

Неодамна објавени , што покажува добар тренд во машинското учење во последниве години. Накратко: бројот на стартапи за машинско учење опадна во последните две години.
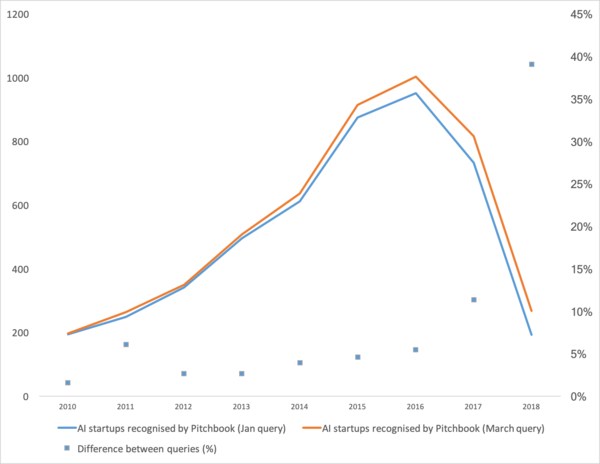
Па. Ајде да погледнеме „дали пукна балонот“, „како да продолжиме да живееме“ и да разговараме за тоа од каде потекнува оваа кичма на прво место.
Прво, да разговараме за тоа што беше засилувач на оваа крива. Од каде дојде таа? Веројатно ќе се сеќаваат на сè машинско учење во 2012 година на натпреварот ImageNet. Впрочем, ова е првиот глобален настан! Но, во реалноста тоа не е така. И растот на кривата започнува малку порано. Би го поделил на неколку точки.
- Во 2008 година се појави терминот „големи податоци“. Започнаа вистинските производи од 2010 година. Големите податоци се директно поврзани со машинското учење. Без големи податоци, стабилната работа на алгоритмите што постоеле во тоа време е невозможна. И ова не се невронски мрежи. До 2012 година, невронските мрежи беа заштитување на маргинално малцинство. Но, тогаш почнаа да работат сосема различни алгоритми, кои постоеја со години, па дури и децении: (1963,1993), (1995), (2003),... Стартапите од тие години првенствено се поврзуваат со автоматска обработка на структурирани податоци: каси, корисници, рекламирање и многу повеќе.
Дериват на овој прв бран е збир на рамки како што се XGBoost, CatBoost, LightGBM итн.
- Во 2011-2012 година победи на голем број натпревари за препознавање слики. Нивната вистинска употреба беше донекаде одложена. Би рекол дека масовно значајни стартапи и решенија почнаа да се појавуваат во 2014 година. Беа потребни две години да се свари дека невроните сè уште работат, да се создадат погодни рамки кои би можеле да се инсталираат и лансираат во разумно време, да се развијат методи кои ќе го стабилизираат и забрзаат времето на конвергенција.
Конволуционите мрежи овозможија да се решат проблемите со компјутерската визија: класификација на слики и предмети на сликата, откривање на предмети, препознавање на предмети и луѓе, подобрување на сликата итн., итн.
- 2015-2017 година. Бумот на алгоритми и проекти базирани на рекурентни мрежи или нивни аналози (LSTM, GRU, TransformerNet, итн.). Се појавија добро функционални алгоритми за говор во текст и системи за машинско преведување. Тие се делумно засновани на конволуциони мрежи за да се извлечат основни карактеристики. Делумно поради фактот што научивме да собираме навистина големи и добри сетови на податоци.
„Дали балонот пукна? Дали возбудата е прегреана? Дали тие умреа како блокчејн?“
Во спротивно! Утре Сири ќе престане да работи на вашиот телефон, а задутре Тесла нема да ја знае разликата помеѓу вртење и кенгур.
Невронските мрежи веќе работат. Тие се во десетици уреди. Тие навистина ви дозволуваат да заработите пари, да го промените пазарот и светот околу вас. Hype изгледа малку поинаку:
Едноставно, невронските мрежи веќе не се нешто ново. Да, многу луѓе имаат големи очекувања. Но, голем број компании научија да користат неврони и да прават производи врз основа на нив. Невроните обезбедуваат нова функционалност, ви дозволуваат да ги намалите работните места и да ја намалите цената на услугите:
- Производствените компании интегрираат алгоритми за да ги анализираат дефектите на производната линија.
- Сточарските фарми купуваат системи за контрола на кравите.
- Автоматски комбинации.
- Автоматски центри за повици.
- Филтри во SnapChat. (добро, барем нешто корисно!)
