

Sveiki, Habr! Jūsų dėmesiui pristatau straipsnio vertimą
.
Kalbant apie reliacines duomenų bazes, negaliu negalvoti, kad kažko trūksta. Jie naudojami visur. Yra daug įvairių duomenų bazių, nuo mažos ir naudingos SQLite iki galingos Teradata. Tačiau yra tik keli straipsniai, paaiškinantys, kaip veikia duomenų bazė. Galite ieškoti patys naudodami „howdoesarelationaldatabasework“, kad pamatytumėte, kiek rezultatų yra nedaug. Be to, šie straipsniai yra trumpi. Jei ieškote naujausių „buzzy“ technologijų („BigData“, „NoSQL“ arba „JavaScript“), rasite išsamesnių straipsnių, paaiškinančių, kaip jos veikia.
Ar reliacinės duomenų bazės per senos ir per nuobodžios, kad jas būtų galima paaiškinti ne universitetų kursuose, moksliniuose darbuose ir knygose?

Aš, kaip kūrėjas, nekenčiu naudoti dalykų, kurių nesuprantu. O jei duomenų bazės buvo naudojamos daugiau nei 40 metų, tai turi būti priežastis. Bėgant metams aš praleidau šimtus valandų, kad iš tikrųjų suprasčiau šias keistas juodas dėžes, kurias naudoju kiekvieną dieną. Reliacinės duomenų bazės labai įdomu, nes jie remiantis naudingomis ir daugkartinio naudojimo koncepcijomis. Jei norite suprasti duomenų bazę, bet niekada neturėjote laiko ar noro gilintis į šią plačią temą, jums turėtų patikti šis straipsnis.
Nors šio straipsnio pavadinimas yra aiškus, šio straipsnio tikslas nėra suprasti, kaip naudotis duomenų baze... Taigi, jau turėtumėte žinoti, kaip parašyti paprastą prisijungimo užklausą ir pagrindines užklausas Neapdorotas; kitaip galite nesuprasti šio straipsnio. Tai vienintelis dalykas, kurį turite žinoti, visa kita paaiškinsiu.
Pradėsiu nuo kai kurių informatikos pagrindų, pvz., algoritmų sudėtingumo laiko atžvilgiu (BigO). Žinau, kad kai kurie iš jūsų nekenčia šios koncepcijos, bet be jos negalėsite suprasti duomenų bazės sudėtingumo. Kadangi tai didžiulė tema, Aš sutelksiu dėmesį į kas, mano nuomone, yra svarbu: kaip veikia duomenų bazė SQL paklausimas. Aš tik supažindinsiu pagrindinės duomenų bazės sąvokoskad straipsnio pabaigoje suprastumėte, kas vyksta po gaubtu.
Kadangi tai ilgas ir techninis straipsnis, kuriame yra daug algoritmų ir duomenų struktūrų, neskubėkite jį perskaityti. Kai kurias sąvokas gali būti sunku suprasti; galite juos praleisti ir vis tiek susidaryti bendrą idėją.
Labiau išmanantiems šį straipsnį šis straipsnis suskirstytas į 3 dalis:
- Žemo ir aukšto lygio duomenų bazės komponentų apžvalga
- Užklausos optimizavimo proceso apžvalga
- Sandorių ir buferio fondo valdymo apžvalga
Grįžti prie pagrindų
Prieš daugelį metų (toli, toli...) kūrėjai turėjo tiksliai žinoti operacijų, kurias jie koduoja, skaičių. Jie mintinai žinojo savo algoritmus ir duomenų struktūras, nes negalėjo sau leisti eikvoti savo lėtų kompiuterių procesoriaus ir atminties.
Šioje dalyje priminsiu kai kurias iš šių sąvokų, nes jos yra būtinos norint suprasti duomenų bazę. Taip pat pristatysiu koncepciją duomenų bazės indeksas.
O(1) prieš O(n2)
Šiais laikais daugeliui kūrėjų nerūpi algoritmų sudėtingumas laikui bėgant... ir jie teisūs!
