


Бүгдээрээ сайн байцгаана уу! Намайг Дмитрий Самсонов гэдэг, би Одноклассники сайтад системийн ахлах администратороор ажилладаг. Бидэнд 7 гаруй физик сервер, үүлэн технологид 11 контейнер, янз бүрийн тохиргоонд 700 өөр кластер үүсгэдэг 200 програм байдаг. Серверүүдийн дийлэнх нь ажиллаж байна CentOS 7.
14 оны 2018-р сарын XNUMX-нд FragmentSmack-ийн эмзэг байдлын талаарх мэдээлэл нийтлэгдсэн.
() болон SegmentSmack (). Эдгээр нь сүлжээний халдлагын вектортой, нэлээд өндөр оноотой (7.5) сул талууд бөгөөд нөөц шавхагдсан (CPU) улмаас үйлчилгээ үзүүлэхээс татгалзах (DoS) аюул заналхийлж байна. Тухайн үед FragmentSmack-ийн цөмийн засварыг санал болгоогүй бөгөөд энэ нь эмзэг байдлын талаарх мэдээлэл нийтлэгдсэнээс хамаагүй хожуу гарч ирсэн. SegmentSmack-ийг устгахын тулд цөмийг шинэчлэхийг санал болгосон. Шинэчлэлтийн багц өөрөө тэр өдөр гарсан бөгөөд зөвхөн суулгах л үлдлээ.
Үгүй ээ, бид цөмийг шинэчлэхийг огт эсэргүүцдэггүй! Гэсэн хэдий ч нюансууд байдаг ...
Үйлдвэрлэлийн цөмийг хэрхэн шинэчлэх вэ
Ерөнхийдөө ямар ч төвөгтэй зүйл байхгүй:
- Багцуудыг татаж авах;
- Тэдгээрийг хэд хэдэн сервер дээр суулгах (үүнд манай клоуд байрладаг серверүүд);
- Юу ч эвдэрсэн эсэхийг шалгаарай;
- Цөмийн бүх стандарт тохиргоог алдаагүй ашиглаж байгаа эсэхийг шалгаарай;
- Хэдэн өдөр хүлээх хэрэгтэй;
- Серверийн гүйцэтгэлийг шалгах;
- Шинэ серверүүдийг шинэ цөм рүү шилжүүлэх;
- Бүх серверүүдийг дата төвөөр шинэчлэх (асуудал гарсан тохиолдолд хэрэглэгчдэд үзүүлэх нөлөөллийг багасгахын тулд нэг дата төвийг нэг дор хийх);
- Бүх серверүүдийг дахин ачаална уу.
Бидэнд байгаа цөмийн бүх салбарыг давтана. Одоогоор энэ нь:
- Хувьцаа CentOS 7 3.10 - ихэнх ердийн серверүүдийн хувьд;
- Ваниль 4.19 - бидний хувьд , учир нь бидэнд BFQ, BBR гэх мэт хэрэгтэй;
- Elrepo kernel-ml 5.2 - for , учир нь 4.19 нь тогтворгүй ажилладаг байсан ч ижил шинж чанарууд хэрэгтэй.
Таны таамаглаж байсанчлан олон мянган серверүүдийг дахин ачаалахад хамгийн их цаг зарцуулдаг. Бүх сул тал нь бүх серверийн хувьд чухал биш тул бид зөвхөн интернетээс шууд хандах боломжтой серверүүдийг л дахин ачаалдаг. Клоуд дээр уян хатан байдлыг хязгаарлахгүйн тулд бид гаднаас хандах боломжтой контейнеруудыг шинэ цөмтэй бие даасан серверүүдтэй холбодоггүй, харин бүх хостуудыг дахин ачаалдаг. Аз болоход тэнд байгаа процедур нь ердийн сервертэй харьцуулахад илүү хялбар байдаг. Жишээлбэл, харьяалалгүй контейнерууд дахин ачаалах үед өөр сервер рүү шилжих боломжтой.
Гэсэн хэдий ч маш их ажил байгаа бөгөөд энэ нь хэдэн долоо хоног шаардагдах бөгөөд хэрэв шинэ хувилбартай холбоотой асуудал гарвал хэдэн сар хүртэл хугацаа шаардагдана. Халдагчид үүнийг маш сайн ойлгодог тул тэдэнд Б төлөвлөгөө хэрэгтэй.
