

Jadi, anda kumpulkan metrik. Dan begitu juga kita. Kami mengumpul metrik juga. Sudah tentu, yang berkaitan dengan perniagaan. Hari ini kami akan memberitahu anda tentang pautan pertama dalam sistem pemantauan kami—pelayan pengagregatan yang serasi dengan statsd. , mengapa kami menulisnya dan mengapa kami meninggalkan brubeck.
Daripada artikel kami sebelum ini (, ) anda boleh mengetahui bahawa sehingga beberapa ketika dahulu kami mengumpul tag menggunakan Ia ditulis dalam C. Ia semudah tetikus (yang penting apabila anda ingin menyumbang) dan, yang paling penting, mengendalikan volum puncak kami sebanyak 2 juta metrik sesaat (MPS) tanpa sebarang masalah. Dokumentasi tersebut mendakwa sokongan untuk 4 juta MPS dengan asterisk. Ini bermakna anda akan mendapat angka yang dinyatakan jika anda mengkonfigurasi rangkaian dengan betul. Linux(Kami tidak tahu berapa banyak MPS yang anda boleh dapat jika anda meninggalkan rangkaian seperti sedia ada.) Walaupun terdapat kelebihan ini, kami mempunyai beberapa aduan serius tentang brubeck.
Tuntutan 1. Github, pembangun projek, berhenti menyokongnya: menerbitkan patch dan pembetulan, menerima PR kami (dan lain-lain). Aktiviti telah disambung semula dalam beberapa bulan lepas (sekitar Februari-Mac 2018), tetapi sebelum itu hampir dua tahun senyap sepenuhnya. Tambahan pula, projek itu sedang dalam pembangunan. , yang boleh menjadi halangan serius kepada pelaksanaan ciri baharu.
Tuntutan 2. Ketepatan pengiraan. Brubeck hanya mengumpul 65536 nilai untuk pengagregatan. Dalam kes kami, untuk sesetengah metrik, tempoh pengagregatan (30 saat) boleh menerima lebih banyak nilai (1,527,392 pada puncak). Hasil daripada pensampelan ini, nilai maksimum dan minimum kelihatan tidak berguna. Sebagai contoh, seperti ini:
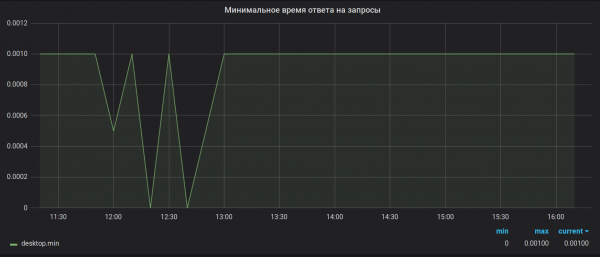
Seperti yang berlaku
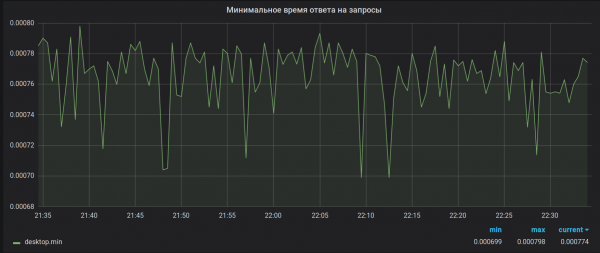
Bagaimana ia sepatutnya
Atas sebab yang sama, jumlah dikira secara salah. Tambahkan pada ini pepijat dengan apungan 32-bit melimpah, yang menghantar pelayan ke segfault apabila menerima metrik yang kelihatan tidak bersalah, dan semuanya menjadi sempurna. Secara kebetulan, pepijat ini tidak pernah diperbaiki.
