


Reguliariai susiduriame su Apache Cassandra duomenų baze ir būtinybe ją valdyti Kubernetes pagrindu veikiančioje infrastruktūroje. Šioje medžiagoje pasidalinsime savo vizija apie būtinus veiksmus, kriterijus ir esamus sprendimus (įskaitant operatorių apžvalgą), kad „Cassandra“ būtų perkelta į K8.
„Kas gali valdyti moterį, gali valdyti ir valstybę“
Kas yra Cassandra? Tai paskirstyta saugojimo sistema, skirta valdyti didelius duomenų kiekius, kartu užtikrinant aukštą pasiekiamumą be vieno gedimo taško. Projekto vargu ar reikia ilgos įžangos, todėl pateiksiu tik pagrindinius Cassandra bruožus, kurie bus aktualūs konkretaus straipsnio kontekste:
- „Cassandra“ parašyta „Java“ kalba.
- „Cassandra“ topologija apima kelis lygius:
- Mazgas – vienas įdiegtas „Cassandra“ egzempliorius;
- Rack yra Cassandra egzempliorių grupė, kurią vienija kai kurios savybės, esančios tame pačiame duomenų centre;
- Duomenų centras – visų Cassandra egzempliorių grupių, esančių viename duomenų centre, rinkinys;
- Klasteris yra visų duomenų centrų rinkinys.
- Cassandra naudoja IP adresą, kad nustatytų mazgą.
- Siekdama pagreitinti rašymo ir skaitymo operacijas, Cassandra kai kuriuos duomenis saugo RAM.
Dabar – apie faktinį potencialų persikėlimą į Kubernetes.
Perkėlimo kontrolinis sąrašas
Kalbėdami apie Cassandra migraciją į Kubernetes, tikimės, kad persikėlus ją bus patogiau valdyti. Ko tam reikės, kas padės?
1. Duomenų saugojimas
Kaip jau buvo paaiškinta, Cassanda dalį duomenų saugo RAM – in Įsiminė. Tačiau yra ir kita duomenų dalis, kuri išsaugoma diske – formoje SSTable. Prie šių duomenų pridedamas subjektas Įsipareigojimo žurnalas — visų operacijų įrašai, kurie taip pat išsaugomi diske.
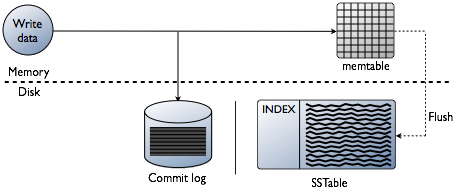
Parašykite sandorių diagramą Cassandra
„Kubernetes“ duomenims saugoti galime naudoti „PersistentVolume“. Dėl patikrintų mechanizmų darbas su duomenimis „Kubernetes“ kasmet tampa vis lengvesnis.
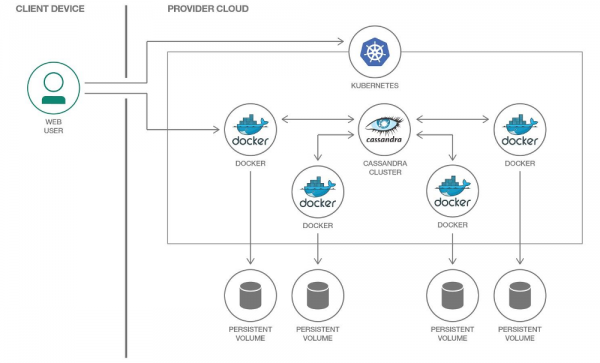
Kiekvienai „Cassandra“ angai paskirsime savo „PersistentVolume“.
Svarbu pažymėti, kad pati „Cassandra“ reiškia duomenų replikaciją, siūlydama tam įmontuotus mechanizmus. Todėl, jei kuriate Cassandra klasterį iš daugybės mazgų, duomenims saugoti nereikia naudoti paskirstytų sistemų, tokių kaip Ceph arba GlusterFS. Tokiu atveju būtų logiška duomenis saugoti pagrindiniame diske naudojant arba montavimas hostPath.