FragmentSmack/SegmentSmack. Товчлох арга зам
Аз болоход, зарим эмзэг байдлын хувьд ийм "В" төлөвлөгөө байдаг бөгөөд үүнийг Товчлох арга гэж нэрлэдэг. Ихэнхдээ энэ нь цөм/програмын тохиргооны өөрчлөлт бөгөөд болзошгүй үр нөлөөг багасгах эсвэл эмзэг байдлын ашиглалтыг бүрэн арилгах боломжтой.
FragmentSmack/SegmentSmack-ийн хувьд Ийм тойрч гарах арга зам:
«Та net.ipv4.ipfrag_high_thresh болон net.ipv3.ipfrag_low_thresh (мөн ipv4 net.ipv4.ipfrag_high_thresh болон net.ipv6.ipfrag_low_thresh) дээрх өгөгдмөл утгуудыг 6MB болон 6MB болон тус тус 256 кБ болгон өөрчилж болно. доогуур. Туршилтууд нь тоног төхөөрөмж, тохиргоо, нөхцөл байдлаас шалтгаалан халдлагын үед CPU-ийн хэрэглээ бага ба мэдэгдэхүйц буурч байгааг харуулж байна. Гэхдээ ipfrag_high_thresh=192 байтаас шалтгаалж гүйцэтгэлд бага зэрэг нөлөөлж болзошгүй, учир нь нэг удаад дахин угсрах дараалалд зөвхөн хоёр 262144К фрагмент багтах боломжтой. Жишээлбэл, том UDP пакетуудтай ажилладаг програмууд эвдрэх эрсдэлтэй".
Параметрүүд өөрсдөө дараах байдлаар тайлбарлав.
ipfrag_high_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments.
ipfrag_low_thresh - LONG INTEGER
Maximum memory used to reassemble IP fragments before the kernel
begins to remove incomplete fragment queues to free up resources.
The kernel still accepts new fragments for defragmentation.
Бидэнд үйлдвэрлэлийн үйлчилгээнд томоохон UDP байхгүй. LAN дээр тасархай урсгал байхгүй, WAN дээр тасархай траффик байгаа боловч чухал биш. Ямар ч шинж тэмдэг байхгүй - та тойрч гарах арга замыг гаргаж болно!
FragmentSmack/SegmentSmack. Анхны цус
Бидний тулгарсан хамгийн эхний асуудал бол үүлэн контейнерууд заримдаа шинэ тохиргоог хэсэгчлэн ашигладаг (зөвхөн ipfrag_low_thresh), заримдаа огт ашигладаггүй байсан - тэд зүгээр л эхэндээ гацсан. Асуудлыг тогтвортой дахин гаргах боломжгүй байсан (бүх тохиргоог гараар ямар ч хүндрэлгүйгээр хийсэн). Эхэндээ сав яагаад унадагийг ойлгох нь тийм ч хялбар биш юм: алдаа олдсонгүй. Нэг зүйл тодорхой байсан: тохиргоог буцаах нь савны эвдрэлийн асуудлыг шийддэг.
Sysctl-ийг хост дээр ашиглах нь яагаад хангалтгүй байна вэ? Контейнер нь өөрийн тусгай сүлжээний Namespace-д амьдардаг тул наад зах нь саванд байгаа нь хостоос ялгаатай байж болно.
Sysctl тохиргоог саванд яг хэрхэн ашигладаг вэ? Манай чингэлэгүүд давуу эрхгүй тул та контейнер руу орсноор ямар ч Sysctl тохиргоог өөрчлөх боломжгүй - танд хангалттай эрх байхгүй. Контейнер ажиллуулахын тулд тэр үед манай клоуд Docker (одоо ). Шинэ контейнерын параметрүүдийг шаардлагатай Sysctl тохиргоог багтаасан API-ээр дамжуулан Docker руу дамжуулсан.
Хувилбаруудыг хайж байх үед Docker API нь бүх алдааг буцаагаагүй нь тогтоогдсон (дор хаяж 1.10 хувилбарт). Бид савыг "докерын ажиллуулах" замаар эхлүүлэхийг оролдохдоо эцэст нь дор хаяж нэг зүйлийг олж харлаа.
write /proc/sys/net/ipv4/ipfrag_high_thresh: invalid argument docker: Error response from daemon: Cannot start container <...>: [9] System error: could not synchronise with container process.
