

Saya cadangkan anda membaca transkrip laporan Nikolai Samokhvalov "Pendekatan industri untuk menala PostgreSQL: eksperimen pada pangkalan data"
Shared_buffers = 25% – adakah ia banyak atau sedikit? Atau betul? Bagaimanakah anda tahu jika cadangan ini - agak ketinggalan zaman - sesuai dalam kes tertentu anda?
Sudah tiba masanya untuk mendekati isu memilih parameter postgresql.conf "seperti orang dewasa." Bukan dengan bantuan "penala automatik" buta atau nasihat ketinggalan zaman daripada artikel dan blog, tetapi berdasarkan:
- eksperimen yang disahkan dengan ketat pada pangkalan data, dijalankan secara automatik, dalam kuantiti yang banyak dan dalam keadaan sedekat mungkin untuk "melawan" yang,
- pemahaman yang mendalam tentang ciri-ciri DBMS dan OS.
Menggunakan Nancy CLI (), kami akan melihat contoh khusus - shared_buffers yang terkenal - dalam situasi yang berbeza, dalam projek yang berbeza dan cuba memikirkan cara memilih tetapan optimum untuk infrastruktur, pangkalan data dan beban kami.

Kami akan bercakap tentang eksperimen dengan pangkalan data. Ini adalah kisah yang berlangsung lebih kurang enam bulan.

Sedikit tentang saya. Pengalaman dengan Postgres selama lebih daripada 14 tahun. Beberapa syarikat rangkaian sosial telah diasaskan. Postgres telah dan digunakan di mana-mana sahaja.
Juga kumpulan RuPostgres di Meetup, tempat ke-2 di dunia. Kami perlahan-lahan menghampiri 2 orang. RuPostgres.org.
Dan di PC pelbagai persidangan, termasuk Highload, saya bertanggungjawab untuk pangkalan data, khususnya Postgres dari awal lagi.

Dan dalam beberapa tahun kebelakangan ini, saya telah memulakan semula latihan perundingan Postgres saya 11 zon waktu dari sini.

Dan apabila saya melakukan ini beberapa tahun yang lalu, saya telah berehat sedikit dalam kerja manual aktif dengan Postgres, mungkin sejak 2010. Saya terkejut betapa sedikit perubahan rutin kerja DBA, dan berapa banyak kerja manual yang masih perlu digunakan. Dan saya serta-merta berfikir bahawa ada sesuatu yang tidak kena di sini, saya perlu mengautomasikan lebih banyak segala-galanya.
Dan kerana semuanya terpencil, kebanyakan pelanggan berada di awan. Dan banyak yang telah diautomasikan, jelas. Lebih lanjut mengenai ini kemudian. Iaitu, semua ini menghasilkan idea bahawa perlu ada beberapa alat, iaitu, beberapa jenis platform yang akan mengautomasikan hampir semua tindakan DBA supaya sejumlah besar pangkalan data boleh diuruskan.

Laporan ini tidak akan termasuk:
- “Penampan perak” dan pernyataan seperti - tetapkan 8 GB atau 25% shared_buffers dan anda akan baik-baik saja. Tidak banyak tentang shared_buffers.
- Tegar "dalaman".

Apa yang akan berlaku?
- Akan ada prinsip pengoptimuman yang kami gunakan dan bangunkan. Akan ada pelbagai idea yang timbul sepanjang perjalanan dan pelbagai alat yang kami cipta sebahagian besarnya dalam Sumber Terbuka, iaitu kami membuat asas dalam Sumber Terbuka. Lebih-lebih lagi, kami mempunyai tiket, semua komunikasi boleh dikatakan Sumber Terbuka. Anda boleh melihat apa yang kami lakukan sekarang, apa yang akan ada dalam keluaran seterusnya, dsb.
- Terdapat juga beberapa pengalaman dalam menggunakan prinsip ini, alat ini dalam beberapa syarikat: daripada syarikat permulaan kecil kepada syarikat besar.

Bagaimana ini semua berkembang?

Pertama, tugas utama DBA, selain memastikan penciptaan contoh, penggunaan sandaran, dll., adalah untuk mencari kesesakan dan mengoptimumkan prestasi.
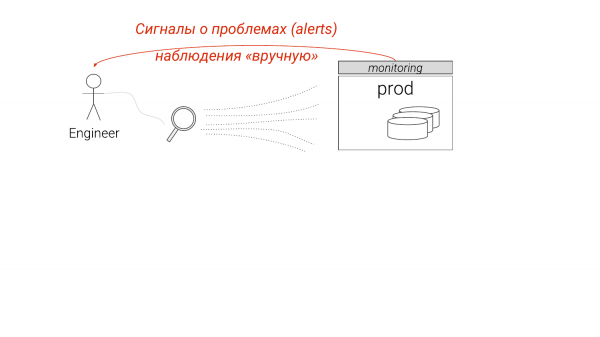
Sekarang ia telah ditetapkan seperti ini. Kami melihat pemantauan, kami melihat sesuatu, tetapi kami kehilangan beberapa butiran. Kami mula menggali dengan lebih berhati-hati, biasanya dengan tangan kami, dan memahami apa yang perlu dilakukan dengannya satu cara atau yang lain.
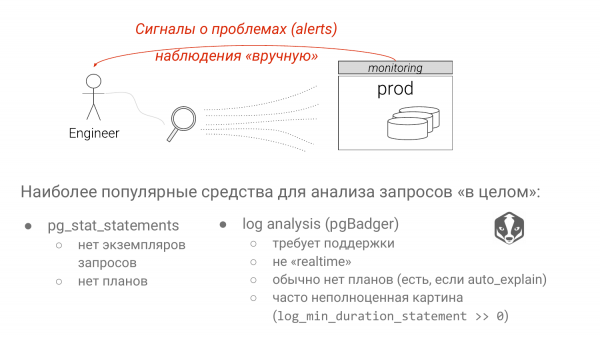
Dan terdapat dua pendekatan. Pg_stat_statements ialah penyelesaian lalai untuk mengenal pasti pertanyaan perlahan. Dan analisis log Postgres menggunakan pgBadger.
Setiap pendekatan mempunyai kelemahan yang serius. Dalam pendekatan pertama, kami telah membuang semua parameter. Dan jika kita melihat kumpulan SELECT * FROM jadual di mana lajur adalah sama dengan "?" atau “$” sejak Postgres 10. Kami tidak tahu sama ada ini imbasan indeks atau imbasan seq. Ia sangat bergantung pada parameter. Jika anda menggantikan nilai yang jarang ditemui di sana, ia akan menjadi imbasan indeks. Jika anda menggantikan nilai yang menduduki 90% daripada jadual di sana, imbasan seq akan jelas, kerana Postgres mengetahui statistiknya. Dan ini adalah kelemahan besar pg_stat_statements, walaupun beberapa kerja sedang dijalankan.
Kelemahan terbesar analisis log ialah anda tidak mampu membeli "log_min_duration_statement = 0" sebagai peraturan. Dan kita akan bercakap tentang ini juga. Oleh itu, anda tidak melihat keseluruhan gambar. Dan beberapa pertanyaan, yang sangat pantas, mungkin menggunakan sejumlah besar sumber, tetapi anda tidak akan melihatnya kerana ia berada di bawah ambang anda.
Bagaimanakah DBA menyelesaikan masalah yang mereka temui?
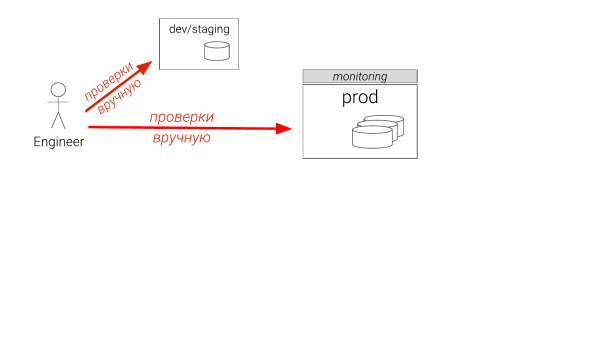
Sebagai contoh, kami menemui beberapa masalah. Apa yang biasa dilakukan? Jika anda seorang pembangun, maka anda akan melakukan sesuatu pada beberapa contoh yang bukan saiz yang sama. Jika anda seorang DBA, maka anda mempunyai pementasan. Dan hanya boleh ada satu. Dan dia ketinggalan enam bulan. Dan anda fikir anda akan pergi ke pengeluaran. Dan juga DBA yang berpengalaman kemudian mendaftar masuk pengeluaran, pada replika. Dan ia berlaku bahawa mereka mencipta indeks sementara, pastikan ia membantu, lepaskan dan berikannya kepada pemaju supaya mereka boleh memasukkannya ke dalam fail migrasi. Ini adalah jenis karut yang berlaku sekarang. Dan ini adalah masalah.
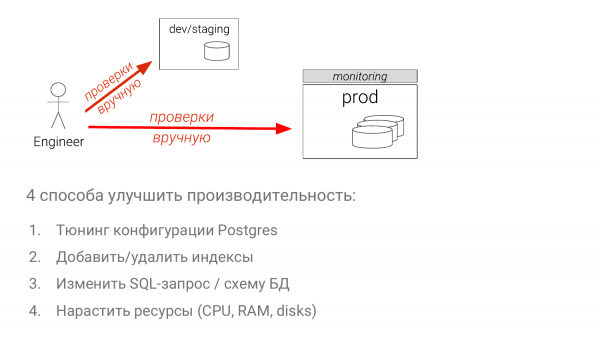
- Tetapkan konfigurasi.
- Optimumkan set indeks.
- Tukar pertanyaan SQL itu sendiri (ini adalah cara yang paling sukar).
- Tambah kapasiti (cara termudah dalam kebanyakan kes).

