

Selalunya orang yang memasuki bidang Sains Data mempunyai jangkaan yang kurang realistik tentang apa yang menanti mereka. Ramai orang berfikir bahawa kini mereka akan menulis rangkaian saraf yang hebat, mencipta pembantu suara daripada Iron Man, atau mengalahkan semua orang dalam pasaran kewangan.
Tetapi kerja Tarikh Saintis dipacu data, dan salah satu aspek yang paling penting dan memakan masa ialah memproses data sebelum memasukkannya ke dalam rangkaian saraf atau menganalisisnya dengan cara tertentu.
Dalam artikel ini, pasukan kami akan menerangkan cara anda boleh memproses data dengan cepat dan mudah dengan arahan dan kod langkah demi langkah. Kami cuba menjadikan kod itu agak fleksibel dan boleh digunakan untuk set data yang berbeza.
Ramai profesional mungkin tidak menemui apa-apa yang luar biasa dalam artikel ini, tetapi pemula akan dapat mempelajari sesuatu yang baru, dan sesiapa yang telah lama bermimpi untuk membuat buku nota berasingan untuk pemprosesan data yang pantas dan berstruktur boleh menyalin kod dan memformatnya untuk diri mereka sendiri, atau
Kami menerima set data. Apa yang perlu dilakukan seterusnya?
Jadi, standardnya: kita perlu memahami apa yang kita hadapi, gambaran keseluruhan. Untuk melakukan ini, kami menggunakan panda untuk mentakrifkan jenis data yang berbeza.
import pandas as pd #импортируем pandas
import numpy as np #импортируем numpy
df = pd.read_csv("AB_NYC_2019.csv") #читаем датасет и записываем в переменную df
df.head(3) #смотрим на первые 3 строчки, чтобы понять, как выглядят значения 
df.info() #Демонстрируем информацию о колонках 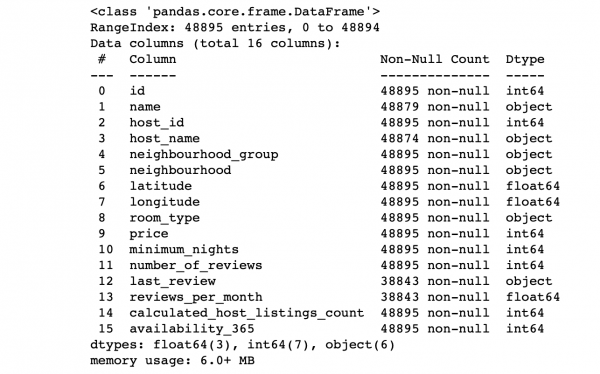
Mari lihat nilai lajur:
- Adakah bilangan baris dalam setiap lajur sepadan dengan jumlah baris?
- Apakah intipati data dalam setiap lajur?
- Lajur manakah yang ingin kita sasarkan untuk membuat ramalan untuknya?
Jawapan kepada soalan ini akan membolehkan anda menganalisis set data dan melukis pelan secara kasar untuk tindakan anda yang seterusnya.
Selain itu, untuk melihat lebih mendalam pada nilai dalam setiap lajur, kita boleh menggunakan fungsi pandas describe(). Walau bagaimanapun, kelemahan fungsi ini ialah ia tidak memberikan maklumat tentang lajur dengan nilai rentetan. Kami akan berurusan dengan mereka kemudian.
df.describe() 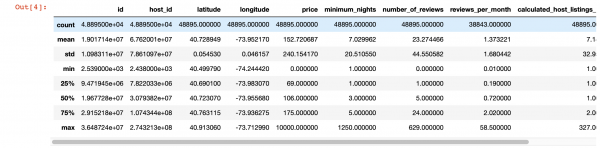
Visualisasi sihir
Mari kita lihat di mana kita tidak mempunyai nilai sama sekali:
import seaborn as sns
sns.heatmap(df.isnull(),yticklabels=False,cbar=False,cmap='viridis') 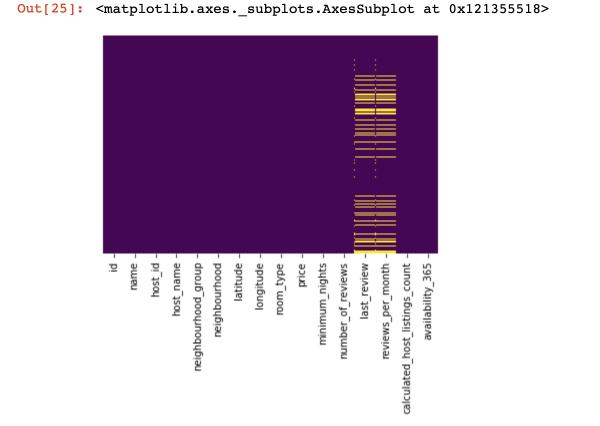
Ini adalah pandangan singkat dari atas, sekarang kita akan beralih kepada perkara yang lebih menarik
Mari cuba cari dan, jika boleh, alih keluar lajur yang hanya mempunyai satu nilai dalam semua baris (ia tidak akan menjejaskan keputusan dalam apa cara sekalipun):
df = df[[c for c
in list(df)
if len(df[c].unique()) > 1]] #Перезаписываем датасет, оставляя только те колонки, в которых больше одного уникального значенияKini kami melindungi diri kami dan kejayaan projek kami daripada baris pendua (baris yang mengandungi maklumat yang sama dalam susunan yang sama seperti salah satu baris yang sedia ada):
df.drop_duplicates(inplace=True) #Делаем это, если считаем нужным.
