


2017 m. laimėjome konkursą plėtoti Alfa-Bank investicinio verslo sandorinį branduolį ir pradėjome darbą (HighLoad++ 2018 m. su ataskaita apie investicinio verslo branduolį Vladimiras Drynkinas, „Alfa Bank“ investicinio verslo pagrindinio sandorio vadovas). Ši sistema turėjo apibendrinti skirtingų šaltinių operacijų duomenis įvairiais formatais, suvesti duomenis į vieningą formą, saugoti ir suteikti prieigą prie jų.
Kūrimo proceso metu sistema vystėsi ir įgijo funkcionalumą, o tam tikru momentu supratome, kad kristalizuojame kažką daugiau nei vien taikomąją programinę įrangą, sukurtą griežtai apibrėžtai užduočių grupei: mums pavyko. sistema, skirta kurti paskirstytas programas su nuolatine saugykla. Mūsų įgyta patirtis sudarė naujo produkto pagrindą - (TDG).
Noriu pakalbėti apie TDG architektūrą ir sprendimus, prie kurių priėjome kūrimo proceso metu, supažindinti su pagrindiniais funkcionalumais ir parodyti, kaip mūsų produktas gali tapti pagrindu kuriant kompleksinius sprendimus.
Architektūriškai sistemą suskirstėme į atskiras vaidmenis, kurių kiekvienas yra atsakingas už tam tikrų problemų sprendimą. Vienas veikiantis programos egzempliorius įgyvendina vieną ar daugiau vaidmenų tipų. Klasteryje gali būti keli to paties tipo vaidmenys:
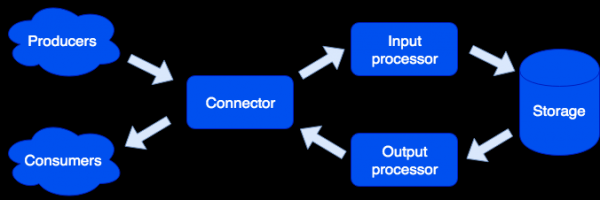
jungtis
Jungtis yra atsakinga už bendravimą su išoriniu pasauliu; jos užduotis yra priimti užklausą, ją išanalizuoti ir, jei tai pavyksta, nusiųsti duomenis apdoroti įvesties procesoriui. Palaikome HTTP, SOAP, Kafka, FIX formatus. Architektūra leidžia tiesiog pridėti naujų formatų palaikymą, o IBM MQ palaikymas netrukus pasirodys. Jei užklausos analizė nepavyko, jungtis pateiks klaidą; kitu atveju jis atsakys, kad užklausa buvo sėkmingai apdorota, net jei tolesnio apdorojimo metu įvyko klaida. Tai buvo padaryta specialiai norint dirbti su sistemomis, kurios nemoka pakartoti užklausų arba, priešingai, daro tai per daug atkakliai. Kad duomenys neprarastų, naudojama taisymo eilė: objektas pirmiausia patenka į ją ir tik sėkmingai apdorojus iš jos pašalinamas. Administratorius gali gauti įspėjimus apie taisymo eilėje likusius objektus, o pašalinęs programinės įrangos klaidą ar aparatinės įrangos gedimą bandyti dar kartą.
Įvesties procesorius
Įvesties procesorius klasifikuoja gautus duomenis pagal būdingus požymius ir iškviečia atitinkamus procesorius. Valdikliai yra Lua kodas, kuris veikia smėlio dėžėje, todėl negali turėti įtakos sistemos veikimui. Šiame etape duomenys gali būti sumažinti iki reikiamos formos ir, jei reikia, gali būti paleistas savavališkas skaičius užduočių, kurios gali įgyvendinti reikiamą logiką. Pavyzdžiui, MDM (Master Data Management) gaminyje, sukurtame ant Tarantool Data Grid, pridedant naują vartotoją, kad nesulėtėtų užklausos apdorojimas, auksinio rekordo kūrimą paleidžiame kaip atskirą užduotį. Smėlio dėžė palaiko duomenų nuskaitymo, keitimo ir pridėjimo užklausas, leidžia atlikti tam tikras funkcijas visuose saugyklos tipo vaidmenyse ir rezultato agregavimo (map/reduce).
Tvarkyklės gali būti aprašytos failuose:
sum.lua
local x, y = unpack(...)
return x + yIr tada, paskelbta konfigūracijoje:
functions:
sum: { __file: sum.lua }
Kodėl Lua? Lua kalba yra labai paprasta. Remiantis mūsų patirtimi, po poros valandų po pažinimo žmonės pradeda rašyti kodą, kuris išsprendžia jų problemą. Ir tai ne tik profesionalūs kūrėjai, bet, pavyzdžiui, analitikai. Be to, jit kompiliatoriaus dėka Lua veikia labai greitai.
saugojimas
Saugykloje saugomi nuolatiniai duomenys. Prieš išsaugant duomenys tikrinami pagal duomenų schemą. Norėdami apibūdinti grandinę, naudojame išplėstinį formatą . Pavyzdys:
{
"name": "User",
"type": "record",
"logicalType": "Aggregate",
"fields": [
{ "name": "id", "type": "string"},
{"name": "first_name", "type": "string"},
{"name": "last_name", "type": "string"}
],
"indexes": ["id"]
}Remiantis šiuo aprašymu, DDL (duomenų apibrėžimo kalba) automatiškai generuojama Tarantula DBVS ir duomenų prieigos schema.