Terdapat banyak perkara yang berlaku dengan perkara ini. Terdapat banyak pemegang dalam Postgres. Terdapat banyak yang perlu diketahui. Terdapat banyak indeks dalam Postgres, terima kasih juga kepada penganjur persidangan ini. Dan semua ini perlu diketahui, dan inilah yang membuatkan bukan DBA berasa seperti DBA mengamalkan ilmu hitam. Maksudnya, anda perlu belajar selama 10 tahun untuk mula memahami semua ini secara normal.
Dan saya seorang pejuang melawan ilmu hitam ini. Saya mahu melakukan segala-galanya supaya ada teknologi, dan tidak ada intuisi dalam semua ini.
Contoh kehidupan sebenar

Saya memerhati perkara ini dalam sekurang-kurangnya dua projek, termasuk projek saya sendiri. Catatan blog lain memberitahu kami bahawa nilai 1 untuk default_statistict_target adalah baik. Baiklah, mari kita cuba dalam pengeluaran.

Dan inilah kita, menggunakan alat kami dua tahun kemudian, dengan bantuan eksperimen pada pangkalan data yang kita bicarakan hari ini, kita boleh membandingkan apa yang telah dan apa yang telah berlaku.
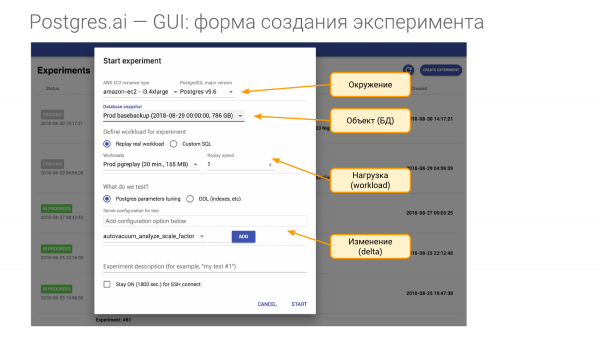
Dan untuk ini kita perlu membuat percubaan. Ia terdiri daripada empat bahagian.
- Yang pertama ialah persekitaran. Kami memerlukan sekeping perkakasan. Dan apabila saya datang ke beberapa syarikat dan menandatangani kontrak, saya memberitahu mereka untuk memberi saya perkakasan yang sama seperti dalam pengeluaran. Untuk setiap Sarjana anda, saya memerlukan sekurang-kurangnya satu perkakasan seperti ini. Sama ada ini mesin maya contoh di Amazon atau Google, atau saya memerlukan perkakasan yang sama. Iaitu, saya mahu mencipta semula persekitaran. Dan dalam konsep persekitaran kami memasukkan versi utama Postgres.
- Bahagian kedua ialah objek kajian kami. Ini adalah pangkalan data. Ia boleh dicipta dalam beberapa cara. Saya akan tunjukkan caranya.
- Bahagian ketiga ialah beban. Inilah saat yang paling sukar.
- Dan bahagian keempat adalah apa yang kita semak, iaitu apa yang kita akan bandingkan dengan apa. Katakan kita boleh menukar satu atau lebih parameter dalam konfigurasi, atau kita boleh mencipta indeks, dsb.
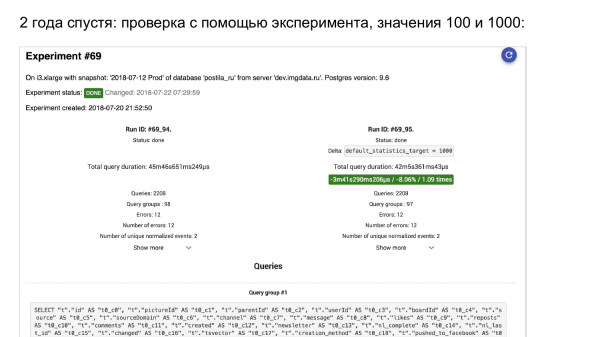
Kami sedang melancarkan percubaan. Berikut ialah pg_stat_statements. Di sebelah kiri adalah apa yang berlaku. Di sebelah kanan - apa yang berlaku.
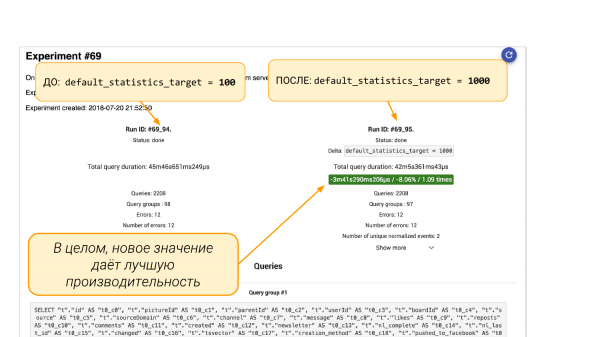
Di sebelah kiri default_statistics_target = 100, di sebelah kanan =1. Kami melihat bahawa ini membantu kami. Secara keseluruhan, semuanya menjadi lebih baik sebanyak 000%.
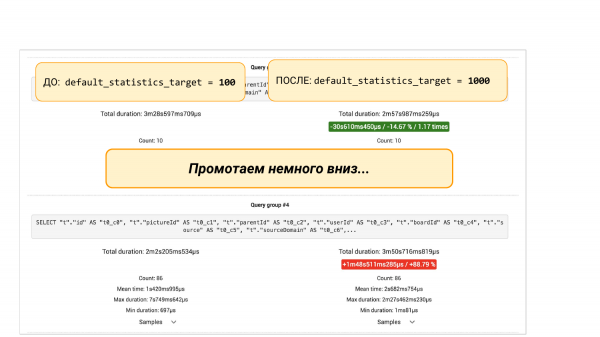
Tetapi jika kita tatal ke bawah, akan terdapat kumpulan permintaan daripada pgBadger atau daripada pg_stat_statements. Terdapat dua pilihan. Kami akan melihat bahawa beberapa permintaan telah menurun sebanyak 88%. Dan inilah pendekatan kejuruteraan. Kita boleh menggali lebih dalam kerana kita tertanya-tanya mengapa ia tenggelam. Anda perlu memahami apa yang berlaku dengan statistik. Mengapa lebih banyak baldi dalam statistik membawa kepada keputusan yang lebih buruk.
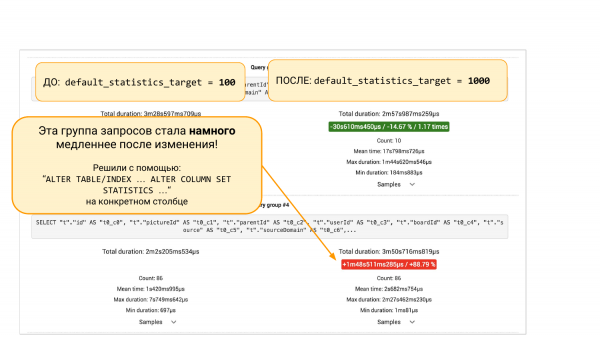
Atau kita tidak boleh menggali, tetapi lakukan "ALTER TABLE ... ALTER COLUMN" dan kembalikan 100 baldi kembali ke statistik lajur ini. Dan kemudian dengan percubaan lain kami boleh memastikan bahawa tampung ini membantu. Semua. Ini ialah pendekatan kejuruteraan yang membantu kami melihat gambaran besar dan membuat keputusan berdasarkan data dan bukannya intuisi.


