

Pengguna kami menulis mesej antara satu sama lain tanpa mengetahui keletihan.

Itu agak banyak. Jika anda bersedia untuk membaca semua mesej semua pengguna, ia akan mengambil masa lebih daripada 150 ribu tahun. Dengan syarat bahawa anda seorang pembaca yang agak maju dan menghabiskan tidak lebih dari satu saat untuk setiap mesej.
Dengan jumlah data sedemikian, adalah penting bahawa logik untuk menyimpan dan mengaksesnya dibina secara optimum. Jika tidak, dalam satu saat yang tidak begitu indah, ia mungkin menjadi jelas bahawa segala-galanya akan menjadi salah tidak lama lagi.
Bagi kami, detik ini datang setahun setengah yang lalu. Bagaimana kami sampai kepada ini dan apa yang berlaku pada akhirnya - kami memberitahu anda mengikut urutan.
sejarah kes
Dalam pelaksanaan pertama, mesej VKontakte berfungsi pada gabungan backend PHP dan MySQL. Ini adalah penyelesaian biasa untuk tapak web pelajar kecil. Walau bagaimanapun, tapak ini berkembang tanpa kawalan dan mula menuntut pengoptimuman struktur data untuk dirinya sendiri.
Pada penghujung tahun 2009, repositori enjin teks pertama telah ditulis, dan pada tahun 2010 mesej telah dipindahkan kepadanya.
Dalam enjin teks, mesej disimpan dalam senarai - sejenis "peti mel". Setiap senarai sedemikian ditentukan oleh uid - pengguna yang memiliki semua mesej ini. Mesej mempunyai satu set atribut: pengecam interlocutor, teks, lampiran dan sebagainya. Pengecam mesej di dalam "kotak" ialah local_id, ia tidak pernah berubah dan diberikan secara berurutan untuk mesej baharu. "Kotak" adalah bebas dan tidak disegerakkan antara satu sama lain di dalam enjin; komunikasi antara mereka berlaku pada peringkat PHP. Anda boleh melihat struktur data dan keupayaan enjin teks dari dalam .
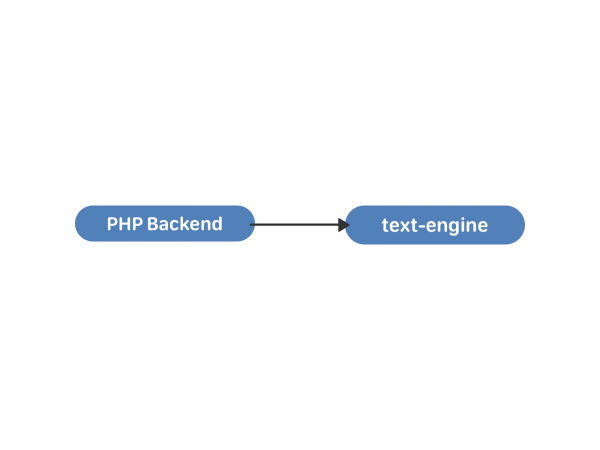
Ini sudah cukup untuk surat-menyurat antara dua pengguna. Cuba teka apa yang berlaku seterusnya?
Pada Mei 2011, VKontakte memperkenalkan perbualan dengan beberapa peserta—berbilang sembang. Untuk bekerjasama dengan mereka, kami menaikkan dua kluster baharu - ahli-sembang dan sembang-ahli. Yang pertama menyimpan data tentang sembang oleh pengguna, yang kedua menyimpan data tentang pengguna melalui sembang. Sebagai tambahan kepada senarai itu sendiri, ini termasuk, sebagai contoh, pengguna yang menjemput dan masa mereka ditambahkan pada sembang.
"PHP, mari hantar mesej ke sembang," kata pengguna.
“Ayuh, {nama pengguna},” kata PHP.
