

Elastic Stack သည် ဆက်နွှယ်မှုမရှိသော Elasticsearch ဒေတာဘေ့စ်၊ Kibana ဝဘ်အင်တာဖေ့စ်နှင့် ဒေတာစုဆောင်းသူများနှင့် ပရိုဆက်ဆာများ (အကျော်ကြားဆုံး Logstash၊ အမျိုးမျိုးသော Beats၊ APM နှင့် အခြားအရာများ)အပေါ် အခြေခံထားကြောင်း သတိရကြပါစို့။ စာရင်းသွင်းထားသော ထုတ်ကုန်အစုအစည်းတစ်ခုလုံးတွင် ကောင်းမွန်သော ထပ်ပေါင်းထည့်မှုတစ်ခုမှာ စက်သင်ယူမှု အယ်ဂိုရီသမ်များကို အသုံးပြု၍ ဒေတာခွဲခြမ်းစိတ်ဖြာခြင်း ဖြစ်သည်။ ဆောင်းပါးတွင် ဤ algorithms များသည် မည်သည်ကို နားလည်ပါသည်။ ကျေးဇူးပြု၍ ကြောင်အောက်၊
Machine learning သည် shareware Elastic Stack ၏ အခကြေးငွေပေးရသည့် အင်္ဂါရပ်ဖြစ်ပြီး X-Pack တွင် ပါဝင်ပါသည်။ ၎င်းကို စတင်အသုံးပြုရန် တပ်ဆင်ပြီးနောက် ရက် 30 အစမ်းသုံးခြင်းကို စတင်ပါ။ အစမ်းသုံးကာလ ကုန်ဆုံးပြီးနောက်၊ ၎င်းကို သက်တမ်းတိုးရန် သို့မဟုတ် စာရင်းသွင်းမှုတစ်ခု ဝယ်ယူရန် အကူအညီကို သင်တောင်းဆိုနိုင်သည်။ စာရင်းသွင်းမှုတစ်ခု၏ ကုန်ကျစရိတ်ကို ဒေတာပမာဏအပေါ်အခြေခံ၍ တွက်ချက်ထားခြင်းမဟုတ်ဘဲ အသုံးပြုထားသော နံပါတ်များပေါ်တွင် တွက်ချက်ပါသည်။ မဟုတ်ပါ၊ ဒေတာပမာဏသည် လိုအပ်သော node အရေအတွက်အပေါ် သက်ရောက်မှုရှိသော်လည်း၊ ကုမ္ပဏီ၏ဘတ်ဂျက်နှင့်စပ်လျဉ်း၍ လိုင်စင်ရယူရန် ဤချဉ်းကပ်မှုသည် လူသားဆန်နေဆဲဖြစ်သည်။ မြင့်မားသောကုန်ထုတ်စွမ်းအားအတွက်မလိုအပ်ပါက၊ သင်သည်ငွေစုနိုင်သည်။
Elastic Stack တွင် ML ကို C++ ဖြင့်ရေးသားထားပြီး Elasticsearch ကိုယ်တိုင်လုပ်ဆောင်သည့် JVM အပြင်ဘက်တွင် လုပ်ဆောင်သည်။ ဆိုလိုသည်မှာ၊ လုပ်ငန်းစဉ် (နည်းလမ်းအားဖြင့်၊ ၎င်းကို autodetect ဟုခေါ်သည်) သည် JVM မျိုမချသည့်အရာအားလုံးကို စားသုံးသည်။ သရုပ်ပြရပ်တည်ချက်တွင် ၎င်းသည် အလွန်အရေးမပါသော်လည်း ထုတ်လုပ်မှုပတ်ဝန်းကျင်တွင် ML လုပ်ဆောင်စရာများအတွက် သီးခြား node များကို ခွဲဝေချထားရန် အရေးကြီးပါသည်။
စက်သင်ယူခြင်းဆိုင်ရာ အယ်လဂိုရီသမ်များကို အမျိုးအစားနှစ်မျိုး ခွဲခြားထားသည်။ и . Elastic Stack တွင်၊ algorithm သည် "ကြီးကြပ်မထားသော" အမျိုးအစားတွင်ရှိသည်။ အားဖြင့် machine learning algorithms ၏ သင်္ချာယန္တရားကို သင်မြင်နိုင်သည်။
ခွဲခြမ်းစိတ်ဖြာမှုကို လုပ်ဆောင်ရန်၊ စက်သင်ယူမှု အယ်လဂိုရီသမ်သည် Elasticsearch အညွှန်းကိန်းများတွင် သိမ်းဆည်းထားသည့် ဒေတာကို အသုံးပြုသည်။ Kibana interface နှင့် API မှတဆင့် ခွဲခြမ်းစိတ်ဖြာခြင်းအတွက် လုပ်ဆောင်စရာများကို ဖန်တီးနိုင်သည်။ ဒါကို Kibana ကတဆင့် သင်လုပ်ရင်၊ တချို့အရာတွေကို သင်သိဖို့ မလိုအပ်ပါဘူး။ ဥပမာအားဖြင့်၊ ၎င်း၏လုပ်ဆောင်မှုအတွင်း algorithm အသုံးပြုသည့် အပိုအညွှန်းများ။
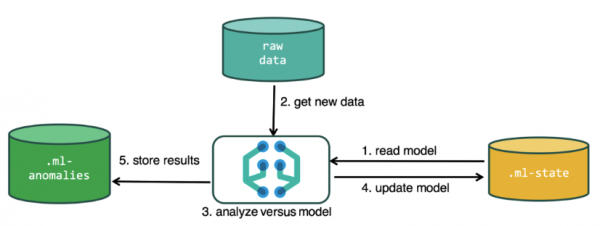