Dan, akhirnya, Tuntutan XPada masa penulisan, kami bersedia untuk mengujinya terhadap semua 14 lebih atau kurang pelaksanaan statistik berfungsi yang kami temui. Mari kita bayangkan bahawa infrastruktur tertentu telah berkembang dengan pesat sehingga menelan 4 juta MPS tidak lagi mencukupi. Atau, walaupun ia belum berkembang lagi, metrik ini sangat penting kepada anda sehinggakan penurunan graf yang singkat, 2-3 minit dalam graf boleh menjadi kritikal dan mencetuskan serangan kemurungan yang tidak dapat diatasi dalam pengurus. Memandangkan merawat kemurungan adalah tugas yang tidak berterima kasih, penyelesaian teknikal diperlukan.
Pertama, toleransi kesalahan, supaya isu pelayan yang tiba-tiba tidak mencetuskan kiamat zombi psikiatri di pejabat. Kedua, kebolehskalaan, supaya ia boleh mengendalikan lebih 4 juta MPS tanpa perlu menggali jauh ke dalam susunan rangkaian. Linux dan dengan tenang tumbuh "lebar" ke saiz yang diperlukan.
Memandangkan kami mempunyai ruang kepala kebolehskalaan, kami memutuskan untuk bermula dengan toleransi kesalahan. "Oh! Toleransi kesalahan! Mudah sahaja, kami boleh melakukannya," fikir kami, dan melancarkan dua pelayan, menjalankan salinan brubeck pada setiap satu. Untuk melakukan ini, kami perlu menyalin trafik dengan metrik ke kedua-dua pelayan dan juga menulis coretan kod untuknya. Kami menyelesaikan masalah toleransi kesalahan dengan cara ini, tetapi... tidak begitu baik. Pada mulanya, semuanya kelihatan baik: setiap brubeck mengumpul versi pengagregatannya sendiri, menulis data ke Graphite setiap 30 saat, menimpa selang lama (ini dilakukan di sebelah Grafit). Jika satu pelayan gagal, kami sentiasa mempunyai pelayan kedua dengan salinan data agregatnya sendiri. Tetapi inilah masalahnya: jika pelayan gagal, corak "saw-to-saw" muncul pada graf. Ini disebabkan oleh fakta bahawa selang 30 saat brubeck tidak disegerakkan dan apabila salah satu daripadanya gagal, ia tidak akan ditulis ganti. Perkara yang sama berlaku apabila pelayan kedua bermula. Ia boleh diterima, tetapi kami mahukan yang lebih baik! Isu kebolehskalaan juga kekal. Semua metrik masih pergi ke pelayan tunggal, dan oleh itu kami terhad kepada 2-4 juta MPS yang sama, bergantung pada prestasi rangkaian.
Jika anda berfikir tentang masalah itu seketika semasa menyekop salji, idea yang jelas mungkin muncul di kepala anda: anda memerlukan statistik yang boleh berfungsi dalam mod teragih. Iaitu, yang melaksanakan penyegerakan antara nod mengikut masa dan metrik. "Sudah tentu penyelesaian sedemikian mungkin sudah wujud," kami berkata, dan pergi googling... Dan tidak menemui apa-apa. Selepas meneliti dokumentasi untuk pelbagai statistik ( Sehingga 11 Disember 2017, kami tidak menemui apa-apa. Nampaknya, baik pembangun mahupun pengguna penyelesaian ini tidak pernah menemui banyak metrik ITU, jika tidak, mereka pasti akan menghasilkan sesuatu.
Dan kemudian kami teringat statistik "mainan", bioyino, yang kami tulis di hackathon Just for Fun (nama projek dijana oleh skrip sebelum hackathon) dan menyedari kami memerlukan statistik kami sendiri dengan segera. kenapa?
- kerana terdapat terlalu sedikit klon statistik di dunia,
- kerana adalah mungkin untuk memberikan toleransi dan skalabilitas kesalahan yang diingini atau hampir dengan yang dikehendaki (termasuk menyegerakkan metrik agregat antara pelayan dan menyelesaikan masalah konflik semasa menghantar),
- kerana anda boleh mengira metrik dengan lebih tepat berbanding brubeck,
- kerana kami sendiri boleh mengumpul statistik yang lebih terperinci, yang hampir tidak pernah diberikan oleh brubeck kepada kami,
- kerana saya berpeluang untuk memprogramkan aplikasi skala teragih hiperprestasi saya sendiri, yang tidak akan meniru sepenuhnya seni bina satu lagi prestasi hiper sedemikian... baik, anda faham.