Tačiau kai dirbate su daugybe duomenų (aš nekalbu apie tūkstančius) arba jei kovojate per milisekundes, labai svarbu suprasti šią sąvoką. Ir kaip jūs galite įsivaizduoti, duomenų bazės turi susidoroti su abiem atvejais! Neversiu jūsų praleisti daugiau laiko, nei reikia, kad suprastumėte esmę. Tai padės mums suprasti sąnaudomis pagrįsto optimizavimo sąvoką vėliau (kaina pagrįstas optimizavimas).
Sąvoka
Algoritmo sudėtingumas laike naudojamas norint pamatyti, kiek laiko užtruks tam tikro duomenų kiekio algoritmas. Šiam sudėtingumui apibūdinti naudojame didelį matematinį žymėjimą O. Šis žymėjimas naudojamas su funkcija, kuri apibūdina, kiek operacijų algoritmui reikia atlikti tam tikram įvesties skaičiui.
Pavyzdžiui, kai sakau „šio algoritmo sudėtingumas yra O(some_function())“, tai reiškia, kad algoritmas reikalauja tam tikros_funkcijos(a_tam tikras_duomenų_suma) operacijų, kad apdorotų tam tikrą duomenų kiekį.
Šiuo atveju, Svarbu ne duomenų kiekis**, kitaip ** kaip didėja operacijų skaičius didėjant duomenų kiekiui. Laiko sudėtingumas nenurodo tikslaus operacijų skaičiaus, bet yra geras būdas įvertinti vykdymo laiką.
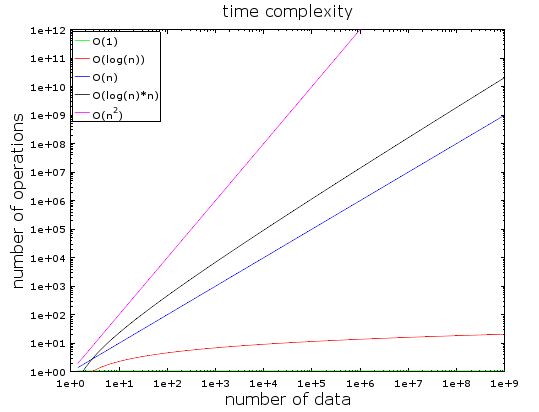
Šioje diagramoje galite matyti operacijų skaičių, palyginti su įvesties duomenų kiekiu, atsižvelgiant į skirtingus algoritmo laiko sudėtingumo tipus. Jiems rodyti naudojau logaritminę skalę. Kitaip tariant, duomenų kiekis greitai padidėja nuo 1 iki 1 mlrd. Matome, kad:
- O(1) arba pastovus sudėtingumas išlieka pastovus (kitaip jis nebūtų vadinamas pastoviu sudėtingumu).
- O(prisijungti(n)) išlieka žemas net ir turint milijardus duomenų.
- Blogiausias sunkumas - O(n2), kur operacijų skaičius sparčiai auga.
- Kitos dvi komplikacijos didėja taip pat greitai.
pavyzdžiai
Turint nedidelį duomenų kiekį, skirtumas tarp O(1) ir O(n2) yra nereikšmingas. Pavyzdžiui, tarkime, kad turite algoritmą, kuris turi apdoroti 2000 elementų.
- O(1) algoritmas jums kainuos 1 operaciją
- O(log(n)) algoritmas jums kainuos 7 operacijas
- O(n) algoritmas jums kainuos 2 operacijų
- O(n*log(n)) algoritmas jums kainuos 14 000 operacijų
- O(n2) algoritmas jums kainuos 4 000 000 operacijų
Skirtumas tarp O(1) ir O(n2) atrodo didelis (4 mln. operacijų), bet prarasite daugiausiai 2 ms, tik laikas mirksėti akimis. Iš tiesų, šiuolaikiniai procesoriai gali apdoroti . Štai kodėl našumas ir optimizavimas nėra daugelio IT projektų problema.
Kaip jau sakiau, dirbant su didžiuliais duomenų kiekiais vis dar svarbu žinoti šią sąvoką. Jei šį kartą algoritmas turi apdoroti 1 000 000 elementų (tai nėra tiek daug duomenų bazei):
- O(1) algoritmas jums kainuos 1 operaciją
- O(log(n)) algoritmas jums kainuos 14 operacijas
- O(n) algoritmas jums kainuos 1 000 000 operacijų
- O(n*log(n)) algoritmas jums kainuos 14 000 000 operacijų
- O(n2) algoritmas jums kainuos 1 000 000 000 000 operacijų
Aš nesuskaičiavau, bet sakyčiau, kad su O(n2) algoritmu jūs turite laiko išgerti kavos (net dvi!). Jei prie duomenų apimties pridėsite dar 0, turėsite laiko nusnūsti.