Параметрийн утга буруу байна. Гэхдээ яагаад? Мөн энэ нь яагаад зөвхөн заримдаа хүчин төгөлдөр бус байдаг вэ? Docker нь Sysctl параметрүүдийг ашиглах дарааллыг баталгаажуулдаггүй (хамгийн сүүлийн туршилтын хувилбар нь 1.13.1), тиймээс заримдаа ipfrag_low_thresh 256М хэвээр байх үед ipfrag_high_thresh-ийг 3K болгож тохируулахыг оролддог, өөрөөр хэлбэл дээд хязгаар нь доогуур байсан. доод хязгаараас хэтэрсэн нь алдаа гарахад хүргэсэн.
Тэр үед бид савыг эхлүүлсний дараа дахин тохируулах механизмаа аль хэдийн ашигласан (савыг хөлдөөх). болон савны нэрийн зайд командуудыг дамжуулан гүйцэтгэх ), мөн бид энэ хэсэгт Sysctl бичих параметрүүдийг нэмсэн. Асуудал шийдэгдсэн.
FragmentSmack/SegmentSmack. Эхний цус 2
Үүлэн дэх Workaround-ийн хэрэглээг ойлгохоос өмнө хэрэглэгчдээс анхны ховор гомдол ирж эхлэв. Тухайн үед анхны серверүүд дээр Workaround ашиглаж эхэлснээс хойш хэдэн долоо хоног өнгөрчээ. Анхан шатны мөрдөн байцаалтын явцад эдгээр үйлчилгээний бүх серверүүд биш, хувь хүний үйлчилгээний эсрэг гомдол ирсэн болохыг харуулсан. Асуудал дахин маш тодорхойгүй болсон.
Юуны өмнө бид Sysctl тохиргоог буцаах гэж оролдсон боловч энэ нь ямар ч нөлөө үзүүлээгүй. Сервер болон програмын тохиргоог янз бүрийн аргаар хийсэн ч тус болсонгүй. Дахин ачаалах нь тус болсон. Дахин ачаалах Linux ажиллахад хэвийн нөхцөл байсан шигээ байгалийн бус байсан Windows Хуучин үед. Гэхдээ энэ нь ажилладаг байсан бөгөөд бид шинэ Sysctl тохиргоог хэрэглэхдээ үүнийг "цөмийн алдаа" гэж тэмдэглэсэн. Бидний тэнэгүүд...
Гурван долоо хоногийн дараа асуудал дахин давтагдсан. Эдгээр серверүүдийн тохиргоо маш энгийн байсан: Nginx прокси/тэнцвэржүүлэгч горимд байна. Замын хөдөлгөөн их биш. Шинэ танилцуулга: үйлчлүүлэгчидтэй холбоотой 504 алдааны тоо өдөр бүр нэмэгдэж байна (). График нь энэ үйлчилгээнд өдөрт 504 алдаа гаргадаг болохыг харуулж байна.
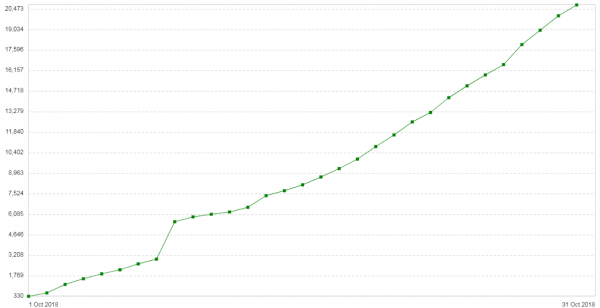
Бүх алдаа нь үүлэн дотор байгаа алдаатай ижил төстэй байна. Энэ арын хэсэгт багцын фрагментуудын санах ойн хэрэглээний график дараах байдалтай байна:
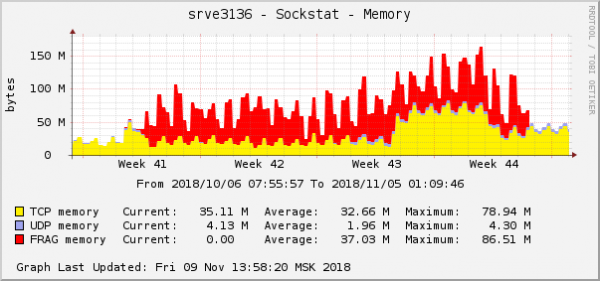
Энэ бол үйлдлийн системийн график дээрх асуудлын хамгийн тод илрэлүүдийн нэг юм. Клоуд дээр яг тэр үед QoS (Traffic Control) тохиргоотой холбоотой өөр нэг сүлжээний асуудлыг зассан. Пакет фрагментуудын санах ойн хэрэглээний график дээр яг адилхан харагдаж байв.
