


Semakin hari, pelanggan menerima permintaan berikut: "Kami mahukannya seperti Amazon RDS, tetapi lebih murah"; "Kami mahukannya seperti RDS, tetapi di mana-mana, dalam mana-mana infrastruktur." Untuk melaksanakan penyelesaian terurus sedemikian pada Kubernetes, kami melihat keadaan semasa pengendali paling popular untuk PostgreSQL (Stolon, pengendali daripada Crunchy Data dan Zalando) dan membuat pilihan kami.
Artikel ini adalah pengalaman yang kami perolehi dari sudut pandangan teori (semakan penyelesaian) dan dari sisi praktikal (apa yang dipilih dan apa yang datang daripadanya). Tetapi pertama-tama, mari kita tentukan apakah keperluan umum untuk pengganti yang berpotensi untuk RDS...
Apa itu RDS
Apabila orang bercakap tentang RDS, dalam pengalaman kami, mereka bermaksud perkhidmatan DBMS terurus yang:
- mudah untuk dikonfigurasikan;
- mempunyai keupayaan untuk bekerja dengan syot kilat dan pulih daripadanya (sebaik-baiknya dengan sokongan );
- membolehkan anda membuat topologi tuan-hamba;
- mempunyai senarai sambungan yang kaya;
- menyediakan pengauditan dan pengurusan pengguna/akses.
Secara umumnya, pendekatan untuk melaksanakan tugas di tangan boleh menjadi sangat berbeza, tetapi laluan dengan Ansible bersyarat tidak dekat dengan kita. (Rakan sekerja dari 2GIS membuat kesimpulan yang sama sebagai hasilnya buat "alat untuk menggunakan kluster failover berasaskan Postgres dengan cepat.")
Operator ialah pendekatan biasa untuk menyelesaikan masalah serupa dalam ekosistem Kubernetes. Pengarah teknikal "Flanta" telah bercakap dengan lebih terperinci tentang mereka berhubung dengan pangkalan data yang dilancarkan di dalam Kubernetes. Dalam .
NB: Untuk mencipta pengendali mudah dengan cepat, kami mengesyorkan agar anda memberi perhatian kepada utiliti Sumber Terbuka kami . Menggunakannya, anda boleh melakukan ini tanpa pengetahuan tentang Go, tetapi dengan cara yang lebih biasa kepada pentadbir sistem: dalam Bash, Python, dsb.
Terdapat beberapa pengendali K8 yang popular untuk PostgreSQL:
- Stolon;
- Operator PostgreSQL Data Renyah;
- Operator Zalando Postgres.
Mari kita lihat mereka dengan lebih dekat.
Pemilihan operator
Sebagai tambahan kepada ciri penting yang telah dinyatakan di atas, kami - sebagai jurutera operasi infrastruktur Kubernetes - juga menjangkakan perkara berikut daripada pengendali:
- penempatan daripada Git dan dengan ;
- sokongan anti-afiniti pod;
- memasang afiniti nod atau pemilih nod;
- pemasangan toleransi;
- ketersediaan keupayaan penalaan;
- teknologi yang boleh difahami dan juga arahan.
Tanpa pergi ke butiran mengenai setiap mata (tanya dalam komen jika anda masih mempunyai soalan mengenainya selepas membaca keseluruhan artikel), saya akan perhatikan secara umum bahawa parameter ini diperlukan untuk menerangkan dengan lebih tepat pengkhususan nod kluster untuk memesannya untuk aplikasi tertentu. Dengan cara ini kita boleh mencapai keseimbangan optimum dari segi prestasi dan kos.
Sekarang mari kita beralih kepada pengendali PostgreSQL sendiri.
1. Stolon
daripada syarikat Itali Sorint.lab in dianggap sebagai sejenis standard di kalangan pengendali untuk DBMS. Ini adalah projek yang agak lama: keluaran awam pertamanya berlaku pada November 2015(!), dan repositori GitHub mempunyai hampir 3000 bintang dan 40+ penyumbang.
