

ဆောင်းပါးတွင် ရိုးရိုး (တွဲထားသော) ဆုတ်ယုတ်မှုမျဉ်း၏ သင်္ချာညီမျှခြင်းကို ဆုံးဖြတ်ရန် နည်းလမ်းများစွာကို ဆွေးနွေးထားသည်။
ဤနေရာတွင် ဆွေးနွေးထားသော ညီမျှခြင်းဖြေရှင်းနည်းအားလုံးသည် အနိမ့်ဆုံး နှစ်ထပ်နည်းလမ်းကို အခြေခံထားသည်။ နည်းလမ်းများကို အောက်ပါအတိုင်း ဖော်ပြကြပါစို့။
- သရုပ်ဖြေရှင်းချက်
- Gradient အဆင်း
- Stochastic gradient ဆင်းသက်သည်။
မျဉ်းဖြောင့်၏ညီမျှခြင်းကိုဖြေရှင်းနည်းတစ်ခုစီအတွက်၊ ဆောင်းပါးသည် အမျိုးမျိုးသောလုပ်ဆောင်ချက်များကို ပံ့ပိုးပေးသည်၊ အဓိကအားဖြင့် စာကြည့်တိုက်ကိုအသုံးမပြုဘဲ ရေးသားထားသည့်အရာများကို ပိုင်းခြားထားသည်။ numpy နှင့် တွက်ချက်မှုများအတွက် အသုံးပြုသည်။ numpy. ကျွမ်းကျင်စွာ အသုံးပြုနိုင်သည်ဟု ယုံကြည်သည်။ numpy ကွန်ပြူတာကုန်ကျစရိတ်ကို လျှော့ချပေးပါလိမ့်မယ်။
ဆောင်းပါးတွင်ပေးထားသောကုဒ်အားလုံးကို ဘာသာစကားဖြင့် ရေးသားထားသည်။ python 2.7 အသုံးပြုခြင်း ဂျူပီတာမှတ်စုစာအုပ်. နမူနာဒေတာပါသည့် အရင်းအမြစ်ကုဒ်နှင့် ဖိုင်ကို တွင်တင်ထားသည်။
ဆောင်းပါးသည် ဥာဏ်ရည်တု-စက်သင်ယူမှုတွင် အလွန်ကျယ်ပြန့်သော အပိုင်းကို ကျွမ်းကျင်စွာ စတင်လေ့လာနေသူများနှင့် စတင်သူနှစ်ဦးစလုံးအတွက် ပိုမိုရည်ရွယ်ပါသည်။
ပစ္စည်းကိုသရုပ်ဖော်ရန်၊ ကျွန်ုပ်တို့သည် အလွန်ရိုးရှင်းသောဥပမာကိုအသုံးပြုသည်။
နမူနာအခြေအနေများ
ကျွန်ုပ်တို့တွင် မှီခိုအားထားမှုကို ဖော်ပြသော တန်ဖိုးငါးခုရှိသည်။ Y от X (ဇယားနံပါတ် 1):
ဇယားနံပါတ် ၁ “ဥပမာ အခြေအနေများ”

တန်ဖိုးထားမှုတွေ ရှိလာမယ်။  တစ်နှစ်တာ၏လဖြစ်သည်၊
တစ်နှစ်တာ၏လဖြစ်သည်၊  - ဒီလဝင်ငွေ။ တစ်နည်းဆိုရသော် ဝင်ငွေသည် တစ်နှစ်တာ၏ လပေါ်တွင် မူတည်သည်။
- ဒီလဝင်ငွေ။ တစ်နည်းဆိုရသော် ဝင်ငွေသည် တစ်နှစ်တာ၏ လပေါ်တွင် မူတည်သည်။  - ဝင်ငွေအပေါ် မူတည်သော တစ်ခုတည်းသော လက္ခဏာ။
- ဝင်ငွေအပေါ် မူတည်သော တစ်ခုတည်းသော လက္ခဏာ။
ဥပမာအားဖြင့် - ထို့ကြောင့်၊ တစ်နှစ်၏လတွင်ဝင်ငွေ၏အခြေအနေအရမှီခိုမှု၏ရှုထောင့်မှနှစ်ခုလုံးနှင့်တန်ဖိုးများအရေအတွက်၏ရှုထောင့်မှ - ၎င်းတို့ထဲမှအလွန်နည်းပါးပါသည်။ သို့သော်၊ ဤကဲ့သို့သောရိုးရှင်းမှုသည် အစပြုသူများ ရောနှောထားသည့်အရာများကို အမြဲတမ်းလွယ်ကူစွာရှင်းပြရန်၊ ၎င်းတို့ပြောသည့်အတိုင်း ဖြစ်နိုင်ချေရှိသည်။ ထို့အပြင် ကိန်းဂဏန်းများ၏ ရိုးရှင်းမှုသည် သိသိသာသာ လုပ်အားစရိတ် မလိုအပ်ဘဲ စာရွက်ပေါ်တွင် နမူနာကို ဖြေရှင်းလိုသူများကို ခွင့်ပြုမည်ဖြစ်သည်။
ဥပမာတွင် ပေးထားသော မှီခိုအား ရိုးရှင်းသော (တွဲထားသော) ဆုတ်ယုတ်မှုမျဉ်း၏ သင်္ချာညီမျှခြင်းဖြင့် အနီးစပ်ဆုံး ခန့်မှန်းနိုင်သည်ဟု ယူဆကြပါစို့။

ဘယ်မှာ  ဝင်ငွေရရှိသည့်လ၊
ဝင်ငွေရရှိသည့်လ၊  - လနှင့်ကိုက်ညီသော ၀င်ငွေ၊
- လနှင့်ကိုက်ညီသော ၀င်ငွေ၊  и
и  ခန့်မှန်းမျဉ်း၏ ဆုတ်ယုတ်မှုကိန်းဂဏန်းများ။
ခန့်မှန်းမျဉ်း၏ ဆုတ်ယုတ်မှုကိန်းဂဏန်းများ။
ကိန်းဂဏန်းကို သတိပြုပါ။  ခန့်မှန်းမျဉ်း၏ slope သို့မဟုတ် gradient ဟုခေါ်လေ့ရှိသည်၊ အဆိုပါပမာဏကိုကိုယ်စားပြုသည်။
ခန့်မှန်းမျဉ်း၏ slope သို့မဟုတ် gradient ဟုခေါ်လေ့ရှိသည်၊ အဆိုပါပမာဏကိုကိုယ်စားပြုသည်။  ပြောင်းလဲသွားတဲ့အခါ
ပြောင်းလဲသွားတဲ့အခါ  .
.
ဥပမာအားဖြင့် ကျွန်ုပ်တို့၏တာဝန်မှာ ညီမျှခြင်းတွင် ထိုသို့သောကိန်းများကို ရွေးချယ်ရန်ဖြစ်သည်။  и
и  ကျွန်ုပ်တို့၏ တွက်ချက်ထားသော ၀င်ငွေတန်ဖိုးများကို လအလိုက် သွေဖည်စေသော အဖြေမှန်များမှ၊ i.e. နမူနာတွင်တင်ပြထားသောတန်ဖိုးများသည်အနည်းငယ်မျှသာရှိလိမ့်မည်။
ကျွန်ုပ်တို့၏ တွက်ချက်ထားသော ၀င်ငွေတန်ဖိုးများကို လအလိုက် သွေဖည်စေသော အဖြေမှန်များမှ၊ i.e. နမူနာတွင်တင်ပြထားသောတန်ဖိုးများသည်အနည်းငယ်မျှသာရှိလိမ့်မည်။
အနည်းဆုံး စတုရန်းပုံနည်းလမ်း
အနည်းဆုံး စတုရန်းနည်းအရ၊ သွေဖည်မှုကို နှစ်ထပ်ဖြင့် တွက်ချက်သင့်သည်။ ဤနည်းပညာသည် ၎င်းတို့တွင် ဆန့်ကျင်ဘက်လက္ခဏာများရှိနေပါက အပြန်အလှန်သွေဖည်မှုများကို ရှောင်ရှားနိုင်မည်ဖြစ်သည်။ ဥပမာအားဖြင့်၊ အကယ်၍ ကိစ္စတစ်ခုတွင်၊ သွေဖည်သည်။ +5 (အပေါင်းငါး) နှင့်အခြား -5 (အနှုတ်ငါး) ထို့နောက် သွေဖည်မှု၏ပေါင်းလဒ်သည် တစ်ခုနှင့်တစ်ခု ဖြတ်သွားမည်ဖြစ်ပြီး ပမာဏမှာ 0 (သုည) ဖြစ်သည်။ သွေဖည်မှုကို နှစ်ထပ်မလုပ်ဘဲ ဖြစ်နိုင်သည်၊ သို့သော် modulus ၏ပိုင်ဆိုင်မှုကိုအသုံးပြုပြီး သွေဖည်မှုများအားလုံးကို အပြုသဘောဆောင်ပြီး စုပုံလာမည်ဖြစ်သည်။ ကျွန်ုပ်တို့သည် ဤအချက်ကို အသေးစိတ်ဖော်ပြမည်မဟုတ်သော်လည်း တွက်ချက်မှုအဆင်ပြေစေရန်အတွက် သွေဖည်ကို နှစ်ထပ်ရန် ထုံးစံအတိုင်း ညွှန်ပြပါသည်။
ဤသည်မှာ နှစ်ထပ်သွေဖည်မှု အနည်းဆုံး ပေါင်းလဒ် (အမှားအယွင်းများ) ကို ဆုံးဖြတ်မည့် ဖော်မြူလာပုံသဏ္ဌာန် ဖြစ်သည်-

ဘယ်မှာ  အဖြေမှန်များ၏ အနီးစပ်ဆုံးလုပ်ဆောင်ချက် (ဆိုလိုသည်မှာ ကျွန်ုပ်တို့တွက်ချက်ထားသော ၀င်ငွေ)၊
အဖြေမှန်များ၏ အနီးစပ်ဆုံးလုပ်ဆောင်ချက် (ဆိုလိုသည်မှာ ကျွန်ုပ်တို့တွက်ချက်ထားသော ၀င်ငွေ)၊
 အဖြေမှန်များဖြစ်ကြသည် (နမူနာတွင်ဖော်ပြထားသော ဝင်ငွေများ)၊
အဖြေမှန်များဖြစ်ကြသည် (နမူနာတွင်ဖော်ပြထားသော ဝင်ငွေများ)၊
 နမူနာအညွှန်းကိန်း (သွေဖည်ဆုံးဖြတ်သည့်လ၏ နံပါတ်)
နမူနာအညွှန်းကိန်း (သွေဖည်ဆုံးဖြတ်သည့်လ၏ နံပါတ်)