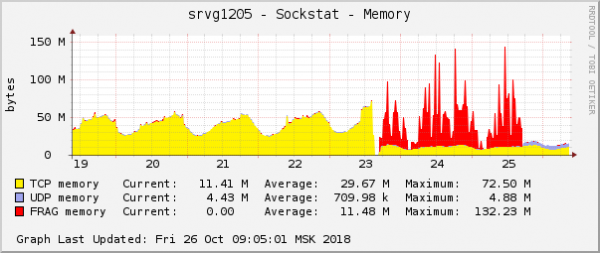
Таамаглал нь энгийн байсан: хэрэв тэд график дээр адилхан харагдаж байвал тэд ижил шалтгаантай болно. Түүнээс гадна энэ төрлийн санах ойтой холбоотой аливаа асуудал маш ховор тохиолддог.
Тогтсон асуудлын мөн чанар нь бид QoS-д анхдагч тохиргоотой fq пакет төлөвлөгчийг ашигласан явдал юм. Анхдагч байдлаар, нэг холболтын хувьд энэ нь дараалалд 100 пакет нэмэх боломжийг олгодог бөгөөд сувгийн хомсдолын үед зарим холболтууд дарааллыг хүчин чадалд нь хааж эхэлсэн. Энэ тохиолдолд пакетуудыг хаядаг. tc статистикт (tc -s qdisc) үүнийг дараах байдлаар харж болно.
qdisc fq 2c6c: parent 1:2c6c limit 10000p flow_limit 100p buckets 1024 orphan_mask 1023 quantum 3028 initial_quantum 15140 refill_delay 40.0ms
Sent 454701676345 bytes 491683359 pkt (dropped 464545, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
1024 flows (1021 inactive, 0 throttled)
0 gc, 0 highprio, 0 throttled, 464545 flows_plimit
"464545 flows_plimit" нь нэг холболтын дарааллын хязгаарыг хэтрүүлсний улмаас хасагдсан пакетууд бөгөөд "унасан 464545" нь энэ хуваарилагчийн бүх хасагдсан пакетуудын нийлбэр юм. Дарааллын уртыг 1 мянга болгож, савыг дахин ажиллуулсны дараа асуудал гарахаа больсон. Та зүгээр суугаад смүүти ууж болно.
FragmentSmack/SegmentSmack. Сүүлчийн цус
Нэгдүгээрт, цөмийн эмзэг байдлыг зарласнаас хойш хэдэн сарын дараа FragmentSmack-ийн засвар эцэст нь гарсан (санаж байна уу, наймдугаар сард зөвхөн SegmentSmack-ийн засвар гарсан), энэ нь бидэнд нэлээд асуудал үүсгэсэн Workout-оос татгалзах боломжийг олгосон. Энэ хугацаанд бид зарим серверийг шинэ цөм рүү аль хэдийн шилжүүлсэн байсан бөгөөд одоо бид эхнээс нь эхлэх хэрэгтэй болсон. Бид яагаад FragmentSmack-ийн засварыг хүлээлгүйгээр цөмийг шинэчилсэн бэ? Үнэндээ эдгээр эмзэг байдлаас хамгаалах үйл явц нь Workout-ийг шинэчлэх үйл явцтай давхцаж (мөн нэгтгэсэн) юм. CentOS (зөвхөн цөмийг шинэчлэхээс ч удаан хугацаа шаардагдана). Түүнээс гадна, SegmentSmack нь илүү аюултай эмзэг байдал бөгөөд үүнийг засах арга тэр даруйд бэлэн болсон тул ямар ч байсан утга учиртай байсан. Гэсэн хэдий ч, зүгээр л цөмийг шинэчлэх CentOS үед гарч ирсэн FragmentSmack эмзэг байдлаас болж бид үүнийг хийж чадаагүй CentOS 7.5 хувилбарыг зөвхөн 7.6 хувилбар дээр л зассан тул бид 7.5 хувилбар руу шинэчлэлтийг зогсоож, 7.6 хувилбар руу шинэчлэлт хийж дахин эхлүүлэх шаардлагатай болсон. Энэ нь бас тохиолддог.
