

Нийтлэлд энгийн (хосолсон) регрессийн шугамын математик тэгшитгэлийг тодорхойлох хэд хэдэн аргыг авч үзнэ.
Энд авч үзсэн тэгшитгэлийг шийдэх бүх аргууд нь хамгийн бага квадратын арга дээр суурилдаг. Аргуудыг дараах байдлаар тэмдэглэе.
- Аналитик шийдэл
- Градиент уналт
- Стохастик градиент уналт
Шулуун шугамын тэгшитгэлийг шийдвэрлэх арга бүрийн хувьд нийтлэлд янз бүрийн функцуудыг өгдөг бөгөөд эдгээрийг ихэвчлэн номын сан ашиглахгүйгээр бичсэн функцүүдэд хуваадаг. Тоон болон тооцоололд ашигладаг хүмүүс Тоон. Энэ нь чадварлаг ашиглах гэж үздэг Тоон тооцоолох зардлыг бууруулна.
Нийтлэлд өгөгдсөн бүх кодыг хэлээр бичсэн болно питон 2.7 ашиглаж байгаа Jupyter тэмдэглэлийн дэвтэр. Эх код болон жишээ өгөгдөл бүхий файлыг нийтэлсэн
Энэхүү нийтлэл нь анхлан суралцагчид болон хиймэл оюун ухааны маш өргөн хүрээтэй хэсэг болох машин сургалтын талаар аажмаар суралцаж эхэлсэн хүмүүст зориулагдсан болно.
Материалыг харуулахын тулд бид маш энгийн жишээг ашигладаг.
Жишээ нөхцөл
Бид хараат байдлыг тодорхойлдог таван үнэт зүйлтэй Y нь X (Хүснэгт No1):
Хүснэгт No1 “Жишээ нөхцөл”

Бид үнэт зүйлс гэж таамаглах болно  жилийн сар бөгөөд
жилийн сар бөгөөд  - энэ сарын орлого. Өөрөөр хэлбэл, орлого нь тухайн жилийн сараас хамаардаг ба
- энэ сарын орлого. Өөрөөр хэлбэл, орлого нь тухайн жилийн сараас хамаардаг ба  - орлого хамаарах цорын ганц тэмдэг.
- орлого хамаарах цорын ганц тэмдэг.
Орлогын жилийн сарнаас нөхцөлт хамаарлын үүднээс ч, утгын тооны хувьд ч ийм жишээтэй - эдгээр нь маш цөөхөн байдаг. Гэсэн хэдий ч ийм хялбарчлах нь тэдний хэлснээр эхлэгчдэд шингэсэн материалыг хялбархан тайлбарлах боломжийг олгоно. Мөн тоонуудын энгийн байдал нь жишээг цаасан дээр гаргахыг хүссэн хүмүүст ихээхэн хэмжээний хөдөлмөрийн зардал гаргахгүй байх боломжийг олгоно.
Жишээнд өгөгдсөн хамаарлыг дараах хэлбэрийн энгийн (хосолсон) регрессийн шугамын математик тэгшитгэлээр нэлээд сайн ойролцоолж болно гэж үзье.

хаана  орлого хүлээн авсан сар,
орлого хүлээн авсан сар,  - тухайн сард тохирсон орлого;
- тухайн сард тохирсон орлого;  и
и  тооцоолсон шугамын регрессийн коэффициентүүд юм.
тооцоолсон шугамын регрессийн коэффициентүүд юм.
коэффициент гэдгийг анхаарна уу  ихэвчлэн тооцоолсон шугамын налуу эсвэл налуу гэж нэрлэдэг; ямар дүнг илэрхийлнэ
ихэвчлэн тооцоолсон шугамын налуу эсвэл налуу гэж нэрлэдэг; ямар дүнг илэрхийлнэ  өөрчлөгдөхөд
өөрчлөгдөхөд  .
.
Мэдээжийн хэрэг, жишээн дээрх бидний даалгавар бол тэгшитгэлд ийм коэффициентийг сонгох явдал юм  и
и  , энэ үед бидний тооцоолсон орлогын утгуудын бодит хариултаас сараар хазайлт, өөрөөр хэлбэл. түүвэрт үзүүлсэн утга нь хамгийн бага байх болно.
, энэ үед бидний тооцоолсон орлогын утгуудын бодит хариултаас сараар хазайлт, өөрөөр хэлбэл. түүвэрт үзүүлсэн утга нь хамгийн бага байх болно.
Хамгийн бага квадрат арга
Хамгийн бага квадратын аргын дагуу хазайлтыг квадратаар тооцоолох хэрэгтэй. Энэ техник нь эсрэг шинж тэмдэгтэй бол хазайлтыг харилцан цуцлахаас зайлсхийх боломжийг олгодог. Жишээлбэл, хэрэв нэг тохиолдолд хазайлт байна +5 (нэмэх тав), нөгөөд нь -5 (хасах тав), дараа нь хазайлтын нийлбэр нь бие биенээ арилгаж, 0 (тэг) болно. Энэ нь хазайлтыг квадрат болгохгүй, харин модулийн өмчийг ашиглах боломжтой бөгөөд дараа нь бүх хазайлт эерэг байх бөгөөд хуримтлагдах болно. Бид энэ талаар дэлгэрэнгүй ярихгүй, гэхдээ тооцооллыг хялбар болгохын тулд хазайлтыг квадрат болгох нь заншилтай гэдгийг зүгээр л хэлье.
