

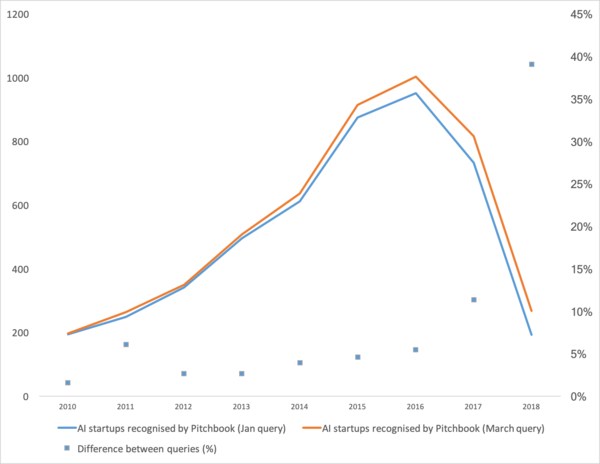
Nesen atbrīvots , kas liecina par labu tendenci mašīnmācībā pēdējos gados. Īsumā: pēdējo divu gadu laikā mašīnmācības jaunuzņēmumu skaits ir strauji samazinājies.
Nu. Apskatīsim “vai burbulis ir pārsprādzis”, “kā turpināt dzīvot” un parunāsim par to, no kurienes vispār rodas šis ķipars.
Vispirms parunāsim par to, kas bija šīs līknes pastiprinātājs. No kurienes viņa nāca? Viņi droši vien visu atcerēsies mašīnmācība 2012. gadā ImageNet konkursā. Galu galā šis ir pirmais globālais pasākums! Bet patiesībā tas tā nav. Un līknes izaugsme sākas nedaudz agrāk. Es to sadalītu vairākos punktos.
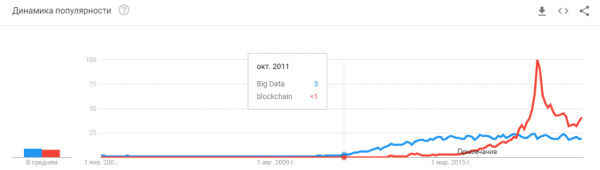
- 2008. gadā parādījās termins “lielie dati”. Sākās īstie produkti kopš 2010. Lielie dati ir tieši saistīti ar mašīnmācīšanos. Bez lielajiem datiem nav iespējama stabila tobrīd pastāvošo algoritmu darbība. Un tie nav neironu tīkli. Līdz 2012. gadam neironu tīkli bija nelielas minoritātes īpašums. Bet tad sāka darboties pavisam citi algoritmi, kas pastāvēja gadiem vai pat gadu desmitiem: (1963,1993, XNUMX), (1995), (2003),... To gadu starta uzņēmumi galvenokārt ir saistīti ar strukturētu datu automātisku apstrādi: kases aparāti, lietotāji, reklāma, daudz kas cits.
Šī pirmā viļņa atvasinājums ir ietvaru kopums, piemēram, XGBoost, CatBoost, LightGBM utt.
- 2011.-2012.gadā uzvarēja vairākos attēlu atpazīšanas konkursos. To faktiskā izmantošana nedaudz aizkavējās. Es teiktu, ka masveidā nozīmīgi jaunuzņēmumi un risinājumi sāka parādīties 2014. gadā. Bija vajadzīgi divi gadi, lai saprastu, ka neironi joprojām darbojas, lai izveidotu ērtus ietvarus, kurus varētu uzstādīt un palaist saprātīgā laikā, izstrādātu metodes, kas stabilizētu un paātrinātu konverģences laiku.
Konvolūcijas tīkli ļāva atrisināt datorredzes problēmas: attēlu un objektu klasifikācija attēlā, objektu noteikšana, objektu un cilvēku atpazīšana, attēla uzlabošana utt.