ခွဲခြမ်းစိတ်ဖြာမှု လုပ်ငန်းစဉ်တွင် အသုံးပြုသည့် နောက်ထပ်ညွှန်းကိန်းများ.ml-state — ကိန်းဂဏန်း အချက်အလက် မော်ဒယ်များ (ခွဲခြမ်းစိတ်ဖြာမှု ဆက်တင်များ)
.ml-anomalies-* — ML algorithms ၏ရလဒ်များ
.ml-notifications — ခွဲခြမ်းစိတ်ဖြာမှုရလဒ်များအပေါ် အခြေခံ၍ အကြောင်းကြားချက်များအတွက် ဆက်တင်များ။
Elasticsearch ဒေတာဘေ့စ်ရှိ ဒေတာဖွဲ့စည်းပုံသည် ၎င်းတို့တွင် သိမ်းဆည်းထားသော အညွှန်းများနှင့် စာရွက်စာတမ်းများ ပါဝင်သည်။ ဆက်စပ်ဒေတာဘေ့စ်တစ်ခုနှင့် နှိုင်းယှဉ်သောအခါ၊ အညွှန်းတစ်ခုကို ဒေတာဘေ့စ်အစီအစဉ်တစ်ခုနှင့် ဇယားတစ်ခုရှိ မှတ်တမ်းတစ်ခုသို့ စာရွက်စာတမ်းတစ်ခုနှင့် နှိုင်းယှဉ်နိုင်သည်။ ဤနှိုင်းယှဉ်မှုသည် အခြေအနေအရဖြစ်ပြီး Elasticsearch အကြောင်းကိုသာ ကြားသိဖူးသူများအတွက် နောက်ထပ်အကြောင်းအရာကို နားလည်လွယ်စေရန် ထောက်ပံ့ပေးထားပါသည်။
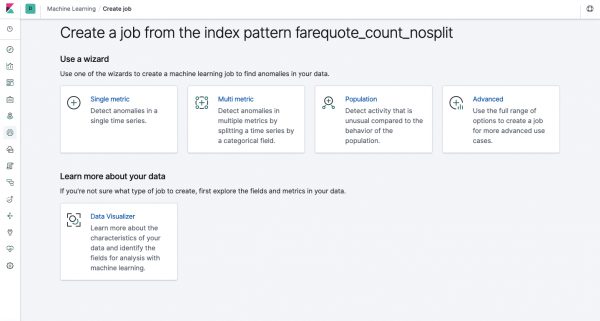
တူညီသောလုပ်ဆောင်နိုင်စွမ်းကို ဝဘ်အင်တာဖေ့စ်မှတဆင့် API မှတဆင့်ရရှိနိုင်ပါသည်၊ ထို့ကြောင့်သဘောတရားများကိုရှင်းလင်းရန်နှင့်နားလည်ရန်အတွက် Kibana မှတဆင့်၎င်းကိုမည်သို့ပြင်ဆင်ရမည်ကိုပြသပါမည်။ ဘယ်ဘက်ရှိ မီနူးတွင် အလုပ်အသစ်တစ်ခုဖန်တီးနိုင်သည့် Machine Learning ကဏ္ဍတစ်ခုရှိသည်။ Kibana interface တွင်၎င်းသည်အောက်ပါပုံနှင့်တူသည်။ ယခု ကျွန်ုပ်တို့သည် အလုပ်အမျိုးအစားတစ်ခုစီကို ခွဲခြမ်းစိတ်ဖြာပြီး ဤနေရာတွင် တည်ဆောက်နိုင်သည့် ခွဲခြမ်းစိတ်ဖြာမှုအမျိုးအစားများကို ပြသပါမည်။
Single Metric - မက်ထရစ်တစ်ခု၏ခွဲခြမ်းစိတ်ဖြာမှု၊ Multi Metric - မက်ထရစ်နှစ်ခု သို့မဟုတ် ထို့ထက်ပိုသော ခွဲခြမ်းစိတ်ဖြာမှု။ ဖြစ်ရပ်နှစ်ခုစလုံးတွင်၊ မက်ထရစ်တစ်ခုစီကို သီးခြားပတ်ဝန်းကျင်တွင် ခွဲခြမ်းစိတ်ဖြာထားသည်၊ ဆိုလိုသည်မှာ၊ Multi Metric ၏ဖြစ်ရပ်တွင်ထင်ရသည့်အတိုင်း algorithm သည် parallel ခွဲခြမ်းစိတ်ဖြာသည့်မက်ထရစ်များ၏အပြုအမူကိုထည့်သွင်းစဉ်းစားခြင်းမရှိပါ။ အမျိုးမျိုးသော မက်ထရစ်များ၏ ဆက်စပ်မှုကို ထည့်သွင်းတွက်ချက်ရန် လူဦးရေခွဲခြမ်းစိတ်ဖြာမှုကို သင်အသုံးပြုနိုင်သည်။ ထို့အပြင် Advanced သည် အချို့သောအလုပ်များအတွက် ထပ်လောင်းရွေးချယ်မှုများဖြင့် algorithms ကို ကောင်းစွာချိန်ညှိနေသည်။
Single Metric
မက်ထရစ်တစ်ခုတည်းတွင် အပြောင်းအလဲများကို ပိုင်းခြားစိတ်ဖြာခြင်းသည် ဤနေရာတွင် လုပ်ဆောင်နိုင်သည့် အရိုးရှင်းဆုံးအရာဖြစ်သည်။ Create Job ကို နှိပ်ပြီးနောက်၊ algorithm သည် ကွဲလွဲချက်များကို ရှာဖွေမည်ဖြစ်သည်။
လယ်ပြင်၌ စုစည်းမှု ကွဲလွဲချက်များကို ရှာဖွေရန် ချဉ်းကပ်နည်းကို သင်ရွေးချယ်နိုင်သည်။ ဥပမာ - ဘယ်အချိန်လဲ။ min ပုံမှန်တန်ဖိုးများအောက်ရှိတန်ဖိုးများကို anomalous ဟု သတ်မှတ်မည်ဖြစ်ပါသည်။ စားသည် Max၊ High Mean၊ Low၊ Mean၊ Distinct နှင့်အခြားသူများ။ လုပ်ဆောင်ချက်အားလုံး၏ ဖော်ပြချက်ကို တွေ့နိုင်သည်။ .