Kitas klausimas, ar norite sukurti atskirą aplinką kūrėjams kiekvienai funkcijų šakai. Šiuo atveju teisingas būdas būtų pakelti vieną Cassandra mazgą ir saugoti duomenis paskirstytoje saugykloje, t.y. paminėti Ceph ir GlusterFS bus jūsų pasirinkimas. Tada kūrėjas bus tikras, kad nepraras testų duomenų net jei bus prarastas vienas iš Kuberntes klasterio mazgų.
2. Stebėjimas
Praktiškai neginčijamas pasirinkimas įgyvendinant stebėjimą Kubernetes yra „Prometheus“. (apie tai išsamiai kalbėjome ). Kaip Cassandrai sekasi „Prometheus“ metrikų eksportuotojams? Ir kas dar svarbiau, jei „Grafana“ yra tinkamos prietaisų skydeliai?
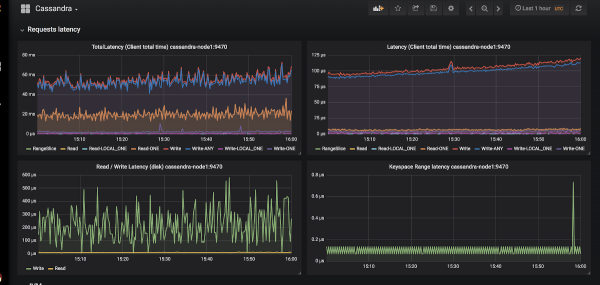
Grafana grafikų atsiradimo Cassandrai pavyzdys
Yra tik du eksportuotojai: и .
Pirmąjį išsirinkome sau, nes:
- „JMX Exporter“ auga ir vystosi, o „Cassandra Exporter“ nesulaukė pakankamai bendruomenės paramos. „Cassandra Exporter“ vis dar nepalaiko daugumos „Cassandra“ versijų.
- Galite paleisti jį kaip javaagent pridėdami vėliavėlę
-javaagent:<plugin-dir-name>/cassandra-exporter.jar=--listen=:9180. - Jam yra vienas , kuris nesuderinamas su Cassandra Exporter.
3. Kubernetes primityvų pasirinkimas
Pagal aukščiau pateiktą Cassandra klasterio struktūrą, pabandykime viską, kas ten aprašyta, išversti į Kubernetes terminologiją:
- Kasandros mazgas → Pod
- Cassandra Rack → StatefulSet
- Cassandra Datacenter → baseinas iš StatefulSets
- Cassandra Cluster → ???
Pasirodo, kad trūksta kažkokio papildomo objekto, kad būtų galima vienu metu valdyti visą „Cassandra“ klasterį. Bet jei ko nors nėra, mes galime tai sukurti! „Kubernetes“ turi mechanizmą, skirtą šiam tikslui nustatyti savo išteklius - .
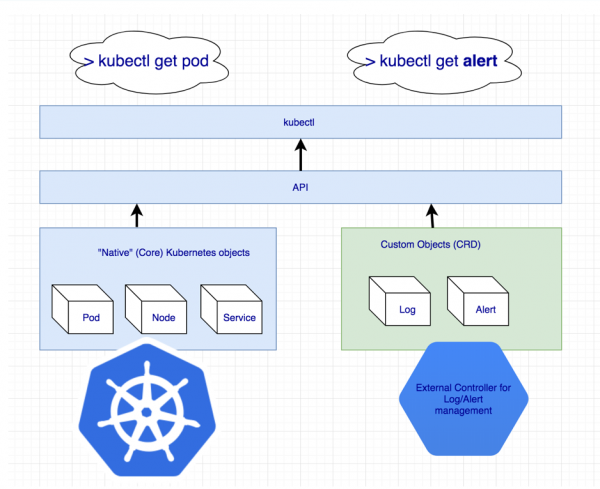
Papildomų žurnalų ir įspėjimų išteklių deklaravimas
Tačiau pats pasirinktinis išteklius nieko nereiškia: juk reikia valdytojas. Gali tekti kreiptis pagalbos ...
