

Hari ini, perkhidmatan Bitrix24 tidak mempunyai ratusan gigabit trafik, dan juga tidak mempunyai kumpulan pelayan yang besar (walaupun, sudah tentu, terdapat beberapa yang sedia ada). Tetapi bagi kebanyakan pelanggan ia adalah alat utama untuk bekerja di syarikat; ia adalah aplikasi kritikal perniagaan sebenar. Oleh itu, tidak ada cara untuk jatuh. Bagaimana jika nahas itu berlaku, tetapi perkhidmatan itu "pulih" begitu cepat sehingga tiada siapa yang menyedari apa-apa? Dan bagaimana mungkin untuk melaksanakan failover tanpa kehilangan kualiti kerja dan bilangan pelanggan? Alexander Demidov, pengarah perkhidmatan awan di Bitrix24, bercakap untuk blog kami tentang cara sistem tempahan telah berkembang sepanjang 7 tahun kewujudan produk.

“Kami melancarkan Bitrix24 sebagai SaaS 7 tahun lalu. Kesukaran utama mungkin yang berikut: sebelum ia dilancarkan secara terbuka sebagai SaaS, produk ini hanya wujud dalam format penyelesaian kotak. Pelanggan membelinya daripada kami, mengehoskannya pada pelayan mereka, menyediakan portal korporat - penyelesaian umum untuk komunikasi pekerja, penyimpanan fail, pengurusan tugas, CRM, itu sahaja. Dan menjelang 2012, kami memutuskan bahawa kami mahu melancarkannya sebagai SaaS, mentadbirnya sendiri, memastikan toleransi kesalahan dan kebolehpercayaan. Kami memperoleh pengalaman sepanjang perjalanan, kerana sehingga itu kami tidak memilikinya - kami hanya pengeluar perisian, bukan pembekal perkhidmatan.
Semasa melancarkan perkhidmatan, kami memahami bahawa perkara yang paling penting ialah memastikan toleransi kesalahan, kebolehpercayaan dan ketersediaan perkhidmatan yang berterusan, kerana jika anda mempunyai tapak web biasa yang mudah, kedai, sebagai contoh, dan ia jatuh pada anda dan duduk di sana selama sejam, hanya anda yang menderita, anda kehilangan pesanan, anda kehilangan pelanggan, tetapi untuk pelanggan anda sendiri, ini tidak begitu kritikal untuknya. Dia kecewa, sudah tentu, tetapi dia pergi dan membelinya di tapak lain. Dan jika ini adalah aplikasi di mana semua kerja dalam syarikat, komunikasi, keputusan terikat, maka perkara yang paling penting adalah untuk mendapatkan kepercayaan pengguna, iaitu, tidak mengecewakan mereka dan tidak jatuh. Kerana semua kerja boleh berhenti jika sesuatu di dalam tidak berfungsi.
Bitrix.24 sebagai SaaS
Kami memasang prototaip pertama setahun sebelum pelancaran awam, pada tahun 2011. Kami memasangnya dalam kira-kira seminggu, melihatnya, memutarnya - malah berfungsi. Iaitu, anda boleh masuk ke dalam borang, masukkan nama portal di sana, portal baharu akan dibuka, dan pangkalan pengguna akan dibuat. Kami melihatnya, menilai produk secara prinsip, membatalkannya dan terus memperhalusinya selama setahun penuh. Kerana kami mempunyai tugas yang besar: kami tidak mahu membuat dua asas kod yang berbeza, kami tidak mahu menyokong produk berpakej yang berasingan, penyelesaian awan yang berasingan - kami mahu melakukan semuanya dalam satu kod.