လုပ်ဆောင်ချက်ကို ခွဲခြားကြည့်ရအောင်၊ တစ်စိတ်တစ်ပိုင်းကွဲပြားသော ညီမျှခြင်းများကို သတ်မှတ်ပြီး ခွဲခြမ်းစိတ်ဖြာမှုဖြေရှင်းချက်သို့ ဆက်သွားရန် အဆင်သင့်ဖြစ်ပါစေ။ သို့သော် ဦးစွာ၊ ကွဲပြားခြင်းအကြောင်း အတိုချုံးလေ့လာပြီး ဆင်းသက်လာခြင်း၏ ဂျီဩမေတြီအဓိပ္ပါယ်ကို သတိရကြပါစို့။
ကွဲပြားခြင်း။
Differentiation သည် function တစ်ခု၏ ဆင်းသက်လာမှုကို ရှာဖွေခြင်း၏ လုပ်ဆောင်မှုဖြစ်သည်။
ဆင်းသက်လာခြင်းကို ဘာအတွက်အသုံးပြုသနည်း။ လုပ်ဆောင်ချက်တစ်ခု၏ ဆင်းသက်လာမှုသည် လုပ်ဆောင်ချက်၏ ပြောင်းလဲမှုနှုန်းကို ဖော်ပြပြီး ၎င်း၏ ဦးတည်ချက်ကို ကျွန်ုပ်တို့အား ပြောပြသည်။ သတ်မှတ်ထားသောအမှတ်တွင် ဆင်းသက်လာပါက အပြုသဘောဆောင်ပါက လုပ်ဆောင်ချက် တိုးလာမည် မဟုတ်ပါက လုပ်ဆောင်ချက် လျော့နည်းသွားမည်ဖြစ်သည်။ အကြွင်းမဲ့ ဆင်းသက်မှုတန်ဖိုး ကြီးလေလေ၊ လုပ်ဆောင်ချက်တန်ဖိုးများ ၏ ပြောင်းလဲမှုနှုန်း မြင့်မားလေ ဖြစ်သလို function ဂရပ်၏ လျှောစောက်လည်း မတ်စောက်လေ ဖြစ်သည်။
ဥပမာအားဖြင့်၊ Cartesian သြဒီနိတ်စနစ်၏ အခြေအနေများအောက်တွင်၊ အမှတ် M(0,0) မှ ဆင်းသက်လာသောတန်ဖိုးသည် ညီမျှသည်။ 25 + ဆိုလိုသည်မှာ သတ်မှတ်အမှတ်တွင် တန်ဖိုးပြောင်းသွားသောအခါ၊  သမားရိုးကျယူနစ်တစ်ခုဖြင့် ညာဘက်သို့၊ တန်ဖိုး
သမားရိုးကျယူနစ်တစ်ခုဖြင့် ညာဘက်သို့၊ တန်ဖိုး  သမားရိုးကျယူနစ် 25 တိုးလာသည်။ ဂရပ်ပေါ်တွင် တန်ဖိုးများ သိသိသာသာ မြင့်တက်လာပုံရသည်။
သမားရိုးကျယူနစ် 25 တိုးလာသည်။ ဂရပ်ပေါ်တွင် တန်ဖိုးများ သိသိသာသာ မြင့်တက်လာပုံရသည်။  ပေးထားသည့်အချက်မှ
ပေးထားသည့်အချက်မှ
နောက်ဥပမာ။ ဆင်းသက်လာတန်ဖိုးသည် ညီမျှသည်။ -0,1 ဆိုလိုသည်မှာ ရွှေ့ပြောင်းသည့်အခါတွင် ဖြစ်သည်။  သမားရိုးကျ ယူနစ်တစ်ခုအတွက် တန်ဖိုး
သမားရိုးကျ ယူနစ်တစ်ခုအတွက် တန်ဖိုး  သမားရိုးကျ ယူနစ် 0,1 သာ လျော့ကျသွားသည်။ တစ်ချိန်တည်းမှာပင်၊ function ၏ဂရပ်တွင်၊ ကျွန်ုပ်တို့သည် သိသာထင်ရှားသော အောက်ဘက်သို့ လျှောစောက်ကို သတိပြုနိုင်သည်။ တောင်ကြီးတစ်ခုနှင့် သရုပ်ဖော်ပုံဆွဲခြင်း ၊ ကျွန်ုပ်တို့သည် အလွန်မတ်စောက်သော တောင်ထွတ်ကိုတက်ခဲ့ရသည့် ယခင်ဥပမာနှင့်မတူဘဲ တောင်ပေါ်မှ ဖြည်းညှင်းစွာ လျှောဆင်းလာပုံနှင့် တူပါသည် :)
သမားရိုးကျ ယူနစ် 0,1 သာ လျော့ကျသွားသည်။ တစ်ချိန်တည်းမှာပင်၊ function ၏ဂရပ်တွင်၊ ကျွန်ုပ်တို့သည် သိသာထင်ရှားသော အောက်ဘက်သို့ လျှောစောက်ကို သတိပြုနိုင်သည်။ တောင်ကြီးတစ်ခုနှင့် သရုပ်ဖော်ပုံဆွဲခြင်း ၊ ကျွန်ုပ်တို့သည် အလွန်မတ်စောက်သော တောင်ထွတ်ကိုတက်ခဲ့ရသည့် ယခင်ဥပမာနှင့်မတူဘဲ တောင်ပေါ်မှ ဖြည်းညှင်းစွာ လျှောဆင်းလာပုံနှင့် တူပါသည် :)
ထို့ကြောင့် function ကိုခွဲခြားပြီးနောက်  အလေးသာမှုများဖြင့်
အလေးသာမှုများဖြင့်  и
и  ကျွန်ုပ်တို့သည် 1st အမှာစာတစ်စိတ်တစ်ပိုင်းကွဲပြားသောညီမျှခြင်းများကို သတ်မှတ်သည်။ ညီမျှခြင်းများကို ဆုံးဖြတ်ပြီးနောက်၊ ကျွန်ုပ်တို့သည် ညီမျှခြင်းနှစ်ခု၏ စနစ်တစ်ခုကို လက်ခံရရှိမည်ဖြစ်ပြီး၊ အဆိုပါ coefficients ၏ထိုကဲ့သို့သောတန်ဖိုးများကို ကျွန်ုပ်တို့ရွေးချယ်နိုင်စေမည့် ဖြေရှင်းခြင်းဖြင့်၊
ကျွန်ုပ်တို့သည် 1st အမှာစာတစ်စိတ်တစ်ပိုင်းကွဲပြားသောညီမျှခြင်းများကို သတ်မှတ်သည်။ ညီမျှခြင်းများကို ဆုံးဖြတ်ပြီးနောက်၊ ကျွန်ုပ်တို့သည် ညီမျှခြင်းနှစ်ခု၏ စနစ်တစ်ခုကို လက်ခံရရှိမည်ဖြစ်ပြီး၊ အဆိုပါ coefficients ၏ထိုကဲ့သို့သောတန်ဖိုးများကို ကျွန်ုပ်တို့ရွေးချယ်နိုင်စေမည့် ဖြေရှင်းခြင်းဖြင့်၊  и
и  ပေးထားသော အမှတ်များမှ သက်ဆိုင်ရာ ဆင်းသက်လာမှုများ၏ တန်ဖိုးများသည် အလွန်သေးငယ်သော ပမာဏဖြင့် ပြောင်းလဲကာ ခွဲခြမ်းစိတ်ဖြာဖြေရှင်းချက်တစ်ခုတွင် လုံးဝမပြောင်းလဲပါ။ တစ်နည်းဆိုရသော်၊ တွေ့ရှိသော coefficients မှအမှားလုပ်ဆောင်ချက်သည် အနိမ့်ဆုံးသို့ရောက်ရှိမည်ဖြစ်ပြီး၊ ဤအချက်များတွင် တစ်စိတ်တစ်ပိုင်း ဆင်းသက်လာမှုများ၏တန်ဖိုးများသည် သုညနှင့် ညီမျှမည်ဖြစ်သည့်အတွက်ကြောင့်ဖြစ်သည်။
ပေးထားသော အမှတ်များမှ သက်ဆိုင်ရာ ဆင်းသက်လာမှုများ၏ တန်ဖိုးများသည် အလွန်သေးငယ်သော ပမာဏဖြင့် ပြောင်းလဲကာ ခွဲခြမ်းစိတ်ဖြာဖြေရှင်းချက်တစ်ခုတွင် လုံးဝမပြောင်းလဲပါ။ တစ်နည်းဆိုရသော်၊ တွေ့ရှိသော coefficients မှအမှားလုပ်ဆောင်ချက်သည် အနိမ့်ဆုံးသို့ရောက်ရှိမည်ဖြစ်ပြီး၊ ဤအချက်များတွင် တစ်စိတ်တစ်ပိုင်း ဆင်းသက်လာမှုများ၏တန်ဖိုးများသည် သုညနှင့် ညီမျှမည်ဖြစ်သည့်အတွက်ကြောင့်ဖြစ်သည်။
ထို့ကြောင့် ကွဲပြားခြင်း၏ စည်းမျဉ်းများ အရ၊ ကိန်းဂဏန်းနှင့် စပ်လျဉ်း၍ ပထမအစီအစဥ်၏ တစ်စိတ်တစ်ပိုင်း ဆင်းသက်ခြင်းညီမျှခြင်း  ပုံစံယူပါမည်
ပုံစံယူပါမည်

1st order partial derivative equation နှင့် စပ်လျဉ်း၍  ပုံစံယူပါမည်
ပုံစံယူပါမည်

ရလဒ်အနေဖြင့်၊ ကျွန်ုပ်တို့သည် မျှတရိုးရှင်းသော ခွဲခြမ်းစိတ်ဖြာမှုဖြေရှင်းချက်ပါရှိသော ညီမျှခြင်းစနစ်တစ်ခုကို လက်ခံရရှိခဲ့သည်-
စတင်{ညီမျှခြင်း*}
စတင်{cases}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
အဆုံးသတ်{cases}
အဆုံး{ညီမျှခြင်း*}
ညီမျှခြင်းအား မဖြေရှင်းမီ ကြိုတင်တင်လိုက်ရအောင်၊ တင်ခြင်းမှန်ကန်ကြောင်း စစ်ဆေးပြီး ဒေတာကို ဖော်မတ်လုပ်ကြပါစို့။
ဒေတာကို တင်ခြင်းနှင့် ဖော်မတ်ချခြင်း။
