

Овие два збора за науката за податоци збунуваат многу луѓе. Рударството на податоци често погрешно се сфаќа како извлекување и преземање податоци, но во реалноста тоа е многу покомплексно. Во оваа објава, ајде да ги ставиме последните допири на рударството и да ја дознаеме разликата помеѓу рударството на податоци и екстракција на податоци.
Што е рударство на податоци?
Рударство на податоци, исто така наречено Откривање на знаење во базата на податоци (KDD), е техника која често се користи за анализа на големи количини на податоци користејќи статистички и математички техники за да се најдат скриени обрасци или трендови и да се извлече вредност од нив.
Што можете да направите со рударството на податоци?
Со автоматизирање на процесот, може да скенира бази на податоци и ефикасно да ги идентификува скриените обрасци. За бизнисите, ископувањето податоци често се користи за да се идентификуваат моделите и односите во податоците за да се помогне во донесувањето подобри деловни одлуки.
Примери за примена
Откако ископувањето податоци стана широко распространето во 1990-тите, компаниите во широк опсег на индустрии, вклучувајќи малопродажба, финансии, здравство, транспорт, телекомуникации, е-трговија итн., почнаа да користат техники за рударство на податоци за да добијат информации засновани на податоци. Рударството на податоци може да помогне во сегментирање на клиентите, откривање на измами, прогноза на продажба и многу повеќе.
- Сегментација на клиентите
Преку анализа на податоците за клиентите и идентификување на карактеристиките на целните клиенти, компаниите можат да ги таргетираат во посебна група и да обезбедат специјални понуди кои ги задоволуваат нивните потреби. - Анализа на пазарна кошничка
Оваа техника се заснова на теоријата дека ако купите одредена група производи, поголема е веројатноста да купите друга група производи. Еден познат пример: кога татковците купуваат пелени за своите бебиња, тие имаат тенденција да купуваат и пиво заедно со пелените. - Прогнозирање на продажбата
Ова може да изгледа слично на анализата на пазарната кошничка, но овој пат анализата на податоците се користи за да се предвиди кога клиентот повторно ќе купи производ во иднина. На пример, тренер купува лименка протеин, која треба да трае 9 месеци. Продавницата што го продава овој протеин планира да издаде нов за 9 месеци, па тренерот повторно ќе го купи. - Откривање измама
Рударството на податоци помага во градењето модели за откривање на измама. Со собирање примероци од лажни и легитимни извештаи, бизнисите се овластени да утврдат кои трансакции се сомнителни. - Откривање на обрасци во производството
Во преработувачката индустрија, рударството на податоци се користи за да помогне во дизајнот на системот преку идентификување на односот помеѓу архитектурата на производот, профилот и потребите на клиентите. Рударството на податоци, исто така, може да ги предвиди временските рокови и трошоците за развој на производот.
И ова се само неколку сценарија за користење на податоци за рударство.
Фази на ископување податоци
Рударството на податоци е сеопфатен процес на собирање, избирање, чистење, трансформирање и извлекување на податоци за да се проценат моделите и на крајот да се извлече вредност.
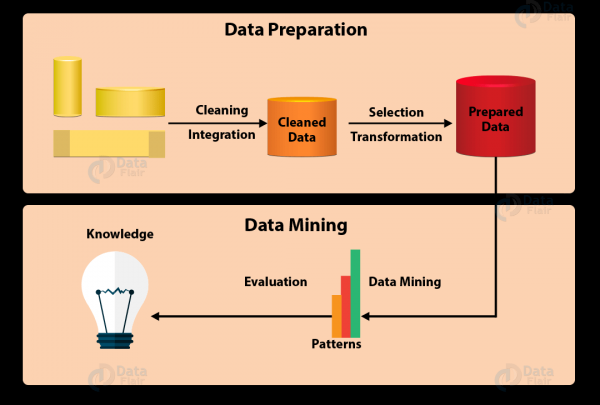
Како по правило, целиот процес на ископување податоци може да се сумира во 7 фази:
- Чистење на податоци
Во реалниот свет, податоците не секогаш се чистат и структурираат. Тие често се бучни, нецелосни и може да содржат грешки. За да се осигурате дека резултатот од ископувањето податоци е точен, прво треба да ги исчистите податоците. Некои методи за чистење вклучуваат пополнување на вредностите што недостасуваат, автоматско и рачно проверување итн. - Интеграција на податоци
Ова е фаза каде што податоците од различни извори се извлекуваат, комбинираат и интегрираат. Изворите можат да бидат бази на податоци, текстуални датотеки, табеларни пресметки, документи, повеќедимензионални множества на податоци, Интернет итн. - Земање примероци на податоци
Вообичаено, не се потребни сите интегрирани податоци во ископувањето податоци. Земањето примероци на податоци е фаза во која само корисни податоци се избираат и се извлекуваат од голема база на податоци. - Конверзија на податоци
Откако ќе се изберат податоците, тие се претвораат во соодветни форми за рударство. Овој процес вклучува нормализација, агрегација, генерализација итн. - Рударство на податоци
Овде доаѓа најважниот дел од ископувањето податоци - користење интелигентни методи за наоѓање шеми во него. Процесот вклучува регресија, класификација, предвидување, групирање, учење на асоцијации и многу повеќе. - Евалуација на моделот
Овој чекор има за цел да идентификува потенцијално корисни, лесни за разбирање и шеми кои поддржуваат хипотези. - Претставување на знаењето
Во завршна фаза, добиените информации се презентираат во атрактивна форма користејќи методи на претставување на знаење и визуелизација.
