

Laba diena Mano vardas Danil Lipovoy, mūsų komanda Sbertech pradėjo naudoti HBase kaip operatyvinių duomenų saugyklą. Ją studijuojant susikaupė patirtis, kurią norėjau susisteminti ir aprašyti (tikimės, kad ji bus naudinga daugeliui). Visi toliau nurodyti eksperimentai buvo atlikti su HBase 1.2.0-cdh5.14.2 ir 2.0.0-cdh6.0.0-beta1 versijomis.
- Bendroji architektūra
- Duomenų rašymas į HBASE
- Duomenų skaitymas iš HBASE
- Duomenų kaupimas talpykloje
- Paketinis duomenų apdorojimas MultiGet/MultiPut
- Lentelių padalijimo į regionus strategija (skaldymas)
- Gedimų tolerancija, kompaktiškumas ir duomenų lokalizacija
- Nustatymai ir našumas
- Testavimas nepalankiausiomis sąlygomis
- išvados
1. Bendroji architektūra
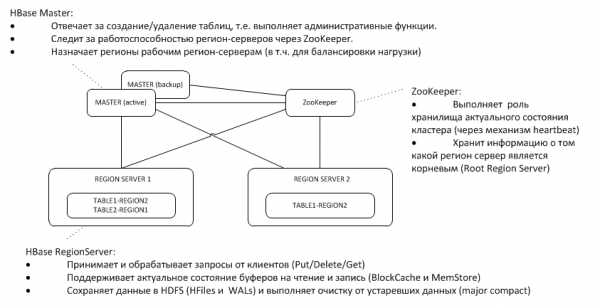
Atsarginis Meistras klausosi ZooKeeper mazgo aktyviojo širdies plakimo ir dingimo atveju perima šeimininko funkcijas.
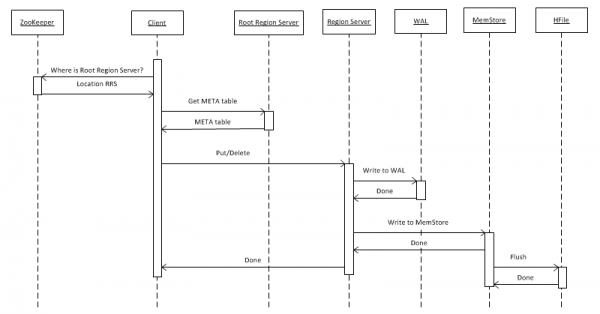
2. Įrašykite duomenis į HBASE
Pirmiausia pažiūrėkime į paprasčiausią atvejį – rakto vertės objekto įrašymą į lentelę naudojant put(rowkey). Pirmiausia klientas turi išsiaiškinti, kur yra šakninio regiono serveris (RRS), kuriame saugoma hbase:meta lentelė. Šią informaciją jis gauna iš „ZooKeeper“. Po to jis pasiekia RRS ir nuskaito hbase:meta lentelę, iš kurios išgauna informaciją apie tai, kuris regiono serveris (RS) yra atsakingas už tam tikros eilutės klavišo duomenų saugojimą dominančioje lentelėje. Ateičiai naudoti meta lentelę talpykloje saugo klientas, todėl vėlesni skambučiai vyksta greičiau, tiesiai į RS.
Toliau RS, gavęs užklausą, pirmiausia jį įrašo į WriteAheadLog (WAL), kuris reikalingas atkūrimui įvykus gedimui. Tada duomenys išsaugomi „MemStore“. Tai yra buferis atmintyje, kuriame yra surūšiuotas tam tikro regiono raktų rinkinys. Lentelę galima suskirstyti į regionus (skyrius), kurių kiekviename yra atskirtas raktų rinkinys. Tai leidžia jums išdėstyti regionus skirtinguose serveriuose, kad pasiektumėte didesnį našumą. Tačiau, nepaisant šio teiginio akivaizdumo, vėliau pamatysime, kad tai veikia ne visais atvejais.
Įdėjus įrašą MemStore, klientui grąžinamas atsakymas, kad įrašas sėkmingai išsaugotas. Tačiau iš tikrųjų jis yra saugomas tik buferyje ir patenka į diską tik praėjus tam tikram laikui arba kai jis užpildomas naujais duomenimis.
Atliekant operaciją „Ištrinti“, duomenys fiziškai neištrinami. Jie tiesiog pažymimi kaip ištrinti, o pats sunaikinimas įvyksta iškviečiant pagrindinę kompaktinę funkciją, kuri išsamiau aprašyta 7 pastraipoje.
