


Dag Allemaal. Ik werk als leidend systeembeheerder bij OK en ben verantwoordelijk voor de stabiele werking van het portaal. Ik wil het hebben over hoe we een proces hebben gebouwd voor het automatisch vervangen van schijven, en hoe we vervolgens de beheerder van dit proces hebben uitgesloten en hem hebben vervangen door een bot.
Dit artikel is een soort transliteratie op HighLoad+ 2018
Een proces bouwen voor het vervangen van schijven
Eerst wat cijfers
OK is een gigantische dienst die door miljoenen mensen wordt gebruikt. Het wordt bediend door ongeveer 7 servers, die zich in 4 verschillende datacenters bevinden. De servers bevatten meer dan 70 schijven. Als je ze op elkaar stapelt, krijg je een toren van meer dan 1 km hoog.
Harde schijven zijn het serveronderdeel dat het vaakst faalt. Met dergelijke volumes moeten we ongeveer 30 schijven per week vervangen, en deze procedure is een niet erg prettige routine geworden.

Incidenten
Ons bedrijf heeft volwaardig incidentmanagement ingevoerd. We registreren elk incident in Jira en lossen het vervolgens op. Als een incident effect heeft gehad op gebruikers, dan komen we zeker samen om na te denken over hoe we in dergelijke gevallen sneller kunnen reageren, hoe we het effect kunnen verminderen en uiteraard hoe we herhaling kunnen voorkomen.
Opslagapparaten vormen hierop geen uitzondering. Hun status wordt gecontroleerd door Zabbix. We monitoren berichten in Syslog op schrijf-/leesfouten, analyseren de status van HW/SW-raids, monitoren SMART en berekenen slijtage voor SSD's.
Hoe schijven voorheen werden vervangen
Wanneer er een trigger optreedt in Zabbix, wordt er een incident aangemaakt in Jira en automatisch toegewezen aan de juiste engineers in de datacenters. We doen dit bij alle HW-incidenten, dat wil zeggen bij incidenten waarbij fysiek werk met apparatuur in het datacenter nodig is.
Een datacenteringenieur is een persoon die problemen met hardware oplost en verantwoordelijk is voor het installeren, onderhouden en ontmantelen van servers. Nadat hij het ticket heeft ontvangen, gaat de ingenieur aan de slag. In schijfplanken verwisselt hij zelfstandig schijven. Maar als hij geen toegang heeft tot het benodigde apparaat, wendt de monteur zich tot de dienstdoende systeembeheerders voor hulp. Allereerst moet u de schijf uit de rotatie halen. Om dit te doen, moet u de nodige wijzigingen aanbrengen op de server, toepassingen stoppen en de schijf ontkoppelen.
De dienstdoende systeembeheerder is tijdens de dienst verantwoordelijk voor de werking van het gehele portaal. Hij onderzoekt incidenten, voert reparaties uit en helpt ontwikkelaars met het voltooien van kleine taken. Hij houdt zich niet alleen bezig met harde schijven.
Voorheen communiceerden datacenteringenieurs via chat met de systeembeheerder. Ingenieurs stuurden links naar Jira-tickets, de beheerder volgde ze en hield een logboek bij van het werk in een notitieblok. Maar chats zijn voor dergelijke taken lastig: de informatie is daar niet gestructureerd en gaat snel verloren. En de beheerder kon gewoon weglopen van de computer en een tijdje niet reageren op verzoeken, terwijl de ingenieur met een stapel schijven bij de server stond en wachtte.
Maar het ergste was dat de beheerders niet het hele plaatje zagen: welke schijfincidenten bestonden er, waar kon zich mogelijk een probleem voordoen. Dit komt doordat we alle HW-incidenten delegeren aan engineers. Ja, het was mogelijk om alle incidenten op het beheerdersdashboard weer te geven. Maar het zijn er veel, en slechts bij een aantal daarvan was de beheerder betrokken.
Bovendien kon de engineer de prioriteiten niet correct stellen, omdat hij niets weet over het doel van specifieke servers of de verdeling van informatie over schijven.
Nieuwe vervangingsprocedure
Het eerste wat we deden was alle schijfincidenten naar een apart type “HW-schijf” verplaatsen en de velden “blokapparaatnaam”, “grootte” en “schijftype” eraan toevoegen, zodat deze informatie in het ticket zou worden opgeslagen en niet voortdurend hoeven te wisselen in de chat.
