

No Google emuāra redaktora: Vai esat kādreiz domājis, kā Google mākoņa tehnisko risinājumu (TSE) inženieri apstrādā jūsu atbalsta pieprasījumus? TSE tehniskā atbalsta inženieri ir atbildīgi par lietotāju ziņoto problēmu avotu identificēšanu un labošanu. Dažas no šīm problēmām ir diezgan vienkāršas, taču dažreiz jūs saskaraties ar biļeti, kas prasa vairāku inženieru uzmanību vienlaikus. Šajā rakstā viens no TSE darbiniekiem pastāstīs par vienu ļoti sarežģītu problēmu no savas nesenās prakses - . Šajā stāstā mēs redzēsim, kā inženieriem izdevās atrisināt situāciju un kādas jaunas lietas viņi uzzināja, novēršot kļūdu. Mēs ceram, ka šis stāsts ne tikai izglītos jūs par dziļi iesakņojušos kļūdu, bet arī sniegs ieskatu procesos, kas tiek veikti, iesniedzot atbalsta kvīti pakalpojumā Google Cloud.

Problēmu novēršana ir gan zinātne, gan māksla. Viss sākas ar hipotēzes izstrādi par sistēmas nestandarta uzvedības iemeslu, pēc tam tiek pārbaudīta tās izturība. Tomēr, pirms formulējam hipotēzi, mums ir skaidri jādefinē un precīzi jāformulē problēma. Ja jautājums izklausās pārāk neskaidrs, jums viss būs rūpīgi jāanalizē; Tā ir problēmu novēršanas “māksla”.
Izmantojot Google Cloud, šādi procesi kļūst eksponenciāli sarežģītāki, jo Google Cloud cenšas nodrošināt savu lietotāju privātumu. Šī iemesla dēļ TSE inženieriem nav piekļuves jūsu sistēmu rediģēšanai, kā arī iespēju skatīt konfigurācijas tikpat plaši kā lietotājiem. Tāpēc, lai pārbaudītu kādu no mūsu hipotēzēm, mēs (inženieri) nevaram ātri pārveidot sistēmu.
Daži lietotāji uzskata, ka mēs visu salabosim kā mehāniku autoservisā un vienkārši nosūtīsim mums virtuālās mašīnas ID, turpretī patiesībā process notiek sarunvalodas formātā: tiek vākta informācija, veidotas un apstiprinātas (vai atspēkotas) hipotēzes, un galu galā lēmuma pieņemšanas problēmas ir balstītas uz saziņu ar klientu.
Attiecīgā problēma
Šodien mums ir stāsts ar labām beigām. Viens no ierosinātās lietas veiksmīgas atrisināšanas iemesliem ir ļoti detalizēts un precīzs problēmas apraksts. Tālāk ir redzama pirmās biļetes kopija (rediģēta, lai paslēptu konfidenciālu informāciju):
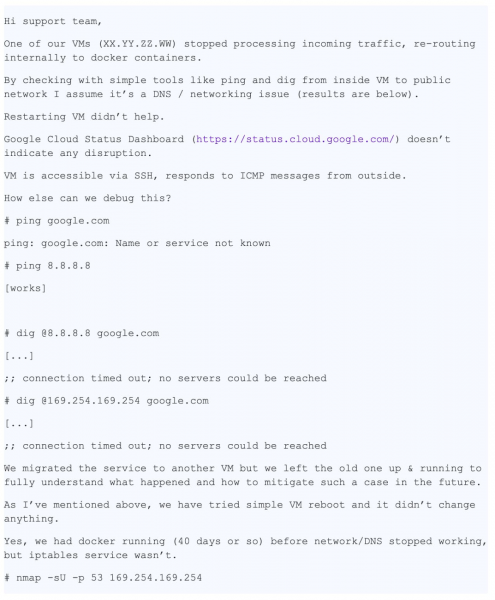
Šis ziņojums satur mums daudz noderīgas informācijas:
- Norādīta konkrēta VM
- Tiek norādīta pati problēma - DNS nedarbojas
- Ir norādīts, kur problēma izpaužas - VM un konteiners
- Ir norādītas darbības, ko lietotājs veica, lai identificētu problēmu.
Pieprasījums tika reģistrēts kā “P1: Critical Impact - Service Unusable in production”, kas nozīmē pastāvīgu situācijas uzraudzību 24/7 saskaņā ar shēmu “Seko saulei” (var lasīt vairāk par ), ar tās pāreju no vienas tehniskā atbalsta komandas uz citu ar katru laika joslu maiņu. Faktiski brīdī, kad problēma sasniedza mūsu komandu Cīrihē, tā jau bija apbraukusi visu pasauli. Līdz tam laikam lietotājs bija veicis mazināšanas pasākumus, taču baidījās no situācijas atkārtošanās ražošanā, jo galvenais iemesls vēl nebija atklāts.
