

Het is waarschijnlijk geen geheim dat vorig jaar een jaar van grote veranderingen was voor Apache Hadoop. Vorig jaar fuseerden Cloudera en Hortonworks (in wezen de overname van laatstgenoemde) en werd Mapr vanwege ernstige financiële problemen verkocht aan Hewlett Packard. En moest een paar jaar eerder bij installaties op locatie vaak de keuze worden gemaakt tussen Cloudera en Hortonworks, vandaag de dag hebben we deze keuze helaas niet meer. Een andere verrassing was het feit dat Cloudera in februari van dit jaar aankondigde dat het zou stoppen met het vrijgeven van binaire assemblages van zijn distributie in de openbare repository, en dat ze nu alleen beschikbaar zijn via een betaald abonnement. Het is uiteraard nog steeds mogelijk om de nieuwste versies van CDH en HDP te downloaden die vóór eind 2019 zijn uitgebracht, en ondersteuning hiervoor wordt gedurende één tot twee jaar verwacht. Maar wat nu? Voor degenen die eerder voor een abonnement betaalden, is er niets veranderd. En voor degenen die niet willen overstappen naar de betaalde versie van de distributie, maar tegelijkertijd de nieuwste versies van clustercomponenten willen ontvangen, evenals patches en andere updates, hebben we dit artikel opgesteld. Daarin zullen we mogelijke opties overwegen om uit deze situatie te komen.
Het artikel is meer een recensie. Het zal geen vergelijking van distributies en een gedetailleerde analyse ervan bevatten, en er zullen geen recepten zijn voor het installeren en configureren ervan. Wat zal er gebeuren? We zullen het kort hebben over een dergelijke distributie als Arenadata Hadoop, die terecht onze aandacht verdient vanwege de beschikbaarheid ervan, wat tegenwoordig zeer zeldzaam is. En dan zullen we het hebben over Vanilla Hadoop, vooral over hoe het kan worden “gekookt” met Apache Bigtop. Klaar? Welkom bij cat.
Arenadata Hadoop

Dit is een volledig nieuw en tot nu toe weinig bekend distributiepakket voor binnenlandse ontwikkeling. Helaas is er op dit moment alleen Habré .
Meer informatie vindt u op de ambtenaar project. De nieuwste versies van de distributie zijn gebaseerd op Hadoop 3.1.2 voor versie 3 en 2.8.5 voor versie 2.
Informatie over de routekaart is te vinden .
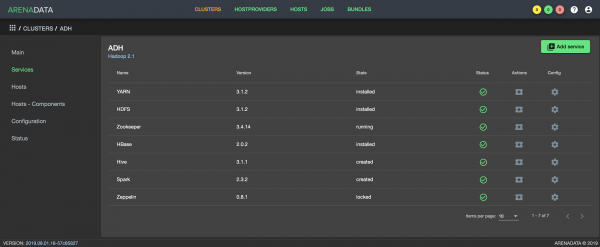
Arenadata Cluster Manager-interface
Het kernproduct van Arenadata is , dat wordt gebruikt voor het installeren, configureren en monitoren van verschillende bedrijfssoftwareoplossingen. ADCM wordt gratis verspreid en de functionaliteit ervan wordt uitgebreid door bundels toe te voegen, dit zijn een reeks weerweerbare speelboeken. Bundels zijn onderverdeeld in twee typen: onderneming en community. Deze laatste kunnen gratis worden gedownload van de Arenadata-website. Het is ook mogelijk om een eigen bundel te ontwikkelen en deze aan ADCM te koppelen.
Voor de implementatie en het beheer van Hadoop 3 wordt een communityversie van de bundel aangeboden in combinatie met ADCM, maar voor Hadoop 2 is er alleen als een alternatief. Wat repositories met pakketten betreft, deze zijn open voor publieke toegang en kunnen op de gebruikelijke manier worden gedownload en geïnstalleerd voor alle componenten van het cluster. Over het algemeen ziet de distributie er erg interessant uit. Ik weet zeker dat er mensen zullen zijn die gewend zijn aan oplossingen zoals Cloudera Manager en Ambari, en die ADCM zelf leuk zullen vinden. Voor sommigen zal het ook een groot pluspunt zijn dan de distributie voor importsubstitutie.
