


Sveiki, aš esu Sergejus Elancevas, tobulėju „Yandex.Cloud“. Anksčiau vadovavau L7 balansyro kūrimui portalui „Yandex“ – kolegos juokauja, kad kad ir ką bedarysiu, pasirodo, kad tai balansuotojas. Papasakosiu Habr skaitytojams, kaip valdyti apkrovą debesų platformoje, ką laikome idealia priemone šiam tikslui pasiekti ir kaip judame link šio įrankio kūrimo.
Pirmiausia pristatykime keletą terminų:
- VIP (Virtual IP) – balansuotojo IP adresas
- Serveris, backend, egzempliorius – virtuali mašina, kurioje veikia programa
- RIP (Real IP) – serverio IP adresas
- Healthcheck – tikrinama serverio parengtis
- Prieinamumo zona, AZ – izoliuota infrastruktūra duomenų centre
- Regionas – skirtingų AZ sąjunga
Apkrovos balansuotojai išsprendžia tris pagrindines užduotis: atlieka patį balansavimą, pagerina paslaugos atsparumą gedimams ir supaprastina jos mastelį. Gedimų tolerancija užtikrinama naudojant automatinį srauto valdymą: balansuotojas stebi programos būseną ir neįtraukia balansavimo atvejų, kurie nepraeina gyvumo patikrinimo. Mastelio keitimas užtikrinamas tolygiai paskirstant apkrovą tarp egzempliorių, taip pat atnaujinant egzempliorių sąrašą. Jei balansavimas nėra pakankamai vienodas, kai kurios instancijos gaus apkrovą, viršijančią jų pajėgumo ribą, ir paslauga taps mažiau patikima.
Apkrovos balansavimo priemonė dažnai klasifikuojama pagal protokolo sluoksnį iš OSI modelio, kuriame jis veikia. Cloud Balancer veikia TCP lygiu, kuris atitinka ketvirtąjį sluoksnį L4.
Pereikime prie „Cloud Balancer“ architektūros apžvalgos. Palaipsniui didinsime detalumo lygį. Balansavimo komponentus skirstome į tris klases. Konfigūracijos plokštumos klasė yra atsakinga už vartotojo sąveiką ir išsaugo tikslinę sistemos būseną. Valdymo plokštuma saugo dabartinę sistemos būseną ir valdo sistemas iš duomenų plokštumos klasės, kurios yra tiesiogiai atsakingos už srauto iš klientų perdavimą į jūsų egzempliorius.
Duomenų plokštuma
Eismas patenka į brangius įrenginius, vadinamus pasienio maršrutizatoriais. Siekiant padidinti atsparumą gedimams, keli tokie įrenginiai vienu metu veikia viename duomenų centre. Tada srautas nukreipiamas į balansuotojus, kurie per BGP klientams praneša bet kokius IP adresus visiems AZ.
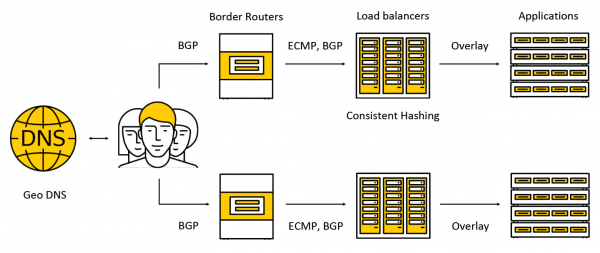
Srautas perduodamas per ECMP – tai maršruto parinkimo strategija, pagal kurią gali būti keli vienodai geri maršrutai į tikslą (mūsų atveju taikinys bus paskirties IP adresas) ir paketai gali būti siunčiami bet kuriuo iš jų. Taip pat palaikome darbą keliose pasiekiamumo zonose pagal tokią schemą: kiekvienoje zonoje skelbiame adresą, srautas eina į artimiausią ir neperžengia jo ribų. Vėliau įraše išsamiau apžvelgsime, kas nutinka eismui.