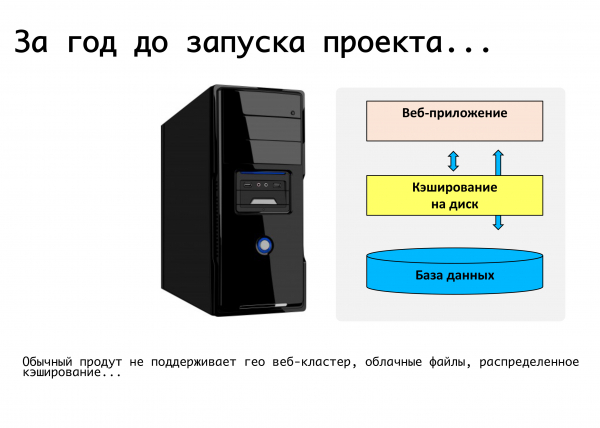
Aplikasi web biasa pada masa itu ialah satu pelayan di mana beberapa kod PHP dijalankan, pangkalan data mysql, fail dimuat naik, dokumen, gambar dimasukkan ke dalam folder muat naik - baik, semuanya berfungsi. Malangnya, adalah mustahil untuk melancarkan perkhidmatan web yang sangat stabil menggunakan ini. Di sana, cache yang diedarkan tidak disokong, replikasi pangkalan data tidak disokong.
Kami merumuskan keperluan: ini ialah keupayaan untuk ditempatkan di lokasi yang berbeza, replikasi sokongan, dan idealnya ditempatkan di pusat data yang diedarkan secara geografi yang berbeza. Pisahkan logik produk dan, sebenarnya, storan data. Dapat menskala secara dinamik mengikut beban, dan bertolak ansur dengan statik sama sekali. Daripada pertimbangan ini, sebenarnya, keperluan untuk produk itu muncul, yang kami perhalusi sepanjang tahun ini. Pada masa ini, dalam platform, yang ternyata bersatu - untuk penyelesaian kotak, untuk perkhidmatan kami sendiri - kami membuat sokongan untuk perkara yang kami perlukan. Sokongan untuk replikasi mysql pada tahap produk itu sendiri: iaitu, pembangun yang menulis kod tidak memikirkan bagaimana permintaannya akan diedarkan, dia menggunakan api kami, dan kami tahu cara mengedarkan permintaan tulis dan baca dengan betul antara tuan dan hamba.
Kami telah membuat sokongan pada peringkat produk untuk pelbagai storan objek awan: storan google, amazon s3, serta sokongan untuk open stack swift. Oleh itu, ini mudah untuk kami sebagai perkhidmatan dan untuk pembangun yang bekerja dengan penyelesaian berpakej: jika mereka hanya menggunakan API kami untuk kerja, mereka tidak memikirkan di mana fail itu akhirnya akan disimpan, secara setempat pada sistem fail atau dalam storan fail objek.
Akibatnya, kami serta-merta memutuskan bahawa kami akan menempah pada tahap keseluruhan pusat data. Pada tahun 2012, kami melancarkan sepenuhnya di Amazon AWS kerana kami sudah mempunyai pengalaman dengan platform ini - tapak web kami sendiri telah dihoskan di sana. Kami tertarik dengan fakta bahawa di setiap wilayah Amazon mempunyai beberapa zon ketersediaan - sebenarnya, (dalam istilahnya) beberapa pusat data yang lebih kurang bebas antara satu sama lain dan membolehkan kami membuat tempahan pada tahap keseluruhan pusat data: jika tiba-tiba gagal, pangkalan data akan direplikasi master-master, pelayan aplikasi web disandarkan, dan data statik dipindahkan ke storan objek s3. Beban adalah seimbang - pada masa itu oleh Amazon elb, tetapi tidak lama kemudian kami datang ke pengimbang beban kami sendiri, kerana kami memerlukan logik yang lebih kompleks.
Apa yang mereka inginkan itulah yang mereka dapat...
Semua perkara asas yang kami ingin pastikan - toleransi kesalahan pelayan itu sendiri, aplikasi web, pangkalan data - semuanya berfungsi dengan baik. Senario paling mudah: jika salah satu aplikasi web kami gagal, maka semuanya mudah - ia dimatikan daripada mengimbangi.
