

Намайг Виктор Ягофаров гэдэг бөгөөд би DomClick дээр Ops (үйл ажиллагаа) багийн техникийн хөгжлийн менежерээр Kubernetes платформыг хөгжүүлж байна. Би Dev <-> Ops процессуудын бүтэц, Орос дахь хамгийн том k8s кластеруудын нэгийг ажиллуулах онцлог, мөн манай багийн ашигладаг DevOps/SRE туршлагын талаар ярихыг хүсч байна.

Үйл ажиллагааны баг
Үйл ажиллагааны баг одоогоор 15 хүнтэй. Тэдний гурав нь оффисыг хариуцдаг, хоёр нь өөр цагийн бүсэд ажилладаг бөгөөд шөнийн цагаар ажиллах боломжтой. Тиймээс Ops-ийн хэн нэгэн нь үргэлж монитор дээр байдаг бөгөөд ямар ч төвөгтэй үйл явдалд хариу өгөхөд бэлэн байдаг. Бидэнд шөнийн ээлж байдаггүй бөгөөд энэ нь бидний сэтгэл зүйг хадгалж, хүн бүр хангалттай унтаж, зөвхөн компьютер дээр төдийгүй чөлөөт цагаа өнгөрөөх боломжийг олгодог.
Хүн бүр өөр өөр чадвартай байдаг: сүлжээний мэргэжилтнүүд, DBA-ууд, ELK стекийн мэргэжилтнүүд, Kubernetes админууд/хөгжүүлэгчид, мониторинг, виртуалчлал, техник хангамжийн мэргэжилтнүүд гэх мэт. Хүн бүрийг нэгтгэдэг нэг зүйл бол хүн бүр бидний хэнийг ч тодорхой хэмжээгээр сольж чадна: жишээлбэл, k8s кластерт шинэ зангилаа оруулах, PostgreSQL-ийг шинэчлэх, CI/CD + Ansible дамжуулах шугам бичих, Python/Bash/Go дээр ямар нэг зүйлийг автоматжуулах, техник хангамжийг холбох. Мэдээллийн төв. Аль ч салбарт хүчтэй ур чадвар нь таныг үйл ажиллагааны чиглэлээ өөрчлөх, өөр чиглэлээр сайжирч эхлэхэд саад болохгүй. Жишээлбэл, би нэг компанид PostgreSQL-ийн мэргэжилтэнээр элссэн бөгөөд одоо миний хариуцах гол чиглэл бол Кубернетес кластерууд юм. Багийн хувьд ямар ч өндөрт баяртай байдаг бөгөөд хөшүүргийн мэдрэмж маш их хөгжсөн байдаг.
Дашрамд хэлэхэд, бид нэр дэвшигчдийг хайж байна. Нэр дэвшигчдэд тавигдах шаардлага нэлээд стандарт байдаг. Миний хувьд тухайн хүн багт нийцэж, зөрчилдөхгүй, мөн өөрийн үзэл бодлоо хамгаалах чадвартай, хөгжихөд бэлэн, шинэ зүйл туршиж үзэхээс айдаггүй, санаагаа санал болгоход бэлэн байх нь чухал юм. Түүнчлэн, скрипт хэлний програмчлалын ур чадвар, үндсэн ойлголтуудын мэдлэг шаардлагатай. Linux мөн Англи хэл. Хэрэв хэн нэгэн алдаа гаргавал асуудлын шийдлийг 10 минут биш, 10 секундын дотор Google-ээс хайж олохын тулд англи хэл хэрэгтэй. Гүнзгий мэдлэгтэй мэргэжилтнүүдтэй Linux Одоо маш хэцүү байна: инээдтэй ч гурван нэр дэвшигчийн хоёр нь "Ачааллын дундаж гэж юу вэ? Энэ нь юунаас бүрддэг вэ?" гэсэн асуултад хариулж чадахгүй бөгөөд "С програмаас цөмийн дамп хэрхэн үүсгэх вэ" гэсэн асуултыг супермэнүүд... эсвэл үлэг гүрвэлүүдэд зориулсан зүйл гэж үздэг. Хүмүүс ихэвчлэн өндөр хөгжсөн бусад чадваруудтай байдаг тул бид үүнийг тэвчих ёстой бөгөөд бид тэдэнд Linux заах болно. "Орчин үеийн үүлэн ертөнцөд DevOps инженер яагаад энэ бүхнийг мэдэх шаардлагатай вэ" гэсэн асуултын хариултыг энэ нийтлэлийн хүрээнээс гадуур үлдээх хэрэгтэй болно, гэхдээ товчхондоо: энэ бүхэн зайлшгүй шаардлагатай.
