

X5 beschikt over 43 distributiecentra en 4 eigen vrachtwagens, waarmee de ononderbroken levering van producten aan 029 winkels wordt gewaarborgd. In dit artikel deel ik mijn ervaringen met het vanaf nul creëren van een interactief magazijngebeurtenisbewakingssysteem. De informatie is nuttig voor logistieke medewerkers van handelsbedrijven met tientallen distributiecentra die een breed scala aan goederen beheren.

De opbouw van systemen voor het monitoren en beheren van bedrijfsprocessen begint doorgaans met het verwerken van meldingen en incidenten. Tegelijkertijd wordt een belangrijk technologisch aandachtspunt over het hoofd gezien, namelijk de mogelijkheid om het daadwerkelijk plaatsvinden van bedrijfsevenementen en de registratie van incidenten te automatiseren. De meeste bedrijfssystemen uit de klasse WMS, TMS en dergelijke beschikken over ingebouwde hulpmiddelen voor het bewaken van hun eigen processen. Maar als het om systemen van verschillende fabrikanten gaat of de monitoringfunctionaliteit niet voldoende is ontwikkeld, moet u dure aanpassingen bestellen of gespecialiseerde adviseurs inschakelen voor aanvullende instellingen.
Laten we eens een aanpak bekijken waarbij we slechts een klein deel van de consultancy nodig hebben met betrekking tot het definiëren van bronnen (tabellen) voor het verkrijgen van indicatoren uit het systeem.
Het bijzondere aan onze warehouses is dat meerdere warehouse management systemen (WMS Exceed) in één logistiek complex opereren. Magazijnen worden niet alleen logisch ingedeeld op basis van de opslagcategorieën (droog, alcohol, bevroren, enz.). Binnen één logistiek complex bevinden zich meerdere afzonderlijke magazijngebouwen. De activiteiten van elk gebouw worden door een eigen WMS aangestuurd.

Om een algemeen beeld te krijgen van de processen die zich in het magazijn afspelen, analyseren managers meerdere keren per dag de rapporten van elk WMS, verwerken ze meldingen van magazijnmedewerkers (ontvangers, orderpickers, stapelaars) en vatten ze de actuele operationele indicatoren samen voor weergave op het informatiebord.
Om managers tijd te besparen, besloten we een goedkoop systeem te ontwikkelen voor de operationele aansturing van gebeurtenissen in het magazijn. Het nieuwe systeem moet, naast het weergeven van ‘hot’ indicatoren van operationeel werk van magazijnprocessen, managers ook helpen bij het registreren van incidenten en het monitoren van de uitvoering van taken om de oorzaken die de gespecificeerde indicatoren beïnvloeden, te elimineren. Nadat we een algemene audit van de IT-architectuur van het bedrijf hadden uitgevoerd, beseften we dat afzonderlijke onderdelen van het vereiste systeem al op de een of andere manier in ons landschap aanwezig waren. Voor deze onderdelen is er zowel een deskundige configuratie als de benodigde ondersteunende diensten. Het enige wat nu nog rest is het combineren van het gehele concept tot één architectonische oplossing en het evalueren van de omvang van de ontwikkeling.
Nadat de hoeveelheid werk die verricht moest worden om het nieuwe systeem te bouwen was ingeschat, werd besloten het project in verschillende fasen op te splitsen:
- Verzamelen van magazijnprocesindicatoren, visualisatie en controle van indicatoren en afwijkingen
- Automatisering van procesnormen en registratie van verzoeken tot afwijkingen bij de afdeling bedrijfsdiensten
- Proactieve monitoring met lastvoorspelling en het opstellen van aanbevelingen voor managers.
In de eerste fase moet het systeem voorbereide delen van operationele gegevens uit alle WMS-complexen verzamelen. Het lezen gebeurt vrijwel in realtime (met tussenpozen van minder dan 5 minuten). Het probleem is dat bij implementatie van het systeem in het gehele netwerk de gegevens uit de DBMS van meerdere tientallen warehouses moeten worden gehaald. De ontvangen operationele gegevens worden verwerkt door de kernlogica van het systeem om afwijkingen van geplande indicatoren te berekenen en statistieken te genereren. De op deze manier verwerkte gegevens moeten in de vorm van overzichtelijke grafieken en diagrammen worden weergegeven op de tablet van de manager of op het informatiebord in het magazijn.

