


SQL, wat is er eenvoudiger? We kunnen allemaal een simpele query schrijven - we typen kiezen, we geven een lijst van de benodigde kolommen, dan vanaf, tabelnaam, enkele voorwaarden in met de meeste en dat is het - bruikbare gegevens zitten in onze zak, en (bijna) ongeacht welk DBMS er op dat moment onder de motorkap zit (of misschien ). Hierdoor kan het werken met vrijwel elke gegevensbron (relationeel en niet-relationeel) worden bekeken vanuit het perspectief van reguliere code (met alle bijbehorende zaken - versiebeheer, codereview, statische analyse, autotests en dergelijke). En dit geldt niet alleen voor de gegevens zelf, schema's en migraties, maar in het algemeen voor de gehele levensduur van de opslag. In dit artikel bespreken we de dagelijkse taken en problemen die gepaard gaan met het werken met verschillende databases onder het mom van "database als code".
En laten we meteen beginnen De eerste gevechten van het type "SQL vs ORM" werden al in 1944 opgemerkt. .
Object-relationele mapping
Voorstanders van ORM hechten traditioneel waarde aan de snelheid en eenvoud van ontwikkeling, onafhankelijkheid van het DBMS en schone code. Voor velen van ons is de code voor het werken met de database (en vaak de database zelf) essentieel.
ziet er meestal ongeveer zo uit…
@Entity
@Table(name = "stock", catalog = "maindb", uniqueConstraints = {
@UniqueConstraint(columnNames = "STOCK_NAME"),
@UniqueConstraint(columnNames = "STOCK_CODE") })
public class Stock implements java.io.Serializable {
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "STOCK_ID", unique = true, nullable = false)
public Integer getStockId() {
return this.stockId;
}
...Het model is bedekt met slimme annotaties, en ergens achter de schermen genereert en voert de dappere ORM tonnen SQL-code uit. Overigens doen ontwikkelaars hun best om zich af te schermen van hun database met kilometers aan abstracties, wat wijst op een zekere... .
Aan de andere kant van de barricades merken aanhangers van pure "handgemaakte" SQL op dat ze alle sappen uit hun DBMS kunnen persen zonder extra lagen en abstracties. Hierdoor ontstaan "datacentrische" projecten, waarbij de database wordt beheerd door speciaal getrainde mensen (ook wel "basists", "basoviki", "basemenshchiki", enz.), en de ontwikkelaars alleen kant-en-klare views en opgeslagen procedures hoeven te "plukken", zonder in details te treden.
Wat als je het beste van twee werelden zou nemen? Want dat is nu mogelijk met een prachtig instrument met een levensbevestigende naam. Ik zal een paar regels uit het algemene concept in mijn vrije vertaling weergeven, en u kunt er in meer detail mee kennismaken .
Clojure is een geweldige taal voor het maken van DSL's, maar SQL is al een geweldige DSL, en we hebben er geen extra nodig. S-expressies zijn geweldig, maar ze voegen hier niets nieuws toe. We eindigen met haakjes omwille van de haakjes. Niet mee eens? Wacht dan tot de databaseabstractie begint te lekken en je de functie gaat bestrijden. (raw-sql)
Dus wat moeten we doen? Laten we SQL gewoon zoals normaal laten - één bestand per query:
-- name: users-by-country
select *
from users
where country_code = :country_code…en lees dat bestand vervolgens, en verander het in een gewone Clojure-functie:
(defqueries "some/where/users_by_country.sql"
{:connection db-spec})
;;; A function with the name `users-by-country` has been created.
;;; Let's use it:
(users-by-country {:country_code "GB"})
;=> ({:name "Kris" :country_code "GB" ...} ...)Als je je aan het principe "SQL apart, Clojure apart" houdt, krijg je:
- Geen syntactische verrassingen. Je database (net als elke andere) is niet 100% SQL-compatibel, maar Yesql maakt zich daar geen zorgen over. Je verspilt nooit tijd aan het zoeken naar functies met een SQL-equivalente syntaxis. Je hoeft nooit meer terug naar een functie. (raw-sql "some('funky'::SYNTAX)")).
- Betere editorondersteuning. Je editor biedt al uitstekende SQL-ondersteuning. Door je SQL als SQL op te slaan, kun je deze eenvoudig gebruiken.
- Opdrachtcompatibiliteit: uw DBA's kunnen de SQL lezen en schrijven die u in uw Clojure-project gebruikt.
- Eenvoudigere prestatie-afstemming. Moet je een plan maken voor een problematische query? Dat is geen probleem als je query gewoon SQL is.