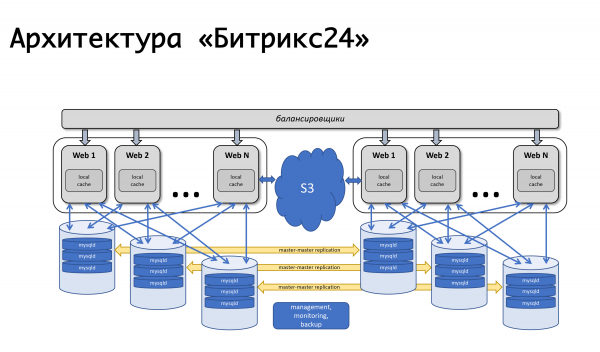
Pengimbang (pada masa itu ia adalah elb Amazon) menandakan mesin yang rosak sebagai tidak sihat dan mematikan pengagihan beban padanya. Penskalaan automatik Amazon berfungsi: apabila beban bertambah, mesin baharu telah ditambahkan pada kumpulan penskalaan automatik, beban telah diagihkan kepada mesin baharu - semuanya baik-baik saja. Dengan pengimbang kami, logiknya adalah lebih kurang sama: jika sesuatu berlaku pada pelayan aplikasi, kami mengalih keluar permintaan daripadanya, membuang mesin ini, memulakan yang baharu dan terus bekerja. Skim ini telah berubah sedikit selama bertahun-tahun, tetapi terus berfungsi: ia mudah, difahami, dan tidak ada kesulitan dengannya.
Kami bekerja di seluruh dunia, puncak beban pelanggan adalah berbeza sama sekali, dan, dengan cara yang baik, kami sepatutnya dapat menjalankan kerja perkhidmatan tertentu pada mana-mana komponen sistem kami pada bila-bila masa - tanpa disedari oleh pelanggan. Oleh itu, kami mempunyai peluang untuk mematikan pangkalan data daripada operasi, mengagihkan semula beban ke pusat data kedua.
Bagaimana semuanya berfungsi? — Kami menukar trafik ke pusat data yang berfungsi - jika berlaku kemalangan di pusat data, maka sepenuhnya, jika ini adalah kerja yang dirancang kami dengan satu pangkalan data, maka kami menukar sebahagian daripada trafik yang melayani pelanggan ini ke pusat data kedua, menggantung ia replikasi. Jika mesin baharu diperlukan untuk aplikasi web kerana beban pada pusat data kedua telah meningkat, ia akan bermula secara automatik. Kami menyelesaikan kerja, replikasi dipulihkan, dan kami mengembalikan keseluruhan beban. Jika kita perlu mencerminkan beberapa kerja di DC kedua, sebagai contoh, memasang kemas kini sistem atau menukar tetapan dalam pangkalan data kedua, maka, secara umum, kita mengulangi perkara yang sama, hanya ke arah yang lain. Dan jika ini adalah kemalangan, maka kami melakukan segala-galanya secara remeh: kami menggunakan mekanisme pengendali acara dalam sistem pemantauan. Jika beberapa semakan dicetuskan dan status menjadi kritikal, maka kami menjalankan pengendali ini, pengendali yang boleh melaksanakan logik ini atau itu. Untuk setiap pangkalan data, kami menentukan pelayan mana yang menjadi failover untuknya dan tempat trafik perlu ditukar jika ia tidak tersedia. Dari segi sejarah, kami menggunakan nagios atau beberapa garpunya dalam satu bentuk atau yang lain. Pada dasarnya, mekanisme serupa wujud dalam hampir mana-mana sistem pemantauan; kami tidak menggunakan apa-apa yang lebih kompleks lagi, tetapi mungkin suatu hari nanti kami akan menggunakannya. Sekarang pemantauan dicetuskan oleh ketiadaan dan mempunyai keupayaan untuk menukar sesuatu.
Adakah kita telah menempah segala-galanya?