Eikime giliau
Jūsų informacija:
- Gera maišos lentelės paieška randa elementą O(1).
- Ieškant gerai subalansuoto medžio gaunami rezultatai O(log(n)).
- Ieškant masyve gaunami rezultatai O(n).
- Geriausi rūšiavimo algoritmai turi sudėtingumą O(n*log(n)).
- Blogas rūšiavimo algoritmas turi sudėtingumą O(n2).
Pastaba: Tolesnėse dalyse matysime šiuos algoritmus ir duomenų struktūras.
Yra keli algoritmų laiko sudėtingumo tipai:
- vidutinis atvejo scenarijus
- geriausiu atveju
- ir blogiausiu atveju
Laiko sudėtingumas dažnai yra blogiausias scenarijus.
Aš kalbėjau tik apie algoritmo sudėtingumą laike, tačiau sudėtingumas taip pat taikomas:
- algoritmo atminties suvartojimas
- disko I/O vartojimo algoritmas
Žinoma, yra komplikacijų, blogesnių nei n2, pavyzdžiui:
- n4: tai baisu! Kai kurie iš minėtų algoritmų turi tokį sudėtingumą.
- 3n: tai dar blogiau! Vienas iš algoritmų, kurį matysime šio straipsnio viduryje, turi tokį sudėtingumą (ir jis iš tikrųjų naudojamas daugelyje duomenų bazių).
- faktorialus n: niekada nepasieksite rezultatų net ir turėdami nedidelį kiekį duomenų.
- nn: Jei susiduriate su šiuo sudėtingumu, turėtumėte paklausti savęs, ar tai tikrai jūsų veiklos sritis...
Pastaba: aš nepateikiau tikrojo didžiojo O žymėjimo apibrėžimo, tik idėją. Šį straipsnį galite perskaityti adresu tikrajam (asimptotiniam) apibrėžimui.
MergeSort
Ką daryti, kai reikia rūšiuoti kolekciją? Ką? Jūs iškviečiate funkciją sort()... Gerai, geras atsakymas... Bet duomenų bazei turite suprasti, kaip veikia ši funkcija sort().
Yra keletas gerų rūšiavimo algoritmų, todėl sutelksiu dėmesį į svarbiausius: sujungti rūšiuoti. Galbūt nesuprantate, kodėl duomenų rūšiavimas yra naudingas dabar, bet turėtumėte atlikti po užklausos optimizavimo dalies. Be to, sujungimo rūšiavimo supratimas padės mums vėliau suprasti bendrą duomenų bazės sujungimo operaciją, vadinamą susijungti prisijungti (susijungimo asociacija).
Sujungti
Kaip ir daugelis naudingų algoritmų, sujungimo rūšiavimas priklauso nuo gudrybės: 2 surūšiuotų N/2 dydžio masyvų sujungimas į N elementų surūšiuotą masyvą kainuoja tik N operacijų. Ši operacija vadinama sujungimu.
Pažiūrėkime, ką tai reiškia, pateikdami paprastą pavyzdį:
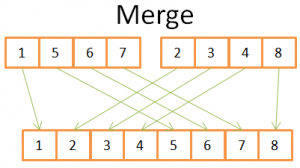
Šiame paveikslėlyje parodyta, kad norint sukurti galutinį surūšiuotą 8 elementų masyvą, reikia kartoti tik vieną kartą per 2 4 elementų masyvus. Kadangi abu 4 elementų masyvai jau surūšiuoti:
- 1) lyginate abu dabartinius elementus dviejuose masyvuose (pradžioje srovė = pirmas)
- 2) tada paimkite mažiausią ir įtraukite jį į 8 elementų masyvą
- 3) ir pereikite prie kito elemento masyve, kuriame paėmėte mažiausią elementą
- ir kartokite 1,2,3, kol pasieksite paskutinį vieno iš masyvo elementą.
- Tada paimkite likusius kito masyvo elementus, kad įtrauktumėte juos į 8 elementų masyvą.