Хоёрдугаарт, асуудалтай холбоотой ховор хэрэглэгчдийн гомдол бидэнд буцаж ирсэн. Одоо бид эдгээр нь үйлчлүүлэгчдээс манай зарим серверт файл байршуулахтай холбоотой гэдгийг аль хэдийн мэдэж байгаа. Түүнээс гадна, нийт массаас маш цөөн тооны байршуулалт эдгээр серверүүдээр дамжсан.
Дээрх түүхээс бидний санаж байгаагаар Sysctl-ийг буцаах нь тус болсонгүй. Дахин ачаалах нь тусалсан боловч түр зуур.
Sysctl-тэй холбоотой хардлагыг арилгаагүй ч энэ удаад аль болох их мэдээлэл цуглуулах шаардлагатай болсон. Юу болж байгааг илүү нарийвчлан судлахын тулд үйлчлүүлэгч дээр байршуулах асуудлыг дахин гаргах чадвар маш их дутагдалтай байсан.
Боломжтой бүх статистик мэдээлэл, бүртгэлийн дүн шинжилгээ нь юу болж байгааг ойлгоход ойртуулсангүй. Тодорхой холболтыг "мэдрэх" тулд асуудлыг дахин гаргах чадваргүй байсан. Эцэст нь, хөгжүүлэгчид програмын тусгай хувилбарыг ашиглан Wi-Fi-аар холбогдсон үед туршилтын төхөөрөмж дээрх асуудлуудыг тогтвортой хуулбарлаж чадсан. Энэ нь мөрдөн байцаалтын явцад гарсан амжилт байлаа. Үйлчлүүлэгч нь Nginx-тэй холбогдсон бөгөөд энэ нь манай Java програм байсан backend руу прокси хийсэн.
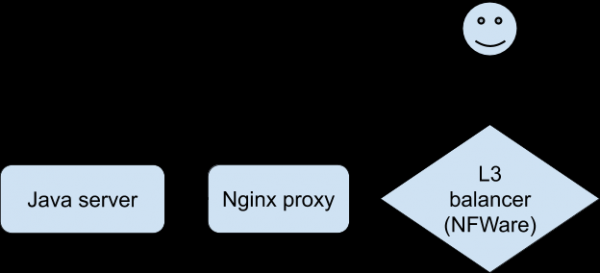
Асуудлын талаархи яриа нь иймэрхүү байсан (Nginx прокси талд зассан):
- Үйлчлүүлэгч: файл татаж авах тухай мэдээлэл авах хүсэлт.
- Java сервер: хариулт.
- Үйлчлүүлэгч: Файлтай POST.
- Java сервер: алдаа.
Үүний зэрэгцээ Java сервер нь үйлчлүүлэгчээс 0 байт өгөгдөл хүлээн авсан гэж бүртгэлд бичдэг бол Nginx прокси нь хүсэлт 30 секундээс илүү хугацаа зарцуулсан гэж бичдэг (30 секунд бол үйлчлүүлэгчийн програмын ажиллах хугацаа). Яагаад хугацаа хэтэрсэн, яагаад 0 байт вэ? HTTP-ийн өнцгөөс харахад бүх зүйл хэвийн ажиллаж байгаа боловч файлтай POST сүлжээнээс алга болсон бололтой. Түүнээс гадна энэ нь үйлчлүүлэгч болон Nginx хооронд алга болдог. Tcpdump-ээр өөрийгөө зэвсэглэх цаг боллоо! Гэхдээ эхлээд та сүлжээний тохиргоог ойлгох хэрэгтэй. Nginx прокси нь L3 тэнцвэржүүлэгчийн ард байдаг . Tunneling нь пакетуудыг L3 тэнцвэржүүлэгчээс сервер рүү хүргэхэд ашиглагддаг бөгөөд энэ нь пакетуудад толгойгоо нэмдэг.
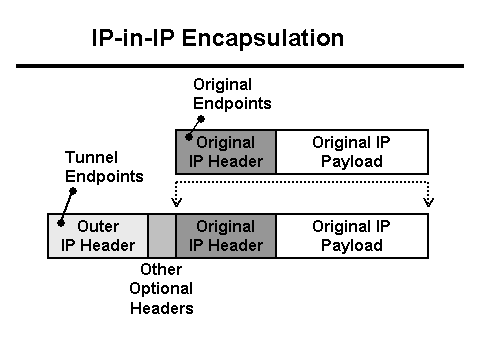
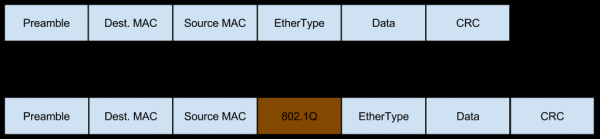
Энэ тохиолдолд сүлжээ нь энэ серверт Vlan хаягтай траффик хэлбэрээр ирдэг бөгөөд энэ нь пакетуудад өөрийн талбаруудыг нэмдэг.
