

Pāvels Seļivanovs, Southbridge risinājumu arhitekts un Slurm skolotājs, uzstājās ar prezentāciju DevOpsConf 2019. Šī runa ir daļa no vienas no Kubernetes padziļinātā kursa tēmām “Slurm Mega”.
notiek Maskavā 18.-20.novembrī.
— Maskava, 22.-24.novembris.
vienmēr pieejams.

Zem griezuma ir ziņojuma atšifrējums.
Labdien, kolēģi un tie, kas viņiem jūt līdzi. Šodien es runāšu par drošību.
Es redzu, ka šodien zālē ir daudz apsargu. Jau iepriekš atvainojos, ja lietoju terminus no drošības pasaules ne gluži tā, kā jums ir ierasts.
Tā sagadījās, ka pirms apmēram pusgada es uzgāju vienu publisku Kubernetes klasteru. Publisks nozīmē, ka ir n-tais nosaukumvietu skaits; šajās nosaukumvietās ir izolēti lietotāji savā nosaukumvietā. Visi šie lietotāji pieder dažādiem uzņēmumiem. Tika pieņemts, ka šis klasteris ir jāizmanto kā CDN. Tas nozīmē, ka viņi dod jums kopu, viņi tur dod lietotāju, jūs dodaties tur uz savu vārdu telpu, izvietojat savas frontes.
Mans iepriekšējais uzņēmums mēģināja pārdot šādu pakalpojumu. Un man palūdza iedurt klasteru, lai redzētu, vai šis risinājums ir piemērots vai nē.
Es nonācu šajā klasterī. Man tika dotas ierobežotas tiesības, ierobežota vārdu telpa. Tur esošie puiši saprata, kas ir drošība. Viņi lasīja par lomām balstītu piekļuves kontroli (RBAC) pakalpojumā Kubernetes — un viņi to izmainīja tā, lai es nevarētu palaist podziņus atsevišķi no izvietošanas. Es neatceros problēmu, kuru mēģināju atrisināt, palaižot podziņu bez izvietošanas, taču es patiešām vēlējos palaist tikai podziņu. Lai veicas, es nolēmu redzēt, kādas tiesības man ir klasterī, ko es varu darīt, ko es nevaru darīt un ko viņi tur ir sagrābuši. Tajā pašā laikā es jums pastāstīšu, ko viņi ir nepareizi konfigurējuši RBAC.
Sagadījās, ka divu minūšu laikā es saņēmu viņu klastera administratoru, apskatīju visas blakus esošās nosaukumvietas, ieraudzīju tur strādājošās ražošanas frontes uzņēmumiem, kuri jau bija iegādājušies pakalpojumu un izvietojuši to. Es tik tikko varēju atturēties no kāda priekšgala un galvenajā lapā ievietot kādu lamuvārdu.
Ar piemēriem pastāstīšu, kā es to izdarīju un kā no tā sevi pasargāt.
Bet vispirms ļaujiet man iepazīstināt ar sevi. Mani sauc Pāvels Seļivanovs. Es esmu Sautbridžas arhitekts. Es saprotu Kubernetes, DevOps un visādas smalkas lietas. Sautbridžas inženieri un es to visu veidojam, un es konsultēju.
Papildus mūsu galvenajām aktivitātēm nesen esam uzsākuši projektus ar nosaukumu Slurms. Mēs cenšamies savu prasmi strādāt ar Kubernetes nedaudz nest masās, mācīt arī citus cilvēkus strādāt ar K8.
Par ko es šodien runāšu? Ziņojuma tēma ir acīmredzama - par Kubernetes klastera drošību. Bet es gribu uzreiz pateikt, ka šī tēma ir ļoti liela - un tāpēc es gribu nekavējoties precizēt, par ko es noteikti nerunāšu. Es nerunāšu par uzlauztiem terminiem, kas jau simts reizes izmantoti internetā. Visa veida RBAC un sertifikāti.
Es runāšu par to, kas mani un manus kolēģus sāpina par drošību Kubernetes klasterī. Mēs redzam šīs problēmas gan starp pakalpojumu sniedzējiem, kas nodrošina Kubernetes klasterus, gan starp klientiem, kas vēršas pie mums. Un pat no klientiem, kuri pie mums ierodas no citām konsultāciju admin kompānijām. Tas ir, traģēdijas mērogs patiesībā ir ļoti liels.