Tai veikia, nes abu 4 elementų masyvai yra surūšiuoti, todėl jums nereikia „grįžti“ į šiuos masyvus.
Dabar, kai suprantame gudrybę, čia yra mano sujungimo pseudokodas:
array mergeSort(array a)
if(length(a)==1)
return a[0];
end if
//recursive calls
[left_array right_array] := split_into_2_equally_sized_arrays(a);
array new_left_array := mergeSort(left_array);
array new_right_array := mergeSort(right_array);
//merging the 2 small ordered arrays into a big one
array result := merge(new_left_array,new_right_array);
return result;Sujungimo rūšiavimas suskaido problemą į mažesnes problemas, o tada suranda mažesnių problemų rezultatus, kad gautų pradinės problemos rezultatą (pastaba: šis algoritmo tipas vadinamas padalinti ir užkariauti). Jei nesuprantate šio algoritmo, nesijaudinkite; Kai pirmą kartą pamačiau, nesupratau. Jei tai gali jums padėti, aš matau šį algoritmą kaip dviejų fazių algoritmą:
- Padalijimo fazė, kai masyvas yra padalintas į mažesnius masyvus
- Rūšiavimo fazė yra ta, kai maži masyvai sujungiami (naudojant jungtį), kad būtų sudarytas didesnis masyvas.
Padalijimo fazė
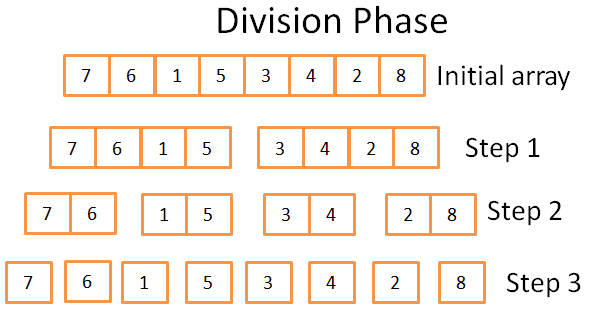
Padalijimo stadijoje masyvas padalinamas į vienetinius masyvus 3 žingsniais. Formalus žingsnių skaičius yra log(N) (kadangi N=8, log(N) = 3).
Iš kur tai žinoti?
Aš genijus! Žodžiu – matematika. Idėja tokia, kad kiekvienas žingsnis dalija pradinio masyvo dydį iš 2. Žingsnių skaičius yra tai, kiek kartų galite padalyti pradinį masyvą į dvi dalis. Tai tikslus logaritmo apibrėžimas (2 bazė).
Rūšiavimo etapas
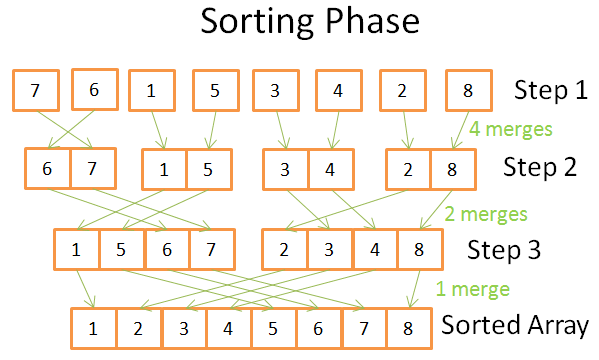
Rūšiavimo etape pradedate nuo vienetinių (vieno elemento) masyvų. Kiekviename veiksme taikote kelias sujungimo operacijas, o bendra kaina yra N = 8 operacijos:
- Pirmajame etape turite 4 sujungimus, kurių kiekvienas kainuoja po 2 operacijas
- Antrame etape turite 2 sujungimus, kurių kiekvienas kainuoja 4 operacijas
- Trečiajame etape turite 1 sujungimą, kuris kainuoja 8 operacijas
Kadangi yra log(N) žingsnių, bendra kaina N * log(N) operacijos.
Sujungimo rūšiavimo pranašumai
Kodėl šis algoritmas toks galingas?
Nes:
- Galite jį pakeisti, kad sumažintumėte atminties plotą, kad nekurtumėte naujų masyvų, o tiesiogiai pakeistumėte įvesties masyvą.