#В некоторых проектах удалять такие данные с самого начала не стоит.Kami membahagikan set data kepada dua: satu dengan nilai kualitatif, dan satu lagi dengan nilai kuantitatif
Di sini kita perlu membuat penjelasan kecil: jika baris dengan data yang hilang dalam data kualitatif dan kuantitatif tidak begitu berkorelasi antara satu sama lain, maka kita perlu memutuskan apa yang kita korbankan - semua baris dengan data yang hilang, hanya sebahagian daripadanya, atau lajur tertentu. Jika garisan berkorelasi, maka kami mempunyai hak untuk membahagikan set data kepada dua. Jika tidak, anda perlu terlebih dahulu menangani baris yang tidak mengaitkan data yang hilang dalam kualitatif dan kuantitatif, dan kemudian membahagikan set data kepada dua.
df_numerical = df.select_dtypes(include = [np.number])
df_categorical = df.select_dtypes(exclude = [np.number])Kami melakukan ini untuk memudahkan kami memproses kedua-dua jenis data yang berbeza ini - kemudian kami akan memahami betapa lebih mudahnya ini menjadikan hidup kami.
Kami bekerja dengan data kuantitatif
Perkara pertama yang perlu kita lakukan ialah menentukan sama ada terdapat "lajur pengintip" dalam data kuantitatif. Kami memanggil lajur ini kerana ia memaparkan diri mereka sebagai data kuantitatif, tetapi bertindak sebagai data kualitatif.
Bagaimanakah kita boleh mengenal pasti mereka? Sudah tentu, semuanya bergantung pada sifat data yang anda analisis, tetapi secara umum lajur tersebut mungkin mempunyai sedikit data unik (dalam kawasan 3-10 nilai unik).
print(df_numerical.nunique())Setelah kami mengenal pasti lajur pengintip, kami akan mengalihkannya daripada data kuantitatif kepada data kualitatif:
spy_columns = df_numerical[['колонка1', 'колока2', 'колонка3']]#выделяем колонки-шпионы и записываем в отдельную dataframe
df_numerical.drop(labels=['колонка1', 'колока2', 'колонка3'], axis=1, inplace = True)#вырезаем эти колонки из количественных данных
df_categorical.insert(1, 'колонка1', spy_columns['колонка1']) #добавляем первую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка2', spy_columns['колонка2']) #добавляем вторую колонку-шпион в качественные данные
df_categorical.insert(1, 'колонка3', spy_columns['колонка3']) #добавляем третью колонку-шпион в качественные данныеAkhir sekali, kami telah mengasingkan sepenuhnya data kuantitatif daripada data kualitatif dan kini kami boleh bekerja dengannya dengan betul. Perkara pertama ialah memahami di mana kita mempunyai nilai kosong (NaN, dan dalam beberapa kes 0 akan diterima sebagai nilai kosong).
for i in df_numerical.columns:
print(i, df[i][df[i]==0].count())Pada ketika ini, adalah penting untuk memahami di mana lajur sifar mungkin menunjukkan nilai yang hilang: adakah ini disebabkan oleh cara data dikumpulkan? Atau bolehkah ia berkaitan dengan nilai data? Soalan-soalan ini mesti dijawab mengikut kes demi kes.