Burtiski ir trīs punkti, par kuriem es šodien runāšu:
- Lietotāja tiesības pret pod tiesībām. Lietotāja tiesības un pod tiesības nav viens un tas pats.
- Informācijas vākšana par klasteru. Es parādīšu, ka jūs varat savākt visu nepieciešamo informāciju no klastera bez īpašām tiesībām šajā klasterī.
- DoS uzbrukums klasterim. Ja mēs nevaram apkopot informāciju, mēs jebkurā gadījumā varēsim ievietot klasteri. Es runāšu par DoS uzbrukumiem klasteru vadības elementiem.
Vēl viena vispārīga lieta, ko pieminēšu, ir tas, uz ko es šo visu testēju, uz kā es noteikti varu teikt, ka tas viss darbojas.
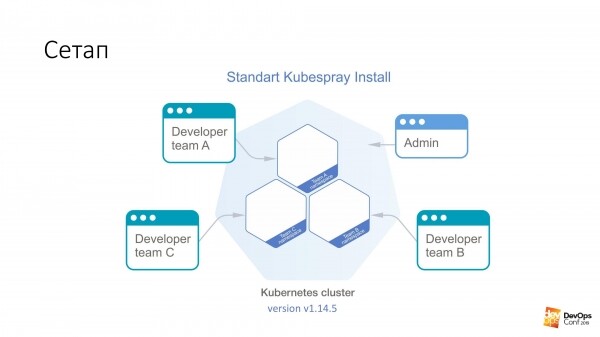
Par pamatu ņemam Kubernetes klastera uzstādīšanu, izmantojot Kubespray. Ja kāds nezina, tas patiesībā ir Ansible lomu kopums. Mēs to pastāvīgi izmantojam savā darbā. Labā lieta ir tā, ka to var ripināt jebkur - var uzrullēt uz dzelzs gabaliņiem vai kaut kur mākonī. Viena instalēšanas metode principā darbojas visam.
Šajā klasterī man būs Kubernetes v1.14.5. Viss Cube klasteris, kuru mēs apsvērsim, ir sadalīts nosaukumvietās, katra nosaukumvieta pieder atsevišķai komandai, un šīs komandas locekļiem ir piekļuve katrai nosaukumvietai. Viņi nevar doties uz dažādām nosaukumu telpām, tikai uz savu. Bet ir noteikts administratora konts, kuram ir tiesības uz visu klasteru.
Es apsolīju, ka pirmā lieta, ko mēs darīsim, ir iegūt klastera administratora tiesības. Mums ir nepieciešams speciāli sagatavots pods, kas pārtrauks Kubernetes kopu. Viss, kas mums jādara, ir jāpiemēro Kubernetes klasterim.
kubectl apply -f pod.yamlŠis pods nonāks pie viena no Kubernetes klastera meistariem. Un pēc tam klasteris ar prieku atgriezīs mums failu ar nosaukumu admin.conf. Programmā Cube šis fails saglabā visus administratora sertifikātus un vienlaikus konfigurē klastera API. Tādā veidā ir viegli iegūt administratora piekļuvi, manuprāt, 98% Kubernetes klasteru.
Es atkārtoju, ka šo aplikumu izveidoja viens jūsu klastera izstrādātājs, kuram ir piekļuve, lai izvietotu savus priekšlikumus vienā mazā nosaukumvietā. To visu ierobežo RBAC. Viņam nebija tiesību. Bet tomēr sertifikāts tika atgriezts.
Tagad parunāsim par speciāli sagatavotu podu. Mēs to varam palaist ar jebkuru attēlu. Ņemsim šo kā piemēru. debian:Džesija.
Mums ir šī lieta:
tolerations:
- effect: NoSchedule
operator: Exists
nodeSelector:
node-role.kubernetes.io/master: "" Kas ir tolerance? Kubernetes klastera meistari parasti tiek apzīmēti ar kaut ko, ko sauc par piesārņojumu. Un šīs “infekcijas” būtība ir tāda, ka pākstis nevar piešķirt galvenajiem mezgliem. Bet neviens neuztraucas nevienā pākstī norādīt, ka tas ir tolerants pret "infekciju". Sadaļā Pielaide tikai teikts, ka, ja kādam mezglam ir NoSchedule, tad mūsu mezgls ir izturīgs pret šādu infekciju - un nekādu problēmu.