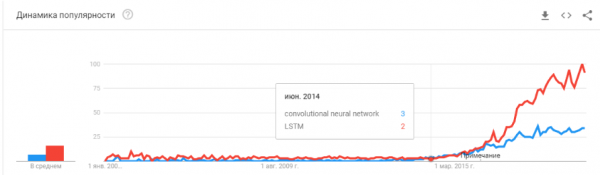
- 2015-2017. Algoritmu un projektu uzplaukums, kuru pamatā ir atkārtoti tīkli vai to analogi (LSTM, GRU, TransformerNet utt.). Ir parādījušies labi funkcionējoši runas pārveidošanas algoritmi un mašīntulkošanas sistēmas. Tie ir daļēji balstīti uz konvolucionālajiem tīkliem, lai iegūtu pamata funkcijas. Daļēji tāpēc, ka mēs iemācījāmies savākt patiešām lielas un labas datu kopas.
"Vai burbulis ir pārsprādzis? Vai ažiotāža ir pārkarsusi? Vai viņi nomira kā blokķēde?
Citādi! Rīt Siri pārtrauks strādāt ar jūsu tālruni, un parīt Tesla nezinās atšķirību starp pagriezienu un ķenguru.
Neironu tīkli jau darbojas. Tie ir desmitiem ierīču. Tie patiešām ļauj nopelnīt naudu, mainīt tirgu un pasauli sev apkārt. Hype izskatās nedaudz savādāk:
Vienkārši neironu tīkli vairs nav kaut kas jauns. Jā, daudziem cilvēkiem ir lielas cerības. Bet liels skaits uzņēmumu ir iemācījušies izmantot neironus un izgatavot produktus, pamatojoties uz tiem. Neironi nodrošina jaunu funkcionalitāti, ļauj samazināt darba vietas un samazināt pakalpojumu cenas:
- Ražošanas uzņēmumi integrē algoritmus, lai analizētu ražošanas līnijas defektus.
- Lopkopības saimniecības pērk sistēmas govju kontrolei.
- Automātiskie kombaini.
- Automatizēti zvanu centri.
- Filtri SnapChat. (nu, vismaz kaut kas noderīgs!)
Bet galvenais un ne pats acīmredzamākais: "Jaunu ideju vairs nav, vai arī tās nenesīs tūlītēju kapitālu." Neironu tīkli ir atrisinājuši desmitiem problēmu. Un viņi izlems vēl vairāk. Visas acīmredzamās idejas, kas pastāvēja, radīja daudzus jaunuzņēmumus. Bet viss, kas atradās virspusē, jau bija savākts. Pēdējo divu gadu laikā es neesmu saskāries ar nevienu jaunu ideju par neironu tīklu izmantošanu. Neviena jauna pieeja (nu, labi, ir dažas problēmas ar GAN).
Un katra nākamā palaišana kļūst arvien sarežģītāka. Tam vairs nav nepieciešami divi puiši, kuri apmāca neironu, izmantojot atvērtos datus. Tam nepieciešami programmētāji, serveris, marķieru komanda, komplekss atbalsts utt.
Līdz ar to ir mazāk jaunuzņēmumu. Bet ir vairāk ražošanas. Vai jāpievieno numura zīmes atpazīšana? Tirgū ir simtiem speciālistu ar atbilstošu pieredzi. Jūs varat kādu nolīgt un pēc pāris mēnešiem jūsu darbinieks izveidos sistēmu. Vai arī iegādājieties gatavu. Bet taisīt jaunu startapu?.. Traki!
Jāizveido apmeklētāju izsekošanas sistēma – kāpēc maksāt par kaudzi licenču, ja 3-4 mēnešu laikā var uztaisīt pats, asināt to savam biznesam.
Tagad neironu tīkli iet pa to pašu ceļu, ko ir izgājušas desmitiem citu tehnoloģiju.
Vai atceraties, kā kopš 1995. gada ir mainījies jēdziens “vietņu izstrādātājs”? Tirgus vēl nav piesātināts ar speciālistiem. Profesionāļu ir ļoti maz. Bet varu derēt, ka pēc 5-10 gadiem nebūs lielas atšķirības starp Java programmētāju un neironu tīklu izstrādātāju. Tirgū pietiks abu speciālistu.