လယ်ပြင်၌ လယ်ယာ ကျွန်ုပ်တို့သည် ခွဲခြမ်းစိတ်ဖြာမှုကို လုပ်ဆောင်မည့် စာရွက်စာတမ်းရှိ ဂဏန်းအကွက်ကို ညွှန်ပြသည်။
လယ်ပြင်၌ - ခွဲခြမ်းစိတ်ဖြာမှုကို ဆောင်ရွက်မည့် အချိန်ဇယားပေါ်ရှိ ကြားကာလ၏ အသေးစိတ်။ သင်သည် အလိုအလျောက်စနစ်ကို ယုံကြည်နိုင်သည် သို့မဟုတ် ကိုယ်တိုင်ရွေးချယ်နိုင်သည်။ အောက်ဖော်ပြပါပုံသည် အသေးစိတ်ဖော်ပြမှု နည်းပါးလွန်းခြင်း၏ ဥပမာတစ်ခုဖြစ်သည် - သင်သည် ကွဲလွဲမှုကို လွတ်သွားနိုင်သည်။ ဤဆက်တင်ကိုအသုံးပြုခြင်းဖြင့် algorithm ၏ အာရုံခံနိုင်စွမ်းကို ကွဲလွဲချက်များအဖြစ် ပြောင်းလဲနိုင်သည်။
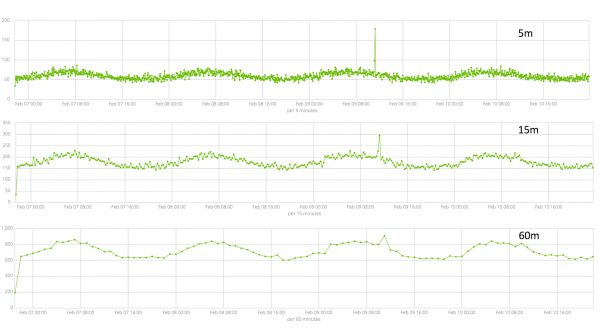
စုဆောင်းထားသောဒေတာ၏ကြာချိန်သည် ခွဲခြမ်းစိတ်ဖြာမှု၏ထိရောက်မှုကို သက်ရောက်မှုရှိသော အဓိကအချက်ဖြစ်သည်။ ခွဲခြမ်းစိတ်ဖြာမှုအတွင်း၊ အယ်လဂိုရီသမ်သည် ထပ်ခါတလဲလဲကြားကာလများကို ခွဲခြားသတ်မှတ်ပေးသည်၊ ယုံကြည်မှုကြားကာလများ (အခြေခံမျဉ်းကြောင်းများ) ကို တွက်ချက်ပြီး ကွဲလွဲချက်များကို ခွဲခြားသတ်မှတ်သည် - မက်ထရစ်၏ ပုံမှန်အပြုအမူများမှ ပုံမှန်သွေဖည်သွားပါသည်။ ဥပမာ-
အချက်အလက်အသေးစားပါရှိသော အခြေခံအချက်များ
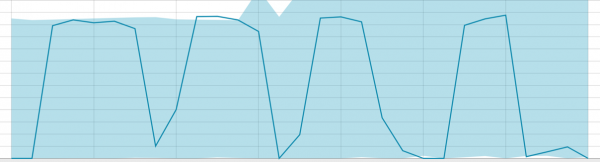
အယ်လဂိုရီသမ်တွင် သင်ယူစရာတစ်ခုခုရှိသောအခါ၊ အခြေခံမျဉ်းသည် ဤကဲ့သို့ဖြစ်သည်-
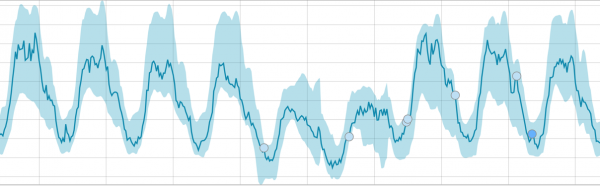
အလုပ်စတင်ပြီးနောက်၊ အယ်လဂိုရီသမ်သည် စံနှုန်းမှ မမှန်မကန်သွေဖည်မှုများကို ဆုံးဖြတ်ပြီး မမှန်မကန်ဖြစ်နိုင်ခြေအရ ၎င်းတို့ကို အဆင့်သတ်မှတ်သည် (သက်ဆိုင်ရာတံဆိပ်၏အရောင်ကို ကွင်းစဥ်တွင်ဖော်ပြထားသည်)။
သတိပေးချက် (အပြာ): 25 အောက်
အသေးအဖွဲ (အဝါ): 25-50
မေဂျာ (လိမ္မော်ရောင်): 50-75
စိုးရိမ်ရ (အနီရောင်): 75-100
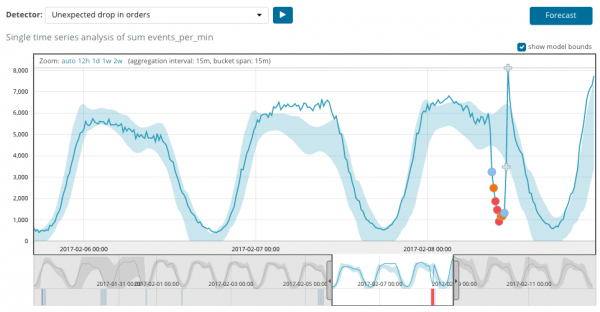