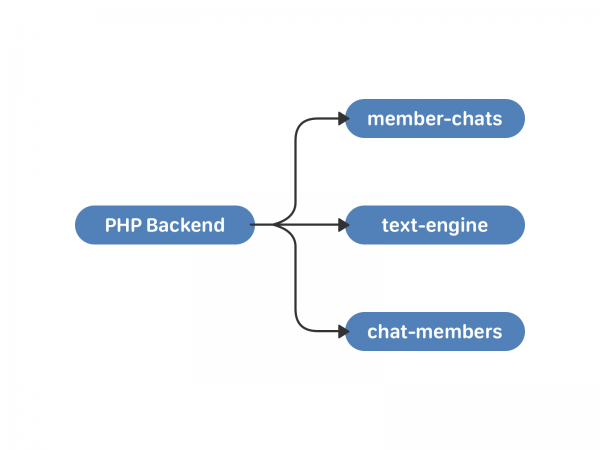
Terdapat kelemahan untuk skim ini. Penyegerakan masih menjadi tanggungjawab PHP. Sembang besar dan pengguna yang menghantar mesej kepada mereka secara serentak adalah cerita yang berbahaya. Memandangkan contoh enjin teks bergantung pada uid, peserta sembang boleh menerima mesej yang sama pada masa yang berbeza. Seseorang boleh hidup dengan ini jika kemajuan terhenti. Tetapi itu tidak akan berlaku.
Pada penghujung tahun 2015, kami melancarkan mesej komuniti dan pada awal tahun 2016, kami melancarkan API untuk mereka. Dengan kemunculan chatbot yang besar dalam komuniti, adalah mungkin untuk melupakan pengagihan beban yang sekata.
Bot yang baik menjana beberapa juta mesej setiap hari - pengguna yang paling banyak bercakap pun tidak boleh berbangga dengan ini. Ini bermakna bahawa beberapa contoh enjin teks, di mana bot tersebut hidup, mula menderita sepenuhnya.
Enjin mesej pada tahun 2016 ialah 100 contoh sembang-ahli dan sembang-ahli, dan 8000 enjin teks. Mereka dihoskan pada seribu pelayan, setiap satu dengan memori 64 GB. Sebagai langkah kecemasan pertama, kami meningkatkan memori sebanyak 32 GB lagi. Kami menganggarkan ramalan. Tanpa perubahan drastik, ini akan mencukupi untuk kira-kira setahun lagi. Anda perlu sama ada mendapatkan perkakasan atau mengoptimumkan pangkalan data itu sendiri.
Oleh kerana sifat seni bina, ia hanya masuk akal untuk meningkatkan perkakasan dalam gandaan. Iaitu, sekurang-kurangnya menggandakan bilangan kereta - jelas sekali, ini adalah laluan yang agak mahal. Kami akan mengoptimumkan.
Konsep baru
Intipati utama pendekatan baharu ialah sembang. Sembang mempunyai senarai mesej yang berkaitan dengannya. Pengguna mempunyai senarai sembang.
Minimum yang diperlukan ialah dua pangkalan data baharu:
- enjin sembang. Ini ialah repositori vektor sembang. Setiap sembang mempunyai vektor mesej yang berkaitan dengannya. Setiap mesej mempunyai teks dan pengecam mesej unik di dalam sembang - chat_local_id.
- enjin pengguna. Ini adalah storan vektor pengguna - pautan kepada pengguna. Setiap pengguna mempunyai vektor peer_id (penutur bicara - pengguna lain, berbilang sembang atau komuniti) dan vektor mesej. Setiap peer_id mempunyai vektor mesej yang berkaitan dengannya. Setiap mesej mempunyai chat_local_id dan ID mesej unik untuk pengguna tersebut - user_local_id.
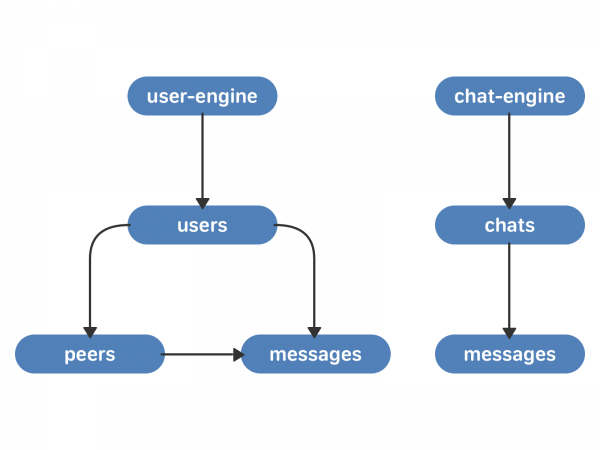
Kelompok baharu berkomunikasi antara satu sama lain menggunakan TCP - ini memastikan susunan permintaan tidak berubah. Permintaan itu sendiri dan pengesahan untuknya direkodkan pada pemacu keras - jadi kami boleh memulihkan keadaan baris gilir pada bila-bila masa selepas kegagalan atau menghidupkan semula enjin. Memandangkan enjin pengguna dan enjin sembang adalah 4 ribu serpihan setiap satu, baris gilir permintaan antara kluster akan diedarkan secara sama rata (tetapi pada hakikatnya tidak ada sama sekali - dan ia berfungsi dengan cepat).