Tālāk mēs sakām, ka mūsu apakšdaļa ir ne tikai iecietīga, bet arī vēlas īpaši mērķēt uz meistaru. Jo meistariem ir visgaršīgākais, kas mums vajadzīgs - visi sertifikāti. Tāpēc mēs sakām nodeSelector — un mums ir standarta uzlīme uz galvenajām ierīcēm, kas ļauj no visiem klastera mezgliem atlasīt tieši tos mezglus, kas ir galvenie.
Ar šīm divām sekcijām viņš noteikti tiks pie meistara. Un viņam atļaus tur dzīvot.
Bet ar atnākšanu pie meistara mums nepietiek. Tas mums neko nedos. Tālāk mums ir šīs divas lietas:
hostNetwork: true
hostPID: true Mēs norādām, ka mūsu pods, kuru mēs palaižam, atradīsies kodola nosaukumvietā, tīkla nosaukumvietā un PID nosaukumvietā. Kad pods tiks palaists galvenajā ierīcē, tas varēs redzēt visas šī mezgla reālās, dzīvās saskarnes, klausīties visu trafiku un redzēt visu procesu PID.
Tad runa ir par sīkumiem. Paņem etcd un lasi ko gribi.
Interesantākā lieta ir šī Kubernetes funkcija, kas tur ir pieejama pēc noklusējuma.
volumeMounts:
- mountPath: /host
name: host
volumes:
- hostPath:
path: /
type: Directory
name: host Un tā būtība ir tāda, ka mēs varam teikt, ka mēs palaižam pat bez tiesībām uz šo klasteru, ka mēs vēlamies izveidot hostPath tipa sējumu. Tas nozīmē izvēlēties ceļu no saimniekdatora, kurā tiks palaists, un pieņemt to kā apjomu. Un tad mēs to saucam par nosaukumu: saimnieks. Mēs uzstādām visu šo saimniekdatora ceļu podā. Šajā piemērā uz /host direktoriju.
Es to atkārtošu vēlreiz. Mēs likām podam nākt pie galvenā, iegūt resursdatora tīklu un resursdatora PID tur — un šajā podā ievietojiet visu galvenās ierīces sakni.
Jūs saprotat, ka Debian mums darbojas bash, un šis bash darbojas zem saknes. Tas ir, mēs tikko saņēmām root uz galvenā, bez jebkādām tiesībām Kubernetes klasterī.
Tad viss uzdevums ir doties uz apakšdirektoriju /host /etc/kubernetes/pki, ja nemaldos, paņemt tur visus klastera galvenos sertifikātus un attiecīgi kļūt par klastera administratoru.
Ja paskatās šādi, šīs ir dažas no visbīstamākajām tiesībām aplikumos — neatkarīgi no lietotāja tiesībām:
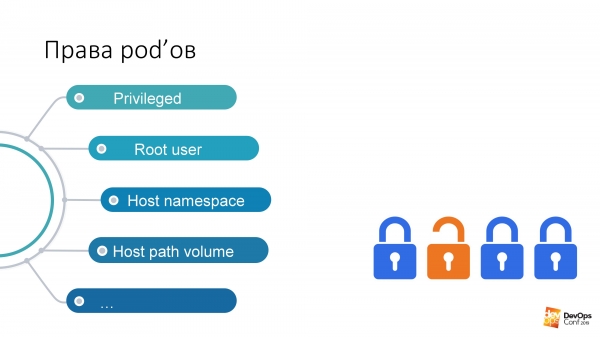
Ja man ir tiesības palaist podziņu kādā klastera nosaukumvietā, tad šim podam ir šīs tiesības pēc noklusējuma. Es varu palaist priviliģētus apvidus, un tas parasti ir visas tiesības, praktiski saknes mezglā.
Mans mīļākais ir Root lietotājs. Un Kubernetes ir šī opcija Run As Non-Root. Tas ir aizsardzības veids pret hakeriem. Vai jūs zināt, kas ir "Moldāvijas vīruss"? Ja jūs pēkšņi esat hakeris un nonākat pie mana Kubernetes klastera, tad mēs, nabaga administratori, lūdzam: “Lūdzu, norādiet savos podiņos, ar kuriem jūs uzlauzīsit manu klasteru, palaist kā ne-root. Pretējā gadījumā jūs palaidīsit procesu savā podā zem saknes, un jums būs ļoti viegli mani uzlauzt. Lūdzu, pasargā sevi no sevis."