4. Ankštarų identifikavimas
Aukščiau esančioje pastraipoje sutarėme, kad vienas „Cassandra“ mazgas bus lygus vienam „Kubernetes“ blokui. Tačiau ankščių IP adresai kiekvieną kartą skirsis. Ir Cassandra mazgo identifikavimas yra pagrįstas IP adresu... Pasirodo, po kiekvieno ankšties pašalinimo Cassandra klasteris pridės naują mazgą.
Yra išeitis, ir ne viena:
- Galime saugoti įrašus pagal pagrindinio kompiuterio identifikatorius (UUID, kurie unikaliai identifikuoja Cassandra egzempliorius) arba pagal IP adresus ir visa tai saugoti kai kuriose struktūrose / lentelėse. Metodas turi du pagrindinius trūkumus:
- Lenktynių būklės rizika, jei du mazgai nukris vienu metu. Po kilimo „Cassandra“ mazgai vienu metu paprašys IP adreso iš lentelės ir konkuruos dėl tų pačių išteklių.
- Jei Cassandra mazgas prarado savo duomenis, nebegalėsime jo identifikuoti.
- Antrasis sprendimas atrodo kaip nedidelis įsilaužimas, bet vis dėlto: mes galime sukurti paslaugą su ClusterIP kiekvienam Cassandra mazgui. Su šiuo įgyvendinimu susijusios problemos:
- Jei Cassandra klasteryje yra daug mazgų, turėsime sukurti daug paslaugų.
- ClusterIP funkcija įgyvendinama per iptables. Tai gali tapti problema, jei Cassandra klasteris turi daug (1000... ar net 100?) mazgų. Nors gali išspręsti šią problemą.
- Trečias sprendimas yra naudoti Cassandra mazgų mazgų tinklą, o ne tam skirtą ankšties tinklą, įgalinant nustatymą
hostNetwork: true. Šis metodas nustato tam tikrus apribojimus:- Vienetams pakeisti. Būtina, kad naujasis mazgas turėtų tą patį IP adresą kaip ir ankstesnis (debesiuose, tokiuose kaip AWS, GCP, to padaryti beveik neįmanoma);
- Naudodamiesi klasterio mazgų tinklu, pradedame konkuruoti dėl tinklo išteklių. Todėl viename klasterio mazge įdėti daugiau nei vieną ankštį su Cassandra bus problematiška.
5. Atsarginės kopijos
Norime išsaugoti pilną vieno Cassandra mazgo duomenų versiją pagal tvarkaraštį. „Kubernetes“ suteikia patogią funkciją , bet čia pati Kasandra įkiša stipiną į mūsų ratus.
Leiskite jums priminti, kad Cassandra kai kuriuos duomenis saugo atmintyje. Norėdami sukurti visą atsarginę kopiją, jums reikia duomenų iš atminties (Atmintinai) perkelti į diską (SST lentelės). Šiuo metu Cassandra mazgas nustoja priimti ryšius ir visiškai išsijungia iš klasterio.
Po to atsarginė kopija pašalinama (momentinė nuotrauka) ir schema išsaugoma (klavišų tarpas). Ir tada paaiškėja, kad vien atsarginė kopija mums nieko neduoda: turime išsaugoti duomenų identifikatorius, už kuriuos buvo atsakingas Cassandra mazgas - tai specialūs žetonai.
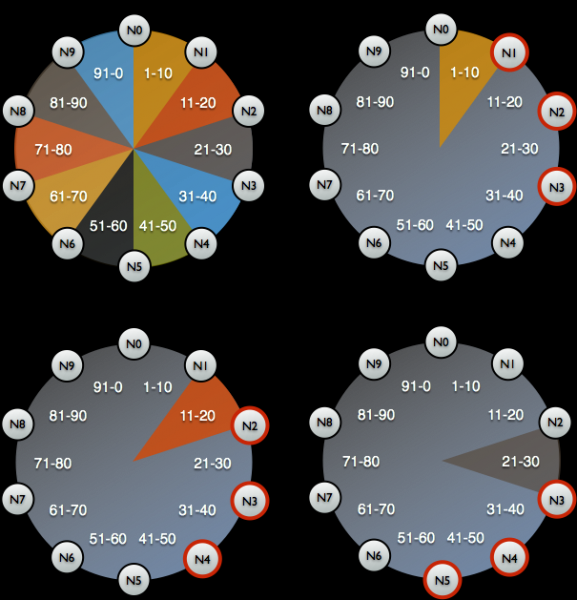
Žetonų platinimas, siekiant nustatyti, už kokius duomenis atsakingi Cassandra mazgai
Scenarijaus pavyzdį, kaip padaryti Cassandra atsarginę kopiją iš Google Kubernetes, galite rasti adresu . Vienintelis dalykas, į kurį scenarijus neatsižvelgia, yra duomenų mazgo nustatymas iš naujo prieš darant momentinę nuotrauką. Tai yra, atsarginė kopija daroma ne dabartinei, o šiek tiek ankstesnei būsenai. Bet tai padeda nenutraukti mazgo veikimo, o tai atrodo labai logiška.