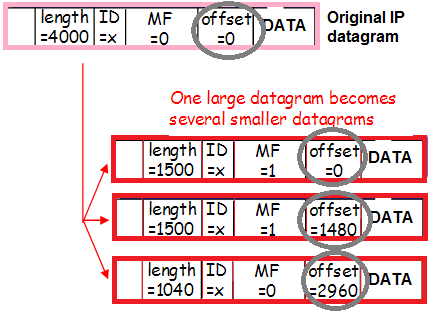
Мөн энэ траффикийг хэсэгчлэн хувааж болно (эргэцүүлэн бодоход гарах эрсдлийг үнэлэх үед бидний ярьж байсан хэсэгчилсэн урсгалын ижил бага хувь), энэ нь толгойн агуулгыг өөрчилдөг:
Дахин нэг удаа: пакетууд нь Vlan хаягаар бүрхэгдсэн, хонгилоор бүрхэгдсэн, хуваагдсан байна. Энэ нь хэрхэн болдгийг илүү сайн ойлгохын тулд үйлчлүүлэгчээс Nginx прокси хүртэлх багцын маршрутыг авч үзье.
- Пакет нь L3 тэнцвэржүүлэгчид хүрдэг. Өгөгдлийн төв дотор зөв чиглүүлэхийн тулд пакетыг хонгилд хийж сүлжээний карт руу илгээдэг.
- Пакет + туннелийн толгой нь MTU-д тохирохгүй тул пакетыг хэсэг болгон хувааж сүлжээнд илгээдэг.
- L3 тэнцвэржүүлэгчийн дараах шилжүүлэгч нь пакет хүлээн авахдаа Vlan хаягийг нэмж илгээдэг.
- Nginx проксины урд байрлах шилжүүлэгч нь (портын тохиргоонд тулгуурлан) сервер Vlan-бүрсэн пакет хүлээж байгааг харж, Vlan хаягийг арилгахгүйгээр үүнийг байгаагаар нь илгээдэг.
- Linux бие даасан багцуудын хэлтэрхийг хүлээн авч, тэдгээрийг нэг том багцад наадаг.
- Дараа нь пакет нь Vlan интерфэйс дээр хүрч, үүнээс эхний давхарга арилдаг - Vlan капсул.
- дараа нь Linux үүнийг Тунелийн интерфэйс рүү илгээдэг бөгөөд тэндээс өөр давхарга - Тунелийн капсулжуулалтыг арилгадаг.
Энэ бүхнийг tcpdump руу параметр болгон дамжуулахад хүндрэлтэй байгаа юм.
Төгсгөлөөс нь эхэлцгээе: vlan болон туннелийн капсулыг устгасан үйлчлүүлэгчдээс цэвэр (шаардлагагүй гарчиггүй) IP пакетууд байгаа юу?
tcpdump host <ip клиента>
Үгүй ээ, сервер дээр ийм багц байгаагүй. Тиймээс асуудал эрт дээр үеэс байх ёстой. Зөвхөн Vlan капсулыг устгасан пакетууд байна уу?
tcpdump ip[32:4]=0xx390x2xx
0xx390x2xx нь hex форматтай үйлчлүүлэгчийн IP хаяг юм.
32:4 — Туннелийн багцад SCR IP бичигдсэн талбарын хаяг ба урт.
Талбайн хаягийг харгис хүчээр сонгох шаардлагатай байсан, учир нь тэд Интернет дээр 40, 44, 50, 54 гэж бичдэг боловч тэнд IP хаяг байхгүй байв. Та мөн hex дэх пакетуудын аль нэгийг (tcpdump дахь -xx эсвэл -XX параметр) харж, мэддэг IP хаягаа тооцоолж болно.
