

Mēs esam veiksmīgi izstrādājuši mūsu PostgreSQL datu bāzes struktūru korespondences glabāšanai, pagājis gads, lietotāji to aktīvi aizpilda, un tagad tajā ir miljoniem ierakstu, un... kaut kas sāka palēnināties.
- 2. daļa: iedalījums “peļņas gūšanai”

Fakts ir tāds, ka Pieaugot tabulas lielumam, pieaug arī indeksu “dziļums”. - kaut arī logaritmiski. Bet laika gaitā tas liek serverim veikt tos pašus lasīšanas/rakstīšanas uzdevumus apstrādāt daudzkārt vairāk datu lapunekā sākumā.
Šeit tas nāk palīgā sadalīšana.
Ļaujiet man atzīmēt, ka mēs nerunājam par sadalīšanu, tas ir, datu sadali starp dažādām datu bāzēm vai serveriem. Jo pat sadalot datus uz daži serveriem, jūs neatbrīvosities no indeksu “uzbriešanas” problēmas laika gaitā. Skaidrs, ka, ja katru dienu vari atļauties nodot ekspluatācijā jaunu serveri, tad tavas problēmas vairs nemaz neslēpsies konkrētas datu bāzes plaknē.
Mēs apsvērsim nevis konkrētus skriptus sadalīšanas ieviešanai “aparatūrā”, bet gan pašu pieeju - ko un kā vajadzētu “sagriezt šķēlēs”, un pie kā noved šāda vēlme.
Koncepcija
Vēlreiz definēsim savu mērķi: mēs vēlamies pārliecināties, ka šodien, rīt un pēc gada PostgreSQL nolasīto datu apjoms jebkuras lasīšanas/rakstīšanas darbības laikā paliek aptuveni tāds pats.
Jebkuram hronoloģiski uzkrātie dati (ziņojumi, dokumenti, žurnāli, arhīvi, ...) kā sadalīšanas atslēga ir dabiska izvēle notikuma datums/laiks. Mūsu gadījumā šāds pasākums ir ziņas nosūtīšanas brīdis.
Ņemiet vērā, ka lietotāji gandrīz vienmēr strādāt tikai ar “jaunākajiem”. tādi dati - viņi lasa jaunākos ziņojumus, analizē jaunākos žurnālus,... Nē, protams, viņi var ritināt laiku atpakaļ, bet viņi to dara ļoti reti.
No šiem ierobežojumiem ir skaidrs, ka optimālais ziņojuma risinājums būtu "ikdienas" sadaļas - galu galā mūsu lietotājs gandrīz vienmēr lasīs to, kas viņam nāca “šodien” vai “vakar”.
Ja dienas laikā rakstām un lasām gandrīz tikai vienā sadaļā, tad arī tas mums dod efektīvāka atmiņas un diska izmantošana - jo visi sadaļu indeksi viegli iekļaujas operatīvajā atmiņā, atšķirībā no "lielajiem un resnajiem" visā tabulā.
soli pa solim
Kopumā viss iepriekš teiktais izklausās pēc vienas nepārtrauktas peļņas. Un tas ir sasniedzams, bet mums būs smagi jācenšas - jo lēmums sadalīt vienu no entītijām noved pie nepieciešamības “zāģēt” saistīto.
Ziņojums, tā īpašības un projekcijas
Tā kā mēs nolēmām sagriezt ziņojumus pēc datumiem, ir lietderīgi sadalīt arī entītijas-rekvizītus, kas ir atkarīgi no tiem (pievienotie faili, adresātu saraksts) un arī pēc ziņojuma datuma.
Tā kā viens no mūsu tipiskajiem uzdevumiem ir precīza ziņojumu reģistru apskate (nelasītie, ienākošie, visi), ir arī loģiski tos “ievilkt” sadalīšanā pēc ziņojumu datumiem.
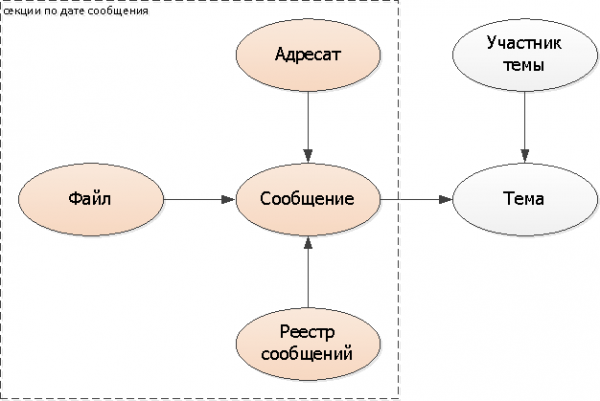
Mēs pievienojam sadalīšanas atslēgu (ziņojuma datumu) visām tabulām: adresāti, fails, reģistri. Jums tas nav jāpievieno pašam ziņojumam, bet jāizmanto esošais DateTime.
Tēmas
Tā kā vairākiem ziņojumiem ir tikai viena tēma, to nevar “sagriezt” vienā modelī, ir jāpaļaujas uz kaut ko citu. Mūsu gadījumā tas ir ideāls pirmās ziņas datums sarakstē — tas ir, tēmas radīšanas brīdis.