Но, главната работа, а не најочигледната: „Нема повеќе нови идеи, или тие нема да донесат инстант капитал“. Невронските мрежи решија десетици проблеми. И ќе одлучат уште повеќе. Сите очигледни идеи што постоеја дадоа повод за многу стартапи. Но, се што беше на површината веќе беше собрано. Во текот на изминатите две години, не наидов на ниту една нова идеја за користење на невронски мрежи. Ниту еден нов пристап (добро, во ред, има неколку проблеми со GANs).
И секое наредно стартување е сè покомплексно. Веќе не бара двајца момци кои тренираат неврон користејќи отворени податоци. Потребни се програмери, сервер, тим од маркери, комплексна поддршка итн.
Како резултат на тоа, има помалку стартапи. Но, има повеќе производство. Треба да додадете препознавање на регистарски таблички? На пазарот има стотици специјалисти со соодветно искуство. Можете да вработите некого и за неколку месеци вашиот вработен ќе го направи системот. Или купи готови. Но, правиш нов стартап?.. Лудо!
Треба да креирате систем за следење посетители - зошто да платите за еден куп лиценци кога можете да направите своја за 3-4 месеци, да го изострите за вашиот бизнис.
Сега невронските мрежи минуваат низ истиот пат низ кој поминаа десетици други технологии.
Се сеќавате ли како концептот на „развивач на веб-страници“ се промени од 1995 година? Пазарот сè уште не е заситен со специјалисти. Има многу малку професионалци. Но, можам да се обложам дека за 5-10 години нема да има голема разлика помеѓу Java програмер и развивач на невронска мрежа. На пазарот ќе има доволно од двајцата специјалисти.
Едноставно ќе има класа на проблеми кои ќе можат да ги решат невроните. Се појави задача - ангажирајте специјалист.
"Што е следно? Каде е ветената вештачка интелигенција?“
Но, тука има едно мало, но интересно недоразбирање :)
Технолошкиот оџак што постои денес, очигледно, нема да не доведе до вештачка интелигенција. Идеите и нивната новина во голема мера се исцрпија себеси. Ајде да зборуваме за она што го држи сегашното ниво на развој.
Ограничувања
Да почнеме со самоуправувачки автомобили. Се чини јасно дека е можно да се направат целосно автономни автомобили со денешната технологија. Но, за колку години тоа ќе се случи не е јасно. Тесла верува дека ова ќе се случи за неколку години -

Има многу други , кои проценуваат дека е 5-10 години.
Најверојатно, според мене, за 15 години самата инфраструктура на градовите ќе се промени на таков начин што појавата на автономни автомобили ќе стане неизбежна и ќе стане нејзино продолжение. Но, ова не може да се смета за интелигенција. Модерната Тесла е многу сложен гасовод за филтрирање на податоци, пребарување и преквалификација. Тоа се правила-правила-правила, собирање податоци и филтри над нив (тука Напишав малку повеќе за ова, или гледај од ознаки).
Првиот проблем
И ова е местото каде што гледаме првиот фундаментален проблем. Голем податок. Токму тоа го роди сегашниот бран на невронски мрежи и машинско учење. Во денешно време, за да направите нешто сложено и автоматско, ви требаат многу податоци. Не само многу, туку многу, многу. Потребни ни се автоматизирани алгоритми за нивно собирање, обележување и употреба. Сакаме да го натераме автомобилот да ги гледа камионите свртени кон сонцето - прво мора да собереме доволен број од нив. Сакаме автомобилот да не полуди со велосипед зашрафен на багажникот - повеќе примероци.
Покрај тоа, еден пример не е доволен. Стотици? Илјадници?

Втор проблем
Втор проблем — визуелизација на она што нашата невронска мрежа го разбра. Ова е многу нетривијална задача. До сега, малку луѓе разбираат како да го визуелизираат ова. Овие написи се многу неодамнешни, ова се само неколку примери, дури и ако се далечни:
опседнатост со текстури. Добро покажува на што невронот има тенденција да фиксира + она што го доживува како почетна информација.

Внимание на . Всушност, привлечноста често може да се користи токму за да се покаже што ја предизвикало таквата мрежна реакција. Сум видел такви работи и за дебагирање и за решенија за производи. Има многу написи на оваа тема. Но, колку се посложени податоците, толку е потешко да се разбере како да се постигне робусна визуелизација.

Па, да, стариот добар сет на „погледни што има внатре во мрежата " Овие слики беа популарни пред 3-4 години, но сите брзо сфатија дека сликите се убави, но немаат големо значење.