Als we het over de nadelen hebben, zullen deze hetzelfde zijn als voor alle andere Hadoop-distributies. Namelijk:
- De zogenaamde ‘vendor lock-in’. Aan de hand van de voorbeelden van Cloudera en Hortonworks hebben we ons al gerealiseerd dat er altijd een risico bestaat dat het bedrijfsbeleid verandert.
- Aanzienlijke achterstand op Apache stroomopwaarts.
Vanille Hadoop

Zoals u weet is Hadoop geen monolithisch product, maar in feite een hele reeks services rond het gedistribueerde bestandssysteem HDFS. Weinig mensen zullen genoeg hebben van één bestandscluster. Sommigen hebben Hive nodig, anderen Presto, en dan zijn er HBase en Phoenix; Spark wordt steeds vaker gebruikt. Voor orkestratie en het laden van gegevens worden soms Oozie, Sqoop en Flume gevonden. En als het beveiligingsprobleem zich voordoet, denk ik onmiddellijk aan Kerberos in combinatie met Ranger.
Binaire versies van Hadoop-componenten zijn beschikbaar op de website van elk van de ecosysteemprojecten in de vorm van tarballs. U kunt ze downloaden en met de installatie beginnen, maar met één voorwaarde: naast het zelfstandig samenstellen van pakketten uit "onbewerkte" binaire bestanden, wat u waarschijnlijk wilt doen, zult u geen enkel vertrouwen hebben in de compatibiliteit van de gedownloade versies van componenten met elk ander. De voorkeursoptie is om te bouwen met Apache Bigtop. Met Bigtop kun je bouwen vanuit Apache Maven-repository's, tests uitvoeren en pakketten bouwen. Maar wat voor ons heel belangrijk is, is dat Bigtop die versies van componenten zal samenstellen die met elkaar compatibel zijn. We zullen er hieronder meer in detail over praten.
Apache Bigtop

Apache Bigtop is een tool voor het bouwen, verpakken en testen van een aantal
open source-projecten, zoals Hadoop en Greenplum. Bigtop heeft er genoeg
releases. Op het moment van schrijven was de nieuwste stabiele release versie 1.4,
en in de master was er 1.5. Verschillende versies van releases gebruiken verschillende versies
componenten. Voor 1.4 hebben Hadoop-kerncomponenten bijvoorbeeld versie 2.8.5 en in master
2.10.0. Ook de samenstelling van ondersteunde componenten verandert. Iets verouderd en
het niet-hernieuwbare verdwijnt, en in de plaats komt iets nieuws, waar meer vraag naar is
het is niet noodzakelijkerwijs iets van de Apache-familie zelf.
Bovendien heeft Bigtop er veel .
Toen we Bigtop begonnen te leren kennen, waren we in de eerste plaats verrast door de bescheiden omvang en populariteit ervan, in vergelijking met andere Apache-projecten, en door de zeer kleine gemeenschap. Hieruit volgt dat er minimale informatie over het product is en dat het zoeken naar oplossingen voor problemen die zich op forums en mailinglijsten hebben voorgedaan, misschien helemaal niets oplevert. In eerste instantie bleek het voor ons een moeilijke taak om de volledige montage van de distributie te voltooien vanwege de kenmerken van de tool zelf, maar we zullen hier later over praten.
Als voorproefje voor degenen die destijds in dergelijke projecten geïnteresseerd waren. Linux-universe, net als Gentoo en LFS, kan het nostalgisch prettig aanvoelen om hiermee te werken en terug te denken aan die "epische" tijden waarin we zelf ebuilds zochten (en zelfs schreven) en Mozilla regelmatig opnieuw compileerden met nieuwe patches.
