


Ir 2019. gads, un mums joprojām nav standarta risinājuma baļķu apkopošanai Kubernetes. Šajā rakstā, izmantojot piemērus no reālas prakses, mēs vēlamies dalīties ar saviem meklējumiem, sastaptajām problēmām un to risinājumiem.
Tomēr vispirms es izdarīšu atrunu, ka dažādi klienti, apkopojot žurnālus, saprot ļoti dažādas lietas:
- kāds vēlas redzēt drošības un audita žurnālus;
- kāds - centralizēta visas infrastruktūras mežizstrāde;
- un dažiem pietiek savākt tikai lietojumprogrammu žurnālus, izņemot, piemēram, balansētājus.
Tālāk ir sniegts izgriezums par to, kā mēs ieviesām dažādus “vēlmju sarakstus” un ar kādām grūtībām saskārāmies.
Teorija: par mežizstrādes rīkiem
Pamatinformācija par mežizstrādes sistēmas sastāvdaļām
Mežizstrāde ir nogājusi garu ceļu, kā rezultātā ir izstrādātas baļķu vākšanas un analīzes metodoloģijas, ko mēs izmantojam šodien. 1950. gados Fortran ieviesa standarta ievades/izvades straumju analogu, kas palīdzēja programmētājam atkļūdot savu programmu. Tie bija pirmie datoru žurnāli, kas atviegloja dzīvi to laiku programmētājiem. Šodien mēs tajās redzam pirmo reģistrēšanas sistēmas komponentu - baļķu avots vai “ražotājs”..
Datorzinātne nestāvēja uz vietas: parādījās datortīkli, pirmie klasteri... Sāka strādāt sarežģītas sistēmas, kas sastāvēja no vairākiem datoriem. Tagad sistēmas administratori bija spiesti vākt žurnālus no vairākām mašīnām, un īpašos gadījumos viņi varēja pievienot OS kodola ziņojumus, ja viņiem bija nepieciešams izmeklēt sistēmas kļūmi. Lai aprakstītu centralizētās žurnālu vākšanas sistēmas, 2000. gadu sākumā tas tika publicēts , kas standartizēja remote_syslog. Šādi parādījās vēl viens svarīgs komponents: baļķu savācējs un to uzglabāšana.
Pieaugot žurnālu apjomam un plaši ieviešot tīmekļa tehnoloģijas, radās jautājums, kādi žurnāli ir ērti jāparāda lietotājiem. Vienkāršie konsoles rīki (awk/sed/grep) ir aizstāti ar modernākiem žurnālu skatītāji - trešā sastāvdaļa.
Sakarā ar baļķu apjoma pieaugumu noskaidrojās kas cits: baļķi vajag, bet ne visus. Un dažādiem baļķiem ir nepieciešami dažādi saglabāšanas līmeņi: daži var pazust vienas dienas laikā, bet citi ir jāuzglabā 5 gadus. Tātad reģistrēšanas sistēmai tika pievienots komponents datu plūsmu filtrēšanai un maršrutēšanai - sauksim to filtrs.
Arī krātuve ir veikusi lielu lēcienu: no parastajiem failiem uz relāciju datu bāzēm un pēc tam uz dokumentiem orientētu krātuvi (piemēram, Elasticsearch). Tātad krātuve tika atdalīta no kolektora.
Galu galā pats žurnāla jēdziens ir paplašinājies līdz sava veida abstraktai notikumu plūsmai, ko mēs vēlamies saglabāt vēsturei. Vai drīzāk, ja jums ir nepieciešams veikt izmeklēšanu vai sastādīt analītisko ziņojumu...
Līdz ar to salīdzinoši īsā laika periodā žurnālu vākšana ir izveidojusies par nozīmīgu apakšsistēmu, ko pamatoti var saukt par vienu no Big Data apakšsadaļām.
