

Rangkaian saraf konvolusi (CNN), yang diilhamkan oleh proses biologi dalam korteks visual manusia, sangat sesuai untuk tugas seperti pengecaman objek dan muka, tetapi meningkatkan ketepatannya memerlukan penalaan yang membosankan dan halus. Itulah sebabnya saintis di Google AI Research sedang meneroka model baharu yang menskalakan CNN dengan cara yang "lebih berstruktur". Mereka menerbitkan hasil kerja mereka di "EfficientNet: Memikirkan Semula Penskalaan Model untuk Rangkaian Neural Konvolusi," disiarkan di portal saintifik Arxiv.org, serta dalam pada blog anda. Pengarang bersama mendakwa bahawa keluarga sistem kecerdasan buatan, yang dipanggil EfficientNets, melebihi ketepatan CNN standard dan meningkatkan kecekapan rangkaian saraf sehingga 10 kali ganda.
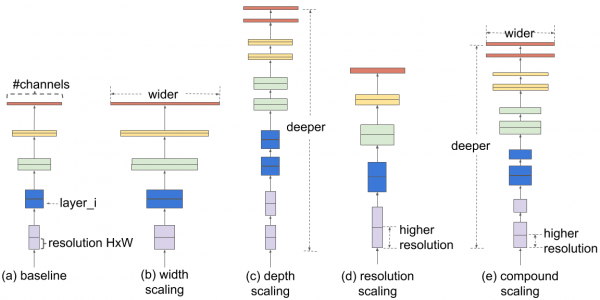
"Amalan biasa model penskalaan adalah dengan sewenang-wenangnya meningkatkan kedalaman atau lebar CNN, dan menggunakan resolusi imej input yang lebih tinggi untuk latihan dan penilaian," tulis jurutera perisian kakitangan Mingxing Tan dan saintis utama Google AI Quoc V .Le). "Tidak seperti pendekatan tradisional yang secara sewenang-wenangnya menskalakan parameter rangkaian seperti lebar, kedalaman dan resolusi input, kaedah kami menskalakan setiap dimensi secara seragam dengan set faktor penskalaan tetap."
Untuk meningkatkan lagi prestasi, para penyelidik menyokong penggunaan rangkaian tulang belakang baharu, lilitan bottleneck terbalik mudah alih (MBConv), yang berfungsi sebagai asas bagi keluarga model EfficientNets.
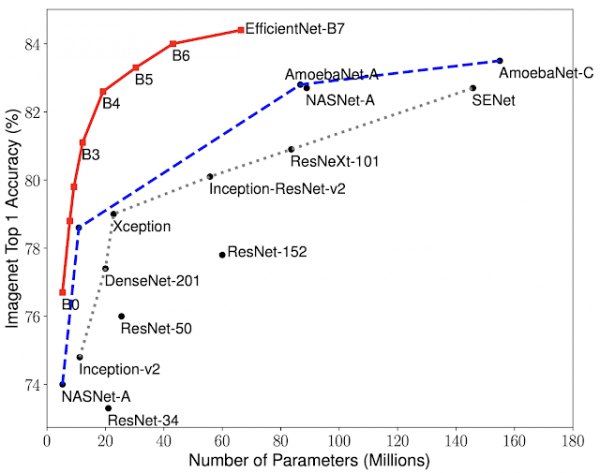
Dalam ujian, EfficientNets telah menunjukkan ketepatan yang lebih tinggi dan kecekapan yang lebih baik daripada CNN sedia ada, mengurangkan saiz parameter dan keperluan sumber pengiraan mengikut susunan magnitud. Salah satu model, EfficientNet-B7, menunjukkan saiz 8,4 kali lebih kecil dan prestasi 6,1 kali lebih baik daripada CNN Gpipe yang terkenal, dan juga mencapai ketepatan 84,4% dan 97,1% (Top-1 dan Top-5). 50 keputusan) dalam ujian pada set ImageNet. Berbanding dengan CNN ResNet-4 yang popular, model EfficientNet lain, EfficientNet-B82,6, menggunakan sumber yang serupa, mencapai ketepatan 76,3% berbanding 50% untuk ResNet-XNUMX.
Model EfficientNets menunjukkan prestasi yang baik pada set data lain, mencapai ketepatan tinggi pada lima daripada lapan tanda aras, termasuk set data CIFAR-100 (91,7% ketepatan) dan (98,8%).
"Dengan menyediakan peningkatan ketara dalam kecekapan model saraf, kami menjangkakan bahawa EfficientNets berpotensi untuk berfungsi sebagai rangka kerja baharu untuk tugas penglihatan komputer masa hadapan," tulis Tan dan Li.
Kod sumber dan skrip latihan untuk Unit Pemprosesan Tensor (TPU) awan Google tersedia secara percuma .
Sumber: 3dnews.ru