- Query's hergebruiken: sleep dezelfde SQL-bestanden naar een ander project omdat het gewoon oude SQL is. Deel het gewoon.
Naar mijn mening is het idee erg cool en tegelijkertijd heel eenvoudig, waardoor het project veel populariteit heeft gekregen in verschillende talen. En we zullen proberen een soortgelijke filosofie toe te passen door SQL-code te scheiden van al het andere, ver buiten ORM.
IDE- en DB-beheerders
Laten we beginnen met een eenvoudige, alledaagse taak. We moeten vaak naar objecten in een database zoeken, bijvoorbeeld een tabel in een schema vinden en de structuur ervan bestuderen (welke kolommen, sleutels, indexen, beperkingen, enz. worden gebruikt). En van elke grafische IDE of databasebeheerder verwachten we allereerst precies deze mogelijkheden. Zodat het snel is en je niet een half uur hoeft te wachten tot een venster met de benodigde informatie wordt weergegeven (vooral bij een trage verbinding met een externe database), en tegelijkertijd zodat de ontvangen informatie actueel en relevant is, en geen oude, gecachede informatie. Bovendien, hoe complexer en groter de database en hoe meer databases er zijn, hoe moeilijker het is om dit te doen.
Maar meestal gooi ik de muis weg en schrijf ik gewoon code. Stel dat je moet uitzoeken welke tabellen (en met welke eigenschappen) in het "HR"-schema staan. In de meeste DBMS'en kan het gewenste resultaat worden bereikt met een eenvoudige query vanuit information_schema:
select table_name
, ...
from information_schema.tables
where schema = 'HR'De inhoud van dergelijke referentietabellen varieert van database tot database, afhankelijk van de mogelijkheden van elk DBMS. Voor MySQL bijvoorbeeld kunt u vanuit dezelfde referentietabel tabelparameters ophalen die specifiek zijn voor dit DBMS:
select table_name
, storage_engine -- Используемый "движок" ("MyISAM", "InnoDB" etc)
, row_format -- Формат строки ("Fixed", "Dynamic" etc)
, ...
from information_schema.tables
where schema = 'HR'Oracle kent information_schema niet, maar heeft wel , en er zijn geen grote problemen:
select table_name
, pct_free -- Минимум свободного места в блоке данных (%)
, pct_used -- Минимум используемого места в блоке данных (%)
, last_analyzed -- Дата последнего сбора статистики
, ...
from all_tables
where owner = 'HR'ClickHouse is hierop geen uitzondering:
select name
, engine -- Используемый "движок" ("MergeTree", "Dictionary" etc)
, ...
from system.tables
where database = 'HR'Iets soortgelijks kan worden gedaan in Cassandra (waar er kolomfamilies zijn in plaats van tabellen en sleutelruimten in plaats van schema's):
select columnfamily_name
, compaction_strategy_class -- Стратегия сборки мусора
, gc_grace_seconds -- Время жизни мусора
, ...
from system.schema_columnfamilies
where keyspace_name = 'HR'Voor de meeste andere databases kunt u ook soortgelijke zoekopdrachten bedenken (zelfs Mongo heeft er een). , die informatie bevat over alle collecties in het systeem).
Deze methode kan natuurlijk worden gebruikt om niet alleen informatie over tabellen te verkrijgen, maar over elk object in het algemeen. Regelmatig delen vriendelijke mensen dergelijke code voor verschillende databases, zoals in de Habr-artikelenreeks "Functies voor het documenteren van PostgreSQL-databases" (, , ). Natuurlijk is het niet zo leuk om al die query's in je hoofd te houden en ze voortdurend te typen, dus heb ik in mijn favoriete IDE/editor een vooraf voorbereide set fragmenten voor veelgebruikte query's, en hoef ik alleen nog maar de namen van de objecten in de sjabloon te typen.
Als gevolg hiervan is deze methode van navigeren en zoeken naar objecten veel flexibeler, bespaart het veel tijd, kunt u precies de informatie krijgen en in de vorm waarin u deze nu nodig hebt (zoals bijvoorbeeld beschreven in het bericht ).
Bewerkingen met objecten
Nadat we de benodigde voorwerpen hebben gevonden en bestudeerd, is het tijd om er iets nuttigs mee te doen. Uiteraard ook zonder je vingers van het toetsenbord te halen.