Failai HFile formatu kaupiami HDFS ir karts nuo karto paleidžiamas nedidelis kompaktiškas procesas, kuris tiesiog sujungia mažus failus į didesnius nieko neištrindamas. Laikui bėgant tai virsta problema, kuri atsiranda tik skaitant duomenis (prie to grįšime šiek tiek vėliau).
Be aukščiau aprašyto įkėlimo proceso, yra kur kas efektyvesnė procedūra, kuri yra bene stipriausia šios duomenų bazės pusė – BulkLoad. Tai slypi tame, kad mes savarankiškai formuojame HFiles ir dedame juos į diską, o tai leidžia tobulai keisti mastelį ir pasiekti labai tinkamą greitį. Tiesą sakant, čia apribojimas yra ne HBase, o aparatinės įrangos galimybės. Toliau pateikiami klasterio, kurį sudaro 16 regionų serverių ir 16 NodeManager YARN (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 gijos), HBase versija 1.2.0-cdh5.14.2, įkrovos rezultatai.
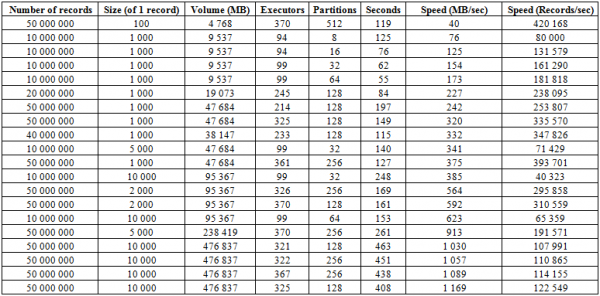
Čia matote, kad padidinę skirsnių (regionų) skaičių lentelėje, taip pat Spark vykdytojų, gauname atsisiuntimo greičio padidėjimą. Be to, greitis priklauso nuo įrašymo garsumo. Dideli blokai padidina MB/sek, maži blokai įterptų įrašų skaičių per laiko vienetą, visi kiti dalykai yra vienodi.
Taip pat galite pradėti krauti į dvi lenteles vienu metu ir gauti dvigubą greitį. Žemiau matote, kad 10 KB blokų rašymas į dvi lenteles vienu metu vyksta maždaug 600 MB/sek greičiu kiekvienoje (iš viso 1275 MB/sek), o tai sutampa su įrašymo į vieną lentelę greičiu 623 MB/sek (žr. Nr. 11 aukščiau)

Tačiau antrasis bandymas su 50 KB įrašais rodo, kad atsisiuntimo greitis šiek tiek auga, o tai rodo, kad jis artėja prie ribinių verčių. Tuo pačiu metu reikia nepamiršti, kad pačiam HBASE praktiškai nesukuriama apkrova, tereikia iš pradžių pateikti duomenis iš hbase:meta, o suklojus HFiles, iš naujo nustatyti BlockCache duomenis ir išsaugoti MemStore buferis į diską, jei jis nėra tuščias.
3. Duomenų nuskaitymas iš HBASE
Jei darysime prielaidą, kad klientas jau turi visą informaciją iš hbase:meta (žr. 2 punktą), tada užklausa eina tiesiai į RS, kur yra saugomas reikalingas raktas. Pirma, paieška atliekama „MemCache“. Nepriklausomai nuo to, ar ten yra duomenų, ar ne, paieška taip pat atliekama „BlockCache“ buferyje ir, jei reikia, „HFiles“. Jei faile buvo rasta duomenų, jie įdedami į BlockCache ir bus greičiau grąžinti kitą užklausą. HFile paieška yra gana greita, nes naudojamas Bloom filtras, t.y. perskaitęs nedidelį kiekį duomenų, iš karto nustato, ar šiame faile yra reikalingas raktas, o jei ne, tada pereina prie kito.
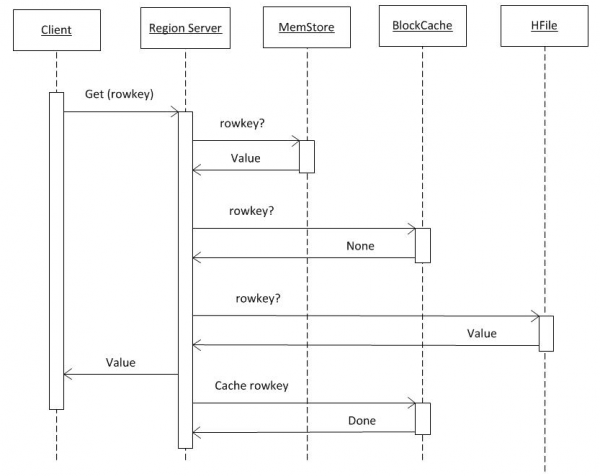
Gavusi duomenis iš šių trijų šaltinių, RS sugeneruoja atsakymą. Visų pirma, jis gali vienu metu perkelti kelias rastas objekto versijas, jei klientas paprašė versijos.