Багийн хэрэгсэл
Хэрэгслийн баг нь автоматжуулалтад чухал үүрэг гүйцэтгэдэг. Тэдний гол ажил бол хөгжүүлэгчдэд тохиромжтой график болон CLI хэрэгслийг бий болгох явдал юм. Жишээлбэл, манай дотоод хөгжлийн хурал нь танд хулганын хэдхэн товшилтоор програмыг Kubernetes-д гаргах, нөөцийг нь тохируулах, хадгалах сангийн түлхүүр гэх мэт боломжийг олгодог. Өмнө нь Jenkins + Helm 2 байсан, гэхдээ би хуулж буулгах аргыг устгаж, програм хангамжийн амьдралын мөчлөгт нэгдмэл байдлыг бий болгохын тулд өөрийн хэрэгслийг боловсруулах шаардлагатай болсон.
Үйл ажиллагааны баг нь хөгжүүлэгчдэд зориулж дамжуулах шугам бичдэггүй, гэхдээ бичихдээ ямар нэгэн асуудлаар зөвлөгөө өгөх боломжтой (зарим хүмүүс Helm 3-тай хэвээр байна).
DevOps
DevOps-ийн хувьд бид үүнийг дараах байдлаар харж байна.
Хөгжүүлэгчийн багууд код бичиж, Confer to dev -> qa/stage -> prod-ээр дамжуулна. Код нь удаашрахгүй, алдаа гаргахгүй байх хариуцлага нь Dev болон Ops багууд юм. Өдрийн цагаар жижүүрийн багийн жижүүр нь юуны түрүүнд өөрийн өргөдлийн дагуу үйл явдалд хариу өгөх ёстой бөгөөд орой, шөнийн цагаар жижүүрийн администратор (Ops) хэрэв мэддэг бол жижүүр хөгжүүлэгчийг сэрээх ёстой. асуудал нь дэд бүтцэд биш гэдэгт итгэлтэй байна. Хяналтын бүх хэмжигдэхүүн болон дохиолол автоматаар эсвэл хагас автоматаар гарч ирдэг.
Ops-ийн хариуцах талбар нь програмыг үйлдвэрлэлд нэвтрүүлсэн цагаас эхэлдэг боловч Dev-ийн хариуцлага үүгээр дуусдаггүй - бид ижил зүйлийг хийдэг бөгөөд нэг завинд байдаг.
Хөгжүүлэгчид админ бичил үйлчилгээ бичихэд тусламж хэрэгтэй бол (жишээлбэл, Go backend + HTML5) зөвлөгөө өгөх ба админууд нь дэд бүтцийн асуудал эсвэл k8-тэй холбоотой асуудлын талаар хөгжүүлэгчдэд зөвлөгөө өгдөг.
Дашрамд хэлэхэд, бидэнд нэг цул байхгүй, зөвхөн микро үйлчилгээнүүд л байдаг. Тэдний тоо одоогийн байдлаар k900s-ийн кластерт 1000-8 хооронд хэлбэлзэж байна, хэрэв тоогоор нь хэмжвэл байршуулалт. Буурцагны тоо 1700-2000 хооронд хэлбэлздэг. Одоогийн байдлаар бүтээгдэхүүний кластерт 2000 орчим хонхорхой бий.
Шаардлагагүй микро үйлчилгээг хянаж, хагас автоматаар хасдаг тул би яг тодорхой тоо хэлж чадахгүй байна. K8s нь шаардлагагүй аж ахуйн нэгжүүдийг хянахад бидэнд тусалдаг , энэ нь маш их нөөц, мөнгө хэмнэдэг.
Нөөцийн менежмент
Хяналт шинжилгээ
Сайн бүтэцтэй, мэдээлэл сайтай хяналт нь томоохон кластерын үйл ажиллагааны тулгын чулуу болдог. Бид мониторингийн бүх хэрэгцээг 100% хангах нийтлэг шийдлийг хараахан олоогүй байгаа тул бид энэ орчинд үе үе өөр өөр захиалгат шийдлүүдийг бий болгодог.