Pastaba: šio tipo algoritmas vadinamas (rūšiavimas be papildomos atminties).
- Galite jį pakeisti, kad tuo pačiu metu būtų naudojama vietos diske ir nedidelis atminties kiekis, nepatirdami didelių disko įvesties / išvesties išlaidų. Idėja yra įkelti į atmintį tik tas dalis, kurios šiuo metu yra apdorojamos. Tai svarbu, kai reikia rūšiuoti kelių gigabaitų lentelę su tik 100 megabaitų atminties buferiu.
Pastaba: šio tipo algoritmas vadinamas .
- Galite jį pakeisti, kad jis veiktų keliuose procesuose / gijose / serveriuose.
Pavyzdžiui, paskirstytas sujungimo rūšiavimas yra vienas iš pagrindinių komponentų (tai yra didelių duomenų struktūra).
- Šis algoritmas gali paversti šviną auksu (tikrai!).
Šis rūšiavimo algoritmas naudojamas daugumoje (jei ne visose) duomenų bazių, tačiau jis nėra vienintelis. Jei norite sužinoti daugiau, galite tai perskaityti , kuriame aptariami įprastų duomenų bazių rūšiavimo algoritmų privalumai ir trūkumai.
Masyvas, medis ir maišos lentelė
Dabar, kai suprantame laiko sudėtingumo ir rūšiavimo idėją, turėčiau papasakoti apie 3 duomenų struktūras. Tai svarbu, nes jie yra šiuolaikinių duomenų bazių pagrindas. Taip pat pristatysiu koncepciją duomenų bazės indeksas.
Masyvas
Dvimatis masyvas yra paprasčiausia duomenų struktūra. Lentelę galima įsivaizduoti kaip masyvą. Pavyzdžiui:
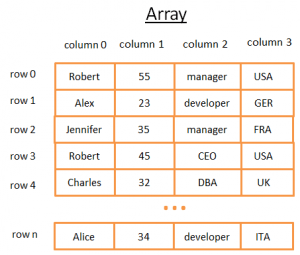
Šis dvimatis masyvas yra lentelė su eilutėmis ir stulpeliais:
- Kiekviena eilutė žymi objektą
- Stulpeliuose saugomos ypatybės, apibūdinančios objektą.
- Kiekviename stulpelyje saugomi tam tikro tipo duomenys (sveikasis skaičius, eilutė, data...).
Tai patogu duomenims saugoti ir vizualizuoti, tačiau kai reikia rasti konkrečią reikšmę, tai netinka.
Pavyzdžiui, jei norite rasti visus JK dirbančius vaikinus, turėtumėte peržiūrėti kiekvieną eilutę, kad nustatytumėte, ar ta eilutė priklauso JK. Tai jums kainuos N operacijųKur N - eilučių skaičius, tai nėra blogai, bet ar gali būti greitesnis būdas? Dabar atėjo laikas mums susipažinti su medžiais.
Pastaba: Daugumoje šiuolaikinių duomenų bazių yra išplėstų masyvų, skirtų efektyviam lentelių saugojimui: krūvoje organizuotos lentelės ir rodyklėmis organizuotos lentelės. Tačiau tai nekeičia problemos, kaip greitai rasti konkrečią sąlygą stulpelių grupėje.
Duomenų bazės medis ir indeksas
Dvejetainis paieškos medis yra dvejetainis medis su specialia savybe, raktas kiekviename mazge turi būti:
- didesnis nei visi raktai, saugomi kairiajame pomedyje
- mažiau nei visi raktai, saugomi dešiniajame pomedyje
Pažiūrėkime, ką tai reiškia vizualiai
Idėja
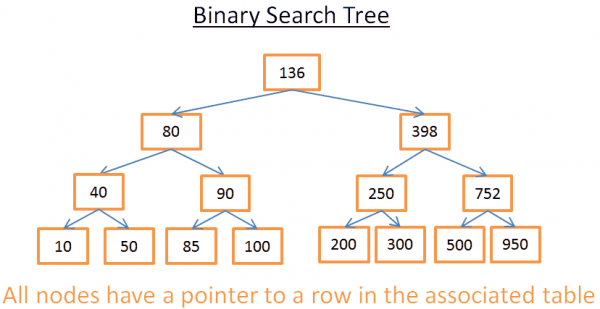
Šis medis turi N = 15 elementų. Tarkime, aš ieškau 208:
- Pradedu nuo šaknies, kurios raktas yra 136. Kadangi 136<208, žiūriu į dešinįjį mazgo 136 pomedį.