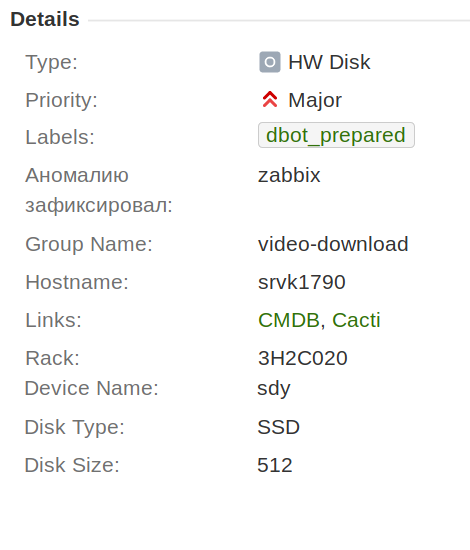
We spraken ook af dat we per incident slechts één schijf zouden vervangen. Dit vereenvoudigde het automatiseringsproces, het verzamelen van statistieken en het werk in de toekomst aanzienlijk.
Daarnaast hebben we het veld “verantwoordelijke beheerder” toegevoegd. De dienstdoende systeembeheerder wordt daar automatisch ingevoegd. Dit is erg handig, omdat de monteur nu altijd ziet wie verantwoordelijk is. U hoeft niet naar de kalender te gaan en te zoeken. Het was dit veld dat het mogelijk maakte om tickets op het dashboard van de beheerder weer te geven waarvoor mogelijk zijn hulp nodig was.
Om ervoor te zorgen dat alle deelnemers maximaal konden profiteren van innovaties, hebben we filters en dashboards gemaakt en de jongens hierover geïnformeerd. Wanneer mensen veranderingen begrijpen, distantiëren ze zich er niet van als iets onnodigs. Het is belangrijk dat een technicus het racknummer weet waar de server zich bevindt, de grootte en het type schijf. De beheerder moet allereerst begrijpen wat voor soort groep servers dit is en wat het effect kan zijn bij het vervangen van een schijf.
De aanwezigheid van velden en hun weergave is handig, maar het heeft ons niet gered van de noodzaak om chats te gebruiken. Om dit te doen, moesten we de workflow veranderen.
Vroeger was het zo:
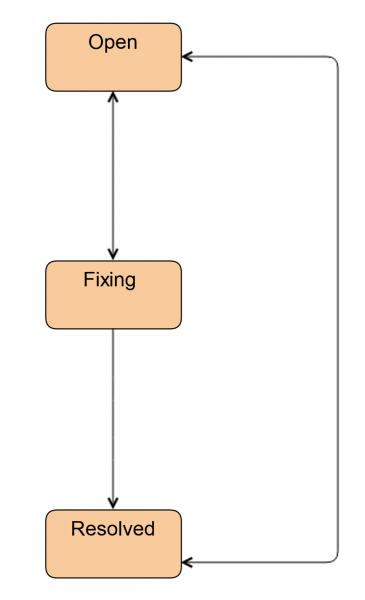
Dit is de manier waarop ingenieurs vandaag de dag blijven werken als ze geen beheerdershulp nodig hebben.
Het eerste wat we deden was een nieuwe status introduceren Onderzoeken. Het ticket heeft deze status als de engineer nog niet heeft besloten of hij een beheerder nodig heeft of niet. Via deze status kan de monteur het ticket overdragen aan de beheerder. Daarnaast gebruiken wij deze status om tickets te markeren wanneer een schijf vervangen moet worden, maar de schijf zelf niet ter plaatse is. Dit gebeurt in het geval van CDN's en externe sites.
We hebben ook status toegevoegd Kant en klaar. Het ticket wordt ernaar overgezet nadat de schijf is vervangen. Dat wil zeggen, alles is al gedaan, maar de HW/SW RAID is gesynchroniseerd op de server. Dit kan behoorlijk lang duren.
Als er een beheerder bij de werkzaamheden betrokken is, wordt de regeling iets ingewikkelder.
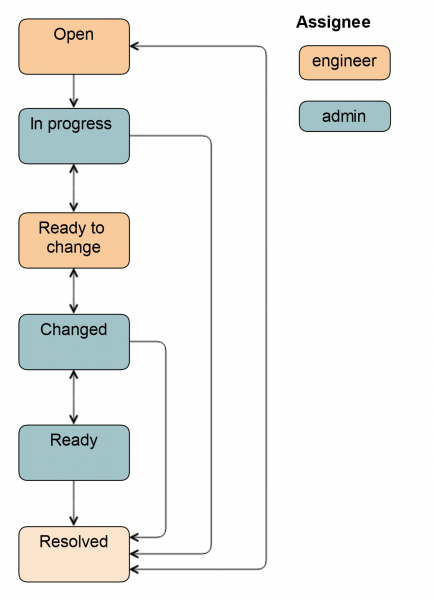
Van status Open Het ticket kan zowel door de systeembeheerder als door de engineer worden vertaald. In status aan de gang de beheerder haalt de schijf uit de rotatie zodat de ingenieur hem er eenvoudig uit kan trekken: zet de achtergrondverlichting aan, ontkoppelt de schijf, stopt applicaties, afhankelijk van de specifieke groep servers.