Бид квадрат хазайлтын (алдаа) хамгийн бага нийлбэрийг тодорхойлох томъёо нь иймэрхүү харагдаж байна:

хаана  үнэн хариултын ойролцоо функц (өөрөөр хэлбэл бидний тооцоолсон орлого),
үнэн хариултын ойролцоо функц (өөрөөр хэлбэл бидний тооцоолсон орлого),
 үнэн хариултууд (түүвэрт оруулсан орлого),
үнэн хариултууд (түүвэрт оруулсан орлого),
 түүвэр индекс (хазайлтыг тодорхойлсон сарын тоо)
түүвэр индекс (хазайлтыг тодорхойлсон сарын тоо)
Функцийг ялгаж, хэсэгчилсэн дифференциал тэгшитгэлийг тодорхойлж, аналитик шийдэл рүү шилжихэд бэлэн байцгаая. Гэхдээ эхлээд ялгаа гэж юу болох талаар богино аялал хийж, деривативын геометрийн утгыг санацгаая.
Ялгаварлах
Дифференциал гэдэг нь функцийн деривативыг олох үйлдэл юм.
Деривативыг юунд ашигладаг вэ? Функцийн дериватив нь функцийн өөрчлөлтийн хурдыг тодорхойлж, түүний чиглэлийг хэлж өгдөг. Хэрэв тухайн цэг дээрх дериватив эерэг байвал функц өснө, үгүй бол функц буурна. Үнэмлэхүй деривативын утга их байх тусам функцийн утгын өөрчлөлтийн хурд өндөр байхаас гадна функцийн графикийн налуу өндөр байх болно.
Жишээлбэл, декартын координатын системийн нөхцөлд M(0,0) цэг дээрх деривативын утга нь тэнцүү байна. + 25 өгөгдсөн цэг дээр утгыг шилжүүлэх үед гэсэн үг  баруун тийш ердийн нэгжээр, утга
баруун тийш ердийн нэгжээр, утга  25 ердийн нэгжээр нэмэгддэг. График дээр энэ нь үнэ цэнийн нэлээд огцом өсөлттэй харагдаж байна
25 ердийн нэгжээр нэмэгддэг. График дээр энэ нь үнэ цэнийн нэлээд огцом өсөлттэй харагдаж байна  өгөгдсөн цэгээс.
өгөгдсөн цэгээс.
Өөр нэг жишээ. Дериватив утга нь тэнцүү байна -0,1 нүүлгэн шилжүүлэх үед гэсэн үг  нэг уламжлалт нэгжийн үнэ цэнэ
нэг уламжлалт нэгжийн үнэ цэнэ  зөвхөн 0,1 ердийн нэгжээр буурдаг. Үүний зэрэгцээ функцын график дээр бид бараг мэдэгдэхүйц доош налууг ажиглаж болно. Уултай зүйрлэвэл бид маш эгц оргилд авирах ёстой байсан өмнөх жишээнээс ялгаатай нь уулнаас зөөлөн энгэрээр маш аажуухан уруудаж байгаа юм шиг :)
зөвхөн 0,1 ердийн нэгжээр буурдаг. Үүний зэрэгцээ функцын график дээр бид бараг мэдэгдэхүйц доош налууг ажиглаж болно. Уултай зүйрлэвэл бид маш эгц оргилд авирах ёстой байсан өмнөх жишээнээс ялгаатай нь уулнаас зөөлөн энгэрээр маш аажуухан уруудаж байгаа юм шиг :)
Тиймээс функцийг ялгасны дараа  магадлалаар
магадлалаар  и
и  , бид 1-р эрэмбийн хэсэгчилсэн дифференциал тэгшитгэлийг тодорхойлно. Тэгшитгэлийг тодорхойлсны дараа бид хоёр тэгшитгэлийн системийг хүлээн авах бөгөөд үүнийг шийдснээр бид коэффициентүүдийн ийм утгыг сонгох боломжтой болно.
, бид 1-р эрэмбийн хэсэгчилсэн дифференциал тэгшитгэлийг тодорхойлно. Тэгшитгэлийг тодорхойлсны дараа бид хоёр тэгшитгэлийн системийг хүлээн авах бөгөөд үүнийг шийдснээр бид коэффициентүүдийн ийм утгыг сонгох боломжтой болно.  и
и  , өгөгдсөн цэгүүд дэх харгалзах деривативын утга нь маш бага хэмжээгээр өөрчлөгддөг бөгөөд аналитик уусмалын хувьд огт өөрчлөгддөггүй. Өөрөөр хэлбэл, олсон коэффициент дэх алдааны функц нь хамгийн багадаа хүрэх болно, учир нь эдгээр цэгүүд дэх хэсэгчилсэн деривативын утга тэгтэй тэнцүү байх болно.
, өгөгдсөн цэгүүд дэх харгалзах деривативын утга нь маш бага хэмжээгээр өөрчлөгддөг бөгөөд аналитик уусмалын хувьд огт өөрчлөгддөггүй. Өөрөөр хэлбэл, олсон коэффициент дэх алдааны функц нь хамгийн багадаа хүрэх болно, учир нь эдгээр цэгүүд дэх хэсэгчилсэн деривативын утга тэгтэй тэнцүү байх болно.
Тиймээс, ялгах дүрмийн дагуу коэффициентийн хувьд 1-р эрэмбийн хэсэгчилсэн дериватив тэгшитгэл.  хэлбэрийг авна:
хэлбэрийг авна:

-д хамаарах 1-р эрэмбийн хэсэгчилсэн дериватив тэгшитгэл  хэлбэрийг авна:
хэлбэрийг авна:

Үүний үр дүнд бид нэлээд энгийн аналитик шийдэл бүхий тэгшитгэлийн системийг хүлээн авлаа.
эхлэл{тэгшитгэл*}
эхлэх{тохиолдол}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
төгсгөл{тохиолдол}
төгсгөл{тэгшитгэл*}
Тэгшитгэлийг шийдэхийн өмнө урьдчилан ачаалж, ачаалал зөв эсэхийг шалгаж, өгөгдлийг форматлаж үзье.