Resursdatora ceļa apjoms, manuprāt, ir ātrākais veids, kā iegūt vēlamo rezultātu no Kubernetes klastera.
Bet ko ar to visu iesākt?
Ikvienam normālam administratoram, kurš sastopas ar Kubernetes, jādomā: “Jā, es jums teicu, Kubernetes nedarbojas. Tajā ir caurumi. Un viss Kubs ir muļķības. Patiesībā ir tāda lieta kā dokumentācija, un, ja paskatās, tad ir sadaļa .
Šis ir yaml objekts — mēs to varam izveidot Kubernetes klasterī —, kas kontrolē drošības aspektus īpaši aprakstā. Tas nozīmē, ka faktiski tā kontrolē tiesības izmantot jebkuru resursdatora tīklu, resursdatora PID, noteiktus skaļuma veidus, kas startēšanas laikā atrodas podiņos. Ar Pod drošības politikas palīdzību to visu var aprakstīt.
Pod drošības politikas interesantākā lieta ir tāda, ka Kubernetes klasterī visi PSP instalētāji nav vienkārši aprakstīti nekādā veidā, tie vienkārši ir atspējoti pēc noklusējuma. Pod drošības politika ir iespējota, izmantojot uzņemšanas spraudni.
Labi, izvietosim klasterī Pod drošības politiku, pieņemsim, ka mums ir daži pakalpojumu podi nosaukumvietā, kuriem var piekļūt tikai administratori. Teiksim, visos citos gadījumos pākstīm ir ierobežotas tiesības. Tā kā, visticamāk, izstrādātājiem nav nepieciešams jūsu klasterī palaist priviliģētus aplikācijas.
Un šķiet, ka ar mums viss ir kārtībā. Un mūsu Kubernetes klasteru nevar uzlauzt divās minūtēs.
Ir problēma. Visticamāk, ja jums ir Kubernetes klasteris, jūsu klasterī ir instalēta uzraudzība. Es pat varētu paredzēt, ka, ja jūsu klasterim ir monitorings, to sauks par Prometeju.
Tas, ko es jums pastāstīšu, būs spēkā gan Prometheus operatoram, gan Prometheus, kas tiek piegādāts tīrā veidā. Jautājums ir tāds, ka, ja es nevaru tik ātri dabūt klasterī administratoru, tas nozīmē, ka man ir jāmeklē vairāk. Un es varu meklēt ar jūsu uzraudzības palīdzību.
Droši vien visi lasa vienus un tos pašus rakstus par Habré, un monitorings atrodas monitoringa nosaukumvietā. Stūres diagrammu visiem sauc aptuveni vienādi. Es domāju, ka, ja jūs instalējat stable/prometheus, jūs saņemsit aptuveni tādus pašus nosaukumus. Un, visticamāk, man pat nevajadzēs uzminēt DNS nosaukumu jūsu klasterī. Jo tas ir standarts.
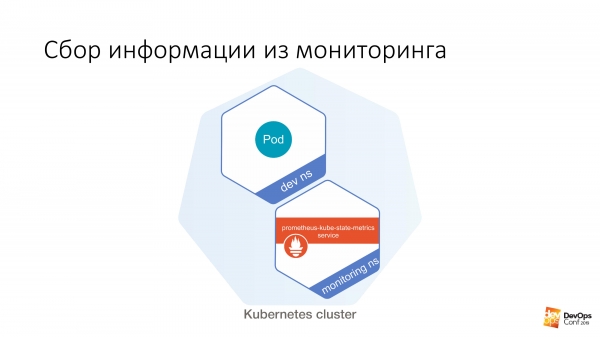
Tālāk mums ir noteikts dev ns, kurā varat palaist noteiktu pod. Un tad no šī podiņa ir ļoti viegli izdarīt kaut ko līdzīgu:
$ curl http://prometheus-kube-state-metrics.monitoring prometheus-kube-state-metrics ir viens no Prometheus eksportētājiem, kas apkopo metriku no pašas Kubernetes API. Tur ir daudz datu, kas darbojas jūsu klasterī, kas tas ir, kādas problēmas jums ir ar to.