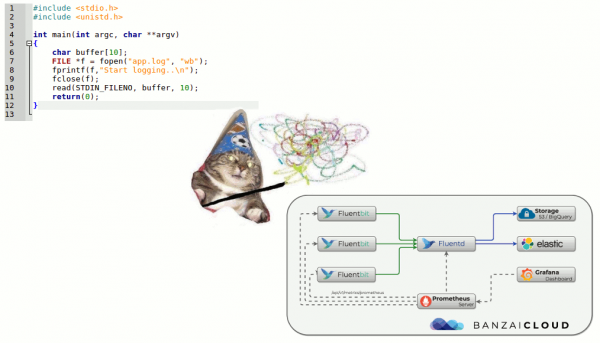
Ja kādreiz “reģistrācijas sistēmai” varēja pietikt ar parastajām izdrukām, tad tagad situācija ir daudz mainījusies.
Kubernetes un baļķi
Kad Kubernetes nonāca pie infrastruktūras, to neapgāja arī jau pastāvošā baļķu savākšanas problēma. Dažos veidos tas kļuva vēl sāpīgāks: infrastruktūras platformas pārvaldība tika ne tikai vienkāršota, bet vienlaikus arī sarežģīta. Daudzi vecie pakalpojumi ir sākuši migrēt uz mikropakalpojumiem. Žurnālu kontekstā tas izpaužas kā pieaugošais žurnālu avotu skaits, to īpašais dzīves cikls un nepieciešamība izsekot visu sistēmas komponentu attiecībām, izmantojot žurnālus...
Raugoties nākotnē, varu apgalvot, ka šobrīd diemžēl Kubernetes nav standartizētas mežizstrādes iespējas, kas būtu labvēlīgas salīdzinājumā ar citām. Vispopulārākās shēmas sabiedrībā ir šādas:
- kāds atritina kaudzi EFK (Elasticsearch, Fluentd, Kibana);
- kāds mēģina nesen izdoto vai lietojumiem ;
- mums (un varbūt ne tikai mēs?..) Esmu lielā mērā apmierināts ar savu attīstību - ...
Parasti K8s klasteros (pašmitinātiem risinājumiem) mēs izmantojam šādus komplektus:
- ;
- .
Tomēr es nekavēšos pie instrukcijām to uzstādīšanai un konfigurēšanai. Tā vietā es pievērsīšos to trūkumiem un globālākiem secinājumiem par situāciju ar baļķiem kopumā.
Prakse ar baļķiem K8s

“Ikdienas baļķi”, cik no jums tur ir?...
Centralizēta žurnālu vākšana no diezgan lielas infrastruktūras prasa ievērojamus resursus, kas tiks tērēti žurnālu vākšanai, uzglabāšanai un apstrādei. Darbojoties dažādiem projektiem, saskārāmies ar dažādām prasībām un no tām izrietošām darbības problēmām.
Izmēģināsim ClickHouse
Apskatīsim centralizētu projekta krātuvi ar lietojumprogrammu, kas diezgan aktīvi ģenerē žurnālus: vairāk nekā 5000 rindu sekundē. Sāksim strādāt ar viņa žurnāliem, pievienojot tos ClickHouse.
Tiklīdz būs nepieciešams maksimālais reāllaika laiks, 4 kodolu serveris ar ClickHouse jau būs pārslogots diska apakšsistēmā:
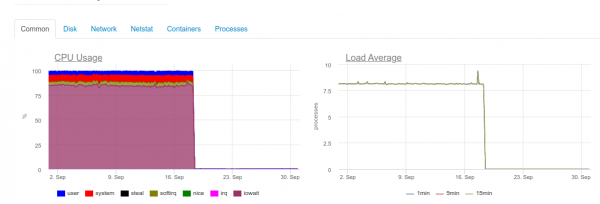
Šāda veida ielāde ir saistīta ar to, ka mēs cenšamies pēc iespējas ātrāk rakstīt ClickHouse. Un datu bāze uz to reaģē ar palielinātu diska slodzi, kas var izraisīt šādas kļūdas:
DB::Exception: Too many parts (300). Merges are processing significantly slower than inserts
Fakts ir tāds, ka programmā ClickHouse (tie satur žurnāla datus) rakstīšanas operāciju laikā ir savas grūtības. Tajos ievietotie dati ģenerē pagaidu nodalījumu, kas pēc tam tiek apvienots ar galveno tabulu. Rezultātā ieraksts diskā izrādās ļoti prasīgs, un uz to attiecas arī ierobežojums, par kuru mēs saņēmām iepriekš minēto paziņojumu: 1 sekundē var sapludināt ne vairāk kā 300 apakšsadaļas (faktiski tas ir 300 ieliktņi sekundē).