Een groot voordeel van Bigtop is de openheid en veelzijdigheid van de tools waarop het is gebaseerd. Het is gebouwd op Gradle en Apache Maven. Gradle staat bekend als Google's favoriete tool voor het bouwen van applicaties. AndroidHet is flexibel en, zoals ze zeggen, "door de wol geverfd". Maven is Apache's eigen tool voor het bouwen van projecten, en aangezien de meeste producten via Maven worden uitgebracht, kon het hier ook niet ontbreken. Het is de moeite waard om aandacht te besteden aan het POM (Project Object Model) – het "fundamentele" XML-bestand dat alles beschrijft wat Maven nodig heeft om met je project te werken, en waarop alle werkzaamheden zijn gebaseerd. Het bevindt zich in
delen van Maven en er zijn enkele obstakels die nieuwe Bigtop-gebruikers gewoonlijk tegenkomen.
Praktijk
Dus waar moet je beginnen? Ga naar de downloadpagina en download de nieuwste stabiele versie als archief. Je kunt daar ook binaire artefacten vinden die door Bigtop zijn verzameld. Trouwens, onder de gebruikelijke pakketbeheerders worden YUM en APT ondersteund.
Als alternatief kunt u de nieuwste stabiele release rechtstreeks downloaden van
github:
$ git clone --branch branch-1.4 https://github.com/apache/bigtop.gitKlonen in “bigtop”…
remote: Enumerating objects: 46, done.
remote: Counting objects: 100% (46/46), done.
remote: Compressing objects: 100% (41/41), done.
remote: Total 40217 (delta 14), reused 10 (delta 1), pack-reused 40171
Получение объектов: 100% (40217/40217), 43.54 MiB | 1.05 MiB/s, готово.
Определение изменений: 100% (20503/20503), готово.
Updating files: 100% (1998/1998), готово.De resulterende map ./bigtop ziet er ongeveer zo uit:
./bigtop-bigpetstore — demotoepassingen, synthetische voorbeelden
./bigtop-ci — CI-toolkit, jenkins
./bigtop-data-generators — gegevensgeneratie, synthetische stoffen, voor rooktests, enz.
./bigtop-deploy - implementatietools
./bigtop-packages — configuraties, scripts, patches voor assemblage, het grootste deel van de tool
./bigtop-test-framework — testkader
./bigtop-tests — de tests zelf, belasting en rook
./bigtop_toolchain — omgeving voor montage, voorbereiding van de omgeving voor de werking van het gereedschap
./build — werkmap bouwen
./dl — directory voor gedownloade bronnen
./docker — docker-images inbouwen, testen
./gradle - geleidelijke configuratie
./output – de map waar build-artefacten naartoe gaan
./provisioner - Bevoorrading
Het meest interessante voor ons in dit stadium is de hoofdconfiguratie ./bigtop/bigtop.bom, waarin we alle ondersteunde componenten met versies zien. Hier kunnen we een andere versie van het product specificeren (als we het plotseling willen proberen te bouwen) of een buildversie (als we bijvoorbeeld een belangrijke patch hebben toegevoegd).
De submap is ook van groot belang ./bigtop/bigtop-packages, wat rechtstreeks verband houdt met het proces van het assembleren van componenten en pakketten ermee.
Dus we hebben het archief gedownload, uitgepakt of een kloon van github gemaakt. Kunnen we beginnen met bouwen?
Nee, laten we eerst de omgeving voorbereiden.
De omgeving voorbereiden
En hier hebben we een kleine retraite nodig. Om bijna elk min of meer complex product te bouwen, is een bepaalde omgeving vereist - in ons geval is dit de JDK, dezelfde gedeelde bibliotheken, headerbestanden, enz., tools zoals ant, ivy2 en nog veel meer. Een van de opties om de omgeving te krijgen die u nodig heeft voor Bigtop is door de benodigde componenten op de buildhost te installeren. Ik kan het mis hebben in de chronologie, maar het lijkt erop dat er met versie 1.0 ook een optie was om vooraf geconfigureerde en toegankelijke Docker-images in te bouwen, die hier te vinden zijn.