- 398>208, todėl žiūriu į kairįjį mazgo 398 pomedį
- 250>208, todėl žiūriu į kairįjį mazgo 250 pomedį
- 200<208, todėl žiūriu į dešinįjį mazgo 200 pomedį. Bet 200 neturi dešiniojo pomedžio, vertė neegzistuoja (nes jei jis egzistuoja, jis bus dešiniajame pomedyje 200).
Tarkime, aš ieškau 40
- Pradedu nuo šaknies, kurios raktas yra 136. Kadangi 136 > 40, žiūriu į kairįjį mazgo 136 pomedį.
- 80 > 40, todėl žiūriu į kairįjį 80 mazgo pomedį
- 40 = 40, mazgas egzistuoja. Gaunu eilutės ID mazgo viduje (ne paveikslėlyje) ir lentelėje ieškau nurodytos eilutės ID.
- Žinodamas eilutės ID, galiu tiksliai žinoti, kurioje lentelės vietoje yra duomenys, todėl galiu juos iš karto gauti.
Galų gale, abi paieškos man kainuos lygių skaičių medžio viduje. Jei atidžiai perskaitysite dalį apie sujungimo rūšiavimą, turėtumėte pamatyti, kad yra log(N) lygiai. Paaiškėja, paieškos išlaidų žurnalas (N), neblogai!
Grįžkime prie savo problemos
Bet tai labai abstraktu, todėl grįžkime prie mūsų problemos. Vietoj paprasto sveikojo skaičiaus įsivaizduokite eilutę, kuri reiškia kažkieno šalį ankstesnėje lentelėje. Tarkime, kad turite medį, kuriame yra lentelės laukas „šalis“ (3 stulpelis):
- Jei norite sužinoti, kas dirba JK
- žiūrite į medį, kad gautumėte mazgą, kuris reiškia Didžiąją Britaniją
- „UKnode“ viduje rasite JK darbuotojų įrašų vietą.
Ši paieška kainuos žurnalo (N) operacijų, o ne N operacijų, jei naudosite masyvą tiesiogiai. Tai, ką ką tik pristatėte, buvo duomenų bazės indeksas.
Galite sukurti indeksų medį bet kuriai laukų grupei (eilutė, skaičius, 2 eilutės, skaičius ir eilutė, data...), jei turite raktų (ty laukų grupių) palyginimo funkciją, kad galėtumėte nustatyti tvarka tarp raktų (taip yra visų pagrindinių duomenų bazės tipų atveju).
B+TreeIndex
Nors šis medis puikiai tinka norint gauti konkrečią vertę, kai reikia, iškyla DIDELI problema gauti kelis elementus tarp dviejų reikšmių. Tai kainuos O (N), nes turėsite pažvelgti į kiekvieną medžio mazgą ir patikrinti, ar jis yra tarp šių dviejų reikšmių (pvz., su užsakytu medžio perėjimu). Be to, ši operacija nėra tinkama įvesties / išvesties diskams, nes turite perskaityti visą medį. Turime rasti būdą, kaip efektyviai vykdyti diapazono užklausa. Norėdami išspręsti šią problemą, šiuolaikinės duomenų bazės naudoja modifikuotą ankstesnio medžio versiją, vadinamą B+Tree. B+ medžio medyje:
- tik žemiausi mazgai (lapai) saugoti informaciją (eilučių vieta susijusioje lentelėje)
- likusieji mazgai yra čia už maršrutą į tinkamą mazgą kratos metu.
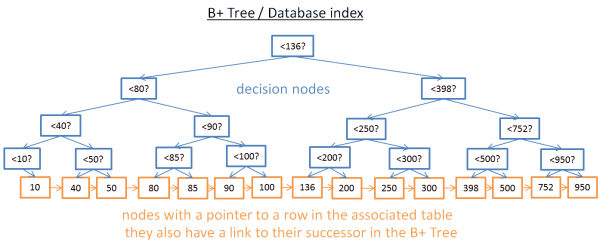
Kaip matote, čia yra daugiau mazgų (du kartus). Iš tiesų, jūs turite papildomų mazgų, „sprendimo mazgų“, kurie padės rasti tinkamą mazgą (kuris išsaugo susietos lentelės eilučių vietą). Tačiau paieškos sudėtingumas vis dar yra O(log(N)) (yra tik dar vienas lygis). Didelis skirtumas yra tas žemesnio lygio mazgai yra prijungti prie jų įpėdinių.