Lai izvairītos no šādas uzvedības, pēc iespējas lielākos gabalos un ne biežāk kā 1 reizi ik pēc 2 sekundēm. Tomēr rakstīšana lielos sērijās liek domāt, ka ClickHouse vajadzētu rakstīt retāk. Tas savukārt var novest pie bufera pārpildes un žurnālu zuduma. Risinājums ir palielināt Fluentd buferi, bet tad palielināsies arī atmiņas patēriņš.
Piezīme: Vēl viens problemātisks aspekts mūsu risinājumam ar ClickHouse bija saistīts ar faktu, ka sadalīšana mūsu gadījumā (guļbūves) tiek īstenota, izmantojot ārējās pievienotās tabulas. . Tas noved pie tā, ka, atlasot lielus laika intervālus, ir nepieciešams pārmērīgs RAM, jo metatabula atkārtojas caur visiem nodalījumiem - pat tiem, kuros acīmredzami nav nepieciešamo datu. Tomēr tagad šo pieeju var droši pasludināt par novecojušu pašreizējām ClickHouse versijām (c ).
Rezultātā kļūst skaidrs, ka ne katram projektam ir pietiekami daudz resursu, lai ClickHouse reāllaikā savāktu žurnālus (precīzāk, to izplatīšana nebūs piemērota). Turklāt jums būs jāizmanto akumulators, pie kura atgriezīsimies vēlāk. Iepriekš aprakstītais gadījums ir reāls. Un tobrīd nevarējām piedāvāt uzticamu un stabilu risinājumu, kas atbilstu klientam un ļautu savākt baļķus ar minimālu kavēšanos...
Kā ar Elasticsearch?
Ir zināms, ka Elasticsearch iztur lielas darba slodzes. Izmēģināsim to tajā pašā projektā. Tagad slodze izskatās šādi:
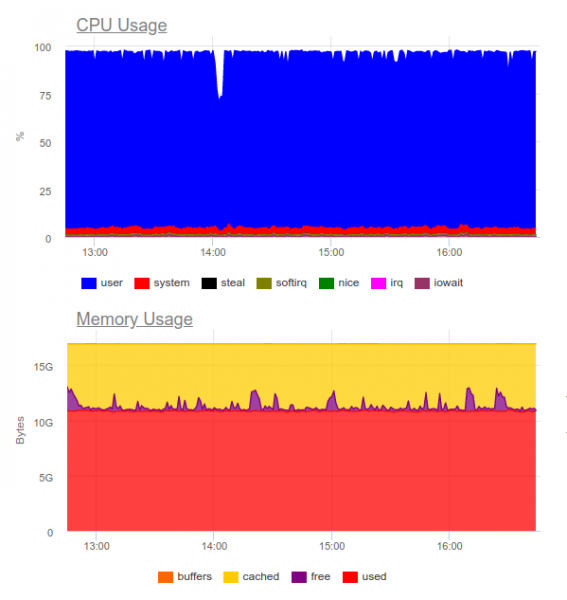
Elasticsearch spēja sagremot datu straumi, tomēr šādu apjomu ierakstīšana ievērojami izmanto centrālo procesoru. To izlemj, organizējot klasteru. Tehniski tā nav problēma, bet izrādās, ka tikai baļķu savākšanas sistēmas darbībai mēs jau izmantojam aptuveni 8 kodolus un sistēmā ir papildus ļoti noslogota komponente...
Secinājums: šī iespēja var būt pamatota, taču tikai tad, ja projekts ir liels un tā vadība ir gatava tērēt ievērojamus resursus centralizētai mežizstrādes sistēmai.
Tad rodas dabisks jautājums:
Kādi baļķi patiešām ir nepieciešami?
 Mēģināsim mainīt pašu pieeju: žurnāliem vienlaikus jābūt informatīviem, nevis aptverošiem ikviens notikums sistēmā.
Mēģināsim mainīt pašu pieeju: žurnāliem vienlaikus jābūt informatīviem, nevis aptverošiem ikviens notikums sistēmā.