Het is geen geheim dat het simpelweg verwijderen van een tabel er in bijna alle databases hetzelfde uitziet:
drop table hr.personsMaar met het aanmaken van tabellen wordt het al interessanter. Vrijwel elk DBMS (inclusief veel NoSQL's) kan in een of andere vorm een "tabel aanmaken", en de belangrijkste onderdelen zullen niet eens veel verschillen (naam, lijst met kolommen, gegevenstypen), maar andere details kunnen aanzienlijk verschillen en zijn afhankelijk van de interne structuur en mogelijkheden van een specifiek DBMS. Mijn favoriete voorbeeld: in de Oracle-documentatie staan alleen "kale" BNF's voor de syntaxis "tabel aanmaken". Andere DBMS'en hebben bescheidener mogelijkheden, maar elk van hen heeft ook veel interessante en unieke functies voor het maken van tabellen (, , , Het is onwaarschijnlijk dat een grafische "wizard" van een andere IDE (vooral een universele) al deze mogelijkheden volledig kan dekken, en als dat wel lukt, dan is het geen lust voor het oog. Tegelijkertijd is een correct en tijdig geschreven operator tafel maken zorgt ervoor dat u ze allemaal eenvoudig kunt gebruiken en dat de opslag en toegang tot uw gegevens betrouwbaar, optimaal en zo comfortabel mogelijk verloopt.
Bovendien hebben veel DBMS'en hun eigen specifieke objecttypen die niet beschikbaar zijn in andere DBMS'en. Bovendien kunnen we bewerkingen uitvoeren, niet alleen op DB-objecten, maar ook op het DBMS zelf, bijvoorbeeld een proces "killen", geheugenruimte vrijmaken, tracering inschakelen, overschakelen naar de "alleen-lezen"-modus en nog veel meer.
Laten we nu een klein stukje tekenen
Een van de meest voorkomende taken is het maken van een diagram met DB-objecten, om objecten en de verbindingen ertussen in een mooie afbeelding te zien. Vrijwel elke grafische IDE, aparte opdrachtregelprogramma's, gespecialiseerde grafische tools en modelleurs kunnen dit. Deze tools tekenen iets voor u "zo goed als ze kunnen", en u kunt dit proces slechts in beperkte mate beïnvloeden met behulp van verschillende parameters in het configuratiebestand of selectievakjes in de interface.
Maar dit probleem kan veel eenvoudiger, flexibeler en eleganter worden opgelost, en natuurlijk met behulp van code. Om diagrammen van elke complexiteit te bouwen, hebben we verschillende gespecialiseerde opmaaktalen (DOT, GraphML, enz.), en daarvoor een hele reeks applicaties (GraphViz, PlantUML, Mermaid) die dergelijke instructies kunnen lezen en visualiseren in verschillende formaten. En we weten al hoe we informatie kunnen verkrijgen over objecten en de verbindingen daartussen.
Hier is een snel voorbeeld van hoe dit eruit zou kunnen zien met PlantUML en (links ziet u de SQL-query die de vereiste instructie voor PlantUML genereert, en rechts het resultaat):
select '@startuml'||chr(10)||'hide methods'||chr(10)||'hide stereotypes' union all
select distinct ccu.table_name || ' --|> ' ||
tc.table_name as val
from table_constraints as tc
join key_column_usage as kcu
on tc.constraint_name = kcu.constraint_name
join constraint_column_usage as ccu
on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and tc.table_name ~ '.*' union all
select '@enduml'En als je het een beetje probeert, dan op basis van Je kunt iets krijgen dat erg lijkt op een echt ER-diagram:
De SQL-query is iets ingewikkelder
-- Шапка
select '@startuml
!define Table(name,desc) class name as "desc" << (T,#FFAAAA) >>
!define primary_key(x) <b>x</b>
!define unique(x) <color:green>x</color>
!define not_null(x) <u>x</u>
hide methods
hide stereotypes'
union all
-- Таблицы
select format('Table(%s, "%s n information about %s") {'||chr(10), table_name, table_name, table_name) ||
(select string_agg(column_name || ' ' || upper(udt_name), chr(10))
from information_schema.columns
where table_schema = 'public'
and table_name = t.table_name) || chr(10) || '}'
from information_schema.tables t
where table_schema = 'public'
union all
-- Связи между таблицами
select distinct ccu.table_name || ' "1" --> "0..N" ' || tc.table_name || format(' : "A %s may haven many %s"', ccu.table_name, tc.table_name)
from information_schema.table_constraints as tc
join information_schema.key_column_usage as kcu on tc.constraint_name = kcu.constraint_name
join information_schema.constraint_column_usage as ccu on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and ccu.constraint_schema = 'public'
and tc.table_name ~ '.*'
union all
-- Подвал
select '@enduml'
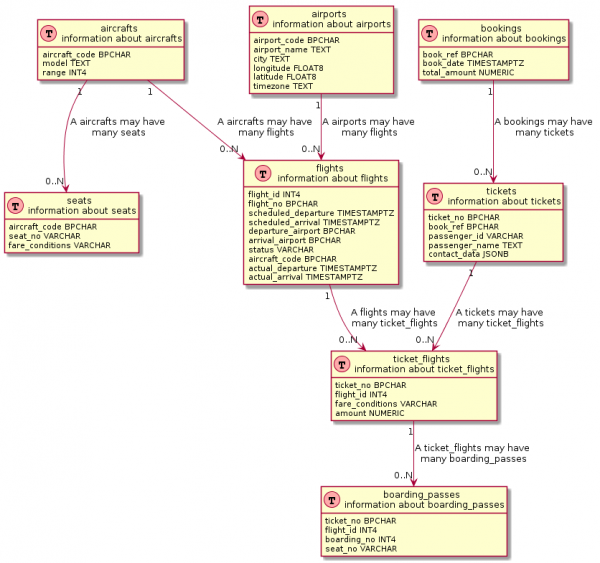
Als je goed kijkt, gebruiken veel visualisatietools vergelijkbare query's onder de motorkap. Deze query's zijn echter meestal diepgaand. , om nog maar te zwijgen van enige wijziging daarvan.