Beberapa contoh dari kawasan lain. Terdapat ujian CI dalam ujian selama bertahun-tahun. Dan tiada projek dalam fikiran yang waras akan hidup tanpa ujian automatik.
Dalam industri lain: dalam penerbangan, dalam industri automotif, apabila kami menguji aerodinamik, kami juga mempunyai peluang untuk melakukan eksperimen. Kami tidak akan melancarkan sesuatu daripada lukisan terus ke angkasa, atau kami tidak akan segera membawa beberapa kereta ke trek. Sebagai contoh, terdapat terowong angin.
Kita boleh membuat kesimpulan daripada pemerhatian industri lain.

Pertama, kita mempunyai persekitaran yang istimewa. Ia hampir dengan pengeluaran, tetapi tidak dekat. Ciri utamanya ialah ia mestilah murah, boleh diulang dan seautomatik yang mungkin. Dan juga mesti ada alat khas untuk menjalankan analisis terperinci.
Kemungkinan besar, apabila kita melancarkan pesawat dan terbang, kita mempunyai kurang peluang untuk mengkaji setiap milimeter permukaan sayap daripada yang kita ada dalam terowong angin. Kami mempunyai lebih banyak alat diagnostik. Kami mampu membawa lebih banyak barang berat yang kami tidak mampu untuk meletakkan di atas kapal terbang di udara. Sama dengan Postgres. Kami mungkin, dalam beberapa kes, mendayakan pengelogan pertanyaan penuh semasa percubaan. Dan kami tidak mahu melakukan ini dalam pengeluaran. Kami mungkin merancang untuk mendayakan ini menggunakan auto_explain.
Dan seperti yang saya katakan, tahap automasi yang tinggi bermakna kita menekan butang dan ulangi. Ini adalah bagaimana ia sepatutnya, supaya terdapat banyak percubaan, supaya ia berada di strim.
Nancy CLI - asas "makmal pangkalan data"

Dan jadi kami melakukan perkara ini. Iaitu, saya bercakap tentang idea-idea ini pada bulan Jun, hampir setahun yang lalu. Dan kami sudah mempunyai apa yang dipanggil Nancy CLI dalam Sumber Terbuka. Ini adalah asas untuk membina makmal pangkalan data.
— Ia dalam Sumber Terbuka, di Gitlab. Anda boleh mengatakannya, anda boleh mencubanya. Saya menyediakan pautan dalam slaid. Anda boleh klik padanya dan ia akan berada di sana dalam semua aspek.
Sudah tentu, masih banyak yang masih dalam pembangunan. Terdapat banyak idea di sana. Tetapi ini adalah sesuatu yang kami gunakan hampir setiap hari. Dan apabila kita mempunyai idea - mengapa apabila kita memadamkan 40 baris, semuanya terpulang kepada IO, maka kita boleh menjalankan eksperimen dan melihat dengan lebih terperinci untuk memahami apa yang berlaku dan kemudian cuba membetulkannya dengan cepat. Iaitu, kami sedang melakukan eksperimen. Sebagai contoh, kita mengubah sesuatu dan melihat apa yang berlaku pada akhirnya. Dan kami tidak melakukan ini dalam pengeluaran. Inilah intipati idea.
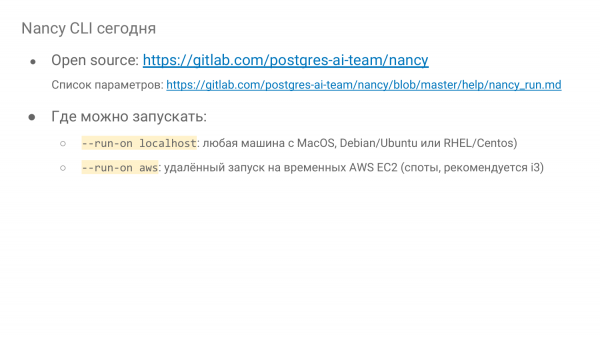
Di mana ini boleh berfungsi? Ini boleh berfungsi secara tempatan, iaitu anda boleh melakukannya di mana-mana, malah anda boleh menjalankannya pada MacBook. Kita perlukan pekerja pelabuhan, mari kita pergi. Itu sahaja. Anda boleh menjalankannya dalam beberapa contoh pada sekeping perkakasan, atau dalam mesin maya, di mana-mana sahaja.
Dan terdapat juga peluang untuk berjalan dari jauh di Amazon dalam Instance EC2, di tempat. Dan ini adalah peluang yang sangat menarik. Sebagai contoh, semalam kami telah menjalankan lebih daripada 500 percubaan pada contoh i3, bermula dengan yang termuda dan berakhir dengan i3-16-xlarge. Dan 500 percubaan berharga $64. Setiap satu berlangsung selama 15 minit. Iaitu, disebabkan oleh fakta bahawa tempat digunakan di sana, ia sangat murah - diskaun 70%, pengebilan sesaat Amazon. Anda boleh melakukan banyak. Anda boleh melakukan penyelidikan sebenar.
Dan tiga versi utama Postgres disokong. Ia tidak begitu sukar untuk menyelesaikan beberapa yang lama dan versi ke-12 yang baharu juga.

