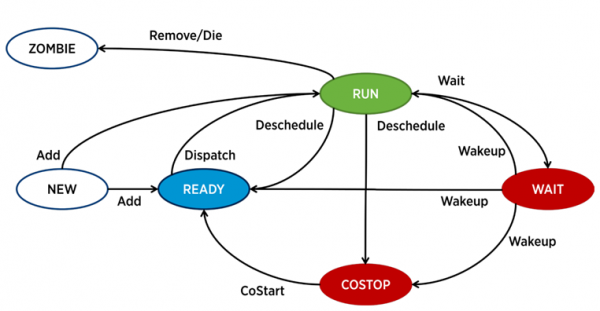
ESXi už kiekvieno vCPU (virtualios mašinos branduolio) veikimą atsakingas atskiras procesas – pasaulis pagal VMware terminologiją. Taip pat yra paslaugų procesų, tačiau VM veikimo analizės požiūriu jie yra mažiau įdomūs.
ESXi procesas gali būti vienoje iš keturių būsenų:
- paleisti – procesas atlieka tam tikrą naudingą darbą.
- Laukti – procesas nevykdo jokio darbo (neaktyvus) arba laukia įvesties/išvesties.
- Costop – sąlyga, kuri atsiranda kelių branduolių virtualiose mašinose. Taip nutinka, kai hipervizoriaus procesoriaus planuoklis (ESXi procesoriaus planuoklis) negali suplanuoti visų aktyvių virtualiosios mašinos branduolių vienu metu vykdymo fizinio serverio branduoliuose. Fiziniame pasaulyje visi procesoriaus branduoliai veikia lygiagrečiai, svečių OS VM viduje tikisi panašaus elgesio, todėl hipervizorius turi sulėtinti VM branduolius, kurie turi galimybę greičiau užbaigti savo laikrodžio ciklą. Šiuolaikinėse ESXi versijose procesoriaus planuoklis naudoja mechanizmą, vadinamą atpalaiduotu bendru planavimu: hipervizorius atsižvelgia į atotrūkį tarp „greičiausio“ ir „lėčiausio“ virtualios mašinos branduolio (kreiptas). Jei tarpas viršija tam tikrą slenkstį, greitoji šerdis pereina į „costop“ būseną. Jei VM branduoliai praleidžia daug laiko šioje būsenoje, tai gali sukelti našumo problemų.
- paruoštas – procesas pereina į šią būseną, kai hipervizorius negali skirti išteklių jo vykdymui. Didelės parengties vertės gali sukelti VM veikimo problemų.
Pagrindiniai virtualios mašinos procesoriaus našumo skaitikliai
Procesoriaus naudojimas, %. Rodo procesoriaus naudojimo procentą tam tikru laikotarpiu.
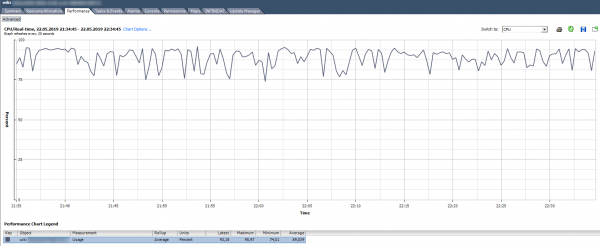
Kaip analizuoti? Jei VM nuolat naudoja 90% procesoriaus arba yra iki 100%, tada turime problemų. Problemos gali būti išreikštos ne tik „lėtu“ programos veikimu VM viduje, bet ir VM neprieinamumu tinkle. Jei stebėjimo sistema rodo, kad VM periodiškai nukrenta, atkreipkite dėmesį į procesoriaus naudojimo diagramos smailes.
Yra standartinis pavojaus signalas, rodantis virtualios mašinos procesoriaus apkrovą:

Ką daryti? Jei VM procesoriaus naudojimas nuolat kyla per stogą, galite galvoti apie vCPU skaičiaus padidinimą (deja, tai ne visada padeda) arba perkelti VM į serverį su galingesniais procesoriais.
CPU naudojimas MHz
Diagramose „vCenter Usage“ procentais galite matyti tik visą virtualią mašiną; atskirų branduolių grafikų nėra (esxtop programoje branduoliams yra % reikšmės). Kiekvienam branduoliui galite pamatyti naudojimą MHz.