Bekerja dengan cakera dalam pangkalan data kami dalam kebanyakan kes adalah berdasarkan gabungan log perubahan binari (binlog), syot kilat statik dan imej separa dalam ingatan. Perubahan pada siang hari ditulis ke binlog, dan petikan keadaan semasa dibuat secara berkala. Syot kilat ialah koleksi struktur data yang dioptimumkan untuk tujuan kami. Ia terdiri daripada pengepala (metaindex imej) dan satu set metafiles. Pengepala disimpan secara kekal dalam RAM dan menunjukkan tempat untuk mencari data daripada syot kilat. Setiap metafile termasuk data yang mungkin diperlukan pada masa yang dekat—contohnya, berkaitan dengan pengguna tunggal. Apabila anda menanyakan pangkalan data menggunakan pengepala syot kilat, metafail yang diperlukan dibaca, dan kemudian perubahan dalam binlog yang berlaku selepas syot kilat dicipta diambil kira. Anda boleh membaca lebih lanjut tentang faedah pendekatan ini .
Pada masa yang sama, data pada cakera keras itu sendiri berubah hanya sekali sehari - larut malam di Moscow, apabila beban adalah minimum. Terima kasih kepada ini (mengetahui bahawa struktur pada cakera adalah malar sepanjang hari), kita mampu untuk menggantikan vektor dengan tatasusunan saiz tetap - dan disebabkan ini, keuntungan dalam ingatan.
Menghantar mesej dalam skema baharu kelihatan seperti ini:
- Bahagian belakang PHP menghubungi enjin pengguna dengan permintaan untuk menghantar mesej.
- enjin pengguna memproksi permintaan kepada contoh enjin sembang yang dikehendaki, yang kembali ke chat_local_id enjin pengguna - pengecam unik mesej baharu dalam sembang ini. Enjin_sembang kemudian menyiarkan mesej kepada semua penerima dalam sembang.
- enjin pengguna menerima chat_local_id daripada chat-engine dan mengembalikan user_local_id kepada PHP - pengecam mesej unik untuk pengguna ini. Pengecam ini kemudiannya digunakan, sebagai contoh, untuk berfungsi dengan mesej melalui API.
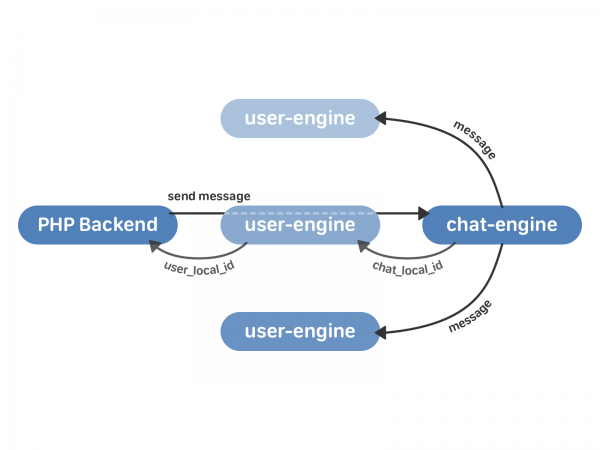
Tetapi selain daripada menghantar mesej, anda perlu melaksanakan beberapa perkara yang lebih penting:
- Subsenarai ialah, sebagai contoh, mesej terbaharu yang anda lihat semasa membuka senarai perbualan. Mesej yang belum dibaca, mesej dengan tag (“Penting”, “Spam”, dsb.).
- Memampatkan mesej dalam enjin sembang
- Caching mesej dalam enjin pengguna
- Cari (melalui semua dialog dan dalam yang khusus).