Apa yang hendak ditulis? Karat, sudah tentu. kenapa?
- kerana sudah ada prototaip penyelesaian,
- kerana pengarang artikel itu sudah mengenali Rust pada masa itu dan tidak sabar-sabar untuk menulis sesuatu di dalamnya untuk pengeluaran dengan kemungkinan mengeluarkannya sebagai sumber terbuka,
- kerana bahasa dengan GC tidak sesuai untuk kami kerana sifat trafik yang diterima (hampir masa nyata) dan jeda GC secara praktikalnya tidak boleh diterima,
- kerana kita memerlukan prestasi maksimum setanding dengan C
- Oleh kerana Rust memberi kita keselarasan tanpa rasa takut, dan jika kita mula menulisnya dalam C/C++, kita akan mendapat lebih daripada brubeck, kelemahan, limpahan penimbal, keadaan perlumbaan dan perkataan menakutkan yang lain.
Terdapat juga hujah terhadap Rust. Syarikat itu tidak mempunyai pengalaman membuat projek di Rust, dan kami tidak merancang untuk menggunakannya dalam projek utama kami. Jadi, terdapat kebimbangan serius bahawa ia tidak akan berjaya, tetapi kami memutuskan untuk mengambil peluang dan mencubanya.
Masa berlalu…
Akhirnya, selepas beberapa percubaan yang gagal, versi pertama yang berfungsi telah sedia. Apa yang berlaku? Inilah rupanya.
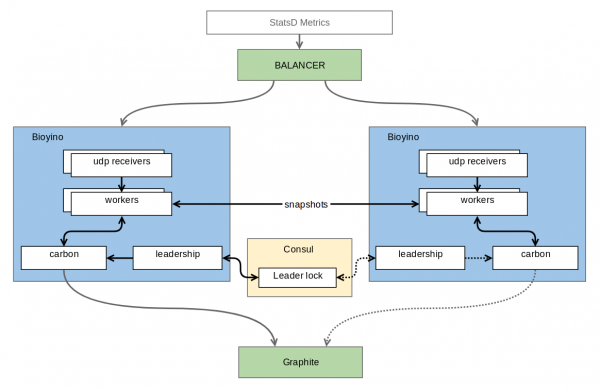
Setiap nod menerima set metriknya sendiri dan mengumpulkannya, tetapi tidak mengagregat metrik untuk jenis yang set penuh diperlukan untuk pengagregatan akhir. Nod disambungkan melalui protokol kunci yang diedarkan, yang membolehkan mereka memilih satu (kami menangis di sini) yang layak untuk menghantar metrik kepada Yang Hebat. Masalah ini sedang ditangani oleh , tetapi pada masa hadapan cita-cita penulis meluaskan kepada Rakit, di mana nod pemimpin konsensus, sudah tentu, yang paling layak. Selain konsensus, nod kerap (secara lalai, sekali sesaat) menghantar bahagian metrik pra-agregat kepada jiran mereka pada saat itu. Ini mengekalkan kebolehskalaan dan toleransi kesalahan—setiap nod masih mengekalkan set penuh metrik, tetapi metrik dihantar secara agregat, melalui TCP dan dikodkan dalam protokol binari, mengurangkan kos penduaan dengan ketara berbanding UDP. Walaupun bilangan metrik masuk yang agak besar, pengumpulan memerlukan memori yang sangat sedikit dan lebih sedikit CPU. Untuk metrik kami yang dimampatkan dengan baik, ini berjumlah hanya beberapa puluh megabait data. Bonus tambahan ialah mengelakkan penulisan semula data yang tidak perlu dalam Grafit, seperti yang berlaku dengan burbeck.
