

BŽŪP teorema yra paskirstytų sistemų teorijos kertinis akmuo. Žinoma, ginčai dėl to nerimsta: apibrėžimai jame nėra kanoniniai, o ir griežto įrodymo nėra... Vis dėlto, tvirtai stovėdami ant kasdienio sveiko proto™ pozicijų, intuityviai suprantame, kad teorema yra teisinga.

Vienintelis dalykas, kuris nėra akivaizdus, yra raidės „P“ reikšmė. Kai klasteris yra padalintas, jis nusprendžia, ar neatsakyti, kol nebus pasiektas kvorumas, ar grąžinti turimus duomenis. Priklausomai nuo šio pasirinkimo rezultatų, sistema klasifikuojama kaip CP arba AP. Pavyzdžiui, Cassandra gali elgtis bet kuriuo būdu, net ne nuo klasterio nustatymų, o nuo kiekvienos konkrečios užklausos parametrų. Bet jei sistema nėra "P" ir ji suskaidoma, kas tada?
Atsakymas į šį klausimą yra šiek tiek netikėtas: CA klasteris negali suskaidyti.
Kas tai per klasteris, kuris negali suskaidyti?
Esminis tokio klasterio atributas yra bendra duomenų saugojimo sistema. Daugeliu atvejų tai reiškia ryšį per SAN, todėl CA sprendimų naudojimas apribojamas didelėms įmonėms, galinčioms palaikyti SAN infrastruktūrą. Norint atlikti kelis serveriai Norint dirbti su tais pačiais duomenimis, reikalinga klasterio failų sistema. Tokios failų sistemos yra HPE (CFS), Veritas (VxCFS) ir IBM (GPFS) portfeliuose.
Oracle RAC
„Real Application Cluster“ parinktis pirmą kartą pasirodė 2001 m., išleidus „Oracle 9i“. Tokiame klasteryje gali būti kelios egzempliorių versijos. serveris dirbti su ta pačia duomenų baze.
„Oracle“ gali dirbti tiek su klasterizuota failų sistema, tiek su savo sprendimu – ASM, Automatic Storage Management.
Kiekviena kopija veda savo žurnalą. Sandorį vykdo ir įpareigoja vienas atvejis. Jei egzempliorius sugenda, vienas iš išlikusių klasterio mazgų (pavyzdžių) nuskaito jo žurnalą ir atkuria prarastus duomenis – taip užtikrinamas pasiekiamumas.
Visi egzemplioriai turi savo talpyklą, o tie patys puslapiai (blokai) gali būti kelių egzempliorių talpykloje vienu metu. Be to, jei vienam egzemplioriui reikia puslapio ir jis yra kito egzemplioriaus talpykloje, jis gali jį gauti iš savo kaimyno naudodamas talpyklos suliejimo mechanizmą, o ne nuskaitęs iš disko.
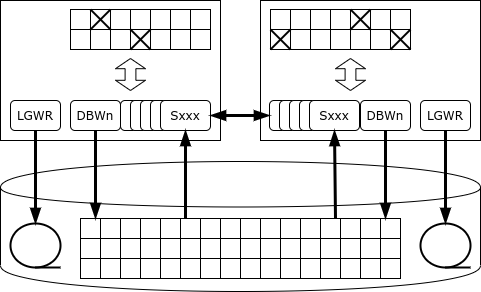
Bet kas atsitiks, jei vienam iš atvejų reikia pakeisti duomenis?
Oracle ypatumas yra tas, kad jame nėra specialios užrakinimo paslaugos: jei serveris nori užrakinti eilutę, tada užrakto įrašas patalpinamas tiesiai į atminties puslapį, kuriame yra užrakinta eilutė. Dėl šio požiūrio „Oracle“ yra našumo čempionė tarp monolitinių duomenų bazių: užrakinimo paslauga niekada netampa kliūtimi. Tačiau klasterio konfigūracijoje tokia architektūra gali sukelti intensyvų tinklo srautą ir aklavietę.
Kai įrašas užrakinamas, egzempliorius praneša visiems kitiems atvejams, kad puslapis, kuriame saugomas tas įrašas, turi išskirtinį sulaikymą. Jei kitam egzemplioriui reikia pakeisti įrašą tame pačiame puslapyje, jis turi palaukti, kol bus atlikti puslapio pakeitimai, tai yra, pakeitimo informacija įrašoma į diske esantį žurnalą (ir operacija gali tęstis). Taip pat gali atsitikti taip, kad puslapis bus pakeistas iš eilės keliomis kopijomis, o tada rašydami puslapį į diską turėsite išsiaiškinti, kas saugo dabartinę šio puslapio versiją.