Kita boleh mentakrifkan objek dalam tiga cara. ini:
- Dump/sql fail.
- Cara utama ialah mengklon direktori PGDATA. Sebagai peraturan, ia diambil dari pelayan sandaran. Jika anda mempunyai sandaran binari biasa, anda boleh membuat klon dari sana. Jika anda mempunyai awan, maka pejabat awan seperti Amazon dan Google akan melakukan ini untuk anda. Ini adalah cara yang paling penting untuk mengklon pengeluaran sebenar. Ini adalah bagaimana kita terungkap.
- Dan kaedah terakhir sesuai untuk penyelidikan apabila anda ingin memahami bagaimana sesuatu berfungsi dalam Postgres. Ini adalah pgbench. Anda boleh menjana menggunakan pgbench. Ia hanya satu pilihan "db-pgbench". Awak beritahu dia skala apa. Dan semuanya akan dijana dalam awan, seperti yang dinyatakan.

Dan muatkan:
- Kita boleh melaksanakan beban dalam satu utas SQL. Ini adalah cara yang paling primitif.
- Dan kita boleh mencontohi beban. Dan kita boleh mencontohinya terlebih dahulu dengan cara berikut. Kami perlu mengumpul semua log. Dan ia menyakitkan. Saya akan tunjukkan sebabnya. Dan menggunakan pgreplay kami bermain, yang dibina ke dalam Nancy.
- Atau pilihan lain. Apa yang dipanggil beban kraf, yang kita lakukan dengan jumlah usaha tertentu. Menganalisis beban semasa kami pada sistem pertempuran, kami mengeluarkan kumpulan permintaan teratas. Dan menggunakan pgbench kita boleh mencontohi beban ini di makmal.

- Sama ada kita perlu melakukan beberapa jenis SQL, iaitu kita menyemak beberapa jenis penghijrahan, mencipta indeks di sana, melaksanakan ANALAZE di sana. Dan kita melihat apa yang berlaku sebelum vakum dan selepas vakum. Secara umum, mana-mana SQL.
- Sama ada kita menukar satu atau lebih parameter dalam konfigurasi. Kami boleh memberitahu kami untuk menyemak, sebagai contoh, 100 nilai di Amazon untuk pangkalan data terabait kami. Dan dalam beberapa jam anda akan mendapat hasilnya. Sebagai peraturan, anda akan mengambil masa beberapa jam untuk menggunakan pangkalan data terabait. Tetapi terdapat tampung dalam pembangunan, kami mempunyai satu siri yang mungkin, iaitu anda boleh secara konsisten menggunakan pgdata yang sama pada pelayan yang sama dan semak. Postgres akan dimulakan semula dan cache akan ditetapkan semula. Dan anda boleh memandu beban.

- Direktori tiba dengan sekumpulan fail yang berbeza, bermula dari petikan pgstat***. Dan perkara yang paling menarik ialah pg_stat_statements, pg_stat_kcacke. Ini ialah dua sambungan yang menganalisis permintaan. Dan pg_stat_bgwriter mengandungi bukan sahaja statistik pgwriter, tetapi juga di pusat pemeriksaan dan cara bahagian belakang itu sendiri menggantikan penimbal yang kotor. Dan semuanya menarik untuk dilihat. Sebagai contoh, apabila kami menyediakan shared_buffers, adalah sangat menarik untuk melihat berapa banyak yang digantikan oleh semua orang.
- Log postgres juga tiba. Dua log – log persediaan dan log main balik beban.
- Ciri yang agak baharu ialah FlameGraphs.
- Selain itu, jika anda menggunakan pilihan pgreplay atau pgbench untuk memainkan beban, maka outputnya akan menjadi asli. Dan anda akan melihat kependaman dan TPS. Ia akan menjadi mungkin untuk memahami bagaimana mereka melihatnya.
- Maklumat sistem.
- Pemeriksaan asas CPU dan IO. Ini lebih kepada contoh EC2 di Amazon, apabila anda ingin melancarkan 100 kejadian yang sama dalam urutan dan menjalankan 100 larian berbeza di sana, maka anda akan mempunyai 10 percubaan. Dan anda perlu memastikan bahawa anda tidak menemui contoh cacat yang sudah ditindas oleh seseorang. Orang lain aktif pada perkakasan ini dan anda mempunyai sedikit sumber yang tinggal. Adalah lebih baik untuk membuang keputusan sedemikian. Dan dengan bantuan sysbench dari Alexey Kopytov, kami melakukan beberapa pemeriksaan pendek yang akan datang dan boleh dibandingkan dengan yang lain, iaitu anda akan memahami bagaimana CPU berkelakuan dan bagaimana IO berkelakuan.

Apakah kesukaran teknikal berdasarkan contoh syarikat yang berbeza?

Katakan kita mahu mengulangi beban sebenar menggunakan log. Ia adalah idea yang bagus jika ia ditulis pada pgreplay Sumber Terbuka. Kami menggunakannya. Tetapi untuk ia berfungsi dengan baik, anda mesti mendayakan pengelogan pertanyaan penuh dengan parameter dan pemasaan.
Terdapat beberapa komplikasi dengan tempoh dan cap masa. Kami akan mengosongkan seluruh dapur ini. Persoalan utama ialah sama ada anda mampu atau tidak?

Masalahnya ialah ia mungkin tidak tersedia. Pertama sekali, anda mesti memahami aliran apa yang akan ditulis pada log. Jika anda mempunyai pg_stat_statements, anda boleh menggunakan pertanyaan ini (pautan akan tersedia dalam slaid) untuk memahami lebih kurang berapa banyak bait akan ditulis sesaat.
Kami melihat panjang permintaan. Kami mengabaikan hakikat bahawa tiada parameter, tetapi kami tahu panjang permintaan dan kami tahu berapa kali sesaat permintaan itu dilaksanakan. Dengan cara ini kita boleh menganggarkan lebih kurang berapa banyak bait sesaat. Kami mungkin membuat kesilapan dua kali lebih banyak, tetapi kami pasti akan memahami pesanan dengan cara ini.
Kita dapat melihat bahawa 802 kali sesaat permintaan ini dilaksanakan. Dan kita melihat bahawa bytes_per saat – 300 kB/s akan ditulis tambah atau tolak. Dan, sebagai peraturan, kita mampu menerima aliran sedemikian.