Vienkārši būs problēmu klase, ko var atrisināt neironi. Ir radies uzdevums - nolīgt speciālistu.
"Ko tālāk? Kur ir apsolītais mākslīgais intelekts?
Bet te ir neliels, bet interesants pārpratums :)
Acīmredzot šodien esošā tehnoloģiju kaudze mūs nenovedīs pie mākslīgā intelekta. Idejas un to novitāte lielā mērā ir sevi izsmēlusi. Parunāsim par to, kas saglabā pašreizējo attīstības līmeni.
Ierobežojumi
Sāksim ar pašbraucošām automašīnām. Šķiet skaidrs, ka ar mūsdienu tehnoloģijām ir iespējams izgatavot pilnībā autonomas automašīnas. Bet pēc cik gadiem tas notiks, nav skaidrs. Tesla uzskata, ka tas notiks pēc pāris gadiem -

Ir daudzi citi , kuri lēš, ka tas ir 5-10 gadi.
Visticamāk, manuprāt, pēc 15 gadiem pilsētu infrastruktūra pati mainīsies tā, ka autonomo automašīnu parādīšanās kļūs neizbēgama un kļūs par tās turpinājumu. Bet to nevar uzskatīt par inteliģenci. Mūsdienu Tesla ir ļoti sarežģīts datu filtrēšanas, meklēšanas un pārkvalificēšanas cauruļvads. Tie ir noteikumi-noteikumi-noteikumi, datu apkopošana un filtri pār tiem (šeit Es uzrakstīju nedaudz vairāk par šo vai skatieties no atzīmes).
Pirmā problēma
Un šeit mēs redzam pirmā fundamentālā problēma. Lielie dati. Tas ir tieši tas, kas izraisīja pašreizējo neironu tīklu un mašīnmācības vilni. Mūsdienās, lai veiktu kaut ko sarežģītu un automātisku, ir nepieciešams daudz datu. Ne tikai daudz, bet ļoti, ļoti daudz. Mums ir nepieciešami automatizēti algoritmi to apkopošanai, marķēšanai un lietošanai. Mēs vēlamies, lai automašīna redzētu kravas automašīnas, kas ir vērstas pret sauli - vispirms mums ir jāsavāc pietiekams to skaits. Gribam, lai ar bagāžniekā pieskrūvētu velosipēdu mašīna netrakotu - vairāk paraugu.
Turklāt ar vienu piemēru nepietiek. Simtiem? Tūkstošiem?

Otrā problēma
Otrā problēma — vizualizācija tam, ko mūsu neironu tīkls ir sapratis. Tas ir ļoti nenozīmīgs uzdevums. Līdz šim daži cilvēki saprot, kā to vizualizēt. Šie raksti ir pavisam nesen, tie ir tikai daži piemēri, pat ja tie ir tālu:
apsēstība ar tekstūrām. Tas labi parāda, uz ko neirons mēdz fiksēties + ko tas uztver kā sākuma informāciju.

Uzmanību plkst . Faktiski pievilcību bieži var izmantot tieši, lai parādītu, kas izraisīja šādu tīkla reakciju. Esmu redzējis šādas lietas gan atkļūdošanai, gan produktu risinājumiem. Par šo tēmu ir daudz rakstu. Bet jo sarežģītāki ir dati, jo grūtāk ir saprast, kā panākt stabilu vizualizāciju.

Jā, vecais labais komplekts “Paskaties, kas ir sieta iekšpusē " Šīs bildes bija populāras pirms 3-4 gadiem, taču visi ātri saprata, ka bildes ir skaistas, taču tām nav lielas nozīmes.
Es neminēju desmitiem citu sīkrīku, metožu, uzlaušanas, pētījumu par to, kā parādīt tīkla iekšpusi. Vai šie rīki darbojas? Vai tie palīdz ātri saprast, kas ir problēma, un atkļūdot tīklu?.. Iegūt pēdējo procentu? Nu, tas ir apmēram tas pats:

Vietnē Kaggle varat skatīties jebkuras sacensības. Un apraksts par to, kā cilvēki pieņem galīgos lēmumus. Mēs salikām 100-500-800 modeļu vienības un tas strādāja!