Kad biļete sasniedza Cīrihi, mums jau bija šāda informācija:
- Saturs
/etc/hosts - Saturs
/etc/resolv.conf - secinājums
iptables-save - Komandas komplektēta
ngreppcap fails
Ar šiem datiem mēs bijām gatavi sākt “izmeklēšanas” un problēmu novēršanas posmu.
Mūsu pirmie soļi
Pirmkārt, mēs pārbaudījām metadatu servera žurnālus un statusu un pārliecinājāmies, ka tas darbojas pareizi. Metadatu serveris reaģē uz IP adresi 169.254.169.254 un, cita starpā, ir atbildīgs par domēna nosaukumu kontroli. Mēs arī vēlreiz pārbaudījām, vai ugunsmūris darbojas pareizi ar virtuālo mašīnu un nebloķē paketes.
Tā bija sava veida dīvaina problēma: nmap pārbaude atspēkoja mūsu galveno hipotēzi par UDP pakešu zudumu, tāpēc mēs domājām izdomājām vēl vairākas iespējas un veidus, kā tās pārbaudīt:
- Vai paketes tiek nomestas selektīvi? => Pārbaudiet iptables noteikumus
- Vai tas nav par mazu? ? => Pārbaudiet izvadi
ip a show - Vai problēma skar arī tikai UDP paketes vai TCP? => Brauc prom
dig +tcp - Vai rakšanas ģenerētās paketes tiek atgrieztas? => Brauc prom
tcpdump - Vai libdns darbojas pareizi? => Brauc prom
stracelai pārbaudītu pakešu pārraidi abos virzienos
Šeit mēs nolemjam piezvanīt lietotājam, lai tiešraidē novērstu problēmas.
Sarunas laikā mēs varam pārbaudīt vairākas lietas:
- Pēc vairākām pārbaudēm mēs izslēdzam iptables noteikumus no iemeslu saraksta
- Mēs pārbaudām tīkla saskarnes un maršrutēšanas tabulas un vēlreiz pārbaudām, vai MTU ir pareiza
- Mēs to atklājam
dig +tcp google.com(TCP) darbojas kā nākas, betdig google.com(UDP) nedarbojas - Aizbraucis
tcpdumptas joprojām darbojasdig, mēs atklājam, ka tiek atgrieztas UDP paketes - Braucam prom
strace dig google.comun mēs redzam, kā rakt pareizi aicinasendmsg()иrecvms(), tomēr otro pārtrauc taimauts
Diemžēl pienāk maiņas beigas un esam spiesti problēmu eskalēt uz nākamo laika joslu. Taču pieprasījums mūsu komandā izraisīja interesi, un kāds kolēģis iesaka izveidot sākotnējo DNS pakotni, izmantojot skrāpējošo Python moduli.
from scapy.all import *
answer = sr1(IP(dst="169.254.169.254")/UDP(dport=53)/DNS(rd=1,qd=DNSQR(qname="google.com")),verbose=0)
print ("169.254.169.254", answer[DNS].summary())Šis fragments izveido DNS paketi un nosūta pieprasījumu metadatu serverim.
Lietotājs palaiž kodu, tiek atgriezta DNS atbilde, un lietojumprogramma to saņem, apstiprinot, ka tīkla līmenī nav problēmu.
Pēc kārtējā “apceļojuma apkārt pasaulei” pieprasījums atgriežas mūsu komandā, un es to pilnībā nododu sev, domājot, ka lietotājam būs ērtāk, ja pieprasījums pārstās riņķot no vienas vietas uz otru.
Tikmēr lietotājs laipni piekrīt nodrošināt sistēmas attēla momentuzņēmumu. Tā ir ļoti laba ziņa: iespēja pašam pārbaudīt sistēmu padara traucējummeklēšanu daudz ātrāku, jo man vairs nav jāprasa lietotājam palaist komandas, sūtīt rezultātus un analizēt tos, visu varu izdarīt pats!
Mani kolēģi sāk nedaudz apskaust. Pusdienu laikā mēs apspriežam konversiju, bet nevienam nav ne jausmas, kas notiek. Par laimi, lietotājs pats jau ir veicis pasākumus, lai mazinātu sekas, un nesteidzas, tāpēc mums ir laiks, lai atrisinātu problēmu. Un, tā kā mums ir attēls, mēs varam veikt jebkurus testus, kas mūs interesē. Lieliski!
Atkāpjoties
Viens no populārākajiem intervijas jautājumiem sistēmu inženiera amatiem ir: “Kas notiek, kad ping ? Jautājums ir lielisks, jo kandidātam ir jāapraksta viss, sākot no čaulas līdz lietotāja telpai, līdz sistēmas kodolam un pēc tam līdz tīklam. Es smaidu: dažreiz intervijas jautājumi dzīvē noder...