Tetapi! Hakikatnya terdapat sistem pembalakan yang berbeza. Dan lalai orang biasanya "syslog".
Dan jika anda mempunyai syslog, maka anda mungkin mempunyai gambar seperti ini. Kami akan mengambil pgbench, mendayakan pengelogan pertanyaan dan melihat apa yang berlaku.
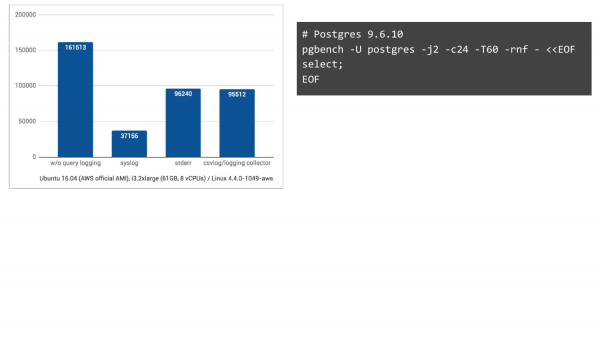
Tanpa pengelogan, ini adalah lajur di sebelah kiri. Kami mendapat 161,000 TPS. Dengan syslog, ini berada dalam Ubuntu Pada 16 April, kami mendapat 37,000 TPS di Amazon. Dan jika kami beralih kepada dua kaedah pembalakan yang lain, keadaan akan jauh lebih baik. Jadi, kami menjangkakan penurunan, tetapi tidak sebanyak itu.
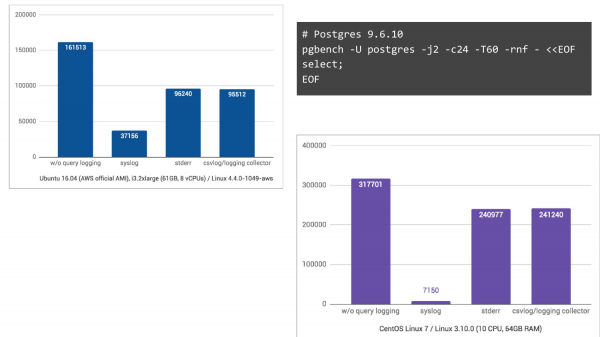
Dan seterusnya CentOS 7, yang juga menggunakan journald, menukar log kepada format binari untuk carian mudah, dsb., merupakan mimpi ngeri sepenuhnya, dengan penurunan TPS sebanyak 44 kali ganda.
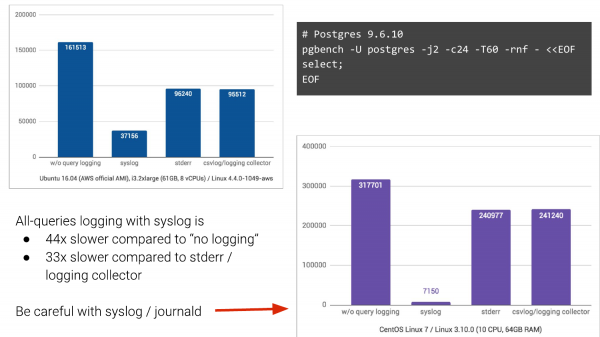
Dan ini adalah apa yang orang hidup dengan. Dan selalunya dalam syarikat, terutamanya yang besar, ini sangat sukar untuk diubah. Jika anda boleh lari daripada syslog, maka sila lari daripadanya.

- Menilai IOPS dan menulis aliran.
- Semak sistem pengelogan anda.
- Jika beban yang diunjurkan adalah terlalu besar, pertimbangkan persampelan.

Kami mempunyai pg_stat_statements. Seperti yang saya katakan, ia mesti ada. Dan kita boleh mengambil dan menerangkan setiap kumpulan permintaan dengan cara yang istimewa dalam fail. Dan kemudian kita boleh menggunakan ciri yang sangat mudah dalam pgbench - ini adalah keupayaan untuk memasukkan beberapa fail menggunakan pilihan "-f".
Ia memahami banyak "-f". Dan anda boleh memberitahu dengan bantuan "@" pada penghujung bahagian yang sepatutnya ada pada setiap fail. Iaitu, kita boleh mengatakan bahawa melakukan ini dalam 10% kes, dan ini dalam 20%. Dan ini akan membawa kita lebih dekat dengan apa yang kita lihat dalam pengeluaran.

Bagaimanakah kita akan memahami apa yang kita ada dalam pengeluaran? Apa bahagian dan bagaimana? Ini sedikit diketepikan. Kami ada satu lagi produk . Juga asas dalam Sumber Terbuka. Dan kami kini sedang giat membangunkannya.
Dia dilahirkan atas sebab yang sedikit berbeza. Atas sebab pemantauan tidak mencukupi. Maksudnya, awak datang, tengok pangkal, tengok masalah yang ada. Dan, sebagai peraturan, anda melakukan pemeriksaan_kesihatan. Jika anda seorang DBA yang berpengalaman, maka anda melakukan pemeriksaan_kesihatan. Kami melihat penggunaan indeks, dll. Jika anda mempunyai OKmeter, maka bagus. Ini adalah pemantauan yang hebat untuk Postgres. OKmeter.io – sila pasangkannya, semuanya dilakukan dengan baik di sana. dah berbayar.
Jika anda tidak mempunyai satu, maka anda biasanya tidak mempunyai banyak. Dalam pemantauan, biasanya terdapat CPU, IO, dan kemudian dengan tempahan, dan itu sahaja. Dan kami memerlukan lebih banyak lagi. Kita perlu melihat bagaimana autovacuum berfungsi, bagaimana pusat pemeriksaan berfungsi, dalam io kita perlu memisahkan pusat pemeriksaan dari bgwriter dan dari bahagian belakang, dsb.
Masalahnya ialah apabila anda membantu syarikat besar, mereka tidak dapat melaksanakan sesuatu dengan cepat. Mereka tidak boleh membeli OKmeter dengan cepat. Mungkin mereka akan membelinya dalam masa enam bulan. Mereka tidak boleh menghantar beberapa pakej dengan cepat.
Dan kami datang dengan idea bahawa kami memerlukan alat khas yang tidak memerlukan apa-apa untuk dipasang, iaitu anda tidak perlu memasang apa-apa sama sekali pada pengeluaran. Pasang pada komputer riba anda, atau pada pelayan pemerhati dari mana anda akan menjalankannya. Dan ia akan menganalisis banyak perkara: sistem pengendalian, sistem fail dan Postgres itu sendiri, membuat beberapa pertanyaan ringan yang boleh dijalankan terus ke pengeluaran dan tiada apa yang akan gagal.
Kami memanggilnya Postgres-checkup. Dari segi perubatan, ini adalah pemeriksaan kesihatan biasa. Jika ia bertemakan automotif, maka ia seperti penyelenggaraan. Anda melakukan penyelenggaraan pada kereta anda setiap enam bulan atau setahun, bergantung pada jenama. Adakah anda melakukan penyelenggaraan untuk pangkalan anda? Maksudnya, adakah anda kerap membuat kajian mendalam? Ia mesti dilakukan. Jika anda membuat sandaran, kemudian buat pemeriksaan, ini tidak kurang pentingnya.
Dan kami mempunyai alat sedemikian. Ia mula aktif muncul hanya kira-kira tiga bulan lalu. Dia masih muda, tetapi ada banyak di sana.