4. Duomenų kaupimas talpykloje
„MemStore“ ir „BlockCache“ buferiai užima iki 80% skirtos on-heap RS atminties (likusi dalis skirta RS aptarnavimo užduotims). Jei įprastas naudojimo režimas yra toks, kad procesai rašo ir iš karto nuskaito tuos pačius duomenis, prasminga sumažinti „BlockCache“ ir padidinti „MemStore“, nes Kai rašomi duomenys nepatenka į talpyklą skaitymui, BlockCache bus naudojama rečiau. „BlockCache“ buferis susideda iš dviejų dalių: „LruBlockCache“ (visada yra krūvoje) ir „BucketCache“ (dažniausiai ne krūvoje arba SSD diske). BucketCache reikia naudoti, kai yra daug skaitymo užklausų ir jos netelpa į LruBlockCache, o tai lemia aktyvų šiukšlių surinkėjo darbą. Tuo pačiu metu neturėtumėte tikėtis radikalaus našumo padidėjimo naudojant skaitymo talpyklą, tačiau prie to grįšime 8 dalyje.
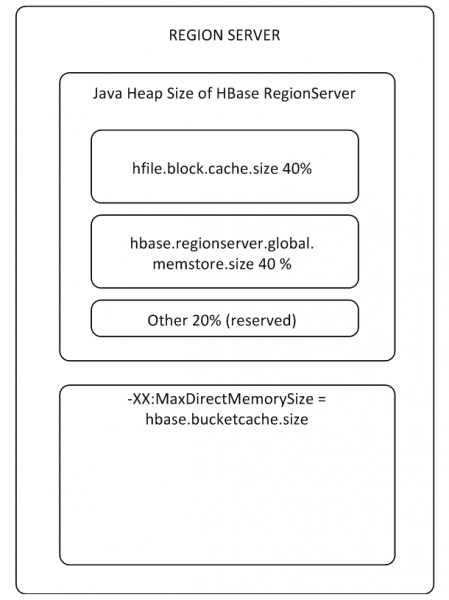
Yra viena „BlockCache“ visam RS ir yra viena „MemStore“ kiekvienai lentelei (po vieną kiekvienai stulpelių šeimai).
Kaip teoriškai rašant duomenys nepatenka į talpyklą ir iš tiesų tokie lentelės parametrai CACHE_DATA_ON_WRITE ir RS „Cache DATA on Write“ yra nustatyti kaip false. Tačiau praktikoje, jei įrašome duomenis į MemStore, tada išplauname juos į diską (taip išvalome), tada ištriname gautą failą, tada vykdydami get užklausą mes sėkmingai gausime duomenis. Be to, net jei visiškai išjungsite „BlockCache“ ir užpildysite lentelę naujais duomenimis, tada iš naujo nustatysite „MemStore“ į diską, ištrinsite juos ir paprašysite kito seanso, jie vis tiek bus iš kažkur nuskaityti. Taigi HBase saugo ne tik duomenis, bet ir paslaptingas paslaptis.
hbase(main):001:0> create 'ns:magic', 'cf'
Created table ns:magic
Took 1.1533 seconds
hbase(main):002:0> put 'ns:magic', 'key1', 'cf:c', 'try_to_delete_me'
Took 0.2610 seconds
hbase(main):003:0> flush 'ns:magic'
Took 0.6161 seconds
hdfs dfs -mv /data/hbase/data/ns/magic/* /tmp/trash
hbase(main):002:0> get 'ns:magic', 'key1'
cf:c timestamp=1534440690218, value=try_to_delete_me
Parametras „Cache DATA on Read“ nustatytas kaip klaidingas. Jei turite kokių nors idėjų, kviečiame jas aptarti komentaruose.
5. Paketinis duomenų apdorojimas MultiGet/MultiPut
Pavienių užklausų apdorojimas (Get/Put/Delete) yra gana brangi operacija, todėl, jei įmanoma, derėtų sujungti jas į sąrašą arba sąrašą, kuris leidžia gerokai padidinti našumą. Tai ypač pasakytina apie rašymo operaciją, tačiau skaitant yra tokia spąsta. Žemiau esančioje diagramoje parodytas laikas, per kurį reikia nuskaityti 50 000 įrašų iš MemStore. Skaitymas buvo atliktas vienoje gijoje, o horizontalioji ašis rodo užklausos klavišų skaičių. Čia matosi, kad padidinus iki tūkstančio raktų vienoje užklausoje, vykdymo laikas krenta, t.y. greitis didėja. Tačiau pagal numatytuosius nustatymus įjungus MSLAB režimą, po šios slenksčio prasideda radikalus našumo sumažėjimas ir kuo didesnis duomenų kiekis įraše, tuo ilgesnis veikimo laikas.