Pieņemsim, ka mums ir veiksmīgs tiešsaistes veikals. Kādi žurnāli ir svarīgi? Savākt pēc iespējas vairāk informācijas, piemēram, no maksājumu vārtejas, ir lieliska ideja. Bet ne visi žurnāli no attēlu sagriešanas pakalpojuma produktu katalogā mums ir kritiski: pietiek tikai ar kļūdām un uzlaboto uzraudzību (piemēram, šī komponenta ģenerēto kļūdu procentuālā daļa no 500).
Tātad esam nonākuši pie secinājuma, ka centralizēta mežizstrāde ne vienmēr ir attaisnojama. Ļoti bieži klients vēlas apkopot visus žurnālus vienuviet, lai gan patiesībā no visa žurnāla ir nepieciešami tikai nosacīti 5% no biznesam kritiskiem ziņojumiem:
- Dažreiz pietiek konfigurēt, teiksim, tikai konteinera žurnāla izmēru un kļūdu savācēju (piemēram, Sentry).
- Negadījumu izmeklēšanai bieži vien var pietikt ar kļūdu paziņojumu un lielu lokālo žurnālu.
- Mums bija projekti, kas iztika tikai ar funkcionāliem testiem un kļūdu vākšanas sistēmām. Izstrādātājam žurnāli kā tādi nebija vajadzīgi - viņi redzēja visu, sākot no kļūdu pēdām.
Ilustrācija no dzīves
Kā labs piemērs var kalpot kāds cits stāsts. Mēs saņēmām pieprasījumu no viena mūsu klienta drošības komandas, kurš jau izmantoja komerciālu risinājumu, kas tika izstrādāts ilgi pirms Kubernetes ieviešanas.
Bija nepieciešams “sadraudzēties” ar centralizēto žurnālu vākšanas sistēmu ar korporatīvo problēmu noteikšanas sensoru - QRadar. Šī sistēma var saņemt žurnālus, izmantojot syslog protokolu, un izgūt tos no FTP. Tomēr uzreiz nebija iespējams to integrēt ar fluentd spraudni remote_syslog (kā izrādījās, ). Problēmas ar QRadar iestatīšanu izrādījās klienta drošības komandas pusē.
Rezultātā daļa biznesam būtisko žurnālu tika augšupielādēta FTP QRadar, bet otra daļa tika novirzīta, izmantojot attālo syslog tieši no mezgliem. Par to mēs pat rakstījām - varbūt tas palīdzēs kādam atrisināt līdzīgu problēmu... Pateicoties izveidotajai shēmai, klients pats saņēma un analizēja kritiskos žurnālus (izmantojot savus iecienītākos rīkus), un mēs varējām samazināt reģistrēšanas sistēmas izmaksas, ietaupot tikai pagājušajā mēnesī.
Vēl viens piemērs liecina par to, ko nevajadzētu darīt. Viens no mūsu klientiem apstrādei no katra notikumi, kas nāk no lietotāja, izveidoti vairākās rindās nestrukturēta produkcija informācija žurnālā. Kā jūs varētu nojaust, šādus žurnālus bija ārkārtīgi neērti gan lasīt, gan uzglabāt.
Kritēriji apaļkokiem
Šādi piemēri liek secināt, ka papildus baļķu savākšanas sistēmas izvēlei jums ir nepieciešams projektēt arī pašus baļķus! Kādas šeit ir prasības?
- Žurnāliem ir jābūt mašīnlasāmā formātā (piemēram, JSON).
- Žurnāliem jābūt kompaktiem un ar iespēju mainīt reģistrēšanas pakāpi, lai atkļūdotu iespējamās problēmas. Tajā pašā laikā ražošanas vidēs jums vajadzētu palaist sistēmas ar tādu reģistrēšanas līmeni kā Brīdinājums vai kļūda.
- Žurnāliem jābūt normalizētiem, tas ir, žurnāla objektā visām rindām jābūt vienādam lauka tipam.
Nestrukturēti apaļkoki var radīt problēmas ar baļķu iekraušanu noliktavā un to apstrādes pilnīgu apturēšanu. Ilustrācijai šeit ir piemērs ar kļūdu 400, ar kuru daudzi noteikti ir saskārušies fluentd žurnālos:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"
Kļūda nozīmē, ka jūs sūtāt indeksam lauku, kura veids ir nestabils, ar gatavu kartēšanu. Vienkāršākais piemērs ir lauks nginx žurnālā ar mainīgo $upstream_status. Tajā var būt gan skaitlis, gan virkne. Piemēram:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}
Žurnāli liecina, ka serveris 10.100.0.10 atbildēja ar kļūdu 404 un pieprasījums tika nosūtīts uz citu satura krātuvi. Rezultātā vērtība žurnālos kļuva šāda:
"upstream_response_time": "0.001, 0.007"
Šī situācija ir tik izplatīta, ka tā pat ir pelnījusi atsevišķu .