Metrieken en monitoring
Laten we verdergaan met een traditioneel moeilijk onderwerp: DB-prestatiemonitoring. Laat me een kort, waargebeurd verhaal herinneren dat "een van mijn vrienden" me vertelde. Aan een ander project werkte een zekere machtige DBA, en weinig ontwikkelaars kenden hem persoonlijk, of zagen hem zelfs maar in de ogen (ondanks het feit dat hij, volgens geruchten, ergens in het gebouw ernaast werkte). Op het "X"-uur, toen het productiesysteem van een grote retailer weer eens "slecht" begon te worden, stuurde hij in stilte screenshots van grafieken van Oracle Enterprise Manager, waarop hij zorgvuldig kritieke plekken met een rode markering markeerde voor "begrijpelijkheid" (dit hielp, op zijn zachtst gezegd, niet veel). En het was volgens deze "fotokaart" dat we moesten behandelen. Tegelijkertijd had niemand toegang tot de kostbare (in beide betekenissen van het woord) Enterprise Manager, omdat het systeem complex en duur is, "komen de ontwikkelaars plotseling ergens op uit en breken ze alles". Daarom vonden de ontwikkelaars "empirisch" de plaats en de reden voor de vertragingen en brachten ze een patch uit. Toen de dreigbrief van de DBA niet snel weer kwam, slaakte iedereen een zucht van verlichting en ging weer verder met zijn huidige taken (tot de volgende brief).
Maar het monitoringproces kan leuker en gebruiksvriendelijker, en vooral - toegankelijk en transparanter voor iedereen. Tenminste, het basisgedeelte, als aanvulling op de belangrijkste monitoringsystemen (die zeker nuttig en in veel gevallen onvervangbaar zijn). Elk DBMS is gratis en absoluut kosteloos, klaar om informatie te delen over de huidige status en prestaties. In dezelfde "verdomde" Oracle DB kan bijna alle informatie over prestaties worden verkregen uit systeemweergaven, van processen en sessies tot de status van de buffercache (bijvoorbeeld , sectie "Monitoring"). PostgreSQL heeft ook een heleboel systeemweergaven voor , met name die welke onmisbaar zijn in het dagelijks leven van elke DBA, zoals , , MySQL heeft hiervoor zelfs een apart schema. . En in Mongo is het ingebouwd verzamelt prestatiegegevens in een systeemverzameling .
Gewapend met een metrische verzamelaar (Telegraf, Metricbeat, Collectd), die aangepaste SQL-query's kan uitvoeren, een opslag van deze metrische gegevens (InfluxDB, Elasticsearch, Timescaledb) en een visualizer (Grafana, Kibana), kunt u een vrij licht en flexibel monitoringsysteem verkrijgen dat nauw geïntegreerd zal zijn met andere systeembrede metrische gegevens (bijvoorbeeld verkregen van de applicatieserver, van het besturingssysteem, enz.). Dit gebeurt bijvoorbeeld in pgwatch2, dat gebruikmaakt van een bundel van InfluxDB + Grafana en een reeks query's naar systeemweergaven, die ook kunnen worden .
In totaal
En dit is slechts een ruwe lijst van wat er met onze database kan worden gedaan met behulp van reguliere SQL-code. Ik weet zeker dat je nog veel meer toepassingen kunt vinden, schrijf ze in de reacties. En we zullen het de volgende keer hebben over hoe (en vooral waarom) je dit allemaal kunt automatiseren en in je CI/CD-pijplijn kunt opnemen.
Bron: www.habr.com