ခွဲခြမ်းစိတ်ဖြာမှုဖြေရှင်းချက်အတွက်နှင့် နောက်ပိုင်းတွင် gradient နှင့် stochastic gradient ဆင်းသက်ခြင်းအတွက်၊ ကုဒ်ကို ပုံစံနှစ်မျိုးဖြင့် အသုံးပြုပါမည်- စာကြည့်တိုက်ကို အသုံးပြုခြင်းဖြစ်သည်၊ numpy ၎င်းကို အသုံးမပြုဘဲ၊ ထို့နောက် ကျွန်ုပ်တို့သည် သင့်လျော်သော ဒေတာပုံစံချခြင်း (ကုဒ်ကိုကြည့်ပါ) လိုအပ်ပါမည်။
ဒေတာဖွင့်ခြင်းနှင့် လုပ်ဆောင်ခြင်းကုဒ်
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'မြင်ကွင်း
ယခု၊ ကျွန်ုပ်တို့သည် ပထမဦးစွာ ဒေတာကို တင်ပြီးသည်နှင့် ဒုတိယအချက်မှာ တင်ခြင်း၏ မှန်ကန်မှုကို စစ်ဆေးပြီး နောက်ဆုံးတွင် ဒေတာကို ဖော်မတ်ချပြီးနောက်၊ ကျွန်ုပ်တို့သည် ပထမဆုံး စိတ်ကူးပုံဖော်မှုကို လုပ်ဆောင်ပါမည်။ ဒီအတွက် မကြာခဏသုံးတဲ့ နည်းလမ်းကတော့ တွဲကွက် စာကြည့်တိုက်များ ပင်လယ်ပင်လယ်. ကျွန်ုပ်တို့၏ဥပမာတွင်၊ အရေအတွက်အကန့်အသတ်ကြောင့်၊ စာကြည့်တိုက်ကိုအသုံးပြုရန်အချက်မရှိပါ။ ပင်လယ်ပင်လယ်. ပုံမှန်စာကြည့်တိုက်ကို အသုံးပြုပါမည်။ matplotlib အပိုင်းအစကို ကြည့်ရုံပါပဲ။
Scatterplot ကုဒ်
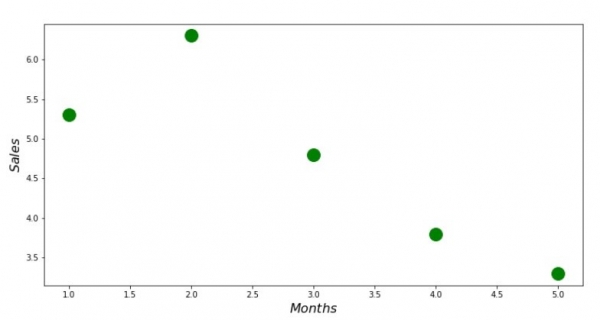
print 'График №1 "Зависимость выручки от месяца года"'
plt.plot(x_us,y_us,'o',color='green',markersize=16)
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.show()ဇယားနံပါတ် 1 "တစ်နှစ်တာ၏လပေါ်ဝင်ငွေအပေါ် မူတည်သည်"
သရုပ်ဖြေရှင်းချက်
အသုံးအများဆုံး tools တွေကိုသုံးကြည့်ရအောင် Python နှင့် ညီမျှခြင်းစနစ်အား ဖြေရှင်းပါ။
စတင်{ညီမျှခြင်း*}
စတင်{cases}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
အဆုံးသတ်{cases}
အဆုံး{ညီမျှခြင်း*}
Cramer ၏စည်းမျဉ်းအရ ယေဘူယျ အဆုံးအဖြတ် နှင့် အဆုံးအဖြတ် များကို ကျွန်ုပ်တို့ တွေ့ရှိပါမည်။  နှင့်
နှင့်  ထို့နောက် သတ်မှတ်ကိန်းကို ပိုင်းခြားသည်။
ထို့နောက် သတ်မှတ်ကိန်းကို ပိုင်းခြားသည်။  ယေဘူယျသတ်မှတ်ကိန်းသို့ - ကိန်းဂဏန်းကို ရှာပါ။
ယေဘူယျသတ်မှတ်ကိန်းသို့ - ကိန်းဂဏန်းကို ရှာပါ။  အလားတူ ကိန်းဂဏန်းကို ကျွန်ုပ်တို့ ရှာဖွေသည်။
အလားတူ ကိန်းဂဏန်းကို ကျွန်ုပ်တို့ ရှာဖွေသည်။  .
.
သရုပ်ခွဲအဖြေကုဒ်
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)ဤသည်မှာ ကျွန်ုပ်တို့ရရှိသောအရာဖြစ်သည်-

ထို့ကြောင့် ဖော်ကိန်းများ၏ တန်ဖိုးများကို တွေ့ရှိပြီး နှစ်ထပ်သွေဖည်မှုများ၏ ပေါင်းလဒ်ကို ထူထောင်ထားသည်။ တွေ့ရှိသော coefficients များနှင့်အညီ scattering histogram ပေါ်တွင် မျဉ်းဖြောင့်တစ်ခုဆွဲကြပါစို့။
ဆုတ်ယုတ်မှုမျဉ်းကုဒ်
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()ဇယားနံပါတ် 2 "မှန်ကန်သော တွက်ချက်ထားသော အဖြေများ"
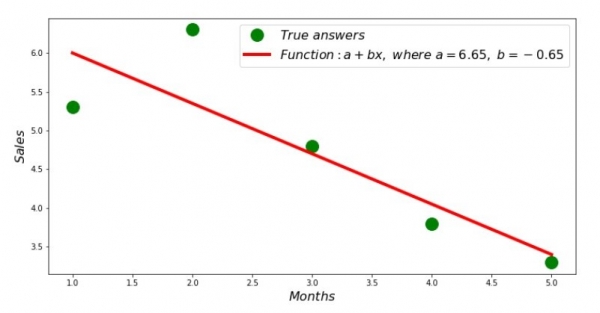
လတိုင်းအတွက် သွေဖည်သောဂရပ်ကို ကြည့်ရှုနိုင်ပါသည်။ ကျွန်ုပ်တို့၏အခြေအနေတွင်၊ ကျွန်ုပ်တို့သည် ၎င်းထံမှ သိသာထင်ရှားသောလက်တွေ့ကျသောတန်ဖိုးကို ရယူမည်မဟုတ်သော်လည်း၊ ရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှုညီမျှခြင်းသည် တစ်နှစ်တစ်လ၏ဝင်ငွေအပေါ် မှီခိုမှုအား မည်မျှကောင်းမွန်ကြောင်း သိချင်စိတ်ကို ကျေနပ်စေသည်။
သွေဖည်သောဇယားကုဒ်
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()ဇယားနံပါတ် 3 "သွေဖည်မှုများ၊ %"
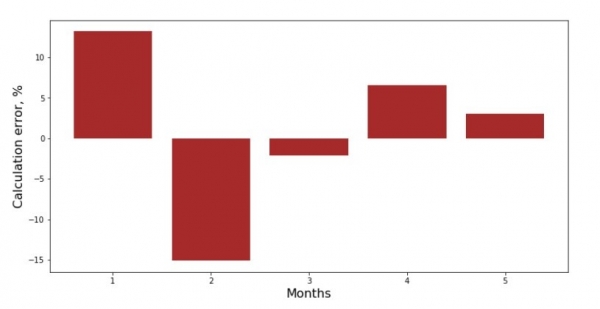
ပြီးပြည့်စုံခြင်းမရှိသော်လည်း ကျွန်ုပ်တို့၏တာဝန်ကို ပြီးမြောက်ခဲ့သည်။
coefficients ကိုဆုံးဖြတ်ရန် function ကိုရေးကြပါစို့  и
и  စာကြည့်တိုက်ကို အသုံးပြု numpyပိုမိုတိကျစွာ၊ ကျွန်ုပ်တို့သည် လုပ်ဆောင်ချက်နှစ်ခုကို ရေးသားပါမည်- တစ်ခုမှာ pseudoinverse matrix ကိုအသုံးပြုခြင်း (လုပ်ငန်းစဉ်သည် တွက်ချက်မှုအရ ရှုပ်ထွေးပြီး မတည်မငြိမ်ဖြစ်နေသောကြောင့် လက်တွေ့တွင် မထောက်ခံပါ)၊ နောက်တစ်ခုသည် matrix equation ကိုအသုံးပြုထားသည်။
စာကြည့်တိုက်ကို အသုံးပြု numpyပိုမိုတိကျစွာ၊ ကျွန်ုပ်တို့သည် လုပ်ဆောင်ချက်နှစ်ခုကို ရေးသားပါမည်- တစ်ခုမှာ pseudoinverse matrix ကိုအသုံးပြုခြင်း (လုပ်ငန်းစဉ်သည် တွက်ချက်မှုအရ ရှုပ်ထွေးပြီး မတည်မငြိမ်ဖြစ်နေသောကြောင့် လက်တွေ့တွင် မထောက်ခံပါ)၊ နောက်တစ်ခုသည် matrix equation ကိုအသုံးပြုထားသည်။
ခွဲခြမ်းစိတ်ဖြာဖြေရှင်းချက်ကုဒ် (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npCoefficients ကိုဆုံးဖြတ်ရာတွင်အသုံးပြုသည့်အချိန်ကို နှိုင်းယှဉ်ကြည့်ကြပါစို့  и
и  တင်ပြပုံနည်းလမ်း ၃ ခုနှင့်အညီ၊
တင်ပြပုံနည်းလမ်း ၃ ခုနှင့်အညီ၊
တွက်ချက်ချိန်တွက်ရန်ကုဒ်
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов без использования библиотеки NumPy:" + ' 33[0m'
% timeit ab_us = Kramer_method(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием псевдообратной матрицы:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием матричного уравнения:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
ဒေတာပမာဏအနည်းငယ်ဖြင့်၊ Cramer ၏နည်းလမ်းကို အသုံးပြု၍ ကိန်းဂဏန်းများကို ရှာဖွေပေးသည့် "ကိုယ်တိုင်ရေးထားသော" လုပ်ဆောင်ချက်သည် ရှေ့တွင်ထွက်ပေါ်လာသည်။
ယခု သင်သည် ကိန်းဂဏန်းများကို ရှာဖွေရန် အခြားနည်းလမ်းများသို့ ဆက်သွားနိုင်သည်။  и
и  .