- Заббик. Дэд бүтцийн ерөнхий байдлыг хянах зорилготой хуучин сайн мониторинг. Энэ нь процесс, санах ой, диск, сүлжээ гэх мэтийн хувьд зангилаа үхэхийг бидэнд хэлдэг. Ямар ч ер бусын зүйл байхгүй, гэхдээ бидэнд тусдаа DaemonSet агентууд байдаг бөгөөд тэдгээрийн тусламжтайгаар жишээ нь бид кластер дахь DNS-ийн төлөвийг хянадаг: бид тэнэг coredns pods хайж, гадаад хостуудын бэлэн байдлыг шалгадаг. Яагаад үүнд санаа зовоод байгаа юм шиг санагдаж байна, гэхдээ их хэмжээний ачаалалтай үед энэ бүрэлдэхүүн хэсэг нь бүтэлгүйтлийн ноцтой цэг юм. Би аль хэдийн , би кластер дахь DNS гүйцэтгэлтэй хэрхэн тэмцэж байсан.
- Прометей оператор. Төрөл бүрийн экспортлогчдын багц нь кластерын бүх бүрэлдэхүүн хэсгүүдийн ерөнхий тоймыг өгдөг. Дараа нь бид энэ бүгдийг Графана дахь том хяналтын самбар дээр дүрслэн харуулж, дохиололд alertmanager ашигладаг.
Бидний хувьд өөр нэг хэрэгтэй хэрэгсэл байсан . Бид үүнийг хэд хэдэн удаа нэг баг өөр багийн орох замтай давхцаж, 50 дахин алдаа гаргасан нөхцөл байдалтай тулгарсны дараа бичсэн. Одоо үйлдвэрлэлд нэвтрүүлэхээсээ өмнө хөгжүүлэгчид хэнд ч нөлөөлөхгүй эсэхийг шалгадаг бөгөөд миний багийн хувьд энэ нь Ingresses-тэй холбоотой асуудлыг анхан шатны оношлох сайн хэрэгсэл юм. Энэ нь эхлээд админуудад зориулагдсан байсан бөгөөд энэ нь нэлээд "болхи" мэт харагддаг байсан нь инээдтэй юм, гэхдээ хөгжүүлэгчид энэ хэрэгсэлд дурласны дараа энэ нь маш их өөрчлөгдөж, "админ админуудад зориулж веб нүүр хийсэн" шиг харагдахгүй болсон. ” Удалгүй бид энэ хэрэгслээс татгалзаж, ийм нөхцөл байдал нь дамжуулах хоолойг ашиглалтад оруулахаас өмнө баталгаажуулах болно.
Cube дахь багийн нөөц
Жишээнүүдэд орохын өмнө бид нөөцийг хэрхэн хуваарилж байгааг тайлбарлах нь зүйтэй бичил үйлчилгээ.
Аль баг, ямар хэмжээгээр ашигладаг болохыг ойлгох нөөц (процессор, санах ой, локал SSD), бид тушаал бүрийг тус тусад нь хуваарилдаг нэрийн орон зай "Cube" -д байгаа ба процессор, санах ой, дискний хамгийн дээд чадварыг хязгаарлаж, өмнө нь багуудын хэрэгцээг хэлэлцсэн. Үүний дагуу нэг тушаал нь ерөнхийдөө кластерыг бүхэлд нь блоклохгүй бөгөөд олон мянган цөм, терабайт санах ойг хуваарилдаг. Нэрийн орон зайд нэвтрэх эрхийг AD-ээр олгодог (бид RBAC ашигладаг). Нэрийн орон зай болон тэдгээрийн хязгаарыг GIT репозитор руу татах хүсэлтээр нэмж, дараа нь бүх зүйлийг Ansible дамжуулах шугамаар автоматаар шилжүүлдэг.
Багийн нөөцийг хуваарилах жишээ:
namespaces:
chat-team:
pods: 23
limits:
cpu: 11
memory: 20Gi
requests:
cpu: 11
memory: 20Gi
Хүсэлт ба хязгаарлалт
куб" авагч нь баталгаатай нөөцийн нөөцийн тоо юм pod (нэг буюу хэд хэдэн докер контейнер) кластерт. Хязгаар нь баталгаагүй дээд хэмжээ юм. Зарим баг өөрийн бүх аппликешнүүдэд хэт олон хүсэлт тавьж, "Cube"-д програмыг байрлуулж чадахгүй байгааг та график дээрээс харж болно.