Konfigūravimo plokštuma
Pagrindinis konfigūravimo plokštumos komponentas yra API, per kurią atliekamos pagrindinės operacijos su balansavimo įrenginiais: egzempliorių kūrimas, ištrynimas, sudėties keitimas, sveikatos patikrinimų rezultatų gavimas ir tt Viena vertus, tai yra REST API, o kita vertus. Kita vertus, mes debesyje labai dažnai naudojame pagrindinį gRPC, todėl REST „verčiame“ į gRPC ir tada naudojame tik gRPC. Bet kokia užklausa sukuria asinchroninių idempotentų užduočių, kurios vykdomos bendrame Yandex.Cloud darbuotojų telkinyje, seriją. Užduotys parašytos taip, kad jas būtų galima bet kada sustabdyti ir paleisti iš naujo. Tai užtikrina mastelį, pakartojamumą ir operacijų registravimą.
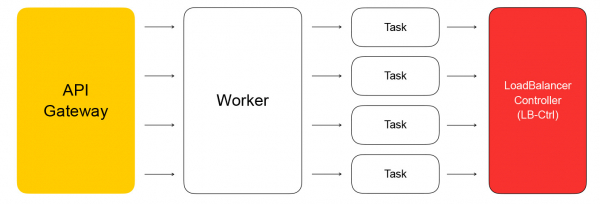
Dėl to API užduotis pateiks užklausą balansavimo paslaugos valdikliui, kuri parašyta Go. Jis gali pridėti ir pašalinti balansavimo priemones, pakeisti užpakalinių programų sudėtį ir nustatymus.
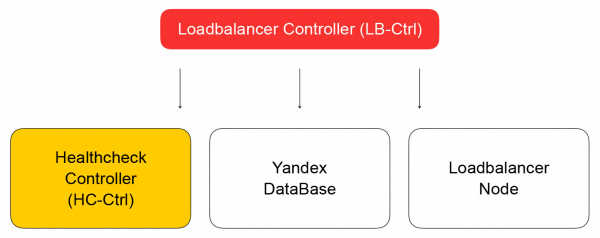
Paslauga saugo savo būseną „Yandex“ duomenų bazėje, paskirstytoje valdomoje duomenų bazėje, kurią netrukus galėsite naudoti. „Yandex.Cloud“, kaip jau mes , galioja šunų maisto koncepcija: jei mes patys naudojamės savo paslaugomis, tai mielai jomis pasinaudos ir mūsų klientai. „Yandex“ duomenų bazė yra tokios koncepcijos įgyvendinimo pavyzdys. Visus savo duomenis saugome YDB, ir mums nereikia galvoti apie duomenų bazės priežiūrą ir mastelį: šios problemos išsprendžiamos už mus, duomenų bazę naudojame kaip paslaugą.
Grįžkime prie balansavimo valdiklio. Jo užduotis yra išsaugoti informaciją apie balansavimo priemonę ir nusiųsti užduotį patikrinti virtualios mašinos parengtį į sveikatos patikrinimo valdiklį.
Sveikatos patikrinimo valdiklis
Jis gauna užklausas pakeisti patikrinimo taisykles, išsaugo jas YDB, paskirsto užduotis tarp sveikatos patikrinimo mazgų ir apibendrina rezultatus, kurie išsaugomi duomenų bazėje ir siunčiami į loadbalancer valdiklį. Jis savo ruožtu siunčia užklausą pakeisti klasterio sudėtį duomenų plokštumoje į apkrovos balansavimo mazgą, kurį aptarsiu toliau.