Kaip analizuoti? Taip atsitinka, kad programa nėra optimizuota kelių branduolių architektūrai: ji 100% naudoja tik vieną branduolį, o likusi dalis yra neveikianti be apkrovos. Pavyzdžiui, naudojant numatytuosius atsarginės kopijos nustatymus, MS SQL pradeda procesą tik viename branduolyje. Dėl to atsarginis kopijavimas sulėtėja ne dėl lėto diskų greičio (tuo iš pradžių skundėsi vartotojas), o dėl to, kad procesorius nesusidoroja. Problema buvo išspręsta pakeitus parametrus: atsarginė kopija pradėjo veikti lygiagrečiai keliuose failuose (atitinkamai keliuose procesuose).
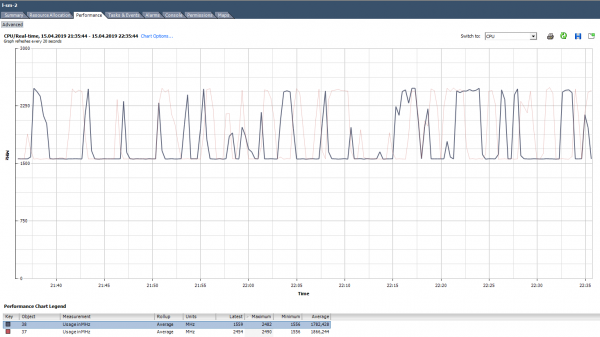
Netolygios šerdies apkrovos pavyzdys.
Taip pat yra situacija (kaip aukščiau esančiame grafike), kai šerdys apkraunamos netolygiai ir kai kurios jų turi 100% smailes. Kaip ir įkeliant tik vieną branduolį, procesoriaus naudojimo signalas neveiks (jis taikomas visai VM), tačiau bus našumo problemų.
Ką daryti? Jei programinė įranga virtualioje mašinoje branduolius apkrauna netolygiai (naudoja tik vieną branduolį arba dalį branduolių), nėra prasmės didinti jų skaičių. Tokiu atveju VM geriau perkelti į serverį su galingesniais procesoriais.
Taip pat galite pabandyti patikrinti energijos suvartojimo nustatymus serverio BIOS. Daugelis administratorių įjungia didelio našumo režimą BIOS ir taip išjungia C būsenų ir P būsenų energijos taupymo technologijas. Šiuolaikiniai Intel procesoriai naudoja Turbo Boost technologiją, kuri padidina atskirų procesoriaus branduolių dažnį kitų branduolių sąskaita. Bet tai veikia tik tada, kai įjungtos energiją taupančios technologijos. Jei juos išjungsime, procesorius negalės sumažinti neapkrautų branduolių energijos suvartojimo.
„VMware“ rekomenduoja serveriuose neišjungti energijos taupymo technologijų, o pasirinkti tokius režimus, kurie kiek įmanoma palieka energijos valdymą hipervizoriui. Tokiu atveju hipervizoriaus energijos suvartojimo nustatymuose turite pasirinkti High Performance.
Jei jūsų infrastruktūroje yra atskirų VM (arba VM branduolių), kuriems reikalingas didesnis procesoriaus dažnis, tinkamai sureguliavus energijos suvartojimą galima žymiai pagerinti jų veikimą.
CPU paruoštas
Jei VM branduolys (vCPU) yra parengties būsenoje, jis neatlieka naudingo darbo. Ši sąlyga atsiranda, kai hipervizorius neranda laisvo fizinio branduolio, kuriam būtų galima priskirti virtualios mašinos vCPU procesą.
Kaip analizuoti? Paprastai, jei virtualios mašinos branduoliai yra parengties būsenoje daugiau nei 10 % laiko, pastebėsite našumo problemų. Paprasčiau tariant, daugiau nei 10 % laiko VM laukia, kol atsiras fiziniai ištekliai.
„vCenter“ galite peržiūrėti 2 skaitiklius, susijusius su CPU parengtimi:
- pasirengimas,
- Parengta.
Abiejų skaitiklių reikšmes galima peržiūrėti tiek visam VM, tiek atskiriems branduoliams.
Pasirengimas rodo reikšmę iškart procentais, bet tik realiuoju laiku (paskutinės valandos duomenys, matavimo intervalas 20 sekundžių). Geriau naudoti šį skaitiklį tik ieškant problemų „karšta ant kulnų“.