Atsitiktinai atnaujinus tuos pačius puslapius skirtinguose RAC mazguose, duomenų bazės našumas labai sumažėja iki taško, kai klasterio našumas gali būti mažesnis nei vieno egzemplioriaus.
Tinkamas „Oracle RAC“ naudojimas yra fizinis duomenų skaidymas (pavyzdžiui, naudojant suskirstytos lentelės mechanizmą) ir prieiga prie kiekvieno skaidinių rinkinio per tam skirtą mazgą. Pagrindinis RAC tikslas buvo ne horizontalus mastelio keitimas, o gedimų tolerancijos užtikrinimas.
Jei mazgas nustoja reaguoti į širdies plakimą, jį pirmą kartą aptikęs mazgas pradeda balsavimo procedūrą diske. Jei trūkstamas mazgas čia nepažymimas, vienas iš mazgų prisiima atsakomybę už duomenų atkūrimą:
- „užšaldo“ visus puslapius, kurie buvo trūkstamo mazgo talpykloje;
- nuskaito trūkstamo mazgo žurnalus (perdaro) ir iš naujo pritaiko šiuose žurnaluose įrašytus pakeitimus, kartu tikrindama, ar kituose mazguose yra naujesnių keičiamų puslapių versijų;
- grąžina laukiančias operacijas.
Siekdama supaprastinti perjungimą tarp mazgų, „Oracle“ turi paslaugos koncepciją – virtualų egzempliorių. Egzempliorius gali teikti kelias paslaugas, o paslauga gali judėti tarp mazgų. Programos egzempliorius, aptarnaujantis tam tikrą duomenų bazės dalį (pavyzdžiui, klientų grupę), veikia su viena paslauga, o tarnyba, atsakinga už šią duomenų bazės dalį, perkeliama į kitą mazgą, kai mazgas sugenda.
„IBM Pure Data Systems for Transactions“.
2009 m. Blue Giant portfelyje pasirodė klasterinis DBVS sprendimas. Ideologiškai tai yra „Parallel Sysplex“ klasterio, sukurto ant „įprastos“ įrangos, įpėdinis. 2009 m. „DB2 pureScale“ buvo išleistas kaip programinės įrangos rinkinys, o 2012 m. IBM pasiūlė įrenginį, pavadintą „Pure Data Systems for Transactions“. Jo nereikėtų painioti su „Pure Data Systems for Analytics“, kuri yra ne kas kita, kaip pervadintas „Netezza“.
Iš pirmo žvilgsnio pureScale architektūra yra panaši į Oracle RAC: tokiu pat būdu keli mazgai yra prijungti prie bendros duomenų saugojimo sistemos, o kiekvienas mazgas vykdo savo DBVS egzempliorių su savo atminties sritimis ir operacijų žurnalais. Tačiau, skirtingai nei „Oracle“, DB2 turi specialią užrakinimo paslaugą, kurią sudaro db2LLM* procesų rinkinys. Klasterio konfigūracijoje ši paslauga yra atskirame mazge, kuris vadinamas sujungimo įrenginiu (CF) Parallel Sysplex, o PowerHA - Pure Data.
PowerHA teikia šias paslaugas:
- spynų tvarkyklė;
- pasaulinė buferinė talpykla;
- tarpprocesinių ryšių sritis.
Norint perkelti duomenis iš PowerHA į duomenų bazės mazgus ir atgal, naudojama nuotolinė atminties prieiga, todėl klasterio sujungimas turi palaikyti RDMA protokolą. „PureScale“ gali naudoti ir „Infiniband“, ir RDMA per Ethernet.
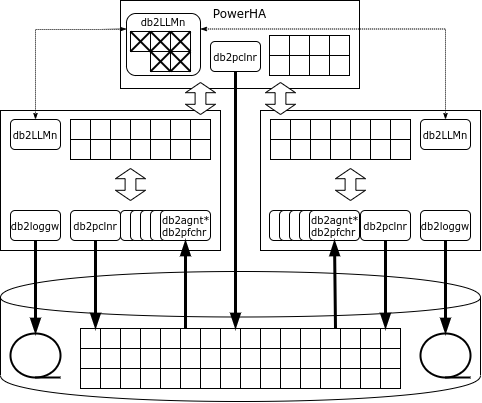
Jei mazgui reikalingas puslapis, o šio puslapio nėra talpykloje, tada mazgas prašo puslapio globaliojoje talpykloje ir tik jei jo nėra, nuskaito jį iš disko. Skirtingai nei „Oracle“, užklausa siunčiama tik „PowerHA“, o ne į gretimus mazgus.
Jei egzempliorius ketina pakeisti eilutę, jis užrakina ją išskirtiniu režimu, o puslapis, kuriame yra eilutė, bendrinamu režimu. Visos spynos užregistruojamos pasaulinėje spynų tvarkyklėje. Kai operacija baigiama, mazgas siunčia pranešimą užrakto tvarkytuvui, kuris nukopijuoja pakeistą puslapį į visuotinę talpyklą, atleidžia užraktus ir anuliuoja pakeistą puslapį kitų mazgų talpyklose.