Kami mempunyai ramai pelanggan dari USA, ramai pelanggan dari Eropah, ramai pelanggan yang lebih dekat dengan Timur - Jepun, Singapura dan sebagainya. Sudah tentu, sebahagian besar pelanggan berada di Rusia. Maksudnya, kerja bukan dalam satu wilayah. Pengguna mahukan respons yang cepat, terdapat keperluan untuk mematuhi pelbagai undang-undang tempatan, dan dalam setiap wilayah kami menempah dua pusat data, serta terdapat beberapa perkhidmatan tambahan, yang, sekali lagi, mudah untuk diletakkan dalam satu wilayah - untuk pelanggan yang berada di wilayah ini berfungsi. Pengendali REST, pelayan kebenaran, mereka kurang kritikal untuk operasi pelanggan secara keseluruhan, anda boleh beralih melaluinya dengan kelewatan kecil yang boleh diterima, tetapi anda tidak mahu mencipta semula roda tentang cara memantau mereka dan apa yang perlu dilakukan dengan mereka. Oleh itu, kami cuba menggunakan penyelesaian sedia ada secara maksimum, dan bukannya membangunkan beberapa jenis kecekapan dalam produk tambahan. Dan di suatu tempat kami secara remeh menggunakan penukaran pada tahap DNS, dan kami menentukan kemeriahan perkhidmatan oleh DNS yang sama. Amazon mempunyai perkhidmatan Route 53, tetapi ia bukan sekadar DNS yang boleh anda masukkan dan itu sahaja—ia lebih fleksibel dan mudah. Melaluinya anda boleh membina perkhidmatan teragih geo dengan geolokasi, apabila anda menggunakannya untuk menentukan dari mana pelanggan datang dan memberinya rekod tertentu - dengan bantuannya anda boleh membina seni bina failover. Pemeriksaan kesihatan yang sama dikonfigurasikan dalam Laluan 53 itu sendiri, anda menetapkan titik akhir yang dipantau, tetapkan metrik, tetapkan protokol mana untuk menentukan "keaktifan" perkhidmatan - tcp, http, https; tetapkan kekerapan pemeriksaan yang menentukan sama ada perkhidmatan itu hidup atau tidak. Dan dalam DNS itu sendiri anda menentukan apa yang akan menjadi utama, apa yang akan menjadi sekunder, di mana untuk menukar jika pemeriksaan kesihatan dicetuskan di dalam laluan 53. Semua ini boleh dilakukan dengan beberapa alat lain, tetapi mengapa ia mudah - kami menetapkannya ke atas sekali dan kemudian jangan fikirkan sama sekali cara kami menyemak, cara kami bertukar: semuanya berfungsi dengan sendirinya.
"tetapi" pertama: bagaimana dan dengan apa untuk menempah laluan 53 itu sendiri? Siapa tahu, bagaimana jika sesuatu berlaku kepadanya? Nasib baik, kami tidak pernah memijak garu ini, tetapi sekali lagi, saya akan mempunyai cerita di hadapan mengapa kami fikir kami masih perlu membuat tempahan. Di sini kami meletakkan straw untuk diri kami sendiri terlebih dahulu. Beberapa kali sehari kami melakukan pemunggahan lengkap semua zon yang kami ada di laluan 53. API Amazon membolehkan anda menghantarnya dengan mudah dalam JSON, dan kami mempunyai beberapa pelayan sandaran tempat kami menukarnya, memuat naiknya dalam bentuk konfigurasi dan mempunyai, secara kasarnya, konfigurasi sandaran. Jika sesuatu berlaku, kami boleh menggunakan ia secara manual dengan cepat tanpa kehilangan data tetapan DNS.
Kedua "tetapi": Apakah dalam gambar ini yang masih belum ditempah? Pengimbang itu sendiri! Pengedaran pelanggan kami mengikut wilayah dibuat dengan sangat mudah. Kami mempunyai domain bitrix24.ru, bitrix24.com, .de - kini terdapat 13 domain yang berbeza, yang beroperasi dalam pelbagai zon. Kami sampai kepada perkara berikut: setiap wilayah mempunyai pengimbangnya sendiri. Ini menjadikannya lebih mudah untuk diedarkan ke seluruh wilayah, bergantung pada di mana beban puncak pada rangkaian berada. Jika ini adalah kegagalan pada tahap pengimbang tunggal, maka ia hanya dikeluarkan dari perkhidmatan dan dikeluarkan dari dns. Jika terdapat beberapa masalah dengan sekumpulan pengimbang, maka mereka disandarkan di tapak lain, dan bertukar antara mereka dilakukan menggunakan laluan yang sama53, kerana disebabkan TTL yang pendek, penukaran berlaku dalam masa maksimum 2, 3, 5 minit .