set -eu
if [[ -z "$1" ]]; then
info "Please provide a keyspace"
exit 1
fi
KEYSPACE="$1"
result=$(nodetool snapshot "${KEYSPACE}")
if [[ $? -ne 0 ]]; then
echo "Error while making snapshot"
exit 1
fi
timestamp=$(echo "$result" | awk '/Snapshot directory: / { print $3 }')
mkdir -p /tmp/backup
for path in $(find "/var/lib/cassandra/data/${KEYSPACE}" -name $timestamp); do
table=$(echo "${path}" | awk -F "[/-]" '{print $7}')
mkdir /tmp/backup/$table
mv $path /tmp/backup/$table
done
tar -zcf /tmp/backup.tar.gz -C /tmp/backup .
nodetool clearsnapshot "${KEYSPACE}"Bash scenarijaus, skirto atsarginei kopijai daryti iš vieno Cassandra mazgo, pavyzdys
Paruošti Cassandra sprendimai Kubernetes mieste
Kas šiuo metu naudojama „Cassandra“ diegimui Kubernetes ir kuris iš jų geriausiai atitinka pateiktus reikalavimus?
1. Sprendimai, pagrįsti StatefulSet arba Helm diagramomis
Naudoti pagrindines StatefulSets funkcijas Cassandra klasteriui paleisti yra geras pasirinkimas. Naudodami „Helm“ diagramos ir „Go“ šablonus galite suteikti vartotojui lanksčią „Cassandra“ diegimo sąsają.
Paprastai tai veikia gerai... kol neįvyksta kažkas netikėto, pvz., mazgo gedimas. Standartiniai Kubernetes įrankiai tiesiog negali atsižvelgti į visas aukščiau aprašytas funkcijas. Be to, šis metodas yra labai ribotas, kiek jį galima išplėsti sudėtingesniems tikslams: mazgo keitimui, atsarginėms kopijoms, atkūrimui, stebėjimui ir kt.
Atstovai:
- ;
- .
Abi diagramos yra vienodai geros, tačiau jos turi aukščiau aprašytų problemų.
2. Kubernetes operatoriumi pagrįsti sprendimai
Tokios parinktys yra įdomesnės, nes suteikia daug galimybių valdyti klasterį. Kuriant „Cassandra“ operatorių, kaip ir bet kurią kitą duomenų bazę, geras modelis atrodo kaip „Sidecar“ <-> Controller <-> CRD:
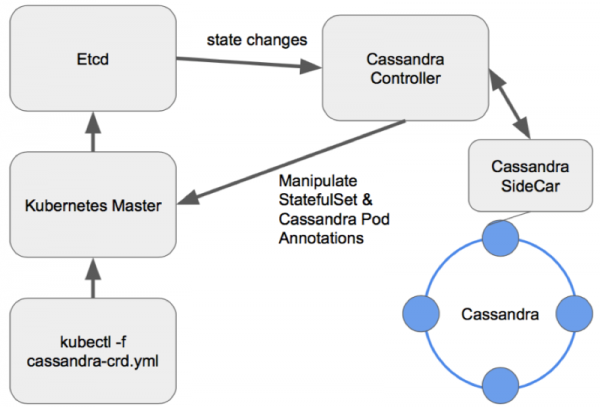
Mazgų valdymo schema gerai suprojektuotame „Cassandra“ operatoriuje
Pažvelkime į esamus operatorius.