Es, protams, pārspīlēju. Taču šīs pieejas nesniedz ātras un tiešas atbildes.
Ja jums ir pietiekami daudz pieredzes, izpētījis dažādas iespējas, varat sniegt spriedumu par to, kāpēc jūsu sistēma pieņēma šādu lēmumu. Bet būs grūti labot sistēmas uzvedību. Uzstādiet kruķi, pārvietojiet slieksni, pievienojiet datu kopu, izmantojiet citu aizmugurtīklu.
Trešā problēma
Trešā fundamentālā problēma — režģi māca statistiku, nevis loģiku. Statistiski šis :

Loģiski, ka tas nav ļoti līdzīgs. Neironu tīkli neko sarežģītu neapgūst, ja vien tie nav spiesti. Viņi vienmēr māca pēc iespējas vienkāršākās zīmes. Vai tev ir acis, deguns, galva? Tātad šī ir seja! Vai arī sniedziet piemēru, kur acis nenozīmē seju. Un atkal - miljoniem piemēru.
Apakšā ir daudz vietas
Es teiktu, ka tieši šīs trīs globālās problēmas šobrīd ierobežo neironu tīklu un mašīnmācības attīstību. Un kur šīs problēmas neierobežoja, tas jau tiek aktīvi izmantots.
Šīs ir beigas? Vai ir izveidoti neironu tīkli?
Nezināms. Bet, protams, visi cer, ka nē.
Ir daudzas pieejas un virzieni, lai atrisinātu pamatproblēmas, kuras es uzsvēru iepriekš. Taču līdz šim neviena no šīm pieejām nav devusi iespēju izdarīt kaut ko principiāli jaunu, atrisināt kaut ko, kas vēl nav atrisināts. Līdz šim visi fundamentālie projekti tiek veikti, pamatojoties uz stabilām pieejām (Tesla), vai arī paliek institūtu vai korporāciju testa projekti (Google Brain, OpenAI).
Aptuveni runājot, galvenais virziens ir izveidot ieejas datu augsta līmeņa attēlojumu. Savā ziņā "atmiņa". Vienkāršākais atmiņas piemērs ir dažādi “Iegulšanas” - attēlu attēlojumi. Nu, piemēram, visas sejas atpazīšanas sistēmas. Tīkls iemācās iegūt no sejas kādu stabilu attēlojumu, kas nav atkarīgs no rotācijas, apgaismojuma vai izšķirtspējas. Būtībā tīkls samazina metriku “dažādas sejas ir tālu” un “identiskas sejas ir tuvu”.
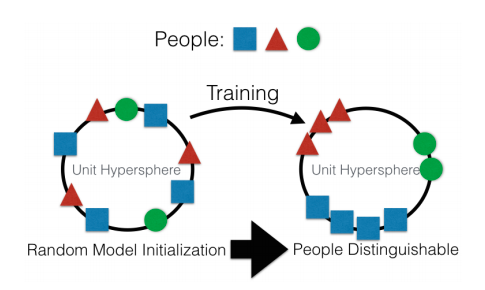
Šādai apmācībai ir nepieciešami desmitiem un simtiem tūkstošu piemēru. Taču rezultātos ir daži no “vienreizējas mācīšanās” elementiem. Tagad mums nav vajadzīgi simtiem seju, lai atcerētos cilvēku. Tikai viena seja un mēs esam viss !
Ir tikai viena problēma... Režģis var apgūt tikai diezgan vienkāršus objektus. Mēģinot atšķirt nevis sejas, bet, piemēram, “cilvēkus pēc apģērba” (uzdevums ) - kvalitāte samazinās par daudzām kārtām. Un tīkls vairs nevar uzzināt diezgan acīmredzamas izmaiņas leņķos.
