

Dit is niet eens een grap, het lijkt erop dat deze foto het meest nauwkeurig de essentie van deze DB's weergeeft, en aan het einde zal het duidelijk zijn waarom:

Volgens de DB-Engines Ranking zijn Cassandra (hierna CS) en HBase (HB) de twee populairste NoSQL-kolomopslagdatabases.
Door de wil van het lot heeft ons datalaadbeheerteam bij Sberbank al en werkt nauw samen met HB. Gedurende deze tijd hebben we de sterke en zwakke punten ervan goed bestudeerd en geleerd hoe we het moesten bereiden. De aanwezigheid van een alternatief in de vorm van CS deed ons echter voortdurend twijfelen: hebben we de juiste keuze gemaakt? Vooral omdat de resultaten... , uitgevoerd door DataStax, gaf aan dat CS HB met gemak verslaat met een bijna verpletterende score. Aan de andere kant is DataStax een geïnteresseerde partij, en je moet hun woord er niet op vertrouwen. Bovendien was de vrij beperkte hoeveelheid informatie over de testomstandigheden verwarrend, dus besloten we zelf uit te zoeken wie de koning is van BigData NoSql, en de resultaten waren behoorlijk interessant.
Voordat we echter verdergaan met de resultaten van de uitgevoerde tests, is het noodzakelijk om de essentiële aspecten van de omgevingsconfiguraties te beschrijven. CS kan namelijk worden gebruikt in een modus die dataverlies toestaat. Dat wil zeggen, wanneer slechts één server (knooppunt) verantwoordelijk is voor de gegevens van een bepaalde sleutel en deze om welke reden dan ook uitvalt, gaat de waarde van deze sleutel verloren. Voor veel taken is dit niet cruciaal, maar voor de bankensector is dit eerder uitzondering dan regel. In ons geval is het essentieel om meerdere kopieën van de gegevens te hebben voor betrouwbare opslag.
Daarom werd alleen de CS-werkingsmodus in drievoudige replicatiemodus in aanmerking genomen, d.w.z. het aanmaken van de sleutelruimte werd uitgevoerd met de volgende parameters:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}; Er zijn twee manieren om het vereiste niveau van consistentie te garanderen. De algemene regel is:
NW + NR > RF
Dit betekent dat het aantal bevestigingen van knooppunten bij het schrijven (NW) plus het aantal bevestigingen van knooppunten bij het lezen (NR) groter moet zijn dan de replicatiefactor. In ons geval is RF = 3, wat betekent dat de volgende opties geschikt zijn:
2 + 2 > 3
3 + 1 > 3
Omdat het voor ons van fundamenteel belang is om gegevens zo betrouwbaar mogelijk op te slaan, is gekozen voor het 3+1-schema. Bovendien werkt HB volgens een vergelijkbaar principe, wat betekent dat een dergelijke vergelijking eerlijker is.
Het is opmerkelijk dat DataStax in hun onderzoek het tegenovergestelde deed: ze stelden RF = 1 in voor zowel CS als HB (voor de laatste door de HDFS-instellingen te wijzigen). Dit is een zeer belangrijk aspect, omdat de impact op de CS-prestaties in dit geval enorm is. De onderstaande afbeelding toont bijvoorbeeld de toename in de tijd die nodig is om data in CS te laden:
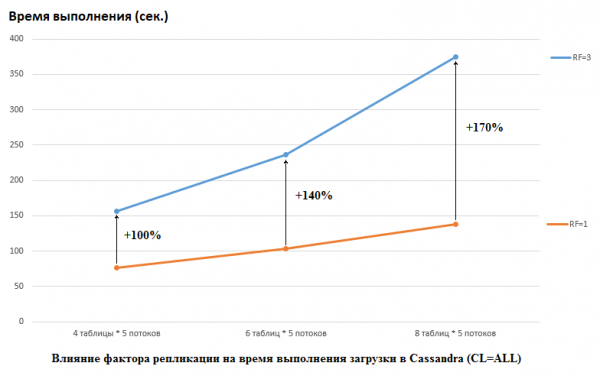
Hier zien we het volgende: hoe meer concurrerende threads data schrijven, hoe langer het duurt. Dit is logisch, maar het is belangrijk dat de prestatievermindering voor RF=3 aanzienlijk hoger is. Met andere woorden, als we naar 4 tabellen schrijven met elk 5 threads (20 in totaal), dan verliest RF=3 ongeveer 2 keer (150 seconden voor RF=3 versus 75 voor RF=1). Maar als we de belasting verhogen door data te laden in 8 tabellen met elk 5 threads (40 in totaal), dan verliest RF=3 2,7 keer (375 seconden versus 138).
