

Dari semasa ke semasa, pemaju memerlukan lulus satu set parameter atau malah keseluruhan pilihan kepada permintaan "di pintu masuk". Kadang-kadang terdapat penyelesaian yang sangat aneh untuk masalah ini.
Mari kita pergi "dari sebaliknya" dan lihat cara untuk tidak melakukannya, mengapa dan bagaimana anda boleh melakukannya dengan lebih baik.
"Penyisipan" nilai secara langsung dalam badan permintaan
Ia biasanya kelihatan seperti ini:
query = "SELECT * FROM tbl WHERE id = " + value... atau seperti ini:
query = "SELECT * FROM tbl WHERE id = :param".format(param=value)Mengenai kaedah ini dikatakan, ditulis dan cukup:

Hampir selalu begitu laluan terus ke suntikan SQL dan beban tambahan pada logik perniagaan, yang terpaksa "melekatkan" rentetan pertanyaan anda.
Pendekatan ini boleh dibenarkan sebahagiannya hanya jika perlu. gunakan partitioning dalam PostgreSQL versi 10 dan ke bawah untuk rancangan yang lebih cekap. Dalam versi ini, senarai bahagian yang diimbas ditentukan tanpa mengambil kira parameter yang dihantar, hanya berdasarkan badan permintaan.
$n-hujah
Gunakan parameter adalah baik, ia membolehkan anda untuk menggunakan , mengurangkan beban kedua-dua pada logik perniagaan (rentetan pertanyaan dibentuk dan dihantar sekali sahaja) dan pada pelayan pangkalan data (penghuraian semula dan perancangan tidak diperlukan untuk setiap contoh permintaan).
Bilangan pembolehubah argumen
Masalah akan menanti kita apabila kita ingin menyampaikan bilangan hujah yang tidak diketahui terlebih dahulu:
... id IN ($1, $2, $3, ...) -- $1 : 2, $2 : 3, $3 : 5, ...Jika anda meninggalkan permintaan dalam borang ini, maka walaupun ia akan menyelamatkan kami daripada kemungkinan suntikan, ia masih akan membawa kepada keperluan untuk melekatkan / menghuraikan permintaan untuk setiap pilihan daripada bilangan hujah. Sudah lebih baik daripada melakukannya setiap kali, tetapi anda boleh melakukannya tanpanya.
Ia cukup untuk lulus hanya satu parameter yang mengandungi perwakilan bersiri tatasusunan:
... id = ANY($1::integer[]) -- $1 : '{2,3,5,8,13}'Satu-satunya perbezaan ialah keperluan untuk menukar hujah secara eksplisit kepada jenis tatasusunan yang dikehendaki. Tetapi ini tidak menimbulkan masalah, kerana kita sudah tahu terlebih dahulu di mana kita menangani.
Pemindahan sampel (matriks)
Biasanya ini adalah pelbagai pilihan untuk memindahkan set data untuk dimasukkan ke dalam pangkalan data "dalam satu permintaan":
INSERT INTO tbl(k, v) VALUES($1,$2),($3,$4),...Sebagai tambahan kepada masalah yang diterangkan di atas dengan "pelekatan semula" permintaan, ini juga boleh membawa kita ke Lupa dan ranap pelayan. Alasannya mudah - PG menyimpan memori tambahan untuk hujah, dan bilangan rekod dalam set hanya dihadkan oleh Senarai Hajat aplikasi logik perniagaan. Dalam kes klinikal terutamanya adalah perlu untuk melihat hujah "bernombor" lebih besar daripada $9000 - jangan lakukan dengan cara ini.
Mari tulis semula pertanyaan, sudah pun memohon siri "dua peringkat".:
INSERT INTO tbl
SELECT
unnest[1]::text k
, unnest[2]::integer v
FROM (
SELECT
unnest($1::text[])::text[] -- $1 : '{"{a,1}","{b,2}","{c,3}","{d,4}"}'
) T;
Ya, dalam kes nilai "kompleks" di dalam tatasusunan, mereka perlu dibingkai dengan petikan.
Adalah jelas bahawa dengan cara ini anda boleh "mengembangkan" pemilihan dengan bilangan medan yang sewenang-wenangnya.
tidak bersarang, tidak bersarang,…
Dari semasa ke semasa terdapat pilihan untuk lulus dan bukannya "tatasusunan" beberapa "tatasusunan lajur" yang saya nyatakan :
SELECT
unnest($1::text[]) k
, unnest($2::integer[]) v;Dengan kaedah ini, jika anda membuat kesilapan semasa menjana senarai nilai untuk lajur yang berbeza, sangat mudah untuk mendapatkan sepenuhnya hasil yang tidak dijangka, yang juga bergantung pada versi pelayan:
-- $1 : '{a,b,c}', $2 : '{1,2}'
-- PostgreSQL 9.4
k | v
-----
a | 1
b | 2
c | 1
a | 2
b | 1
c | 2
-- PostgreSQL 11
k | v
-----
a | 1
b | 2
c |JSON
Bermula dari versi 9.3, PostgreSQL mempunyai fungsi lengkap untuk bekerja dengan jenis json. Oleh itu, jika parameter input anda ditakrifkan dalam penyemak imbas, anda boleh terus ke sana dan membentuk objek json untuk pertanyaan SQL:
SELECT
key k
, value v
FROM
json_each($1::json); -- '{"a":1,"b":2,"c":3,"d":4}'Untuk versi terdahulu, kaedah yang sama boleh digunakan untuk setiap (hstore), tetapi "lipatan" yang betul dengan melarikan objek kompleks dalam hstore boleh menyebabkan masalah.