Jei ieškote reikšmių nuo 40 iki 100, naudodami šį B + medį:
- Jums tereikia ieškoti 40 (arba artimiausios reikšmės po 40, jei 40 nėra), kaip tai padarėte su ankstesniu medžiu.
- Tada surinkite 40 įpėdinių naudodami tiesiogines įpėdinių nuorodas, kol pasieksite 100.
Tarkime, kad radote M įpėdinių ir medis turi N mazgų. Konkretaus mazgo radimas kainuoja log(N), kaip ir ankstesniame medyje. Bet kai gausite šį mazgą, gausite M operacijų įpėdinių su nuorodomis į jų įpėdinius. Ši paieška kainuoja tik M+log(N) operacijų, palyginti su N operacijomis ankstesniame medyje. Be to, jums nereikia skaityti viso medžio (tik M+log(N) mazgai), o tai reiškia mažiau disko naudojimo. Jei M yra mažas (pvz., 200 eilučių), o N yra didelis (1 000 000 eilučių), skirtumas bus DIDELIS.
Tačiau čia (vėl!) atsiranda naujų problemų. Jei įtraukiate arba ištrinate eilutę duomenų bazėje (taigi ir susijusiame B+medžio indekse):
- turite palaikyti tvarką tarp mazgų B+Medžio viduje, kitaip negalėsite rasti mazgų nerūšiuotame medyje.
- turite išlaikyti minimalų įmanomą lygių skaičių B+Tree, kitaip O(log(N)) laiko sudėtingumas tampa O(N).
Kitaip tariant, B+Tree turi būti savarankiškas ir subalansuotas. Laimei, tai įmanoma naudojant išmaniąsias trynimo ir įterpimo operacijas. Tačiau tai kainuoja: įterpimai ir ištrynimai B+ medyje kainuoja O(log(N)). Štai kodėl kai kurie iš jūsų tai girdėjote naudoti per daug indeksų nėra gera idėja. tikrai, sulėtinate greitą lentelės eilutės įterpimą/atnaujinimą/trynimąnes duomenų bazėje reikia atnaujinti lentelės indeksus, naudojant brangią O(log(N)) operaciją kiekvienam indeksui. Be to, indeksų pridėjimas reiškia didesnį darbo krūvį sandorių vadybininkas (bus aprašyta straipsnio pabaigoje).
Daugiau informacijos rasite Vikipedijos straipsnyje . Jei norite B+Tree diegimo duomenų bazėje pavyzdžio, pažiūrėkite и iš pirmaujančio MySQL kūrėjo. Jie abu sutelkia dėmesį į tai, kaip InnoDB (MySQL variklis) tvarko indeksus.
Pastaba: skaitytojas man pasakė, kad dėl žemo lygio optimizavimo B+ medis turėtų būti visiškai subalansuotas.
Hashtable
Paskutinė svarbi duomenų struktūra yra maišos lentelė. Tai labai naudinga, kai norite greitai surasti vertes. Be to, maišos lentelės supratimas padės mums vėliau suprasti įprastą duomenų bazės prisijungimo operaciją, vadinamą maišos prisijungimu ( maišos prisijungti). Šią duomenų struktūrą duomenų bazė taip pat naudoja kai kuriems vidiniams dalykams saugoti (pvz. užrakinamas stalas arba buferinis baseinas, vėliau pamatysime abi šias sąvokas).
Maišos lentelė yra duomenų struktūra, kuri greitai suranda elementą pagal raktą. Norėdami sukurti maišos lentelę, turite apibrėžti:
- raktas jūsų elementams
- maišos funkcija už raktus. Apskaičiuotos raktų maišos nurodo elementų vietą (vadinamą segmentai ).
- klavišų palyginimo funkcija. Suradę tinkamą segmentą, naudodami šį palyginimą turite rasti ieškomą elementą segmente.