.
Gradient အဆင်း
ပထမဦးစွာ၊ gradient ဆိုသည်မှာ မည်သည်ကို သတ်မှတ်ကြပါစို့။ ရိုးရိုးရှင်းရှင်းပြောရလျှင် gradient သည် function တစ်ခု၏ အမြင့်ဆုံးတိုးတက်မှုကိုညွှန်ပြသည့် အပိုင်းတစ်ခုဖြစ်သည်။ တောင်ပေါ်တက်ခြင်းနှင့် နှိုင်းယှဥ်၍ မျဉ်းစောင်းမျက်နှာစာသည် တောင်ထိပ်သို့ မတ်စောက်ဆုံးတက်သည့်နေရာဖြစ်သည်။ တောင်နှင့် နမူနာကို ပြုစုပျိုးထောင်ရာတွင် အမှန်တွင် ကျွန်ုပ်တို့သည် မြေနိမ့်ပိုင်းသို့ အမြန်ဆုံးရောက်ရှိရန် မတ်စောက်သော ဆင်းသက်ရန် လိုအပ်ကြောင်း၊ ဆိုလိုသည်မှာ အနိမ့်ဆုံး - လုပ်ဆောင်မှု အတိုးအလျှော့ မလုပ်နိုင်သော နေရာဖြစ်သည်။ ဤအချိန်တွင် ဆင်းသက်လာမှုသည် သုညနှင့် ညီမျှလိမ့်မည်။ ထို့ကြောင့်၊ ကျွန်ုပ်တို့သည် gradient မလိုအပ်သော်လည်း antigradient တစ်ခုဖြစ်သည်။ Antigradient ကိုရှာရန် gradient ကို မြှောက်ရန်သာလိုသည်။ -1 (အနုတ်တစ်ခု)။
လုပ်ဆောင်ချက်တစ်ခုတွင် minima များစွာရှိနိုင်သည်ဟူသောအချက်ကို အာရုံစိုက်ကြည့်ကြစို့၊ အောက်တွင်ဖော်ပြထားသော အဆိုပြုထားသော algorithm ကိုအသုံးပြုပြီး ၎င်းတို့အနက်မှတစ်ခုသို့ ဆင်းသွားပါက၊ တွေ့ရှိထားသည့်ထက်နိမ့်နိုင်သည့် အခြားနိမ့်ဆုံးတစ်ခုကို ရှာတွေ့နိုင်မည်မဟုတ်ပါ။ စိတ်လျှော့လိုက်ရအောင်၊ ဒါက ငါတို့အတွက် ခြိမ်းခြောက်မှုမဟုတ်ဘူး! ကျွန်ုပ်တို့၏ကိစ္စတွင်၊ ကျွန်ုပ်တို့သည် ကျွန်ုပ်တို့၏လုပ်ဆောင်မှုမှစ၍ အနည်းဆုံးတစ်ခုတည်းဖြင့် ကိုင်တွယ်ဖြေရှင်းနေပါသည်။  ဂရပ်ပေါ်တွင် ပုံမှန် parabola တစ်ခုဖြစ်သည်။ ကျွန်ုပ်တို့၏ကျောင်းသင်္ချာသင်တန်းမှ ကျွန်ုပ်တို့အားလုံး ကောင်းစွာသိထားသင့်သည့်အတိုင်း parabola တွင် အနိမ့်ဆုံးတစ်ခုသာရှိသည်။
ဂရပ်ပေါ်တွင် ပုံမှန် parabola တစ်ခုဖြစ်သည်။ ကျွန်ုပ်တို့၏ကျောင်းသင်္ချာသင်တန်းမှ ကျွန်ုပ်တို့အားလုံး ကောင်းစွာသိထားသင့်သည့်အတိုင်း parabola တွင် အနိမ့်ဆုံးတစ်ခုသာရှိသည်။
gradient ကို ဘာ့ကြောင့် လိုအပ်သလဲ ဆိုတာ သိရှိပြီးနောက်၊ gradient သည် segment တစ်ခု ဖြစ်သည်၊ ဆိုလိုသည်မှာ ပေးထားသော coordinates ရှိသော vector တစ်ခု ဖြစ်ပြီး၊ အတိအကျ တူညီသော coefficients ဖြစ်သည့်  и
и  ကျွန်ုပ်တို့သည် gradient ဆင်းသက်မှုကို အကောင်အထည်ဖော်နိုင်သည်။
ကျွန်ုပ်တို့သည် gradient ဆင်းသက်မှုကို အကောင်အထည်ဖော်နိုင်သည်။
မစတင်မီ၊ ဆင်းသက်သည့် အယ်လဂိုရီသမ်နှင့်ပတ်သက်သည့် စာကြောင်းအနည်းငယ်ကိုသာ ဖတ်ရန် အကြံပြုလိုသည်-
- ကျွန်ုပ်တို့သည် coefficients ၏သြဒိနိတ်များကို pseudo-random ပုံစံဖြင့် ဆုံးဖြတ်သည်။
 и . ကျွန်ုပ်တို့၏ဥပမာတွင်၊ သုညနှင့်နီးသော ကိန်းများကို သတ်မှတ်ပါမည်။ ဤသည်မှာ သာမန်အလေ့အကျင့်တစ်ခုဖြစ်သော်လည်း ကိစ္စတစ်ခုစီတွင် ၎င်း၏ကိုယ်ပိုင်အလေ့အကျင့်ရှိနိုင်သည်။
и . ကျွန်ုပ်တို့၏ဥပမာတွင်၊ သုညနှင့်နီးသော ကိန်းများကို သတ်မှတ်ပါမည်။ ဤသည်မှာ သာမန်အလေ့အကျင့်တစ်ခုဖြစ်သော်လည်း ကိစ္စတစ်ခုစီတွင် ၎င်း၏ကိုယ်ပိုင်အလေ့အကျင့်ရှိနိုင်သည်။ - သြဒိနိတ်မှ အမှတ်တွင် 1st order partial derivative ၏တန်ဖိုးကို နုတ်ပါ။ . ဒီတော့ derivative က positive ဆိုရင် function က တိုးလာပါတယ်။ ထို့ကြောင့်၊ ဆင်းသက်ခြင်း၏တန်ဖိုးကို နုတ်ခြင်းဖြင့် ကျွန်ုပ်တို့သည် ကြီးထွားမှု၏ ဆန့်ကျင်ဘက်ဦးတည်ချက်ဖြစ်သော ဆင်းသက်ရာလမ်းကြောင်းသို့ ရွေ့သွားပါမည်။ derivative သည် negative ဖြစ်နေပါက၊ ဤအမှတ်တွင် function သည် ကျဆင်းသွားပြီး derivative ၏တန်ဖိုးကို နုတ်ခြင်းဖြင့် ဆင်းသက်ခြင်းဆီသို့ ဦးတည်သွားပါသည်။
- ကျွန်ုပ်တို့သည် သြဒီနိတ်ဖြင့် အလားတူလုပ်ဆောင်မှုကို လုပ်ဆောင်ပါသည်။ : အမှတ်တွင် တစ်စိတ်တစ်ပိုင်း ဆင်းသက်ခြင်း၏ တန်ဖိုးကို နုတ်ပါ။ .