Sesungguhnya, Stolon ialah contoh seni bina yang bijak:
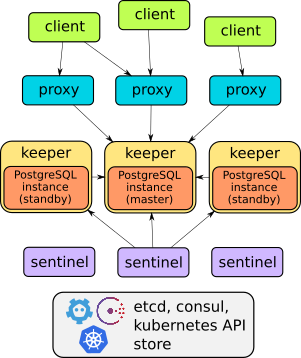
Peranti pengendali ini boleh didapati secara terperinci dalam laporan atau . Secara umum, cukuplah untuk mengatakan bahawa ia boleh melakukan semua yang diterangkan: failover, proksi untuk akses pelanggan telus, sandaran... Selain itu, proksi menyediakan akses melalui satu perkhidmatan titik akhir - tidak seperti dua penyelesaian lain yang dibincangkan di bawah (masing-masing mempunyai dua perkhidmatan untuk mengakses pangkalan).
Walau bagaimanapun, Stolon , itulah sebabnya ia tidak boleh digunakan dengan cara yang mudah dan cepat – “seperti kek panas” – untuk mencipta tika DBMS dalam Kubernetes. Pengurusan dijalankan melalui utiliti stolonctl, penempatan dilakukan melalui carta Helm dan yang tersuai ditakrifkan dan ditentukan dalam ConfigMap.
Di satu pihak, ternyata operator itu sebenarnya bukan pengendali (lagipun, ia tidak menggunakan CRD). Tetapi sebaliknya, ia adalah sistem fleksibel yang membolehkan anda mengkonfigurasi sumber dalam K8 seperti yang anda lihat patut.
Untuk meringkaskan, bagi kami secara peribadi nampaknya tidak optimum untuk membuat carta berasingan untuk setiap pangkalan data. Oleh itu, kami mula mencari alternatif.
2. Operator PostgreSQL Data Renyah
, sebuah syarikat pemula muda Amerika, kelihatan seperti alternatif yang logik. Sejarah awamnya bermula dengan keluaran pertama pada Mac 2017, sejak itu repositori GitHub telah menerima kurang daripada 1300 bintang dan 50+ penyumbang. Keluaran terbaharu dari September telah diuji untuk berfungsi dengan Kubernetes 1.15-1.18, OpenShift 3.11+ dan 4.4+, GKE dan VMware Enterprise PKS 1.3+.
Seni bina Crunchy Data PostgreSQL Operator juga memenuhi keperluan yang dinyatakan:
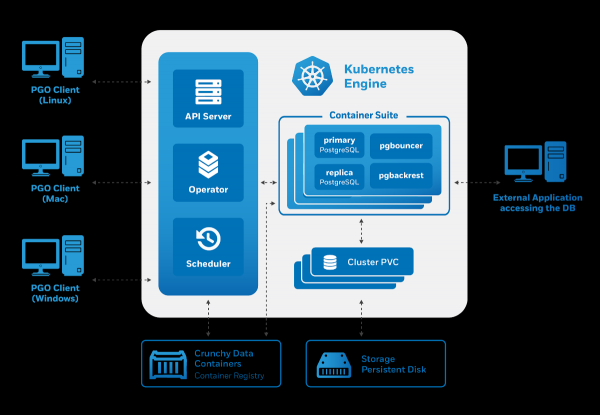
Pengurusan berlaku melalui utiliti pgo, bagaimanapun, ia seterusnya menjana Sumber Tersuai untuk Kubernetes. Oleh itu, pengendali menggembirakan kami sebagai bakal pengguna:
- terdapat kawalan melalui CRD;
- pengurusan pengguna yang mudah (juga melalui CRD);
- integrasi dengan komponen lain — koleksi khusus imej kontena untuk PostgreSQL dan utiliti untuk bekerja dengannya (termasuk pgBackRest, pgAudit, sambungan daripada sumbangan, dsb.).