Энэ нөхцөл байдлаас гарах зөв арга бол нөөцийн бодит хэрэглээг харж, хүссэн хэмжээтэй (хүсэлт) харьцуулах явдал юм.
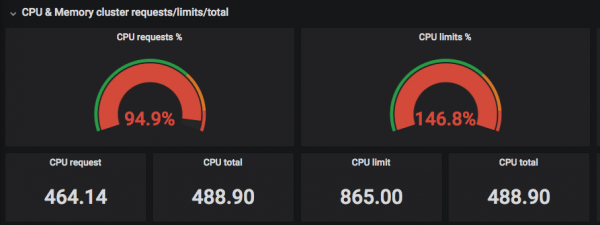
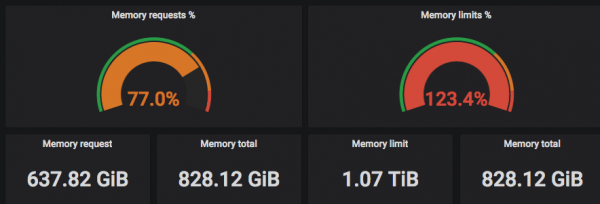
Дээрх дэлгэцийн агшинд та "Хүссэн" CPU-ууд нь хэлхээний бодит тоотой таарч байгааг харж болно, мөн хязгаар нь CPU-ийн хэлхээний бодит тооноос хэтэрч болно =)
Одоо зарим нэрийн талбарыг нарийвчлан авч үзье (би нэрийн зай kube-системийг сонгосон - "Cube"-ийн бүрэлдэхүүн хэсгүүдийн системийн нэрийн орон зай) болон бодит ашигласан процессорын цаг болон санах ойн хүссэнтэй харьцуулсан харьцааг харцгаая:
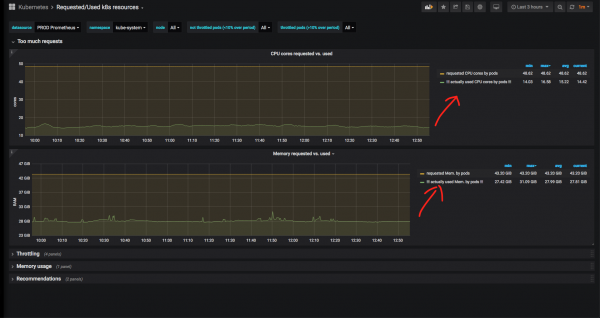
Бодит хэрэглэгдэж байгаагаас хамаагүй илүү санах ой болон CPU нь системийн үйлчилгээнд зориулагдсан нь ойлгомжтой. Kube-системийн хувьд энэ нь үндэслэлтэй юм: nginx оролт хянагч эсвэл nodelocaldns оргил үедээ CPU-ийг цохиж, маш их хэмжээний RAM зарцуулсан тул энд ийм нөөцийг зөвтгөж байна. Нэмж дурдахад, бид сүүлийн 3 цагийн графикт найдах боломжгүй: түүхэн хэмжүүрүүдийг урт хугацааны туршид харах нь зүйтэй юм.
"Зөвлөмж"-ийн системийг боловсруулсан. Жишээлбэл, "хязгаарлалт"-ыг (зөвшөөрөгдсөн дээд хязгаар) нэмэгдүүлэх нь ямар нөөцийг илүү сайн болохыг эндээс харж болно: нөөц нь CPU эсвэл санах ойг хуваарилсан хугацаанд зарцуулсан байх үед. "хөлдөхгүй" болтол хүлээж байна:
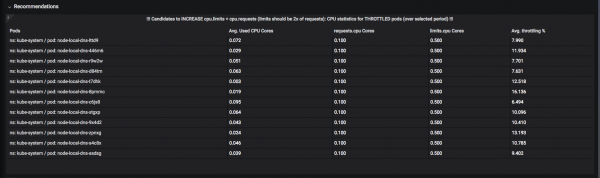
Тэдний хоолны дуршлыг бууруулах ёстой буурцагнууд энд байна:
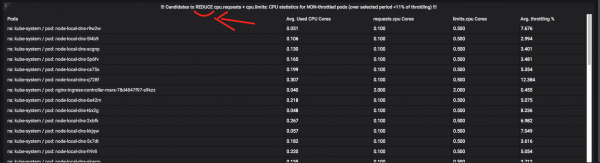
дээр бууруулах + нөөцийн хяналт, та нэгээс олон нийтлэл бичих боломжтой тул сэтгэгдэл дээр асуулт асуугаарай. Ийм хэмжигдэхүүнийг автоматжуулах ажил нь маш хэцүү бөгөөд "цонх" функцууд болон "CTE" Prometheus / VictoriaMetrics-тэй тэнцвэржүүлэх үйл ажиллагаа нь маш хэцүү бөгөөд маш их цаг хугацаа шаарддаг гэж би хэлж чадна (эдгээр нэр томъёог хашилтанд оруулсан болно, учир нь бараг байдаг. PromQL-д ийм зүйл байхгүй бөгөөд та аймшигтай асуултуудыг текстийн хэд хэдэн дэлгэц болгон хувааж, оновчтой болгох хэрэгтэй).