Bij het kiezen van een geschikt systeem voor de pilot-implementatie van de eerste fase, kozen we voor Zabbix. Dit systeem wordt al gebruikt om de IT-prestaties van magazijnsystemen te bewaken. Door een aparte installatie toe te voegen om bedrijfsstatistieken van het magazijn te verzamelen, krijgt u een algemeen beeld van de gezondheid van het magazijn.
De algemene architectuur van het systeem zag er zoals in de afbeelding uit.
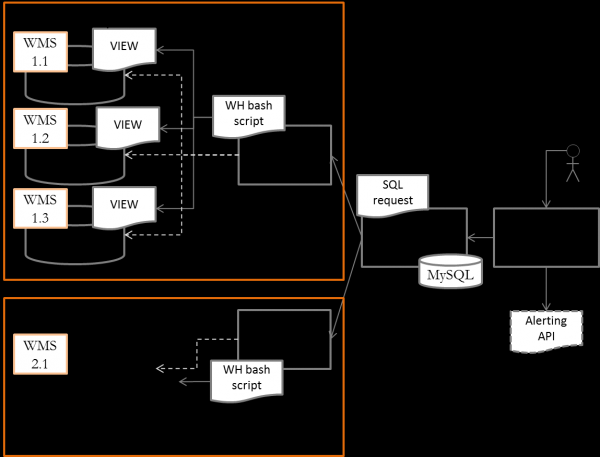
Elk WMS-exemplaar wordt gedefinieerd als een host voor het bewakingssysteem. Het verzamelen van metrische gegevens wordt uitgevoerd door een centrale server in het datacenternetwerk door een script uit te voeren met een voorbereide SQL-query. Als u een systeem wilt bewaken dat geen directe toegang tot de database aanbeveelt (bijvoorbeeld SAP EWM), kunt u scriptaanroepen naar gedocumenteerde API-functies gebruiken om indicatoren te verkrijgen of een eenvoudig programma schrijven in python/vbascript.
Er wordt een Zabbix-proxy-instantie in het warehousenetwerk geïmplementeerd om de belasting van de hoofdserver te verdelen. Proxy biedt ondersteuning voor het werken met alle lokale WMS-instanties. Wanneer de Zabbix-server opnieuw parameters opvraagt, wordt er op de host een script uitgevoerd met de Zabbix-proxy om metrische gegevens op te vragen uit de WMS-database.
Om grafieken en magazijnindicatoren op het centrale scherm weer te geven. server We implementeren Grafana in Zabbix. Naast het weergeven van kant-en-klare dashboards met infographics over de magazijnprestaties, zal Grafana worden gebruikt om afwijkingen in statistieken te monitoren en automatische waarschuwingen naar het magazijnservicesysteem te sturen voor incidentbeheer.
Laten we als voorbeeld de implementatie van controle over het laden van de ontvangstruimte van het magazijn beschouwen. De volgende factoren werden gekozen als de belangrijkste prestatie-indicatoren van de processen in dit deel van het magazijn:
- het aantal voertuigen in de ontvangstruimte, rekening houdend met de statussen (gepland, aangekomen, documenten, lossen, vertrek);
- werklast van de plaatsings- en bevoorradingszones (afhankelijk van de opslagcondities).
Instellingen
De installatie en configuratie van de belangrijkste componenten van het systeem (SQLcl, Zabbix, Grafana) worden in verschillende bronnen beschreven en worden hier niet herhaald. Het gebruik van SQLcl in plaats van SQLplus komt doordat SQLcl (de command line interface van het Oracle DBMS, geschreven in Java) geen extra installatie van Oracle Client vereist en direct werkt.