Өгөгдлийг ачаалах, форматлах
Аналитик шийдэл, дараа нь градиент ба стохастик градиент уналтын хувьд бид кодыг хоёр хувилбараар ашиглах болно гэдгийг тэмдэглэх нь зүйтэй: номын санг ашиглах. Тоон Үүнийг ашиглахгүйгээр бид зохих өгөгдлийг форматлах шаардлагатай болно (кодыг үзнэ үү).
Өгөгдөл ачаалах, боловсруулах код
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'Дүрслэх
Одоо бид нэгдүгээрт, өгөгдлийг ачаалсны дараа, хоёрдугаарт, ачааллын зөв эсэхийг шалгаж, эцэст нь өгөгдлийг форматласны дараа бид эхний дүрслэлийг хийх болно. Үүний тулд ихэвчлэн ашигладаг арга хос зураг номын сангууд Далайн төрсөн. Бидний жишээн дээр тоо хязгаарлагдмал учраас номын сан ашиглах нь утгагүй юм Далайн төрсөн. Бид ердийн номын санг ашиглах болно Матплотлиб мөн зүгээр л тархалтын графикийг хараарай.
Тархалтын код
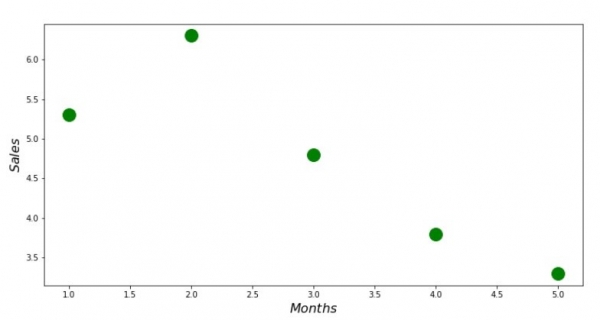
print 'График №1 "Зависимость выручки от месяца года"'
plt.plot(x_us,y_us,'o',color='green',markersize=16)
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.show()График No1 “Орлогын тухайн оны сараас хамаарах байдал”
Аналитик шийдэл
Хамгийн түгээмэл хэрэглүүрүүдийг авч үзье Python тэгшитгэлийн системийг шийд:
эхлэл{тэгшитгэл*}
эхлэх{тохиолдол}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
төгсгөл{тохиолдол}
төгсгөл{тэгшитгэл*}
Крамерын дүрмийн дагуу бид ерөнхий тодорхойлогч, түүнчлэн тодорхойлогчийг олох болно  болон өөр
болон өөр  , үүний дараа тодорхойлогчийг хуваана
, үүний дараа тодорхойлогчийг хуваана  ерөнхий тодорхойлогч руу - коэффициентийг ол
ерөнхий тодорхойлогч руу - коэффициентийг ол  , ижил төстэй байдлаар бид коэффициентийг олдог
, ижил төстэй байдлаар бид коэффициентийг олдог  .
.
Аналитик шийдлийн код
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)Эндээс бидэнд юу байна:

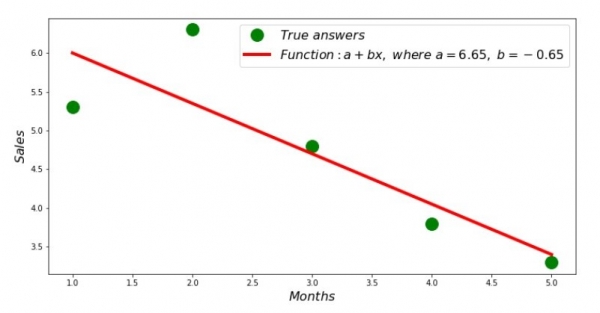
Тиймээс коэффициентүүдийн утгыг олж, квадрат хазайлтын нийлбэрийг тогтоов. Олдсон коэффициентүүдийн дагуу сарнилын гистограмм дээр шулуун шугам зуръя.
Регрессийн мөрийн код
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()График No2 "Зөв, тооцоолсон хариултууд"
Та сар бүрийн хазайлтын графикийг харж болно. Манай тохиолдолд бид үүнээс ямар ч чухал практик үнэ цэнийг олж авахгүй, гэхдээ энгийн шугаман регрессийн тэгшитгэл нь орлогын тухайн оны сараас хамааралтай байдлыг хэр сайн тодорхойлдог тухай сонирхлыг хангах болно.
Хазайх графикийн код
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()График No3 “Хазайлт, %”
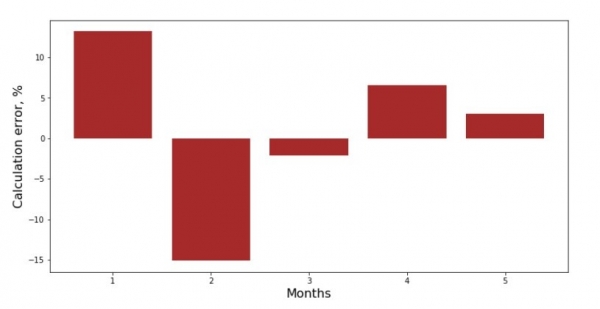
Төгс биш ч бид даалгавраа биелүүлсэн.
Коэффициентийг тодорхойлох функцийг бичье  и
и  номын санг ашигладаг Тоон, илүү нарийвчлалтайгаар бид хоёр функцийг бичих болно: нэг нь псевдоурвуу матриц (процесс нь тооцоолоход төвөгтэй бөгөөд тогтворгүй байдаг тул практикт хэрэглэхийг зөвлөдөггүй), нөгөө нь матрицын тэгшитгэлийг ашиглана.