Үүний үр дүнд хөгжүүлэгчид Cube-д өөрсдийн нэрийн орон зайг хянах хэрэгсэлтэй болж, хаана, ямар үед ямар програм хангамжийн нөөцөө "тасах", ямар серверт бүхэл бүтэн CPU-г шөнөжин өгөх боломжтойг өөрсдөө сонгох боломжтой.
Арга зүй
Компанид одоогийнх шиг загварлаг, бид DevOps-ийг дагаж мөрддөг- болон SRE- дадлагажигч Компани нь 1000 бичил үйлчилгээ, 350 орчим хөгжүүлэгчид, бүхэл бүтэн дэд бүтцийн 15 админтай бол та "моод байх" хэрэгтэй: энэ бүх "суурь үгс" -ийн ард бүх зүйлийг, хүн бүрийг автоматжуулах яаралтай хэрэгцээ байгаа бөгөөд админууд нь саад тотгор учруулах ёсгүй. процессуудад.
Ops-ийн хувьд бид үйлчилгээний хариуны хувь хэмжээ, алдаатай холбоотой янз бүрийн хэмжигдэхүүн, хяналтын самбарыг хөгжүүлэгчдэд өгдөг.
Бид дараах аргуудыг ашигладаг. , и тэдгээрийг нэгтгэх замаар. Бид хяналтын самбарын тоог багасгахыг хичээдэг бөгөөд ингэснээр ямар үйлчилгээ одоогоор доройтож байгаа нь тодорхой харагдах болно (жишээлбэл, секундэд хариу өгөх код, хариу өгөх хугацаа 99 хувь) гэх мэт. Ерөнхий хяналтын самбарт зарим шинэ хэмжигдэхүүн шаардлагатай болмогц бид тэдгээрийг шууд зурж, нэмдэг.
Би нэг сар график зураагүй. Энэ нь магадгүй сайн шинж тэмдэг юм: энэ нь ихэнх "хүсэл" аль хэдийн биелсэн гэсэн үг юм. Долоо хоногийн турш би өдөрт дор хаяж нэг удаа шинэ график зурдаг байсан.
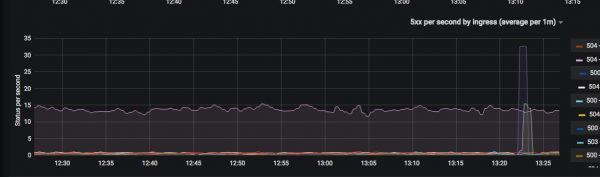
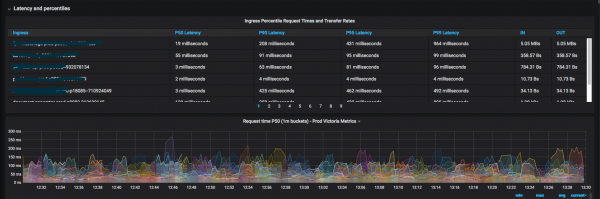
Үүний үр дүнд гарсан үр дүн нь үнэ цэнэтэй юм, учир нь одоо хөгжүүлэгчид админ руу "ямар нэгэн хэмжигдэхүүнийг хаанаас үзэх вэ" гэсэн асуултаар маш ховор ханддаг.