- Kemas kini masa nyata (Longpolling).
- Menyimpan sejarah untuk melaksanakan caching pada klien mudah alih.
Semua subsenarai adalah struktur yang berubah dengan pantas. Untuk bekerja dengan mereka kami gunakan . Pilihan ini dijelaskan oleh fakta bahawa di bahagian atas pokok kadangkala kami menyimpan keseluruhan segmen mesej daripada syot kilat - contohnya, selepas pengindeksan semula setiap malam, pokok itu terdiri daripada satu bahagian atas, yang mengandungi semua mesej subsenarai. Pokok Splay menjadikannya mudah untuk dimasukkan ke tengah-tengah bucu sedemikian tanpa perlu memikirkan tentang mengimbangi. Di samping itu, Splay tidak menyimpan data yang tidak diperlukan, yang menjimatkan memori kita.
Mesej melibatkan sejumlah besar maklumat, kebanyakannya teks, yang berguna untuk dapat dimampatkan. Adalah penting bahawa kita boleh menyahrkibkan walaupun satu mesej individu dengan tepat. Digunakan untuk memampatkan mesej dengan heuristik kita sendiri - sebagai contoh, kita tahu bahawa dalam mesej perkataan bergantian dengan "bukan perkataan" - ruang, tanda baca - dan kami juga mengingati beberapa ciri menggunakan simbol untuk bahasa Rusia.
Memandangkan terdapat lebih sedikit pengguna daripada sembang, untuk menyimpan permintaan cakera akses rawak dalam enjin sembang, kami menyimpan mesej dalam enjin pengguna.
Carian mesej dilaksanakan sebagai pertanyaan pepenjuru daripada enjin pengguna kepada semua kejadian enjin sembang yang mengandungi sembang pengguna ini. Hasilnya digabungkan dalam enjin pengguna itu sendiri.
Nah, semua butiran telah diambil kira, yang tinggal hanyalah beralih kepada skim baharu - dan sebaik-baiknya tanpa disedari oleh pengguna.
Penghijrahan data
Jadi, kami mempunyai enjin teks yang menyimpan mesej mengikut pengguna, dan dua kluster sembang-ahli dan sembang-ahli yang menyimpan data tentang bilik berbilang sembang dan pengguna di dalamnya. Bagaimana untuk beralih daripada ini kepada enjin pengguna dan enjin sembang baharu?
sembang ahli dalam skema lama digunakan terutamanya untuk pengoptimuman. Kami dengan cepat memindahkan data yang diperlukan daripadanya kepada ahli sembang, dan kemudian ia tidak lagi mengambil bahagian dalam proses migrasi.
Beratur untuk ahli sembang. Ia termasuk 100 contoh, manakala enjin sembang mempunyai 4 ribu. Untuk memindahkan data, anda perlu memasukkannya ke dalam pematuhan - untuk ini, ahli sembang dibahagikan kepada 4 ribu salinan yang sama, dan kemudian membaca binlog ahli sembang telah didayakan dalam enjin sembang.
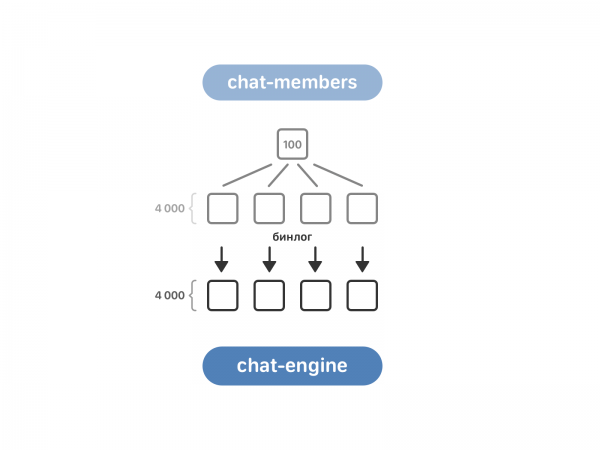
Sekarang enjin sembang tahu tentang berbilang sembang daripada ahli sembang, tetapi ia belum tahu apa-apa tentang dialog dengan dua orang lawan bicara. Dialog sedemikian terletak dalam enjin teks dengan merujuk kepada pengguna. Di sini kami mengambil data "head-on": setiap contoh enjin sembang bertanya kepada semua contoh enjin teks jika mereka mempunyai dialog yang diperlukan.