Paruoštas skaitiklio vertes taip pat galima žiūrėti iš istorinės perspektyvos. Tai naudinga nustatant modelius ir giliau analizuojant problemą. Pavyzdžiui, jei virtualioje mašinoje tam tikru metu pradeda kilti našumo problemų, galite palyginti CPU Ready reikšmės intervalus su visa serverio, kuriame veikia ši VM, apkrova ir imtis priemonių apkrovai sumažinti (jei DRS nepavyksta).
Paruošta, skirtingai nei parengtis, rodoma ne procentais, o milisekundėmis. Tai yra Sumation tipo skaitiklis, ty parodo, kiek laiko matavimo laikotarpiu VM šerdis buvo parengties būsenoje. Šią vertę galite konvertuoti į procentą naudodami paprastą formulę:
(CPU parengties suminė vertė / (diagramos numatytasis atnaujinimo intervalas sekundėmis * 1000)) * 100 = procesoriaus parengtis %
Pavyzdžiui, toliau pateiktoje diagramoje esančios VM visos virtualios mašinos didžiausia parengties vertė bus tokia:

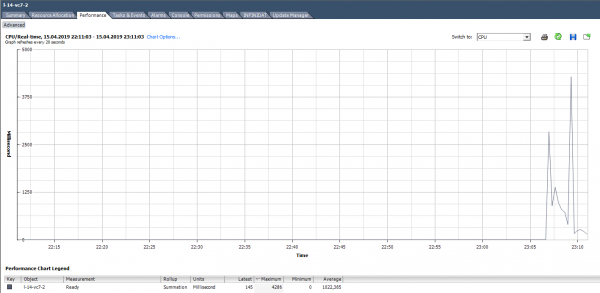
Skaičiuodami pasirengimo procentą, turėtumėte atkreipti dėmesį į du dalykus:
- Parengties vertė visai VM yra Ready per branduolius suma.
- Matavimo intervalas. Realiuoju laiku tai yra 20 sekundžių, o, pavyzdžiui, dienos diagramose - 300 sekundžių.
Aktyviai šalinant triktis šiuos paprastus dalykus galima lengvai praleisti, o brangų laiką galima sugaišti sprendžiant neegzistuojančias problemas.
Remdamiesi toliau pateiktos diagramos duomenimis, apskaičiuokime Ready. (324474/(20*1000))*100 = 1622 % visai VM. Jei pažvelgsite į branduolius, tai nėra taip baisu: 1622 m/64 = 25% vienam branduoliui. Šiuo atveju laimikį pastebėti gana lengva: Ready vertė yra nereali. Bet jei mes kalbame apie 10–20% visai VM su keliais branduoliais, tada kiekvienos šerdies vertė gali būti normaliame diapazone.
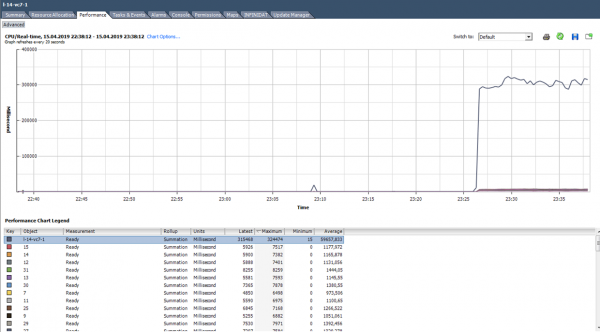
Ką daryti? Didelė Ready reikšmė rodo, kad serveris neturi pakankamai procesoriaus resursų normaliam virtualių mašinų veikimui. Esant tokiai situacijai, belieka sumažinti procesoriaus perteklinį prenumeratą (vCPU:pCPU). Akivaizdu, kad tai galima pasiekti sumažinus esamų VM parametrus arba perkeliant dalį VM į kitus serverius.
Bendras sustojimas
Kaip analizuoti? Šis skaitiklis taip pat yra Sumation tipo ir konvertuojamas į procentus taip pat, kaip ir Ready:
(CPU bendro sustabdymo sumavimo reikšmė / (diagramos numatytasis atnaujinimo intervalas sekundėmis * 1000)) * 100 = procesoriaus bendro sustabdymo %
Čia taip pat reikia atkreipti dėmesį į VM branduolių skaičių ir matavimo intervalą.