Ketiga "tetapi": Apa yang belum ditempah? S3, betul. Apabila kami meletakkan fail yang kami simpan untuk pengguna di s3, kami benar-benar percaya bahawa ia menindik perisai dan tidak perlu menempah apa-apa di sana. Tetapi sejarah menunjukkan bahawa perkara berlaku secara berbeza. Secara umum, Amazon menerangkan S3 sebagai perkhidmatan asas, kerana Amazon sendiri menggunakan S3 untuk menyimpan imej mesin, konfigurasi, imej AMI, syot kilat... Dan jika s3 ranap, seperti yang berlaku sekali dalam tempoh 7 tahun ini, selagi kami telah menggunakan bitrix24, ia mengikutinya seperti peminat Terdapat banyak perkara yang timbul - ketidakupayaan untuk memulakan mesin maya, kegagalan api, dan sebagainya.
Dan S3 boleh jatuh - ia berlaku sekali. Oleh itu, kami datang ke skim berikut: beberapa tahun yang lalu tidak ada kemudahan penyimpanan objek awam yang serius di Rusia, dan kami mempertimbangkan pilihan untuk melakukan sesuatu sendiri... Nasib baik, kami tidak mula melakukan ini, kerana kami akan telah menggali kepakaran yang kita tidak ada, dan mungkin akan merosakkan. Kini Mail.ru mempunyai storan serasi s3, Yandex memilikinya, dan beberapa pembekal lain memilikinya. Kami akhirnya mendapat idea bahawa kami ingin mempunyai, pertama, sandaran, dan kedua, keupayaan untuk bekerja dengan salinan tempatan. Untuk wilayah Rusia secara khusus, kami menggunakan perkhidmatan Mail.ru Hotbox, yang serasi dengan API dengan s3. Kami tidak memerlukan sebarang pengubahsuaian besar pada kod di dalam aplikasi, dan kami membuat mekanisme berikut: dalam s3 terdapat pencetus yang mencetuskan penciptaan/pemadaman objek, Amazon mempunyai perkhidmatan yang dipanggil Lambda - ini adalah pelancaran kod tanpa pelayan yang akan dilaksanakan hanya apabila pencetus tertentu dicetuskan.
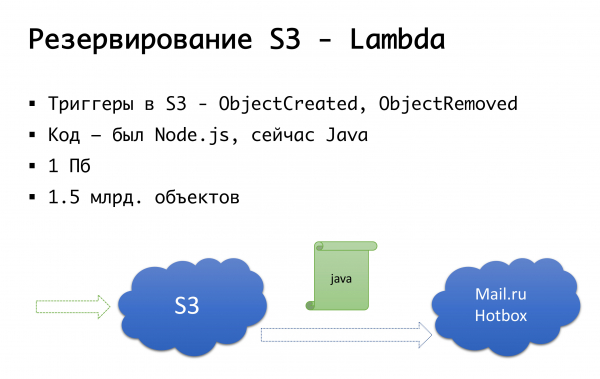
Kami melakukannya dengan sangat mudah: jika pencetus kami menyala, kami melaksanakan kod yang akan menyalin objek ke storan Mail.ru. Untuk melancarkan sepenuhnya kerja dengan salinan data tempatan, kami juga memerlukan penyegerakan terbalik supaya pelanggan yang berada dalam segmen Rusia boleh bekerja dengan storan yang lebih dekat dengan mereka. Mel akan menyelesaikan pencetus dalam storannya - penyegerakan terbalik boleh dilakukan pada peringkat infrastruktur, tetapi buat masa ini kami melakukan ini pada tahap kod kami sendiri. Jika kami melihat bahawa pelanggan telah menyiarkan fail, maka pada peringkat kod kami meletakkan acara itu dalam baris gilir, memprosesnya dan melakukan replikasi terbalik. Mengapa ia buruk: jika kami melakukan beberapa jenis kerja dengan objek kami di luar produk kami, iaitu, melalui beberapa cara luaran, kami tidak akan mengambil kiranya. Oleh itu, kami menunggu sehingga akhir, apabila pencetus muncul di peringkat storan, supaya tidak kira dari mana kami melaksanakan kod itu, objek yang datang kepada kami disalin ke arah lain.