Wat het voorbereiden van de omgeving betreft, is er een assistent hiervoor: Puppet.
U kunt de volgende opdrachten gebruiken, uitgevoerd vanuit de hoofdmap
hulpmiddel, ./bigtop:
./gradlew toolchain
./gradlew toolchain-devtools
./gradlew toolchain-puppetmodules
Of rechtstreeks via pop:
puppet apply --modulepath=<path_to_bigtop> -e "include bigtop_toolchain::installer"
puppet apply --modulepath=<path_to_bigtop> -e "include bigtop_toolchain::deployment-tools"
puppet apply --modulepath=<path_to_bigtop> -e "include bigtop_toolchain::development-tools"Helaas kunnen zich in dit stadium al problemen voordoen. Het algemene advies hier is om een ondersteunde distributie te gebruiken, up-to-date op de build-host, of de docker-route te proberen.
montage
Wat kunnen we proberen te verzamelen? Het antwoord op deze vraag wordt gegeven door de uitvoer van het commando
./gradlew tasks In de sectie Pakkettaken vindt u een aantal producten die laatste artefacten van Bigtop zijn.
Ze zijn te herkennen aan het achtervoegsel -rpm of -pkg-ind (in het geval van build
in havenarbeider). In ons geval is Hadoop het meest interessant.
Laten we proberen de omgeving van onze buildserver in te bouwen:
./gradlew hadoop-rpmBigtop zal zelf de benodigde bronnen downloaden die nodig zijn voor een specifiek onderdeel en beginnen met de montage. De werking van de tool is dus afhankelijk van Maven-repository's en andere bronnen, dat wil zeggen dat er internettoegang voor nodig is.
Tijdens bedrijf wordt standaarduitvoer gegenereerd. Soms kunnen deze en foutmeldingen u helpen begrijpen wat er mis is gegaan. En soms heb je aanvullende informatie nodig. In dit geval is het de moeite waard om argumenten toe te voegen --info of --debugen kan ook nuttig zijn –stacktrace. Er is een handige manier om een dataset te genereren voor latere toegang tot mailinglijsten, de sleutel --scan.
Met zijn hulp zal bigtop alle informatie verzamelen en in gradle plaatsen, waarna het een link zal verstrekken,
Door dit te volgen, zal een competent persoon kunnen begrijpen waarom de montage mislukte.
Houd er rekening mee dat deze optie informatie kan vrijgeven die u niet wilt, zoals gebruikersnamen, knooppunten, omgevingsvariabelen, enz., dus wees voorzichtig.
Vaak zijn fouten een gevolg van het onvermogen om onderdelen te verkrijgen die nodig zijn voor de montage. Normaal gesproken kunt u het probleem oplossen door een patch te maken om iets in de bronnen te repareren, bijvoorbeeld adressen in pom.xml in de hoofdmap van de bronnen. Dit wordt gedaan door het te maken en in de juiste map te plaatsen ./bigtop/bigtop-packages/src/common/oozie/ patch, bijvoorbeeld in de vorm patch2-fix.diff.
--- a/pom.xml
+++ b/pom.xml
@@ -136,7 +136,7 @@
<repositories>
<repository>
<id>central</id>
- <url>http://repo1.maven.org/maven2</url>
+ <url>https://repo1.maven.org/maven2</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
Hoogstwaarschijnlijk hoeft u op het moment dat u dit artikel leest, de bovenstaande oplossing niet zelf uit te voeren.
Wanneer u patches en wijzigingen aan het assemblagemechanisme introduceert, moet u mogelijk de assemblage “resetten” met behulp van de opdracht opruimen:
./gradlew hadoop-clean
> Task :hadoop_vardefines
> Task :hadoop-clean
BUILD SUCCESSFUL in 5s
2 actionable tasks: 2 executedMet deze bewerking worden alle wijzigingen aan de assemblage van dit onderdeel ongedaan gemaakt, waarna de assemblage opnieuw wordt uitgevoerd. Deze keer proberen we het project in een docker-image te bouwen:
./gradlew -POS=centos-7 -Pprefix=1.2.1 hadoop-pkg-ind
> Task :hadoop-pkg-ind
Building 1.2.1 hadoop-pkg on centos-7 in Docker...