номын санг ашигладаг Тоон, илүү нарийвчлалтайгаар бид хоёр функцийг бичих болно: нэг нь псевдоурвуу матриц (процесс нь тооцоолоход төвөгтэй бөгөөд тогтворгүй байдаг тул практикт хэрэглэхийг зөвлөдөггүй), нөгөө нь матрицын тэгшитгэлийг ашиглана.
Аналитик шийдлийн код (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npКоэффициентийг тодорхойлоход зарцуулсан хугацааг харьцуулж үзье  и
и  , танилцуулсан 3 аргын дагуу.
, танилцуулсан 3 аргын дагуу.
Тооцооллын хугацааг тооцоолох код
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов без использования библиотеки NumPy:" + ' 33[0m'
% timeit ab_us = Kramer_method(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием псевдообратной матрицы:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием матричного уравнения:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
Бага хэмжээний өгөгдөлтэй бол "өөрөө бичсэн" функц гарч ирдэг бөгөөд энэ нь Крамерын аргыг ашиглан коэффициентийг олдог.
Одоо та коэффициентийг олох өөр аргууд руу шилжиж болно  и
и  .
.
Градиент уналт
Эхлээд градиент гэж юу болохыг тодорхойлъё. Энгийнээр хэлбэл, градиент нь функцийн хамгийн их өсөлтийн чиглэлийг заадаг сегмент юм. Ууланд авирахтай зүйрлэвэл градиент нь уулын оройд хамгийн эгц авирсан газар байдаг. Уулын жишээг боловсруулахдаа бид нам дор газарт аль болох хурдан хүрэхийн тулд хамгийн эгц уруудах хэрэгтэй, өөрөөр хэлбэл функц нь нэмэгдэж, буурахгүй байх ёстой гэдгийг бид санаж байна. Энэ үед дериватив нь тэгтэй тэнцүү байх болно. Тиймээс бидэнд градиент хэрэггүй, харин эсрэг градиент хэрэгтэй. Антиградиентийг олохын тулд градиентийг үржүүлэхэд л хангалттай -1 (хасах нэг).
Функц нь хэд хэдэн минимумтай байж болох бөгөөд доор санал болгож буй алгоритмыг ашиглан тэдгээрийн аль нэгэнд нь бууж өгснөөр бид өөр минимумыг олох боломжгүй бөгөөд энэ нь олдсоноос доогуур байж магадгүй гэдгийг анхаарна уу. Тайвширцгаая, энэ нь бидэнд аюул занал учруулахгүй! Манай тохиолдолд бид өөрсдийн үйл ажиллагаанаас хойш нэг доод талтай харьцаж байна  график дээр ердийн парабол байна. Бид бүгд сургуулийнхаа математикийн хичээлээс маш сайн мэдэх ёстой учраас парабола нь зөвхөн нэг минимумтай байдаг.
график дээр ердийн парабол байна. Бид бүгд сургуулийнхаа математикийн хичээлээс маш сайн мэдэх ёстой учраас парабола нь зөвхөн нэг минимумтай байдаг.
Бид яагаад градиент хэрэгтэй байгааг олж мэдсэний дараа градиент нь сегмент, өөрөөр хэлбэл өгөгдсөн координат бүхий вектор бөгөөд яг ижил коэффициентүүд юм.  и
и  бид градиент уналтыг хэрэгжүүлж чадна.
бид градиент уналтыг хэрэгжүүлж чадна.
Эхлэхээсээ өмнө би буух алгоритмын талаар хэдхэн өгүүлбэр уншихыг санал болгож байна.
- Бид коэффициентүүдийн координатыг псевдо-санамсаргүй байдлаар тодорхойлдог
 и . Бидний жишээн дээр бид тэгтэй ойролцоо коэффициентийг тодорхойлох болно. Энэ бол нийтлэг практик боловч тохиолдол бүр өөрийн гэсэн практиктай байж болно.
и . Бидний жишээн дээр бид тэгтэй ойролцоо коэффициентийг тодорхойлох болно. Энэ бол нийтлэг практик боловч тохиолдол бүр өөрийн гэсэн практиктай байж болно. - Координатаас цэг дээрх 1-р эрэмбийн хэсэгчилсэн деривативын утгыг хасна . Тэгэхээр дериватив эерэг байвал функц нэмэгдэнэ. Тиймээс деривативын утгыг хасснаар бид өсөлтийн эсрэг чиглэлд, өөрөөр хэлбэл буурах чиглэлд шилжих болно. Хэрэв дериватив нь сөрөг байвал энэ цэг дэх функц буурч, деривативын утгыг хасснаар бид буурах чиглэлд шилжинэ.
- Бид ижил төстэй үйлдлийг координатаар гүйцэтгэдэг : цэг дээрх хэсэгчилсэн деривативын утгыг хасна .
- Хамгийн багадаа үсэрч, гүн гүнзгий сансарт нисэхгүйн тулд буух чиглэлд алхамын хэмжээг тохируулах шаардлагатай. Ерөнхийдөө та тооцооллын зардлыг бууруулахын тулд алхамыг хэрхэн зөв тохируулах, буух явцад хэрхэн өөрчлөх талаар бүхэл бүтэн нийтлэл бичиж болно. Харин одоо бидний өмнө арай өөр даалгавар байгаа бөгөөд бид алхамын хэмжээг шинжлэх ухааны “нудрах” арга буюу тэдний хэлдгээр эмпирик байдлаар тогтоох болно.
- Бид өгөгдсөн координатаас гарсны дараа и Деривативын утгыг хасвал бид шинэ координатыг авна и . Бид тооцоолсон координатаас дараагийн алхамыг (хасах) хийдэг. Тиймээс шаардлагатай нэгдэлд хүрэх хүртэл мөчлөг дахин дахин эхэлдэг.
 и
и  . Бидний жишээн дээр бид тэгтэй ойролцоо коэффициентийг тодорхойлох болно. Энэ бол нийтлэг практик боловч тохиолдол бүр өөрийн гэсэн практиктай байж болно.