Mengumpul kumpulan pertanyaan yang paling "berpengaruh" - laporkan K003 dalam Postgres-checkup
Dan terdapat sekumpulan laporan K. Tiga laporan setakat ini. Dan terdapat laporan sedemikian K003. Terdapat bahagian atas daripada pg_stat_statements, diisih mengikut jumlah_masa.
Apabila kami mengisih kumpulan permintaan mengikut total_time, di bahagian atas kami melihat kumpulan yang paling banyak memuatkan sistem kami, iaitu menggunakan lebih banyak sumber. Mengapa saya menamakan kumpulan pertanyaan? Kerana kami membuang parameter. Ini bukan lagi permintaan, tetapi kumpulan permintaan, iaitu ia diabstraksikan.
Dan jika kami mengoptimumkan dari atas ke bawah, kami akan meringankan sumber kami dan menangguhkan masa apabila kami perlu meningkatkan. Ini adalah cara yang sangat baik untuk menjimatkan wang.
Mungkin ini bukan cara yang sangat baik untuk menjaga pengguna, kerana kita mungkin tidak melihat kes yang jarang berlaku, tetapi sangat menjengkelkan di mana seseorang menunggu 15 saat. Secara keseluruhan, mereka sangat jarang sehingga kami tidak melihatnya, tetapi kami berurusan dengan sumber.

Apa yang berlaku dalam jadual ini? Kami mengambil dua gambar. Postgres_checkup akan memberi anda delta untuk setiap metrik: jumlah masa, panggilan, baris, shared_blks_read, dll. Itu sahaja, delta telah dikira. Masalah besar dengan pg_stat_statements ialah ia tidak ingat bila ia ditetapkan semula. Jika pg_stat_database ingat, maka pg_stat_statements tidak ingat. Anda melihat bahawa terdapat sejumlah 1, tetapi kami tidak tahu dari mana kami mengira.
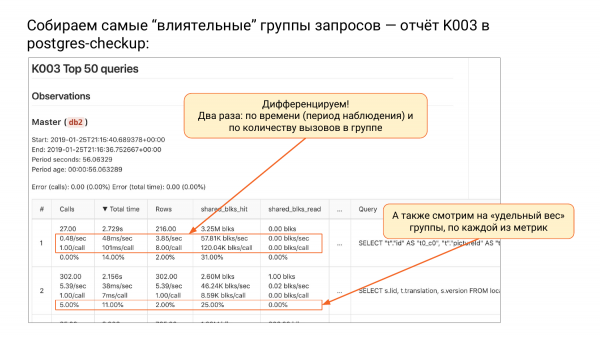
Dan di sini kita tahu, di sini kita mempunyai dua gambar. Kita tahu bahawa delta dalam kes ini ialah 56 saat. Jurang yang sangat singkat. Diisih mengikut jumlah_masa. Dan kemudian kita boleh membezakan, iaitu kita membahagikan semua metrik mengikut tempoh. Jika kita membahagikan setiap metrik mengikut tempoh, kita akan mempunyai bilangan panggilan sesaat.
Seterusnya, jumlah_masa sesaat ialah metrik kegemaran saya. Ia diukur dalam saat, sesaat, iaitu berapa saat yang diambil oleh sistem kami untuk melaksanakan kumpulan permintaan ini sesaat. Jika anda melihat lebih daripada satu saat sesaat di sana, ini bermakna anda terpaksa memberikan lebih daripada satu teras. Ini adalah metrik yang sangat baik. Anda boleh faham bahawa rakan ini, sebagai contoh, memerlukan sekurang-kurangnya tiga teras.
Ini adalah pengetahuan kami, saya tidak pernah melihat perkara seperti itu di mana-mana. Sila ambil perhatian - ini adalah perkara yang sangat mudah - saat sesaat. Kadangkala, apabila CPU anda 100%, kemudian setengah jam sesaat, iaitu, anda menghabiskan setengah jam melakukan permintaan ini sahaja.
Seterusnya kita melihat baris sesaat. Kami tahu berapa banyak baris sesaat yang dikembalikan.
Dan kemudian ada juga perkara yang menarik. Berapa banyak shared_buffers yang kita baca sesaat daripada shared_buffers itu sendiri. Hit sudah ada, dan kami mengambil baris dari cache sistem pengendalian atau dari cakera. Pilihan pertama adalah pantas, dan yang kedua mungkin pantas atau tidak, bergantung pada keadaan.
Dan cara kedua pembezaan ialah membahagikan bilangan permintaan dalam kumpulan ini. Dalam lajur kedua anda akan sentiasa mempunyai satu pertanyaan dibahagikan setiap pertanyaan. Dan kemudian ia menarik - berapa milisaat dalam permintaan ini. Kami tahu bagaimana pertanyaan ini berkelakuan secara purata. 101 milisaat diperlukan untuk setiap permintaan. Ini adalah metrik tradisional yang perlu kita fahami.
Berapakah bilangan baris yang dipulangkan oleh setiap pertanyaan secara purata? Kami melihat 8 kumpulan ini kembali. Secara purata, berapa banyak yang diambil dari cache dan dibaca. Kami melihat bahawa segala-galanya dicache dengan baik. Hit padu untuk kumpulan pertama.
Dan subrentetan keempat dalam setiap baris ialah berapa peratus daripada jumlah itu. Kami ada panggilan. Katakan 1. Dan kita boleh faham apa sumbangan kumpulan ini. Kami melihat bahawa dalam kes ini kumpulan pertama menyumbang kurang daripada 000%. Iaitu, ia sangat perlahan sehingga kita tidak melihatnya dalam gambaran keseluruhan. Dan kumpulan kedua ialah 000% untuk panggilan. Iaitu, 0,01% daripada semua panggilan adalah kumpulan kedua.
Jumlah_masa juga menarik. Kami menghabiskan 14% daripada jumlah masa kerja kami untuk kumpulan permintaan pertama. Dan untuk yang kedua - 11%, dsb.
Saya tidak akan menerangkan secara terperinci, tetapi terdapat kehalusan di sana. Kami memaparkan ralat di bahagian atas, kerana apabila kami membuat perbandingan, syot kilat mungkin terapung, iaitu, beberapa permintaan mungkin gagal dan tidak boleh hadir lagi dalam permintaan kedua, manakala beberapa permintaan baharu mungkin muncul. Dan di sana kita mengira ralat. Jika anda melihat 0, maka itu bagus. Tiada ralat. Jika kadar ralat adalah sehingga 20%, tidak mengapa.