Jei puslapis, kuriame yra pakeista eilutė, jau yra užrakintas, užrakto tvarkyklė nuskaitys pakeistą puslapį iš mazgo, kuris atliko pakeitimą, atminties, atleis užraktą, anuliuos pakeistą puslapį kitų mazgų talpyklose ir suteikite puslapio užraktą mazgui, kuris jo paprašė.
„Nešvarūs“, tai yra, pakeisti, puslapiai gali būti įrašomi į diską tiek iš įprasto mazgo, tiek iš PowerHA (išdavimo).
Jei vienas iš pureScale mazgų sugenda, atkūrimas apsiriboja tik tomis operacijomis, kurios dar nebuvo užbaigtos gedimo metu: puslapiai, kuriuos tas mazgas modifikavo užbaigtose operacijose, yra pasaulinėje PowerHA talpykloje. Mazgas iš naujo paleidžiamas sumažintos konfigūracijos viename iš klasterio serverių, grąžina laukiančias operacijas ir atleidžia užraktus.
PowerHA veikia dviejuose serveriuose, o pagrindinis mazgas sinchroniškai atkartoja savo būseną. Jei pirminis PowerHA mazgas sugenda, klasteris ir toliau veikia su atsarginiu mazgu.
Žinoma, jei prie duomenų rinkinio pasieksite per vieną mazgą, bendras klasterio našumas bus didesnis. „PureScale“ netgi gali pastebėti, kad tam tikrą duomenų sritį apdoroja vienas mazgas, o tada visi su ta sritimi susiję užraktai bus apdorojami mazgo vietoje, nebendraujant su PowerHA. Tačiau kai tik programa bandys pasiekti šiuos duomenis per kitą mazgą, centralizuotas užrakto apdorojimas bus atnaujintas.
IBM vidiniai 90 % skaitymo ir 10 % rašymo darbo krūvio testai, kurie labai panašūs į realaus pasaulio gamybos darbo krūvius, rodo beveik tiesinį mastelį iki 128 mazgų. Bandymo sąlygos, deja, neatskleidžiamos.
HPE NonStop SQL
„Hewlett-Packard Enterprise“ portfelis taip pat turi savo labai prieinamą platformą. Tai „NonStop“ platforma, kurią 1976 m. rinkai išleido „Tandem Computers“. 1997 m. kompaniją įsigijo „Compaq“, kuri savo ruožtu 2002 m. susijungė su „Hewlett-Packard“.
„NonStop“ naudojamas kuriant svarbias programas, pavyzdžiui, HLR arba banko kortelių apdorojimą. Platforma pristatoma kaip programinės ir techninės įrangos kompleksas (prietaisas), kurį sudaro skaičiavimo mazgai, duomenų saugojimo sistema ir ryšio įranga. ServerNet tinklas (šiuolaikinėse sistemose - Infiniband) tarnauja tiek mainams tarp mazgų, tiek prieigai prie duomenų saugojimo sistemos.
Ankstyvosiose sistemos versijose buvo naudojami patentuoti procesoriai, kurie buvo sinchronizuojami vienas su kitu: visas operacijas sinchroniškai atliko keli procesoriai, o kai tik vienas iš procesorių padarė klaidą, jis buvo išjungtas, o antrasis toliau dirbo. Vėliau sistema perėjo prie įprastų procesorių (iš pradžių MIPS, paskui Itanium ir galiausiai x86), o sinchronizavimui pradėti naudoti kiti mechanizmai:
- pranešimai: kiekvienas sistemos procesas turi „šešėlinį“ dvynį, kuriam aktyvus procesas periodiškai siunčia pranešimus apie savo būseną; jei pagrindinis procesas nepavyksta, šešėlinis procesas pradeda veikti nuo paskutinio pranešimo nustatyto momento;
- balsavimas: saugojimo sistema turi specialų techninės įrangos komponentą, kuris priima kelias vienodas prieigas ir jas vykdo tik tada, kai prieigos sutampa; Vietoj fizinės sinchronizacijos procesoriai veikia asinchroniškai, o jų darbo rezultatai lyginami tik I/O momentais.
Nuo 1987 m. NonStop platformoje veikia reliacinė DBVS – iš pradžių SQL/MP, o vėliau SQL/MX.