. Бидний жишээн дээр бид тэгтэй ойролцоо коэффициентийг тодорхойлох болно. Энэ бол нийтлэг практик боловч тохиолдол бүр өөрийн гэсэн практиктай байж болно. цэг дээрх 1-р эрэмбийн хэсэгчилсэн деривативын утгыг хасна
цэг дээрх 1-р эрэмбийн хэсэгчилсэн деривативын утгыг хасна  . Тэгэхээр дериватив эерэг байвал функц нэмэгдэнэ. Тиймээс деривативын утгыг хасснаар бид өсөлтийн эсрэг чиглэлд, өөрөөр хэлбэл буурах чиглэлд шилжих болно. Хэрэв дериватив нь сөрөг байвал энэ цэг дэх функц буурч, деривативын утгыг хасснаар бид буурах чиглэлд шилжинэ.
. Тэгэхээр дериватив эерэг байвал функц нэмэгдэнэ. Тиймээс деривативын утгыг хасснаар бид өсөлтийн эсрэг чиглэлд, өөрөөр хэлбэл буурах чиглэлд шилжих болно. Хэрэв дериватив нь сөрөг байвал энэ цэг дэх функц буурч, деривативын утгыг хасснаар бид буурах чиглэлд шилжинэ.  : цэг дээрх хэсэгчилсэн деривативын утгыг хасна
: цэг дээрх хэсэгчилсэн деривативын утгыг хасна  .
. и
и  Деривативын утгыг хасвал бид шинэ координатыг авна
Деривативын утгыг хасвал бид шинэ координатыг авна  и
и  . Бид тооцоолсон координатаас дараагийн алхамыг (хасах) хийдэг. Тиймээс шаардлагатай нэгдэлд хүрэх хүртэл мөчлөг дахин дахин эхэлдэг.
. Бид тооцоолсон координатаас дараагийн алхамыг (хасах) хийдэг. Тиймээс шаардлагатай нэгдэлд хүрэх хүртэл мөчлөг дахин дахин эхэлдэг.Бүгд! Одоо бид Мариана шуудууны хамгийн гүн хавцлыг хайхад бэлэн байна. Эхэлцгээе.
Градиент буурах код
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Бид Мариана шуудууны ёроолд шумбаж, тэндээс бүх коэффициентийн утгыг олсон  и
и  , энэ нь яг хүлээж байсан зүйл юм.
, энэ нь яг хүлээж байсан зүйл юм.
Дахиад шумбалт хийцгээе, зөвхөн энэ удаад л манай гүний хөлөг онгоц бусад технологиор, тухайлбал номын сангаар дүүрэн байх болно. Тоон.
Градиент буурах код (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Коэффициент утгууд  и
и  хувиршгүй.
хувиршгүй.
Градиент буурах үед алдаа хэрхэн өөрчлөгдсөнийг, өөрөөр хэлбэл алхам бүрт квадрат хазайлтын нийлбэр хэрхэн өөрчлөгдсөнийг харцгаая.
Квадрат хазайлтын нийлбэрийг зурах код
print 'График№4 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()График No4 “Градиент буурах үеийн квадрат хазайлтын нийлбэр”
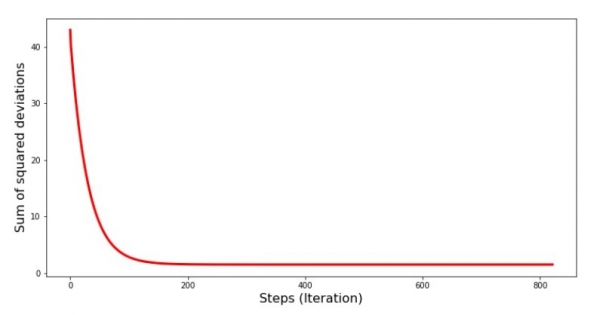
График дээр бид алхам бүрт алдаа багасч, тодорхой тооны давталтын дараа бид бараг хэвтээ шугамыг ажиглаж байгааг харж байна.
Эцэст нь кодыг гүйцэтгэх хугацааны зөрүүг тооцоолъё:
Градиент буурах тооцооны хугацааг тодорхойлох код
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска без использования библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска с использованием библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
Магадгүй бид буруу зүйл хийж байгаа байх, гэхдээ энэ нь номын сан ашигладаггүй энгийн "гэрээс бичсэн" функц юм. Тоон номын санг ашиглан функцийг тооцоолох хугацааг давж гарна Тоон.
Гэхдээ бид зүгээр зогсохгүй, энгийн шугаман регрессийн тэгшитгэлийг шийдэх өөр нэг сонирхолтой аргыг судлахаар явж байна. Уулз!
Стохастик градиент уналт
Стохастик градиент уналтын үйл ажиллагааны зарчмыг хурдан ойлгохын тулд түүний энгийн градиент уналтаас ялгааг тодорхойлох нь дээр. Бид градиент уналтын хувьд деривативын тэгшитгэлд  и
и  түүвэрт байгаа бүх шинж чанар, үнэн хариултуудын утгуудын нийлбэрийг ашигласан (өөрөөр хэлбэл бүх зүйлийн нийлбэр).
түүвэрт байгаа бүх шинж чанар, үнэн хариултуудын утгуудын нийлбэрийг ашигласан (өөрөөр хэлбэл бүх зүйлийн нийлбэр).  и
и  ). Стохастик градиент удмын хувьд бид түүвэрт байгаа бүх утгыг ашиглахгүй, харин түүврийн индекс гэж нэрлэгддэг псевдо санамсаргүй байдлаар сонгож, утгыг нь ашиглана.