Un mācīties no miljoniem piemēru arī ir jautri.
Ir darbs, lai būtiski samazinātu vēlēšanu skaitu. Piemēram, uzreiz var atsaukt atmiņā vienu no pirmajiem darbiem OneShot mācīšanās :
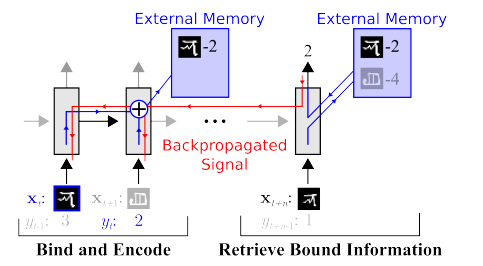
Tādu darbu, piemēram, ir daudz vai vai .
Ir tikai viens mīnuss - parasti apmācība labi darbojas, izmantojot dažus vienkāršus “MNIST” piemērus. Un, pārejot uz sarežģītiem uzdevumiem, jums ir nepieciešama liela datu bāze, objektu modelis vai kāda veida maģija.
Kopumā darbs pie One-Shot apmācības ir ļoti interesants temats. Jūs atrodat daudz ideju. Taču lielākoties divas manis uzskaitītās problēmas (sagatavošanās ar milzīgu datu kopu / sarežģītu datu nestabilitāte) ievērojami traucē mācīšanos.
No otras puses, GAN — ģeneratīvie pretrunīgie tīkli — tuvojas iegulšanas tēmai. Jūs droši vien esat lasījis daudzus rakstus par Habrē par šo tēmu. (, ,)
GAN iezīme ir kādas iekšējās stāvokļa telpas veidošana (būtībā tā pati iegulšana), kas ļauj zīmēt attēlu. Tā var būt , var būt .
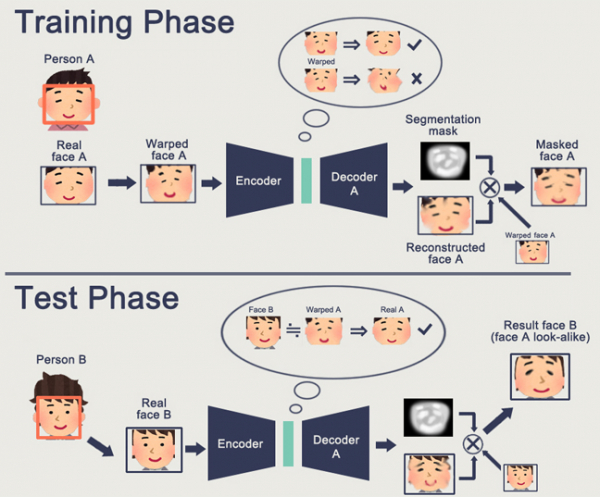
GAN problēma ir tā, ka jo sarežģītāks ir ģenerētais objekts, jo grūtāk to aprakstīt “ģeneratora-diskriminatora” loģikā. Rezultātā vienīgās reālās GAN lietojumprogrammas, par kurām ir dzirdēts, ir DeepFake, kas atkal manipulē ar sejas attēlojumu (kam ir milzīga bāze).
Esmu redzējis ļoti maz citu noderīgu lietojumu. Parasti kaut kāda viltība, kas saistīta ar attēlu zīmējumu apdari.
Un atkal. Nevienam nav ne jausmas, kā tas ļaus mums virzīties uz gaišāku nākotni. Loģikas/telpas attēlošana neironu tīklā ir laba. Bet mums ir vajadzīgs milzīgs skaits piemēru, mēs nesaprotam, kā neirons to attēlo pats par sevi, mēs nesaprotam, kā likt neironam atcerēties kādu patiešām sarežģītu ideju.
Pastiprināšanas mācīšanās - šī ir pieeja no pavisam cita virziena. Noteikti atceraties, kā Google pārspēja visus Go. Nesenās uzvaras Starcraft un Dota. Bet šeit viss nebūt nav tik rožaini un daudzsološi. Viņš vislabāk runā par RL un tās sarežģījumiem .