Pada peringkat kod, kami mendaftarkan kedua-dua storan untuk setiap pelanggan: satu dianggap sebagai yang utama, yang lain dianggap sebagai sandaran. Jika semuanya baik-baik saja, kami bekerja dengan storan yang lebih dekat dengan kami: iaitu, pelanggan kami yang berada di Amazon, mereka bekerja dengan S3, dan mereka yang bekerja di Rusia, mereka bekerja dengan Hotbox. Jika bendera dicetuskan, maka failover harus disambungkan dan kami menukar pelanggan ke storan lain. Kami boleh menandai kotak ini secara berasingan mengikut wilayah dan boleh menukarnya ke sana ke mari. Kami belum menggunakan ini dalam amalan lagi, tetapi kami telah menyediakan mekanisme ini dan kami berpendapat bahawa suatu hari nanti kami akan memerlukan suis ini dan berguna. Ini sudah berlaku sekali.
Oh, dan Amazon melarikan diri...
April ini menandakan ulang tahun permulaan penyekatan Telegram di Rusia. Pembekal yang paling terjejas yang berada di bawah ini ialah Amazon. Dan, malangnya, syarikat Rusia yang bekerja untuk seluruh dunia lebih menderita.
Jika syarikat itu global dan Rusia adalah segmen yang sangat kecil untuknya, 3-5% - baik, satu cara atau yang lain, anda boleh mengorbankan mereka.
Jika ini adalah syarikat Rusia semata-mata - saya pasti bahawa ia perlu ditempatkan secara tempatan - baik, ia hanya akan memudahkan pengguna itu sendiri, selesa, dan risiko akan berkurangan.
Bagaimana jika ini adalah syarikat yang beroperasi secara global dan mempunyai bilangan pelanggan yang lebih kurang sama dari Rusia dan di suatu tempat di seluruh dunia? Ketersambungan segmen adalah penting, dan ia mesti bekerjasama antara satu sama lain dalam satu cara atau yang lain.
Pada akhir Mac 2018, Roskomnadzor telah menghantar surat kepada pengendali terbesar untuk memaklumkan mereka tentang rancangan mereka untuk menyekat beberapa juta alamat IP Amazon bagi menyekat... Zello messenger. Terima kasih kepada penyedia yang sama, mereka berjaya membocorkan surat itu kepada semua orang, dan menjadi jelas bahawa sambungan dengan Amazon boleh terjejas. Hari itu hari Jumaat, dan kami berlari dengan panik kepada rakan sekerja kami di servers.ru, sambil berkata, "Kawan-kawan, kami memerlukan beberapa pelayan yang bukan di Rusia, bukan di Amazon, tetapi, sebagai contoh, di suatu tempat di Amsterdam," supaya kami sekurang-kurangnya boleh menyediakan pelayan kami sendiri di sana. VPN Dan proksi untuk beberapa titik akhir yang tidak dapat kami kawal, seperti titik akhir S3—kami tidak boleh cuba menyediakan perkhidmatan baharu dan mendapatkan alamat IP yang berbeza; kami masih perlu dapat menghubungi mereka. Dalam masa beberapa hari, pelayan ini telah dikonfigurasikan, dihidupkan dan dijalankan, dan pada dasarnya bersedia untuk permulaan penyekatan. Menariknya, Roskomnadzor, selepas melihat kekecohan dan panik itu, berkata, "Tidak, kami tidak menyekat apa-apa sekarang." (Tetapi itu berlaku sehingga saat mereka mula menyekat Telegram.) Selepas menyediakan pilihan pintasan dan menyedari penyekatan itu belum dilaksanakan, kami tetap memutuskan untuk tidak menyiasat semuanya. Untuk berjaga-jaga.