). Стохастик градиент удмын хувьд бид түүвэрт байгаа бүх утгыг ашиглахгүй, харин түүврийн индекс гэж нэрлэгддэг псевдо санамсаргүй байдлаар сонгож, утгыг нь ашиглана.
Жишээлбэл, хэрэв индекс нь 3 (гурав) гэсэн тоогоор тодорхойлогдвол утгыг авна  и
и  , дараа нь бид утгуудыг дериватив тэгшитгэлд орлуулж, шинэ координатыг тодорхойлно. Дараа нь координатыг тодорхойлсны дараа бид түүврийн индексийг дахин псевдо-санамсаргүй байдлаар тодорхойлж, индекст харгалзах утгыг хэсэгчилсэн дифференциал тэгшитгэлд орлуулж, координатыг шинэ аргаар тодорхойлно.
, дараа нь бид утгуудыг дериватив тэгшитгэлд орлуулж, шинэ координатыг тодорхойлно. Дараа нь координатыг тодорхойлсны дараа бид түүврийн индексийг дахин псевдо-санамсаргүй байдлаар тодорхойлж, индекст харгалзах утгыг хэсэгчилсэн дифференциал тэгшитгэлд орлуулж, координатыг шинэ аргаар тодорхойлно.  и
и  гэх мэт. нэгдэл нь ногоон болж хувирах хүртэл. Эхлээд харахад энэ нь огт ажиллахгүй мэт санагдаж болох ч энэ нь тийм юм. Алдаа алхам тутамдаа багасдаггүй ч гэсэн хандлага байгаа нь үнэн.
гэх мэт. нэгдэл нь ногоон болж хувирах хүртэл. Эхлээд харахад энэ нь огт ажиллахгүй мэт санагдаж болох ч энэ нь тийм юм. Алдаа алхам тутамдаа багасдаггүй ч гэсэн хандлага байгаа нь үнэн.
Стохастик градиент уналт нь ердийнхөөс ямар давуу талтай вэ? Хэрэв бидний түүврийн хэмжээ маш том бөгөөд хэдэн арван мянган утгаараа хэмжигддэг бол түүврийг бүхэлд нь биш харин санамсаргүй мянгаар нь боловсруулах нь илүү хялбар байдаг. Эндээс стохастик градиент удам гарч ирдэг. Бидний хувьд мэдээжийн хэрэг бид тийм ч их ялгааг анзаарахгүй.
Кодыг харцгаая.
Стохастик градиент уналтын код
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
Бид коэффициентүүдийг анхааралтай ажиглаж, "Энэ яаж байж болох вэ?" Гэсэн асуултыг асуудаг. Бид бусад коэффициент утгыг авсан  и
и  . Магадгүй стохастик градиент уналт нь тэгшитгэлийн илүү оновчтой параметрүүдийг олсон уу? Харамсалтай нь үгүй. Квадрат хазайлтын нийлбэрийг харахад хангалттай бөгөөд коэффициентийн шинэ утгуудын хувьд алдаа илүү их байгааг олж хараарай. Бид цөхрөх гэж яарахгүй байна. Алдааны өөрчлөлтийн графикийг байгуулъя.
. Магадгүй стохастик градиент уналт нь тэгшитгэлийн илүү оновчтой параметрүүдийг олсон уу? Харамсалтай нь үгүй. Квадрат хазайлтын нийлбэрийг харахад хангалттай бөгөөд коэффициентийн шинэ утгуудын хувьд алдаа илүү их байгааг олж хараарай. Бид цөхрөх гэж яарахгүй байна. Алдааны өөрчлөлтийн графикийг байгуулъя.
Стохастик градиент удам дахь квадрат хазайлтын нийлбэрийг зурах код
print 'График №5 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()График No5 “Стохастик градиент буурах үеийн квадрат хазайлтын нийлбэр”
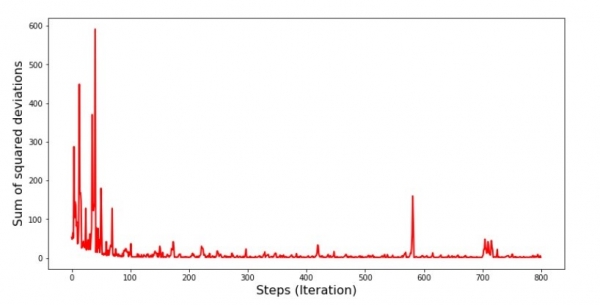
Хуваарийг харахад бүх зүйл байрандаа орж, одоо бид бүгдийг засах болно.
Тэгээд юу болсон бэ? Дараахь зүйл тохиолдсон. Бид нэг сарыг санамсаргүй байдлаар сонгох үед бидний алгоритм нь орлогыг тооцоолох алдааг багасгахыг эрэлхийлдэг. Дараа нь бид өөр сарыг сонгож, тооцооллыг давтан хийх боловч бид хоёр дахь сонгосон сарын алдааг багасгадаг. Одоо эхний хоёр сар энгийн шугаман регрессийн тэгшитгэлийн шугамаас ихээхэн хазайсан гэдгийг санаарай. Энэ нь эдгээр хоёр сарын аль нэгийг сонгохдоо тэдгээрийн алдааг бууруулснаар бидний алгоритм бүх түүврийн алдааг ноцтойгоор нэмэгдүүлдэг гэсэн үг юм. Тэгэхээр юу хийх вэ? Хариулт нь энгийн: та буух алхамыг багасгах хэрэгтэй. Эцсийн эцэст, буух алхамыг бууруулснаар алдаа нь дээш доош "үсрэх" зогсох болно. Өөрөөр хэлбэл, "үсрэх" алдаа зогсохгүй, гэхдээ тийм ч хурдан хийхгүй :) Шалгацгаая.