Het ticket wordt vervolgens overgedragen naar Klaar om te veranderen: Dit is een signaal voor de monteur dat de schijf eruit kan worden getrokken. Alle velden in Jira zijn al ingevuld, de engineer weet welk type en grootte van de schijf. Deze gegevens worden automatisch ingevoerd op basis van de vorige status of door de beheerder.
Na het vervangen van de schijf wordt de ticketstatus gewijzigd in Veranderd. Het controleert of de juiste schijf is geplaatst, het partitioneren is voltooid, de applicatie is gestart en er zijn enkele gegevenshersteltaken gestart. Het ticket kan ook worden overgezet naar de status Kant en klaar, in dit geval blijft de beheerder verantwoordelijk, omdat hij de schijf in rotatie heeft gebracht. Het volledige diagram ziet er als volgt uit.
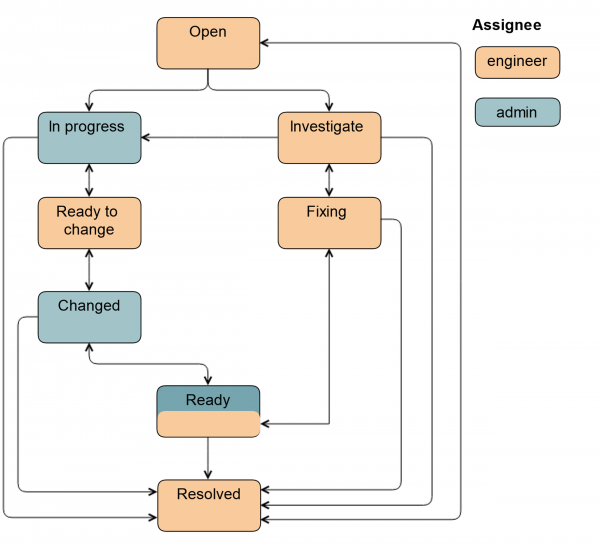
Het toevoegen van nieuwe velden heeft ons leven veel eenvoudiger gemaakt. De jongens begonnen met gestructureerde informatie te werken, het werd duidelijk wat er moest gebeuren en in welk stadium. Prioriteiten zijn veel relevanter geworden, omdat ze nu door de beheerder worden vastgesteld.
Chatten is niet nodig. De beheerder kan uiteraard naar de monteur schrijven “dit moet sneller vervangen worden” of “het is al avond, heb je tijd om dit te vervangen?” Maar we communiceren niet meer dagelijks in chats over deze kwesties.
Schijven werden in batches vervangen. Als de beheerder iets eerder naar zijn werk is gekomen, hij vrije tijd heeft en er nog niets is gebeurd, kan hij een aantal servers voorbereiden op vervanging: vul de velden in, verwijder de schijven uit de rotatie en draag de taak over aan een ingenieur. De engineer komt even later naar het datacenter, ziet de opgave, haalt de benodigde schijven uit het magazijn en vervangt deze direct. Als gevolg daarvan is het vervangingspercentage gestegen.
Geleerde lessen bij het bouwen van Workflow
- Bij het samenstellen van een procedure moet u informatie uit verschillende bronnen verzamelen.
Sommige van onze beheerders wisten niet dat de ingenieur zelf de schijven verwisselt. Sommige mensen dachten dat MD RAID-synchronisatie door technici werd afgehandeld, ook al hadden sommigen van hen daar niet eens toegang toe. Sommige vooraanstaande ingenieurs deden dit, maar niet altijd omdat het proces nergens beschreven stond. - De procedure moet eenvoudig en begrijpelijk zijn.
Het is moeilijk voor een persoon om veel stappen in gedachten te houden. De belangrijkste buurstatussen in Jira moeten op het hoofdscherm worden geplaatst. U kunt ze hernoemen, wij noemen dit bijvoorbeeld In uitvoering Klaar om te veranderen. En andere statussen kunnen worden verborgen in een vervolgkeuzemenu, zodat ze geen doorn in het oog zijn. Maar het is beter om mensen niet te beperken, maar ze de kans te geven de overstap te maken.
Leg de waarde van innovatie uit. Als mensen het begrijpen, accepteren ze de nieuwe procedure meer. Voor ons was het heel belangrijk dat mensen niet door het hele proces klikken, maar het volgen. Vervolgens hebben we hierop automatisering gebouwd. - Wacht, analyseer, zoek het uit.