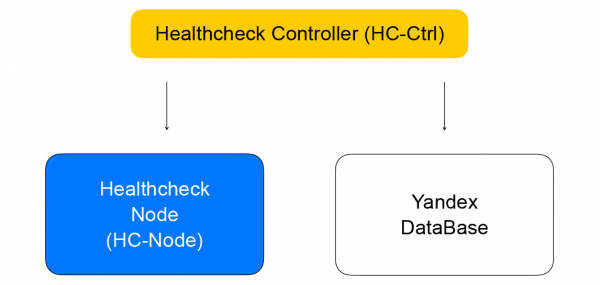
Pakalbėkime daugiau apie sveikatos patikrinimus. Juos galima suskirstyti į kelias klases. Auditai turi skirtingus sėkmės kriterijus. TCP patikrinimai turi sėkmingai užmegzti ryšį per fiksuotą laiką. HTTP patikrinimams reikalingas sėkmingas ryšys ir atsakymas su 200 būsenos kodu.
Taip pat čekiai skiriasi veiksmų klase – jie yra aktyvūs ir pasyvūs. Pasyvūs patikrinimai tiesiog stebi, kas vyksta eisme, nesiimant jokių specialių veiksmų. Tai neveikia labai gerai L4, nes tai priklauso nuo aukštesnio lygio protokolų logikos: L4 nėra informacijos apie tai, kiek laiko užtruko operacija ir ar ryšio užbaigimas buvo geras ar blogas. Norint atlikti aktyvius patikrinimus, balansuotojas turi siųsti užklausas kiekvienam serverio egzemplioriui.
Dauguma apkrovos balansuotojų gyvumo patikras atlieka patys. „Cloud“ nusprendėme atskirti šias sistemos dalis, kad padidintume mastelį. Šis metodas leis mums padidinti balansuotojų skaičių ir išlaikyti sveikatos patikrinimo užklausų skaičių tarnybai. Patikrinimus atlieka atskiri būklės patikrinimo mazgai, kuriuose tikrinimo tikslai yra suskaidomi ir kartojami. Negalite atlikti patikrinimų iš vieno pagrindinio kompiuterio, nes jis gali nepavykti. Tada negausime jo patikrintų atvejų būklės. Atliekame bet kurio egzemplioriaus patikrinimą iš mažiausiai trijų sveikatos patikrinimo mazgų. Patikrinimo tarp mazgų tikslus išskaidome naudodami nuoseklius maišos algoritmus.
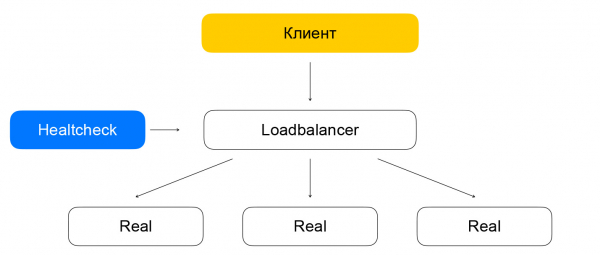
Balansavimo ir sveikatos patikrinimo atskyrimas gali sukelti problemų. Jei sveikatos patikrinimo mazgas pateikia užklausas egzemplioriui, apeidamas balansuotoją (kuris šiuo metu neaptarnauja srauto), tada susidaro keista situacija: atrodo, kad resursas yra gyvas, bet srautas jo nepasieks. Šią problemą sprendžiame taip: garantuojame, kad sveikatos patikrinimo srautą inicijuosime per balansuotojus. Kitaip tariant, paketų su srautu iš klientų ir sveikatos patikrinimų perkėlimo schema skiriasi minimaliai: abiem atvejais paketai pasieks balansuotojus, kurie juos pristatys į tikslinius išteklius.
Skirtumas tas, kad klientai pateikia užklausas VIP, o sveikatos patikrinimai pateikia užklausas kiekvienam atskiram RIP. Čia iškyla įdomi problema: savo vartotojams suteikiame galimybę kurti išteklius pilkuosiuose IP tinkluose. Įsivaizduokime, kad yra du skirtingi debesų savininkai, kurie savo paslaugas paslėpė už balansuotojų. Kiekvienas iš jų turi išteklių 10.0.0.1/24 potinklyje su tais pačiais adresais. Reikia mokėti juos kažkaip atskirti, o čia reikia pasinerti į virtualaus „Yandex.Cloud“ tinklo struktūrą. Geriau sužinoti daugiau informacijos , mums dabar svarbu, kad tinklas būtų daugiasluoksnis ir jame būtų tuneliai, kuriuos galima atskirti pagal potinklio ID.