Dan pada tahun 2019, kita masih hidup dalam keadaan menyekat. Saya melihat malam tadi: kira-kira sejuta IP terus disekat. Benar, Amazon hampir disekat sepenuhnya, pada kemuncaknya ia mencapai 20 juta alamat... Secara umum, realitinya mungkin tidak ada koheren, koheren yang baik. Tiba-tiba. Ia mungkin tidak wujud atas sebab teknikal - kebakaran, jengkaut, semua itu. Atau, seperti yang kita lihat, tidak sepenuhnya teknikal. Oleh itu, seseorang yang besar dan besar, dengan AS sendiri, mungkin boleh menguruskan ini dengan cara lain - sambungan terus dan perkara lain sudah berada di tahap l2. Tetapi dalam versi mudah, seperti versi kami atau lebih kecil, anda boleh, sekiranya berlaku, mempunyai lebihan pada tahap pelayan yang dibangkitkan di tempat lain, dikonfigurasikan terlebih dahulu vpn, proksi, dengan keupayaan untuk menukar konfigurasi dengan cepat kepada mereka dalam segmen tersebut yang penting untuk ketersambungan anda. Ini berguna untuk kami lebih daripada sekali, apabila penyekatan Amazon bermula; dalam senario terburuk, kami hanya membenarkan trafik S3 melalui mereka, tetapi secara beransur-ansur semua ini telah diselesaikan.
Bagaimana untuk menempah... keseluruhan pembekal?
Pada masa ini kami tidak mempunyai senario sekiranya seluruh Amazon jatuh. Kami mempunyai senario yang sama untuk Rusia. Di Rusia, kami dihoskan oleh satu penyedia, yang daripadanya kami memilih untuk mempunyai beberapa tapak. Dan setahun yang lalu kami menghadapi masalah: walaupun ini adalah dua pusat data, mungkin terdapat masalah pada tahap konfigurasi rangkaian pembekal yang masih akan menjejaskan kedua-dua pusat data. Dan kami mungkin tidak tersedia di kedua-dua tapak. Sudah tentu itulah yang berlaku. Kami akhirnya mempertimbangkan semula seni bina di dalam. Ia tidak banyak berubah, tetapi untuk Rusia kami kini mempunyai dua tapak, yang bukan dari pembekal yang sama, tetapi dari dua tapak yang berbeza. Jika satu gagal, kita boleh bertukar kepada yang lain.
Secara hipotesis, untuk Amazon kami sedang mempertimbangkan kemungkinan tempahan di peringkat penyedia lain; mungkin Google, mungkin orang lain... Tetapi setakat ini kami telah memerhati dalam amalan bahawa walaupun Amazon mengalami kemalangan pada tahap satu zon ketersediaan, kemalangan di peringkat seluruh rantau agak jarang berlaku. Oleh itu, kami secara teorinya mempunyai idea bahawa kami mungkin membuat tempahan "Amazon bukan Amazon", tetapi dalam praktiknya ini belum lagi berlaku.
Beberapa perkataan tentang automasi
Adakah automasi sentiasa diperlukan? Di sini adalah wajar untuk mengingati kesan Dunning-Kruger. Pada paksi "x" ialah pengetahuan dan pengalaman yang kami peroleh, dan pada paksi "y" ialah keyakinan dalam tindakan kami. Pada mulanya kita tidak tahu apa-apa dan tidak pasti sama sekali. Kemudian kita tahu sedikit dan menjadi mega-yakin - ini adalah apa yang dipanggil "puncak kebodohan", digambarkan dengan baik oleh gambar "demensia dan keberanian". Kemudian kami telah belajar sedikit dan bersedia untuk berperang. Kemudian kita melangkah pada beberapa kesilapan yang mega-serius dan mendapati diri kita berada dalam lembah keputusasaan, apabila kita seolah-olah tahu sesuatu, tetapi sebenarnya kita tidak tahu banyak. Kemudian, apabila kita mendapat pengalaman, kita menjadi lebih yakin.