Costopo būsenoje branduolys neatlieka naudingo darbo. Teisingai pasirinkus VM dydį ir įprastą serverio apkrovą, bendro sustabdymo skaitiklis turėtų būti artimas nuliui.
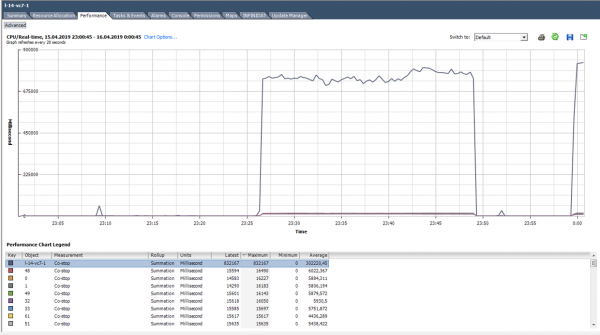
Šiuo atveju apkrova akivaizdžiai nenormali :)
Ką daryti? Jei viename hipervizoriuje veikia kelios VM su dideliu branduolių skaičiumi ir procesoriaus prenumerata yra per didelė, gali padidėti bendro sustabdymo skaitiklis, o tai sukels problemų dėl šių VM veikimo.
Be to, bendras sustabdymas padidės, jei aktyvūs vienos VM branduoliai naudos gijas viename fiziniame serverio branduolyje su įjungtu hipertreading. Tokia situacija gali kilti, pavyzdžiui, jei VM turi daugiau branduolių nei fiziškai pasiekiama serveryje, kuriame ji veikia, arba jei VM įgalintas nustatymas „preferHT“. Galite perskaityti apie šį nustatymą .
Norėdami išvengti VM veikimo problemų dėl didelio bendro sustabdymo, pasirinkite VM dydį pagal programinės įrangos, kuri veikia šioje VM, gamintojo rekomendacijas ir fizinio serverio, kuriame veikia VM, galimybes.
Nepridėkite branduolių rezervo; tai gali sukelti našumo problemų ne tik pačiai VM, bet ir jos kaimynams serveryje.
Kita naudinga procesoriaus metrika
paleisti – kiek laiko (ms) matavimo laikotarpiu vCPU buvo RUN būsenoje, tai yra iš tikrųjų atliko naudingą darbą.
Idle – kiek laiko (ms) matavimo laikotarpiu vCPU buvo neaktyvus. Didelės tuščiosios eigos vertės nėra problema, vCPU tiesiog neturėjo „nieko veikti“.
Laukti – kiek laiko (ms) matavimo laikotarpiu vCPU buvo laukimo būsenoje. Kadangi IDLE yra įtrauktas į šį skaitiklį, didelės laukimo reikšmės taip pat nerodo problemos. Bet jei Wait IDLE yra žemas, kai Wait yra didelis, tai reiškia, kad VM laukė, kol bus baigtos įvesties / išvesties operacijos, o tai savo ruožtu gali reikšti kietojo disko ar bet kurių virtualių VM įrenginių veikimo problemą.
Maksimalus apribojimas – kiek laiko (ms) matavimo laikotarpiu vCPU buvo parengties būsenoje dėl nustatyto resurso limito. Jei našumas yra nepaaiškinamai mažas, naudinga patikrinti šio skaitiklio reikšmę ir procesoriaus limitą VM nustatymuose. VM iš tiesų gali turėti apribojimų, kurių jūs nežinote. Pavyzdžiui, tai atsitinka, kai VM buvo klonuotas iš šablono, kuriame buvo nustatytas procesoriaus limitas.
Pakeiskite laukti – kiek laiko matavimo laikotarpiu vCPU laukė operacijos su VMkernel Swap. Jei šio skaitiklio reikšmės viršija nulį, tada VM tikrai turi našumo problemų. Daugiau apie SWAP kalbėsime straipsnyje apie RAM skaitiklius.
ESXTOP
Jei „vCenter“ našumo skaitikliai tinka istoriniams duomenims analizuoti, operatyvinę problemos analizę geriau atlikti ESXTOP. Čia visos vertės pateikiamos paruošta forma (nereikia nieko versti), o minimalus matavimo laikotarpis yra 2 sekundės.