„Healthcheck“ mazgai susisiekia su balansavimo įrenginiais naudodami vadinamuosius kvazi-IPv6 adresus. Kvaziadresas yra IPv6 adresas su įterptu IPv4 adresu ir vartotojo potinklio ID. Srautas pasiekia balansavimo įrenginį, kuris iš jo išgauna IPv4 išteklių adresą, pakeičia IPv6 į IPv4 ir siunčia paketą į vartotojo tinklą.
Atvirkštinis srautas vyksta taip pat: balansavimo priemonė mato, kad tikslas yra pilkas sveikatos tikrintojų tinklas, ir konvertuoja IPv4 į IPv6.
VPP – duomenų plokštumos širdis
Balansuoklis įdiegtas naudojant Vector Packet Processing (VPP) technologiją, Cisco sistemą, skirtą tinklo srauto paketiniam apdorojimui. Mūsų atveju sistema veikia kartu su vartotojo erdvės tinklo įrenginių valdymo biblioteka - Data Plane Development Kit (DPDK). Tai užtikrina aukštą paketų apdorojimo našumą: branduolyje įvyksta daug mažiau pertraukimų ir nėra kontekstinio perjungimo tarp branduolio erdvės ir vartotojo erdvės.
VPP žengia dar toliau ir iš sistemos išspaudžia dar daugiau našumo, sujungdama paketus į partijas. Našumas didėja dėl agresyvaus šiuolaikinių procesorių talpyklų naudojimo. Naudojamos tiek duomenų talpyklos (paketai apdorojami „vektoriais“, duomenys yra arti vienas kito), ir instrukcijų talpyklos: VPP paketų apdorojimas vyksta pagal grafiką, kurio mazguose yra funkcijos, atliekančios tą pačią užduotį.
Pavyzdžiui, IP paketų apdorojimas VPP vyksta tokia tvarka: iš pradžių paketų antraštės išanalizuojamos analizavimo mazge, o po to siunčiamos į mazgą, kuris pagal maršruto lenteles persiunčia paketus toliau.
Šiek tiek hardcore. VPP autoriai netoleruoja kompromisų naudojant procesoriaus talpyklas, todėl tipiškame paketų vektoriaus apdorojimo kode yra rankinis vektorizavimas: yra apdorojimo ciklas, kuriame apdorojama tokia situacija kaip „eilėje turime keturis paketus“, tada tas pats dviem, tada - vienam. Išankstinio gavimo instrukcijos dažnai naudojamos duomenims įkelti į talpyklas, kad paskesniuose iteracijose būtų pagreitinta prieiga prie jų.
n_left_from = frame->n_vectors;
while (n_left_from > 0)
{
vlib_get_next_frame (vm, node, next_index, to_next, n_left_to_next);
// ...
while (n_left_from >= 4 && n_left_to_next >= 2)
{
// processing multiple packets at once
u32 next0 = SAMPLE_NEXT_INTERFACE_OUTPUT;
u32 next1 = SAMPLE_NEXT_INTERFACE_OUTPUT;
// ...