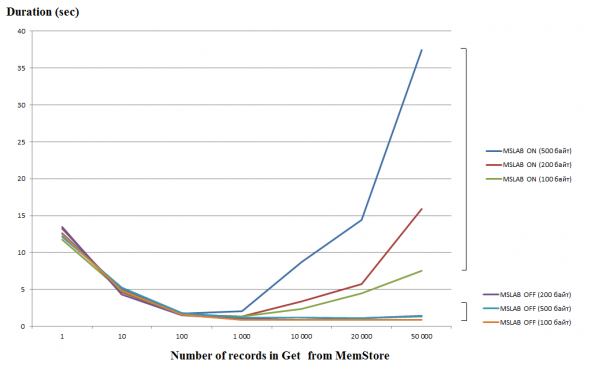
Testai buvo atlikti virtualioje mašinoje, 8 branduoliai, versija HBase 2.0.0-cdh6.0.0-beta1.
MSLAB režimas skirtas sumažinti krūvos fragmentaciją, kuri atsiranda dėl naujos ir senos kartos duomenų maišymo. Kaip išeitis, kai įjungtas MSLAB, duomenys dedami į santykinai mažas ląsteles (gabalus) ir apdorojami dalimis. Dėl to, kai prašomo duomenų paketo apimtis viršija skirtą dydį, našumas smarkiai sumažėja. Kita vertus, šio režimo išjungti taip pat nepatartina, nes intensyvaus duomenų apdorojimo momentais jis sustos dėl GC. Geras sprendimas yra padidinti ląstelių tūrį aktyvaus rašymo per įdėjimą atveju kartu su skaitymu. Verta paminėti, kad problema nekyla, jei po įrašymo paleidžiate praplovimo komandą, kuri iš naujo nustato „MemStore“ į diską, arba jei įkeliate naudodami „BulkLoad“. Toliau pateiktoje lentelėje parodyta, kad užklausos iš „MemStore“ dėl didesnių (ir tokio paties kiekio) duomenų sulėtėja. Tačiau padidinę gabalų dydį grąžiname apdorojimo laiką į normalų.
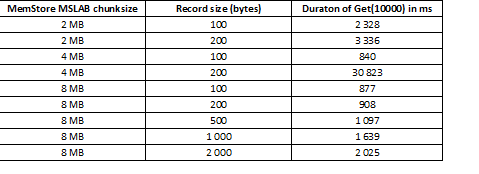
Be gabalų dydžio padidinimo, padeda duomenų skaidymas pagal regionus, t.y. stalo padalijimas. Dėl to į kiekvieną regioną gaunama mažiau užklausų ir, jei jos telpa į langelį, atsakymas išlieka geras.
6. Lentelių padalijimo į regionus strategija (skilimas)
Kadangi HBase yra rakto vertės saugykla, o skaidymas atliekamas pagal raktą, labai svarbu duomenis padalyti tolygiai visuose regionuose. Pavyzdžiui, suskaidžius tokią lentelę į tris dalis, duomenys bus suskirstyti į tris sritis:
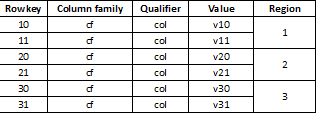
Taip atsitinka, kad tai sukelia staigų sulėtėjimą, jei vėliau įkelti duomenys atrodo kaip, pavyzdžiui, ilgos reikšmės, kurių dauguma prasideda tuo pačiu skaitmeniu, pavyzdžiui:
1000001
1000002
...
1100003
Kadangi raktai saugomi kaip baitų masyvas, jie visi prasidės taip pat ir priklausys tam pačiam regionui #1, kuriame saugomas šis raktų diapazonas. Yra keletas skaidymo strategijų:
HexStringSplit – paverčia raktą šešioliktaine koduota eilute diapazone „00000000“ => „FFFFFFFF“, o kairėje pusėje užpildoma nuliais.
UniformSplit – paverčia raktą į baitų masyvą su šešioliktaine koduote diapazone "00" => "FF", o dešinėje užpildyta nuliais.