Ik beschrijf de belangrijkste punten waar u op moet letten bij het gebruik van Zabbix voor het bewaken van bedrijfsprocesindicatoren in magazijnen. Ook beschrijf ik een van de mogelijke manieren om deze te implementeren. Bovendien gaat dit bericht niet over veiligheid. De veiligheid van de verbindingen en het gebruik van de gepresenteerde methoden vereisen aanvullende ontwikkeling in het proces van het overbrengen van de pilotoplossing naar productief gebruik.
Het belangrijkste is dat bij de implementatie van een dergelijk systeem programmeren overbodig is en dat gebruikgemaakt kan worden van de instellingsmogelijkheden die het systeem biedt.
Het Zabbix-monitoringsysteem biedt verschillende opties voor het verzamelen van statistieken uit het bewaakte systeem. Dit kan worden gedaan door de gecontroleerde hosts rechtstreeks te pollen, of via een geavanceerdere methode om gegevens naar de server te sturen via de zabbix_sender van de host, inclusief methoden voor het configureren van laagwaardige detectieparameters. De methode van het rechtstreeks peilen van hosts door de centrale server is zeer geschikt voor het oplossen van ons probleem, omdat dit volledige controle biedt over de volgorde van ontvangst van metrische gegevens en garandeert dat er één pakket met instellingen/scripts wordt gebruikt, zonder dat deze naar elke gecontroleerde host hoeven te worden gedistribueerd.
Als ‘proefkonijnen’ voor het debuggen en inrichten van het systeem gebruiken wij WMS-werktabellen voor acceptatiemanagement:
- Voertuigen bij de receptie, alle aangekomen voertuigen: Alle voertuigen met statussen voor de periode "- 72 uur vanaf het huidige tijdstip" - SQL-query-identificatie: getCars.
- Geschiedenis van alle voertuigstatussen: Statussen van alle voertuigen met aankomsten in 72 uur — SQL-query-identificatie: autogeschiedenis.
- Geplande voertuigen voor acceptatie: Statussen van alle voertuigen met aankomst in de status "Gepland", tijdsinterval "- 24 uur" en "+24 uur" vanaf het huidige tijdstip - SQL-query-ID: auto'sIn.
Nadat we een aantal prestatiegegevens voor het magazijn hebben vastgelegd, kunnen we SQL-query's naar de WMS-database voorbereiden. Om query's uit te voeren, is het raadzaam om niet de hoofddatabase te gebruiken, maar de 'hot' kopie ervan: de standby.
We maken verbinding met het standby Oracle DBMS om gegevens te ontvangen. IP-adres voor verbinding met de testdatabase 192.168.1.106We slaan de verbindingsparameters op. server Zabbix in TNSNames.ORA van de SQLcl-werkmap:
# cat /opt/sqlcl/bin/TNSNames.ORA
WH1_1=
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.1.106)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = WH1_1)
)
)Hiermee kunnen we SQL-query's uitvoeren op elke host via EZconnect, waarbij we alleen de gebruikersnaam/het wachtwoord en de naam van de database hoeven op te geven:
# sql znew/Zabmon1@WH1_1We slaan de voorbereide SQL-query's op in de werkmap op de Zabbix-server:
/etc/zabbix/sqlen geef toegang aan de zabbix-gebruiker van onze server:
# chown zabbix:zabbix -R /etc/zabbix/sqlBestanden met verzoeken ontvangen een unieke identificatienaam voor toegang van de Zabbix-server. Elke query naar de database via SQLcl retourneert ons verschillende parameters. Gezien de specifieke kenmerken van Zabbix, dat slechts één metriek in een aanvraag kan verwerken, gebruiken we aanvullende scripts om de queryresultaten te parseren in afzonderlijke metrieken.