- အနိမ့်ဆုံးကိုခုန်ကျော်ပြီး နက်ရှိုင်းသောအာကာသထဲသို့ ပျံသန်းခြင်းမပြုရန်၊ ဆင်းသက်ရာလမ်းကြောင်းတွင် ခြေလှမ်းအရွယ်အစားကို သတ်မှတ်ရန် လိုအပ်သည်။ ယေဘုယျအားဖြင့်၊ သင်သည် ခြေလှမ်းကို မှန်ကန်စွာ သတ်မှတ်နည်းနှင့် တွက်ချက်မှုဆိုင်ရာ ကုန်ကျစရိတ်များကို လျှော့ချရန်အတွက် ဆင်းသက်သည့် လုပ်ငန်းစဉ်အတွင်း ၎င်းကို မည်သို့ပြောင်းလဲရမည်အကြောင်း ဆောင်းပါးတစ်ခုလုံးကို ရေးသားနိုင်သည်။ သို့သော် ယခုကျွန်ုပ်တို့ရှေ့တွင် အနည်းငယ်ကွဲပြားသောအလုပ်တစ်ခုရှိပါသည်၊ ကျွန်ုပ်တို့သည် “poke” ၏ သိပ္ပံနည်းကျနည်းလမ်းကို အသုံးပြု၍ သို့မဟုတ် တူညီသောစကားပုံတွင် လက်တွေ့ကျကျပြောထားသည့်အတိုင်း ခြေလှမ်းအရွယ်အစားကို တည်ထောင်ပါမည်။
- ပြီးတာနဲ့ ငါတို့ပေးထားတဲ့ သြဒိနိတ်တွေကနေ и နိမိတ်လက္ခဏာများ၏ တန်ဖိုးများကို နုတ်ပါ၊ ကျွန်ုပ်တို့သည် သြဒိနိတ်အသစ်များကို ရယူသည်။ и . ကျွန်ုပ်တို့သည် တွက်ချက်ထားသော သြဒိနိတ်များမှ ပြီးသော နောက်တစ်ဆင့် (အနုတ်) ကို ယူသည်။ ထို့ကြောင့် လိုအပ်သော ပေါင်းစည်းမှု မပြီးမချင်း သံသရာသည် အဖန်ဖန် အထပ်ထပ် စတင်သည်။
 и
и  . ကျွန်ုပ်တို့၏ဥပမာတွင်၊ သုညနှင့်နီးသော ကိန်းများကို သတ်မှတ်ပါမည်။ ဤသည်မှာ သာမန်အလေ့အကျင့်တစ်ခုဖြစ်သော်လည်း ကိစ္စတစ်ခုစီတွင် ၎င်း၏ကိုယ်ပိုင်အလေ့အကျင့်ရှိနိုင်သည်။
. ကျွန်ုပ်တို့၏ဥပမာတွင်၊ သုညနှင့်နီးသော ကိန်းများကို သတ်မှတ်ပါမည်။ ဤသည်မှာ သာမန်အလေ့အကျင့်တစ်ခုဖြစ်သော်လည်း ကိစ္စတစ်ခုစီတွင် ၎င်း၏ကိုယ်ပိုင်အလေ့အကျင့်ရှိနိုင်သည်။ အမှတ်တွင် 1st order partial derivative ၏တန်ဖိုးကို နုတ်ပါ။
အမှတ်တွင် 1st order partial derivative ၏တန်ဖိုးကို နုတ်ပါ။  . ဒီတော့ derivative က positive ဆိုရင် function က တိုးလာပါတယ်။ ထို့ကြောင့်၊ ဆင်းသက်ခြင်း၏တန်ဖိုးကို နုတ်ခြင်းဖြင့် ကျွန်ုပ်တို့သည် ကြီးထွားမှု၏ ဆန့်ကျင်ဘက်ဦးတည်ချက်ဖြစ်သော ဆင်းသက်ရာလမ်းကြောင်းသို့ ရွေ့သွားပါမည်။ derivative သည် negative ဖြစ်နေပါက၊ ဤအမှတ်တွင် function သည် ကျဆင်းသွားပြီး derivative ၏တန်ဖိုးကို နုတ်ခြင်းဖြင့် ဆင်းသက်ခြင်းဆီသို့ ဦးတည်သွားပါသည်။
. ဒီတော့ derivative က positive ဆိုရင် function က တိုးလာပါတယ်။ ထို့ကြောင့်၊ ဆင်းသက်ခြင်း၏တန်ဖိုးကို နုတ်ခြင်းဖြင့် ကျွန်ုပ်တို့သည် ကြီးထွားမှု၏ ဆန့်ကျင်ဘက်ဦးတည်ချက်ဖြစ်သော ဆင်းသက်ရာလမ်းကြောင်းသို့ ရွေ့သွားပါမည်။ derivative သည် negative ဖြစ်နေပါက၊ ဤအမှတ်တွင် function သည် ကျဆင်းသွားပြီး derivative ၏တန်ဖိုးကို နုတ်ခြင်းဖြင့် ဆင်းသက်ခြင်းဆီသို့ ဦးတည်သွားပါသည်။  : အမှတ်တွင် တစ်စိတ်တစ်ပိုင်း ဆင်းသက်ခြင်း၏ တန်ဖိုးကို နုတ်ပါ။
: အမှတ်တွင် တစ်စိတ်တစ်ပိုင်း ဆင်းသက်ခြင်း၏ တန်ဖိုးကို နုတ်ပါ။  .
. и
и  နိမိတ်လက္ခဏာများ၏ တန်ဖိုးများကို နုတ်ပါ၊ ကျွန်ုပ်တို့သည် သြဒိနိတ်အသစ်များကို ရယူသည်။
နိမိတ်လက္ခဏာများ၏ တန်ဖိုးများကို နုတ်ပါ၊ ကျွန်ုပ်တို့သည် သြဒိနိတ်အသစ်များကို ရယူသည်။  и
и  . ကျွန်ုပ်တို့သည် တွက်ချက်ထားသော သြဒိနိတ်များမှ ပြီးသော နောက်တစ်ဆင့် (အနုတ်) ကို ယူသည်။ ထို့ကြောင့် လိုအပ်သော ပေါင်းစည်းမှု မပြီးမချင်း သံသရာသည် အဖန်ဖန် အထပ်ထပ် စတင်သည်။
. ကျွန်ုပ်တို့သည် တွက်ချက်ထားသော သြဒိနိတ်များမှ ပြီးသော နောက်တစ်ဆင့် (အနုတ်) ကို ယူသည်။ ထို့ကြောင့် လိုအပ်သော ပေါင်းစည်းမှု မပြီးမချင်း သံသရာသည် အဖန်ဖန် အထပ်ထပ် စတင်သည်။အားလုံး! ယခုကျွန်ုပ်တို့သည် Mariana Trench ၏အနက်ရှိုင်းဆုံးသောင်ပြင်ကိုရှာဖွေရန်အဆင်သင့်ဖြစ်နေပါပြီ။ စလိုက်ကြစို့။
gradient ဆင်းသက်မှုအတွက် ကုဒ်
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Mariana Trench ၏အောက်ခြေသို့ ခုန်ဆင်းပြီး ထိုနေရာတွင် တူညီသောကိန်းဂဏန်းတန်ဖိုးများကို တွေ့ရှိခဲ့သည်။  и
и  အတိအကျ မျှော်လင့်ရမည့်အရာဖြစ်သည်။
အတိအကျ မျှော်လင့်ရမည့်အရာဖြစ်သည်။
နောက်ထပ်ငုပ်ကြည့်ရအောင်၊ ဒီတစ်ကြိမ်မှာသာ ကျွန်ုပ်တို့ရဲ့ ရေနက်ယာဉ်မှာ အခြားနည်းပညာတွေနဲ့ ပြည့်နှက်နေမယ့် စာကြည့်တိုက်၊ numpy.
gradient ဆင်းသက်မှုအတွက် ကုဒ် (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
ဖော်ကိန်းတန်ဖိုးများ  и
и  မပြောင်းလဲနိုင်သော။
မပြောင်းလဲနိုင်သော။
gradient ဆင်းစဉ်အတွင်း error မည်ကဲ့သို့ ပြောင်းလဲခဲ့သည်ကို ကြည့်ကြပါစို့၊ ဆိုလိုသည်မှာ၊ အဆင့်တစ်ခုစီတွင် နှစ်ထပ်သွေဖည်မှုပေါင်းလဒ်များ မည်သို့ပြောင်းလဲသွားသည်ကို လေ့လာကြည့်ကြပါစို့။
နှစ်ထပ်သွေဖည်မှုများ၏ ပေါင်းလဒ်များကို ပုံဖော်ရန်အတွက် ကုဒ်
print 'График№4 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()ဂရပ် နံပါတ် 4 " gradient ဆင်းစဉ်အတွင်း နှစ်ထပ်သွေဖည်မှုပေါင်းလဒ်"
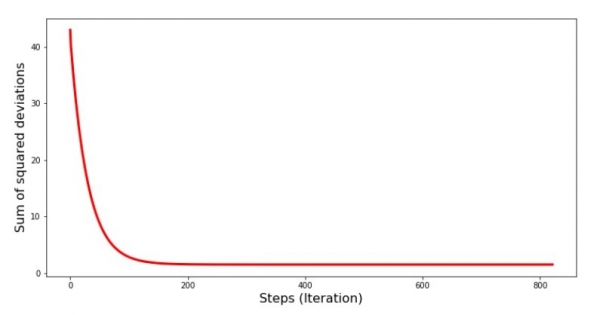
ဂရပ်ပေါ်တွင် အဆင့်တစ်ဆင့်ချင်းစီတွင် အမှားအယွင်းများ လျော့နည်းလာသည်ကို ကျွန်ုပ်တို့တွေ့မြင်ရပြီး အချို့သော ထပ်ခါတလဲလဲ ပြုလုပ်မှုများပြီးနောက် အလျားလိုက်နီးပါးမျဉ်းကြောင်းကို သတိပြုမိပါသည်။
နောက်ဆုံးအနေနဲ့၊ ကုဒ်လုပ်ဆောင်ချိန်ရဲ့ ကွာခြားချက်ကို ခန့်မှန်းကြည့်ရအောင်။
gradient ဆင်းသက်မှု တွက်ချက်ချိန်ကို ဆုံးဖြတ်ရန် ကုဒ်
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска без использования библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска с использованием библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
ကျွန်ုပ်တို့ တစ်ခုခုမှားနေပြီ ဖြစ်ကောင်းဖြစ်နိုင်သော်လည်း ၎င်းသည် စာကြည့်တိုက်ကို အသုံးမပြုသော ရိုးရှင်းသော "အိမ်တွင်ရေးထားသော" လုပ်ဆောင်ချက်တစ်ခုဖြစ်သည်။ numpy စာကြည့်တိုက်ကို အသုံးပြု၍ လုပ်ဆောင်ချက်တစ်ခု၏ တွက်ချက်မှုအချိန်ကို ပိုမိုကောင်းမွန်စေသည်။ numpy.