Be to, galite nurodyti bet kokį padalijimo klavišų diapazoną arba rinkinį ir konfigūruoti automatinį padalijimą. Tačiau vienas iš paprasčiausių ir veiksmingiausių metodų yra UniformSplit ir maišos sujungimo naudojimas, pavyzdžiui, svarbiausia baitų pora, paleidžiant raktą per funkciją CRC32 (rowkey) ir pats eilutės klavišas:
maiša + eilutės klavišas
Tada visi duomenys bus tolygiai paskirstyti regionuose. Skaitant pirmieji du baitai tiesiog išmetami ir lieka originalus raktas. RS taip pat kontroliuoja duomenų ir raktų kiekį regione ir, viršijus ribas, automatiškai suskaido juos į dalis.
7. Gedimų tolerancija ir duomenų lokalizacija
Kadangi tik vienas regionas yra atsakingas už kiekvieną raktų rinkinį, problemų, susijusių su RS gedimais ar eksploatacijos nutraukimu, sprendimas yra saugoti visus būtinus duomenis HDFS. Kai RS nukrenta, kapitonas tai nustato, nes ZooKeeper mazge neplaka širdies. Tada jis priskiria aptarnaujamą regioną kitam RS ir kadangi HFiles saugomi paskirstytoje failų sistemoje, naujasis savininkas juos nuskaito ir toliau aptarnauja duomenis. Tačiau kadangi dalis duomenų gali būti „MemStore“ ir neturėjo laiko patekti į „HFiles“, WAL, kuri taip pat saugoma HDFS, naudojama operacijų istorijai atkurti. Pritaikius pakeitimus, RS gali reaguoti į užklausas, tačiau toks žingsnis priveda prie to, kad dalis duomenų ir juos aptarnaujančių procesų atsiduria skirtinguose mazguose, t.y. vietovė mažėja.
Problemos sprendimas yra didelis sutankinimas - ši procedūra perkelia failus į tuos mazgus, kurie yra atsakingi už juos (kur yra jų regionai), dėl ko šios procedūros metu smarkiai padidėja tinklo ir diskų apkrova. Tačiau ateityje prieiga prie duomenų bus pastebimai pagreitinta. Be to, major_compaction sujungia visus HFiles į vieną failą regione ir taip pat išvalo duomenis, priklausomai nuo lentelės nustatymų. Pavyzdžiui, galite nurodyti objekto versijų, kurios turi būti išsaugotos, skaičių arba eksploatavimo laiką, po kurio objektas bus fiziškai ištrintas.
Ši procedūra gali turėti labai teigiamą poveikį HBase veikimui. Toliau pateiktame paveikslėlyje parodyta, kaip dėl aktyvaus duomenų įrašymo pablogėjo našumas. Čia galite pamatyti, kaip 40 gijų rašė į vieną lentelę ir 40 gijų vienu metu nuskaito duomenis. Rašymo gijos sukuria vis daugiau HFile failų, kuriuos skaito kitos gijos. Dėl to vis daugiau duomenų reikia pašalinti iš atminties ir ilgainiui pradeda veikti GC, o tai praktiškai paralyžiuoja visą darbą. Pradėjus pagrindinį tankinimą, buvo pašalintos susidariusios šiukšlės ir atkurtas produktyvumas.
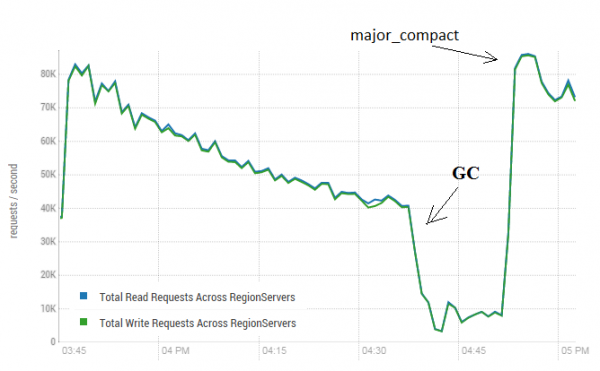
Bandymas buvo atliktas naudojant 3 DataNodes ir 4 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 gijos). HBase versija 1.2.0-cdh5.14.2
Verta paminėti, kad pagrindinis tankinimas buvo pradėtas „gyvoje“ lentelėje, į kurią buvo aktyviai įrašomi ir skaitomi duomenys. Internete buvo paskelbtas pareiškimas, kad tai gali sukelti neteisingą atsakymą skaitant duomenis. Norėdami patikrinti, buvo paleistas procesas, kuris sugeneravo naujus duomenis ir įrašė juos į lentelę. Po to iškart perskaičiau ir patikrinau, ar gauta reikšmė sutampa su užrašyta. Vykstant šiam procesui, pagrindinis tankinimas buvo vykdomas apie 200 kartų ir nebuvo užfiksuotas nė vienas gedimas. Galbūt problema iškyla retai ir tik esant didelei apkrovai, todėl saugiau sustabdyti rašymo ir skaitymo procesus, kaip planuota, ir atlikti valymą, kad būtų išvengta tokių GC nutekėjimų.