SGD-г бага багаар ажиллуулах код
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
График No6 “Стохастик градиент буурах үеийн квадрат хазайлтын нийлбэр (80 мянган алхам)”
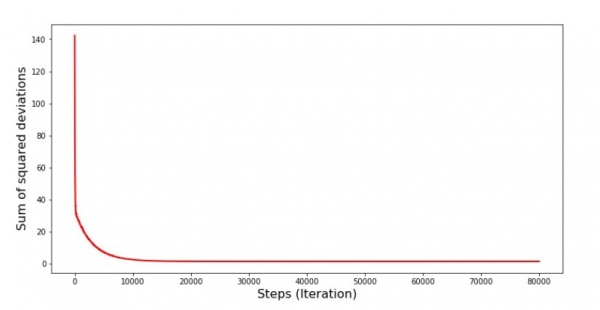
Коэффициентүүд сайжирсан боловч тийм ч тохиромжтой биш байна. Таамаглалаар үүнийг ингэж засаж болно. Жишээлбэл, бид сүүлийн 1000 давталт дээр хамгийн бага алдаа гаргасан коэффициентүүдийн утгыг сонгоно. Үнэн, үүний тулд бид коэффициентүүдийн утгыг өөрсдөө бичих хэрэгтэй болно. Бид үүнийг хийхгүй, харин хуваарьт анхаарлаа хандуулах болно. Энэ нь гөлгөр харагдах бөгөөд алдаа нь жигд буурч байх шиг байна. Үнэндээ энэ нь үнэн биш юм. Эхний 1000 давталтыг харж, сүүлчийнхтэй нь харьцуулцгаая.
SGD графикийн код (эхний 1000 алхам)
print 'График №7 "Сумма квадратов отклонений по-шагово. Первые 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
print 'График №7 "Сумма квадратов отклонений по-шагово. Последние 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()График No7 “SGD квадрат хазайлтын нийлбэр (эхний 1000 алхам)”
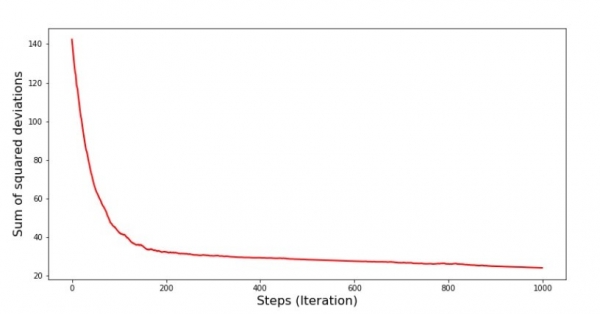
График No8 “SGD квадрат хазайлтын нийлбэр (сүүлийн 1000 алхам)”
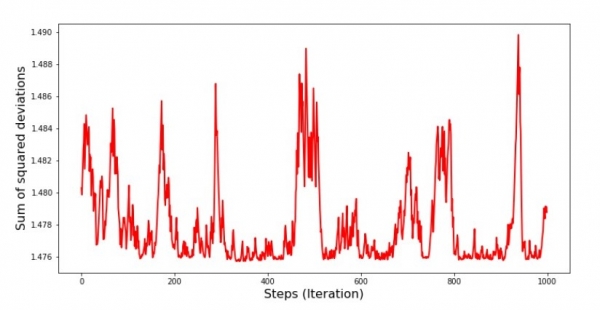
Уналтын эхэн үед бид алдаа нэлээд жигд, огцом буурч байгааг ажиглаж байна. Сүүлийн давталтуудад алдаа нь 1,475-ийн утгыг тойрч, зарим үед энэ оновчтой утгатай тэнцэж байгааг бид харж байна, гэхдээ дараа нь энэ нь нэмэгдсээр байна ... Би давтан хэлье, та утгуудыг бичиж болно. коэффициентүүд  и
и  , дараа нь алдаа багатайг сонгоно уу. Гэсэн хэдий ч бидэнд илүү ноцтой асуудал тулгарсан: оновчтой утгыг авахын тулд бид 80 мянган алхам хийх шаардлагатай болсон (кодыг үзнэ үү). Мөн энэ нь градиент уналттай харьцуулахад стохастик градиент уналтаар тооцоолох цагийг хэмнэх санаатай аль хэдийн зөрчилдөж байна. Юуг засч, сайжруулах боломжтой вэ? Эхний давталтуудад бид итгэлтэйгээр доошилж байгааг анзаарахад хэцүү биш тул эхний давталтуудад том алхам үлдээж, урагшлахдаа алхамыг багасгах хэрэгтэй. Бид энэ нийтлэлд үүнийг хийхгүй - энэ нь хэтэрхий урт байна. Хүссэн хүмүүс үүнийг яаж хийхийг өөрсдөө бодож болно, энэ нь хэцүү биш :)
, дараа нь алдаа багатайг сонгоно уу. Гэсэн хэдий ч бидэнд илүү ноцтой асуудал тулгарсан: оновчтой утгыг авахын тулд бид 80 мянган алхам хийх шаардлагатай болсон (кодыг үзнэ үү). Мөн энэ нь градиент уналттай харьцуулахад стохастик градиент уналтаар тооцоолох цагийг хэмнэх санаатай аль хэдийн зөрчилдөж байна. Юуг засч, сайжруулах боломжтой вэ? Эхний давталтуудад бид итгэлтэйгээр доошилж байгааг анзаарахад хэцүү биш тул эхний давталтуудад том алхам үлдээж, урагшлахдаа алхамыг багасгах хэрэгтэй. Бид энэ нийтлэлд үүнийг хийхгүй - энэ нь хэтэрхий урт байна. Хүссэн хүмүүс үүнийг яаж хийхийг өөрсдөө бодож болно, энэ нь хэцүү биш :)
Одоо номын санг ашиглан стохастик градиент уналтыг хийцгээе Тоон (мөн бидний өмнө нь тодорхойлсон чулуунууд дээр бүдрэх хэрэггүй)
Стохастик градиент удмын код (NumPy)
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
Утга нь ашиглахгүйгээр буухтай бараг ижил байв Тоон. Гэсэн хэдий ч энэ нь логик юм.