Het kostte ons ongeveer een maand om de procedure, de technische implementatie, vergaderingen en discussies op te bouwen. En de implementatie duurt ruim drie maanden. Ik zag hoe mensen de innovatie langzaam gaan gebruiken. In de beginfase was er veel negativiteit. Maar het stond volledig los van de procedure zelf en de technische implementatie ervan. Zo gebruikte één beheerder niet Jira, maar de Jira plugin in Confluence, en waren sommige zaken voor hem niet beschikbaar. We lieten hem Jira zien, en de productiviteit van de beheerder nam toe, zowel voor algemene taken als voor het vervangen van schijven.
Automatisering van schijfvervanging
We hebben de automatisering van schijfvervanging meerdere keren benaderd. We hadden al ontwikkelingen en scripts, maar die werkten allemaal interactief of handmatig en vereisten een lancering. En pas na de introductie van de nieuwe procedure beseften we dat dit precies was wat we misten.
Omdat ons vervangingsproces nu is opgedeeld in fasen, die elk een specifieke uitvoerder en een lijst met acties hebben, kunnen we automatisering in fasen mogelijk maken, en niet allemaal tegelijk. De eenvoudigste fase - Ready (het controleren van RAID/gegevenssynchronisatie) kan bijvoorbeeld eenvoudig worden gedelegeerd aan een bot. Als de bot een beetje heeft geleerd, kun je hem een belangrijkere taak geven: de schijf in rotatie brengen, enz.
Dierentuin opstellingen
Voordat we het over de bot hebben, maken we eerst een korte excursie naar onze dierentuin met installaties. In de eerste plaats komt dat door de gigantische omvang van onze infrastructuur. Ten tweede proberen we voor elke dienst de optimale hardwareconfiguratie te selecteren. We hebben ongeveer 20 hardware RAID-modellen, voornamelijk LSI en Adaptec, maar er zijn ook HP en DELL in verschillende versies. Elke RAID-controller heeft zijn eigen beheerhulpprogramma. De reeks opdrachten en de uitgifte ervan kunnen voor elke RAID-controller van versie tot versie verschillen. Waar HW-RAID niet wordt gebruikt, kan mdroid worden gebruikt.
We doen bijna alle nieuwe installaties zonder schijfback-up. We proberen geen hardware- en software-RAID meer te gebruiken, omdat we back-ups van onze systemen maken op datacenterniveau en niet op servers. Maar er zijn natuurlijk veel oudere servers die ondersteund moeten worden.
Ergens worden de schijven in RAID-controllers overgebracht naar onbewerkte apparaten, ergens worden JBOD's gebruikt. Er zijn configuraties met één systeemschijf op de server, en als deze moet worden vervangen, moet u de server opnieuw installeren met de installatie van het besturingssysteem en applicaties van dezelfde versies, vervolgens configuratiebestanden toevoegen en applicaties starten. Er zijn ook veel servergroepen waar de back-up niet op het niveau van het schijfsubsysteem wordt uitgevoerd, maar rechtstreeks in de applicaties zelf.
In totaal hebben we meer dan 400 unieke servergroepen waarop bijna 100 verschillende applicaties draaien. Om zo’n groot aantal opties te kunnen dekken, hadden we een multifunctionele automatiseringstool nodig. Het liefst met een eenvoudige DSL, zodat niet alleen degene die het geschreven heeft het kan ondersteunen.
We kozen voor Ansible omdat het agentloos is: er was geen noodzaak om infrastructuur voor te bereiden, een snelle start. Daarnaast is het geschreven in Python, wat binnen het team als standaard wordt geaccepteerd.
Algemeen schema
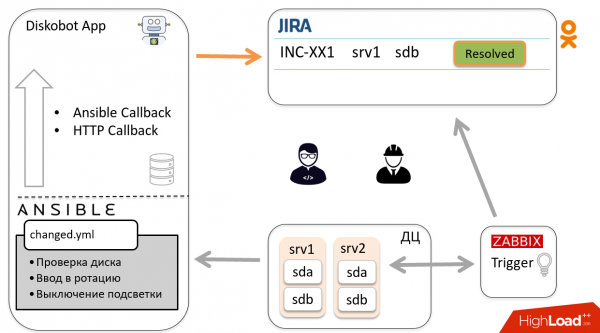
Laten we eens kijken naar het algemene automatiseringsschema met één incident als voorbeeld. Zabbix detecteert dat de sdb-schijf defect is, de trigger licht op en er wordt een ticket aangemaakt in Jira. De beheerder keek ernaar, realiseerde zich dat het geen duplicaat was en geen vals-positief, dat wil zeggen dat de schijf moest worden vervangen, en bracht het ticket over naar In uitvoering.