/* Prefetch next iteration. */
{
vlib_buffer_t *p2, *p3;
p2 = vlib_get_buffer (vm, from[2]);
p3 = vlib_get_buffer (vm, from[3]);
vlib_prefetch_buffer_header (p2, LOAD);
vlib_prefetch_buffer_header (p3, LOAD);
CLIB_PREFETCH (p2->data, CLIB_CACHE_LINE_BYTES, STORE);
CLIB_PREFETCH (p3->data, CLIB_CACHE_LINE_BYTES, STORE);
}
// actually process data
/* verify speculative enqueues, maybe switch current next frame */
vlib_validate_buffer_enqueue_x2 (vm, node, next_index,
to_next, n_left_to_next,
bi0, bi1, next0, next1);
}
while (n_left_from > 0 && n_left_to_next > 0)
{
// processing packets by one
}
// processed batch
vlib_put_next_frame (vm, node, next_index, n_left_to_next);
}Taigi, „Healthchecks“ per IPv6 bendrauja su VPP, o tai paverčia juos IPv4. Tai atlieka grafiko mazgas, kurį vadiname algoritminiu NAT. Atvirkštiniam srautui (ir konvertavimui iš IPv6 į IPv4) yra tas pats algoritminis NAT mazgas.
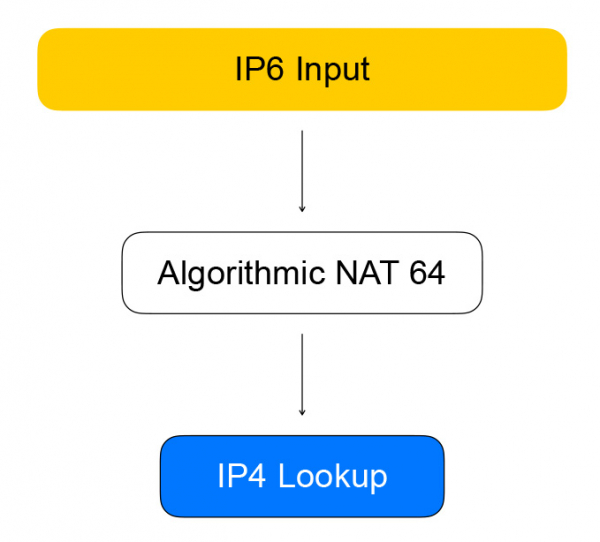
Tiesioginis srautas iš balansavimo klientų eina per grafiko mazgus, kurie patys atlieka balansavimą.
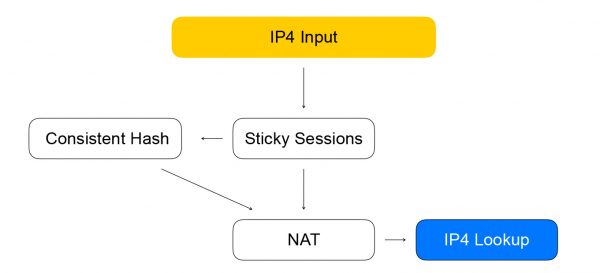
Pirmasis mazgas yra lipnios sesijos. Jame saugoma maiša nustatytoms sesijoms. 5 korteles apima kliento, iš kurio perduodama informacija, adresą ir prievadą, išteklių, galimų priimti srautą, adresą ir prievadus, taip pat tinklo protokolą.
5 kortelių maiša padeda mums atlikti mažiau skaičiavimų tolesniame nuosekliame maišos mazge, taip pat geriau tvarkyti išteklių sąrašo pakeitimus už balansavimo priemonės. Kai paketas, kuriam nėra seanso, patenka į balansavimo įrenginį, jis siunčiamas į nuoseklų maišos mazgą. Čia vyksta balansavimas naudojant nuoseklų maišą: pasirenkame išteklius iš galimų „gyvų“ išteklių sąrašo. Tada paketai siunčiami į NAT mazgą, kuris iš tikrųjų pakeičia paskirties adresą ir perskaičiuoja kontrolines sumas. Kaip matote, vadovaujamės VPP taisyklėmis – like to like, grupuodami panašius skaičiavimus, kad padidintume procesoriaus talpyklų efektyvumą.
Nuoseklus maišas
Kodėl mes jį pasirinkome ir kas tai yra? Pirma, apsvarstykime ankstesnę užduotį - iš sąrašo pasirinktą šaltinį.