We bereiden het hoofdscript voor, dat we wh_Metrics.sh noemen, om een SQL-query naar de database aan te roepen, de resultaten op te slaan en een technische metriek te retourneren met indicatoren voor het succes van het ophalen van gegevens:
#!/bin/sh
## настройка окружения</i>
export ORACLE_HOME=/usr/lib/oracle/11.2/client64
export PATH=$PATH:$ORACLE_HOME/bin
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib64:/usr/lib:$ORACLE_HOME/bin
export TNS_ADMIN=$ORACLE_HOME/network/admin
export JAVA_HOME=/
alias sql="opt/sqlcl/bin/sql"
## задаём путь к файлу с sql-запросом и параметризованное имя файла
scriptLocation=/etc/zabbix/sql
sqlFile=$scriptLocation/sqlScript_"$2".sql
## задаём путь к файлу для хранения результатов
resultFile=/etc/zabbix/sql/mon_"$1"_main.log
## настраиваем строку подключения к БД
username="$3"
password="$4"
tnsname="$1"
## запрашиваем результат из БД
var=$(sql -s $username/$password@$tnsname < $sqlFile)
## форматируем результат запроса и записываем в файл
echo $var | cut -f5-18 -d " " > $resultFile
## проверяем наличие ошибок
if grep -q ora "$resultFile"; then
echo null > $resultFile
echo 0
else
echo 1
fiPlaats het voltooide bestand met het script in de map voor het plaatsen van externe scripts in overeenstemming met de Zabbix-proxy configuratie-instellingen (standaard - /usr/local/share/zabbix/externalscripts).
De identificatie van de database waaruit het script resultaten ontvangt, wordt doorgegeven als een scriptparameter. De DB-identificatie moet overeenkomen met de instellingenreeks in het bestand TNSNames.ORA.
Het resultaat van het aanroepen van een SQL-query wordt opgeslagen in een bestand van het volgende type: mon_base_id_main.log waar base_id = DB-identificatie ontvangen als scriptparameter. De opdeling van het resultatenbestand op basis van database-identificatiecodes wordt uitgevoerd als er gelijktijdig verzoeken van de server naar meerdere databases worden verzonden. De query retourneert een gesorteerde tweedimensionale reeks waarden.
Het volgende script, laten we het getMetrica.sh noemen, is nodig om een bepaalde metriek uit een bestand met het queryresultaat te verkrijgen:
#!/bin/sh
## определяем имя файла с результатом запроса
resultFile=/etc/zabbix/sql/mon_”$1”_main.log
## разбираем массив значений результата средствами скрипта:
## при работе со статусами, запрос возвращает нам двумерный массив (RSLT) в виде
## {статус1 значение1 статус2 значение2…} разделённых пробелами (значение IFS)
## параметром запроса передаём код статуса и скрипт вернёт значение
IFS=’ ‘
str=$(cat $resultFile)
status_id=null
read –ra RSLT <<< “$str”
for i in “${RSLT[@]}”; do
if [[ “$status_id” == null ]]; then
status_id=”$I"
elif [[ “$status_id” == “$2” ]]; then
echo “$i”
break
else
status_id=null
fi
doneNu zijn we klaar om Zabbix te configureren en te beginnen met het monitoren van de acceptatieprocesmetrieken in het magazijn.
Op elk databaseknooppunt wordt een Zabbix-agent geïnstalleerd en geconfigureerd.
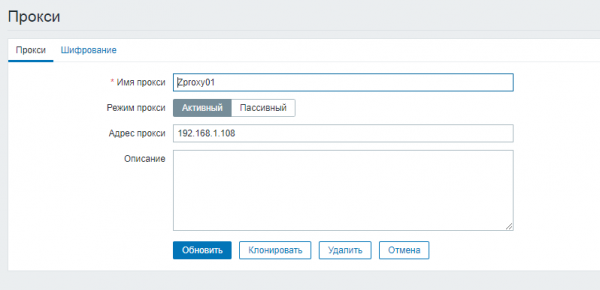
Op de hoofdserver definiëren we alle servers met Zabbix-proxy. Voor instellingen volgt u het volgende pad:
Beheer → Proxy → Proxy aanmaken
We definiëren de gecontroleerde hosts:
Instellingen → Netwerkknooppunten → Netwerkknooppunt maken
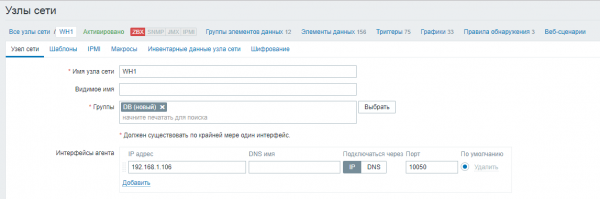
De hostnaam moet overeenkomen met de knooppuntnaam die is opgegeven in het configuratiebestand van de agent.