Visa duomenų bazė yra padalinta į dalis, ir kiekviena dalis yra atsakinga už savo duomenų prieigos tvarkyklės (DAM) procesą. Tai suteikia duomenų įrašymo, talpyklos ir užrakinimo mechanizmus. Duomenų apdorojimą vykdo vykdytojo serverio procesai, veikiantys tuose pačiuose mazguose kaip ir atitinkami duomenų valdytojai. SQL/MX planuoklis paskirsto užduotis vykdytojams ir apibendrina rezultatus. Kai reikia atlikti sutartus pakeitimus, naudojamas TMF (Transaction Management Facility) bibliotekos teikiamas dviejų fazių įpareigojimo protokolas.
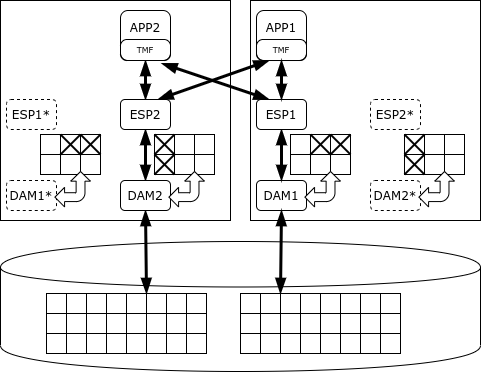
„NonStop SQL“ gali nustatyti procesų prioritetus, kad ilgos analitinės užklausos netrukdytų vykdyti operacijų. Tačiau jos tikslas yra būtent trumpųjų operacijų apdorojimas, o ne analizė. Kūrėjas garantuoja „NonStop“ klasterio prieinamumą penkių „devynių“ lygiu, tai yra, prastovos trukmė yra tik 5 minutės per metus.
SAP-HANA
Pirmasis stabilus HANA DBMS (1.0) leidimas įvyko 2010 m. lapkritį, o SAP ERP paketas buvo pakeistas į HANA 2013 m. gegužę. Platforma paremta įsigytomis technologijomis: TREX Search Engine (paieška stulpelinėje saugykloje), P*TIME DBMS ir MAX DB.
Pats žodis „HANA“ yra akronimas, High performance Analytical Appliance. Ši DBVS pateikiama kaip kodas, kuris gali veikti bet kuriuose x86 serveriuose, tačiau pramoniniai įrenginiai leidžiami tik sertifikuotoje įrangoje. Sprendimus galima įsigyti iš HP, Lenovo, Cisco, Dell, Fujitsu, Hitachi, NEC. Kai kurios „Lenovo“ konfigūracijos netgi leidžia veikti be SAN – bendros saugojimo sistemos vaidmenį atlieka GPFS klasteris vietiniuose diskuose.
Skirtingai nuo aukščiau išvardytų platformų, HANA yra atmintyje esanti DBVS, t. y. pirminis duomenų vaizdas yra saugomas RAM, o į diską įrašomi tik žurnalai ir periodinės momentinės nuotraukos, kad būtų galima atkurti nelaimės atveju.
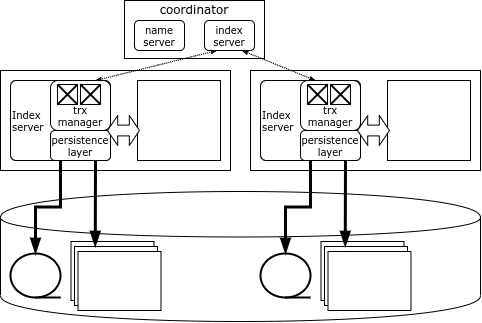
Kiekvienas HANA klasterio mazgas yra atsakingas už savo duomenų dalį, o duomenų žemėlapis saugomas specialiame komponente – Name Server, esančiame koordinatoriaus mazge. Duomenys tarp mazgų nesidubliuoja. Užrakinimo informacija taip pat saugoma kiekviename mazge, tačiau sistema turi visuotinį aklavietės detektorių.
Kai HANA klientas prisijungia prie klasterio, jis atsisiunčia savo topologiją ir gali tiesiogiai pasiekti bet kurį mazgą, priklausomai nuo to, kokių duomenų jam reikia. Jei sandoris paveikia vieno mazgo duomenis, tada jis gali būti vykdomas lokaliai to mazgo, tačiau pasikeitus kelių mazgų duomenims, inicijuojantis mazgas susisiekia su koordinatoriaus mazgu, kuris atidaro ir koordinuoja paskirstytą operaciją, įpareigojant ją naudoti optimizuotas dviejų fazių įteikimo protokolas.
Koordinatoriaus mazgas yra dubliuojamas, todėl jei koordinatorius sugenda, atsarginis mazgas iš karto perima. Bet jei mazgas su duomenimis sugenda, vienintelis būdas pasiekti jo duomenis yra paleisti mazgą iš naujo. Paprastai HANA klasteriai palaiko atsarginį serverį, kad kuo greičiau iš naujo paleistų prarastą mazgą.
Šaltinis: www.habr.com