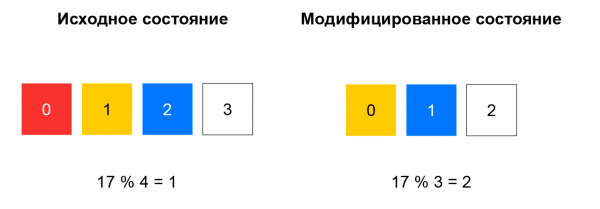
Esant nenuosekliai maišai, apskaičiuojama gaunamo paketo maiša ir iš sąrašo parenkamas išteklius, padalijus šią maišą iš išteklių skaičiaus. Kol sąrašas nesikeičia, ši schema veikia gerai: visada siunčiame paketus su ta pačia 5 kortele į tą patį egzempliorių. Jei, pavyzdžiui, kai kurie ištekliai nustojo reaguoti į sveikatos patikrinimus, didelės maišos dalies pasirinkimas pasikeis. Kliento TCP ryšiai bus nutrūkę: paketas, kuris anksčiau pasiekė egzempliorių A, gali pradėti pasiekti egzempliorių B, kuris nėra susipažinęs su šio paketo seansu.
Nuoseklus maišas išsprendžia aprašytą problemą. Lengviausias būdas paaiškinti šią sąvoką yra toks: įsivaizduokite, kad turite žiedą, kuriam paskirstote išteklius maišos būdu (pavyzdžiui, pagal IP:portą). Resurso pasirinkimas – tai rato pasukimas kampu, kurį lemia paketo maiša.
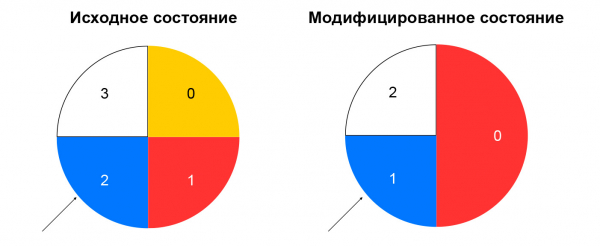
Tai sumažina srauto perskirstymą, kai pasikeičia išteklių sudėtis. Išteklių ištrynimas turės įtakos tik tai nuoseklaus maišos žiedo daliai, kurioje buvo išteklius. Pridėjus išteklius, pasikeičia ir paskirstymas, tačiau turime lipnių seansų mazgą, kuris leidžia neperjungti jau sukurtų seansų į naujus išteklius.
Pažiūrėjome, kas atsitinka nukreipiant srautą tarp balansavimo priemonės ir išteklių. Dabar pažiūrėkime į grįžtamąjį eismą. Tai atliekama pagal tą patį modelį, kaip ir tikrinant srautą – naudojant algoritminį NAT, ty atvirkštinį NAT 44 klientų srautui ir per NAT 46 sveikatos patikrinimų srautui. Mes laikomės savo schemos: sujungiame sveikatos patikrinimų srautą ir realų naudotojų srautą.
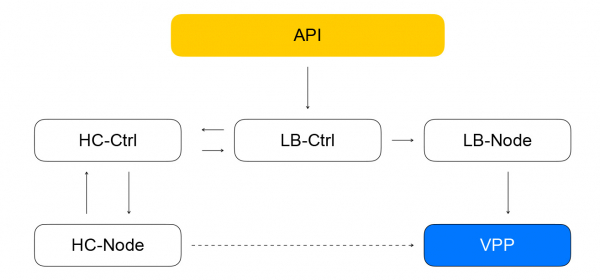
Apkrovos balansavimo mazgas ir surinkti komponentai
Balansuotojų ir išteklių sudėtį VPP praneša vietinė tarnyba - loadbalancer-node. Jis užsiprenumeruoja įvykių srautą iš „loadbalancer-controller“ ir gali nubrėžti skirtumą tarp dabartinės VPP būsenos ir tikslinės būsenos, gautos iš valdiklio. Gauname uždarą sistemą: įvykiai iš API ateina į balansavimo valdiklį, kuris sveikatos patikrinimo valdikliui paskiria užduotis, kad patikrintų resursų „gyvumą“. Tai savo ruožtu priskiria užduotis sveikatos patikrinimo mazgui ir apibendrina rezultatus, o po to siunčia juos atgal į balansavimo valdiklį. Apkrovos balansavimo mazgas prenumeruoja įvykius iš valdiklio ir keičia VPP būseną. Tokioje sistemoje kiekviena tarnyba apie gretimas paslaugas žino tik tai, kas būtina. Ryšių skaičius yra ribotas ir mes turime galimybę savarankiškai valdyti ir keisti skirtingus segmentus.
