

Hoe kunnen bedrijfsvereisten worden vertaald naar specifieke datastructuren aan de hand van het voorbeeld van het helemaal opnieuw ontwerpen van een berichtendatabase?
- Deel 1: Het basisframe ontwerpen

Onze basis zal niet zo groot en verspreid zijn, of , maar “zodat het was”, maar het was goed - functioneel, snel en passen op één server PostgreSQL - zodat u bijvoorbeeld ergens aan de zijkant een afzonderlijk exemplaar van de service kunt implementeren.
Daarom gaan we hier niet in op de onderwerpen sharding, replicatie en geografisch gedistribueerde systemen. We richten ons alleen op de schematische oplossingen binnen de database.
Stap 1: Een paar bedrijfsgegevens
Wij ontwerpen onze boodschap niet abstract, maar integreren deze in de omgeving. . Dat wil zeggen dat onze mensen niet ‘gewoon met elkaar corresponderen’, maar met elkaar communiceren in de context van het oplossen van specifieke bedrijfsproblemen.
Welke taken heeft een bedrijf? Laten we eens kijken naar het voorbeeld van Vasily, het hoofd van de ontwikkelingsafdeling.
- "Nikolay, dit probleem heeft vandaag nog een patch nodig!"
Dit betekent dat correspondentie kan worden gevoerd in de context van bepaalde document. - "Kolya, ga je vanavond naar Dota?"
Dat wil zeggen dat zelfs één paar gesprekspartners gelijktijdig kan communiceren. over verschillende onderwerpen. - "Petr, Nikolay, kijk in de bijlage voor de prijslijst voor de nieuwe server."
Eén bericht kan dus meerdere geadresseerden. Het bericht kan bevatten bijgevoegde bestanden. - "Semyon, kijk jij ook even."
En er moet een mogelijkheid zijn om reeds bestaande correspondentie te voeren een nieuw lid uitnodigen.
Laten we het nu even bij deze lijst met ‘voor de hand liggende’ behoeften houden.
Zonder inzicht in de toegepaste specificaties van de taak en de daaraan opgelegde beperkingen is het onmogelijk om een ontwerp te maken effectief Het is vrijwel onmogelijk om het databaseschema op te lossen.
Stap 2: Minimaal logisch circuit
Schematisch gezien lijkt alles tot nu toe erg op e-mailcorrespondentie, een traditioneel hulpmiddel bij het zakendoen. Dus ja, “algoritmisch” lijken veel bedrijfstaken op elkaar, dus de hulpmiddelen om ze op te lossen zullen structureel vergelijkbaar zijn.
Laten we het reeds verkregen logische schema van relaties tussen entiteiten repareren. Om ons model gemakkelijker te kunnen begrijpen, gebruiken we de meest primitieve weergaveoptie zonder de complicaties van UML- of IDEF-notaties:
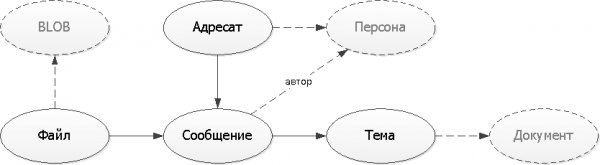
In ons voorbeeld zijn de persoon, het document en de binaire ‘body’ van het bestand ‘externe’ entiteiten die onafhankelijk bestaan zonder onze service. Daarom zullen we ze vanaf nu gewoon waarnemen als enkele links “ergens” op basis van UUID.
Tekenen schema's zo eenvoudig mogelijk - De meeste mensen aan wie je ze laat zien, zijn geen experts in het lezen van UML/IDEF. Maar - teken zeker.
Stap 3: Schets de tabelstructuur
Over tabel- en veldnamenDe “Russische” namen van velden en tabellen kunnen anders worden behandeld, maar dit is een kwestie van smaak. Omdat de er zijn geen buitenlandse ontwikkelaars, en PostgreSQL stelt ons in staat namen te geven, zelfs in hiërogliefen, als ze dat wel zijn tussen aanhalingstekens, dan geven we er de voorkeur aan om objecten ondubbelzinnig en duidelijk te benoemen, zodat er geen discrepanties ontstaan.
Omdat er veel mensen tegelijk berichten schrijven, kunnen sommigen van hen dit zelfs doen in offline modus, dan is de eenvoudigste optie UUID's gebruiken als identificatiegegevens niet alleen voor externe entiteiten, maar ook voor alle objecten binnen onze service. Bovendien kunnen ze zelfs aan de clientzijde worden gegenereerd. Dit helpt ons bij het verzenden van berichten wanneer de database tijdelijk niet beschikbaar is, en de kans op een botsing is extreem laag.