Walau bagaimanapun, percubaan untuk mula menggunakan operator daripada Crunchy Data mendedahkan beberapa masalah:
- Tiada kemungkinan toleransi - hanya nodeSelector disediakan.
- Pod yang dibuat adalah sebahagian daripada Deployment, walaupun pada hakikatnya kami menggunakan aplikasi stateful. Tidak seperti StatefulSets, Deployments tidak boleh mencipta cakera.
Kelemahan terakhir membawa kepada detik lucu: pada persekitaran ujian kami berjaya menjalankan 3 replika dengan satu cakera simpanan tempatan, menyebabkan pengendali melaporkan bahawa 3 replika berfungsi (walaupun tidak berfungsi).
Satu lagi ciri pengendali ini ialah penyepaduan siap sedia dengan pelbagai sistem tambahan. Sebagai contoh, mudah untuk memasang pgAdmin dan pgBounce, dan masuk Grafana dan Prometheus pra-konfigurasi dipertimbangkan. Baru-baru ini Penyepaduan yang lebih baik dengan projek dinyatakan secara berasingan , terima kasih kepada pengendali yang menawarkan visualisasi yang jelas bagi metrik PgSQL di luar kotak.
Walau bagaimanapun, pilihan pelik sumber yang dijana oleh Kubernetes membawa kami kepada keperluan untuk mencari penyelesaian yang berbeza.
3. Operator Zalando Postgres
Kami telah mengenali produk Zalando untuk masa yang lama: kami mempunyai pengalaman menggunakan Zalenium dan, sudah tentu, kami mencuba ialah penyelesaian HA popular mereka untuk PostgreSQL. Mengenai pendekatan syarikat untuk mencipta salah seorang pengarangnya, Alexey Klyukin, berkata di udara , dan kami menyukainya.
Ini adalah penyelesaian termuda yang dibincangkan dalam artikel: keluaran pertama berlaku pada Ogos 2018. Walau bagaimanapun, walaupun jumlah keluaran rasmi yang kecil, projek ini telah mencapai tahap yang jauh, sudah melebihi populariti penyelesaian daripada Crunchy Data dengan 1300+ bintang di GitHub dan bilangan maksimum penyumbang (70+).
"Di bawah hud" pengendali ini menggunakan penyelesaian yang diuji masa:
- Patroni dan Untuk pemanduan,
- - untuk sandaran,
- - sebagai kolam sambungan.
Beginilah cara seni bina pengendali dari Zalando dipersembahkan:
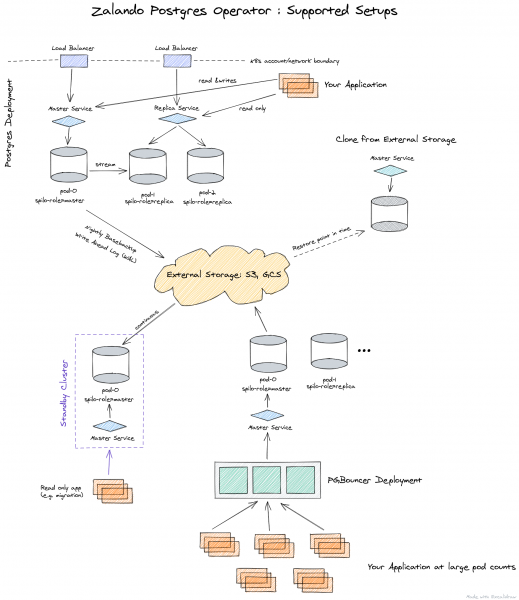
Pengendali diurus sepenuhnya melalui Sumber Tersuai, secara automatik mencipta StatefulSet daripada bekas, yang kemudiannya boleh disesuaikan dengan menambahkan pelbagai kereta sampingan pada pod. Semua ini adalah kelebihan yang ketara berbanding dengan pengendali dari Crunchy Data.