Jadi, jika kami masih memutuskan bahawa kami mungkin kehilangan data yang terdapat sifar, kami harus menggantikan sifar dengan NaN untuk memudahkan anda mengendalikan data yang hilang ini kemudian:
df_numerical[["колонка 1", "колонка 2"]] = df_numerical[["колонка 1", "колонка 2"]].replace(0, nan)Sekarang mari kita lihat di mana kita kehilangan data:
sns.heatmap(df_numerical.isnull(),yticklabels=False,cbar=False,cmap='viridis') # Можно также воспользоваться df_numerical.info() 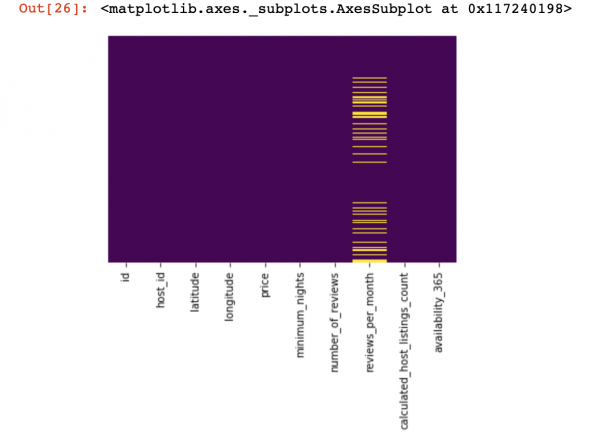
Di sini nilai-nilai di dalam lajur yang tiada harus ditandakan dengan warna kuning. Dan kini keseronokan bermula - bagaimana untuk menangani nilai-nilai ini? Sekiranya saya memadamkan baris dengan nilai atau lajur ini? Atau isikan nilai kosong ini dengan beberapa nilai lain?
Berikut ialah rajah anggaran yang boleh membantu anda memutuskan perkara yang boleh, pada dasarnya, dilakukan dengan nilai kosong:
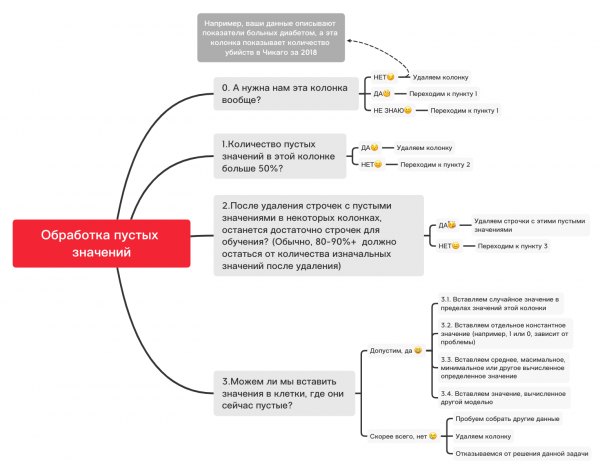
0. Alih keluar lajur yang tidak perlu
df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1. Adakah bilangan nilai kosong dalam lajur ini melebihi 50%?
print(df_numerical.isnull().sum() / df_numerical.shape[0] * 100)df_numerical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)#Удаляем, если какая-то колонка имеет больше 50 пустых значений2. Padam baris dengan nilai kosong
df_numerical.dropna(inplace=True)#Удаляем строчки с пустыми значениями, если потом останется достаточно данных для обучения3.1. Memasukkan nilai rawak
import random #импортируем random
df_numerical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True) #вставляем рандомные значения в пустые клетки таблицы3.2. Memasukkan nilai tetap
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>") #вставляем определенное значение с помощью SimpleImputer
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.3. Masukkan nilai purata atau paling kerap
from sklearn.impute import SimpleImputer #импортируем SimpleImputer, который поможет вставить значения
imputer = SimpleImputer(strategy='mean', missing_values = np.nan) #вместо mean можно также использовать most_frequent
df_numerical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_numerical[['колонка1', 'колонка2', 'колонка3']]) #Применяем это для нашей таблицы
df_numerical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True) #Убираем колонки со старыми значениями3.4. Masukkan nilai yang dikira oleh model lain
Kadangkala nilai boleh dikira menggunakan model regresi menggunakan model daripada perpustakaan sklearn atau perpustakaan lain yang serupa. Pasukan kami akan menumpukan artikel berasingan tentang cara ini boleh dilakukan dalam masa terdekat.
Jadi, buat masa ini, naratif tentang data kuantitatif akan terganggu, kerana terdapat banyak nuansa lain tentang cara melakukan penyediaan dan prapemprosesan data dengan lebih baik untuk tugas yang berbeza, dan perkara asas untuk data kuantitatif telah diambil kira dalam artikel ini, dan kini adalah masa untuk kembali kepada data kualitatif. yang mana kita pisahkan beberapa langkah ke belakang daripada yang kuantitatif. Anda boleh menukar buku nota ini sesuka hati anda, menyesuaikannya dengan tugasan yang berbeza, supaya prapemprosesan data berjalan dengan pantas!