Be to, pagrindinis sutankinimas neturi įtakos „MemStore“ būsenai; norėdami nuplauti ją į diską ir sutankinti, turite naudoti flush (connection.getAdmin().flush(TableName.valueOf(tblName))).
8. Nustatymai ir našumas
Kaip jau minėta, HBase demonstruoja didžiausią sėkmę ten, kur jai nereikia nieko daryti, kai vykdo BulkLoad. Tačiau tai taikoma daugumai sistemų ir žmonių. Tačiau šis įrankis labiau tinka masiniams duomenims saugoti dideliuose blokuose, o jei procesui reikia kelių konkuruojančių skaitymo ir rašymo užklausų, naudojamos aukščiau aprašytos Get ir Put komandos. Norint nustatyti optimalius parametrus, buvo vykdomi paleidimai su įvairiais lentelės parametrų ir nustatymų deriniais:
- 10 gijų buvo paleista vienu metu 3 kartus iš eilės (vadinkime tai gijų bloku).
- Visų bloko gijų veikimo laikas buvo suvidurkintas ir buvo galutinis bloko veikimo rezultatas.
- Visi siūlai dirbo su ta pačia lentele.
- Prieš kiekvieną sriegio bloko pradžią buvo atliktas pagrindinis sutankinimas.
- Kiekvienas blokas atliko tik vieną iš šių operacijų:
— Padėkite
— Gauk
-Gauti+Put
- Kiekvienas blokas atliko 50 000 savo operacijos pakartojimų.
- Įrašo bloko dydis yra 100 baitų, 1000 baitų arba 10000 XNUMX baitų (atsitiktinis).
- Buvo paleisti blokai su skirtingu prašomų raktų skaičiumi (vienu raktu arba 10).
- Blokai buvo paleisti pagal skirtingus stalo nustatymus. Pakeisti parametrai:
— BlockCache = įjungta arba išjungta
— BlockSize = 65 KB arba 16 KB
— Pertvaros = 1, 5 arba 30
— MSLAB = įjungta arba išjungta
Taigi blokas atrodo taip:
a. MSLAB režimas buvo įjungtas / išjungtas.
b. Buvo sukurta lentelė, kuriai nustatyti šie parametrai: BlockCache = true/none, BlockSize = 65/16 Kb, Partition = 1/5/30.
c. Suspaudimas nustatytas į GZ.
d. 10 gijų buvo paleista vienu metu, atliekant 1/10 put/get/get+put operacijų šioje lentelėje su 100/1000/10000 baitų įrašais, atliekant 50 000 užklausų iš eilės (atsitiktiniai klavišai).
e. Taškas d buvo pakartotas tris kartus.
f. Visų siūlų veikimo laikas buvo suvidurkintas.
Buvo išbandyti visi galimi deriniai. Nuspėjama, kad greitis sumažės didėjant įrašo dydžiui arba kad išjungus talpyklą sulėtės. Tačiau tikslas buvo suprasti kiekvieno parametro įtakos laipsnį ir reikšmingumą, todėl surinkti duomenys buvo įvesti į tiesinės regresijos funkcijos įvestį, kuri leidžia įvertinti reikšmingumą naudojant t statistiką. Žemiau pateikiami blokų, atliekančių Put operacijas, rezultatai. Visas derinių rinkinys 2*2*3*2*3 = 144 variantai + 72 tk. kai kurie buvo atlikti du kartus. Taigi iš viso yra 216 važiavimų:
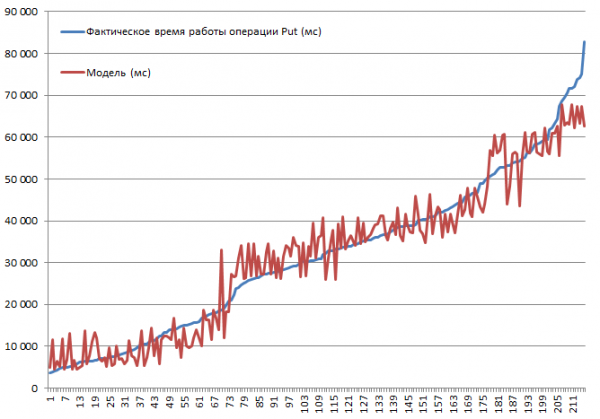
Bandymai buvo atlikti naudojant mini klasterį, kurį sudaro 3 DataNodes ir 4 RS (CPU Xeon E5-2680 v4 @ 2.40 GHz * 64 gijos). HBase versija 1.2.0-cdh5.14.2.