De ruwe structuur van de tabellen in onze database ziet er als volgt uit:
Tabellen: RU
CREATE TABLE "Тема"(
"Тема"
uuid
PRIMARY KEY
, "Документ"
uuid
, "Название"
text
);
CREATE TABLE "Сообщение"(
"Сообщение"
uuid
PRIMARY KEY
, "Тема"
uuid
, "Автор"
uuid
, "ДатаВремя"
timestamp
, "Текст"
text
);
CREATE TABLE "Адресат"(
"Сообщение"
uuid
, "Персона"
uuid
, PRIMARY KEY("Сообщение", "Персона")
);
CREATE TABLE "Файл"(
"Файл"
uuid
PRIMARY KEY
, "Сообщение"
uuid
, "BLOB"
uuid
, "Имя"
text
);Tabellen : EN
CREATE TABLE theme(
theme
uuid
PRIMARY KEY
, document
uuid
, title
text
);
CREATE TABLE message(
message
uuid
PRIMARY KEY
, theme
uuid
, author
uuid
, dt
timestamp
, body
text
);
CREATE TABLE message_addressee(
message
uuid
, person
uuid
, PRIMARY KEY(message, person)
);
CREATE TABLE message_file(
file
uuid
PRIMARY KEY
, message
uuid
, content
uuid
, filename
text
);Het gemakkelijkste wat je kunt doen bij het beschrijven van een formaat is om te beginnen met het ‘afwikkelen’ van de grafiek van verbindingen uit tabellen waarnaar niet wordt verwezen onszelf aan niemand vertellen.
Stap 4: Identificeer niet-voor-de-hand-liggende behoeften
Dat is het, we hebben een database ontworpen waar u naar kunt schrijven en ergens lezen.
Laten we ons eens verplaatsen in de schoenen van de gebruiker van onze dienst: wat willen wij ermee doen?
- Laatste berichten
Het chronologisch gesorteerd volgens verschillende criteria het register van “mijn” berichten. Waar ik een van de geadresseerden ben, waar ik de auteur ben, waar ze mij schreven en ik niet antwoordde, waar ze mij niet antwoordden, … - Deelnemers aan de correspondentie
Wie doet er eigenlijk mee aan dit lange, lange gesprek?
Onze structuur maakt het mogelijk om beide problemen “in het algemeen” op te lossen, maar niet snel. Het probleem is dat voor het sorteren binnen de eerste taak kan geen index maken, geschikt voor elk van de deelnemers (en alle records zullen moeten worden geëxtraheerd), en om de tweede op te lossen is het nodig alle berichten extraheren op het onderwerp.
Onbedoelde gebruikerstaken kunnen een groot probleem vormen kruis op productiviteit.
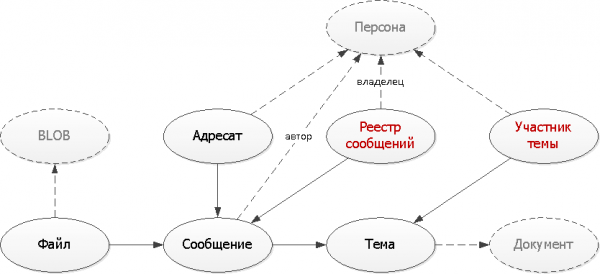
Stap 5: Slimme denormalisatie
Beide problemen worden opgelost door extra tabellen, die we zullen gebruiken. duplicaat van een deel van de gegevens, die noodzakelijk zijn voor het opstellen van indexen op basis van deze gegevens, die geschikt zijn voor onze taken.
Tabellen: RU
CREATE TABLE "РеестрСообщений"(
"Владелец"
uuid
, "ТипРеестра"
smallint
, "ДатаВремя"
timestamp
, "Сообщение"
uuid
, PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение")
);
CREATE INDEX ON "РеестрСообщений"("Владелец", "ТипРеестра", "ДатаВремя" DESC);
CREATE TABLE "УчастникТемы"(
"Тема"
uuid
, "Персона"
uuid
, PRIMARY KEY("Тема", "Персона")
);Tabellen : EN
CREATE TABLE message_registry(
owner
uuid
, registry
smallint
, dt
timestamp
, message
uuid
, PRIMARY KEY(owner, registry, message)
);
CREATE INDEX ON message_registry(owner, registry, dt DESC);
CREATE TABLE theme_participant(
theme
uuid
, person
uuid
, PRIMARY KEY(theme, person)
);Hier hebben we twee typische benaderingen gebruikt bij het maken van hulptabellen:
- Vermenigvuldiging van records
Vanuit één oorspronkelijk berichtrecord maken we in één keer meerdere vervolgrecords aan in verschillende typen registers voor verschillende eigenaren - zowel voor de verzender als voor de ontvanger. Maar nu wordt elk register op de index geplaatst. Normaal gesproken willen we immers alleen de eerste pagina zien. - Uniekheid van records
Elke keer dat u een bericht binnen een bepaald onderwerp verstuurt, hoeft u alleen maar te controleren of er al een dergelijk bericht bestaat. Zo niet, dan voegen we het toe aan ons ‘woordenboek’.
Het volgende deel van het artikel zal het volgende bespreken in de structuur van onze database.
Bron: www.habr.com