အောက်ဖော်ပြပါဂရပ်သည် တွေ့ရှိသောကွဲလွဲချက်များကို နမူနာပြသည်။
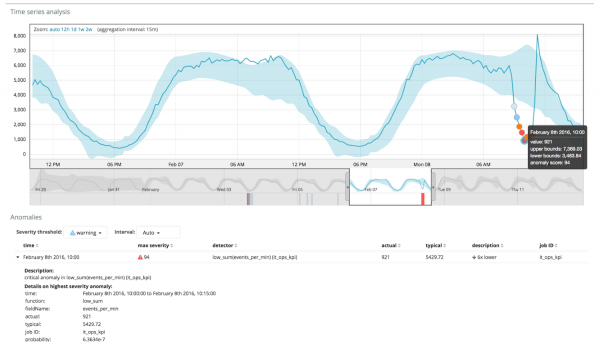
ဤနေရာတွင် ကွဲလွဲမှုတစ်ခု ဖြစ်နိုင်ခြေကို ညွှန်ပြသည့် နံပါတ် 94 ကို သင်တွေ့နိုင်ပါသည်။ တန်ဖိုးသည် 100 နီးပါးဖြစ်သောကြောင့် ကျွန်ုပ်တို့တွင် ကွဲလွဲမှုတစ်ခုရှိသည်ကို ဆိုလိုသည်မှာ ရှင်းပါသည်။ ဂရပ်အောက်ရှိ ကော်လံသည် ထိုနေရာတွင် ပေါ်လာသည့် မက်ထရစ်တန်ဖိုး၏ 0.000063634% ၏ ဖြစ်နိုင်ခြေနည်းပါးသော ဖြစ်နိုင်ခြေကို ပြသည်။
ကွဲလွဲချက်များကို ရှာဖွေခြင်းအပြင်၊ Kibana တွင် ကြိုတင်ခန့်မှန်းခြင်းကိုလည်း လုပ်ဆောင်နိုင်သည်။ ဤသည်မှာ ရိုးရိုးရှင်းရှင်းနှင့် တူညီသော ကွဲလွဲချက်များဖြင့် လုပ်ဆောင်သည် - ခလုတ် ခန့်မှန်းချက် ညာဘက်အပေါ်ထောင့်မှာ။
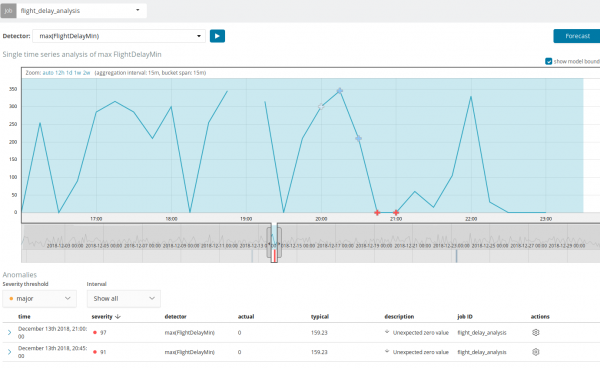
ခန့်မှန်းချက်သည် အများဆုံး 8 ပတ်ကြိုတင်ခန့်မှန်းထားသည်။ တကယ်လုပ်ချင်ရင်တောင် ဒီဇိုင်းက မဖြစ်နိုင်တော့ဘူး။
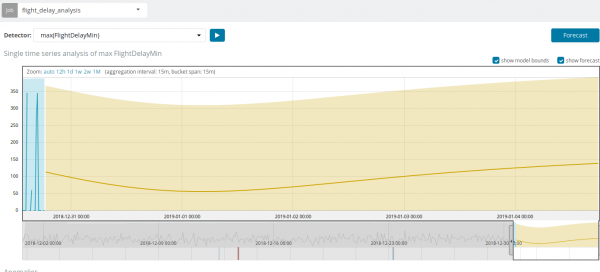
အချို့သောအခြေအနေများတွင်၊ အခြေခံအဆောက်အဦပေါ်တွင်အသုံးပြုသူတင်ဆောင်မှုကိုစောင့်ကြည့်သောအခါတွင်ခန့်မှန်းချက်သည်အလွန်အသုံးဝင်လိမ့်မည်။
Multi Metric
Elastic Stack ရှိ နောက်ထပ် ML အင်္ဂါရပ်သို့ ဆက်သွားကြပါစို့ - မက်ထရစ်များစွာကို အသုတ်တစ်ခုတွင် ပိုင်းခြားစိတ်ဖြာခြင်း။ သို့သော် ၎င်းသည် မက်ထရစ်တစ်ခုအပေါ် အခြားတစ်ခုအပေါ် မှီခိုမှုကို ခွဲခြမ်းစိတ်ဖြာမည်ဟု မဆိုလိုပါ။ ၎င်းသည် Single Metric နှင့် အတူတူပင်ဖြစ်သည်၊ သို့သော် တစ်ခုနှင့်တစ်ခု အကျိုးသက်ရောက်မှုကို လွယ်ကူစွာ နှိုင်းယှဉ်နိုင်ရန် ဖန်သားပြင်တစ်ခုပေါ်ရှိ မက်ထရစ်များစွာဖြင့်။ လူဦးရေကဏ္ဍတွင် မက်ထရစ်တစ်ခု၏ မှီခိုမှုအပေါ် ပိုင်းခြားစိတ်ဖြာခြင်းအကြောင်း ဆွေးနွေးပါမည်။