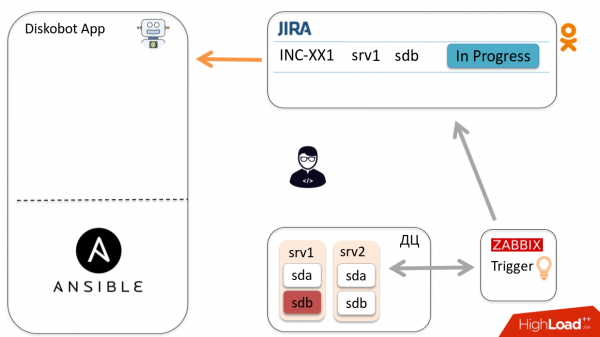
De DiskoBot-applicatie, geschreven in Python, vraagt Jira periodiek naar nieuwe tickets. Het merkt dat er een nieuw In progress-ticket is verschenen, de bijbehorende thread wordt geactiveerd, waardoor het playbook in Ansible wordt gestart (dit wordt gedaan voor elke status in Jira). In dit geval wordt Prepare2change gestart.
Ansible wordt naar de host gestuurd, haalt de schijf uit de rotatie en rapporteert de status aan de applicatie via Callbacks.
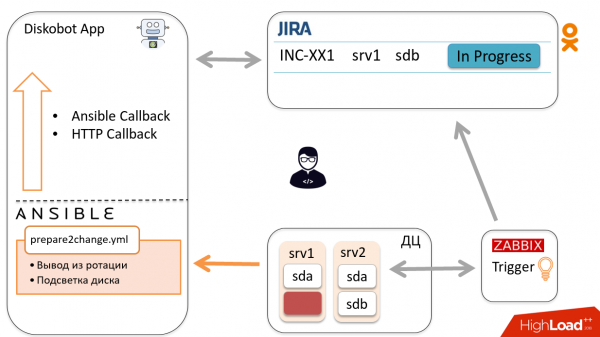
Op basis van de resultaten zet de bot het ticket automatisch over naar Ready to change. De monteur krijgt een melding en gaat de schijf wisselen, waarna hij het ticket overzet naar Gewijzigd.
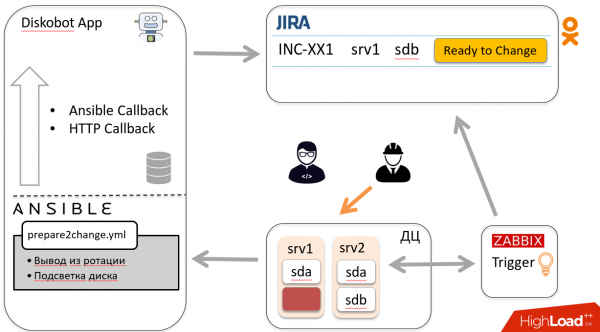
Volgens het hierboven beschreven schema gaat het ticket terug naar de bot, die een ander playbook lanceert, naar de host gaat en de schijf in rotatie brengt. De bot sluit het ticket. Hoera!
Laten we het nu hebben over enkele componenten van het systeem.
Diskobot
Deze applicatie is geschreven in Python. Het selecteert tickets van Jira volgens JQL. Afhankelijk van de status van het ticket gaat deze naar de corresponderende handler, die op zijn beurt het Ansible-playbook lanceert dat overeenkomt met de status.
JQL en polling-intervallen worden gedefinieerd in het applicatieconfiguratiebestand.
jira_states:
investigate:
jql: '… status = Open and "Disk Size" is EMPTY'
interval: 180
inprogress:
jql: '… and "Disk Size" is not EMPTY and "Device Name" is not EMPTY'
ready:
jql: '… and (labels not in ("dbot_ignore") or labels is EMPTY)'
interval: 7200
Van de tickets met de status In uitvoering worden bijvoorbeeld alleen de tickets geselecteerd waarbij de velden Schijfgrootte en Apparaatnaam zijn ingevuld. Apparaatnaam is de naam van het blokapparaat dat nodig is om het playbook uit te voeren. Er is schijfgrootte nodig zodat de ingenieur weet welke schijfgrootte nodig is.
En onder de tickets met de status Gereed worden tickets met het label dbot_ignore eruit gefilterd. Overigens gebruiken we Jira-labels zowel voor dit filteren als voor het markeren van dubbele tickets en het verzamelen van statistieken.
Als een playbook mislukt, wijst Jira het label dbot_failed toe, zodat dit later kan worden opgelost.
Interoperabiliteit met Ansible
De applicatie communiceert met Ansible via . Aan playbook_executor geven we de bestandsnaam en een reeks variabelen door. Hierdoor kunt u het Ansible-project in de vorm van reguliere yml-bestanden houden, in plaats van het in Python-code te beschrijven.
Ook in Ansible, via *extra_vars*, de naam van het blokapparaat, de status van het ticket, evenals de callback_url, die de uitgiftesleutel bevat - deze wordt gebruikt voor callback in HTTP.
Voor elke lancering wordt een tijdelijke inventaris gegenereerd, bestaande uit één host en de groep waartoe deze host behoort, zodat group_vars worden toegepast.