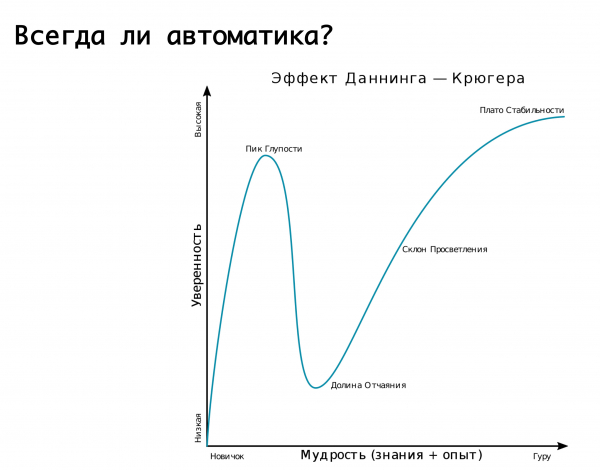
Logik kami tentang pelbagai suis automatik kepada kemalangan tertentu diterangkan dengan sangat baik oleh graf ini. Kami mula - kami tidak tahu bagaimana untuk melakukan apa-apa, hampir semua kerja dilakukan dengan tangan. Kemudian kami menyedari bahawa kami boleh melampirkan automasi pada segala-galanya dan, seperti, tidur dengan tenang. Dan tiba-tiba kami memijak mega-rake: positif palsu dicetuskan, dan kami menukar trafik ke sana ke mari apabila, dengan cara yang baik, kami tidak sepatutnya melakukan ini. Akibatnya, replikasi rosak atau sesuatu yang lain-ini adalah lembah keputusasaan. Dan kemudian kita sampai kepada pemahaman bahawa kita mesti mendekati segala-galanya dengan bijak. Iaitu, masuk akal untuk bergantung pada automasi, menyediakan kemungkinan penggera palsu. Tetapi! jika akibatnya boleh memudaratkan, maka lebih baik serahkan kepada syif bertugas, kepada jurutera yang bertugas, yang akan memastikan dan memantau bahawa benar-benar berlaku kemalangan, dan akan melakukan tindakan yang perlu secara manual...
Kesimpulan
Sepanjang 7 tahun, kami beralih daripada fakta bahawa apabila sesuatu jatuh, terdapat panik-panik, kepada pemahaman bahawa masalah tidak wujud, hanya ada tugas, mereka mesti - dan boleh - diselesaikan. Apabila anda membina perkhidmatan, lihat dari atas, nilai semua risiko yang mungkin berlaku. Jika anda melihatnya dengan segera, maka sediakan lebihan kerja terlebih dahulu dan kemungkinan membina infrastruktur toleran kesalahan, kerana mana-mana titik yang boleh gagal dan membawa kepada ketidakupayaan perkhidmatan pasti akan berbuat demikian. Dan walaupun nampaknya beberapa elemen infrastruktur pasti tidak akan gagal - seperti s3 yang sama, masih perlu diingat bahawa ia boleh. Dan sekurang-kurangnya secara teori, ada idea tentang apa yang akan anda lakukan dengan mereka jika sesuatu berlaku. Mempunyai pelan pengurusan risiko. Apabila anda berfikir tentang melakukan segala-galanya secara automatik atau manual, nilaikan risiko: apakah yang akan berlaku jika automasi mula menukar segala-galanya - bukankah ini akan membawa kepada situasi yang lebih teruk berbanding kemalangan? Mungkin di suatu tempat adalah perlu untuk menggunakan kompromi yang munasabah antara penggunaan automasi dan reaksi jurutera yang bertugas, yang akan menilai gambaran sebenar dan memahami sama ada sesuatu perlu ditukar di tempat atau "ya, tetapi bukan sekarang."
Kompromi yang munasabah antara perfeksionisme dan usaha sebenar, masa, wang yang boleh anda belanjakan pada skim yang akhirnya akan anda miliki.
Teks ini ialah versi laporan Alexander Demidov yang dikemas kini dan diperluas pada persidangan itu .
Sumber: www.habr.com