CPU ESXTOP ekranas iškviečiamas klavišu "c" ir atrodo taip:

Patogumui galite palikti tik virtualios mašinos procesus paspausdami Shift-V.
Norėdami peržiūrėti atskirų VM branduolių metriką, paspauskite „e“ ir įveskite dominančios VM GID (30919 toliau esančioje ekrano kopijoje):
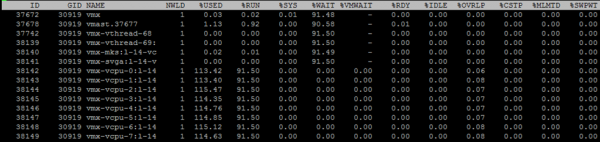
Leiskite trumpai peržvelgti stulpelius, kurie pateikiami pagal numatytuosius nustatymus. Papildomų stulpelių galima pridėti paspaudus „f“.
NWLD (pasaulių skaičius) – procesų skaičius grupėje. Norėdami išplėsti grupę ir peržiūrėti kiekvieno proceso metriką (pavyzdžiui, kiekvieno branduolio kelių branduolių VM), paspauskite „e“. Jei grupėje yra daugiau nei vienas procesas, tada grupės metrikos reikšmės yra lygios atskirų procesų metrikų sumai.
% Naudota – kiek serverio procesoriaus ciklų naudoja procesas arba procesų grupė.
%RUN – kiek laiko matavimo laikotarpiu procesas buvo RUN būsenoje, t.y. atliko naudingą darbą. Jis skiriasi nuo %USED tuo, kad neatsižvelgia į hipergiją, dažnio mastelį ir laiką, praleistą atliekant sistemos užduotis (%SYS).
%SYS – laikas, praleistas atliekant sistemos užduotis, pavyzdžiui: pertraukimų apdorojimas, įvestis/išvestis, tinklo veikimas ir tt Vertė gali būti didelė, jei VM turi didelę įvesties/išvesties.
%OVRLP – kiek laiko fizinis branduolys, kuriame veikia VM procesas, praleido kitų procesų užduotims atlikti.
Šios metrikos viena su kita yra susijusios taip:
%USED = %RUN + %SYS – %OVRLP.
Paprastai % Naudota metrika yra informatyvesnė.
%LAUKTI – kiek laiko matavimo laikotarpiu procesas buvo laukimo būsenoje. Įjungia IDLE.
%IDLE – kiek laiko matavimo laikotarpiu procesas buvo IŠLEIDIMO būsenoje.
%SWPWT – kiek laiko matavimo laikotarpiu vCPU laukė operacijos su VMkernel Swap.
%VMWAIT – kiek laiko matavimo laikotarpiu vCPU laukė įvykio (dažniausiai I/O). „vCenter“ nėra panašaus skaitiklio. Didelės reikšmės rodo VM įvesties/išvesties problemas.
%WAIT = %VMWAIT + %IDLE + %SWPWT.
Jei VM nenaudoja VMkernel Swap, tada analizuojant našumo problemas patartina žiūrėti į %VMWAIT, kadangi ši metrika neatsižvelgia į laiką, kai VM nieko nedarė (%IDLE).
%RDY – kiek laiko matavimo laikotarpiu procesas buvo parengties būsenoje.
%CSTP – kiek laiko matavimo laikotarpiu procesas buvo „cocoop“ būsenoje.
%MLMTD – kiek laiko matavimo laikotarpiu vCPU buvo parengties būsenoje dėl nustatyto resurso limito.
%WAIT + %RDY + %CSTP + %RUN = 100% – VM branduolys visada yra vienoje iš šių keturių būsenų.
CPU hipervizoriuje
„vCenter“ taip pat turi hipervizoriaus procesoriaus našumo skaitiklius, tačiau jie nėra nieko įdomūs – tai tiesiog visų serveryje esančių VM skaitiklių suma.
Patogiausias būdas peržiūrėti procesoriaus būseną serveryje yra skirtuke Suvestinė:

Serveriui, taip pat virtualiai mašinai, yra standartinis aliarmas:
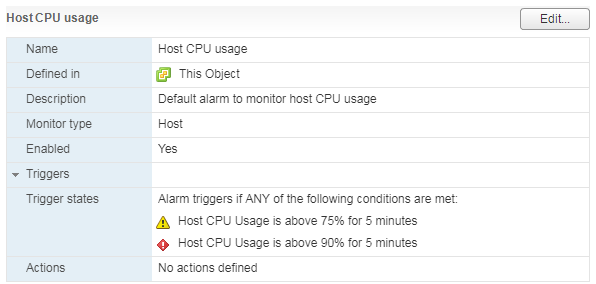
Kai serverio procesoriaus apkrova yra didelė, jame veikiančios VM pradeda patirti našumo problemų.