Hier is een voorbeeld van een taak die HTTP-callback implementeert.
We krijgen het resultaat van het uitvoeren van playbooks met behulp van callaback(s). Er zijn twee soorten:
- , biedt het gegevens over de resultaten van de uitvoering van het draaiboek. Het beschrijft de taken die zijn gestart, succesvol of niet succesvol zijn voltooid. Deze callback wordt aangeroepen wanneer het playbook klaar is met spelen.
- HTTP-callback om informatie te ontvangen tijdens het afspelen van een playbook. In de Ansible-taak voeren we een POST/GET-verzoek uit naar onze applicatie.
Variabelen worden doorgegeven via HTTP-callback(s) die zijn gedefinieerd tijdens de uitvoering van het playbook en die we willen opslaan en gebruiken in volgende uitvoeringen. We schrijven deze gegevens in sqlite.
We laten ook reacties achter en wijzigen de ticketstatus via HTTP-callback.
HTTP-callback
# Make callback to Diskobot App
# Variables:
# callback_post_body: # A dict with follow keys. All keys are optional
# msg: If exist it would be posted to Jira as comment
# data: If exist it would be saved in Incident.variables
# desire_state: Set desire_state for incident
# status: If exist Proceed issue to that status
- name: Callback to Diskobot app (jira comment/status)
uri:
url: "{{ callback_url }}/{{ devname }}"
user: "{{ diskobot_user }}"
password: "{{ diskobot_pass }}"
force_basic_auth: True
method: POST
body: "{{ callback_post_body | to_json }}"
body_format: json
delegate_to: 127.0.0.1
Zoals veel taken van hetzelfde type, plaatsen we het in een apart gemeenschappelijk bestand en nemen we het indien nodig op, om het niet voortdurend in draaiboeken te herhalen. Dit omvat de callback_url, die de probleemsleutel en de hostnaam bevat. Wanneer Ansible dit POST-verzoek uitvoert, begrijpt de bot dat het deel uitmaakte van een bepaald incident.
En hier is een voorbeeld uit het playbook, waarin we een schijf uitvoeren vanaf een MD-apparaat:
# Save mdadm configuration
- include: common/callback.yml
vars:
callback_post_body:
status: 'Ready to change'
msg: "Removed disk from mdraid {{ mdadm_remove_disk.msg | comment_jira }}"
data:
mdadm_data: "{{ mdadm_remove_disk.removed }}"
parted_info: "{{ parted_info | default() }}"
when:
- mdadm_remove_disk | changed
- mdadm_remove_disk.removed
Deze taak zet het Jira-ticket over naar de status ‘Klaar om te wijzigen’ en voegt een opmerking toe. Ook slaat de variabele mdam_data een lijst op met md-apparaten waarvan de schijf is verwijderd, en parted_info slaat een partitiedump van parted op.
Wanneer de ingenieur een nieuwe schijf plaatst, kunnen we deze variabelen gebruiken om de partitiedump te herstellen, en om de schijf in de MD-apparaten te plaatsen waarvan deze is verwijderd.
Ansible-controlemodus
Het was eng om de automatisering in te schakelen. Daarom hebben we besloten om alle playbooks in de modus uit te voeren
, waarbij Ansible geen acties uitvoert op de servers, maar deze alleen emuleert.
Zo'n lancering verloopt via een aparte callback-module en het resultaat van de uitvoering van het playbook wordt als commentaar in Jira opgeslagen.
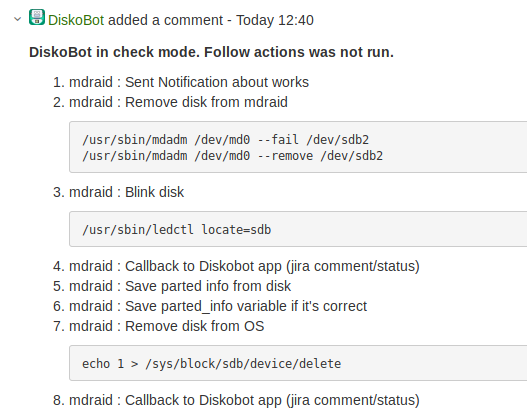
Ten eerste maakte dit het mogelijk om het werk van de bot en playbooks te valideren. Ten tweede vergroot het het vertrouwen van beheerders in de bot.
Toen we de validatie doorstonden en beseften dat je Ansible niet alleen in de dry run-modus kunt draaien, hebben we in Jira een Run Diskobot-knop gemaakt om hetzelfde playbook met dezelfde variabelen op dezelfde host te starten, maar dan in de normale modus.
Bovendien wordt de knop gebruikt om het playbook opnieuw te starten als deze crasht.
Structuur van draaiboeken
Ik heb al gezegd dat de bot, afhankelijk van de status van het Jira-ticket, verschillende playbooks lanceert.