Kā vienkāršs piemērs:
kube_pod_container_info{namespace=“kube-system”,pod=”kube-apiserver-k8s- 1″,container=”kube-apiserver”,image=
"gcr.io/google-containers/kube-apiserver:v1.14.5"
,image_id=»docker-pullable://gcr.io/google-containers/kube- apiserver@sha256:e29561119a52adad9edc72bfe0e7fcab308501313b09bf99df4a96 38ee634989″,container_id=»docker://7cbe7b1fea33f811fdd8f7e0e079191110268f2 853397d7daf08e72c22d3cf8b»} 1
Veicot vienkāršu čokurošanās pieprasījumu no nepiederošas ierīces, varat iegūt šādu informāciju. Ja nezināt, kuru Kubernetes versiju izmantojat, tas jums viegli pateiks.
Un pats interesantākais ir tas, ka papildus kube-state-metrics piekļuvei jūs varat tikpat viegli piekļūt arī pašam Prometheus. No turienes varat apkopot metriku. Jūs pat varat izveidot metriku no turienes. Pat teorētiski jūs varat izveidot šādu vaicājumu no Prometheus klastera, kas to vienkārši izslēgs. Un jūsu uzraudzība pārtrauks darboties no kopas.
Un šeit rodas jautājums, vai kāds ārējs monitorings uzrauga jūsu uzraudzību. Es tikko saņēmu iespēju darboties Kubernetes klasterī bez jebkādām sekām sev. Jūs pat nezināsiet, ka es tur darbojos, jo vairs nav nekādas uzraudzības.
Tāpat kā ar PSP, šķiet, ka problēma ir tajā, ka visas šīs smalkās tehnoloģijas - Kubernetes, Prometheus - tās vienkārši nedarbojas un ir pilnas ar caurumiem. Ne īsti.
Ir tāda lieta - .
Ja esat parasts administrators, tad, visticamāk, jūs zināt par tīkla politiku, ka tas ir tikai vēl viens yaml, kuru klasterī jau ir daudz. Un dažas tīkla politikas noteikti nav vajadzīgas. Un pat ja jūs izlasāt, kas ir tīkla politika, ka tas ir Kubernetes yaml ugunsmūris, tas ļauj ierobežot piekļuves tiesības starp nosaukumvietām, starp podiem, tad jūs noteikti nolēmāt, ka Kubernetes ugunsmūris yaml formātā ir balstīts uz nākamajām abstrakcijām. ... Nē, nē. Tas noteikti nav nepieciešams.
Pat ja neesat teicis saviem drošības speciālistiem, ka, izmantojot savu Kubernetes, varat izveidot ļoti vienkāršu un vienkāršu ugunsmūri, turklāt ļoti detalizētu. Ja viņi to vēl nezina un jūs netraucē: “Nu, dod man, dod man...” Tad jebkurā gadījumā jums ir nepieciešama tīkla politika, lai bloķētu piekļuvi dažām pakalpojumu vietām, kuras var izņemt no jūsu klastera. bez jebkādas atļaujas.
Tāpat kā manis sniegtajā piemērā, varat iegūt kube stāvokļa metriku no jebkuras Kubernetes klastera nosaukumvietas bez jebkādām tiesībām to darīt. Tīkla politikām ir slēgta piekļuve no visām pārējām nosaukumvietām pārraudzības nosaukumvietai, un tas arī viss: nav piekļuves, nav problēmu. Visās esošajās diagrammās, gan standarta Prometheus, gan Prometheus, kas atrodas operatorā, stūres vērtībās ir vienkārši iespēja tiem vienkārši iespējot tīkla politikas. Jums tas vienkārši jāieslēdz, un tie darbosies.
Šeit patiešām ir viena problēma. Būdams parasts bārdains administrators, jūs, visticamāk, nolēmāt, ka tīkla politikas nav vajadzīgas. Un pēc visu veidu rakstu lasīšanas par resursiem, piemēram, Habr, jūs nolēmāt, ka flanelis, īpaši ar saimniekdatora vārtejas režīmu, ir labākā lieta, ko varat izvēlēties.
Ko darīt?