Paprastas pavyzdys
Paimkime aiškų pavyzdį:
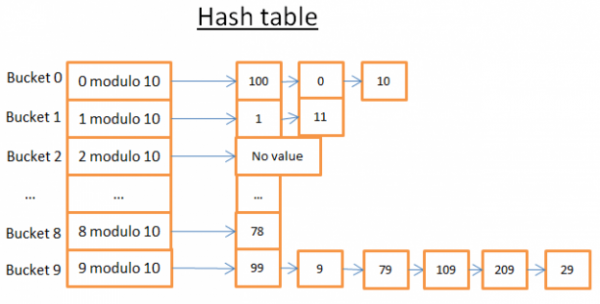
Šioje maišos lentelėje yra 10 segmentų. Kadangi esu tinginys, pavaizdavau tik 5 segmentus, bet žinau, kad tu protingas, todėl kitus 5 leisiu tau pavaizduoti patiems. Naudojau rakto maišos funkciją modulo 10. Kitaip tariant, išsaugau tik paskutinį elemento rakto skaitmenį, kad rasčiau jo segmentą:
- jei paskutinis skaitmuo yra 0, elementas patenka į 0 segmentą,
- jei paskutinis skaitmuo yra 1, elementas patenka į 1 segmentą,
- jei paskutinis skaitmuo yra 2, elementas patenka į 2 sritį,
- ...
Palyginimo funkcija, kurią naudoju, yra tiesiog lygybė tarp dviejų sveikųjų skaičių.
Tarkime, kad norite gauti 78 elementą:
- Maišos lentelė apskaičiuoja maišos kodą 78, kuris yra 8.
- Maišos lentelė žiūri į 8 segmentą, o pirmasis rastas elementas yra 78.
- Ji grąžina jums 78 prekę
- Paieška kainuoja tik 2 operacijas (vienas skirtas maišos vertei apskaičiuoti, o kitas elementui ieškoti segmente).
Tarkime, kad norite gauti 59 elementą:
- Maišos lentelė apskaičiuoja maišos kodą 59, kuris yra 9.
- Maišos lentelė ieško 9 segmente, pirmasis rastas elementas yra 99. Kadangi 99!=59, 99 elementas nėra tinkamas elementas.
- Taikant tą pačią logiką, imamas antrasis elementas (9), trečias (79), ..., paskutinis (29).
- Elementas nerastas.
- Paieška kainavo 7 operacijas.
Gera maišos funkcija
Kaip matote, priklausomai nuo vertės, kurios ieškote, kaina nėra vienoda!
Jei dabar pakeisiu rakto maišos funkciją modulo 1 000 000 (tai yra, paimdamas paskutinius 6 skaitmenis), antroji paieška kainuoja tik 1 operaciją, nes segmente 000059 nėra elementų. Tikras iššūkis yra rasti gerą maišos funkciją, kuri sukurtų segmentus, kuriuose būtų labai mažas elementų skaičius.
Mano pavyzdyje lengva rasti gerą maišos funkciją. Bet tai yra paprastas pavyzdys, rasti gerą maišos funkciją yra sunkiau, kai raktas yra:
- eilutė (pavyzdžiui, pavardė)
- 2 eilutės (pavyzdžiui, pavardė ir vardas)
- 2 eilutės ir data (pavyzdžiui, pavardė, vardas ir gimimo data)
- ...
Naudojant gerą maišos funkciją, maišos lentelės paieška kainuoja O (1).
Masyvas vs maišos lentelė
Kodėl nepanaudojus masyvo?
Hmm, geras klausimas.
- Maišos lentelė gali būti iš dalies įkeltas į atmintį, o likę segmentai gali likti diske.
- Naudodami masyvą turite naudoti gretimą vietą atmintyje. Jei kraunate didelį stalą labai sunku rasti pakankamai nuolatinės erdvės.
- Maišos lentelėje galite pasirinkti norimą raktą (pavyzdžiui, šalį ir asmens pavardę).
Norėdami gauti daugiau informacijos, galite perskaityti straipsnį apie , kuris yra efektyvus maišos lentelės įgyvendinimas; jums nereikia suprasti Java, kad suprastumėte šiame straipsnyje aptartas sąvokas.
Šaltinis: www.habr.com