Es nolemju šo HR jautājumu attiecināt uz aktuālu problēmu. Aptuveni runājot, mēģinot noteikt DNS nosaukumu, notiek šādi:
- Lietojumprogramma izsauc sistēmas bibliotēku, piemēram, libdns
- libdns pārbauda sistēmas konfigurāciju, ar kuru DNS serveri tam jāsazinās (shēmā tas ir 169.254.169.254, metadatu serveris)
- libdns izmanto sistēmas izsaukumus, lai izveidotu UDP ligzdu (SOKET_DGRAM) un nosūtītu UDP paketes ar DNS vaicājumu abos virzienos
- Izmantojot sysctl saskarni, varat konfigurēt UDP steku kodola līmenī
- Kodols mijiedarbojas ar aparatūru, lai pārsūtītu paketes tīklā, izmantojot tīkla interfeisu
- Hipervizors uztver un pārsūta paketi metadatu serverim, saskaroties ar to
- Metadatu serveris ar savu burvību nosaka DNS nosaukumu un atgriež atbildi, izmantojot to pašu metodi
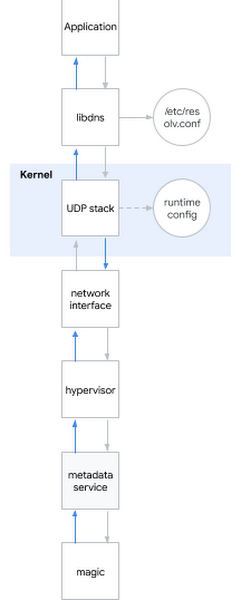
Ļaujiet man atgādināt, kādas hipotēzes mēs jau esam apsvēruši:
Hipotēze: bojātas bibliotēkas
- 1. tests: palaidiet strace sistēmā, pārbaudiet, vai dig izsauc pareizos sistēmas zvanus
- Rezultāts: tiek izsaukti pareizie sistēmas zvani
- 2. tests: izmantojiet srapy, lai pārbaudītu, vai mēs varam noteikt nosaukumus, apejot sistēmas bibliotēkas
- Rezultāts: mēs varam
- 3. tests: palaidiet rpm –V libdns pakotnē un md5sum bibliotēkas failos
- Rezultāts: bibliotēkas kods ir pilnīgi identisks kodam darba operētājsistēmā
- 4. tests: uzstādiet lietotāja saknes sistēmas attēlu virtuālajā datorā bez šīs darbības, palaidiet chroot, pārbaudiet, vai DNS darbojas
- Rezultāts: DNS darbojas pareizi
Secinājums, pamatojoties uz testiem: problēma nav bibliotēkās
Hipotēze: DNS iestatījumos ir kļūda
- 1. tests: pārbaudiet tcpdump un pārbaudiet, vai DNS paketes tiek nosūtītas un atgrieztas pareizi pēc dig palaišanas
- Rezultāts: paketes tiek pārsūtītas pareizi
- 2. tests: vēlreiz pārbaudiet serverī
/etc/nsswitch.confи/etc/resolv.conf - Rezultāts: viss ir pareizi
Secinājums, pamatojoties uz testiem: problēma nav DNS konfigurācijā
Hipotēze: serde bojāta
- Tests: instalējiet jaunu kodolu, pārbaudiet parakstu, restartējiet
- Rezultāts: līdzīga uzvedība
Secinājums, pamatojoties uz testiem: kodols nav bojāts
Hipotēze: nepareiza lietotāja tīkla (vai hipervizora tīkla interfeisa) uzvedība
- 1. pārbaude: pārbaudiet ugunsmūra iestatījumus
- Rezultāts: ugunsmūris nodod DNS paketes gan resursdatorā, gan GCP
- 2. tests: pārtveriet trafiku un uzraugiet DNS pieprasījumu pārsūtīšanas un atgriešanas pareizību
- Rezultāts: tcpdump apstiprina, ka resursdators ir saņēmis atgriešanas paketes
Secinājums, pamatojoties uz testiem: problēma nav tīklā
Hipotēze: metadatu serveris nedarbojas
- 1. tests: pārbaudiet, vai metadatu servera žurnālos nav anomāliju
- Rezultāts: žurnālos nav anomāliju
- 2. tests: apiet metadatu serveri, izmantojot
dig @8.8.8.8 - Rezultāts: izšķirtspēja ir bojāta, pat neizmantojot metadatu serveri
Secinājums, pamatojoties uz testiem: problēma nav metadatu serverī
Apakšējā līnija: mēs pārbaudījām visas apakšsistēmas, izņemot izpildlaika iestatījumi!