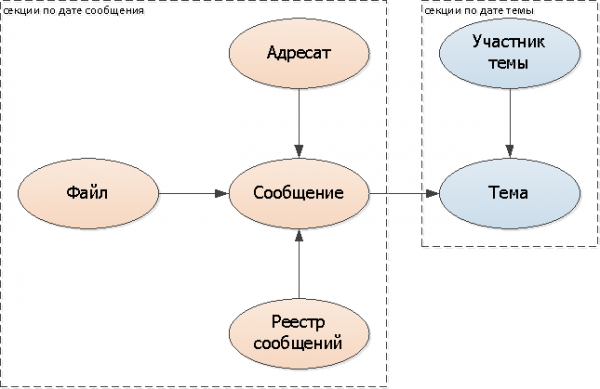
Pievienojiet sadalīšanas atslēgu (tēmas datumu) visām tabulām: tēma, dalībnieks.
Bet tagad mums ir divas problēmas vienlaikus:
- Kurā sadaļā meklēt ziņas par tēmu?
- Kurā sadaļā man meklēt tēmu no ziņojuma?
Mēs, protams, varam turpināt meklēšanu visās sadaļās, taču tas būs ļoti skumji un atteiks visus mūsu laimestus. Tāpēc, lai zinātu, kur tieši meklēt, izveidosim loģiskas saites/norādes uz sadaļām:
- pievienosim vēstulē tēmas datuma lauks
- papildināsim tēmu iestatīts ziņojuma datums šī sarakste (var būt atsevišķa tabula vai datumu masīvs)
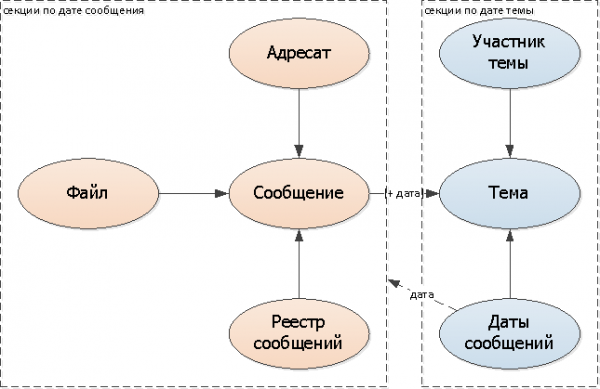
Tā kā katrai atsevišķai sarakstei ziņojumu datumu sarakstā būs maz modifikāciju (galu galā gandrīz visas ziņas iekrīt 1-2 blakus dienās), es pievērsīšos šai opcijai.
Kopumā mūsu datu bāzes struktūra bija šāda, ņemot vērā sadalīšanu:
Tabulas: RU, ja jums ir nepatika pret kirilicas alfabētu tabulu/lauku nosaukumos, labāk neskatīties
-- секции по дате сообщения
CREATE TABLE "Сообщение_YYYYMMDD"(
"Сообщение"
uuid
PRIMARY KEY
, "Тема"
uuid
, "ДатаТемы"
date
, "Автор"
uuid
, "ДатаВремя" -- используем как дату
timestamp
, "Текст"
text
);
CREATE TABLE "Адресат_YYYYMMDD"(
"ДатаСообщения"
date
, "Сообщение"
uuid
, "Персона"
uuid
, PRIMARY KEY("Сообщение", "Персона")
);
CREATE TABLE "Файл_YYYYMMDD"(
"ДатаСообщения"
date
, "Файл"
uuid
PRIMARY KEY
, "Сообщение"
uuid
, "BLOB"
uuid
, "Имя"
text
);
CREATE TABLE "РеестрСообщений_YYYYMMDD"(
"ДатаСообщения"
date
, "Владелец"
uuid
, "ТипРеестра"
smallint
, "ДатаВремя"
timestamp
, "Сообщение"
uuid
, PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение")
);
CREATE INDEX ON "РеестрСообщений_YYYYMMDD"("Владелец", "ТипРеестра", "ДатаВремя" DESC);
-- секции по дате темы
CREATE TABLE "Тема_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Документ"
uuid
, "Название"
text
);
CREATE TABLE "УчастникТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
, "Персона"
uuid
, PRIMARY KEY("Тема", "Персона")
);
CREATE TABLE "ДатыСообщенийТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Дата"
date
);
Ietaupiet diezgan santīmu
Nu, ja mēs neizmantojam pamatojoties uz lauka vērtību sadalījumu (izmantojot trigerus un mantojumu vai PARTITION BY) un “manuāli” lietojumprogrammas līmenī, pamanīsit, ka sadalīšanas atslēgas vērtība jau ir saglabāta pašas tabulas nosaukumā.
Tātad, ja jūs tā esat Vai jūs ļoti uztrauc saglabāto datu apjoms?, tad varat atbrīvoties no šiem “papildu” laukiem un adresēt konkrētas tabulas. Tiesa, visas atlases no vairākām sadaļām šajā gadījumā būs jāpārnes uz pieteikuma pusi.
Avots: www.habr.com