Multi Metric ဖြင့် စတုရန်းကို နှိပ်ပြီးနောက်၊ ဆက်တင်များပါသည့် ဝင်းဒိုးတစ်ခု ပေါ်လာလိမ့်မည်။ ၎င်းတို့ကို ပိုမိုအသေးစိတ်ကြည့်ကြပါစို့။
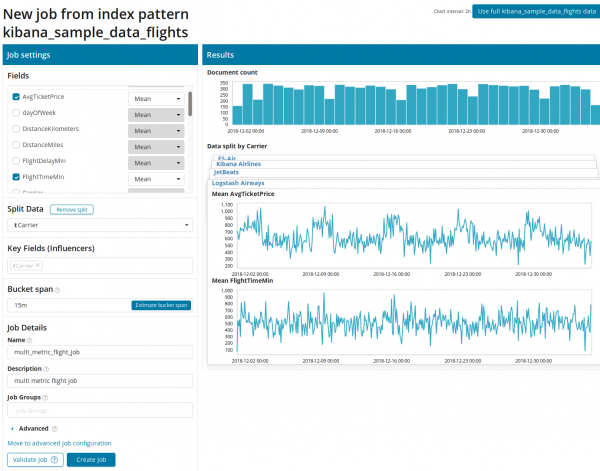
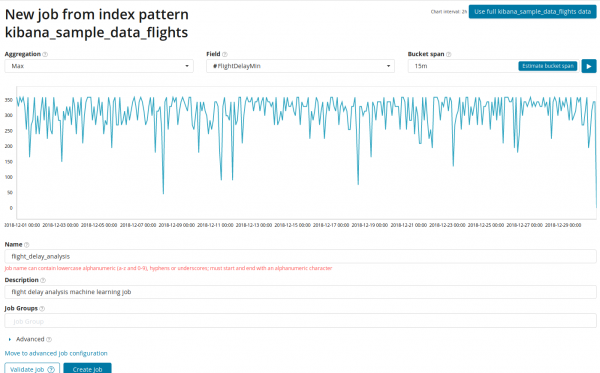
ပထမဦးစွာ သင်သည် ၎င်းတို့အပေါ် ခွဲခြမ်းစိတ်ဖြာမှုနှင့် ဒေတာစုစည်းမှုအတွက် နယ်ပယ်များကို ရွေးချယ်ရန် လိုအပ်သည်။ ဤနေရာတွင် ပေါင်းစပ်ရွေးချယ်စရာများသည် Single Metric (Max၊ High Mean၊ Low၊ Mean၊ Distinct နှင့် အခြား)။ ထို့ထက်ပို၍ ဆန္ဒရှိပါက ဒေတာကို အကွက် (field) တစ်ခုအဖြစ် ပိုင်းခြားထားသည်။ Data ခွဲပါ။) ဥပမာမှာ၊ ဒါကို နယ်ပယ်အလိုက် လုပ်တယ်။ မူရင်းလေဆိပ် ID. ညာဘက်ရှိ မက်ထရစ်ဂရပ်ကို ယခု ဂရပ်အများအပြားအဖြစ် ပြသထားကြောင်း သတိပြုပါ။
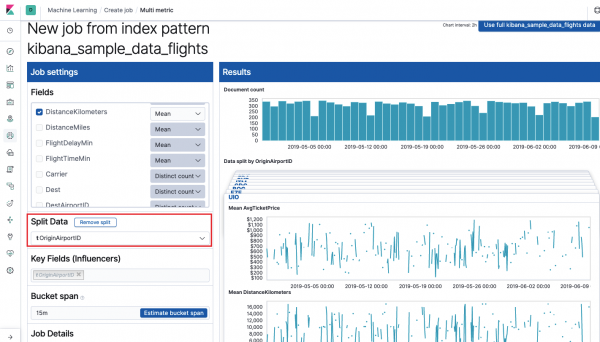
လယ်ယာ အဓိကနယ်ပယ်များ (လွှမ်းမိုးနိုင်သူများ) တွေ့ရှိထားသောကွဲလွဲချက်များကို တိုက်ရိုက်အကျိုးသက်ရောက်သည်။ ပုံမှန်အားဖြင့် ဤနေရာတွင် အနည်းဆုံးတန်ဖိုးတစ်ခု အမြဲရှိနေမည်ဖြစ်ပြီး၊ သင်သည် နောက်ထပ်တစ်ခုကို ထည့်နိုင်သည်။ အယ်လဂိုရီသမ်သည် “သြဇာအကြီးဆုံး” တန်ဖိုးများကို ခွဲခြမ်းစိတ်ဖြာပြီး ပြသသည့်အခါ ဤနယ်ပယ်များ၏ လွှမ်းမိုးမှုကို ထည့်သွင်းစဉ်းစားမည်ဖြစ်သည်။
စတင်ပြီးနောက်၊ ဤကဲ့သို့သောအရာသည် Kibana မျက်နှာပြင်တွင်ပေါ်လာလိမ့်မည်။
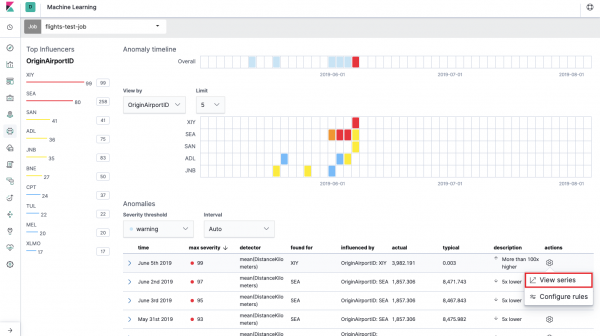
ဒါကို ခေါ်တာ။ အကွက်တန်ဖိုးတစ်ခုစီအတွက် ကွဲလွဲချက်များ၏ အပူမြေပုံ မူရင်းလေဆိပ် ID၊ ကျွန်ုပ်တို့ဖော်ပြခဲ့သည်။ Data ခွဲပါ။. Single Metric ကဲ့သို့ပင်၊ အရောင်သည် ပုံမှန်မဟုတ်သော သွေဖည်မှုအဆင့်ကို ညွှန်ပြသည်။ သံသယဖြစ်ဖွယ်ခွင့်ပြုချက်များစွာရှိသောသူများကို ခြေရာခံရန်၊ ဥပမာအားဖြင့် အလားတူခွဲခြမ်းစိတ်ဖြာမှုတစ်ခုကို လုပ်ဆောင်ရန် အဆင်ပြေသည်။ ကျွန်တော်တို့ ရေးထားပြီးသား ဤနေရာတွင် စုဆောင်းပြီး ခွဲခြမ်းစိတ်ဖြာနိုင်သည်။