Data kualitatif
Pada asasnya, untuk data kualitatif, kaedah One-hot-encoding digunakan untuk memformatnya daripada rentetan (atau objek) kepada nombor. Sebelum beralih ke titik ini, mari kita gunakan gambar rajah dan kod di atas untuk menangani nilai kosong.
df_categorical.nunique()sns.heatmap(df_categorical.isnull(),yticklabels=False,cbar=False,cmap='viridis') 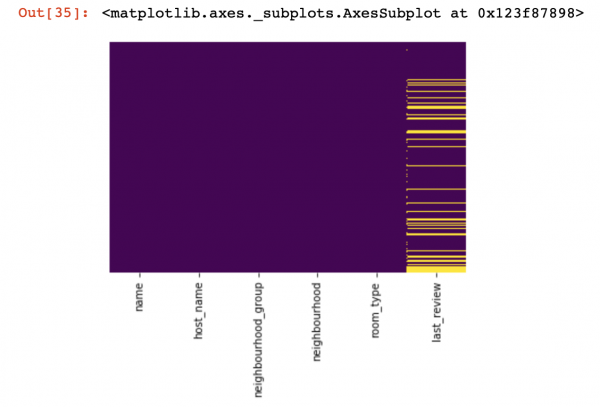
0. Alih keluar lajur yang tidak perlu
df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True)1. Adakah bilangan nilai kosong dalam lajur ini melebihi 50%?
print(df_categorical.isnull().sum() / df_numerical.shape[0] * 100)df_categorical.drop(labels=["колонка1","колонка2"], axis=1, inplace=True) #Удаляем, если какая-то колонка
#имеет больше 50% пустых значений2. Padam baris dengan nilai kosong
df_categorical.dropna(inplace=True)#Удаляем строчки с пустыми значениями,
#если потом останется достаточно данных для обучения3.1. Memasukkan nilai rawak
import random
df_categorical["колонка"].fillna(lambda x: random.choice(df[df[column] != np.nan]["колонка"]), inplace=True)3.2. Memasukkan nilai tetap
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='constant', fill_value="<Ваше значение здесь>")
df_categorical[["новая_колонка1",'новая_колонка2','новая_колонка3']] = imputer.fit_transform(df_categorical[['колонка1', 'колонка2', 'колонка3']])
df_categorical.drop(labels = ["колонка1","колонка2","колонка3"], axis = 1, inplace = True)Jadi, kami akhirnya mendapat pegangan mengenai nulls dalam data kualitatif. Kini tiba masanya untuk melakukan pengekodan satu-panas pada nilai yang terdapat dalam pangkalan data anda. Kaedah ini sangat kerap digunakan untuk memastikan algoritma anda boleh belajar daripada data berkualiti tinggi.
def encode_and_bind(original_dataframe, feature_to_encode):
dummies = pd.get_dummies(original_dataframe[[feature_to_encode]])
res = pd.concat([original_dataframe, dummies], axis=1)
res = res.drop([feature_to_encode], axis=1)
return(res)features_to_encode = ["колонка1","колонка2","колонка3"]
for feature in features_to_encode:
df_categorical = encode_and_bind(df_categorical, feature))Jadi, kami akhirnya selesai memproses data kualitatif dan kuantitatif yang berasingan - masa untuk menggabungkannya kembali
new_df = pd.concat([df_numerical,df_categorical], axis=1)Selepas kami menggabungkan set data menjadi satu, kami akhirnya boleh menggunakan transformasi data menggunakan MinMaxScaler daripada perpustakaan sklearn. Ini akan menjadikan nilai kami antara 0 dan 1, yang akan membantu semasa melatih model pada masa hadapan.
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
new_df = min_max_scaler.fit_transform(new_df)Data ini kini sedia untuk apa sahaja - rangkaian saraf, algoritma ML standard, dsb.!
Dalam artikel ini, kami tidak mengambil kira bekerja dengan data siri masa, kerana untuk data tersebut anda harus menggunakan teknik pemprosesan yang sedikit berbeza, bergantung pada tugas anda. Pada masa hadapan, pasukan kami akan menumpukan artikel berasingan untuk topik ini, dan kami berharap ia akan dapat membawa sesuatu yang menarik, baharu dan berguna ke dalam hidup anda, seperti yang satu ini.
Sumber: www.habr.com