Misschien is dit deels het geheim van succesvolle loadtests voor CS uitgevoerd door DataStax, want voor HB op onze stand had het wijzigen van de replicatiefactor van 2 naar 3 geen effect. Dat wil zeggen, schijven vormen geen bottleneck voor HB in onze configuratie. Er zijn echter nog veel meer valkuilen, zoals het feit dat onze versie van HB licht gepatcht en geoptimaliseerd was, de omgevingen compleet anders zijn, enz. Het is ook belangrijk om te vermelden dat ik misschien gewoon niet weet hoe ik CS goed moet voorbereiden en dat er effectievere manieren zijn om ermee te werken, en ik hoop dat we daar in de reacties achter komen. Maar eerst het belangrijkste.
Alle tests werden uitgevoerd op een hardwarecluster bestaande uit 4 servers, elk in de volgende configuratie:
CPU: Xeon E5-2680 v4 @ 2.40 GHz 64 threads.
Schijven: 12 stuks SATA HDD
Java-versie: 1.8.0_111
CS-versie: 3.11.5
cassandra.yml-parametersaantal tokens: 256
hinted_handoff_enabled: waar
hinted_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
hints_directory: /data10/cassandra/hints
hints_flush_periode_in_ms: 10000
max_hints_bestandsgrootte_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
authenticator: AllowAllAuthenticator
autorisatie: AllowAllAuthorizer
rol_beheerder: CassandraRolManager
rollen_geldigheid_in_ms: 2000
machtigingen_geldigheid_in_ms: 2000
geldigheid_inloggegevens_in_ms: 2000
partitie: org.apache.cassandra.dht.Murmur3Partitioner
data_file_directories:
— /data1/cassandra/data # elke dataN-directory is een aparte schijf
— /data2/cassandra/data
— /data3/cassandra/data
— /data4/cassandra/data
— /data5/cassandra/data
— /data6/cassandra/data
— /data7/cassandra/data
— /data8/cassandra/data
commitlog_directory: /data9/cassandra/commitlog
cdc_enabled: onwaar
schijffoutbeleid: stop
commit_failure_policy: stop
voorbereide_statements_cache_grootte_mb:
thrift_prepared_statements_cache_grootte_mb:
sleutelcachegrootte_in_mb:
sleutelcache_opslagperiode: 14400
rijcachegrootte in mb: 0
rij_cache_opslaan_periode: 0
counter_cache_grootte_in_mb:
counter_cache_save_periode: 7200
opgeslagen_caches_map: /data10/cassandra/opgeslagen_caches
commitlog_sync: periodiek
commitlog_synchronisatieperiode_in_ms: 10000
commitlog_segment_grootte_in_mb: 32
zaadleverancier:
- klassenaam: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
— zaden: "*,*"
concurrent_reads: 256 # probeerde 64 - geen verschil opgemerkt
concurrent_writes: 256 # probeerde 64 - geen verschil opgemerkt
concurrent_counter_writes: 256 # probeerde 64 - geen verschil opgemerkt
gelijktijdige_gematerialiseerde_weergave_schrijfbewerkingen: 32
memtable_heap_space_in_mb: 2048 # probeerde 16 GB - was langzamer
memtable_allocation_type: heap_buffers
index_samenvatting_capaciteit_in_mb:
index_summary_resize_interval_in_minuten: 60
trickle_fsync: onwaar
trickle_fsync_interval_in_kb: 10240
opslagpoort: 7000
ssl_opslag_poort: 7001
luister_adres: *
uitzendadres: *
listen_on_broadcast_address: waar
internodesauthenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: waar
native_transport_poort: 9042
start_rpc: waar
rpc_adres: *
rpc_poort: 9160
rpc_keepalive: waar
rpc_server_type:synchronisatie
zuinigheid_ingelijst_transport_formaat_in_mb: 15
incrementele_back-ups: false
snapshot_before_compaction: onwaar
auto_snapshot: waar
kolomindexgrootte in kb: 64
kolom_index_cache_grootte_in_kb: 2
gelijktijdige_verdichters: 4
verdichtingsdoorvoer_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000
bereik_aanvraag_timeout_in_ms: 200000
schrijfverzoek_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_contention_timeout_in_ms: 20000
afkappen_verzoek_timeout_in_ms: 60000
verzoek_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: onwaar
eindpunt_snitch: GossipingPropertyFileSnitch
dynamische_snitch_update_interval_in_ms: 100
dynamische_snitch_reset_interval_in_ms: 600000
drempelwaarde voor dynamische_snitch_slechtheid: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
server_encryptie_opties:
interne_encryptie: geen
client_encryptie_opties:
ingeschakeld: onwaar
internodiën_compressie: dc
inter_dc_tcp_nodelay: onwaar
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
door de gebruiker gedefinieerde functies inschakelen: onwaar
enable_scripted_user_defined_functions: onwaar
windows_timer_interval: 1
transparante_gegevensversleutelingsopties:
ingeschakeld: onwaar
grafsteen_waarschuwing_drempel: 1000
grafsteen_falen_drempel: 100000
batch_size_waarschuwingsdrempel_in_kb: 200
batch_size_fail_threshold_in_kb: 250
niet-gelogde_batch_over_partities_waarschuwingsdrempel: 10
verdichting_grote_partitie_waarschuwing_drempel_mb: 100
gc_waarschuwingsdrempel_in_ms: 1000
tegendruk ingeschakeld: onwaar
enable_materialized_views: waar
enable_sasi_indexes: waar
GC-instellingen:
### CMS-instellingen-XX:+GebruikParNieuwGC
-XX:+GebruikConcMarkSweepGC
-XX:+CMSParalelRemarkEnabled
-XX:Overlevingsratio=8
-XX:MaxTenuringThreshold=1
-XX:CMSInitiatingOccupancyFraction=75
-XX:+GebruikCMSInitiatingOccupancyOnly
-XX:CMSWachtDuur=10000
-XX:+CMSParalelInitialMarkEnabled
-XX:+CMSEdenChunksRecordAltijd
-XX:+CMSClassUnloadingEnabled
Aan het jvm.options-geheugen was 16 GB toegewezen (we hebben ook 32 GB geprobeerd, maar dat maakte geen verschil).
De tabellen zijn gemaakt met de opdracht:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};HB-versie: 1.2.0-cdh5.14.2 (in de klasse org.apache.hadoop.hbase.regionserver.HRegion hebben we MetricsRegion uitgesloten, wat leidde tot GC als het aantal regio's op RegionServer groter was dan 1000)
Niet-standaard HBase-parameterszookeeper.sessie.timeout: 120000
hbase.rpc.timeout: 2 minuut(en)
hbase.client.scanner.timeout.period: 2 minuut(en)
hbase.master.handler.aantal: 10
hbase.regionserver.lease.periode, hbase.client.scanner.timeout.periode: 2 minuut(en)
hbase.regionserver.handler.aantal: 160
hbase.regionserver.metahandler.aantal: 30
hbase.regionserver.logroll.periode: 4 uur
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.grootte: 1 GiB
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: 1 dag(en)
Geavanceerd configuratiefragment van HBase Service (veiligheidsklep) voor hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.naamruimte.init.timeout3600000
hbase.regionserver.optionelecacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Java-configuratieopties voor HBase RegionServer:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParalelRemarkEnabled -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis: 2 minuut(en)
hbase.snapshot.region.timeout: 2 minuut(en)
hbase.snapshot.master.timeout.millis: 2 minuut(en)
Maximale loggrootte van HBase REST-server: 100 MiB
HBase REST Server Maximale logbestandback-ups: 5
Maximale loggrootte van HBase Thrift-server: 100 MiB
HBase Thrift Server Maximale logbestandback-ups: 5
Master Max Log-grootte: 100 MiB
Maximale back-ups van logbestanden: 5
Maximale loggrootte van RegionServer: 100 MiB
RegionServer Maximale logbestandback-ups: 5
Detectievenster voor HBase Active Master: 4 minuten
dfs.client.hedged.read.threadpool.grootte: 40
dfs.client.hedged.read.threshold.millis: 10 milliseconde(n)
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Maximaal aantal procesbestandsbeschrijvingen: 180000
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.grootte: 20
Regio Mover-threads: 6
Client Java Heap-grootte in bytes: 1 GiB
Standaardgroep HBase REST-server: 3 GiB
Standaardgroep HBase Thrift-server: 3 GiB
Java Heap-grootte van HBase Master in bytes: 16 GiB
Java-heapgrootte van HBase RegionServer in bytes: 32 GiB
+Dierentuinier
maxClientCnxns: 601
maxSessionTimeout: 120000
Tabellen maken:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
verander 'ns:t1', {NAAM => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSIE => 'GZ'}
Eén belangrijk punt is hier: de DataStax-beschrijving vermeldt niet hoeveel regio's er zijn gebruikt om HB-tabellen te maken, hoewel dit cruciaal is voor grote volumes. Daarom is voor de tests gekozen voor het getal 64, wat opslag tot 640 GB mogelijk maakt, oftewel een middelgrote tabel.