အပူမြေပုံအောက်တွင် ကွဲလွဲချက်များစာရင်းတစ်ခုရှိသည်၊ တစ်ခုချင်းစီမှ အသေးစိတ်ခွဲခြမ်းစိတ်ဖြာရန်အတွက် Single Metric မြင်ကွင်းသို့ သင်ပြောင်းနိုင်ပါသည်။
ပြည်သူ့အင်အား
မတူညီသော မက်ထရစ်များကြား ဆက်စပ်မှုများကြား ကွဲလွဲချက်များကို ရှာဖွေရန် Elastic Stack တွင် အထူးပြု လူဦးရေ ခွဲခြမ်းစိတ်ဖြာမှု ရှိသည်။ ဥပမာအားဖြင့်၊ ပစ်မှတ်စနစ်သို့ တောင်းဆိုမှုအရေအတွက် တိုးလာသောအခါတွင် အခြားသူများနှင့် နှိုင်းယှဉ်ပါက ဆာဗာ၏ စွမ်းဆောင်ရည်တွင် မှားယွင်းသောတန်ဖိုးများကို သင်ရှာဖွေနိုင်သည် ၎င်း၏အကူအညီဖြင့် ၎င်းသည် ၎င်း၏အကူအညီဖြင့် ဖြစ်ပါသည်။
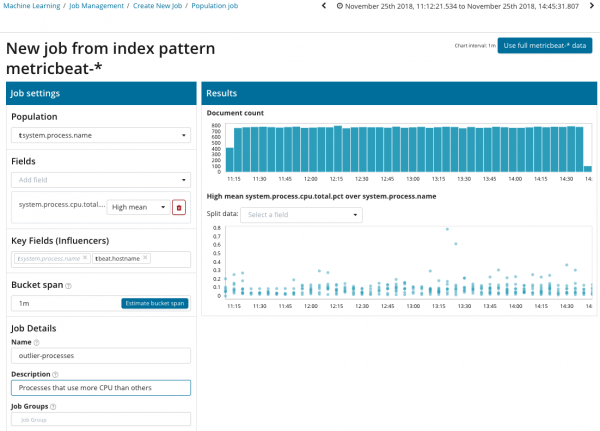
ဤပုံဥပမာတွင်၊ လူဦးရေအကွက်သည် ခွဲခြမ်းစိတ်ဖြာထားသော မက်ထရစ်များနှင့် ဆက်စပ်မည့်တန်ဖိုးကို ညွှန်ပြသည်။ ဤကိစ္စတွင်၎င်းသည်လုပ်ငန်းစဉ်၏အမည်ဖြစ်သည်။ ရလဒ်အနေဖြင့် လုပ်ငန်းစဉ်တစ်ခုစီ၏ ပရိုဆက်ဆာဝန်သည် တစ်ခုနှင့်တစ်ခုအပေါ် မည်ကဲ့သို့ အကျိုးသက်ရောက်သည်ကို ကျွန်ုပ်တို့ မြင်တွေ့ရမည်ဖြစ်သည်။
ခွဲခြမ်းစိတ်ဖြာထားသောဒေတာ၏ဂရပ်သည် Single Metric နှင့် Multi Metric ဆိုင်ရာ ကိစ္စများနှင့် ကွဲပြားကြောင်း ကျေးဇူးပြု၍ သတိပြုပါ။ ခွဲခြမ်းစိတ်ဖြာထားသော ဒေတာတန်ဖိုးများ ဖြန့်ဖြူးခြင်းဆိုင်ရာ ပိုမိုကောင်းမွန်သော ခံယူချက်တစ်ခုအတွက် ဒီဇိုင်းဖြင့် ဤအရာကို Kibana တွင် ပြုလုပ်ခဲ့သည်။
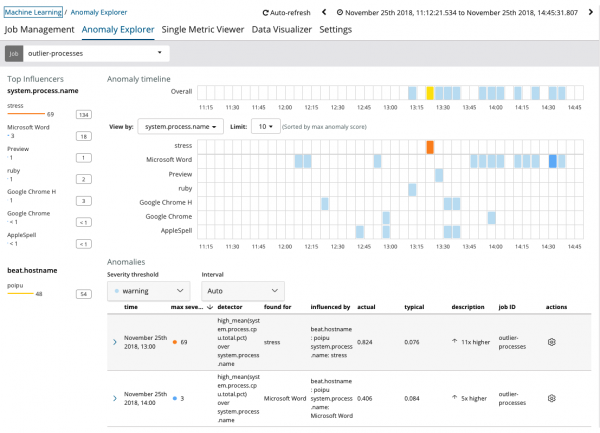