Ten eerste is het veel eenvoudiger om de ingang te organiseren.
Ten tweede is het in sommige gevallen gewoon noodzakelijk.
Als u bijvoorbeeld een systeemschijf vervangt, moet u eerst naar het implementatiesysteem gaan, een taak maken en na een correcte implementatie wordt de server toegankelijk via ssh en kunt u de applicatie daarop uitrollen. Als we dit allemaal in één playbook zouden doen, zou Ansible het niet kunnen voltooien omdat de host niet beschikbaar is.
We gebruiken Ansible-rollen voor elke groep servers. Hier kun je zien hoe de draaiboeken in één ervan zijn georganiseerd.
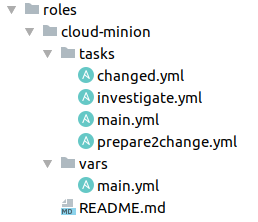
Handig omdat het direct duidelijk is waar welke taken zich bevinden. In main.yml, de invoer voor de Ansible-rol, kunnen we eenvoudig de ticketstatus of algemene taken opnemen die voor iedereen vereist zijn, bijvoorbeeld het doorgeven van identificatie of het ontvangen van een token.
onderzoek.yml
Wordt uitgevoerd voor tickets met de status Onderzoek en Open. Het belangrijkste voor dit playbook is de naam van het blokapparaat. Deze informatie is niet altijd beschikbaar.
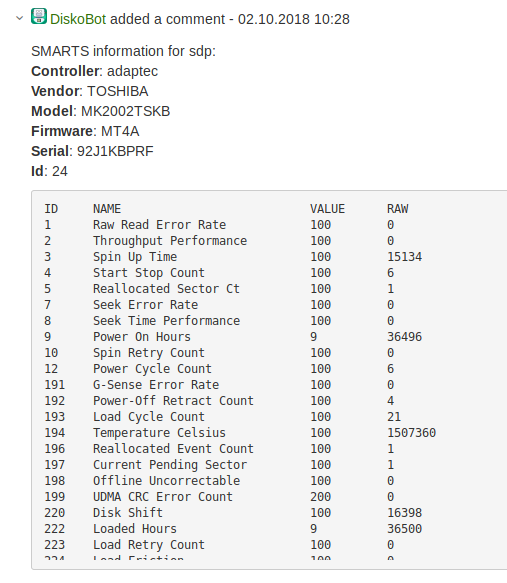
Om dit te verkrijgen analyseren we de Jira-samenvatting, de laatste waarde van de Zabbix-trigger. Het kan de naam van het blokapparaat bevatten - geluk. Of het kan een mountpunt bevatten, dan moet je naar de server gaan, het parseren en de vereiste schijf berekenen. De trigger kan ook een scsi-adres of andere informatie verzenden. Maar het komt ook voor dat er geen aanwijzingen zijn en dat je moet analyseren.
Nadat we de naam van het blokapparaat hebben ontdekt, verzamelen we informatie over het type en de grootte van de schijf om de velden in Jira in te vullen. Ook verwijderen we informatie over de leverancier, het model, de firmware, ID, SMART en plakken dit alles in een opmerking in het Jira-ticket. De beheerder en engineer hoeven niet meer naar deze gegevens te zoeken. 🙂
prepare2change.yml
De schijf uit rotatie halen, voorbereiden op vervanging. De moeilijkste en belangrijkste fase. Hier kunt u de toepassing stoppen als deze niet gestopt zou moeten worden. Of verwijder een schijf die niet genoeg replica's had, en daardoor een effect had op gebruikers, waarbij gegevens verloren gingen. Hier hebben we de meeste controles en meldingen in de chat.
In het eenvoudigste geval hebben we het over het verwijderen van een schijf uit een HW/MD RAID.
In complexere situaties (in onze opslagsystemen), wanneer de back-up op applicatieniveau wordt uitgevoerd, moet u via de API naar de applicatie gaan, de schijfuitvoer rapporteren, deze deactiveren en het herstel starten.
We migreren nu massaal naar , en als de server cloudgebaseerd is, roept Diskobot de cloud-API aan, zegt dat deze gaat werken met deze minion - de server waarop containers draaien - en vraagt "migreer alle containers van deze minion." En schakelt tegelijkertijd de achtergrondverlichting van de schijf in, zodat de ingenieur onmiddellijk kan zien welke eruit moet worden getrokken.
gewijzigd.yml
Na het vervangen van een schijf controleren wij eerst de beschikbaarheid ervan.
Ingenieurs installeren niet altijd nieuwe schijven, daarom hebben we een controle toegevoegd op SMART-waarden die ons tevreden stellen.