+++ dirname ./bigtop-ci/build.sh
++ cd ./bigtop-ci/..
++ pwd
+ BIGTOP_HOME=/tmp/bigtop
+ '[' 6 -eq 0 ']'
+ [[ 6 -gt 0 ]]
+ key=--prefix
+ case $key in
+ PREFIX=1.2.1
+ shift
+ shift
+ [[ 4 -gt 0 ]]
+ key=--os
+ case $key in
+ OS=centos-7
+ shift
+ shift
+ [[ 2 -gt 0 ]]
+ key=--target
+ case $key in
+ TARGET=hadoop-pkg
+ shift
+ shift
+ [[ 0 -gt 0 ]]
+ '[' -z x ']'
+ '[' -z x ']'
+ '[' '' == true ']'
+ IMAGE_NAME=bigtop/slaves:1.2.1-centos-7
++ uname -m
+ ARCH=x86_64
+ '[' x86_64 '!=' x86_64 ']'
++ docker run -d bigtop/slaves:1.2.1-centos-7 /sbin/init
+
CONTAINER_ID=0ce5ac5ca955b822a3e6c5eb3f477f0a152cd27d5487680f77e33fbe66b5bed8
+ trap 'docker rm -f
0ce5ac5ca955b822a3e6c5eb3f477f0a152cd27d5487680f77e33fbe66b5bed8' EXIT
....
много вывода
....
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-hdfs-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-yarn-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-mapreduce-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-hdfs-namenode-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-hdfs-secondarynamenode-2.8.5-
1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-hdfs-zkfc-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-hdfs-journalnode-2.8.5-
1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-hdfs-datanode-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-httpfs-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-yarn-resourcemanager-2.8.5-
1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-yarn-nodemanager-2.8.5-
1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-yarn-proxyserver-2.8.5-
1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-yarn-timelineserver-2.8.5-
1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-mapreduce-historyserver-2.8.5-
1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-client-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-conf-pseudo-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-doc-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-libhdfs-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-libhdfs-devel-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-hdfs-fuse-2.8.5-1.el7.x86_64.rpm
Wrote: /bigtop/build/hadoop/rpm/RPMS/x86_64/hadoop-debuginfo-2.8.5-1.el7.x86_64.rpm
+ umask 022
+ cd /bigtop/build/hadoop/rpm//BUILD
+ cd hadoop-2.8.5-src
+ /usr/bin/rm -rf /bigtop/build/hadoop/rpm/BUILDROOT/hadoop-2.8.5-1.el7.x86_64
Executing(%clean): /bin/sh -e /var/tmp/rpm-tmp.uQ2FCn
+ exit 0
+ umask 022
Executing(--clean): /bin/sh -e /var/tmp/rpm-tmp.CwDb22
+ cd /bigtop/build/hadoop/rpm//BUILD
+ rm -rf hadoop-2.8.5-src
+ exit 0
[ant:touch] Creating /bigtop/build/hadoop/.rpm
:hadoop-rpm (Thread[Task worker for ':',5,main]) completed. Took 38 mins 1.151 secs.
:hadoop-pkg (Thread[Task worker for ':',5,main]) started.
> Task :hadoop-pkg
Task ':hadoop-pkg' is not up-to-date because:
Task has not declared any outputs despite executing actions.
:hadoop-pkg (Thread[Task worker for ':',5,main]) completed. Took 0.0 secs.
BUILD SUCCESSFUL in 40m 37s
6 actionable tasks: 6 executed
+ RESULT=0
+ mkdir -p output
+ docker cp
ac46014fd9501bdc86b6c67d08789fbdc6ee46a2645550ff6b6712f7d02ffebb:/bigtop/build .