Kemudian kita kembali kepada topik kita. Kita perlu menyusun beban kerja. Kami mengambilnya dari atas ke bawah dan pergi sehingga kami mencapai 80% atau 90%. Biasanya ini adalah 10-20 kumpulan. Dan kami membuat fail untuk pgbench. Kami menggunakan secara rawak di sana. Kadang-kadang ini, malangnya, tidak berjaya. Dan dalam Postgres 12 akan ada lebih banyak peluang untuk menggunakan pendekatan ini.
Dan kemudian kita mendapat 80-90% dalam jumlah_masa dengan cara ini. Apakah yang perlu saya letakkan seterusnya selepas "@"? Kami melihat panggilan, melihat berapa banyak faedah yang ada dan memahami bahawa kami berhutang begitu banyak faedah di sini. Daripada peratusan ini kita boleh memahami cara mengimbangi setiap fail. Selepas itu kita menggunakan pgbench dan pergi bekerja.
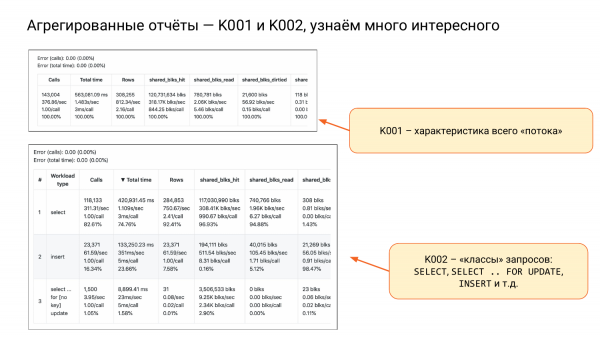
Kami juga mempunyai K001 dan K002.
K001 ialah satu rentetan besar dengan empat rentetan kecil. Ini adalah ciri keseluruhan beban kita. Lihat lajur kedua dan subbaris kedua. Kami melihat bahawa kira-kira satu setengah saat sesaat, iaitu jika terdapat dua teras, maka ia akan menjadi baik. Akan ada kira-kira 75% kapasiti. Dan ia akan berfungsi seperti ini. Jika kita mempunyai 10 teras, maka secara amnya kita akan tenang. Dengan cara ini kita boleh menilai sumber.
K002 ialah apa yang saya panggil kelas pertanyaan, iaitu SELECT, INSERT, UPDATE, DELETE. Dan secara berasingan PILIH UNTUK KEMASKINI, kerana ia adalah kunci.
Dan di sini kita boleh membuat kesimpulan bahawa SELECT ialah pembaca biasa - 82% daripada semua panggilan, tetapi pada masa yang sama - 74% dalam total_time. Iaitu, mereka dipanggil banyak, tetapi menggunakan lebih sedikit sumber.
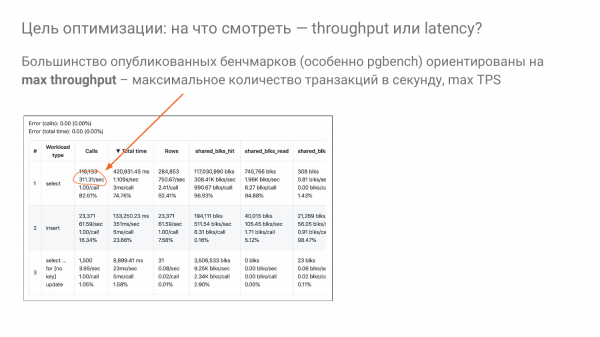
Dan kita kembali kepada soalan: "Bagaimanakah kita boleh memilih shared_buffers yang betul?" Saya perhatikan bahawa kebanyakan penanda aras adalah berdasarkan idea - mari lihat apakah daya tampungnya, iaitu apa daya tampungnya. Ia biasanya diukur dalam TPS atau QPS.
Dan kami cuba memerah sebanyak mungkin transaksi sesaat dari kereta menggunakan parameter penalaan. Berikut adalah tepat 311 sesaat untuk pilihan.

Tetapi tiada siapa yang memandu ke tempat kerja dan pulang ke rumah dengan kelajuan penuh. Ini mengarut. Begitu juga dengan pangkalan data. Kami tidak perlu memandu pada kelajuan penuh, dan tiada siapa yang memandu. Tiada siapa yang tinggal dalam pengeluaran, yang mempunyai 100% CPU. Walaupun, mungkin seseorang hidup, tetapi ini tidak baik.
Ideanya ialah kami biasanya memandu pada 20 peratus kapasiti, sebaik-baiknya tidak melebihi 50%. Dan kami cuba mengoptimumkan masa tindak balas untuk pengguna kami terutamanya. Iaitu, kita mesti memusing tombol kita supaya terdapat kependaman minimum pada kelajuan 20%, secara bersyarat. Ini adalah idea yang juga kami cuba gunakan dalam eksperimen kami.
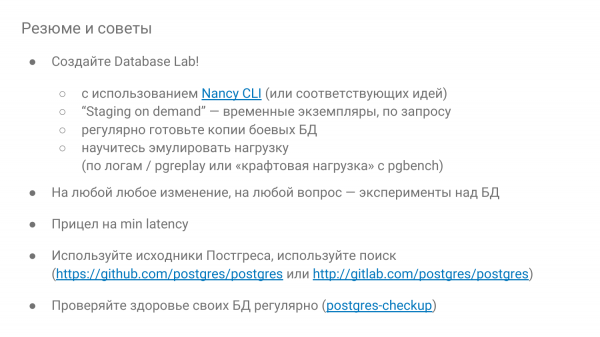
Dan akhirnya, cadangan:
- Pastikan anda melakukan Makmal Pangkalan Data.
- Jika boleh, lakukan atas permintaan supaya ia terbentang seketika - main dan buang. Jika anda mempunyai awan, maka ini tidak perlu dikatakan, iaitu mempunyai banyak berdiri.
- Ingin tahu. Dan jika ada sesuatu yang salah, kemudian semak dengan eksperimen bagaimana ia berkelakuan. Nancy boleh digunakan untuk melatih diri anda untuk menyemak cara pangkalan itu berfungsi.
- Dan sasarkan masa tindak balas minimum.
- Dan jangan takut dengan sumber Postgres. Apabila anda bekerja dengan sumber, anda mesti tahu bahasa Inggeris. Terdapat banyak komen di sana, semuanya dijelaskan di sana.
- Dan semak kesihatan pangkalan data dengan kerap, sekurang-kurangnya sekali setiap tiga bulan, secara manual, atau Postgres-checkup.