သို့သော် ကျွန်ုပ်တို့သည် မတ်တပ်ရပ်မနေဘဲ ရိုးရှင်းသော linear regression equation ကိုဖြေရှင်းရန် အခြားစိတ်လှုပ်ရှားဖွယ်နည်းလမ်းတစ်ခုကို လေ့လာရန် ဦးတည်နေပါသည်။ ငါတို့ကိုတွေ့ပါ။
Stochastic gradient ဆင်းသက်သည်။
stochastic gradient ဆင်းသက်ခြင်း၏ လုပ်ဆောင်မှုနိယာမကို လျင်မြန်စွာ နားလည်နိုင်ရန်၊ ၎င်းသည် သာမန် gradient ဆင်းသက်ခြင်းမှ ၎င်း၏ ကွာခြားချက်များကို ဆုံးဖြတ်ရန် ပိုကောင်းသည်။ ကျွန်ုပ်တို့သည် gradient ဆင်းသက်ခြင်း၏ဖြစ်ရပ်တွင်၊ ဆင်းသက်လာသော ညီမျှခြင်းများတွင်  и
и  နမူနာတွင် ရရှိနိုင်သော အင်္ဂါရပ်အားလုံး၏ တန်ဖိုးများနှင့် စစ်မှန်သောအဖြေများကို အသုံးပြုခဲ့သည် (ဆိုလိုသည်မှာ အားလုံး၏ပေါင်းလဒ်များ၊
နမူနာတွင် ရရှိနိုင်သော အင်္ဂါရပ်အားလုံး၏ တန်ဖိုးများနှင့် စစ်မှန်သောအဖြေများကို အသုံးပြုခဲ့သည် (ဆိုလိုသည်မှာ အားလုံး၏ပေါင်းလဒ်များ၊  и
и  ) stochastic gradient မျိုးနွယ်တွင်၊ ကျွန်ုပ်တို့သည် နမူနာတွင်ပါရှိသော တန်ဖိုးအားလုံးကို အသုံးမပြုသော်လည်း၊ ယင်းအစား၊ pseudo-random ဟုခေါ်သော နမူနာအညွှန်းကို ရွေးချယ်ပြီး ၎င်း၏တန်ဖိုးများကို အသုံးပြုပါ။
) stochastic gradient မျိုးနွယ်တွင်၊ ကျွန်ုပ်တို့သည် နမူနာတွင်ပါရှိသော တန်ဖိုးအားလုံးကို အသုံးမပြုသော်လည်း၊ ယင်းအစား၊ pseudo-random ဟုခေါ်သော နမူနာအညွှန်းကို ရွေးချယ်ပြီး ၎င်း၏တန်ဖိုးများကို အသုံးပြုပါ။
ဥပမာအားဖြင့်၊ အညွှန်းကိန်းသည် နံပါတ် 3 (၃) ဟု သတ်မှတ်ပါက တန်ဖိုးများကို ယူသည်။  и
и  ထို့နောက် ကျွန်ုပ်တို့သည် တန်ဖိုးများကို ဆင်းသက်သောညီမျှခြင်းများတွင် အစားထိုးပြီး သြဒီနိတ်အသစ်များကို ဆုံးဖြတ်သည်။ ထို့နောက် သြဒီနိတ်များကို ဆုံးဖြတ်ပြီးနောက်၊ ကျွန်ုပ်တို့သည် နမူနာညွှန်းကိန်းကို ကျပန်းကျပန်း ဆုံးဖြတ်ကာ တစ်စိတ်တစ်ပိုင်းကွဲပြားသောညီမျှခြင်းများတွင် အညွှန်းကိန်းများနှင့် သက်ဆိုင်သည့် တန်ဖိုးများကို အစားထိုးကာ သြဒိနိတ်များကို နည်းလမ်းသစ်ဖြင့် ဆုံးဖြတ်ပါသည်။
ထို့နောက် ကျွန်ုပ်တို့သည် တန်ဖိုးများကို ဆင်းသက်သောညီမျှခြင်းများတွင် အစားထိုးပြီး သြဒီနိတ်အသစ်များကို ဆုံးဖြတ်သည်။ ထို့နောက် သြဒီနိတ်များကို ဆုံးဖြတ်ပြီးနောက်၊ ကျွန်ုပ်တို့သည် နမူနာညွှန်းကိန်းကို ကျပန်းကျပန်း ဆုံးဖြတ်ကာ တစ်စိတ်တစ်ပိုင်းကွဲပြားသောညီမျှခြင်းများတွင် အညွှန်းကိန်းများနှင့် သက်ဆိုင်သည့် တန်ဖိုးများကို အစားထိုးကာ သြဒိနိတ်များကို နည်းလမ်းသစ်ဖြင့် ဆုံးဖြတ်ပါသည်။  и
и  စသည်တို့ ပေါင်းဆုံ စိမ်းလန်းသည့်တိုင်အောင် ပထမတစ်ချက်တွင်၊ ၎င်းသည် လုံးဝအလုပ်လုပ်ပုံမပေါ်သော်လည်း၊ အဆင့်တိုင်းတွင် အမှားသည် လျော့နည်းသွားမည်မဟုတ်သော်လည်း သဘောထားအမှန်ရှိသည်ကို သတိပြုသင့်သည်မှာ အမှန်ပင်ဖြစ်သည်။
စသည်တို့ ပေါင်းဆုံ စိမ်းလန်းသည့်တိုင်အောင် ပထမတစ်ချက်တွင်၊ ၎င်းသည် လုံးဝအလုပ်လုပ်ပုံမပေါ်သော်လည်း၊ အဆင့်တိုင်းတွင် အမှားသည် လျော့နည်းသွားမည်မဟုတ်သော်လည်း သဘောထားအမှန်ရှိသည်ကို သတိပြုသင့်သည်မှာ အမှန်ပင်ဖြစ်သည်။
သမားရိုးကျတစ်ခုထက် stochastic gradient ဆင်းသက်ခြင်း၏အားသာချက်များကားအဘယ်နည်း။ ကျွန်ုပ်တို့၏နမူနာအရွယ်အစားသည် အလွန်ကြီးမားပြီး တန်ဘိုးထောင်ပေါင်းများစွာဖြင့် တိုင်းတာပါက၊ နမူနာတစ်ခုလုံးထက် ကျပန်းတစ်ထောင်ကို စီမံလုပ်ဆောင်ရန် ပို၍လွယ်ကူပါသည်။ ဤနေရာတွင် stochastic gradient ဆင်းသက်လာခြင်းဖြစ်သည်။ ကျွန်ုပ်တို့၏အခြေအနေတွင်၊ ကွာခြားချက်များစွာကို ကျွန်ုပ်တို့သတိပြုမိမည်မဟုတ်ပါ။
ကုဒ်ကိုကြည့်ရအောင်။
stochastic gradient ဆင်းသက်မှုအတွက် ကုဒ်
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
ကျွန်ုပ်တို့သည် ကိန်းဂဏန်းများကို ဂရုတစိုက်ကြည့်ရှုပြီး “ဒါက ဘယ်လိုဖြစ်နိုင်သလဲ” ဟူသောမေးခွန်းကို မိမိကိုယ်ကို ဖမ်းဆုပ်ထားသည်။ အခြား coefficient တန်ဖိုးများ ကျွန်ုပ်တို့ ရရှိပါသည်။  и
и  . stochastic gradient သည် ညီမျှခြင်းအတွက် ပိုမိုသင့်လျော်သော ဘောင်များကို ရှာတွေ့နိုင်ပါသလား။ ကံမကောင်းစွာနဲ့။ နှစ်ထပ်သွေဖည်မှုများ၏ပေါင်းလဒ်ကိုကြည့်ရန် လုံလောက်ပြီး coefficients ၏တန်ဖိုးအသစ်များဖြင့် error သည်ပိုကြီးလာသည်ကိုတွေ့မြင်ရမည်ဖြစ်ပါသည်။ ကျွန်ုပ်တို့သည် စိတ်ပျက်အားငယ်ရန် အလျင်မလိုပါ။ error change ရဲ့ ဂရပ်တစ်ခုကို တည်ဆောက်ကြည့်ရအောင်။
. stochastic gradient သည် ညီမျှခြင်းအတွက် ပိုမိုသင့်လျော်သော ဘောင်များကို ရှာတွေ့နိုင်ပါသလား။ ကံမကောင်းစွာနဲ့။ နှစ်ထပ်သွေဖည်မှုများ၏ပေါင်းလဒ်ကိုကြည့်ရန် လုံလောက်ပြီး coefficients ၏တန်ဖိုးအသစ်များဖြင့် error သည်ပိုကြီးလာသည်ကိုတွေ့မြင်ရမည်ဖြစ်ပါသည်။ ကျွန်ုပ်တို့သည် စိတ်ပျက်အားငယ်ရန် အလျင်မလိုပါ။ error change ရဲ့ ဂရပ်တစ်ခုကို တည်ဆောက်ကြည့်ရအောင်။
Stochastic gradient ဆင်းသက်မှုတွင် နှစ်ထပ်သွေဖည်မှုပေါင်းလဒ်ကို ကြံစည်ရန် ကုဒ်
print 'График №5 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()ဂရပ်နံပါတ် 5 "stochastic gradient ဆင်းသက်စဉ်အတွင်း နှစ်ထပ်သွေဖည်မှုပေါင်းလဒ်"
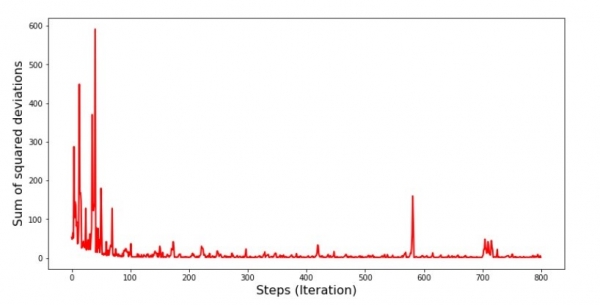
အချိန်ဇယားကိုကြည့်လိုက်တော့ အရာအားလုံးက နေရာကျပြီး အခုတော့ အားလုံးပြင်လိုက်မယ်။
