

Laiku pa laikam rodas uzdevums meklēt saistītus datus, izmantojot atslēgu kopu, līdz mēs sasniedzam nepieciešamo kopējo ierakstu skaitu.
Visreālākais piemērs ir secināt 20 vecākie uzdevumi, uzskaitīti darbinieku sarakstā (Piemēram, vienas nodaļas ietvaros). Dažādiem vadības paneļiem ar īsiem darba jomu kopsavilkumiem bieži vien ir nepieciešama līdzīga tēma.

Šajā rakstā mēs apsvērsim šīs problēmas “naivā” risinājuma ieviešanu PostgreSQL, “gudrāku” un ļoti sarežģītu algoritmu. "cikls" SQL valodā ar izejas nosacījumu, kas balstīts uz atrastajiem datiem, kas var būt noderīgi gan vispārējai izstrādei, gan pielietojumam citos līdzīgos gadījumos.
Ņemsim testa datu kopu no Lai novērstu izvades ierakstu "lēkšanu" no viena laika uz otru, kad sakārtotās vērtības sakrīt, Paplašināsim subjektu indeksu, pievienojot primāro atslēgu.Tas nekavējoties padarīs to unikālu un garantēs skaidru kārtošanas secību:
CREATE INDEX ON task(owner_id, task_date, id);
-- а старый - удалим
DROP INDEX task_owner_id_task_date_idx;Tas ir uzrakstīts tā, kā izklausās.
Vispirms ieskicēsim vienkāršāko pieprasījuma versiju, nododot izpildītāju ID. :
SELECT
*
FROM
task
WHERE
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
ORDER BY
task_date, id
LIMIT 20; 
Tas ir mazliet skumji — mēs pasūtījām tikai 20 ierakstus, un Index Scan tos mums atgrieza. 960 līnijas, kas tad bija jāsakārto... Centīsimies lasīt mazāk.
nenest + MASSĪVS
Pirmais apsvērums, kas mums palīdzēs, ir tas, vai mums ir nepieciešams tikai 20 sakārtoti ierakstus, tad pietiek izlasīt ne vairāk kā 20, sakārtoti vienā secībā katram atslēga. Par laimi, piemērots indekss (īpašnieka_id, uzdevuma_datums, ID) mums ir.
Izmantosim to pašu ekstrakcijas un "atklāšanas kolonnās" mehānismu. integrālas tabulas ieraksts, kā tas ir Mēs arī pielietosim locīšanu masīvā, izmantojot funkciju ARRAY():
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 -- ограничиваем тут...
)) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; -- ... и тут - тоже 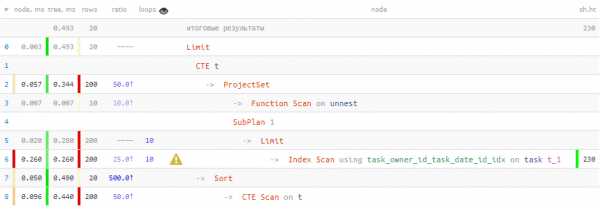
Ak, tas ir daudz labāk! Par 40 % ātrāk un 4.5 reizes mazāk datu Man tas bija jāizlasa.
Tabulas ierakstu materializācija, izmantojot CTEEs vēlētos vērst jūsu uzmanību uz to, ka dažos gadījumos Mēģinājums strādāt ar ierakstu laukiem tūlīt pēc to meklēšanas apakšvaicājumā, tos "neietverot" CTE, var novest pie InitPlan "reizināšana" proporcionāli šo pašu lauku skaitam:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1)
Buffers: shared hit=16
InitPlan 1 (returns $0)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 2 (returns $1)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 3 (returns $2)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4"
InitPlan 4 (returns $3)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
Viens un tas pats ieraksts tika "meklēts" 4 reizes... Līdz PostgreSQL 11 šāda problēma tika novērota regulāri, un risinājums bija to "ietīt" CTE, kas ir absolūts optimizētāja ierobežojums šajās versijās.
Rekursīvs akumulators
Iepriekšējā versijā mēs lasījām kopā 200 līnijas nepieciešamo 20 dēļ. Vairs ne 960, bet vēl mazāk - vai tas ir iespējams?
Mēģināsim izmantot nepieciešamās zināšanas kopā xnumx ieraksti. Tas ir, mēs atkārtosim datu nolasīšanu, līdz sasniegsim nepieciešamo skaitu.
1. darbība: sākuma saraksts
Acīmredzot mūsu "mērķa" 20 ierakstu sarakstam jāsākas ar "pirmajiem" ierakstiem vienai no mūsu owner_id atslēgām. Tātad, vispirms atradīsim tos "pats pirmais" katrai no atslēgām un pievienojiet to sarakstam, sakārtojot to vēlamajā secībā — (uzdevuma_datums, ID).