Vlan болон туннелийн капсулыг устгаагүй багцын хэсгүүд байгаа юу?
tcpdump ((ip[6:2] > 0) and (not ip[6] = 64))
Энэ ид шид бидэнд бүх хэлтэрхийнүүд, түүний дотор сүүлчийнхийг нь харуулах болно. Магадгүй ижил зүйлийг IP-ээр шүүж болно, гэхдээ би оролдоогүй, учир нь тийм олон пакет байдаггүй бөгөөд надад хэрэгтэй байгаа нь ерөнхий урсгалаас амархан олддог. Тэд энд байна:
14:02:58.471063 In 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), length 1516: (tos 0x0, ttl 63, id 53652, offset 0, flags [+], proto IPIP (4), length 1500)
11.11.11.11 > 22.22.22.22: truncated-ip - 20 bytes missing! (tos 0x0, ttl 50, id 57750, offset 0, flags [DF], proto TCP (6), length 1500)
33.33.33.33.33333 > 44.44.44.44.80: Flags [.], seq 0:1448, ack 1, win 343, options [nop,nop,TS val 11660691 ecr 2998165860], length 1448
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ...........A....
0x0010: 4500 05dc d194 2000 3f09 d5fb 0a66 387d E.......?....f8}
0x0020: 1x67 7899 4500 06xx e198 4000 3206 6xx4 .faEE.....@.2.m.
0x0030: b291 x9xx x345 2541 83b9 0050 9740 0x04 .......A...P.@..
0x0040: 6444 4939 8010 0257 8c3c 0000 0101 080x dDI9...W.......
0x0050: 00b1 ed93 b2b4 6964 xxd8 ffe1 006a 4578 ......ad.....jEx
0x0060: 6966 0000 4x4d 002a 0500 0008 0004 0100 if..MM.*........
14:02:58.471103 00:de:ff:1a:94:11 ethertype IPv4 (0x0800), урт 62: (tos 0x0, ttl 63, id 53652, офсет 1480, туг [байхгүй], прото IPIP (4), урт 40)
11.11.11.11 > 22.22.22.22: ip-proto-4
0x0000: 0000 0001 0006 00de fb1a 9441 0000 0800 ..........А....
0x0010: 4500 0028 d194 00b9 3f04 faf6 2x76 385x E..(....?....f8}
0x0020: 1x76 6545 xxxx 1x11 2d2c 0c21 8016 8e43 .faE...D-,.!...C
0x0030: x978 e91d x9b0 d608 0000 0000 0000 7c31 .x............|Q
0x0040: 881d c4b6 0000 0000 0000 0000 0000 .............
Эдгээр нь гэрэл зурагтай нэг багцын хоёр хэсэг (ижил ID 53652) юм (эхний багцад Exif гэсэн үг харагдаж байна). Хогийн цэгт нэгтгэсэн хэлбэрээр биш, энэ түвшинд багцууд байдаг тул угсралттай холбоотой асуудал тодорхой байна. Эцэст нь энэ тухай баримтат нотолгоо бий!
Пакет декодер нь бүтээхэд саад болох ямар ч асуудлыг илрүүлээгүй. Энд оролдсон: . Эхлээд та тэнд ямар нэгэн зүйл хийх гэж оролдоход декодер нь пакет форматад дургүй байдаг. Srcmac болон Ethertype хоёрын хооронд нэмэлт хоёр октет байсан нь тогтоогдсон (фрагмент мэдээлэлтэй холбоогүй). Тэдгээрийг арилгасны дараа декодер ажиллаж эхлэв. Гэсэн хэдий ч энэ нь ямар ч асуудалгүй байгааг харуулсан.
Юу ч хэлж байсан, тэдгээр Sysctl-ээс өөр юу ч олдсонгүй. Үлдсэн зүйл бол цар хүрээг ойлгож, цаашдын арга хэмжээг шийдэхийн тулд асуудалтай серверүүдийг тодорхойлох арга замыг олох явдал байв. Шаардлагатай тоолуур хангалттай хурдан олдсон:
netstat -s | grep "packet reassembles failed”
Энэ нь мөн snmpd-д OID=1.3.6.1.2.1.4.31.1.1.16.1 ().
"IP-г дахин угсрах алгоритмаар илрүүлсэн алдааны тоо (ямар ч шалтгаанаар: хугацаа хэтэрсэн, алдаа гэх мэт)."