ဒါဆို ဘာဖြစ်တာလဲ? အောက်ပါအတိုင်း ဖြစ်သွားပါသည်။ ကျွန်ုပ်တို့သည် တစ်လကို ကျပန်းရွေးချယ်သောအခါ၊ ကျွန်ုပ်တို့၏ အယ်လဂိုရီသမ်သည် ဝင်ငွေတွက်ချက်ရာတွင် အမှားအယွင်းများကို လျှော့ချရန် ရှာဖွေသော ရွေးချယ်ထားသောလအတွက်ဖြစ်သည်။ ထို့နောက် ကျွန်ုပ်တို့သည် အခြားတစ်လကို ရွေးချယ်ပြီး တွက်ချက်မှုကို ထပ်ခါတလဲလဲ ပြုလုပ်သော်လည်း ဒုတိယရွေးချယ်ထားသောလအတွက် အမှားအယွင်းကို လျှော့ချပေးပါသည်။ ပထမနှစ်လသည် ရိုးရှင်းသော linear regression equation ၏မျဉ်းကြောင်းမှ သိသိသာသာသွေဖည်သွားသည်ကို သတိရပါ။ ဆိုလိုသည်မှာ ဤနှစ်လအတွင်း မည်သည့်အရာကိုမဆို ရွေးချယ်သောအခါ၊ ၎င်းတို့တစ်ခုစီ၏ အမှားအယွင်းများကို လျှော့ချခြင်းဖြင့်၊ ကျွန်ုပ်တို့၏ အယ်လဂိုရီသမ်သည် နမူနာတစ်ခုလုံးအတွက် အမှားအယွင်းကို ပြင်းထန်စွာ တိုးလာစေသည်ဟု ဆိုလိုပါသည်။ ဒါဆို ဘာလုပ်ရမလဲ။ အဖြေက ရိုးရှင်းပါတယ်- ဆင်းသက်တဲ့ အဆင့်ကို လျှော့ချဖို့ လိုပါတယ်။ နောက်ဆုံးတွင်၊ ဆင်းသက်သည့်အဆင့်ကို လျှော့ချခြင်းဖြင့် အမှားသည် အတက်အဆင်း “ခုန်နေသည်” ကိုလည်း ရပ်သွားမည်ဖြစ်သည်။ သို့မဟုတ်၊ "ခုန်ခြင်း" အမှားသည်ရပ်တန့်မည်မဟုတ်သော်လည်း၎င်းသည်ဤမျှမြန်ဆန်စွာလုပ်ဆောင်မည်မဟုတ် :) စစ်ဆေးကြပါစို့။
အတိုးနှုန်းအနည်းငယ်ဖြင့် SGD ကိုလည်ပတ်ရန် ကုဒ်
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
ဂရပ် နံပါတ် 6 "stochastic gradient ဆင်းသက်စဉ်အတွင်း နှစ်ထပ်သွေဖည်မှုပေါင်း (ခြေလှမ်း 80)"
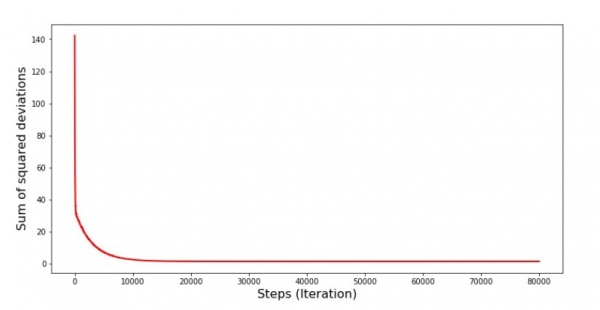
ကိန်းဂဏာန်းများ တိုးတက်လာသော်လည်း စံမမီသေးပါ။ မုသားအားဖြင့်၊ ဤနည်းဖြင့် ပြင်နိုင်သည်။ ဥပမာအားဖြင့်၊ ကျွန်ုပ်တို့သည် နောက်ဆုံးအကြိမ် 1000 တွင် အမှားအနည်းဆုံးပြုလုပ်ထားသည့် coefficients ၏တန်ဖိုးများကို ရွေးချယ်သည်။ မှန်ပါသည်၊ ဤအတွက် ကျွန်ုပ်တို့သည်လည်း ဖော်ကိန်းများ၏ တန်ဖိုးများကို ၎င်းတို့ကိုယ်တိုင် ချရေးရမည်ဖြစ်ပါသည်။ ဒါကို ကျွန်တော်တို့ မလုပ်ပေမယ့် အချိန်ဇယားကို အာရုံစိုက်ပါ။ ချောမွေ့ပုံရပြီး အမှားအယွင်းက အညီအမျှ လျော့နည်းသွားပုံရသည်။ တကယ်တော့ ဒါက မမှန်ပါဘူး။ ပထမအကြိမ် 1000 ကိုကြည့်ရှုပြီး နောက်ဆုံးနှင့် နှိုင်းယှဉ်ကြည့်ကြပါစို့။
SGD ဇယားအတွက် ကုဒ် (ပထမအဆင့် 1000)
print 'График №7 "Сумма квадратов отклонений по-шагово. Первые 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
print 'График №7 "Сумма квадратов отклонений по-шагово. Последние 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()ဂရပ်နံပါတ် 7 “နှစ်ထပ်သွေဖည်မှုပေါင်းလဒ် SGD (ပထမခြေလှမ်း 1000)”
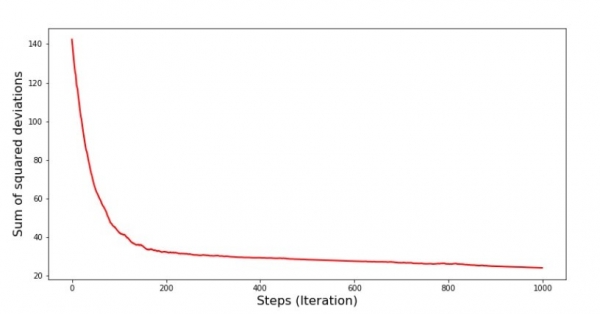
ဂရပ်နံပါတ် 8 "နှစ်ထပ်သွေဖည်မှုပေါင်းလဒ် SGD (နောက်ဆုံးအဆင့် 1000)"
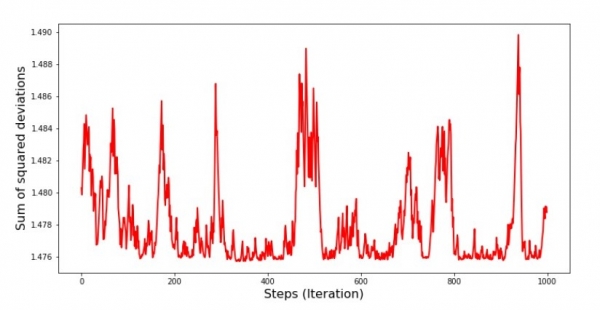
ဆင်းသက်ခြင်း၏အစတွင်၊ ကျွန်ုပ်တို့သည် မျှမျှတတတူညီပြီး အမှားအယွင်းကျဆင်းမှုကို သတိပြုမိပါသည်။ နောက်ဆုံးအကြိမ်တွေမှာ error က 1,475 ရဲ့တန်ဖိုးကို ပတ်ပြီး ပတ်လည်သွားနေတာကိုတွေ့မြင်ရပြီး တချို့အခိုက်အတန့်တွေမှာလည်း ဒီ optimal value နဲ့ ညီမျှပေမယ့် နောက်တော့ ဆက်တက်သွားသေးတယ်... ထပ်ပြောပါတယ်၊ ကိန်းဂဏန်းများ  и
и  ပြီးလျှင် error နည်းသောသူများကို ရွေးပါ။ သို့သော်၊ ကျွန်ုပ်တို့တွင် ပို၍လေးနက်သောပြဿနာတစ်ခုရှိပါသည်- အကောင်းဆုံးနှင့်နီးစပ်သောတန်ဖိုးများရရှိရန် ခြေလှမ်းပေါင်း 80 (ကုဒ်ကိုကြည့်ပါ) ကိုလုပ်ဆောင်ရပါမည်။ ၎င်းသည် stochastic gradient descent နှင့် gradient descent နှင့် ဆက်စပ်ပြီး stochastic gradient မှ တွက်ချက်ချိန်ကို ချွေတာခြင်းအယူအဆနှင့် ဆန့်ကျင်နေပါသည်။ ဘာတွေကို ပြုပြင်ပြီး မြှင့်တင်နိုင်မလဲ။ ပထမအကြိမ်တွင် ကျွန်ုပ်တို့သည် ယုံကြည်မှုရှိရှိ ကျဆင်းသွားသည်ကို သတိပြုမိရန် မခဲယဉ်းပေ၊ ထို့ကြောင့် ပထမအကြိမ်တွင် ကြီးမားသောခြေလှမ်းတစ်ခုကို ချန်ထားခဲ့ကာ ကျွန်ုပ်တို့ရှေ့ဆက်သွားသည့်အတိုင်း ခြေလှမ်းကို လျှော့ချသင့်သည်။ ဤဆောင်းပါးတွင် ကျွန်ုပ်တို့ ဤအရာကို မလုပ်ပါ - ရှည်လွန်းနေပြီဖြစ်သည်။ လုပ်ချင်တဲ့သူတွေက ဘယ်လိုလုပ်ရမလဲဆိုတာ မခက်ပါဘူး :)
ပြီးလျှင် error နည်းသောသူများကို ရွေးပါ။ သို့သော်၊ ကျွန်ုပ်တို့တွင် ပို၍လေးနက်သောပြဿနာတစ်ခုရှိပါသည်- အကောင်းဆုံးနှင့်နီးစပ်သောတန်ဖိုးများရရှိရန် ခြေလှမ်းပေါင်း 80 (ကုဒ်ကိုကြည့်ပါ) ကိုလုပ်ဆောင်ရပါမည်။ ၎င်းသည် stochastic gradient descent နှင့် gradient descent နှင့် ဆက်စပ်ပြီး stochastic gradient မှ တွက်ချက်ချိန်ကို ချွေတာခြင်းအယူအဆနှင့် ဆန့်ကျင်နေပါသည်။ ဘာတွေကို ပြုပြင်ပြီး မြှင့်တင်နိုင်မလဲ။ ပထမအကြိမ်တွင် ကျွန်ုပ်တို့သည် ယုံကြည်မှုရှိရှိ ကျဆင်းသွားသည်ကို သတိပြုမိရန် မခဲယဉ်းပေ၊ ထို့ကြောင့် ပထမအကြိမ်တွင် ကြီးမားသောခြေလှမ်းတစ်ခုကို ချန်ထားခဲ့ကာ ကျွန်ုပ်တို့ရှေ့ဆက်သွားသည့်အတိုင်း ခြေလှမ်းကို လျှော့ချသင့်သည်။ ဤဆောင်းပါးတွင် ကျွန်ုပ်တို့ ဤအရာကို မလုပ်ပါ - ရှည်လွန်းနေပြီဖြစ်သည်။ လုပ်ချင်တဲ့သူတွေက ဘယ်လိုလုပ်ရမလဲဆိုတာ မခက်ပါဘူး :)
ယခု စာကြည့်တိုက်ကို အသုံးပြု၍ stochastic gradient ဆင်းသက်မှုကို လုပ်ဆောင်ကြပါစို့ numpy (အရင်က တွေ့ရှိခဲ့တဲ့ ကျောက်တုံးတွေကို မထိမိပါစေနဲ့)
Stochastic Gradient Descent (NumPy) အတွက် ကုဒ်
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
တန်ဖိုးများသည် အသုံးမပြုဘဲ ဆင်းလာသောအခါနှင့် နီးပါးတူပါသည်။ numpy. သို့သော် ဤသည်မှာ ယုတ္တိရှိသည်။