Īsi apkopojot autora rakstīto:
- Modeļi, kas izņemti no kastes, vairumā gadījumu nav piemēroti / nedarbojas slikti
- Praktiskās problēmas ir vieglāk atrisināt citos veidos. Boston Dynamics neizmanto RL tās sarežģītības/neprognozējamības/skaitļošanas sarežģītības dēļ
- Lai RL darbotos, ir nepieciešama sarežģīta funkcija. Bieži vien ir grūti izveidot/uzrakstīt
- Grūti apmācīt modeļus. Jums ir jāpavada daudz laika, lai sūknētu un izkļūtu no vietējā optimuma
- Rezultātā modeli ir grūti atkārtot, modelis ir nestabils ar mazākajām izmaiņām
- Bieži vien pārvērš dažus nejaušus modeļus, pat nejaušu skaitļu ģeneratoru
Galvenais ir tas, ka RL vēl nestrādā ražošanā. Google ir daži eksperimenti ( , ). Bet es neesmu redzējis nevienu produktu sistēmu.
atmiņa. Visa iepriekš aprakstītā negatīvā puse ir struktūras trūkums. Viena no pieejām, lai mēģinātu to visu sakārtot, ir nodrošināt neironu tīklu ar piekļuvi atsevišķai atmiņai. Lai viņa tur varētu ierakstīt un pārrakstīt savu soļu rezultātus. Tad neironu tīklu var noteikt pēc pašreizējā atmiņas stāvokļa. Tas ir ļoti līdzīgs klasiskajiem procesoriem un datoriem.
Slavenākais un populārākais — no DeepMind:
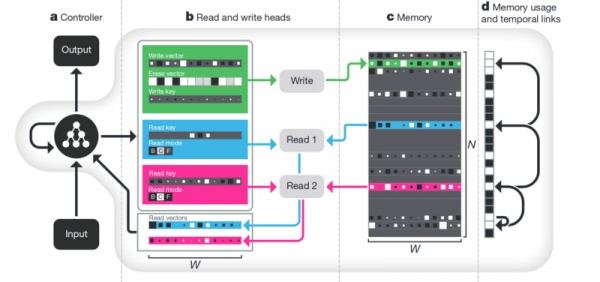
Šķiet, ka tā ir atslēga inteliģences izpratnei? Bet droši vien nē. Sistēma joprojām prasa milzīgu datu apjomu apmācībai. Un tas galvenokārt darbojas ar strukturētiem tabulas datiem. Turklāt, kad Facebook līdzīga problēma, tad viņi izvēlējās ceļu “izskrūvējiet atmiņu, vienkārši padariet neironu sarežģītāku un iegūstiet vairāk piemēru – un tas mācīsies pats no sevis”.
Atdalīšana. Vēl viens veids, kā veidot jēgpilnu atmiņu, ir ņemt tos pašus iegulumus, bet treniņa laikā ieviest papildu kritērijus, kas ļautu izcelt tajos “nozīmes”. Piemēram, mēs vēlamies apmācīt neironu tīklu, lai atšķirtu cilvēka uzvedību veikalā. Ja mēs sekotu standarta ceļam, mums būtu jāizveido ducis tīklu. Viens meklē cilvēku, otrs nosaka, ko viņš dara, trešais ir viņa vecums, ceturtais ir viņa dzimums. Atsevišķa loģika aplūko to veikala daļu, kurā tas dara/ir apmācīts to darīt. Trešais nosaka tā trajektoriju utt.
Vai arī, ja datu būtu bezgalīgi daudz, tad būtu iespējams apmācīt vienu tīklu visiem iespējamiem rezultātiem (acīmredzot šādu datu masīvu nevar savākt).