Didžiausias įterpimo greitis – 3.7 sekundės – buvo pasiektas išjungus MSLAB režimą, ant stalo su vienu skaidiniu, įjungus BlockCache, BlockSize = 16, įrašai 100 baitų, 10 vienetų pakuotėje.
Mažiausias įterpimo greitis 82.8 sek. buvo pasiektas įjungus MSLAB režimą, lentelėje su vienu skaidiniu, įjungus BlockCache, BlockSize = 16, įrašai po 10000 1 baitų, po XNUMX.
Dabar pažiūrėkime į modelį. Matome gerą modelio, paremto R2, kokybę, tačiau visiškai aišku, kad ekstrapoliacija čia draudžiama. Faktinis sistemos elgesys keičiantis parametrams nebus tiesinis, šis modelis reikalingas ne prognozėms, o tam, kad suprastų, kas atsitiko duotuose parametruose. Pavyzdžiui, iš Studento kriterijaus matome, kad parametrai BlockSize ir BlockCache nėra svarbūs Put operacijai (kuri paprastai yra gana nuspėjama):

Tačiau faktas, kad padidėjus skaidinių skaičiui sumažina našumą, yra šiek tiek netikėta (jau matėme teigiamą skaidinių skaičiaus padidinimo naudojant BulkLoad poveikį), nors ir suprantama. Pirma, norint apdoroti, turite sugeneruoti užklausas 30 regionų, o ne vieną, o duomenų kiekis nėra toks, kad tai duotų naudos. Antra, bendrą veikimo laiką lemia lėčiausias RS, o kadangi duomenų mazgų skaičius yra mažesnis už RS skaičių, kai kuriuose regionuose vietovė yra nulinė. Na, pažvelkime į penkis geriausius:

Dabar įvertinkime „Get blokų“ vykdymo rezultatus:

Skyrių skaičius prarado reikšmę, o tai tikriausiai paaiškinama tuo, kad duomenys gerai talpinami, o skaitymo talpykla yra reikšmingiausias (statistiškai) parametras. Natūralu, kad pranešimų skaičiaus padidinimas užklausoje taip pat labai naudingas našumui. Geriausi balai:

Na, galiausiai pažvelkime į bloko modelį, kuris pirmą kartą buvo atliktas, o tada įdėtas:

Čia svarbūs visi parametrai. Ir lyderių rezultatai:

9. Apkrovos testavimas
Na, pagaliau pradėsime daugmaž neblogą apkrovą, bet visada įdomiau, kai turi su kuo palyginti. „DataStax“, pagrindinio „Cassandra“ kūrėjo, svetainėje yra NT iš daugelio NoSQL saugyklų, įskaitant HBase 0.98.6-1 versiją. Įkėlimas buvo atliktas 40 gijų, duomenų dydis 100 baitų, SSD diskai. Skaitymo-keitimo-rašymo operacijų testavimo rezultatas parodė tokius rezultatus.
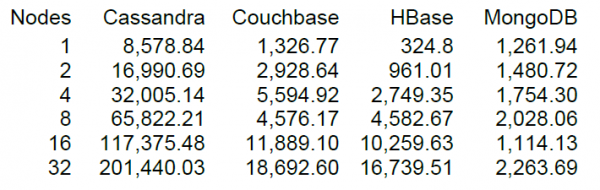
Kiek suprantu, skaitymas buvo atliktas 100 įrašų blokais ir 16 HBase mazgų, DataStax testas parodė 10 tūkstančių operacijų per sekundę našumą.
Laimei, kad mūsų klasteris taip pat turi 16 mazgų, bet nelabai „pasisekė“, kad kiekvienas turi 64 branduolius (gijas), o DataStax teste jų tik 4. Kita vertus, jie turi SSD diskus, o mes – HDD. ar daugiau naujos versijos HBase ir procesoriaus panaudojimas apkrovos metu praktiškai nepadidėjo (vizualiai 5-10 proc.). Tačiau pabandykime pradėti naudoti šią konfigūraciją. Numatytieji lentelės nustatymai, nuskaitymas raktų diapazone nuo 0 iki 50 milijonų atliekamas atsitiktinai (t. y. kiekvieną kartą iš esmės naujas). Lentelėje yra 50 milijonų įrašų, suskirstytų į 64 skaidinius. Raktai sumaišomi naudojant crc32. Lentelės nustatymai yra numatytieji, MSLAB įjungtas. Paleidus 40 gijų, kiekviena gija nuskaito 100 atsitiktinių raktų rinkinį ir iš karto įrašo sugeneruotus 100 baitų atgal į šiuos raktus.