Naar welke kenmerken kijken we?Aantal opnieuw toegewezen sectoren (5) < 100
Huidig aantal openstaande sectoren (107) == 0
Als de schijf de test niet doorstaat, krijgt de technicus een melding dat hij deze opnieuw moet vervangen. Als alles in orde is, wordt de achtergrondverlichting uitgeschakeld, worden markeringen aangebracht en wordt de schijf in rotatie gebracht.
ready.yml
Het eenvoudigste geval: de HW/SW-raidsynchronisatie controleren of de gegevenssynchronisatie in de applicatie voltooien.
Applicatie-API
Ik heb meerdere keren gezegd dat de bot vaak toegang heeft tot applicatie-API's. Natuurlijk beschikten niet alle applicaties over de benodigde methoden, dus moesten ze worden aangepast. Dit zijn de belangrijkste methoden die we gebruiken:
- Toestand. Status van een cluster of schijf om te begrijpen of er mee gewerkt kan worden;
- Start Stop. Schijfactivering/-deactivering;
- Migreren/herstellen. Datamigratie en herstel tijdens en na vervanging.
Lessen geleerd van Ansible
Ik vind Ansible echt geweldig. Maar vaak, als ik naar verschillende opensource-projecten kijk en zie hoe mensen draaiboeken schrijven, word ik een beetje bang. Complexe logische verwevingen van wanneer/loop, gebrek aan flexibiliteit en idempotentie als gevolg van veelvuldig gebruik van shell/command.
We hebben besloten om alles zoveel mogelijk te vereenvoudigen, waarbij we profiteren van het voordeel van Ansible: modulariteit. Op het hoogste niveau zijn er playbooks; deze kunnen worden geschreven door elke beheerder, externe ontwikkelaar die een beetje Ansible kent.
- name: Blink disk
become: True
register: locate_action
disk_locate:
locate: '{{ locate }}'
devname: '{{ devname }}'
ids: '{{ locate_ids | default(pd_id) | default(omit) }}'
Als bepaalde logica moeilijk te implementeren is in draaiboeken, verplaatsen we deze naar een Ansible-module of filter. Scripts kunnen in Python of een andere taal worden geschreven.
Ze zijn gemakkelijk en snel te schrijven. De schijfachtergrondverlichtingsmodule, waarvan hierboven een voorbeeld wordt getoond, bestaat bijvoorbeeld uit 265 lijnen.

Op het laagste niveau bevindt zich de bibliotheek. Voor dit project hebben we een aparte applicatie geschreven, een soort abstractie over hardware- en software-RAID's die de bijbehorende verzoeken uitvoeren.
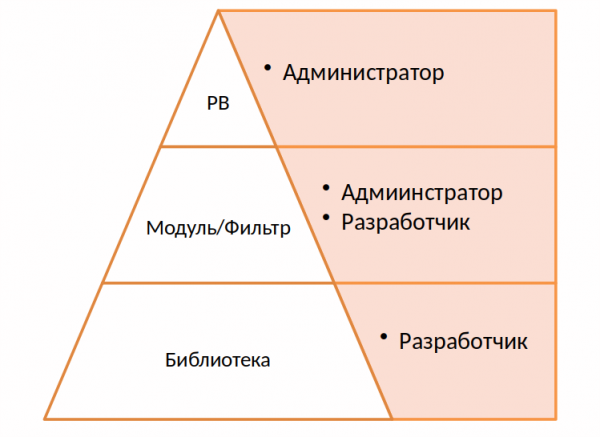
De grootste sterke punten van Ansible zijn de eenvoud en de duidelijke draaiboeken. Ik geloof dat je dit moet gebruiken en geen enge yaml-bestanden en een groot aantal voorwaarden, shell-code en lussen moet genereren.
Als je onze ervaring met de Ansible API wilt herhalen, houd dan twee dingen in gedachten:
- Playbook_executor en playbooks in het algemeen kunnen geen time-out krijgen. Er is een time-out voor de ssh-sessie, maar er is geen time-out voor het playbook. Als we proberen een schijf te ontkoppelen die niet langer in het systeem bestaat, zal het playbook eindeloos blijven draaien, dus moesten we de lancering ervan in een aparte wrapper verpakken en deze met een time-out beëindigen.
- Ansible draait op gevorkte processen, dus de API is niet thread-safe. We voeren al onze playbooks single-threaded uit.
Hierdoor konden we de vervanging van ongeveer 80% van de schijven automatiseren. Over het geheel genomen is het vervangingspercentage verdubbeld. Tegenwoordig kijkt de beheerder alleen maar naar het incident, besluit of de schijf moet worden vervangen of niet, en maakt vervolgens één klik.
Maar nu beginnen we tegen een ander probleem aan te lopen: sommige nieuwe beheerders weten niet hoe ze schijven moeten wisselen. 🙂
Bron: www.habr.com