Hebat - enjin sembang tahu sembang berbilang sembang yang ada dan tahu dialog apa yang ada.
Anda perlu menggabungkan mesej dalam sembang berbilang sembang supaya anda mendapat senarai mesej dalam setiap sembang. Mula-mula, enjin sembang mendapatkan semula daripada enjin teks semua mesej pengguna daripada sembang ini. Dalam sesetengah kes, terdapat banyak daripada mereka (sehingga ratusan juta), tetapi dengan pengecualian yang sangat jarang berlaku, sembang sesuai sepenuhnya dengan RAM. Kami mempunyai mesej tidak tersusun, masing-masing dalam beberapa salinan - lagipun, ia semua ditarik dari contoh enjin teks berbeza yang sepadan dengan pengguna. Matlamatnya adalah untuk mengisih mesej dan menyingkirkan salinan yang mengambil ruang yang tidak perlu.
Setiap mesej mempunyai cap masa yang mengandungi masa ia dihantar dan teks. Kami menggunakan masa untuk mengisih - kami meletakkan penunjuk kepada mesej tertua peserta berbilang sembang dan membandingkan cincangan daripada teks salinan yang dimaksudkan, bergerak ke arah peningkatan cap masa. Adalah logik bahawa salinan akan mempunyai cincangan dan cap masa yang sama, tetapi dalam amalan ini tidak selalu berlaku. Seperti yang anda ingat, penyegerakan dalam skema lama telah dijalankan oleh PHP - dan dalam kes yang jarang berlaku, masa menghantar mesej yang sama berbeza antara pengguna yang berbeza. Dalam kes ini, kami membenarkan diri kami mengedit cap masa - biasanya dalam satu saat. Masalah kedua ialah susunan mesej yang berbeza untuk penerima yang berbeza. Dalam kes sedemikian, kami membenarkan salinan tambahan dibuat, dengan pilihan pesanan yang berbeza untuk pengguna yang berbeza.
Selepas ini, data tentang mesej dalam berbilang sembang dihantar ke enjin pengguna. Dan di sini datang ciri yang tidak menyenangkan bagi mesej yang diimport. Dalam operasi biasa, mesej yang datang ke enjin dipesan dengan ketat dalam tertib menaik oleh user_local_id. Mesej yang diimport daripada enjin lama ke dalam enjin pengguna kehilangan harta berguna ini. Pada masa yang sama, untuk kemudahan ujian, anda perlu dapat mengaksesnya dengan cepat, mencari sesuatu di dalamnya dan menambah yang baharu.
Kami menggunakan struktur data khas untuk menyimpan mesej yang diimport.
Ia mewakili vektor saiz  mana semua orang
mana semua orang  - berbeza dan tersusun dalam tertib menurun, dengan susunan elemen khas. Dalam setiap segmen dengan indeks
- berbeza dan tersusun dalam tertib menurun, dengan susunan elemen khas. Dalam setiap segmen dengan indeks  elemen disusun. Mencari elemen dalam struktur sedemikian memerlukan masa
elemen disusun. Mencari elemen dalam struktur sedemikian memerlukan masa  melalui
melalui  carian binari. Penambahan elemen dilunaskan
carian binari. Penambahan elemen dilunaskan  .
.
Jadi, kami mengetahui cara memindahkan data daripada enjin lama kepada yang baharu. Tetapi proses ini mengambil masa beberapa hari - dan tidak mungkin pada hari ini pengguna kami akan meninggalkan tabiat menulis antara satu sama lain. Untuk tidak kehilangan mesej pada masa ini, kami beralih kepada skema kerja yang menggunakan kluster lama dan baharu.
Data ditulis kepada ahli sembang dan enjin pengguna (dan bukan kepada enjin teks, seperti dalam operasi biasa mengikut skema lama). enjin pengguna memproksi permintaan kepada enjin sembang - dan di sini tingkah laku bergantung pada sama ada sembang ini telah digabungkan atau tidak. Jika sembang belum digabungkan, enjin sembang tidak menulis mesej itu kepada dirinya sendiri dan pemprosesannya hanya berlaku dalam enjin teks. Jika sembang telah digabungkan ke dalam enjin sembang, ia mengembalikan chat_local_id kepada enjin pengguna dan menghantar mesej kepada semua penerima. enjin pengguna memproksi semua data ke enjin teks - supaya jika sesuatu berlaku, kami sentiasa boleh melancarkan semula, mempunyai semua data semasa dalam enjin lama. text-engine mengembalikan user_local_id, yang disimpan oleh enjin pengguna dan kembali ke bahagian belakang.