soalan
Terima kasih banyak-banyak! Satu perkara yang sangat menarik.
Dua keping.
Ya, dua keping. Cuma saya kurang faham. Apabila saya dan Nancy bekerja, bolehkah kita mengubahsuai hanya satu parameter atau keseluruhan kumpulan?
Kami mempunyai parameter konfigurasi delta. Anda boleh membelok ke sana seberapa banyak yang anda mahu sekaligus. Tetapi anda perlu memahami bahawa apabila anda mengubah banyak perkara, anda boleh membuat kesimpulan yang salah.
ya. Kenapa saya tanya? Kerana sukar untuk menjalankan eksperimen apabila anda hanya mempunyai satu parameter. Anda ketatkannya, lihat cara ia berfungsi. Saya keluarkan dia. Kemudian anda mulakan yang seterusnya.
Anda boleh mengetatkannya pada masa yang sama, tetapi ia bergantung pada keadaan, tentu saja. Tetapi lebih baik untuk menguji satu idea. Kami ada idea semalam. Kami mempunyai situasi yang sangat rapat. Terdapat dua konfigurasi. Dan kami tidak dapat memahami mengapa terdapat perbezaan yang besar. Dan timbul idea bahawa anda perlu menggunakan dikotomi untuk memahami secara konsisten dan mencari perbezaannya. Anda boleh segera membuat separuh daripada parameter sama, kemudian suku, dsb. Semuanya fleksibel.
Dan ada satu lagi soalan. Projek ini masih muda dan berkembang. Dokumentasi sudah siap, adakah penerangan terperinci?
Saya secara khusus membuat pautan di sana kepada penerangan parameter. Ia ada di sana. Tetapi banyak perkara yang belum ada. Saya mencari orang yang berfikiran sama. Dan saya dapati mereka apabila saya membuat persembahan. Ini sangat keren. Seseorang sudah bekerja dengan saya, seseorang membantu dan melakukan sesuatu di sana. Dan jika anda berminat dengan topik ini, berikan maklum balas tentang perkara yang tiada.
Sebaik sahaja kita membina makmal, mungkin akan ada maklum balas. Jom tengok. Terima kasih!
helo! Terima kasih atas laporan itu! Saya melihat bahawa terdapat sokongan Amazon. Adakah terdapat rancangan untuk menyokong GSP?
Soalan yang baik. Kami mula melakukannya. Dan kami membekukannya buat masa ini kerana kami ingin menjimatkan wang. Iaitu, terdapat sokongan menggunakan run on localhost. Anda boleh membuat contoh sendiri dan bekerja secara tempatan. By the way, itulah yang kami lakukan. Saya melakukan ini di Getlab, di sana di GSP. Tetapi kami tidak nampak gunanya melakukan orkestrasi sedemikian, kerana Google tidak mempunyai tempat yang murah. Terdapat ??? contoh, tetapi mereka mempunyai had. Pertama, mereka sentiasa hanya mempunyai diskaun 70% dan anda tidak boleh bermain dengan harga di sana. Secara langsung, kami menaikkan harga sebanyak 5-10% untuk mengurangkan kemungkinan anda akan ditendang. Iaitu, anda menyimpan bintik-bintik, tetapi ia boleh diambil daripada anda pada bila-bila masa. Jika anda membida lebih tinggi sedikit daripada yang lain, anda akan dibunuh kemudian. Google mempunyai spesifikasi yang berbeza sama sekali. Dan terdapat satu lagi batasan yang sangat buruk - mereka hanya hidup selama 24 jam. Dan kadang-kadang kami ingin menjalankan eksperimen selama 5 hari. Tetapi anda boleh melakukan ini di tempat; bintik kadang-kadang bertahan selama berbulan-bulan.
hello! Terima kasih atas laporan itu! Anda menyebut tentang pemeriksaan. Bagaimanakah anda mengira ralat stat_statements?
Soalan yang sangat bagus. Saya boleh tunjukkan dan beritahu anda dengan terperinci. Ringkasnya, kita melihat bagaimana set kumpulan permintaan telah terapung: berapa banyak yang telah jatuh dan berapa banyak kumpulan baru telah muncul. Dan kemudian kita melihat dua metrik: jumlah_masa dan panggilan, jadi terdapat dua ralat. Dan kita melihat kepada sumbangan kumpulan terapung. Terdapat dua subkumpulan: mereka yang pergi dan mereka yang tiba. Mari kita lihat apakah sumbangan mereka kepada gambaran keseluruhan.
Adakah anda tidak takut ia akan bertukar ke sana dua atau tiga kali sepanjang masa antara syot kilat?
Iaitu, adakah mereka mendaftar semula atau apa?
Sebagai contoh, permintaan ini telah didahulukan sekali, kemudian ia datang dan didahulukan lagi, kemudian ia datang lagi dan didahulukan lagi. Dan anda mengira sesuatu di sini, dan di manakah semuanya?
Soalan yang bagus, kita perlu lihat.
Saya melakukan perkara yang serupa. Ia lebih mudah, sudah tentu, saya melakukannya sendiri. Tetapi saya terpaksa menetapkan semula, menetapkan semula stat_statements dan mengetahui pada masa syot kilat bahawa terdapat kurang daripada pecahan tertentu, yang masih tidak mencapai siling jumlah stat_statements boleh terkumpul di sana. Dan pemahaman saya ialah, kemungkinan besar, tiada apa yang dialihkan.
Ya Ya.
Tetapi saya tidak faham bagaimana lagi untuk melakukannya dengan pasti.
Malangnya, saya tidak ingat sama ada kami menggunakan teks pertanyaan di sana atau id pertanyaan dengan pg_stat_statements dan fokus padanya. Jika kita memberi tumpuan kepada queryid, maka secara teori kita membandingkan perkara yang setanding.
Tidak, dia boleh dipaksa keluar beberapa kali antara syot kilat dan datang semula.
Dengan id yang sama?
Ya.
Kami akan mengkaji ini. Soalan yang baik. Kita perlu mengkajinya. Tetapi buat masa ini, apa yang kita lihat sama ada ditulis 0...
Ini, sudah tentu, kes yang jarang berlaku, tetapi saya terkejut apabila saya mengetahui bahawa stat_statemetns boleh menggantikan di sana.
Terdapat banyak perkara dalam Pg_stat_statements. Kami mendapati fakta bahawa jika anda mempunyai track_utility = on, maka set anda juga dijejaki.
Ya sudah tentu.
Dan jika anda mempunyai java hibernate, yang rawak, maka jadual hash mula terletak di sana. Dan sebaik sahaja anda mematikan aplikasi yang sangat dimuatkan, anda akan mendapat 50-100 kumpulan. Dan semuanya lebih kurang stabil di sana. Satu cara untuk memerangi perkara ini adalah dengan meningkatkan pg_stat_statements.max.
Ya, tetapi anda perlu tahu berapa banyak. Dan entah bagaimana kita perlu memerhatikannya. Itulah apa yang saya lakukan. Iaitu, saya mempunyai pg_stat_statements.max. Dan saya melihat bahawa pada masa syot kilat saya belum mencapai 70%. Okay, jadi kami tidak kehilangan apa-apa. Mari kita set semula. Dan kita jimat lagi. Jika syot kilat seterusnya kurang daripada 70, kemungkinan besar anda tidak kehilangan apa-apa lagi.
ya. Lalai kini ialah 5. Dan ini sudah cukup untuk ramai orang.
Biasanya ya.
Video:

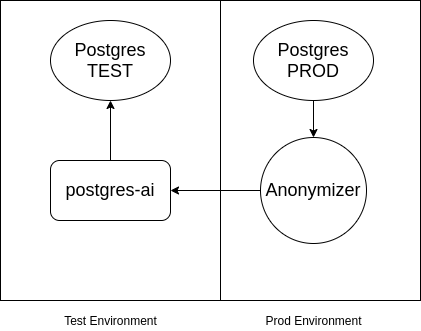
PS Bagi pihak saya sendiri, saya akan menambah bahawa jika Postgres mengandungi data sulit dan ia tidak boleh disertakan dalam persekitaran ujian, maka anda boleh menggunakan . Skimnya lebih kurang seperti berikut:
Sumber: www.habr.com