Paket UDP dengan metrik tidak seimbang antara nod pada peralatan rangkaian menggunakan round robin mudah. Sememangnya, perkakasan rangkaian tidak menghuraikan kandungan paket dan oleh itu boleh mengendalikan lebih daripada 4M paket sesaat, apatah lagi metrik yang tidak diketahuinya. Memandangkan metrik tidak diterima secara individu dalam setiap paket, kami tidak menjangkakan sebarang isu prestasi di sini. Jika pelayan ranap, peranti rangkaian dengan cepat (dalam 1-2 saat) mengesan ini dan mengalih keluar pelayan yang turun daripada putaran. Akibatnya, nod pasif (iaitu, bukan pemimpin) boleh dihidupkan dan dimatikan dengan hampir tiada penurunan ketara dalam graf. Yang paling kita rugi ialah beberapa metrik yang tiba pada saat terakhir. Kehilangan/penukaran ketua secara tiba-tiba masih akan mewujudkan anomali kecil (selang 30 saat masih tidak segerak), tetapi jika terdapat komunikasi antara nod, masalah ini boleh diminimumkan, contohnya, dengan menghantar paket penyegerakan.
Sedikit tentang dalaman. Aplikasi ini, sudah tentu, berbilang benang, tetapi seni bina benang berbeza daripada yang digunakan dalam brubeck. Benang dalam brubeck adalah sama—masing-masing bertanggungjawab untuk pengumpulan dan pengagregatan data. Dalam bioyino, benang pekerja dibahagikan kepada dua kumpulan: mereka yang bertanggungjawab untuk pemprosesan rangkaian dan mereka yang bertanggungjawab untuk pengagregatan. Bahagian ini membenarkan pengurusan aplikasi yang lebih fleksibel bergantung pada jenis metrik: apabila pengagregatan intensif diperlukan, pengagregat boleh ditambah, manakala di mana terdapat banyak trafik rangkaian, lebih banyak rangkaian rangkaian boleh ditambah. Pada masa ini, kami beroperasi dengan lapan rangkaian rangkaian dan empat rangkaian pengagregatan pada pelayan kami.
Bahagian pengiraan (pengagregatan) agak membosankan. Penampan yang diisi dengan aliran rangkaian diedarkan di antara benang pengiraan, di mana ia kemudiannya dihuraikan dan diagregatkan. Atas permintaan, metrik dihantar ke nod lain. Semua ini, termasuk pemindahan data antara nod dan interaksi dengan Konsul, dilakukan secara tidak segerak dan berjalan pada rangka kerja. .
Komponen rangkaian yang bertanggungjawab untuk menerima metrik membentangkan lebih banyak cabaran pembangunan. Matlamat utama mengasingkan aliran rangkaian kepada entiti yang berasingan adalah untuk mengurangkan masa setiap aliran dibelanjakan. tiada untuk membaca data daripada soket. Pilihan untuk menggunakan UDP tak segerak dan recvmsg biasa dengan cepat menjadi tidak digunakan: yang pertama menggunakan terlalu banyak CPU ruang pengguna untuk pemprosesan acara, manakala yang kedua menggunakan terlalu banyak suis konteks. Oleh itu, pendekatan semasa ialah Dengan penampan yang besar (dan penampan, tuan-tuan pegawai, bukan apa-apa!). Sokongan untuk UDP biasa dikhaskan untuk kes beban rendah apabila recvmmsg tidak diperlukan. Mod berbilang mesej mencapai matlamat utama: utas rangkaian menghabiskan sebahagian besar masanya untuk mengosongkan baris gilir OS—membaca data daripada soket dan memindahkannya ke penimbal ruang pengguna, hanya sekali-sekala bertukar untuk menyerahkan penimbal penuh kepada pengagregat. Barisan soket boleh dikatakan tidak pernah terkumpul, dan bilangan paket yang tercicir hampir tidak meningkat.