Tijdens de test bevatte HBase 22 duizend tabellen en 67 duizend regio's (dit zou fataal zijn geweest voor versie 1.2.0, als de hierboven genoemde patch er niet was geweest).
Nu, wat betreft de code. Omdat het niet duidelijk was welke configuraties het meest voordelig waren voor een specifieke database, werden de tests in verschillende combinaties uitgevoerd. Dat wil zeggen, in sommige tests werden 4 tabellen gelijktijdig geladen (alle 4 knooppunten werden gebruikt voor de verbinding). In andere tests werkten we met 8 verschillende tabellen. In sommige gevallen was de batchgrootte 100, in andere 200 (de batchparameter - zie de code hieronder). De datagrootte voor waarde is 10 bytes of 100 bytes (dataSize). In totaal werden er elke keer 5 miljoen records in elke tabel geschreven en gelezen. In dit geval werden er 5 threads in elke tabel geschreven/gelezen (thNum threadnummer), die elk een eigen sleutelbereik gebruikten (count = 1 miljoen):
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("BEGIN BATCH ");
for (int i = 0; i < batch; i++) {
String value = RandomStringUtils.random(dataSize, true, true);
sb.append("INSERT INTO ")
.append(tableName)
.append("(id, title) ")
.append("VALUES (")
.append(key)
.append(", '")
.append(value)
.append("');");
key++;
}
sb.append("APPLY BATCH;");
final String query = sb.toString();
session.execute(query);
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN (");
for (int i = 0; i < batch; i++) {
sb = sb.append(key);
if (i+1 < batch)
sb.append(",");
key++;
}
sb = sb.append(");");
final String query = sb.toString();
ResultSet rs = session.execute(query);
}
}
Daarom werd voor HB een soortgelijke functionaliteit voorzien:
Configuration conf = getConf();
HTable table = new HTable(conf, keyspace + ":" + tableName);
table.setAutoFlush(false, false);
List<Get> lGet = new ArrayList<>();
List<Put> lPut = new ArrayList<>();
byte[] cf = Bytes.toBytes("cf");
byte[] qf = Bytes.toBytes("value");
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lPut.clear();
for (int i = 0; i < batch; i++) {
Put p = new Put(makeHbaseRowKey(key));
String value = RandomStringUtils.random(dataSize, true, true);
p.addColumn(cf, qf, value.getBytes());
lPut.add(p);
key++;
}
table.put(lPut);
table.flushCommits();
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lGet.clear();
for (int i = 0; i < batch; i++) {
Get g = new Get(makeHbaseRowKey(key));
lGet.add(g);
key++;
}
Result[] rs = table.get(lGet);
}
}
Omdat de client in HB moet zorgen voor een gelijkmatige verdeling van de gegevens, zag de sleutelzoutfunctie er als volgt uit:
public static byte[] makeHbaseRowKey(long key) {
byte[] nonSaltedRowKey = Bytes.toBytes(key);
CRC32 crc32 = new CRC32();
crc32.update(nonSaltedRowKey);
long crc32Value = crc32.getValue();
byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7);
return ArrayUtils.addAll(salt, nonSaltedRowKey);
}
En nu het meest interessante gedeelte: de resultaten:
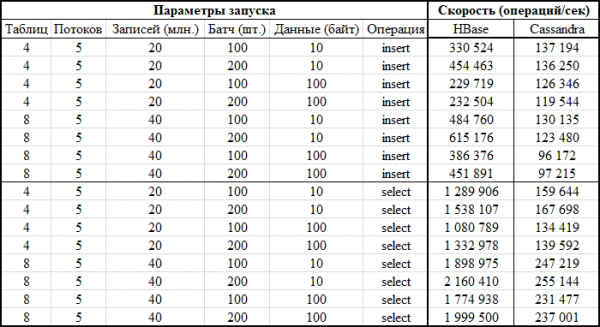
Hetzelfde in grafiekvorm:
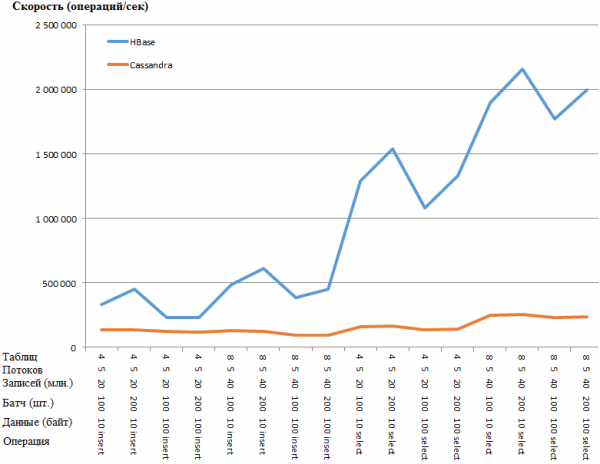
Het HB-voordeel is zo verbazingwekkend dat er een vermoeden bestaat van een bottleneck in de CS-configuratie. Googlen en het aanpassen van de meest voor de hand liggende parameters (zoals concurrent_writes of memtable_heap_space_in_mb) leverde echter geen versnelling op. Tegelijkertijd zijn de logs schoon en zijn er geen klachten.