Memandangkan kami memilih penyelesaian daripada Zalando antara 3 pilihan yang sedang dipertimbangkan, penerangan lanjut tentang keupayaannya akan dibentangkan di bawah, serta-merta bersama-sama dengan amalan aplikasi.
Berlatih dengan Operator Postgres dari Zalando
Penggunaan operator adalah sangat mudah: hanya muat turun keluaran semasa dari GitHub dan gunakan fail YAML dari direktori . Sebagai alternatif, anda juga boleh menggunakan .
Selepas pemasangan, anda perlu bimbang tentang penyediaan . Ini dilakukan melalui ConfigMap postgres-operator dalam ruang nama tempat anda memasang pengendali. Setelah repositori dikonfigurasikan, anda boleh menggunakan kluster PostgreSQL pertama anda.
Sebagai contoh, penggunaan standard kami kelihatan seperti ini:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
Manifes ini menggunakan sekumpulan 3 tika dengan kereta sampingan dalam bentuk , daripada mana kami mengambil metrik aplikasi. Seperti yang anda lihat, semuanya sangat mudah, dan jika anda mahu, anda boleh mencipta bilangan kluster yang tidak terhad.
Ia patut diberi perhatian panel pentadbiran web - . Ia disertakan dengan pengendali dan membolehkan anda membuat dan memadam kelompok, serta bekerja dengan sandaran yang dibuat oleh pengendali.
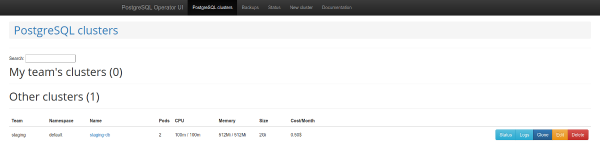
Senarai kluster PostgreSQL
Pengurusan sandaran
Satu lagi ciri menarik ialah sokongan . Mekanisme ini secara automatik mencipta peranan dalam PostgreSQL, berdasarkan senarai nama pengguna yang terhasil. API kemudiannya membenarkan anda mengembalikan senarai pengguna yang peranan dibuat secara automatik.
Masalah dan penyelesaian
Walau bagaimanapun, penggunaan pengendali tidak lama lagi mendedahkan beberapa kelemahan yang ketara:
- kekurangan sokongan nodeSelector;
- ketidakupayaan untuk melumpuhkan sandaran;
- apabila menggunakan fungsi penciptaan pangkalan data, keistimewaan lalai tidak muncul;
- Kadangkala dokumentasi tiada atau sudah lapuk.
Nasib baik, banyak daripada mereka boleh diselesaikan. Mari kita mulakan dari akhir - masalah dengan dokumentasi.
Kemungkinan besar, anda akan menghadapi hakikat bahawa tidak selalu jelas cara mendaftarkan sandaran dan cara menyambung baldi sandaran ke UI Operator. Dokumentasi bercakap tentang perkara ini secara sepintas lalu, tetapi penerangan sebenar ada :
- perlu membuat rahsia;
- serahkan kepada operator sebagai parameter
pod_environment_secret_namedalam CRD dengan tetapan operator atau dalam ConfigMap (bergantung pada cara anda memutuskan untuk memasang operator).
Walau bagaimanapun, ternyata, ini pada masa ini mustahil. Itulah sebabnya kami mengumpul dengan beberapa perkembangan tambahan pihak ketiga. Untuk maklumat lanjut mengenainya, lihat di bawah.
Jika anda menghantar parameter untuk sandaran kepada operator, iaitu - wal_s3_bucket dan kunci akses dalam AWS S3, kemudian ia akan membuat sandaran segala-galanya: bukan sahaja asas dalam pengeluaran, tetapi juga pementasan. Ini tidak sesuai dengan kami.