+ docker cp
ac46014fd9501bdc86b6c67d08789fbdc6ee46a2645550ff6b6712f7d02ffebb:/bigtop/output .
+ docker rm -f ac46014fd9501bdc86b6c67d08789fbdc6ee46a2645550ff6b6712f7d02ffebb
ac46014fd9501bdc86b6c67d08789fbdc6ee46a2645550ff6b6712f7d02ffebb
+ '[' 0 -ne 0 ']'
+ docker rm -f ac46014fd9501bdc86b6c67d08789fbdc6ee46a2645550ff6b6712f7d02ffebb
Error: No such container:
ac46014fd9501bdc86b6c67d08789fbdc6ee46a2645550ff6b6712f7d02ffebb
BUILD SUCCESSFUL in 41m 24s
1 actionable task: 1 executedDe assemblage werd uitgevoerd onder CentOSmaar het kan ook onder Ubuntu:
./gradlew -POS=ubuntu-16.04 -Pprefix=1.2.1 hadoop-pkg-indNaast het samenstellen van pakketten voor diverse distributies LinuxDe tool kan bijvoorbeeld een repository met gecompileerde pakketten aanmaken:
./gradlew yumU kunt zich ook herinneren aan rooktests en implementatie in Docker.
Maak een cluster van drie knooppunten:
./gradlew -Pnum_instances=3 docker-provisionerVoer rooktests uit in een cluster van drie knooppunten:
./gradlew -Pnum_instances=3 -Prun_smoke_tests docker-provisionerEen cluster verwijderen:
./gradlew docker-provisioner-destroyKrijg opdrachten voor het verbinden binnen docker-containers:
./gradlew docker-provisioner-sshToon status:
./gradlew docker-provisioner-statusU kunt meer lezen over implementatietaken in de documentatie.
Als we het over tests hebben, zijn er vrij veel, voornamelijk rook en integratie. Hun analyse valt buiten het bestek van dit artikel. Laat ik zeggen dat het samenstellen van een distributiekit niet zo moeilijk is als het op het eerste gezicht lijkt. We zijn erin geslaagd alle componenten die we in onze productie gebruiken te assembleren en te testen, en we hadden ook geen problemen met de implementatie ervan en het uitvoeren van basisbewerkingen in de testomgeving.
Naast de bestaande componenten in Bigtop is het mogelijk om van alles toe te voegen, zelfs uw eigen softwareontwikkeling. Dit alles is perfect geautomatiseerd en past in het CI/CD concept.
Conclusie
Het is duidelijk dat de op deze manier samengestelde distributie niet onmiddellijk naar productie moet worden gestuurd. U moet begrijpen dat als er een echte behoefte is om uw distributie op te bouwen en te ondersteunen, u hierin geld en tijd moet investeren.
In combinatie met de juiste aanpak en een professioneel team kan het echter heel goed zonder commerciële oplossingen.
Het is belangrijk op te merken dat het Bigtop-project zelf ontwikkeling behoeft en momenteel niet actief lijkt te worden ontwikkeld. Het vooruitzicht dat Hadoop 3 erin zal verschijnen is ook onduidelijk. Als je trouwens echt behoefte hebt om Hadoop 3 te bouwen, kun je kijken naar van Arenadata, waarin naast standaard
Er zijn een aantal extra componenten (Ranger, Knox, NiFi).
Wat Rostelecom betreft, voor ons is Bigtop een van de opties die momenteel worden overwogen. Of we er nu voor kiezen of niet, de tijd zal het leren.
Bijlage
Om een nieuwe component in de assembly op te nemen, moet u de beschrijving ervan toevoegen aan bigtop.bom en ./bigtop-packages. Je kunt dit proberen naar analogie met de bestaande componenten. Probeer het uit te zoeken. Het is niet zo moeilijk als het op het eerste gezicht lijkt.
Wat denk je? We zien graag uw mening in de reacties en danken u voor uw aandacht!
Het artikel is opgesteld door het datamanagementteam van Rostelecom
Bron: www.habr.com