Стохастик градиентийн уналт биднийг хэр удаан үргэлжилсэнийг олж мэдье.
SGD тооцоолох хугацааг тодорхойлох код (80 мянган алхам)
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска без использования библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска с использованием библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
Ойд ойртох тусам үүл бараан болно: дахин "өөрөө бичсэн" томъёо нь хамгийн сайн үр дүнг харуулж байна. Энэ бүхэн номын санг ашиглах бүр ч нарийн арга зам байх ёстойг харуулж байна Тоон, энэ нь тооцооллын үйл ажиллагааг үнэхээр хурдасгадаг. Энэ нийтлэлд бид тэдний талаар суралцахгүй. Чөлөөт цагаараа бодох зүйл байх болно :)
Дүгнэж хэлье
Дүгнэлт хийхээсээ өмнө би эрхэм уншигчийн маань асуусан асуултанд хариулахыг хүсч байна. Чухамдаа яагаад ийм "эрүү шүүлт"-ээр "эрүү шүүлт"-ээр унадаг вэ, хэрэв бидний гарт ийм хүчирхэг, энгийн төхөөрөмж байгаа бол нандин нам дор газрыг олохын тулд яагаад уулыг өгсөж, уруудах (ихэвчлэн доошоо) явах хэрэгтэй вэ? Биднийг зөв газар руу шууд дамжуулдаг аналитик шийдлийн хэлбэр үү?
Энэ асуултын хариулт нь гадаргуу дээр байгаа. Одоо бид үнэн хариулт болох маш энгийн жишээг харлаа  нэг тэмдгээс хамаарна
нэг тэмдгээс хамаарна  . Та үүнийг амьдралд тийм ч олон удаа хардаггүй тул бидэнд 2, 30, 50 ба түүнээс дээш тэмдэг байна гэж төсөөлөөд үз дээ. Энэ шинж чанар бүрийн хувьд мянга, бүр хэдэн арван мянган утгыг нэмье. Энэ тохиолдолд аналитик шийдэл нь туршилтыг тэсвэрлэхгүй бөгөөд амжилтгүй болно. Хариуд нь градиент уналт ба түүний өөрчлөлтүүд нь биднийг зорилгодоо ойртуулах болно - хамгийн бага функц. Мөн хурдны талаар санаа зовох хэрэггүй - бид алхамын уртыг (өөрөөр хэлбэл хурд) тохируулах, зохицуулах арга замыг авч үзэх болно.
. Та үүнийг амьдралд тийм ч олон удаа хардаггүй тул бидэнд 2, 30, 50 ба түүнээс дээш тэмдэг байна гэж төсөөлөөд үз дээ. Энэ шинж чанар бүрийн хувьд мянга, бүр хэдэн арван мянган утгыг нэмье. Энэ тохиолдолд аналитик шийдэл нь туршилтыг тэсвэрлэхгүй бөгөөд амжилтгүй болно. Хариуд нь градиент уналт ба түүний өөрчлөлтүүд нь биднийг зорилгодоо ойртуулах болно - хамгийн бага функц. Мөн хурдны талаар санаа зовох хэрэггүй - бид алхамын уртыг (өөрөөр хэлбэл хурд) тохируулах, зохицуулах арга замыг авч үзэх болно.
Тэгээд одоо бодит товч хураангуй.
Нэгдүгээрт, нийтлэлд танилцуулсан материал нь энгийн (зөвхөн биш) шугаман регрессийн тэгшитгэлийг хэрхэн шийдвэрлэхийг ойлгоход "өгөгдлийн эрдэмтэд"-д тусална гэж найдаж байна.
Хоёрдугаарт, бид тэгшитгэлийг шийдэх хэд хэдэн арга замыг авч үзсэн. Одоо бид нөхцөл байдлаас шалтгаалан асуудлыг шийдвэрлэхэд хамгийн тохиромжтойг нь сонгож болно.
Гуравдугаарт, бид нэмэлт тохиргооны хүч, тухайлбал градиент уруудах алхамын уртыг харсан. Энэ параметрийг үл тоомсорлож болохгүй. Дээр дурдсанчлан тооцооллын зардлыг бууруулахын тулд буух үед алхамын уртыг өөрчлөх шаардлагатай.
Дөрөвдүгээрт, манай тохиолдолд "гэрээр бичсэн" функцууд нь тооцооллын хамгийн сайн цаг хугацааны үр дүнг харуулсан. Энэ нь номын сангийн чадавхийг мэргэжлийн түвшинд ашиглаагүйтэй холбоотой байх Тоон. Гэсэн хэдий ч, дараах дүгнэлт нь өөрийгөө харуулж байна. Нэг талаас, заримдаа энэ нь тогтсон санал бодлыг эргэлзэх нь зүйтэй бөгөөд нөгөө талаас бүх зүйлийг төвөгтэй болгох нь үргэлж үнэ цэнэтэй зүйл биш юм - эсрэгээр заримдаа асуудлыг шийдэх илүү хялбар арга нь илүү үр дүнтэй байдаг. Бидний зорилго бол энгийн шугаман регрессийн тэгшитгэлийг шийдвэрлэх гурван аргыг шинжлэх явдал байсан тул "өөрөө бичсэн" функцийг ашиглах нь бидэнд хангалттай байсан.
Уран зохиол (эсвэл үүнтэй төстэй зүйл)
1. Шугаман регресс
2. Хамгийн бага квадратын арга
3. Дериватив
4. Gradient
5. Градиент уруудах
6. NumPy номын сан
Эх сурвалж: www.habr.com