Stochastic gradient ဆင်းသက်ခြင်းများသည် ကျွန်ုပ်တို့ကို မည်မျှကြာအောင်ပြုလုပ်ခဲ့သည်ကို လေ့လာကြည့်ကြပါစို့။
SGD တွက်ချက်ချိန်ကို ဆုံးဖြတ်ရန်အတွက် ကုဒ် (ခြေလှမ်း 80)
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска без использования библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска с использованием библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
တောထဲသို့ပိုဝင်လေလေ တိမ်များပိုမှောင်လေဖြစ်သည်- တစ်ဖန် "ကိုယ်တိုင်ရေးထားသော" ဖော်မြူလာသည် အကောင်းဆုံးရလဒ်ကိုပြသသည်။ ဤအရာအားလုံးသည် စာကြည့်တိုက်ကို အသုံးပြုရန် ပိုမိုသိမ်မွေ့သောနည်းလမ်းများ ရှိသင့်သည်ဟု အကြံပြုထားသည်။ numpyတွက်ချက်မှုလုပ်ငန်းများကို အမှန်တကယ် မြန်ဆန်စေသည်။ ဤဆောင်းပါး၌ ကျွန်ုပ်တို့သည် ၎င်းတို့အကြောင်း လေ့လာမည်မဟုတ်ပါ။ အားလပ်ချိန်တွေမှာ စဉ်းစားစရာတွေရှိမယ် :)
အကျဉ်းချုပ်
အကျဉ်းချုပ်မရေးမီ ကျွန်ုပ်တို့၏ချစ်လှစွာသောစာဖတ်သူထံမှ ဖြစ်နိုင်ခြေအရှိဆုံးမေးခွန်းတစ်ခုကို ကျွန်ုပ်ဖြေကြားလိုပါသည်။ အဘယ်ကြောင့်နည်းဟူမူ- စင်စစ်အားဖြင့် အမျိုးအနွယ်များနှင့် ဤကဲ့သို့ “ညှဉ်းပန်းနှိပ်စက်ခြင်း” သည် အဘယ်ကြောင့်နည်း၊ ကျွန်ုပ်တို့လက်၌ ဤမျှလောက်အစွမ်းထက်ပြီး ရိုးရှင်းသောကိရိယာတစ်ခု ကျွန်ုပ်တို့လက်၌ရှိလျှင် အဖိုးတန်မြေနိမ့်ပိုင်းကို ရှာဖွေရန်အတွက် တောင်ပေါ်အတက်အဆင်း (များအားဖြင့် အဆင်း) လမ်းလျှောက်ရန် လိုအပ်ပါသနည်း။ ခွဲခြမ်းစိတ်ဖြာမှုဖြေရှင်းချက်ပုံစံ၊
ဒီမေးခွန်းရဲ့ အဖြေက မျက်နှာပြင်ပေါ်မှာ ရှိနေပါတယ်။ ယခု ကျွန်ုပ်တို့သည် စစ်မှန်သော အဖြေဖြစ်သည့် အလွန်ရိုးရှင်းသော ဥပမာကို ကြည့်ပါ။  လက္ခဏာတစ်ခုပေါ် မူတည်
လက္ခဏာတစ်ခုပေါ် မူတည်  . ဘဝမှာ ဒါကို မကြာခဏ မမြင်ရတဲ့အတွက် ငါတို့မှာ လက္ခဏာ 2၊ 30၊ 50 သို့မဟုတ် ထို့ထက်မက ရှိနေတယ်လို့ စိတ်ကူးကြည့်ကြပါစို့။ ရည်ညွှန်းချက်တစ်ခုစီအတွက် ထောင်ပေါင်းများစွာ သို့မဟုတ် သောင်းဂဏန်းတန်ဖိုးများကိုပင် ထည့်ကြပါစို့။ ဤကိစ္စတွင်၊ ခွဲခြမ်းစိတ်ဖြာမှုအဖြေသည် စမ်းသပ်မှုကို ခံနိုင်ရည်ရှိပြီး ကျရှုံးမည်မဟုတ်ပေ။ တစ်ဖန်၊ gradient ဆင်းသက်ခြင်းနှင့် ၎င်း၏ကွဲလွဲချက်များသည် ကျွန်ုပ်တို့အား ပန်းတိုင်သို့ တစ်ဖြည်းဖြည်း နီးကပ်လာစေလိမ့်မည် - လုပ်ဆောင်ချက်၏ အနိမ့်ဆုံးဖြစ်သည်။ မြန်နှုန်းအတွက် စိတ်မပူပါနှင့် - ခြေလှမ်းအရှည် (အမြန်နှုန်း) ကို သတ်မှတ်၍ ထိန်းညှိနိုင်စေမည့် နည်းလမ်းများကို ကြည့်ရှုနိုင်ပါမည်။
. ဘဝမှာ ဒါကို မကြာခဏ မမြင်ရတဲ့အတွက် ငါတို့မှာ လက္ခဏာ 2၊ 30၊ 50 သို့မဟုတ် ထို့ထက်မက ရှိနေတယ်လို့ စိတ်ကူးကြည့်ကြပါစို့။ ရည်ညွှန်းချက်တစ်ခုစီအတွက် ထောင်ပေါင်းများစွာ သို့မဟုတ် သောင်းဂဏန်းတန်ဖိုးများကိုပင် ထည့်ကြပါစို့။ ဤကိစ္စတွင်၊ ခွဲခြမ်းစိတ်ဖြာမှုအဖြေသည် စမ်းသပ်မှုကို ခံနိုင်ရည်ရှိပြီး ကျရှုံးမည်မဟုတ်ပေ။ တစ်ဖန်၊ gradient ဆင်းသက်ခြင်းနှင့် ၎င်း၏ကွဲလွဲချက်များသည် ကျွန်ုပ်တို့အား ပန်းတိုင်သို့ တစ်ဖြည်းဖြည်း နီးကပ်လာစေလိမ့်မည် - လုပ်ဆောင်ချက်၏ အနိမ့်ဆုံးဖြစ်သည်။ မြန်နှုန်းအတွက် စိတ်မပူပါနှင့် - ခြေလှမ်းအရှည် (အမြန်နှုန်း) ကို သတ်မှတ်၍ ထိန်းညှိနိုင်စေမည့် နည်းလမ်းများကို ကြည့်ရှုနိုင်ပါမည်။
ယခုလည်း တကယ့်အကျဉ်းချုပ်။
ပထမဦးစွာ၊ ဆောင်းပါးတွင်တင်ပြထားသောအကြောင်းအရာသည် ရိုးရှင်းသော (သာမက) မျဉ်းကြောင်းဆုတ်ယုတ်မှုညီမျှခြင်းများကို မည်သို့ဖြေရှင်းရမည်ကို နားလည်ရန် "ဒေတာသိပ္ပံပညာရှင်များ" ကိုအစပြုရန် ကူညီပေးလိမ့်မည်ဟု မျှော်လင့်ပါသည်။
ဒုတိယ၊ ကျွန်ုပ်တို့သည် ညီမျှခြင်းအား ဖြေရှင်းရန် နည်းလမ်းများစွာကို ကြည့်ရှုခဲ့သည်။ အခုအခြေအနေပေါ်မူတည်ပြီး ပြဿနာဖြေရှင်းဖို့ အသင့်တော်ဆုံးကို ရွေးချယ်နိုင်ပါပြီ။
တတိယ၊ ထပ်ဆင့်ဆက်တင်များ၏ ပါဝါကို ကျွန်ုပ်တို့တွေ့မြင်ခဲ့သည်၊ အနက်ရောင်အဆင့် ဆင်းသက်ခြင်း ခြေလှမ်းအရှည်။ ဤသတ်မှတ်ချက်ကို လျစ်လျူရှု၍မရပါ။ အထက်တွင်ဖော်ပြခဲ့သည့်အတိုင်း တွက်ချက်မှုကုန်ကျစရိတ်ကို လျှော့ချရန်အတွက် ဆင်းသက်စဉ်အတွင်း အဆင့်အရှည်ကို ပြောင်းလဲသင့်သည်။
စတုတ္ထအချက်အနေဖြင့်၊ ကျွန်ုပ်တို့၏အခြေအနေတွင်၊ "ကိုယ်တိုင်ရေးထားသော" လုပ်ဆောင်ချက်များသည် တွက်ချက်မှုများအတွက် အကောင်းဆုံးအချိန်ရလဒ်များကို ပြသခဲ့သည်။ ဤသည်မှာ စာကြည့်တိုက်၏ စွမ်းဆောင်နိုင်ရည်များကို ပရော်ဖက်ရှင်နယ်အသုံးအများဆုံးမဟုတ်ခြင်းကြောင့် ဖြစ်နိုင်သည်။ numpy. ဒါပေမယ့် ဖြစ်နိုင်ရင် အောက်ပါ နိဂုံးက သူ့ဟာသူ အကြံပြုပါတယ်။ တစ်ဖက်တွင်၊ တစ်ခါတစ်ရံတွင် ခိုင်လုံသောထင်မြင်ယူဆချက်များကို မေးခွန်းထုတ်ရကျိုးနပ်ပြီး အခြားတစ်ဖက်တွင်မူ အရာအားလုံးကို ရှုပ်ထွေးစေမည့် အမြဲတမ်းမထိုက်တန်ပါ - ဆန့်ကျင်ဘက်အနေနှင့် တစ်ခါတစ်ရံတွင် ပြဿနာတစ်ခုကို ဖြေရှင်းရာတွင် ပိုမိုရိုးရှင်းသောနည်းလမ်းက ပို၍ထိရောက်ပါသည်။ ကျွန်ုပ်တို့၏ပန်းတိုင်သည် ရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှုညီမျှခြင်းအား ဖြေရှင်းရန် ချဉ်းကပ်မှုသုံးခုကိုခွဲခြမ်းစိတ်ဖြာရန်ဖြစ်သောကြောင့်၊ "ကိုယ်တိုင်ရေးထားသော" လုပ်ဆောင်ချက်များကို အသုံးပြုခြင်းသည် ကျွန်ုပ်တို့အတွက် လုံလောက်ပါသည်။
စာပေ (ဒါမှမဟုတ်)
1. Linear ဆုတ်ယုတ်မှု
2. အနည်းဆုံး နှစ်ထပ်နည်းလမ်း
3. ဆင်းသက်လာသည်။
၂၀
5. Gradient မျိုးနွယ်
6. NumPy စာကြည့်တိုက်
source: www.habr.com