Atdalīšanas pieeja mums saka – apmācīsim tīklu, lai tas pats varētu atšķirt jēdzienus. Lai pēc video veidotu iegulšanu, kur viens laukums noteiktu darbību, laicīgi noteiktu stāvokli uz grīdas, noteiktu cilvēka augumu un personas dzimumu. Tajā pašā laikā, apmācot, es vēlētos gandrīz nevis rosināt tīklu ar šādiem galvenajiem jēdzieniem, bet gan lai tas izceltu un grupētu jomas. Šādu rakstu ir diezgan daudz (daži no tiem , , ) un kopumā tie ir diezgan teorētiski.
Bet šim virzienam, vismaz teorētiski, vajadzētu aptvert sākumā uzskaitītās problēmas.
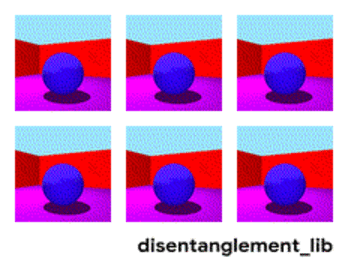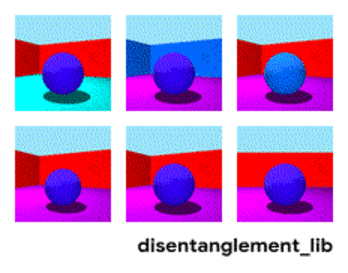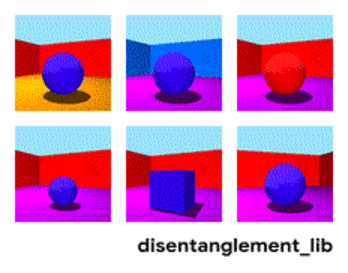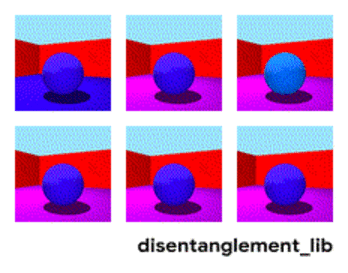
Attēlu sadalīšana atbilstoši parametriem “sienas krāsa/grīdas krāsa/objekta forma/objekta krāsa/utt.”

Sejas sadalīšana pēc parametriem "izmērs, uzacis, orientācija, ādas krāsa utt."
Cits
Ir daudzas citas, ne tik globālas jomas, kas ļauj kaut kā samazināt datu bāzi, strādāt ar neviendabīgākiem datiem utt.
Uzmanību. Iespējams, nav jēgas to nodalīt kā atsevišķu metodi. Tikai pieeja, kas uzlabo citus. Viņam veltīti daudzi raksti (,,). Uzmanības mērķis ir uzlabot tīkla reakciju tieši uz nozīmīgiem objektiem apmācības laikā. Bieži vien pēc kāda veida ārēja mērķa apzīmējuma vai neliela ārējā tīkla.
3D simulācija. Ja uztaisa labu 3D dzinēju, ar to bieži var nosegt 90% treniņu datu (es pat redzēju piemēru, kur gandrīz 99% datu sedza labs dzinējs). Ir daudz ideju un uzlaušanas, kā panākt, lai tīkls, kas apmācīts 3D dzinējā, darbotos, izmantojot reālus datus (precīza regulēšana, stila pārsūtīšana utt.). Taču bieži vien laba dzinēja izveidošana ir par vairākām kārtām grūtāka nekā datu vākšana. Dzinēju izgatavošanas piemēri:
Robotu apmācība (, )
Treniņš preces veikalā (bet tajos divos projektos, ko taisījām, bez tā varējām viegli iztikt).
Apmācība Teslā (atkal video iepriekš).
Atzinumi
Viss raksts savā ziņā ir secinājumi. Iespējams, galvenais vēstījums, ko vēlējos izteikt, bija "bezmaksas ir beigušās, neironi vairs nesniedz vienkāršus risinājumus." Tagad mums ir smagi jāstrādā, lai pieņemtu sarežģītus lēmumus. Vai arī smagi strādājiet, veicot sarežģītus zinātniskus pētījumus.
Kopumā tēma ir apspriežama. Varbūt lasītājiem ir interesantāki piemēri?
Avots: www.habr.com