Varat mēģināt pārizvietot Kubernetes klasterī esošo tīkla risinājumu, mēģināt aizstāt to ar kaut ko funkcionālāku. Par to pašu Calico, piemēram. Bet es gribu uzreiz teikt, ka uzdevums mainīt tīkla risinājumu Kubernetes darba klasterī ir diezgan nenozīmīgs. Divreiz atrisināju (abas reizes gan teorētiski), bet Slurmā pat parādījām, kā to izdarīt. Mūsu studentiem mēs parādījām, kā mainīt tīkla risinājumu Kubernetes klasterī. Principā varat mēģināt pārliecināties, ka ražošanas klasterī nav dīkstāves. Bet, visticamāk, jums tas neizdosies.
Un problēma patiesībā tiek atrisināta ļoti vienkārši. Klasterī ir sertifikāti, un jūs zināt, ka jūsu sertifikāti beigsies pēc gada. Nu, un parasti parasts risinājums ar sertifikātiem klasterī - kāpēc mēs uztraucamies, celsim blakus jaunu klasteri, ļausim vecajam sapuvāt un visu pārkārtosim. Tiesa, kad tas sapuvis, mums būs jāpasēž viena diena, bet šeit ir jauns klasteris.
Paceļot jaunu kopu, tajā pašā laikā flaneļa vietā ievietojiet Calico.
Ko darīt, ja jūsu sertifikāti tiek izsniegti uz simts gadiem un jūs neplānojat pārdalīt klasteru? Ir tāda lieta kā Kube-RBAC-Proxy. Šī ir ļoti forša izstrāde, kas ļauj iegult sevi kā blakusvāģa konteineru jebkurā Kubernetes klastera podā. Un tas faktiski pievieno atļauju šim podam, izmantojot paša Kubernetes RBAC.
Ir viena problēma. Iepriekš šis Kube-RBAC-Proxy risinājums tika iebūvēts operatora Prometheus. Bet tad viņš bija prom. Tagad modernās versijas paļaujas uz to, ka jums ir tīkla politika, un aizveriet to, izmantojot tās. Un tāpēc mums diagramma būs nedaudz jāpārraksta. Patiesībā, ja jūs dodaties uz , ir piemēri, kā to izmantot kā blakusvāģus, un diagrammas būs minimāli jāpārraksta.
Ir vēl viena neliela problēma. Prometejs nav vienīgais, kas izsniedz savus rādītājus ikvienam. Visi mūsu Kubernetes klastera komponenti var arī atgriezt savus rādītājus.
Bet, kā jau teicu, ja nevarat piekļūt klasterim un apkopot informāciju, varat vismaz nodarīt kaitējumu.
Tāpēc es ātri parādīšu divus veidus, kā var sabojāt Kubernetes kopu.
Jūs smiesieties, kad es jums to pateikšu, šie ir divi reāli dzīves gadījumi.
Pirmā metode. Resursu izsīkšana.
Palaidīsim vēl vienu īpašu podiņu. Tam būs šāda sadaļa.
resources:
requests:
cpu: 4
memory: 4Gi Kā jūs zināt, pieprasījumi ir CPU un atmiņas apjoms, kas resursdatorā ir rezervēts konkrētiem podiem ar pieprasījumiem. Ja mums ir četru kodolu resursdators Kubernetes klasterī un četri CPU podi tur ierodas ar pieprasījumiem, tas nozīmē, ka šim resursdatoram vairs nevarēs nonākt neviens pods ar pieprasījumiem.
Ja es palaižu šādu podziņu, es izpildīšu komandu:
$ kubectl scale special-pod --replicas=...Tad neviens cits nevarēs izvietot Kubernetes klasterī. Jo visiem mezgliem beigsies pieprasījumi. Un tādējādi es apturēšu jūsu Kubernetes kopu. Ja es to daru vakarā, es varu apturēt izvietošanu diezgan ilgu laiku.
Ja mēs vēlreiz paskatīsimies uz Kubernetes dokumentāciju, mēs redzēsim šo lietu, ko sauc par Limit Range. Tas nosaka resursus klasteru objektiem. Jūs varat uzrakstīt Limit Range objektu yaml, lietot to noteiktām nosaukumvietām - un tad šajā nosaukumvietā varat teikt, ka jums ir noklusējuma, maksimālie un minimālie resursi podiem.