Хэрэгжүүлэлт Үйлчилгээний тор Энэ нь яг л булан тойронд байгаа бөгөөд хүн бүрийн амьдралыг илүү хялбар болгох ёстой тул Tools-ийн хамт олон "Эрүүл хүний хүсэлт" хийсвэрийг хэрэгжүүлэхэд аль хэдийн ойрхон байна: HTTP(үүд) хүсэлт бүрийн амьдралын мөчлөг хяналтанд харагдах болно. Үйлчилгээ хоорондын (зөвхөн биш) харилцан үйлчлэлийн явцад "ямар үе шатанд бүх зүйл эвдэрсэн" гэдгийг ойлгох боломжтой байх болно. DomClick төвийн мэдээнд бүртгүүлээрэй. =)
Kubernetes дэд бүтцийн дэмжлэг
Түүхийн хувьд бид нөхөөстэй хувилбарыг ашигладаг Кубеспрай — Kubernetes-ийг байршуулах, өргөтгөх, шинэчлэх чухал үүрэг. Хэзээ нэгэн цагт kubeadm бус суулгацын дэмжлэгийг үндсэн салбараас тасалж, kubeadm руу шилжих үйл явцыг санал болгоогүй. Үүний үр дүнд Southbridge компани өөрөө сэрээ хийсэн (kubeadm-ийн дэмжлэгтэйгээр, чухал асуудлуудыг хурдан засах боломжтой).
Бүх k8s кластеруудыг шинэчлэх үйл явц дараах байдалтай байна.
- Авах Кубеспрай Southbridge-аас манай утастай Мержимтэй холбогдоорой.
- Бид шинэчлэлтийг гаргаж байна Стресс- "Шоо".
- Бид шинэчлэлтийг нэг нэгээр нь гаргадаг (Ansible-д энэ нь "цуврал: 1") дотор Дев- "Шоо".
- Бид шинэчилж байна бүтээгдэхүүний бямба гарагийн орой нэг удаад нэг зангилаа.
Цаашид солих төлөвлөгөөтэй байгаа Кубеспрай илүү хурдан ямар нэг зүйлийн төлөө, явах kubeadm.
Бидэнд нийтдээ гурван "шоо" бий: Стресс, Хөгжүүлэлт, Үйлдвэрлэл. Бид өөр нэгийг гаргахаар төлөвлөж байна (халуун зогсолт) Хоёр дахь дата төвд бүтээгдэхүүн-“Cube”. Стресс и Дев "виртуал машинууд"-д (oVirt for Stress болон VMWare cloud for Dev) амьдардаг. бүтээгдэхүүний- "Шоо" нь "нүцгэн металл" дээр амьдардаг: эдгээр нь 32 CPU утас, 64-128 ГБ санах ой, 300 ГБ SSD RAID 10 бүхий ижил зангилаа бөгөөд нийтдээ 50 ширхэг байдаг. Гурван "нимгэн" зангилаа нь "мастер" -д зориулагдсан болно. бүтээгдэхүүний- "Куба": 16 ГБ санах ой, 12 CPU утас.
Борлуулалтын хувьд бид "нүцгэн металл" ашиглахыг илүүд үзэж, шаардлагагүй давхаргаас зайлсхийхийг илүүд үздэг OpenStack програм: бидэнд "шуугиантай хөршүүд" болон CPU хэрэггүй цаг хулгайлах. Дотоодын OpenStack-ийн хувьд удирдлагын нарийн төвөгтэй байдал ойролцоогоор хоёр дахин нэмэгддэг.
CI/CD "Cubic" болон бусад дэд бүтцийн бүрэлдэхүүн хэсгүүдийн хувьд бид тусдаа GIT серверийг ашигладаг Helm 3 (энэ нь Helm 2-ээс нэлээд хэцүү шилжилт байсан, гэхдээ бид сонголтуудад маш их баяртай байна. атомын), Женкинс, Ансибл, Докер. Бид функцийн салбарууд болон нэг репозитороос өөр өөр орчинд байршуулах дуртай.
дүгнэлт

Үйл ажиллагааны инженерийн өнцгөөс харахад энэ нь ерөнхийдөө DomClick дээр DevOps процесс ямар харагддаг вэ. Нийтлэл миний бодож байснаас бага техникийн шинжтэй болсон тул Habré дээрх DomClick мэдээг дагаж мөрдөөрэй: Кубернетес болон бусад зүйлсийн талаар "хатуу" нийтлэлүүд гарах болно.
Эх сурвалж: www.habr.com