De gegevens zijn gelijkmatig verdeeld over de knooppunten, de statistieken van alle knooppunten zijn ongeveer hetzelfde.
Dit is hoe de statistieken voor de tabel met een van de knooppunten eruit zienSleutelruimte: ks
Aantal keren gelezen: 9383707
Leeslatentie: 0.04287025042448576 ms
Schrijfaantal: 15462012
Schrijflatentie: 0.1350068438699957 ms
In afwachting van flushes: 0
Tabel: t1
SSTable-aantal: 16
Gebruikte ruimte (live): 148.59 MiB
Gebruikte ruimte (totaal): 148.59 MiB
Ruimte gebruikt door snapshots (totaal): 0 bytes
Off-heap geheugen gebruikt (totaal): 5.17 MiB
SSTable-compressieverhouding: 0.5720989576459437
Aantal partities (schatting): 3970323
Memtable-celaantal: 0
Memtable-gegevensgrootte: 0 bytes
Memtable off heap-geheugen gebruikt: 0 bytes
Aantal Memtable-switches: 5
Lokaal aantal gelezen berichten: 2346045
Lokale leeslatentie: NaN ms
Lokaal schrijfaantal: 3865503
Lokale schrijflatentie: NaN ms
In afwachting van flushes: 0
Percentage gerepareerd: 0.0
Bloom-filter valspositieve resultaten: 25
Bloomfilter valse verhouding: 0.00000
Gebruikte Bloom-filterruimte: 4.57 MiB
Bloomfilter off-heapgeheugen gebruikt: 4.57 MiB
Indexsamenvatting off-heap geheugen gebruikt: 590.02 KiB
Compressiemetadata van heapgeheugen gebruikt: 19.45 KiB
Minimale bytes voor gecomprimeerde partitie: 36
Maximale bytes voor gecomprimeerde partitie: 42
Gemiddeld aantal bytes van gecomprimeerde partitie: 42
Gemiddeld aantal levende cellen per plak (laatste vijf minuten): NaN
Maximaal aantal levende cellen per plak (laatste vijf minuten): 0
Gemiddeld aantal grafstenen per plak (laatste vijf minuten): NaN
Maximaal aantal grafstenen per plak (laatste vijf minuten): 0
Gedropte mutaties: 0 bytes
Een poging om de batchgrootte te verkleinen (tot één voor één verzenden) had geen effect, het werd alleen maar erger. Het is mogelijk dat dit in feite de maximale prestatie voor CS is, aangezien de resultaten voor CS vergelijkbaar zijn met die voor DataStax – ongeveer honderdduizend bewerkingen per seconde. Als u bovendien naar het resourcegebruik kijkt, ziet u dat CS veel meer CPU en schijfruimte gebruikt:
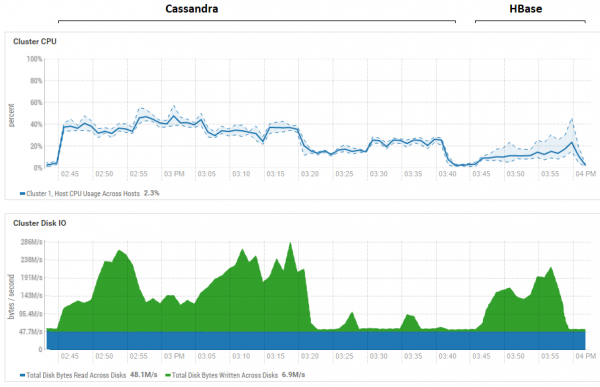
De afbeelding toont het gebruik tijdens het uitvoeren van alle tests op rij voor beide databases.