Недостатоци на рударството на податоци
- Голема инвестиција на време и труд
Бидејќи ископувањето податоци е долг и сложен процес, бара многу работа од продуктивни и вешти луѓе. Рударите на податоци можат да ги искористат предностите на моќните алатки за ископување податоци, но бараат експерти да ги подготват податоците и да ги разберат резултатите. Како резултат на тоа, може да потрае некое време за да се обработат сите информации. - Приватност и безбедност на податоците
Бидејќи ископувањето податоци собира информации за клиентите преку пазарни методи, може да ја наруши приватноста на корисниците. Покрај тоа, хакерите можат да добијат податоци зачувани во системите за рударство на податоци. Ова претставува закана за безбедноста на податоците на клиентите. Ако украдените податоци се злоупотребуваат, тоа лесно може да им наштети на другите.
Горенаведеното е краток вовед во рударството на податоци. Како што веќе спомнав, податочното рударство вклучува процес на собирање и интегрирање на податоци, кој го вклучува и процесот на екстракција на податоци. Во овој случај, слободно може да се каже дека екстракцијата на податоци може да биде дел од долгорочниот процес на ископување податоци.
Што е екстракција на податоци?
Исто така познат како „веб-копирање податоци“ и „стружење на веб“, овој процес е чин на извлекување податоци од (обично неструктурирани или слабо структурирани) извори на податоци во централизирани локации и нивно централизирање на едно место за складирање или понатамошна обработка. Поточно, неструктурираните извори на податоци вклучуваат веб-страници, е-пошта, документи, PDF-датотеки, скениран текст, извештаи од мејнфрејм, датотеки од ролна до ролна, реклами итн. Централизираното складирање може да биде локално, облак или хибридно. Важно е да се запамети дека екстракцијата на податоците не вклучува обработка или друга анализа што може да се случи подоцна.
Што можете да направите со екстракција на податоци?
Во основа, целите на екстракција на податоци спаѓаат во 3 категории.
- Архивирање
Извлекувањето податоци може да ги трансформира податоците од физички формати: книги, весници, фактури во дигитални формати, како што се бази на податоци за складирање или резервна копија. - Промена на форматот на податоците
Кога сакате да мигрирате податоци од вашата моментална локација на нова во развој, можете да собирате податоци од вашата сопствена локација со нејзино извлекување. - Анализа на податоци
Вообичаена е дополнителна анализа на извлечените податоци за да се добие увид. Ова може да изгледа слично на ископувањето податоци, но имајте на ум дека ископувањето податоци е целта на ископувањето податоци, а не дел од него. Покрај тоа, податоците се анализираат поинаку. Еден пример: Сопствениците на онлајн продавници извлекуваат информации за производите од страниците за е-трговија како Amazon за да ги следат стратегиите на конкурентите во реално време. Како и ископувањето податоци, екстракцијата на податоци е автоматизиран процес кој има многу придобивки. Во минатото, луѓето користеа рачно копирање и залепување податоци од едно до друго место, што одземаше многу време. Извлекувањето податоци го забрзува собирањето и значително ја подобрува точноста на извлечените податоци.
Некои примери за користење на екстракција на податоци
Слично на ископувањето податоци, ископувањето податоци е широко користено во различни индустрии. Покрај следењето на цените во е-трговијата, ископувањето податоци може да помогне во вашето сопствено истражување, собирање вести, маркетинг, недвижнини, патувања и туризам, консалтинг, финансии и многу повеќе.
- Оловна генерација
Компаниите можат да извлечат податоци од директориумите: Yelp, Crunchbase, Yellowpages и да генерираат потенцијални клиенти за развој на бизнисот. Можете да го погледнете видеото подолу за да научите како да извлекувате податоци од Yellowpages користејќи го . - Агрегација на содржина и вести
Веб-страниците за собирање содржини можат да примаат редовни текови на податоци од повеќе извори и да ги ажурираат нивните сајтови. - Анализа на чувства
Со извлекување прегледи, коментари и повратни информации од сајтовите на социјалните медиуми како што се Инстаграм и Твитер, експертите можат да ги анализираат основните чувства и да добијат увид во тоа како се перципира бренд, производ или феномен.