Не спомнав десетици други гаџети, методи, хакови, истражувања за тоа како да се прикажат внатрешноста на мрежата. Дали овие алатки работат? Дали тие ви помагаат брзо да разберете што е проблемот и да ја дебагирате мрежата?.. Добијте го последниот процент? Па, истото е:

Можете да гледате кое било натпреварување на Kaggle. И опис на тоа како луѓето донесуваат конечни одлуки. Наредени 100-500-800 единици модели и успеа!
Се разбира, претерувам. Но, овие пристапи не даваат брзи и директни одговори.
Имајќи доволно искуство, разгледувајќи различни опции, можете да дадете пресуда зошто вашиот систем донел таква одлука. Но, ќе биде тешко да се поправи однесувањето на системот. Инсталирајте патерица, поместете го прагот, додајте база на податоци, земете друга задна мрежа.
Трет проблем
Трет фундаментален проблем - мрежите учат статистика, а не логика. Статистички ова :

Логично, не е многу слично. Невронските мрежи не учат ништо сложено освен ако не се принудени. Тие секогаш ги учат наједноставните можни знаци. Дали имаш очи, нос, глава? Значи ова е лицето! Или дајте пример каде што очите не значат лице. И повторно - милиони примери.
Има многу простор на дното
Би рекол дека токму овие три глобални проблеми во моментов го ограничуваат развојот на невронските мрежи и машинското учење. И таму каде што овие проблеми не го ограничија, тој веќе активно се користи.
Ова е крајот? Дали невронските мрежи се отворени?
Непознат. Но, се разбира, сите се надеваат дека не.
Постојат многу пристапи и насоки за решавање на основните проблеми што ги истакнав погоре. Но, досега, ниту еден од овие пристапи не овозможи да се направи нешто суштински ново, да се реши нешто што сè уште не е решено. Досега, сите фундаментални проекти се прават врз основа на стабилни пристапи (Tesla), или остануваат тест проекти на институти или корпорации (Google Brain, OpenAI).
Грубо кажано, главната насока е да се создаде одредена претстава на високо ниво на влезните податоци. Во извесна смисла, „меморија“. Наједноставниот пример за меморија е разни „Вградување“ - претстави на слики. Па, на пример, сите системи за препознавање лица. Мрежата учи да добие од лицето некаква стабилна претстава што не зависи од ротација, осветлување или резолуција. Во суштина, мрежата ја минимизира метриката „различните лица се далеку“ и „идентичните лица се блиску“.
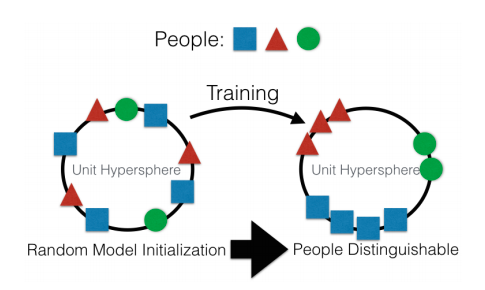
За ваква обука потребни се десетици и стотици илјади примери. Но, резултатот носи некои од зачетоците на „Учење со еден истрел“. Сега не ни требаат стотици лица за да се потсетиме на некоја личност. Само едно лице и тоа е се што сме !
Има само еден проблем... Решетката може да научи само прилично едноставни предмети. Кога се обидувате да разликувате не лица, туку, на пример, „луѓе по облека“ (задача ) - квалитетот паѓа за многу реда на големина. И мрежата повеќе не може да научи прилично очигледни промени во аглите.
И учењето од милиони примери е исто така забавно.
Се работи за значително намалување на изборите. На пример, веднаш може да се потсетиме на едно од првите дела на OneShot учење :
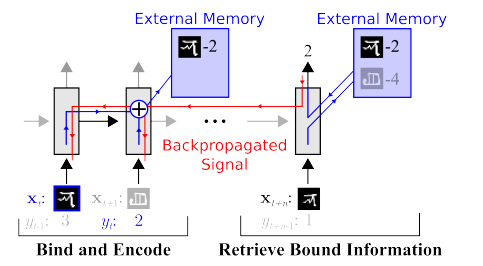
Има многу такви дела, на пример или или .
Има еден минус - обично обуката работи добро на некои едноставни, „MNIST“ примери. И кога се префрлате на сложени задачи, потребна ви е голема база на податоци, модел на предмети или некаква магија.
Општо земено, работата на обуката One-Shot е многу интересна тема. Ќе најдете многу идеи. Но, во најголем дел, двата проблема што ги набројав (пред-обука за огромна база на податоци / нестабилност на сложени податоци) во голема мера го попречуваат учењето.