Dalam perihalan parameter untuk Spilo, yang merupakan pembungkus Docker asas untuk PgSQL apabila menggunakan operator, ternyata: anda boleh lulus parameter WAL_S3_BUCKET kosong, dengan itu melumpuhkan sandaran. Lebih-lebih lagi, untuk kegembiraan yang besar, saya dapati , yang segera kami terima ke dalam garpu kami. Sekarang anda hanya perlu menambah enableWALArchiving: false kepada sumber kluster PostgreSQL.
Ya, terdapat peluang untuk melakukannya secara berbeza dengan menjalankan 2 operator: satu untuk pementasan (tanpa sandaran), dan yang kedua untuk pengeluaran. Tetapi kami dapat melakukannya dengan satu.
Ok, kami belajar cara memindahkan akses kepada pangkalan data untuk S3 dan sandaran mula masuk ke dalam storan. Bagaimana untuk membuat halaman sandaran berfungsi dalam UI Operator?

Anda perlu menambah 3 pembolehubah pada UI Operator:
-
SPILO_S3_BACKUP_BUCKET -
AWS_ACCESS_KEY_ID -
AWS_SECRET_ACCESS_KEY
Selepas ini, pengurusan sandaran akan tersedia, yang dalam kes kami akan memudahkan kerja dengan pementasan, membolehkan kami menghantar kepingan daripada pengeluaran di sana tanpa skrip tambahan.
Kelebihan lain ialah kerja dengan API Teams dan peluang yang luas untuk mencipta pangkalan data dan peranan menggunakan alat pengendali. Walau bagaimanapun, yang dicipta peranan tidak mempunyai hak secara lalai. Oleh itu, pengguna yang mempunyai hak baca tidak dapat membaca jadual baharu.
Kenapa begitu? Walaupun fakta bahawa dalam kod perlu GRANT, mereka tidak selalu digunakan. Terdapat 2 kaedah: syncPreparedDatabases и syncDatabases. В syncPreparedDatabases - walaupun pada hakikatnya dalam seksyen preparedDatabases ada syarat defaultRoles и defaultUsers untuk mencipta peranan, hak lalai tidak digunakan. Kami sedang dalam proses menyediakan tampalan supaya hak ini digunakan secara automatik.
Dan perkara terakhir dalam penambahbaikan yang berkaitan dengan kami - , yang menambahkan Perkaitan Nod pada StatefulSet yang dibuat. Pelanggan kami selalunya memilih untuk mengurangkan kos dengan menggunakan contoh spot, dan mereka jelas tidak bernilai mengehos perkhidmatan pangkalan data. Isu ini boleh diselesaikan melalui toleransi, tetapi kehadiran Node Affinity memberikan keyakinan yang lebih besar.
Apa yang berlaku?
Berdasarkan hasil penyelesaian masalah di atas, kami telah memasukkan Operator Postgres dari Zalando , di mana ia dikumpul dengan tompok berguna sedemikian. Dan untuk kemudahan yang lebih besar, kami juga mengumpul .
Senarai PR yang diterima masuk ke dalam garpu:
- ;
- ;
- ;
- .
Alangkah baiknya jika komuniti menyokong PR ini supaya mereka mendapat upstream dengan versi pengendali seterusnya (1.6).
Bonus! Kisah kejayaan penghijrahan pengeluaran
Jika anda menggunakan Patroni, pengeluaran langsung boleh dipindahkan ke operator dengan masa henti yang minimum.
Spilo membolehkan anda membuat kluster siap sedia melalui storan S3 dengan , apabila log binari PgSQL pertama kali disimpan dalam S3 dan kemudian dipam keluar oleh replika. Tetapi apa yang perlu dilakukan jika anda mempunyai tiada digunakan oleh Wal-E pada infrastruktur lama? Penyelesaian kepada masalah ini sudah ada pada hab.
Replikasi logik PostgreSQL datang untuk menyelamatkan. Walau bagaimanapun, kami tidak akan menerangkan secara terperinci tentang cara membuat penerbitan dan langganan, kerana... rancangan kami gagal.