Ar šādas lietas palīdzību mēs varam ierobežot lietotājus konkrētās komandu produktu nosaukumvietās, lai savos aplikumos norādītu visa veida nepatīkamas lietas. Bet diemžēl, pat ja jūs sakāt lietotājam, ka viņš nevar palaist aplikumus ar pieprasījumiem vairāk nekā vienam CPU, ir tik brīnišķīga mēroga komanda, vai arī viņi var veikt mērogošanu, izmantojot informācijas paneli.
Un šeit nāk metode numur divi. Mēs izlaižam 11 111 111 111 111 pākstis. Tie ir vienpadsmit miljardi. Tas nav tāpēc, ka es izdomāju šādu numuru, bet gan tāpēc, ka es pats to redzēju.
Īsts stāsts. Vēlu vakarā grasījos iziet no biroja. Es redzu kaktā sēžam izstrādātāju grupu un izmisīgi kaut ko dara ar saviem klēpjdatoriem. Es piegāju pie puišiem un jautāju: "Kas ar jums noticis?"
Nedaudz agrāk, ap deviņiem vakarā, viens no izstrādātājiem gatavojās doties mājās. Un es nolēmu: "Tagad es samazināšu savu pieteikumu līdz vienam." Nospiedu vienu, bet internets nedaudz palēninājās. Viņš vēlreiz nospieda vienu, viņš nospieda vienu un noklikšķināja uz Enter. Es bakstīju uz visu, ko varēju. Tad atdzīvojās internets – un viss sāka samazināties līdz šim skaitlim.
Tiesa, šis stāsts nenotika Kubernetes, tajā laikā tas bija Nomad. Tas beidzās ar faktu, ka pēc stundas mūsu mēģinājumiem apturēt Nomad no neatlaidīgiem mērogošanas mēģinājumiem Nomads atbildēja, ka viņš nepārtrauks mērogošanu un nedarīs neko citu. "Esmu noguris, es dodos prom." Un viņš saritinājās.
Protams, es mēģināju to darīt arī Kubernetes. Kubernetess nebija apmierināts ar vienpadsmit miljardiem pākstīm, viņš teica: “Es nevaru. Pārsniedz iekšējos mutes aizsargus." Bet 1 000 000 000 pākstis varētu.
Atbildot uz vienu miljardu, Kubs neatkāpās sevī. Viņš patiešām sāka mērogot. Jo tālāk process gāja, jo vairāk laika viņam prasīja jaunu pākstīm. Bet tomēr process turpinājās. Vienīgā problēma ir tā, ka, ja es varu neierobežoti palaist podus savā nosaukumvietā, tad pat bez pieprasījumiem un ierobežojumiem es varu palaist tik daudz podiņu ar dažiem uzdevumiem, ka ar šo uzdevumu palīdzību mezgli sāks pievienoties atmiņā, CPU. Kad es palaižu tik daudz podziņu, informācijai no tiem vajadzētu nonākt krātuvē, tas ir, utt. Un, kad tur nonāk pārāk daudz informācijas, krātuve sāk atgriezties pārāk lēni - un Kubernetes sāk kļūt blāvi.
Un vēl viena problēma... Kā zināms, Kubernetes vadības elementi nav viena centrālā lieta, bet vairākas sastāvdaļas. Jo īpaši ir kontroliera pārvaldnieks, plānotājs un tā tālāk. Visi šie puiši vienlaikus sāks darīt nevajadzīgu, stulbu darbu, kas laika gaitā sāks aizņemt arvien vairāk laika. Kontroliera pārvaldnieks izveidos jaunus aplikumus. Plānotājs mēģinās viņiem atrast jaunu mezglu. Visticamāk, drīz jūsu klasterī beigsies jauni mezgli. Kubernetes klasteris sāks strādāt arvien lēnāk.
Bet es nolēmu iet vēl tālāk. Kā zināms, Kubernetes ir tāda lieta, ko sauc par servisu. Nu, pēc noklusējuma jūsu klasteros, visticamāk, pakalpojums darbojas, izmantojot IP tabulas.