Асуудлыг судалсан серверүүдийн дотроос хоёр дээр энэ тоолуур илүү хурдан, хоёр дээр илүү удаан, хоёр дээр нь огт нэмэгдээгүй байна. Энэхүү тоолуурын динамикийг Java сервер дээрх HTTP алдааны динамиктай харьцуулах нь харилцан хамаарлыг илрүүлсэн. Өөрөөр хэлбэл, тоолуурыг хянаж болно.
Асуудлын найдвартай үзүүлэлттэй байх нь маш чухал бөгөөд ингэснээр та Sysctl-ийг буцаах нь тус болж байгаа эсэхийг нарийн тодорхойлох боломжтой, учир нь өмнөх түүхээс үүнийг програмаас шууд ойлгох боломжгүй гэдгийг бид мэдэж байсан. Энэ үзүүлэлт нь хэрэглэгчид үүнийг олж мэдэхээс өмнө үйлдвэрлэлийн бүх асуудлыг тодорхойлох боломжийг бидэнд олгоно.
Sysctl-ийг буцасны дараа хяналтын алдаанууд зогссон тул асуудлын шалтгаан нь нотлогдсон бөгөөд буцаах нь тусалдаг.
Бид шинэ хяналт хэрэгжиж эхэлсэн бусад серверүүд дээрх хуваагдлын тохиргоог буцаах ба хаа нэгтээ бид фрагментуудад өмнө нь анхдагч байснаас илүү их санах ойг хуваарилсан (энэ нь UDP статистик байсан бөгөөд ерөнхийдөө хэсэгчилсэн алдагдал нь мэдэгдэхүйц биш байсан) .
Хамгийн чухал асуултууд
Манай L3 тэнцвэржүүлэгч дээр пакетууд яагаад хуваагдсан байдаг вэ? Хэрэглэгчээс тэнцвэржүүлэгч рүү ирдэг ихэнх пакетууд нь SYN болон ACK юм. Эдгээр багцын хэмжээ бага байна. Гэхдээ ийм пакетуудын эзлэх хувь маш том тул тэдгээрийн цаана бид хуваагдаж эхэлсэн том пакетууд байгааг анзаараагүй.
Үүний шалтгаан нь эвдэрсэн тохиргооны скрипт байсан Vlan интерфэйстэй серверүүд дээр (тухайн үед үйлдвэрлэлд хаяглагдсан траффиктэй маш цөөхөн серверүүд байсан). Advmss нь манай чиглэлд байгаа пакетууд нь жижиг хэмжээтэй байх ёстой бөгөөд ингэснээр хонгилын толгойг хавсаргасны дараа хуваагдах шаардлагагүй болно гэсэн мэдээллийг үйлчлүүлэгчдэд хүргэх боломжийг бидэнд олгодог.
Яагаад Sysctl-ийг буцаах нь тус болсонгүй, харин дахин ачаалахад тус болсон бэ? Sysctl-г буцаах нь багцуудыг нэгтгэх санах ойн хэмжээг өөрчилсөн. Үүний зэрэгцээ фрагментуудын санах ой хэт их байгаа нь холболтыг удаашруулахад хүргэсэн бөгөөд энэ нь фрагментууд дараалалд удаан хугацаагаар саатахад хүргэсэн бололтой. Энэ нь үйл явц нь циклээр явагдсан гэсэн үг юм.
Дахин ачаалснаар санах ойг цэвэрлэж, бүх зүйл дарааллаар нь эргэж ирэв.
Товч шийдэлгүйгээр хийх боломжтой байсан уу? Тийм ээ, гэхдээ халдлагад өртсөн тохиолдолд хэрэглэгчдийг үйлчилгээгүй орхих эрсдэл өндөр байдаг. Мэдээжийн хэрэг, тойрч гарах арга хэрэгслийг ашигласнаар хэрэглэгчдэд зориулсан үйлчилгээний нэг удаашрах зэрэг янз бүрийн асуудал гарсан боловч бид энэ үйлдлүүд нь үндэслэлтэй байсан гэж бид үзэж байна.
Андрей Тимофеевт маш их баярлалаа () мөрдөн байцаалт явуулахад туслалцаа үзүүлсэн, түүнчлэн Алексей Кренев () - шинэчлэлтийн аварга том ажлын төлөө Centos болон серверийн цөмүүд. Энэ тохиолдолд процессыг хэд хэдэн удаа дахин эхлүүлэх шаардлагатай болсон бөгөөд үүний үр дүнд олон сар зарцуулагдсан.
Эх сурвалж: www.habr.com