Palaikomas asinchroninis duomenų replikavimas (planuojama pridėti sinchroninį).
Išvesties procesorius
Kartais reikia informuoti išorinius vartotojus apie naujų duomenų gavimą, tam yra išvesties procesoriaus vaidmuo. Išsaugojus duomenis, juos galima perduoti atitinkamam tvarkytojui (pavyzdžiui, kad būtų atnešta į vartotojui reikalingą formą) – o tada perduoti į jungtį siuntimui. Čia taip pat naudojama remonto eilė: jei niekas objekto nepriėmė, vėliau administratorius gali bandyti dar kartą.
Mastelio keitimas
Jungties, įvesties procesoriaus ir išvesties procesoriaus vaidmenys yra be būsenos, todėl galime padidinti sistemos mastelį horizontaliai, tiesiog pridedant naujų taikomųjų programų egzempliorių su įjungtu norimu vaidmens tipu. Saugykla naudojama horizontaliam mastelio keitimui organizuoti klasterį naudojant virtualius kibirus. Pridėjus naują serverį, kai kurie segmentai iš senų serverių perkeliami į naują serverį fone; tai vyksta vartotojams skaidriai ir neturi įtakos visos sistemos veikimui.
Duomenų ypatybės
Objektai gali būti labai dideli ir juose gali būti kitų objektų. Duomenų papildymo ir atnaujinimo atomiškumą užtikriname saugodami objektą su visomis priklausomybėmis viename virtualiame kibirėlyje. Tai neleidžia objektui „išsiskleisti“ keliuose fiziniuose serveriuose.
Palaikomas versijų kūrimas: kiekvienas objekto atnaujinimas sukuria naują versiją, o mes visada galime paimti laiko pjūvį ir pamatyti, kaip tada atrodė pasaulis. Duomenims, kuriems nereikia ilgos istorijos, galime apriboti versijų skaičių arba net išsaugoti tik vieną – naujausią – tai yra iš esmės išjungti tam tikro tipo versijų kūrimą. Taip pat galite apriboti istoriją pagal laiką: pavyzdžiui, ištrinti visus tam tikro tipo objektus, senesnius nei 1 metai. Taip pat palaikomas archyvavimas: galime iškrauti senesnius nei nurodyta laiku objektus, atlaisvindami vietos klasteryje.
užduotys
Tarp įdomių funkcijų verta paminėti galimybę paleisti užduotis pagal tvarkaraštį, vartotojo prašymu arba programiškai iš smėlio dėžės:
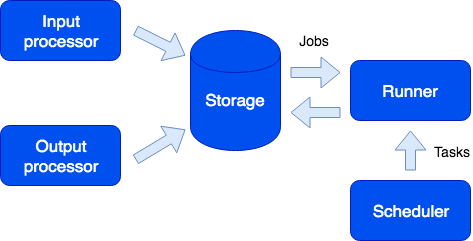
Čia matome kitą vaidmenį – bėgikas. Šis vaidmuo yra be būsenos ir, jei reikia, į klasterį galima įtraukti papildomų programų egzempliorių su šiuo vaidmeniu. Bėgiko pareiga yra atlikti užduotis. Kaip minėta, iš smėlio dėžės galima generuoti naujas užduotis; jie išsaugomi saugykloje esančioje eilėje ir tada vykdomi bėgikoje. Tokio tipo užduotis vadinama Job. Taip pat turime užduočių tipą, vadinamą Užduotis – tai vartotojo nustatytos užduotys, vykdomos pagal tvarkaraštį (naudojant cron sintaksę) arba pagal poreikį. Norėdami paleisti ir stebėti tokias užduotis, turime patogų užduočių tvarkyklę. Kad ši funkcija būtų prieinama, turite įjungti planuotojo vaidmenį; šis vaidmuo turi būseną, todėl jis nesikeičia, o tai nėra būtina; tuo pačiu, kaip ir visi kiti vaidmenys, gali turėti repliką, kuri pradeda veikti, jei meistras staiga atsisako.
kaupiklis
Kitas vaidmuo vadinamas medkirčiu. Jis renka žurnalus iš visų klasterio narių ir suteikia sąsają juos įkelti ir peržiūrėti per žiniatinklio sąsają.