Од друга страна, GAN - генеративни противнички мрежи - пристапуваат кон темата Вградување. Веројатно сте прочитале еден куп написи на Хабре на оваа тема. (, ,)
Карактеристика на GAN е формирањето на некој внатрешен простор за состојби (во суштина истото Вградување), што ви овозможува да нацртате слика. Тоа може да биде , може да биде .
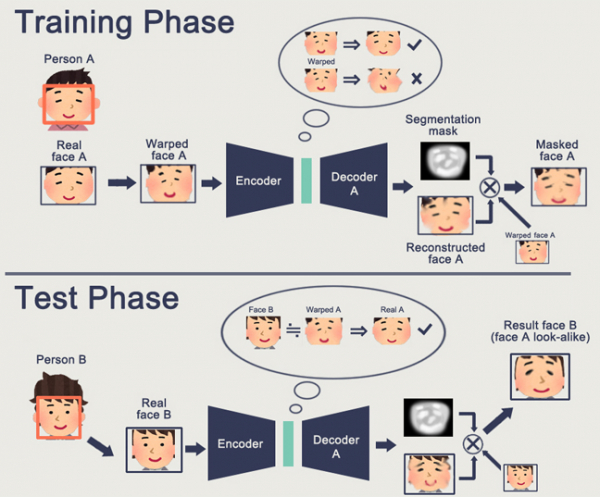
Проблемот со GAN е што колку е покомплексен генерираниот објект, толку е потешко да се опише во логиката „генератор-дискриминатор“. Како резултат на тоа, единствените вистински апликации на GAN за кои се слуша се DeepFake, кој, повторно, манипулира со претставите на лицето (за што има огромна база).
Сум видел многу малку други корисни употреби. Обично некој вид на измама вклучува завршување на цртежи на слики.
И повторно. Никој нема идеја како ова ќе ни овозможи да се преселиме во посветла иднина. Претставувањето логика/простор во невронска мрежа е добро. Но, ни требаат огромен број примери, не разбираме како невронот го претставува ова сам по себе, не разбираме како да го натераме невронот да запомни некоја навистина сложена идеја.
Засилување на учењето - ова е пристап од сосема друга насока. Сигурно се сеќавате како Google ги победи сите во Go. Неодамнешните победи во Starcraft и Dota. Но, овде сè е далеку од толку розово и ветувачко. Тој најдобро зборува за РЛ и нејзината сложеност .
Накратко да резимираме што напиша авторот:
- Моделите надвор од кутијата не се вклопуваат / работат лошо во повеќето случаи
- Практичните проблеми полесно се решаваат на други начини. Boston Dynamics не користи RL поради неговата сложеност/непредвидливост/компјутерска сложеност
- За да работи RL, потребна ви е сложена функција. Често е тешко да се создаде/напише
- Тешко е да се обучуваат модели. Мора да потрошите многу време за да пумпате и да излезете од локалната оптима
- Како резултат на тоа, тешко е да се повтори моделот, моделот е нестабилен со најмали промени
- Честопати повеќе одговара на некои случајни обрасци, дури и на генератор на случаен број
Клучната поента е дека RL сè уште не работи во производството. Google има некои експерименти ( , ). Но, не сум видел ниту еден производен систем.
Меморија. Негативната страна на сè што е опишано погоре е недостатокот на структура. Еден од пристапите за да се обиде да го среди сето ова е да и обезбедиме на невронската мрежа пристап до посебна меморија. За да може таму да ги снима и да ги препише резултатите од нејзините чекори. Тогаш невронската мрежа може да се одреди според моменталната состојба на меморијата. Ова е многу слично на класичните процесори и компјутери.
Најпознатите и најпопуларните - од DeepMind:
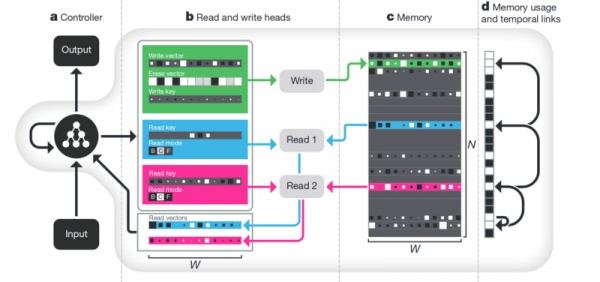
Се чини дека ова е клучот за разбирање на интелигенцијата? Но веројатно не. Системот сè уште бара огромна количина на податоци за обука. И работи главно со структурирани табеларни податоци. Згора на тоа, кога Фејсбук сличен проблем, потоа тргнаа по патот „завртете ја меморијата, само направете го невронот покомплициран и имајте повеќе примери - и тој ќе научи сам“.