လုပ်ငန်းစဉ်သည် ပုံမှန်မဟုတ်စွာ ပြုမူနေကြောင်း ဂရပ်က ဖော်ပြသည်။ စိတ်ဖိစီးမှု ဆာဗာပေါ်တွင် (နည်းလမ်းအားဖြင့်၊ အထူး utility တစ်ခုမှထုတ်ပေးသည်) poipu(သို့မဟုတ်) သြဇာလွှမ်းမိုးသူဖြစ်ရန် လွှမ်းမိုးခဲ့သူ၊
အဆင့်မြင့်
ချိန်ညှိမှုဖြင့် ပိုင်းခြားစိတ်ဖြာခြင်း။ Advanced ခွဲခြမ်းစိတ်ဖြာခြင်းဖြင့်၊ နောက်ထပ်ဆက်တင်များကို Kibana တွင်ပေါ်လာသည်။ ဖန်တီးမှုမီနူးရှိ အဆင့်မြင့်အကွက်ကို နှိပ်ပြီးနောက်၊ တက်ဘ်များပါသည့် ဤဝင်းဒိုး ပေါ်လာသည်။ တက်ဘ် ယောဘသည်အသေးစိတ် ကျွန်ုပ်တို့သည် ၎င်းကို ရည်ရွယ်ချက်ရှိရှိ ကျော်သွားသည်၊ ခွဲခြမ်းစိတ်ဖြာမှုကို သတ်မှတ်ခြင်းနှင့် တိုက်ရိုက်မသက်ဆိုင်သော အခြေခံဆက်တင်များရှိသည်။
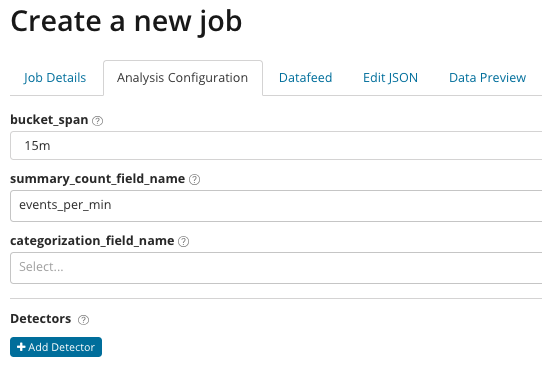
В အနှစ်ချုပ်_count_field_name ပေါင်းစည်းထားသောတန်ဖိုးများပါရှိသော စာရွက်စာတမ်းများမှ အကွက်တစ်ခု၏အမည်ကို ရွေးချယ်နိုင်ပါသည်။ ဤဥပမာတွင် တစ်မိနစ်လျှင် ဖြစ်ရပ်အရေအတွက်။ IN ပြောင်းလဲနိုင်သောတန်ဖိုးအချို့ပါရှိသောစာရွက်စာတမ်းမှအကွက်တစ်ခု၏အမည်နှင့်တန်ဖိုးကိုညွှန်ပြသည်။ ဤအကွက်တွင် မျက်နှာဖုံးကို အသုံးပြု၍ ခွဲခြမ်းစိတ်ဖြာထားသော ဒေတာကို အတွဲများအဖြစ် ခွဲနိုင်သည်။ ခလုတ်ကိုအာရုံစိုက်ပါ။ detector ထည့်ပါ။ ယခင်ပုံဥပမာတွင်။ အောက်တွင် ဤခလုတ်ကို နှိပ်ခြင်း၏ ရလဒ်ဖြစ်သည်။
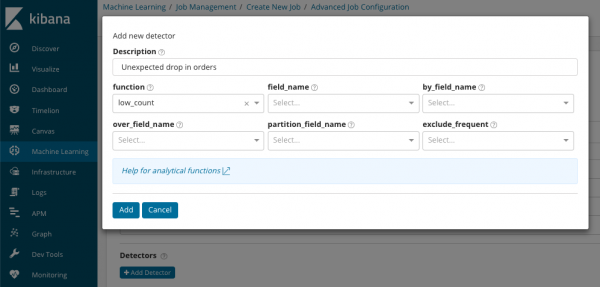
ဤသည်မှာ သီးခြားလုပ်ဆောင်စရာတစ်ခုအတွက် ကွဲလွဲမှားနေသော detector ကို configure လုပ်ခြင်းအတွက် နောက်ထပ်ပိတ်ဆို့ခြင်းတစ်ခုဖြစ်သည်။ ကျွန်ုပ်တို့သည် အောက်ပါဆောင်းပါးများတွင် သီးခြားအသုံးပြုမှုကိစ္စများ (အထူးသဖြင့် လုံခြုံရေးကိစ္စများ) ကို ဆွေးနွေးရန် စီစဉ်ထားပါသည်။ ဥပမာအားဖြင့်, disassembled ကိစ္စများထဲမှတစ်ခု။ ၎င်းသည် ရှားပါးသောတန်ဖိုးများ ပေါ်လာခြင်းအတွက် ရှာဖွေမှုနှင့် ဆက်စပ်နေပါသည်။ .