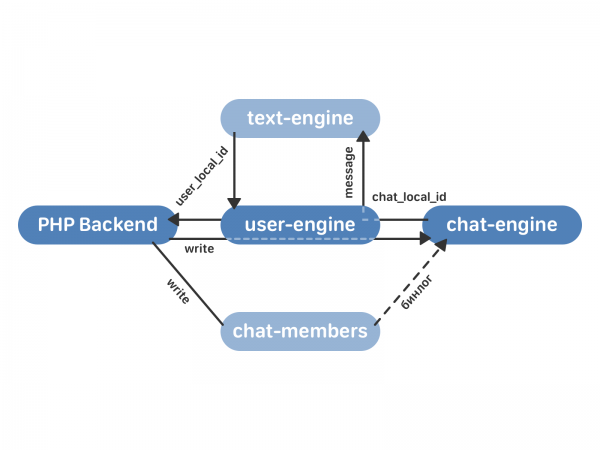
Akibatnya, proses peralihan kelihatan seperti ini: kami menyambungkan gugusan enjin pengguna dan enjin sembang kosong. enjin sembang membaca keseluruhan binlog ahli sembang, kemudian proksi bermula mengikut skema yang diterangkan di atas. Kami memindahkan data lama dan mendapatkan dua kluster yang disegerakkan (lama dan baharu). Yang tinggal hanyalah menukar bacaan daripada enjin teks kepada enjin pengguna dan melumpuhkan proksi.
Penemuan
Terima kasih kepada pendekatan baharu, semua metrik prestasi enjin telah dipertingkatkan dan masalah dengan ketekalan data telah diselesaikan. Kini kami boleh melaksanakan ciri baharu dengan pantas dalam mesej (dan telah pun mula melakukan ini - kami meningkatkan bilangan maksimum peserta sembang, melaksanakan carian untuk mesej yang dimajukan, melancarkan mesej yang disematkan dan menaikkan had jumlah bilangan mesej bagi setiap pengguna) .
Perubahan dalam logik benar-benar besar. Dan saya ingin ambil perhatian bahawa ini tidak selalu bermakna pembangunan sepanjang tahun oleh pasukan yang besar dan berjuta-juta baris kod. enjin sembang dan enjin pengguna bersama-sama dengan semua cerita tambahan seperti Huffman untuk pemampatan mesej, pokok Splay dan struktur untuk mesej yang diimport adalah kurang daripada 20 ribu baris kod. Dan mereka telah ditulis oleh 3 pembangun dalam masa 10 bulan sahaja (namun, perlu diingat bahawa - juara dunia ).
Selain itu, daripada menggandakan bilangan pelayan, kami mengurangkan bilangan pelayan sebanyak separuh - kini enjin pengguna dan enjin sembang hidup pada 500 mesin fizikal, manakala skim baharu mempunyai ruang kepala yang besar untuk memuatkan. Kami menjimatkan banyak wang untuk peralatan - kira-kira $5 juta + $750 ribu setahun dalam perbelanjaan operasi.
Kami berusaha untuk mencari penyelesaian terbaik untuk masalah yang paling kompleks dan berskala besar. Kami mempunyai banyak daripada mereka - dan itulah sebabnya kami mencari pembangun berbakat dalam jabatan pangkalan data. Jika anda suka dan tahu cara menyelesaikan masalah sedemikian, mempunyai pengetahuan yang sangat baik tentang algoritma dan struktur data, kami menjemput anda untuk menyertai pasukan. Hubungi kami untuk butiran.
Walaupun cerita ini bukan tentang anda, sila ambil perhatian bahawa kami menghargai cadangan. Beritahu rakan tentang , dan jika dia berjaya menyelesaikan tempoh percubaan, anda akan menerima bonus sebanyak 100 ribu rubel.
Sumber: www.habr.com