json_populate_recordset
Jika anda mengetahui terlebih dahulu bahawa data daripada tatasusunan json "input" akan diisi untuk beberapa jadual, anda boleh menyimpan banyak dalam medan "menderujuk" dan menghantar kepada jenis yang dikehendaki menggunakan fungsi json_populate_recordset:
SELECT
*
FROM
json_populate_recordset(
NULL::pg_class
, $1::json -- $1 : '[{"relname":"pg_class","oid":1262},{"relname":"pg_namespace","oid":2615}]'
);json_to_recordset
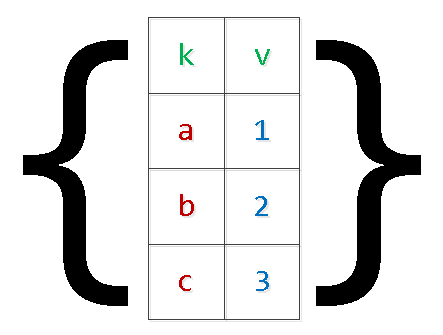
Dan fungsi ini hanya akan "mengembangkan" tatasusunan objek yang diluluskan ke dalam pilihan, tanpa bergantung pada format jadual:
SELECT
*
FROM
json_to_recordset($1::json) T(k text, v integer);
-- $1 : '[{"k":"a","v":1},{"k":"b","v":2}]'
k | v
-----
a | 1
b | 2JADUAL SEMENTARA
Tetapi jika jumlah data dalam sampel yang dihantar adalah sangat besar, maka membuangnya ke dalam satu parameter bersiri adalah sukar, dan kadang-kadang mustahil, kerana ia memerlukan satu kali peruntukan memori yang besar. Sebagai contoh, anda perlu mengumpul kumpulan besar data peristiwa daripada sistem luaran untuk masa yang lama dan lama, dan kemudian anda mahu memprosesnya sekali sahaja di sisi pangkalan data.
Dalam kes ini, penyelesaian terbaik adalah menggunakan :
CREATE TEMPORARY TABLE tbl(k text, v integer);
...
INSERT INTO tbl(k, v) VALUES($1, $2); -- повторить много-много раз
...
-- тут делаем что-то полезное со всей этой таблицей целиком
Kaedahnya bagus untuk penghantaran jarang dalam jumlah besar data.
Dari sudut pandangan menerangkan struktur datanya, jadual sementara berbeza daripada jadual "biasa" dalam hanya satu ciri. dalam jadual sistem pg_class, dan dalam pg_type, pg_depend, pg_attribute, pg_attrdef, ... — dan tiada apa-apa.
Oleh itu, dalam sistem web dengan sejumlah besar sambungan jangka pendek untuk setiap satu daripada mereka, jadual sedemikian akan menghasilkan rekod sistem baharu setiap kali, yang dipadamkan apabila sambungan ke pangkalan data ditutup. Akhirnya, penggunaan TEMP TABLE yang tidak terkawal membawa kepada "bengkak" jadual dalam pg_catalog dan memperlahankan banyak operasi yang menggunakannya.
Sudah tentu, ini boleh dilawan pas berkala VACUUM PENUH mengikut jadual katalog sistem.
Pembolehubah Sesi
Katakan pemprosesan data daripada kes sebelumnya agak rumit untuk satu pertanyaan SQL, tetapi anda mahu melakukannya dengan kerap. Iaitu, kami mahu menggunakan pemprosesan prosedur dalam , tetapi menggunakan pemindahan data melalui jadual sementara akan menjadi terlalu mahal.
Kami juga tidak boleh menggunakan $n-parameters untuk menghantar ke blok tanpa nama. Pembolehubah sesi dan fungsi akan membantu kita keluar dari situasi itu. tetapan_semasa.
Sebelum versi 9.2, anda perlu membuat prakonfigurasi kelas_pembolehubah_suai untuk pembolehubah sesi "mereka". Pada versi semasa, anda boleh menulis sesuatu seperti ini:
SET my.val = '{1,2,3}';
DO $$
DECLARE
id integer;
BEGIN
FOR id IN (SELECT unnest(current_setting('my.val')::integer[])) LOOP
RAISE NOTICE 'id : %', id;
END LOOP;
END;
$$ LANGUAGE plpgsql;
-- NOTICE: id : 1
-- NOTICE: id : 2
-- NOTICE: id : 3Terdapat penyelesaian lain yang tersedia dalam bahasa prosedur lain yang disokong.
Tahu lebih banyak cara? Kongsi dalam komen!
Sumber: www.habr.com