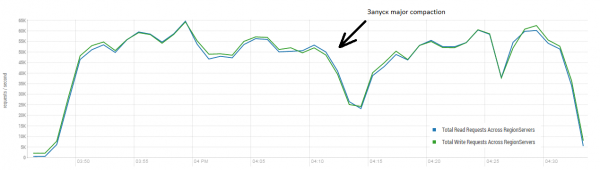
Stovas: 16 DataNode ir 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 gijos). HBase versija 1.2.0-cdh5.14.2.
Vidutinis rezultatas yra arčiau 40 tūkstančių operacijų per sekundę, o tai yra žymiai geriau nei DataStax teste. Tačiau eksperimentiniais tikslais galite šiek tiek pakeisti sąlygas. Mažai tikėtina, kad visi darbai bus atliekami tik ant vieno stalo, o taip pat tik ant unikalių raktų. Tarkime, kad yra tam tikras „karštas“ klavišų rinkinys, kuris generuoja pagrindinę apkrovą. Todėl pabandykime sukurti apkrovą didesniais įrašais (10 KB), taip pat partijomis po 100, 4 skirtingose lentelėse ir apribojant prašomų raktų diapazoną iki 50 tūkst.. Žemiau esančiame grafike parodytas 40 gijų paleidimas, kiekviena gija skaitoma 100 klavišų rinkinį ir iš karto įrašo atsitiktinius 10 KB ant šių klavišų atgal.
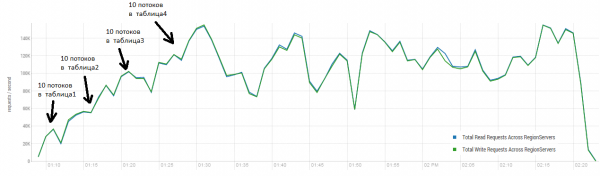
Stovas: 16 DataNode ir 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 gijos). HBase versija 1.2.0-cdh5.14.2.
Apkrovos metu kelis kartus buvo pradėtas pagrindinis tankinimas, kaip parodyta aukščiau, be šios procedūros eksploatacinės savybės pamažu pablogės, tačiau vykdant atsiranda ir papildoma apkrova. Sumažėjimą sukelia įvairios priežastys. Kartais gijos baigdavo veikti ir būdavo pauzė, kol jos buvo paleidžiamos iš naujo, kartais trečiųjų šalių programos apkrovė klasterį.
Skaitymas ir iš karto rašymas yra vienas iš sunkiausių HBase darbo scenarijų. Jei pateikiate tik mažas įdėjimo užklausas, pavyzdžiui, 100 baitų, sujungdami jas į 10-50 tūkstančių vienetų pakuotes, galite gauti šimtus tūkstančių operacijų per sekundę, panašiai yra ir su tik skaitomomis užklausomis. Verta pastebėti, kad rezultatai yra radikaliai geresni už gautus DataStax, labiausiai dėl užklausų blokais po 50 tūkst.
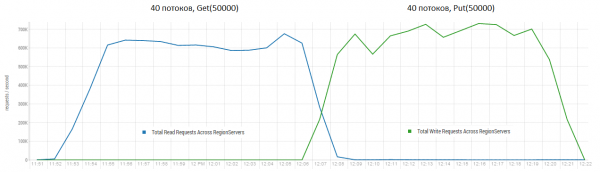
Stovas: 16 DataNode ir 16 RS (CPU Xeon E5-2680 v4 @ 2.40GHz * 64 gijos). HBase versija 1.2.0-cdh5.14.2.
10. Išvados
Ši sistema yra gana lanksčiai sukonfigūruota, tačiau daugelio parametrų įtaka vis dar nežinoma. Kai kurie iš jų buvo išbandyti, bet nebuvo įtraukti į gautą testų rinkinį. Pavyzdžiui, preliminarūs eksperimentai parodė nereikšmingą tokio parametro kaip DATA_BLOCK_ENCODING, kuris koduoja informaciją naudodamas gretimų langelių reikšmes, o tai suprantama atsitiktinai sugeneruotiems duomenims, reikšmę. Jei naudosite daug pasikartojančių objektų, nauda gali būti reikšminga. Apskritai galime teigti, kad HBase sukuria gana rimtos ir gerai apgalvotos duomenų bazės įspūdį, kuri gali būti gana produktyvi atliekant operacijas su dideliais duomenų blokais. Ypač jei įmanoma laiku atskirti skaitymo ir rašymo procesus.
Jei jūsų nuomone yra kažkas, kas nėra pakankamai atskleista, esu pasirengęs jums papasakoti išsamiau. Kviečiame pasidalinti savo patirtimi arba padiskutuoti, jei su kuo nors nesutinkate.
Šaltinis: www.habr.com