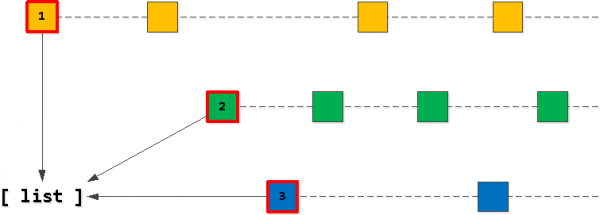
2. darbība. Atrodiet "nākamos" ierakstus
Tagad, ja mēs ņemam pirmo ierakstu no mūsu saraksta un sākam "solis" tālāk pa indeksu saglabājot atslēgu owner_id, visi atrastie ieraksti ir tieši nākamie iegūtajā atlasē. Protams, tikai līdz mēs šķērsojam pielietoto atslēgu otrais ieraksts sarakstā.
Ja izrādās, ka mēs "šķērsojām" otro ierakstu, tad sarakstam jāpievieno pēdējais nolasītais ieraksts, nevis pirmais (ar to pašu īpašnieka ID), pēc kura mēs vēlreiz pārkārtojam sarakstu.
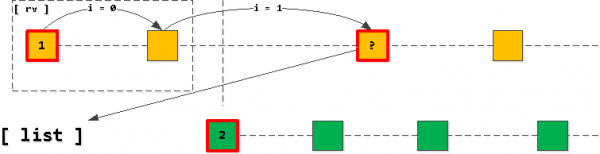
Tas ir, mēs vienmēr nonākam pie tā, ka sarakstā ir ne vairāk kā viens ieraksts katrai atslēgai (ja ieraksti beidzas un mēs tos neesam "pārsvītrojuši", tad pirmais ieraksts vienkārši pazudīs no saraksta un nekas netiks pievienots), un tie vienmēr sakārtots lietojumprogrammas atslēgas augošā secībā (task_date, id).
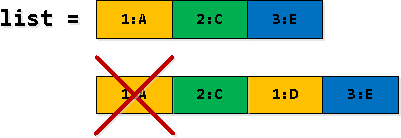
3. darbība. Ierakstu filtrēšana un izvēršana
Dažās mūsu rekursīvās atlases rindās daži ieraksti rv Dublikātu ieraksti — vispirms atrodam tādus ierakstus kā "šķērso otrā ieraksta robežu sarakstā" un pēc tam tos aizstājam ar pirmo ierakstu sarakstā. Tātad pirmais gadījums ir jāizfiltrē.
Baidītais pēdējais jautājums
WITH RECURSIVE T AS (
-- #1 : заносим в список "первые" записи по каждому из ключей набора
WITH wrap AS ( -- "материализуем" record'ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list -- сортируем список в нужном порядке
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
-- #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го
SELECT
CASE
-- если ничего не найдено для ключа 1-й записи
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] -- убираем ее из списка
-- если мы НЕ пересекли прикладной ключ 2-й записи
WHEN X.not_cross THEN
T.list -- просто протягиваем тот же список без модификаций
-- если в списке уже нет 2-й записи
WHEN T.list[2] IS NULL THEN
-- просто возвращаем пустой список
'{}'
-- пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}')
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( -- "материализуем" record
SELECT
CASE
-- если все-таки "перешагнули" через 2-ю запись
WHEN NOT T.not_cross
-- то нужная запись - первая из спписка
THEN T.list[1]
ELSE ( -- если не пересекли, то ключ остался как в предыдущей записи - отталкиваемся от нее
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
-- если 2-й записи уже нет в списке, но мы хоть что-то нашли
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE -- ничего не нашли или "перешагнули"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND -- ограничиваем тут количество
T.list IS DISTINCT FROM '{}' -- или пока список не кончился
)
-- #3 : "разворачиваем" записи - порядок гарантирован по построению
SELECT
(rv).*
FROM
T
WHERE
not_cross; -- берем только "непересекающие" записи 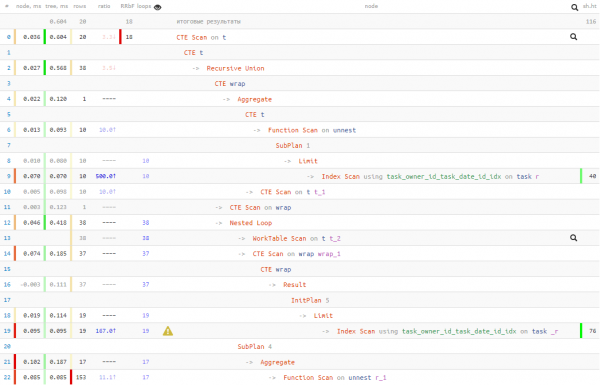
Tādējādi mēs 20% izpildes laika tika tirgoti 50% datu nolasījumuTas ir, ja jums ir pamats uzskatīt, ka lasīšana varētu būt lēna (piemēram, dati bieži vien neatrodas kešatmiņā un tie ir jāizgūst no diska), tad šī metode var samazināt jūsu atkarību no lasīšanas.
Jebkurā gadījumā izpildes laiks bija labāks nekā ar "naivo" pirmo variantu. Bet kuru no šīm trim iespējām izmantot, ir jūsu ziņā.
Avots: www.habr.com