Ja palaižat, piemēram, vienu miljardu aplikumu un pēc tam izmantojat skriptu, lai piespiestu Kubernetis izveidot jaunus pakalpojumus:
for i in {1..1111111}; do
kubectl expose deployment test --port 80
--overrides="{"apiVersion": "v1",
"metadata": {"name": "nginx$i"}}";
done Visos klastera mezglos aptuveni vienlaicīgi tiks ģenerēti arvien vairāk jaunu iptables noteikumu. Turklāt katram pakalpojumam tiks ģenerēts viens miljards iptables noteikumu.
Es visu šo lietu pārbaudīju uz vairākiem tūkstošiem, līdz pat desmit. Un problēma ir tā, ka jau pie šī sliekšņa ir diezgan problemātiski veikt ssh mezglam. Jo paciņas, ejot cauri tik daudzām ķēdēm, sāk justies ne pārāk labi.
Un arī tas viss tiek atrisināts ar Kubernetes palīdzību. Ir tāds Resursu kvotas objekts. Iestata klastera nosaukumvietai pieejamo resursu un objektu skaitu. Mēs varam izveidot yaml objektu katrā Kubernetes klastera nosaukumvietā. Izmantojot šo objektu, mēs varam teikt, ka šai nosaukumvietai mums ir piešķirts noteikts pieprasījumu un ierobežojumu skaits, un tad mēs varam teikt, ka šajā nosaukumu telpā ir iespējams izveidot 10 pakalpojumus un 10 podi. Un atsevišķs izstrādātājs var vismaz sevi vakaros nosmakt. Kubernetes viņam pateiks: "Jūs nevarat mērogot savus pākstis līdz šādai summai, jo resurss pārsniedz kvotu." Tas arī viss, problēma atrisināta. .
Šajā sakarā rodas viens problemātisks punkts. Jūs jūtat, cik grūti kļūst izveidot nosaukumvietu Kubernetes. Lai to izveidotu, mums ir jāņem vērā daudzas lietas.
Resursu kvota + ierobežojuma diapazons + RBAC
• Izveidojiet nosaukumvietu
• Izveidojiet ierobežojuma diapazonu iekšpusē
• Izveidot resursu kvotas ietvaros
• Izveidojiet pakalpojuma kontu CI
• Izveidot lomu piesaisti CI un lietotājiem
• Pēc izvēles palaidiet nepieciešamos servisa blokus
Tāpēc vēlos izmantot iespēju, lai padalītos ar saviem notikumiem. Ir tāda lieta, ko sauc par SDK operatoru. Tas ir veids, kā Kubernetes klasteris var rakstīt operatorus. Jūs varat rakstīt paziņojumus, izmantojot Ansible.
Sākumā tas tika rakstīts Ansible, un tad es redzēju, ka ir SDK operators, un Ansible lomu pārrakstīju par operatoru. Šis paziņojums ļauj izveidot objektu Kubernetes klasterī, ko sauc par komandu. Komandā tas ļauj aprakstīt šīs komandas vidi yaml valodā. Un komandas vidē tas ļauj mums aprakstīt, ka mēs piešķiram tik daudz resursu.
Mazliet .
Un noslēgumā. Ko darīt ar šo visu?
Pirmkārt. Pod drošības politika ir laba. Un, neskatoties uz to, ka neviens no Kubernetes instalētājiem tos neizmanto līdz šai dienai, jums tie joprojām ir jāizmanto savās kopās.
Tīkla politika nav tikai vēl viena nevajadzīga funkcija. Tas ir tas, kas patiešām ir vajadzīgs klasterī.
LimitRange/ResourceQuota — ir pienācis laiks to izmantot. Mēs sākām to lietot jau sen, un ilgu laiku es biju pārliecināts, ka visi to lieto. Izrādījās, ka tas notiek reti.
Papildus tam, ko minēju ziņojuma laikā, ir arī nedokumentētas funkcijas, kas ļauj uzbrukt klasterim. Nesen izlaists .
Dažas lietas ir tik skumjas un sāpīgas. Piemēram, noteiktos apstākļos Kubernetes klastera kubeleti var nodot warlocks direktorijas saturu neautorizētam lietotājam.
Ir norādījumi, kā reproducēt visu, ko es jums teicu. Ir faili ar ražošanas piemēriem par to, kā izskatās ResourceQuota un Pod drošības politika. Un tam visam var pieskarties.
Paldies visiem.
Avots: www.habr.com