Nota
Secara lalai, saiz penimbal ditetapkan agak besar. Jika anda memutuskan untuk menguji pelayan sendiri, anda mungkin mendapati bahawa selepas menghantar sebilangan kecil metrik, ia tidak tiba di Graphite, kekal dalam penimbal strim rangkaian. Untuk mengendalikan sebilangan kecil metrik, anda harus menetapkan nilai yang lebih kecil dalam fail konfigurasi bufsize dan task-queue-saiz.
Akhir sekali, beberapa carta untuk pencinta carta.
Statistik tentang bilangan metrik masuk untuk setiap pelayan: lebih daripada 2 juta MPS.
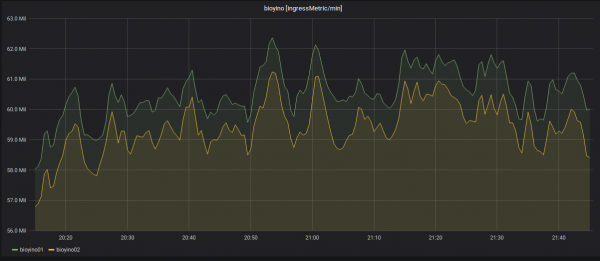
Melumpuhkan salah satu nod dan mengagihkan semula metrik masuk.
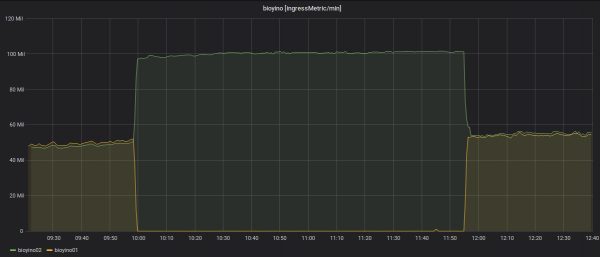
Statistik tentang metrik keluar: hanya satu nod yang pernah dihantar—bos serbuan.
Statistik bagi setiap operasi nod, dengan mengambil kira ralat dalam pelbagai modul sistem.
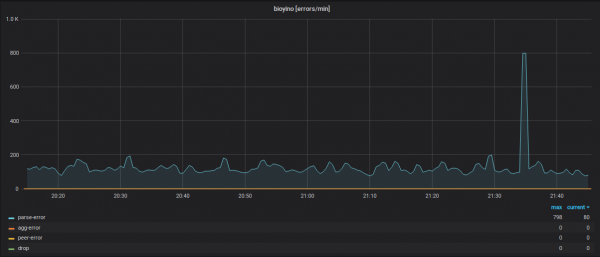
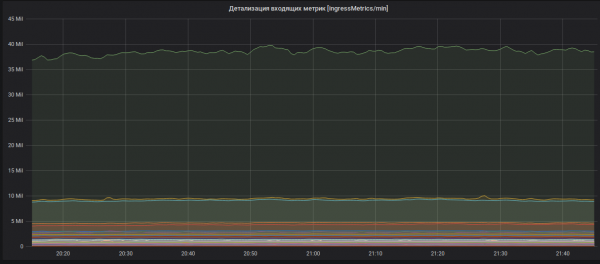
Butiran metrik masuk (nama metrik disembunyikan).
Apa yang kita merancang untuk melakukan semua ini seterusnya? Tulis kod sialan, sudah tentu! Projek ini pada asalnya dirancang sebagai sumber terbuka dan akan kekal begitu sepanjang hayatnya. Pelan segera kami termasuk menukar kepada versi Raft kami sendiri, menukar protokol rakan sebaya kepada yang lebih mudah alih, menambah statistik dalaman tambahan, jenis metrik baharu, pembetulan pepijat dan penambahbaikan lain.
Sudah tentu, sesiapa yang bersedia membantu membangunkan projek itu dialu-alukan: buat PR, isu, dan kami akan membalasnya apabila boleh, memperbaikinya, dsb.
Itu sahaja orang, seperti yang mereka katakan, beli gajah kami!

Sumber: www.habr.com