Kā ar uzticamību?
Ir reizes, kad visi žurnāli bez izņēmuma ir vitāli svarīgi. Un līdz ar to ir problēmas ar tipiskajām baļķu savākšanas shēmām K8s, kas ierosinātas / apspriestas iepriekš.
Piemēram, fluentd nevar savākt baļķus no īslaicīgiem konteineriem. Vienā no mūsu projektiem datu bāzes migrācijas konteiners darbojās mazāk nekā 4 sekundes un pēc tam tika dzēsts - saskaņā ar attiecīgo anotāciju:
"helm.sh/hook-delete-policy": hook-succeeded
Šī iemesla dēļ migrācijas izpildes žurnāls netika iekļauts krātuvē. Politika šajā gadījumā var palīdzēt. before-hook-creation.
Vēl viens piemērs ir Docker žurnāla rotācija. Pieņemsim, ka ir lietojumprogramma, kas aktīvi raksta žurnālos. Normālos apstākļos mums izdodas apstrādāt visus žurnālus, taču, tiklīdz parādās problēma – piemēram, kā aprakstīts iepriekš ar nepareizu formātu – apstrāde apstājas, un Docker pagriež failu. Rezultātā var tikt zaudēti biznesam svarīgi žurnāli.
Tāpēc svarīgi ir atdalīt žurnālu plūsmas, iegulstot vērtīgākos nosūtot tieši lietojumprogrammā, lai nodrošinātu to drošību. Turklāt nebūtu lieki dažus izveidot baļķu “akumulators”., kas var izturēt īslaicīgu krātuves nepieejamību, vienlaikus saglabājot svarīgus ziņojumus.
Visbeidzot, mēs nedrīkstam to aizmirst Ir svarīgi pareizi uzraudzīt jebkuru apakšsistēmu. Pretējā gadījumā ir viegli nonākt situācijā, kurā fluentd atrodas stāvoklī CrashLoopBackOff un neko nesūta, un tas sola svarīgas informācijas zaudēšanu.
Atzinumi
Šajā rakstā mēs neaplūkojam SaaS risinājumus, piemēram, Datadog. Daudzas no šeit aprakstītajām problēmām vienā vai otrā veidā jau ir atrisinājušas komercuzņēmumi, kas specializējas žurnālu vākšanā, taču ne visi dažādu iemeslu dēļ var izmantot SaaS (galvenās ir izmaksas un atbilstība 152-FZ).
Centralizēta žurnālu vākšana sākotnēji šķiet vienkāršs uzdevums, taču tā nebūt nav. Ir svarīgi atcerēties, ka:
- Detalizēti jāreģistrē tikai kritiskie komponenti, savukārt pārraudzību un kļūdu apkopošanu var konfigurēt citām sistēmām.
- Ražošanā apaļkokiem jābūt minimāliem, lai neradītu nevajadzīgu slodzi.
- Žurnāliem jābūt mašīnlasāmiem, normalizētiem un stingrā formātā.
- Tiešām kritiskie žurnāli jāsūta atsevišķā straumē, kas jānodala no galvenajiem.
- Ir vērts apsvērt baļķu akumulatoru, kas var glābt jūs no lielas slodzes uzliesmojumiem un padarīt noliktavas slodzi vienmērīgāku.

Šie vienkāršie noteikumi, ja tie tiek piemēroti visur, ļautu iepriekš aprakstītajām shēmām darboties, pat ja tām trūkst svarīgu komponentu (akumulatora). Ja jūs neievērosiet šādus principus, uzdevums jūs un infrastruktūru viegli novedīs pie citas ļoti noslogotas (un tajā pašā laikā neefektīvas) sistēmas sastāvdaļas.
PS
Lasi arī mūsu emuārā:
- «";
- «";
- «'.
Avots: www.habr.com