Чекори за вадење податоци
Извлекувањето податоци е првата фаза на ETL (кратенка Extract, Transform, Load) и ELT (извади, вчитувај и трансформира). ETL и ELT самите се дел од целосната стратегија за интеграција на податоци. Со други зборови, екстракцијата на податоци може да биде дел од рударството на податоци.
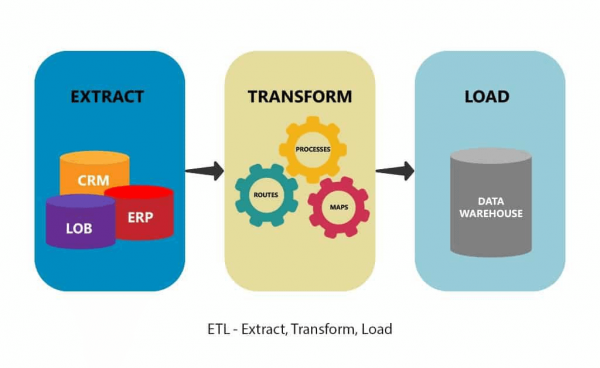
Извлечете, конвертирате, вчитајте
Додека ископувањето податоци е за извлекување информации од големи количини на податоци, екстракцијата на податоци е многу пократок и поедноставен процес. Може да се намали на три фази:
- Избор на извор на податоци
Изберете го изворот од кој сакате да извлечете податоци, како веб-локација. - Собирање на податоци
Испратете барање „GET“ на страницата и анализирајте го добиениот HTML документ користејќи програмски јазици како што се Python, PHP, R, Ruby итн. - Складирање на податоци
Зачувајте податоци во вашата локална база на податоци или складирање облак за понатамошна употреба. Ако сте искусен програмер кој сака да извлекува податоци, горните чекори може да ви изгледаат едноставни. Меѓутоа, ако не кодирате, кратенка е да користите алатки за екстракција на податоци, на пр. . Алатките за извлекување податоци, како алатките за ископување податоци, се дизајнирани да заштедат енергија и да ја олеснат обработката на податоците за секого. Овие алатки не се само економични, туку и погодни за почетници. Тие им овозможуваат на корисниците да собираат податоци за неколку минути, да ги складираат во облакот и да ги извезуваат во многу формати: Excel, CSV, HTML, JSON или во бази на податоци на веб-страници преку API.
Недостатоци на екстракција на податоци
- Пад на серверот
При преземање податоци во голем обем, веб-серверот на целната локација може да биде преоптоварен, што може да предизвика паѓање на серверот. Ова ќе им наштети на интересите на сопственикот на страницата. - Забрани со IP
Кога некое лице собира податоци премногу често, веб-локациите може да ја блокираат нивната IP адреса. Ресурсот може целосно да одбие IP адреса или да го ограничи пристапот, со што податоците ќе бидат нецелосни. За да ги вратите податоците и да избегнете блокирање, треба да го направите тоа со умерена брзина и да користите некои техники против блокирање. - Правни проблеми
Извлекувањето податоци од веб паѓа во сива зона кога станува збор за законитоста. Големите сајтови како Linkedin и Facebook јасно наведуваат во нивните услови за користење дека секое автоматизирано вадење податоци е забрането. Имаше многу судски процеси меѓу компаниите поради активност на бот.
Клучни разлики помеѓу ископувањето податоци и вадењето податоци
- Рударството на податоци се нарекува и откривање на знаење во бази на податоци, екстракција на знаење, анализа на податоци/шаблони, собирање информации. Екстракцијата на податоци се користи наизменично со екстракција на веб-податоци, веб индексирање, ископување податоци итн.
- Истражувањето за рударство на податоци главно се заснова на структурирани податоци, додека во ископувањето податоци обично се извлекува од неструктурирани или лошо структурирани извори.
- Целта на ископувањето податоци е да ги направи податоците покорисни за анализа. Извлекувањето податоци е собирање на податоци на едно место каде што може да се складираат или обработуваат.
- Анализата во ископувањето податоци се заснова на математички методи за идентификување на обрасци или трендови. Извлекувањето податоци се заснова на програмски јазици или алатки за екстракција на податоци за индексирање извори.
- Целта на ископувањето податоци е да се пронајдат факти кои претходно биле непознати или игнорирани, додека екстракцијата на податоци се занимава со постоечките информации.
- Рударството на податоци е покомплексно и бара големи инвестиции во обука на луѓето. Извлекувањето податоци, кога се користи со вистинската алатка, може да биде исклучително едноставно и исплатливо.
Им помагаме на почетниците да не се мешаат во Data. Создадовме промотивен код специјално за жителите на Хабра HABR, давајќи дополнителен попуст од 10% на попустот наведен на банерот.
Повеќе курсеви
Избрани статии
Извор: www.habr.com