We specificeren de groep voor het knooppunt, evenals het IP-adres of de DNS-naam van het knooppunt met de database.
Wij creëren metrieken en specificeren hun eigenschappen:
Instellingen → Knooppunten → 'knooppuntnaam' → Gegevenselementen>Gegevenselement maken
1) Maak een hoofdmetriek om alle parameters uit de database op te vragen
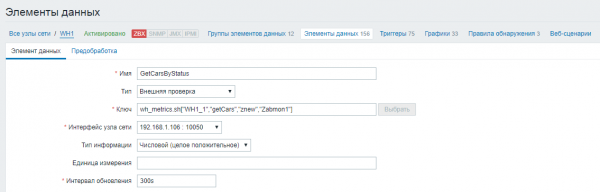
We stellen de naam van het data-element in en geven het type ‘Externe controle’ aan. In het veld “Sleutel” definiëren we een script waaraan we de naam van de Oracle-database, de naam van de SQL-query, inloggegevens en het wachtwoord voor verbinding met de database als parameters doorgeven. We stellen het query-update-interval in op 5 minuten (300 seconden).
2) Maak de resterende statistieken voor elke voertuigstatus. De waarden van deze statistieken worden gegenereerd op basis van de resultaten van de controle van de hoofdstatistiek.
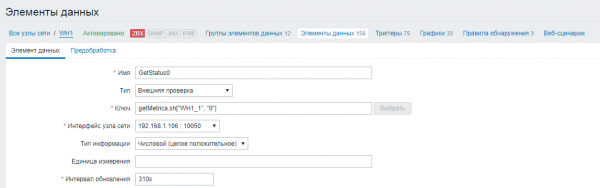
We stellen de naam van het data-element in en geven het type ‘Externe controle’ aan. In het veld “Sleutel” definiëren we een script waaraan we de naam van de Oracle-database en de statuscode waarvan we de waarde willen volgen als parameters doorgeven. We stellen het queryupdate-interval 10 seconden langer in dan de hoofdmetriek (310 seconden), zodat de resultaten tijd hebben om naar het bestand te worden geschreven.
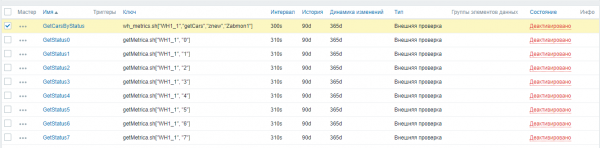
Om de juiste statistieken te verkrijgen, is de volgorde waarin controles worden geactiveerd van belang. Om conflicten bij het ontvangen van gegevens te voorkomen, activeren we eerst de hoofdmetriek GetCarsByStatus door het script wh_Metrics.sh aan te roepen.
Instellingen → Knooppunten → 'knooppuntnaam' → Data-elementen → Subfilter “Externe controles”. We vinken het gewenste vakje aan en klikken op “Activeren”.
Vervolgens activeren we de resterende statistieken in één bewerking, waarbij we ze allemaal tegelijk selecteren:
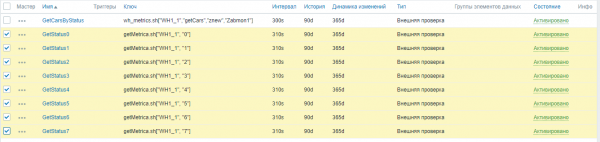
Nu is Zabbix begonnen met het verzamelen van bedrijfsgegevens over het magazijn.
In de volgende artikelen gaan we dieper in op het koppelen van Grafana en het maken van dashboards voor magazijnactiviteiten voor verschillende categorieën gebruikers. Daarnaast wordt op basis van Grafana controle op afwijkingen in de magazijnactiviteiten geïmplementeerd en, afhankelijk van de grenzen en herhaalbaarheid van de afwijkingen, registratie van incidenten in het Warehouse Management Service Center-systeem via API of het eenvoudig verzenden van meldingen naar de manager via e-mail.

Bron: www.habr.com