Paslaugos
Verta paminėti, kad sistema leidžia lengvai kurti paslaugas. Konfigūracijos faile galite nurodyti, kurios užklausos siunčiamos į vartotojo parašytą tvarkyklę, kuri veikia smėlio dėžėje. Šioje tvarkyklėje galite, pavyzdžiui, paleisti tam tikrą analitinę užklausą ir grąžinti rezultatą.
Paslauga aprašyta konfigūracijos faile:
services:
sum:
doc: "adds two numbers"
function: sum
return_type: int
args:
x: int
y: int
GraphQL API sugeneruojama automatiškai ir paslauga tampa prieinama skambinti:
query {
sum(x: 1, y: 2)
} Tai paskambins tvarkytojui sumkuris grąžins rezultatą:
3
Užklausų profiliavimas ir metrika
Norėdami suprasti sistemos veikimą ir profiliavimo užklausas, įdiegėme OpenTracing protokolo palaikymą. Sistema gali siųsti informaciją pagal poreikį į šį protokolą palaikančius įrankius, tokius kaip Zipkin, kuris leis suprasti, kaip buvo įvykdyta užklausa:
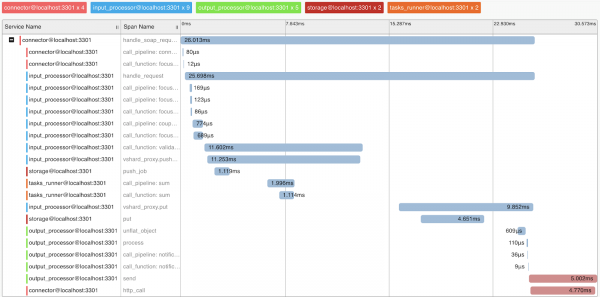
Natūralu, kad sistemoje yra vidinių metrikų, kurias galima rinkti naudojant „Prometheus“ ir vizualizuoti naudojant „Grafana“.
Dislokuoti
Tarantool Data Grid gali būti įdiegtas iš RPM paketų arba archyvo, naudojant paskirstymo arba Ansible įrankį, taip pat palaikoma Kubernetes ().
Verslo logiką (konfigūraciją, tvarkykles) įgyvendinanti programa archyvo pavidalu įkeliama į įdiegtą Tarantool Data Grid klasterį per vartotojo sąsają arba naudojant scenarijų per mūsų pateiktą API.
Programų pavyzdžiai
Kokias programas galima sukurti naudojant Tarantool Data Grid? Tiesą sakant, dauguma verslo užduočių yra kažkaip susijusios su duomenų srauto apdorojimu, saugojimu ir prieiga. Todėl, jei turite didelius duomenų srautus, kuriuos reikia saugiai saugoti ir pasiekti, mūsų produktas gali sutaupyti daug laiko kūrimui ir sutelkti dėmesį į jūsų verslo logiką.
Pavyzdžiui, norime rinkti informaciją apie nekilnojamojo turto rinką, kad, pavyzdžiui, ateityje turėtume informacijos apie geriausius pasiūlymus. Šiuo atveju pabrėšime šias užduotis:
- Robotai, renkantys informaciją iš atvirų šaltinių, bus mūsų duomenų šaltiniai. Šią problemą galite išspręsti naudodami paruoštus sprendimus arba rašydami kodą bet kuria kalba.
- Tada Tarantool Data Grid priims ir išsaugos duomenis. Jei duomenų formatas iš skirtingų šaltinių skiriasi, galite parašyti kodą Lua, kuris konvertuos į vieną formatą. Išankstinio apdorojimo etape taip pat galėsite, pavyzdžiui, filtruoti pasikartojančius pasiūlymus arba papildomai duomenų bazėje atnaujinti informaciją apie rinkoje dirbančius agentus.
- Dabar klasteryje jau turite keičiamo dydžio sprendimą, kurį galima užpildyti duomenimis ir pasirinkti duomenis. Tada galite įdiegti naują funkcionalumą, pavyzdžiui, parašyti paslaugą, kuri pateiks duomenų užklausą ir pateiks naudingiausią pasiūlymą per dieną – tam reikės kelių eilučių konfigūracijos faile ir šiek tiek Lua kodo.
Kas toliau?
Mūsų prioritetas yra palengvinti kūrimo naudojimą . Pavyzdžiui, tai yra IDE, palaikantis profiliavimo ir derinimo tvarkykles, veikiančias smėlio dėžėje.
Taip pat didelį dėmesį skiriame saugos klausimams. Šiuo metu atliekame Rusijos FSTEC sertifikavimą, kad patvirtintume aukštą saugumo lygį ir atitiktume programinės įrangos produktų, naudojamų asmens duomenų informacinėse sistemose ir vyriausybės informacinėse sistemose, sertifikavimo reikalavimus.
Šaltinis: www.habr.com