Расклопување. Друг начин да се создаде значајна меморија е да ги земете истите вградувања, но за време на обуката, воведете дополнителни критериуми што ќе ви овозможат да ги истакнете „значењата“ во нив. На пример, сакаме да обучиме невронска мрежа да прави разлика помеѓу човечкото однесување во продавница. Ако одевме по стандардниот пат, ќе требаше да направиме десетина мрежи. Едниот бара личност, вториот одредува што прави, третиот е неговата возраст, четвртиот е неговиот пол. Посебна логика гледа во делот од продавницата каде што го прави/е обучен да го прави тоа. Третиот ја одредува неговата траекторија итн.
Или, ако има бесконечна количина на податоци, тогаш би било можно да се обучи една мрежа за сите можни исходи (очигледно, таква низа на податоци не може да се собере).
Пристапот на расклопување ни кажува - ајде да ја обучиме мрежата за таа самата да прави разлика помеѓу концептите. Така што ќе формира вградување врз основа на видеото, каде што една област ќе го одреди дејството, навреме ќе се одреди положбата на подот, ќе се одреди висината на личноста и ќе се одреди полот на личноста. Во исто време, кога тренирам, би сакал речиси да не ја поттикнувам мрежата со такви клучни концепти, туку таа да ги истакнува и групира областите. Има доста такви написи (некои од нив , , ) и воопшто се доста теоретски.
Но, оваа насока, барем теоретски, треба да ги покрие проблемите наведени на почетокот.
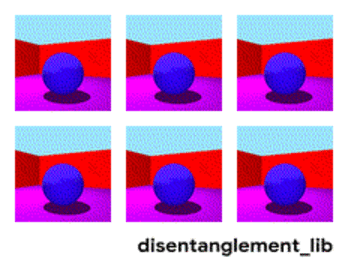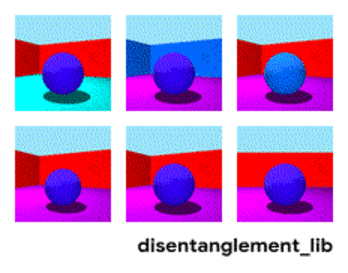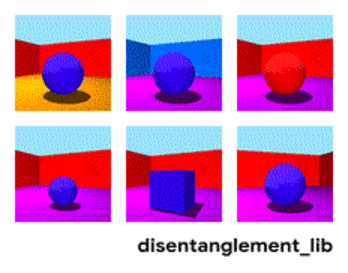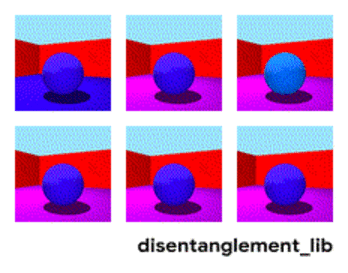
Распаѓање на сликата според параметрите „боја на ѕид/боја на под/облик на објект/боја на објект/итн“.

Распаѓање на лице според параметрите „големина, веѓи, ориентација, боја на кожа итн“.
Останати
Има многу други, не толку глобални области кои ви дозволуваат некако да ја намалите базата на податоци, да работите со повеќе хетерогени податоци итн.
Внимание. Веројатно нема смисла да се издвои ова како посебен метод. Само пристап кој ги подобрува другите. Многу статии се посветени на него (,,). Поентата на внимание е да се подобри одговорот на мрежата конкретно на значајни објекти за време на обуката. Често со некаква надворешна ознака на целта, или мала надворешна мрежа.
3D симулација. Ако направите добар 3D мотор, често можете да покриете 90% од податоците за обуката со него (дури видов пример каде скоро 99% од податоците беа покриени со добар мотор). Има многу идеи и хакови за тоа како да се направи мрежа обучена на 3D мотор да работи со помош на вистински податоци (фино подесување, пренос на стил, итн.). Но, често е да се направи добар мотор за неколку реда потешко од собирањето податоци. Примери кога биле направени мотори:
Обука за роботи (, )
обука стоки во продавницата (но во двата проекти што ги направивме, лесно можевме без неа).
Тренинг во Тесла (повторно, видеото погоре).
Наоди
Целата статија е, во извесна смисла, заклучоци. Веројатно главната порака што сакав да ја испратам беше „бесплатите завршија, невроните повеќе не даваат едноставни решенија“. Сега треба да работиме напорно за да донесеме сложени одлуки. Или работете напорно правејќи сложени научни истражувања.
Генерално, темата е дискутабилна. Можеби читателите имаат поинтересни примери?
Извор: www.habr.com