1. Cassandra-operatorius iš instaclustr
- Pasirengimas: Alfa
- Licencija: Apache 2.0
- Įdiegta: Java
Tai iš tiesų labai perspektyvus ir aktyviai vystomas projektas iš įmonės, siūlančios valdomus Cassandra diegimus. Kaip aprašyta aukščiau, jis naudoja šoninį konteinerį, kuris priima komandas per HTTP. Parašyta „Java“, kartais trūksta pažangesnių „client-go“ bibliotekos funkcijų. Be to, operatorius nepalaiko skirtingų stelažų vienam duomenų centrui.
Tačiau operatorius turi tokius privalumus kaip stebėjimo palaikymas, aukšto lygio klasterių valdymas naudojant CRD ir net atsarginių kopijų kūrimo dokumentacija.
2. Navigatorius iš Jetstack
- Pasirengimas: Alfa
- Licencija: Apache 2.0
- Įgyvendinta: Golang
Teiginys, skirtas DB kaip paslaugai įdiegti. Šiuo metu palaiko dvi duomenų bazes: Elasticsearch ir Cassandra. Turi tokius įdomius sprendimus kaip prieigos prie duomenų bazės valdymas per RBAC (tam turi savo atskirą navigatorių-apiserverį). Įdomus projektas, į kurį vertėtų pasidomėti atidžiau, tačiau paskutinis įsipareigojimas buvo priimtas prieš pusantrų metų, kas akivaizdžiai sumažina jo potencialą.
3. Cassandra-operator Vgkowski
- Pasirengimas: Alfa
- Licencija: Apache 2.0
- Įgyvendinta: Golang
Jie to nesvarstė „rimtai“, nes paskutinis įsipareigojimas saugyklai buvo daugiau nei prieš metus. Atsisakoma operatoriaus kūrimo: naujausia „Kubernetes“ versija, apie kurią pranešta kaip palaikoma, yra 1.9.
4. Cassandra-operatorius pagal Rooką
- Pasirengimas: Alfa
- Licencija: Apache 2.0
- Įgyvendinta: Golang
Operatorius, kurio plėtra nevyksta taip greitai, kaip norėtume. Jis turi gerai apgalvotą CRD struktūrą, skirtą klasterių valdymui, išsprendžia mazgų identifikavimo problemą naudojant Service with ClusterIP (tas pats "nulaužimas")... bet kol kas tai viskas. Šiuo metu nėra stebėjimo ar atsarginių kopijų (beje, mes esame už stebėjimą ). Įdomu tai, kad naudodami šį operatorių taip pat galite įdiegti „ScyllaDB“.
NB: Mes naudojome šį operatorių su nedideliais pakeitimais viename iš savo projektų. Per visą eksploatacijos laikotarpį (~4 mėnesius) operatoriaus darbe jokių problemų nepastebėta.
5. CassKop iš Orange
- Pasirengimas: Alfa
- Licencija: Apache 2.0
- Įgyvendinta: Golang
Jauniausias operatorius sąraše: pirmasis įsipareigojimas buvo atliktas 23 m. gegužės 2019 d. Jau dabar jo arsenale yra daugybė funkcijų iš mūsų sąrašo, apie kurias daugiau informacijos galite rasti projekto saugykloje. Operatorius sukurtas remiantis populiariu operatoriumi-sdk. Palaiko stebėjimą iš dėžutės. Pagrindinis skirtumas nuo kitų operatorių yra naudojimas , įdiegtas Python ir naudojamas ryšiui tarp Cassandra mazgų.
išvados
Kasandros perkėlimo į „Kubernetes“ būdų ir galimų variantų skaičius kalba pats už save: tema yra paklausi.
Šiame etape galite išbandyti bet kurį iš aukščiau išvardytų dalykų savo rizika ir rizika: nė vienas kūrėjas negarantuoja 100% savo sprendimo veikimo gamybinėje aplinkoje. Tačiau jau dabar daugelis produktų atrodo daug žadantys, kad juos būtų galima naudoti kūrimo stenduose.
Manau, kad ateityje ši moteris laive pravers!
PS
Taip pat skaitykite mūsų tinklaraštyje:
- «»;
- «»;
- «»;
- «".
Šaltinis: www.habr.com