Wat betreft het krachtige voordeel van HB bij het lezen. Hier ziet u dat voor beide databases het schijfgebruik bij het lezen extreem laag is (leestests vormen het laatste deel van de testcyclus voor elke database; voor CS is dat bijvoorbeeld van 15:20 tot 15:40). In het geval van HB is de reden duidelijk: de meeste gegevens hangen in het geheugen, in de memstore, en een deel wordt gecached in de blockcache. Wat CS betreft, is het niet erg duidelijk hoe het is geregeld. Het schijfgebruik is echter ook niet zichtbaar. Voor het geval dat er een poging is gedaan om de cache in te schakelen, is row_cache_size_in_mb = 2048 en caching = {'keys': 'ALL', 'rows_per_partition': '2000000'}, maar het is zelfs nog iets erger geworden.
Het is ook de moeite waard om nogmaals een belangrijk punt te noemen over het aantal regio's in HB. In ons geval was de waarde 64. Als je dit verlaagt en bijvoorbeeld gelijk maakt aan 4, dan daalt de snelheid met een factor 2 tijdens het lezen. De reden hiervoor is dat de memstore sneller vol raakt, bestanden vaker worden geflasht en er tijdens het lezen meer bestanden moeten worden verwerkt, wat een vrij complexe operatie is voor HB. In de praktijk wordt dit aangepakt door na te denken over de strategie van presplitting en compactification. We gebruiken hiervoor een zelfgeschreven hulpprogramma dat rommel verzamelt en HFiles constant op de achtergrond comprimeert. Het is goed mogelijk dat ze voor de DataStax-tests 1 regio per tabel hebben toegewezen (wat onjuist is), en dit zou enigszins verduidelijken waarom HB zoveel verloor in hun leestests.
Hieruit kunnen de volgende voorlopige conclusies worden getrokken. Als we ervan uitgaan dat er geen grote fouten zijn gemaakt tijdens de tests, dan is Cassandra een kolos op lemen voeten. Preciezer gezegd, terwijl hij op één been balanceert, zoals te zien is op de afbeelding aan het begin van dit artikel, laat hij relatief goede resultaten zien, maar in een gevecht onder dezelfde omstandigheden verliest hij volledig. Tegelijkertijd hebben we, rekening houdend met het lage CPU-gebruik op onze hardware, geleerd om twee RegionServer HB per host te gebruiken en daarmee de prestaties te verdubbelen. Dat wil zeggen, rekening houdend met het resourcegebruik, is de situatie voor CS nog deplorabeler.
Deze tests zijn natuurlijk vrij synthetisch en de gebruikte datavolumes zijn relatief bescheiden. Het is mogelijk dat de situatie anders zou zijn bij de overstap naar terabytes, maar als we terabytes kunnen laden voor HB, dan bleek het voor CS problematisch te zijn. Zelfs met deze volumes werd er vaak een OperationTimedOutException gegenereerd, hoewel de parameters voor de responswachttijd al meerdere malen waren verhoogd ten opzichte van de standaardparameters.
Ik hoop dat we door gezamenlijke inspanningen de knelpunten van CS kunnen vinden en als het mogelijk is om het proces te versnellen, zal ik aan het einde van het bericht zeker informatie toevoegen over de uiteindelijke resultaten.
UPD: Dankzij het advies van kameraden kon ik het lezen versnellen. Het was:
159 ops (644 tabellen, 4 threads, batch 5).
Toegevoegd:
.withLoadBalancingPolicy(nieuw TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build()))
En ik speelde met het aantal draden. Het resultaat was als volgt:
4 tabellen, 100 threads, batch = 1 (individueel): 301 ops
4 tabellen, 100 threads, batch = 10: 447 ops
4 tabellen, 100 threads, batch = 100: 625 ops
Later zal ik andere afstemmingstips toepassen, een volledige testcyclus uitvoeren en de resultaten aan het einde van dit bericht toevoegen.
Bron: www.habr.com