Iedziļināties kodola izpildlaika iestatījumos
Lai konfigurētu kodola izpildes vidi, varat izmantot komandrindas opcijas (grub) vai sysctl saskarni. Es paskatījos iekšā /etc/sysctl.conf un padomājiet, es atklāju vairākus pielāgotus iestatījumus. Sajūta, ka esmu kaut ko uztvēris, es atmetu visus iestatījumus, kas nav saistīti ar tīklu vai TCP, atstājot kalnu iestatījumus. net.core. Tad es devos uz vietu, kur virtuālajā mašīnā bija saimniekdatora atļaujas, un sāku lietot iestatījumus pa vienam, vienu pēc otra ar bojāto VM, līdz atradu vainīgo:
net.core.rmem_default = 2147483647Šeit tā ir DNS pārkāpuma konfigurācija! Es atradu slepkavības ieroci. Bet kāpēc tas notiek? Man joprojām bija vajadzīgs motīvs.
Pamata DNS pakešu bufera lielums ir konfigurēts, izmantojot net.core.rmem_default. Tipiskā vērtība ir aptuveni 200 KiB, taču, ja jūsu serveris saņem daudz DNS pakešu, iespējams, vēlēsities palielināt bufera lielumu. Ja buferis ir pilns, kad tiek saņemta jauna pakete, piemēram, tāpēc, ka lietojumprogramma to neapstrādā pietiekami ātri, jūs sāksit zaudēt paketes. Mūsu klients pareizi palielināja bufera lielumu, jo baidījās no datu zuduma, jo viņš izmantoja lietojumprogrammu metriku apkopošanai, izmantojot DNS paketes. Viņa iestatītā vērtība bija maksimālā iespējamā: 231-1 (ja iestatīta uz 231, kodols atgriezīs “INVALID ARGUMENT”).
Pēkšņi es sapratu, kāpēc nmap un scapy darbojās pareizi: viņi izmantoja neapstrādātas ligzdas! Neapstrādātas ligzdas atšķiras no parastajām ligzdām: tās apiet iptables, un tās netiek buferētas!
Bet kāpēc "buferis pārāk liels" rada problēmas? Tas acīmredzami nedarbojas, kā paredzēts.
Šajā brīdī es varētu reproducēt problēmu vairākos kodolos un vairākos izplatījumos. Problēma jau parādījās 3.x kodolā, un tagad tā parādījās arī 5.x kodolā.
Patiešām, startējot
sysctl -w net.core.rmem_default=$((2**31-1))DNS pārtrauca darbu.
Es sāku meklēt darba vērtības, izmantojot vienkāršu bināro meklēšanas algoritmu, un atklāju, ka sistēma darbojās ar 2147481343, taču šis skaitlis man bija bezjēdzīgs skaitļu kopums. Es ieteicu klientam izmēģināt šo numuru, un viņš atbildēja, ka sistēma darbojas ar google.com, taču joprojām radīja kļūdu citos domēnos, tāpēc es turpināju izmeklēšanu.
Esmu uzstādījis , rīks, kuru vajadzēja izmantot agrāk: tas precīzi parāda, kur kodolā nonāk pakete. Vainīgais bija funkcija udp_queue_rcv_skb. Es lejupielādēju kodola avotus un pievienoju dažus lai izsekotu, kur tieši pakete nonāk. Es ātri atradu pareizo stāvokli if, un kādu laiku vienkārši skatījās uz to, jo tieši tad viss beidzot sanāca veselā attēlā: 231-1, bezjēdzīgs skaitlis, nestrādājošs domēns... Tas bija koda fragments __udp_enqueue_schedule_skb:
if (rmem > (size + sk->sk_rcvbuf))
goto uncharge_drop;Lūdzu, ņemiet vērā:
rmemir tipa intsizeir u16 tipa (neparakstīts sešpadsmit bitu int) un saglabā paketes izmērusk->sk_rcybufir int tipa un saglabā bufera lielumu, kas pēc definīcijas ir vienāds ar vērtību innet.core.rmem_default
Kad sk_rcvbuf tuvojas 231, paketes lieluma summēšana var izraisīt . Un, tā kā tas ir int, tā vērtība kļūst negatīva, tāpēc nosacījums kļūst patiess, kad tam vajadzētu būt nepatiesam (vairāk par to varat lasīt vietnē ).
Kļūdu var labot triviālā veidā: ar liešanu unsigned int. Es piemēroju labojumu un restartēju sistēmu, un DNS atkal darbojās.
Uzvaras garša
Es savus atklājumus pārsūtīju klientam un nosūtīju kodola ielāps. Esmu gandarīts: katrs puzles gabals sader kopā, es varu precīzi izskaidrot, kāpēc mēs novērojām to, ko novērojām, un galvenais, ka mēs spējām atrast problēmas risinājumu, pateicoties mūsu komandas darbam!
Ir vērts atzīt, ka gadījums izrādījās rets, un par laimi mēs reti saņemam tik sarežģītus pieprasījumus no lietotājiem.
Avots: www.habr.com