ESXTOP serverio procesoriaus apkrovos duomenys pateikiami ekrano viršuje. Be standartinės procesoriaus apkrovos, kuri nėra labai informatyvi hipervizoriams, yra dar trys metrikos:
PAGRINDINĖ NAUDOJIMAS (%) – įkeliamas fizinis serverio branduolys. Šis skaitiklis rodo, kiek laiko šerdis atliko darbą matavimo laikotarpiu.
PCPU UTIL (%) – jei įjungtas hipersriegis, tada viename fiziniame šerdyje yra dvi gijos (PCPU). Ši metrika rodo, kiek laiko užtruko kiekviena gija, kad užbaigtų darbą.
Naudotas PCPU (%) – toks pat kaip PCPU UTIL (%), tačiau atsižvelgiama į dažnio mastelį (arba sumažinant šerdies dažnį energijos taupymo tikslais, arba padidinant pagrindinį dažnį dėl Turbo Boost technologijos) ir hipersriegius.
PCPU_USED% = PCPU_UTIL% * efektyvus šerdies dažnis / nominalus šerdies dažnis.
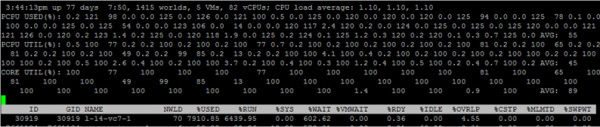
Šioje ekrano kopijoje kai kuriems branduoliams dėl Turbo Boost USED vertė yra didesnė nei 100%, nes šerdies dažnis yra didesnis nei nominalus.
Keletas žodžių apie tai, kaip atsižvelgiama į hipergiją. Jei procesai 100% laiko vykdomi abiejose fizinio serverio šerdies gijose, o branduolys veikia nominaliu dažniu, tada:
- CORE UTIL branduoliui bus 100 proc.
- PCPU UTIL abiem gijomis bus 100 proc.
- PCPU, Naudojamas abiem gijomis, bus 50%.
Jei matavimo laikotarpiu abi gijos neveikė 100% laiko, tai tais laikotarpiais, kai sriegiai dirbo lygiagrečiai, branduoliams NAUDOTAS PCPU dalinamas per pusę.
ESXTOP taip pat turi ekraną su serverio procesoriaus energijos suvartojimo parametrais. Čia galite pamatyti, ar serveris naudoja energiją taupančias technologijas: C būsenos ir P būsenos. Skambinama mygtuku "p":

Dažnos procesoriaus našumo problemos
Galiausiai apžvelgsiu tipines VM procesoriaus veikimo problemų priežastis ir pateiksiu trumpus patarimus, kaip jas išspręsti:
Pagrindinio laikrodžio greičio nepakanka. Jei neįmanoma atnaujinti VM į galingesnius branduolius, galite pabandyti pakeisti maitinimo parametrus, kad Turbo Boost veiktų efektyviau.
Neteisingas VM dydis (per daug / mažai branduolių). Jei įdiegsite keletą branduolių, VM bus didelė procesoriaus apkrova. Jei yra daug, sustokite aukštai.
Didelis CPU prenumerata serveryje. Jei VM aukštas parengties lygis, sumažinkite procesoriaus perteklinį prenumeratą.
Neteisinga NUMA topologija didelėse VM. NUMA topologija, kurią mato VM (vNUMA), turi atitikti serverio NUMA topologiją (pNUMA). Diagnostika ir galimi šios problemos sprendimai surašyti, pavyzdžiui, knygoje . Jei nenorite gilintis ir neturite VM įdiegtos OS licencijavimo apribojimų, sukurkite daug virtualių VM lizdų, po vieną branduolį. Daug neprarasi :)
Tai viskas apie centrinį procesorių. Užduoti klausimus. Kitoje dalyje kalbėsiu apie RAM.
Naudingos nuorodos
Šaltinis: www.habr.com