လယ်ပြင်၌ function ကို ကွဲလွဲချက်များကို ရှာဖွေရန် သီးခြားလုပ်ဆောင်ချက်တစ်ခုကို သင်ရွေးချယ်နိုင်သည်။ လွဲလို့ ရှားပါးသောနောက်ထပ် စိတ်ဝင်စားစရာကောင်းတဲ့ လုပ်ဆောင်ချက်တွေ ရှိပါသေးတယ်- . ၎င်းတို့သည် နေ့ သို့မဟုတ် တစ်ပတ်လုံး တိုင်းတာမှုများ၏ အပြုအမူများတွင် ကွဲလွဲချက်များကို ခွဲခြားသတ်မှတ်သည်။ အခြားခွဲခြမ်းစိတ်ဖြာခြင်းလုပ်ဆောင်ချက်များ .
В field_name ခွဲခြမ်းစိတ်ဖြာမှုဆောင်ရွက်မည့် စာရွက်စာတမ်း၏ နယ်ပယ်ကို ညွှန်ပြသည်။ By_field_name ဤနေရာတွင် သတ်မှတ်ထားသော စာရွက်စာတမ်းအကွက်၏ တန်ဖိုးတစ်ခုစီအတွက် ခွဲခြမ်းစိတ်ဖြာမှုရလဒ်များကို ပိုင်းခြားရန် အသုံးပြုနိုင်သည်။ ဖြည့်စွက်ရင် over_field_name အထက်တွင် ဆွေးနွေးခဲ့သည့် လူဦးရေ ခွဲခြမ်းစိတ်ဖြာမှုကို သင်ရရှိမည်ဖြစ်သည်။ တန်ဖိုးတစ်ခု သတ်မှတ်ရင် partition_field_nameထို့နောက် စာရွက်စာတမ်း၏ ဤအကွက်အတွက် သီးခြားအခြေခံလိုင်းများကို တန်ဖိုးတစ်ခုစီအတွက် တွက်ချက်မည် (တန်ဖိုး၊ ဥပမာ၊ ဆာဗာအမည် သို့မဟုတ် ဆာဗာပေါ်ရှိ လုပ်ငန်းစဉ်များ ဖြစ်နိုင်သည်)။ IN မကြာခဏ ဖယ်ထုတ်ပါ။ ရွေးချယ်နိုင်ပါတယ်။ အားလုံး သို့မဟုတ် အဘယ်သူမျှမဆိုလိုသည်မှာ မကြာခဏ ဖြစ်ပေါ်နေသော စာရွက်စာတမ်း အကွက်တန်ဖိုးများကို ဖယ်ထုတ်ခြင်း (သို့မဟုတ်) ပါဝင်သည်။
ဤဆောင်းပါးတွင်၊ ကျွန်ုပ်တို့သည် Elastic Stack တွင် စက်သင်ယူမှုစွမ်းရည်များအကြောင်း အတတ်နိုင်ဆုံး တိုတိုတုတ်တုတ် အကြံဥာဏ်ပေးနိုင်ရန် ကြိုးစားခဲ့သည်၊ နောက်ကွယ်တွင် အသေးစိတ်အချက်များစွာ ကျန်နေသေးသည်။ Elastic Stack ကို အသုံးပြု၍ သင်ဖြေရှင်းနိုင်ခဲ့သည့် ကိစ္စရပ်များနှင့် မည်သည့်အလုပ်များအတွက် အသုံးပြုသည်ကို မှတ်ချက်တွင် ပြောပြပါ။ ကျွန်ုပ်တို့ထံ ဆက်သွယ်ရန်၊ သင်သည် Habré သို့မဟုတ် ကိုယ်ရေးကိုယ်တာ မက်ဆေ့ချ်များကို အသုံးပြုနိုင်သည်။ .
source: www.habr.com