Hakikatnya ialah pangkalan data mempunyai beberapa jadual yang dimuatkan dengan berjuta-juta baris, yang, lebih-lebih lagi, sentiasa diisi semula dan dipadamkan. с copy_data, apabila replika baharu menyalin semua kandungan daripada induk, ia tidak dapat bersaing dengan induk. Menyalin kandungan berjaya selama seminggu, tetapi tidak pernah mengejar induknya. Akhirnya, ia membantu saya menyelesaikan masalah rakan sekerja dari Avito: anda boleh memindahkan data menggunakan pg_dump. Saya akan menerangkan versi algoritma ini (yang diubah suai sedikit).
Ideanya ialah anda boleh membuat langganan orang kurang upaya terikat pada slot replikasi tertentu, dan kemudian membetulkan nombor transaksi. Terdapat replika yang tersedia untuk kerja pengeluaran. Ini penting kerana replika akan membantu mencipta pembuangan yang konsisten dan terus menerima perubahan daripada induk.
Perintah seterusnya yang menerangkan proses migrasi akan menggunakan notasi hos berikut:
- master — pelayan sumber;
- replika1 — replika penstriman pada pengeluaran lama;
- replika2 - replika logik baharu.
Rancangan migrasi
1. Buat langganan pada induk untuk semua jadual dalam skema public asas dbname:
psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;"
2. Buat slot replikasi pada induk:
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');"
3. Hentikan replikasi pada replika lama:
psql -h replica1 -c "select pg_wal_replay_pause();"
4. Dapatkan nombor transaksi daripada tuan:
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';"
5. Keluarkan tempat pembuangan daripada replika lama. Kami akan melakukan ini dalam beberapa utas, yang akan membantu mempercepatkan proses:
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname
6. Muat naik dump ke pelayan baharu:
pg_restore -h replica2 -F d -j 8 -d dbname dump/
7. Selepas memuat turun dump, anda boleh memulakan replikasi pada replika penstriman:
psql -h replica1 -c "select pg_wal_replay_resume();"
7. Mari buat langganan pada replika logik baharu:
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');"
8. Jom dapatkan oid langganan:
psql -h replica2 -d dbname -c "select oid, * from pg_subscription;"
9. Katakan ia diterima oid=1000. Mari gunakan nombor transaksi pada langganan:
psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');"
10. Mari mulakan replikasi:
psql -h replica2 -d dbname -c "alter subscription oldprod enable;"
11. Semak status langganan, replikasi harus berfungsi:
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;"
psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;"
12. Selepas replikasi dimulakan dan pangkalan data disegerakkan, anda boleh beralih.
13. Selepas melumpuhkan replikasi, anda perlu membetulkan urutan. Ini diterangkan dengan baik .
Terima kasih kepada pelan ini, pertukaran berlaku dengan kelewatan yang minimum.
Kesimpulan
Pengendali Kubernetes membolehkan anda memudahkan pelbagai tindakan dengan mengurangkannya kepada penciptaan sumber K8s. Walau bagaimanapun, setelah mencapai automasi yang luar biasa dengan bantuan mereka, perlu diingat bahawa ia juga boleh membawa beberapa nuansa yang tidak dijangka, jadi pilih pengendali anda dengan bijak.
Setelah mempertimbangkan tiga pengendali Kubernetes paling popular untuk PostgreSQL, kami memilih projek daripada Zalando. Dan kami terpaksa mengatasi kesukaran tertentu dengannya, tetapi hasilnya sangat menggembirakan, jadi kami merancang untuk mengembangkan pengalaman ini kepada beberapa pemasangan PgSQL yang lain. Jika anda mempunyai pengalaman menggunakan penyelesaian yang serupa, kami akan gembira melihat butiran dalam ulasan!
PS
Baca juga di blog kami:
- «»;
- «»;
- «'.
Sumber: www.habr.com