Kokių problemų pavyko išvengti?
Visos mūsų paslaugos valdymo plokštumoje yra parašytos Go ir turi geras mastelio ir patikimumo charakteristikas. Go turi daug atvirojo kodo bibliotekų, skirtų paskirstytoms sistemoms kurti. Aktyviai naudojame GRPC, visuose komponentuose yra atvirojo kodo paslaugų atradimo diegimas – mūsų paslaugos stebi viena kitos veiklą, gali dinamiškai keisti savo sudėtį ir tai susiejome su GRPC balansavimu. Metrikams taip pat naudojame atvirojo kodo sprendimą. Duomenų plotmėje gavome neblogą našumą ir didelį resursų rezervą: pasirodė labai sunku surinkti stovą, ant kurio galėtume pasikliauti VPP, o ne geležinės tinklo plokštės našumu.
Problemos ir sprendimai
Kas neveikė taip gerai? Go turi automatinį atminties valdymą, tačiau atminties nutekėjimo vis tiek pasitaiko. Lengviausias būdas su jais susidoroti yra vykdyti gorutinas ir nepamiršti jų nutraukti. Išsinešti: stebėkite savo Go programų atminties suvartojimą. Dažnai geras rodiklis yra gorutinų skaičius. Šioje istorijoje yra pliusas: „Go“ lengva gauti vykdymo duomenis - atminties suvartojimą, vykdomų gorutinų skaičių ir daugybę kitų parametrų.
Be to, „Go“ gali būti ne geriausias pasirinkimas funkciniams testams. Jie yra gana žodiniai, o standartinis metodas „paleisti viską CI grupėje“ jiems nelabai tinka. Faktas yra tas, kad funkciniai testai reikalauja daugiau išteklių ir sukelia realų skirtąjį laiką. Dėl šios priežasties bandymai gali nepavykti, nes CPU yra užimtas vienetų testais. Išvada: jei įmanoma, atlikite „sunkius“ bandymus atskirai nuo vienetinių bandymų.
„Microservice“ įvykių architektūra yra sudėtingesnė nei monolitas: rinkti žurnalus dešimtyse skirtingų mašinų nėra labai patogu. Išvada: jei teikiate mikropaslaugas, nedelsdami pagalvokite apie sekimą.
Mūsų planai
Paleisime vidinį balansavimo įtaisą, IPv6 balansavimo priemonę, pridėsime Kubernetes scenarijų palaikymą, toliau skirsime savo paslaugas (šiuo metu yra atskirtos tik „Healthcheck-node“ ir „Healthcheck-ctrl“), pridėsime naujų sveikatos patikrinimų, taip pat įdiegsime išmanųjį patikrinimų agregavimą. Svarstome galimybę savo paslaugas padaryti dar labiau nepriklausomas – kad jos bendrautų ne tiesiogiai tarpusavyje, o naudodamos pranešimų eilę. Neseniai debesyje pasirodė su SQS suderinama paslauga .
Neseniai įvyko viešas „Yandex Load Balancer“ išleidimas. Naršyti į servisą, tvarkykite balansuotojus jums patogiu būdu ir padidinkite savo projektų atsparumą gedimams!
Šaltinis: www.habr.com
